
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With the improved knowledge on clinical relevance and more convenient access to the patient-reported outcome data, clinical researchers prefer to adopt minimal clinically important difference (MCID) rather than statistical significance as a testing standard to examine the effectiveness of certain intervention or treatment in clinical trials. A practical method to determining the MCID is based on the diagnostic measurement. By using this approach, the MCID can be formulated as the solution of a large margin classification problem. However, this method only produces the point estimation, hence lacks ways to evaluate its performance. In this paper, we introduce an m-out-of-n bootstrap approach which provides the interval estimations for MCID and its classification error, an associated accuracy measure for performance assessment. A variety of extensive simulation studies are implemented to show the advantages of our proposed method. Analysis of the chondral lesions and meniscus procedures (ChAMP) trial is our motivating example and is used to illustrate our method.
1. Introduction
Statistical significance is widely reported in clinical studies to infer treatment effect. For instance, in a randomised controlled trial to compare debridement to the observation of chondral lesions encountered during partial meniscectomy (Bisson et al., Citation2017), the difference of the patient outcomes before surgery and one year after is used to assess the existence of any statistically significant effect.
Although this framework based on a threshold of the p-value objectifies the research outcome, solely relying on it can have two potentially serious consequences. First, statistical significance only signifies the existence of treatment effect, no matter how large is the effect size. The statistical significance could result from a huge sample size, hence may clinically irrelevant to the patients at all. Second, a clinically importance effect could be classified as statistically non-significant due to various reasons, say, the small sample size in the study, hence be unfairly ignored. In brief statistical significance does not necessarily imply clinical importance, and vice versa.
Over the years clinical investigators are realising that the determination of a treatment's clinical importance is much more valuable and reliable than merely seeking its statistical significance. Also, the development of various patient-rated instruments contributes huge amounts of patient-reported outcome (PRO) data, which provides the researchers with chances to study the clinical relevance. In order to study clinical importance, Jaeschke, Singer, and Guyatt (Citation1989) proposed the concept of minimal clinically important difference (MCID). It is defined as the smallest change in an outcome that an individual patient would identify as important, therefore offers a threshold above which outcome is experienced as relevant by the patients. This avoids the problem of mere statistical significance (Wright, Hannon, Hegedus, & Kavchak, Citation2012). The MCID provides objective reference for clinicians and health policy-makers regarding the effectiveness of the treatment, hence has quickly gained its popularity (Erdogan, Leung, Pohl, Tennant, & Conaghan, Citation2016; McGlothlin & Lewis, Citation2014).
A variety of methods have been proposed to calculate the MCID. The anchor based method compares the changes in scores with an anchor as the reference. A popular anchor is the anchor question in the questionnaire. For instance, the short form (SF36) health survey (Ware & Sherbourne, Citation1992) serves this role in the ChAMP trial study (Bisson et al., Citation2017, Citation2018, Citation2019; Kluczynski et al., Citation2017). Hedayat, Wang, and Xu (Citation2015) adopted this anchor based method and formulated the MCID as the threshold value in post-treatment change such that the probability of disagreement between the estimated satisfaction based on the MCID and the PRO is minimised.
Although the proposal in Hedayat et al. (Citation2015) possesses the statistical rigour and paves the way for potential extension, it has some limitations. First, Hedayat et al. (Citation2015) rely on a testing data set with a very large sample size to have their method implemented and assessed; however, the sample size of a clinical study is usually much smaller, therefore such a testing data set is not available for real application. Second, Hedayat et al. (Citation2015) only provide a point estimation for the MCID, which is not informative enough in most clinical studies (Cook, Citation2008; Erdogan et al., Citation2016). Without an interval estimation, it is unknown how accurate this point estimation is. Furthermore, without an interval estimation, we have no idea how to compare multiple MCIDs derived for different population subgroups, hence the population heterogeneity could not be learned.
In this paper, we aim at solving the problems mentioned above and filling in this gap in the literature. We first introduce the concept of classification error to gauge the effectiveness of the MCID. More importantly, this concept also allows us to compare MCIDs derived for different population subgroups or computed using different methods. Second, using the m-out-of-n bootstrap technique, we obtain an interval estimation of the MCID, and also that of the classification error. The interval estimation makes it possible to conduct statistical inference on the MCID. It also allows us to fully learn the population heterogeneity based on the MCID.
Our proposal has two distinct features. First, different from Hedayat et al. (Citation2015), our framework does not rely on a testing data set with a large sample size, hence can be conveniently used in various clinical studies. Second, although the bootstrap has already been a well-known and established statistical technique since Efron (Citation1979), we stress that its conventional version cannot be directly applied in our context due to the restrictive conditions for it to be valid. Instead, the one we adopt is the m-out-of-n bootstrap with its theoretical properties justified in Shao (Citation1994), Shao (Citation1996), Bickel, Götze, and van Zwet (Citation1997) and among others.
In the remainder of this paper, we first introduce our motivating example, the ChAMP trial study in Section 2. Then in Section 3, we review the concept of MCID and introduce that of the classification error. Our methodology, including both simple linear and nonparametric kernel MCIDs and the bootstrap scheme to compute the confidence interval, is presented in Section 4. We show the finite sample performance of our proposed method through simulation studies in Section 5 and apply our method to the ChAMP trial study in Section 6. The mathematical details are contained in Appendix.
2. Motivating example: ChAMP trial
Our motivating example is the chondral lesions and meniscus procedures (ChAMP) trial that examines whether the presence of the chondral lesions surrounding the knee cartilage affects patients' recovery from the arthroscopic partial meniscectomy (APM) (Bisson et al., Citation2017). In the field of orthopaedics, APM is one of the most common treatment options to repair the knee damage especially for the patients with a meniscus tear. During the operations, however, the surgeons can often find the additional knee damages in the form of chondral lesions. The effect of these chondral lesions on patients' post-operative outcomes are unclear, and whether these lesions need to be treated by debridement remains an open question. Thus, the ChAMP trial is designed to help the clinical physicians better understand this relation and provide them with reasonable suggestions on preoperative evaluation and treatment option.
This study enrolled eligible patients who were years old, diagnosed with a symptomatically consistent meniscus tear by magnetic resonance imaging, and underwent APM. Of the subjects who enrolled, 190 patients with surgically significant chondral lesions were randomised to receive debridement (CL-Deb group; n=98) or observation (CL-noDeb group; n=92). Outcome measures include the Western Ontario and McMaster Universities Osteoarthritis Index (WOMAC) and the SF-36 health survey. Each outcome was evaluated at baseline and one-year postoperatively. The demographic data such as age and sex at baseline and surgical data including the location and type of meniscal tears were also collected.
The major goal of the study is to assess whether and how the debridement group is different from the observation group in terms of the change of the WOMAC pain score from enrolment to one year after surgery, and how it relates to other covariate variables and clinical biomarkers. In our investigation, we focus on the study of the interval estimation of the MCID and its classification error. We use an anchor based method to compute the MCID and the anchor question we use is in the SF-36 health survey.
3. The MCID and the classification error
In the ChAMP trial, we denote each patient's reported outcome in the SF-36 health survey as a binary variable, where Y =1 if the patient reports a better health condition after the surgery and Y =−1 otherwise. The difference of each patient's WOMAC pain score from baseline to one year after surgery, denoted as X, is treated as the patient's diagnostic measurement. Let a p-dimensional covariate be the patient's clinical profile with
.
It is reasonable and of interest to consider the MCID as a function of the patient's clinical profile,
. The population heterogeneity could also be learned from the knowledge of
. According to Hedayat et al. (Citation2015), the
is defined as the minimiser of
(1)
(1) where E is the expectation taken with respect to
and
is the standard sign function. Given independent and identically distributed observations
, the empirical version of the objective function in (Equation1
(1)
(1) ) becomes
(2)
(2) which involves the 0–1 loss function
. The direct minimisation of (Equation2
(2)
(2) ) is infeasible. In this paper, we follow Hedayat et al. (Citation2015) to approximate the
function with the non-smooth ramp loss function. Note that the non-smooth ramp loss is defined as
where
is a scalar factor. As
,
. Then our objective function becomes
(3)
(3) Due to the non-convexity of the non-smooth ramp loss, the optimisation problem in (Equation3
(3)
(3) ) requires nonconvex minimisation. Note that we can write
, where both
and
are convex functions. Hence, we apply the difference of convex (DC) algorithm (ThiHoaiAn & DinhTao, Citation1997) to minimise (Equation3
(3)
(3) ), which has the form
(4)
(4) Figure illustrates the relation among the
,
,
and
loss functions.
Figure 1. The illustration of the 0–1 loss , its surrogate non-smooth ramp loss
, and the DC decomposition
.
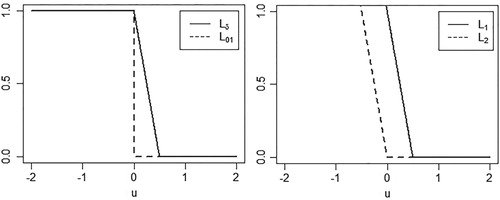
Once the minimiser is obtained, we can validate whether the debridement or the observation of the chondral lesions for each patient is indeed prescribed correctly. This is essential since it provides knowledgeable advice in future surgical practice for new patients. To re-evaluate whether the treatment is offered appropriately, we need a statistical measure to quantify the discrepancy between the patient's PRO
and its dichotomous diagnostic measure from learning his/her MCID
. Here, to avoid confusion, we use a generic notation
to represent any patient that would like to be validated. This results in
(5)
(5) where
is the expectation taken with respect to
. While there are other alternative measures to study, this error (Equation5
(5)
(5) ), usually called the classification error, or the test error, is popularly used in the statistical machine learning literature.
The estimation for the classification error is not a trivial task (Laber & Murphy, Citation2011). In this paper, we concentrate on creating confidence intervals for both the MCID and the classification error.
4. Methodology
In this section, we first present detailed algorithms to calculating MCID. We consider both simple linear MCID and its nonparametric kernel counterpart. We then introduce our bootstrap scheme to construct confidence intervals for MCID and the classification error.
4.1. Algorithms for MCID
It is of particular interest to clinicians if the MCID has a comprehensible structure. For instance, , where
could include the treatment variable, some of the demographic variables and clinical biomarkers. This is the simple linear MCID we consider below. On the other hand, although easily interpretable, a linear structure suffers from the model misspecification issue, thereby yields a solution which may not achieve optimal performance. Therefore, we also consider the nonparametric kernel MCID adopting the reproducing kernel Hilbert space framework.
4.1.1. A simple linear MCID
We assume . We add a penalty term
in (Equation4
(4)
(4) ) to avoid model overfitting. Let
, then the objective function in (Equation4
(4)
(4) ) is
, where
It is an iterative algorithm to minimise (Equation4
(4)
(4) ). Let
be the estimator of
at the kth iteration. We first approximate
with its affine minorisation function
, where
is the subgradient of
at
,
Hence
(6)
(6)
To solve (Equation6(6)
(6) ), we derive its dual problem by using the slack variable technique. The details are retained in Appendix 1. It shows that, we arrive at the dual problem
(7)
(7) subject to
and
. This optimisation problem only has simple box constraints hence can be solved by any quadratic programming method.
We conclude the algorithm by presenting how and
can be computed. The Karush–Kuhn–Tucker (KKT) conditions associated with optimisation problem (Equation7
(7)
(7) ) are, respectively,
(8)
(8)
(9)
(9)
(10)
(10)
(11)
(11)
(12)
(12)
(13)
(13) Therefore, we have three scenarios to discuss depending on the magnitude of
: if
, by (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ) we get
and
; if
, by (Equation10
(10)
(10) ) and (Equation13
(13)
(13) ) we have
and
; if
, by (Equation10
(10)
(10) ), (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ) we have
. Therefore, we can summarise the KKT conditions more concisely as
which implies
(14)
(14) Hence through (Equation8
(8)
(8) ) we can estimate
as
and through (Equation14
(14)
(14) ) we can estimate
as
Finally, we achieve the estimators
and
after iterative process (Equation6
(6)
(6) ) converges. For any new patient with data
, his/her predicted linear MCID is
4.1.2. A nonparametric kernel MCID
Define a feature vector for the profiles of the ith patient in the enlarged feature space. We can specify a continuous, symmetric and positive-semidefinite kernel function K corresponding to the inner product in the mapping φ, that is,
. Then, we have
with
and
, where
is the reproducing kernel Hilbert space (RKHS) with a kernel function
. The norm in
, denoted by
, is induced by the following inner product:
where
and
.
Following the representation theorem (Kimeldorf & Wahba, Citation1971), the nonparametric kernel MCID can be expressed as . Let
, then the objective function in (Equation4
(4)
(4) ) is
, where
Similar to the linear case, it is an iterative algorithm to minimise (Equation4
(4)
(4) ). Let
be the estimator of
at the
iteration. We first approximate
with its affine minorisation function
, where
is the subgradient of
at
,
Consequently,
(15)
(15)
Similar to the linear case, we use the slack variable technique and reach the dual problem
(16)
(16) subject to
and
. This optimisation problem only have simple box constraints hence can be solved by any quadratic programming method.
We conclude the algorithm by presenting how and
can be computed. The Karush–Kuhn–Tucker (KKT) conditions associated with optimisation problem (Equation16
(16)
(16) ) are, respectively,
(17)
(17)
(18)
(18)
(19)
(19)
(20)
(20)
(21)
(21)
(22)
(22) Three scenarios can be consequently discussed based on the magnitude of
: if
, by (Equation21
(21)
(21) ) and (Equation22
(22)
(22) ) we have
and
; if
, by (Equation19
(19)
(19) ) and (Equation22
(22)
(22) ) we obtain
and
; if
, by (Equation19
(19)
(19) ), (Equation21
(21)
(21) ) and (Equation22
(22)
(22) ) we obtain
. Now we can summarise the KKT conditions more concisely as
which implies
(23)
(23) Thus for
,
can be estimated via (Equation17
(17)
(17) ) as
and
can be estimated via (Equation23
(23)
(23) ) as
We can get the estimators
and
after iterative process (Equation15
(15)
(15) ) converges. As a result, for any new patient with data
, his/her predicted nonparametric kernel MCID is
. Note that the most common use of the nonparametric kernel function is the Gaussian radial basis function
, where σ is a positive scale parameter. If
, the nonparametric kernel case will reduce to the simple linear case.
4.2. Bootstrap procedure for MCID and the classification error
A point estimation alone does not allow one to quantify its uncertainty hence limits the usefulness of the MCID and its classification error in real applications. Hedayat et al. (Citation2015) postulates a testing data set with a very large sample size to quantify the effectiveness of their MCID in numerical studies, but such a testing data set is usually infeasible in clinical studies. Resampling method with the bootstrap as a representative, on the other hand, could serve as a tool to construct a confidence interval for an estimand under these situations.
To appropriately use bootstrap, we have to be cautious on the regularity conditions under which the theoretical properties can be justified (Bickel et al., Citation1997). If these conditions are not satisfied, the conventional bootstrap has to be properly modified. The objective function to be minimised in (Equation4(4)
(4) ) and the one in (Equation5
(5)
(5) ) are generally non-smooth functions. If there exists a non-negligible probability concentrated at the discontinuous points of the objective function, that is,
, it is called the irregular case under which Shao (Citation1994) showed that the conventional bootstrap is inconsistent. Instead, we propose to adopt the m-out-of-n bootstrap, a general method for remedying bootstrap inconsistency due to non-smoothness, and theoretically justified in Bickel et al. (Citation1997), Shao (Citation1994, Citation1996) and references therein.
The m-out-of-n bootstrap is the conventional nonparametric bootstrap except that the resample size, historically denoted as m, is of a smaller order compared to the original sample size n. That is, and
(or
) as
(Shao, Citation1994). The intuition of the m-out-of-n bootstrap is to let the empirical distribution tend to the true generative distribution at a faster rate, and essentially this allows the empirical distribution to reach its limit faster hence the bootstrap samples are drawn as if they were from the true generative distribution. Intuitively the requirement of
(or
) is consistent with Hedayat et al. (Citation2015) who required a very large sample size for their testing data. To some extent, in the m-out-of-n bootstrap, those n−m subjects serve the role of the testing sample (Shao, Citation1996). Practically m is usually chosen as
for some
. In our numerical studies, we choose
. Our algorithm is detailed below.
For , we generate bootstrap samples with size m as
. The MCID can be derived as
based on the method in Section 4. To be more specific, the simple linear MCID is
and the nonparametric kernel MCID is
, where
denotes the profile for a new patient. Accordingly, the classification error based on MCID
is computed as
Similarly,
can also be distinguished as
and
for simple linear and nonparametric kernel cases.
We repeat the above procedure in total B times. If we approach the simple linear MCID, we obtain . Let
and
be the
th and
th quantiles of
,
and
be the
th and
th quantiles of
,
and
be the
th and
-th quantiles of
, and
and
be the
th and
th quantiles of
. Thus, the
th confidence interval of α is given by
, the
th confidence interval of
is given by
,
th confidence interval of
is given by
, and
th confidence interval of
is given by
. If we approach the nonparametric kernel MCID, we have
. Similarly the
th confidence interval of
is given by
, and
th confidence interval of
is given by
.
5. Simulation studies
In this section, we apply the proposed method to provide confidence intervals for the MCID and the classification error via extensive numerical studies based on simulated data.
We consider two scenarios. In the first scenario, we generate a random sample consisting of independent and identically distributed observations , where we first generate patient's clinical profile
from a bivariate normal distribution
, where
and
. Then, we generate
from
, where
and
. Finally, we generate the binary patient reported outcome
from Bern(
), where
. Note that under this scenario, the linear MCID is the underlying truth. We also generate a new observation
with
,
and
from the same distribution as all
. The true value of the MCID for this patient is
.
The data under the second scenario are generated similarly to the first, except that the is generated from
. Hence the linear structure for the MCID is misspecified in this setting. Similar to the first scenario, we also generate a new observation
with
,
and
. The true value of the MCID for this new patient is
.
In each of the two scenarios, we apply both simple linear and nonparametric kernel MCID methods. The nonparametric kernel we apply is the Gaussian kernel defined as . The scale parameter can be found by setting it as the median of pairwise Euclidean distances within the observations
used to estimate the prediction rule (Hedayat et al., Citation2015). The m-out-of-n bootstrap samples are generated 1000 times for each case. For simplicity we set
in our numerical studies and we use the multifold cross validation method to determine the tuning parameter λ. We report two different sample sizes: n=500 and n=1000 for each situation.
Based on 500 simulation replications, our results are summarised in Tables and . It can be seen that, in scenario 1, the length of the confidence interval is much shorter and the coverage is much more accurate when the correct linear structure and a larger sample size are used. The length is much larger and the coverage is much broader when the nonparametric kernel function is used. In scenario 2, the coverage using the nonparametric kernel is much broader. More importantly we find that the estimation of the MCID using the incorrect simple linear structure is biased so that it gives very poor coverage. This issue cannot be uncovered if a confidence interval is not available as in Hedayat et al. (Citation2015). It also reinforces the necessity and importance of developing interval estimation for the MCID.
Table 1. Confidence interval for MCID in simulation studies.
Table 2. Confidence interval for the classification error in simulation studies.
We notice that the coverage for the classification error is very broad and Xu et al. (Citation2015) also noted the similar phenomenon. Due to the computational burden, we only explore our method up to the sample size of 1000. Under the situation with a much larger sample size, the coverage would become more accurate.
6. ChAMP trial analysis
In the ChAMP trial study, 190 patients with chondral lesions undergoing APM are randomised to either treatment (debridement) group or control (no debridement, observation) group
. It is of interest to investigate whether the debridement treatment on the chondral lesions would encourage the recovery from the surgery of repairing knee damage.
As we mentioned in the previous section, the binary variable Y is derived from the anchor question in the SF-36 health survey. The patient's diagnostic measurement X is the difference in WOMAC pain score between baseline and one year after surgery. The score is scaled from 0 (extreme problem) to 100 (no problem). Patient's clinical profile includes their age (continuous), treatment assignment (binary), sex (binary) and knee damage (four level categorical). The knee damage variable is the total number of types of meniscus tears that the patient suffers from. It reflects the severity of patient's knee damage.
After excluding the missing data, our analysis contains 157 patients. Among them, 80 patients are assigned in the debridement group and 77 others observation group. In our analysis, we first compute the MCID for the whole population, for the subpopulation within the debridement group (), for the subpopulation within the observation group (
), and their difference, respectively, where the MCID
only includes an intercept term. We call this ‘No model’ in Table . Then based on the structure
which we call ‘Model 1’, the structure
which we call ‘Model 2’, and the nonparametric
which we call ‘Model 3’ in Table , separately, we implement our proposed estimation procedure. The results are summarised in Table . Note that although we concentrate on interval estimations, we also list the ‘point estimation’ column mainly for the purpose of comparing with the results in Hedayat et al. (Citation2015). Here we generated the m-out-of-n bootstrap samples B=1000 times with
. Also, a sensitivity analysis on the value of B in Table demonstrates that the results are not sensitive when it varies from around 500 to 1500.
Table 3. Interval estimation for the ChAMP trial analysis.
Table 4. Sensitivity analysis for the ChAMP trial.
From Table , the point estimation of MCID for the subgroup 2.0216 looks quite different from that for the
subgroup
. Without the interval estimation, one would believe that they are different however with no further evidence on the degree of how they are different. Now with interval estimation, we see the confidence interval for each of them covers zero, and the confidence interval for the difference also covers zero. The similar phenomenon could also be observed under either ‘Model 1’ or ‘Model 2’ or ‘Model 3’.
Across the first three models, each of the MCID quantities has slightly different estimates, but each of their confidence intervals covers zero. ‘Model 3’ has difference MCID estimates than its linear counterpart, indicating the potential model interpretability insufficiency contributed by the linear component of the MCID.
Also for the treatment effect in ‘Model 1’ and ‘Model 2’, although their estimates are different, each of their confidence intervals also covers zero. As we can see, although ‘Model 3’ looks more flexible than its linear counterpart, it lacks clear interpretability of the treatment effect. The different results from ‘No model’ and ‘Model 3’ also indicates that there may also exist some other unobserved covariate variables that may play a role to quantifying the population heterogeneity in terms of MCID.
The classification errors for the first three models are roughly similar with that of ‘Model 1’ slightly greater than ‘Model 2’. This is reasonable since ‘Model 2’ controls more covariates hence should have a greater ability for model interpretability. ‘Model 3’ has smaller lower bound and upper bound of its confidence interval than ‘Model 2’ because it is generally acknowledged that a nonparametric kernel model entails fewer model assumptions than its linear counterpart model hence is regarded as more flexible.
In all, besides the point estimation of the MCID in each population of interest, our proposed method also provides its interval estimation which gives us a better understanding of the scale of MCID hence could facilitate us to compare with some certain historical values or values from other populations or other diseases so that a better, more convincing health policy decision could be made. The ChAMP study shows that the MCID between the debridement group and the observation group has some difference, but that difference is not significant. One of the major findings of the ChAMP trial study is that to debride the chondral lesions does not have a statistically significant effect hence recommends that not to debride the chondral lesions in future surgical practice (Bisson et al., Citation2017). Using the proposed method for the MCID in this paper, we reach the same conclusion. This could have a big impact on the orthopaedics surgical practice since the additional debridement of chondral lesions would bring a significant medical cost to the patients.
Acknowledgments
The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Zehua Zhou
Zehua Zhou is PhD candidate from the Department of Biostatistics at SUNY Buffalo. Before that, he obtained his Bachelor degree in Bioengineering from China Pharmaceutical University in 2014 and his Master degree in Biostatistics from SUNY Buffalo in 2017. He is interested in statistical machine learning methods, missing data analysis, and personalized medicine.
Jiwei Zhao
Jiwei Zhao is Assistant Professor from the Department of Biostatistics at SUNY Buffalo. He earned his PhD degree in Statistics from the University of Wisconsin-Madison in 2012. He is generally interested in using statistical and machine learning techniques to solve challenging problems in biomedical data science.
Melissa Kluczynski
Melissa Kluczynski is Clinical Research Associate from the Department of Orthopaedics at SUNY Buffalo. She is also affiliated with the UBMD Orthopaedics and Sports Medicine.
References
- Bickel, P., Götze, F., & van Zwet, W. (1997). Resampling fewer than n observations: Gains, losses, and remedies for losses. Statistica Sinica, 7, 1–31.
- Bisson, L. J., Kluczynski, M. A., Wind, W. M., Fineberg, M. S., Bernas, G. A., Rauh, M. A., … Zhao, J. (2017). Patient outcomes after observation versus debridement of unstable chondral lesions during partial meniscectomy. The Journal of Bone and Joint Surgery, 99, 1078–1085. doi: 10.2106/JBJS.16.00855
- Bisson, L. J., Kluczynski, M. A., Wind, W. M., Fineberg, M. S., Bernas, G. A., Rauh, M. A., … Zhao, J. (2018). How does the presence of unstable chondral lesions affect patient outcomes after partial meniscectomy? The ChAMP randomized controlled trial. The American Journal of Sports Medicine, 46, 590–597. doi: 10.1177/0363546517744212
- Bisson, L., Phillips, P., Matthews, J., Zhou, Z., Zhao, J., Wind, W., Fineberg, M., Bernas, G., Rauh, M., Marzo, J. and Kluczynski, M. (2019). Association Between Bone Marrow Lesions, Chondral Lesions, and Pain in Patients Without Radiographic Evidence of Degenerative Joint Disease Who Underwent Arthroscopic Partial Meniscectomy. Orthopaedic Journal of Sports Medicine, 7(3), 2325967119830381. doi: 10.1177/2325967119830381
- Cook, C. E. (2008). Clinimetrics corner: The minimal clinically important change score (MCID): A necessary pretense. Journal of Manual & Manipulative Therapy, 16, 82E–83E. doi: 10.1179/jmt.2008.16.4.82E
- Efron, B. (1979). Bootstrap methods: Another look at the jackknife. The Annals of Statistics, 7, 1–26. doi: 10.1214/aos/1176344552
- Erdogan, B. D., Leung, Y. Y., Pohl, C., Tennant, A., & Conaghan, P. G. (2016). Minimal clinically important difference as applied in rheumatology: An OMERACT Rasch Working Group systematic review and critique. The Journal of Rheumatology, 43, 194–202. doi: 10.3899/jrheum.141150
- Hedayat, A., Wang, J., & Xu, T. (2015). Minimum clinically important difference in medical studies. Biometrics, 71, 33–41. doi: 10.1111/biom.12251
- Jaeschke, R., Singer, J., & Guyatt, G. H. (1989). Measurement of health status: Ascertaining the minimal clinically important difference. Controlled Clinical Trials, 10, 407–415. doi: 10.1016/0197-2456(89)90005-6
- Kimeldorf, G., & Wahba, G. (1971). Some results on Tchebycheffian spline functions. Journal of Mathematical Analysis and Applications, 33, 82–95. doi: 10.1016/0022-247X(71)90184-3
- Kluczynski, M. A., Marzo, J. M., Wind, W. M., Fineberg, M. S., Bernas, G. A., M. A. Rauh, … Bisson, L. J. (2017). The effect of body mass index on clinical outcomes in patients without radiographic evidence of degenerative joint disease after arthroscopic partial meniscectomy. Arthroscopy: The Journal of Arthroscopic & Related Surgery, 33, 2054–2063.
- Laber, E. B., & Murphy, S. A. (2011). Adaptive confidence intervals for the test error in classification. Journal of the American Statistical Association, 106, 904–913. doi: 10.1198/jasa.2010.tm10053
- McGlothlin, A. E., & Lewis, R. J. (2014). Minimal clinically important difference: Defining what really matters to patients. JAMA, 312, 1342–1343. doi: 10.1001/jama.2014.13128
- Shao, J. (1994). Bootstrap sample size in nonregular cases. Proceedings of the American Mathematical Society, 122, 1251–1262. doi: 10.1090/S0002-9939-1994-1227529-8
- Shao, J. (1996). Bootstrap model selection. Journal of the American Statistical Association, 91, 655–665. doi: 10.1080/01621459.1996.10476934
- Thi Hoai An, L., & Dinh Tao, P. (1997). Solving a class of linearly constrained indefinite quadratic problems by DC algorithms. Journal of Global Optimization, 11, 253–285. doi: 10.1023/A:1008288411710
- Ware, J. E., Jr, & Sherbourne, C. D. (1992). The MOS 36-item short-form health survey (SF-36): I. Conceptual framework and item selection. Medical Care, 30, 473–483. doi: 10.1097/00005650-199206000-00002
- Wright, A., Hannon, J., Hegedus, E. J., & Kavchak, A. E. (2012). Clinimetrics corner: A closer look at the minimal clinically important difference (MCID). Journal of Manual & Manipulative Therapy, 20, 160–166. doi: 10.1179/2042618612Y.0000000001
- Xu, Y., Yu, M., Zhao, Y.-Q., Li, Q., Wang, S., & Shao, J. (2015). Regularized outcome weighted subgroup identification for differential treatment effects. Biometrics, 71, 645–653. doi: 10.1111/biom.12322
Appendices
Appendix 1
To solve (Equation6(6)
(6) ), we need to derive its dual problem by replacing the loss function in
with slack variables
,
, and adding two sets of constraints. This leads to
(A1)
(A1) subject to
and
,
, where
. Then its primary Lagrangian is
where
and
are vectors of non-negative Lagrange multipliers, corresponding to the two sets of constraints in (EquationA1
(A1)
(A1) ). Setting derivatives of the Lagrangian with respect to the primary space variables
and
to 0, we get
Plugging them back to
, we have
where
is a square matrix with
th element as
,
,
.
Appendix 2
To solve (Equation15(15)
(15) ), we need to derive its dual problem by replacing the loss function in
with slack variables
, and adding two sets of constraints. This results in
(A2)
(A2) subject to
and
, where
. Then its primary Lagrangian is
where
and
are vectors of non-negative Lagrange multipliers, corresponding to the two sets of constraints in (EquationA2
(A2)
(A2) ). Setting derivatives of the Lagrangian with respect to the primary space variables
and
to 0, we get
Plugging them back to
, we have
where
is a square matrix with
th element as
,
,
.