
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
With a view to providing a tool to accurately model time series processes which may be corrupted with errors such as measurement, round-off and data aggregation, this study developed an integrated moving average (IMA) model with a transition matrix for the errors resulting in a convex combination of two ARMA errors. Datasets on interest rates in the United States and Nigeria were used to demonstrate the application of the formulated model. Basic tools such as the autocovariance function, maximum likelihood method, Newton–Raphson iterative method and Kolmogorov–Smirnov test statistic were employed to examine and fit the formulated specification to data. Test results showed that the proposed model provided a generalisation and a more flexible specification than the existing models of AR error and ARMA error in fitting time series processes in the presence of errors.
1. Introduction
In the study on structural relationships, a question of practical interest to researchers is how to describe relationships when concerned variables are measured with errors. This investigation started with early influential studies such as Lindley (Citation1947), Madansky (Citation1959), Kendall and Stuart (Citation1961) and Barnett (Citation1967). More recent studies include Schneeweiss and Shalabh (Citation2007) and Rudelson and Zhou (Citation2017) among others. Extension to time series models was also discussed in Eni, Ogban, Ekpenyong, and Atsu (Citation2007), who developed a model for autoregressive process (AR) which was observed with measurement errors suspected to be MA(1) correlated. Follow-up study by Eni and Mahmud (Citation2008) formulated a first order integrated moving average, IMA(1) model for a process in which the error is uniformly AR(1) correlated. For an IMA process observed with error which may not follow an AR process, Eni (Citation2013) proposed an IMA(1) model corrupted with ARMA(1,1) error. We acknowledge that in real life situations, an otherwise naturally IMA process may as a result of certain errors (such as measurement and round-off) be corrupted in form of disturbance by a combination of several processes such that the error pattern varies, say between AR and ARMA processes within a specified period, arising from the varying dynamics of the process to be observed. Thus in the present paper, we focus on situations when an IMA(1) process is observed with measurement error which follows a convex combination of AR(1) and ARMA(1,1) errors. We assumed that the transition from one error pattern to another at a specified time is governed by a Markov modulated process.
In technical terms, consider an integrated moving average model (Box & Jenkins, Citation1976):
(1)
(1) where
is the output variable,
is white noise process with 0 mean and constant variance
and θ, a weight parameter, L is a backward shift operator. If
is not directly observable but instead we observe
where
is an error component introduced by faulty measurement or observation process, Model (Equation1
(1)
(1) ) then becomes
(2)
(2) where
and
This study intends to develop an integrated moving average model (Equation1
(1)
(1) ) for the case in which
is a Markov modulated mixture of AR(1) and ARMA(1,1).
The motivation behind this study is simple to understand: In applications, dynamic time series processes usually undergo some ‘discontinuities’ so that the assumption that their underlying processes are constant over time may not be realistic. Examples may be constructed on how such ‘discontinuities’ manifest: The financial crisis of 2008, for instance, provides a good example on how financial markets experience variations in the states of their liquidity over time. Exchange rate movements may alternate between two states of appreciation and depreciation (Engel & Hamilton, Citation1990) or among the three states of ‘stagnation’, appreciation and depreciation (Ayodeji, Citation2016) over time. Furthermore, Akay and Yilmazkuday (Citation2008) noted that business cycles may vary among the three states of recession, low and high growth states. Garcia and Perron (Citation1996) also made a similar submission for interest rates. In the same vein, the distribution of error pattern in time series processes may vary over time. In time series analysis, we are not concerned just about modelling variable of interest, but if (and when) such variables are subject to ‘instability’ over time, then such instability must be taken into consideration.
The study therefore has three main objectives; first, to formulate an IMA model corrupted with a combination of ARMA errors using the concepts of convex mixture and Markov processes; second, to estimate the parameters of the formulated model using the maximum likelihood method incorporating the autocovariance function approach; and third, to demonstrate the usage of the proposed model in application to interest rates in the United States and Nigerian financial institution. We will also validate our model by comparing empirical results with those from pure ARMA processes using the Kolmogorov–Smirnov test and some graphical analysis.
Two major advantages accrue from this study: first, a more flexible and realistic model to describe time series process observed with measurement error; and second, a generalisation of the models provided in Eni and Mahmud (Citation2008) and Eni (Citation2013). The plan of the study is as follows: Section 2 builds up IMA(1) model corrupted with a Markov modulated convex combination of ARMA(1,1) errors, Section 3 presents some theoretical results and fits the proposed model to a set of data on interest rates. Some comparison measures were also employed to evaluate the adequacy of the proposed model with respect to existing models of IMA(1) with AR and ARMA errors. Some concluding remarks were provided in Section 4.
2. Methodology
Suppose the error in Equation (Equation2
(2)
(2) ) is a Markov modulated mixture of AR(1) and ARMA(1,1), so that when
is AR(1) correlated,
(3)
(3) and when it is ARMA(1,1) correlated,
(4)
(4) Let A be the transition matrix for
between AR(1) and ARMA(1,1), that is,
where
Let
(5)
(5) For convex combination condition to be satisfied, it is required that
(6)
(6) At steady state,
(7)
(7)
(8)
(8) so that a convex combination of
can be written as
(9)
(9) Updating Equation (Equation2
(2)
(2) ) with (Equation9
(9)
(9) ) gives
(10)
(10) where
is a white noise process uncorrelated with
.
Our next task is to estimate the parameters φ in ,
,
, β, p and q in the error term
For simplicity, we note that the observed process (Equation10
(10)
(10) ) may be identified as ARMA(2,3):
(11)
(11) where
is a white noise process. Comparing Equations (Equation10
(10)
(10) ) and (Equation11
(11)
(11) ) we make the following correspondence:
(12)
(12)
(13)
(13)
(14)
(14)
Grouping the white noise process in Equation (Equation14(14)
(14) ) according to time t−i,
we have
(15)
(15)
(16)
(16)
(17)
(17)
(18)
(18) We solve Equation (Equation11
(11)
(11) ) through the maximum likelihood estimation method to obtain estimates of
,
,
,
and
and consequently,
and
To estimate the remaining unknowns, φ, β, p and q, we must obtain variances
and
of the white noise processes
and
respectively. Barnett (Citation1967) has shown that if
and
are known (the so-called over-identified case), then the maximum likelihood of relevant parameters can be obtained by solving directly the likelihood equation. Moran (Citation1971) also demonstrated that if the ratio
is known instead, the desired parameters are identifiable. In this case, however,
and
are not known, neither is their ratio. We therefore adopt the autocorrelation function approach as described in Eni (Citation2013). The following theorems, remarks and corollaries give the relevant expressions.
3. Main results
Define the following quantities,
By Box and Jenkins (Citation1976),
Also,
Lemma 3.1
The variances and
of the white noise process
and
are
(19)
(19)
(20)
(20) where
(21)
(21)
(22)
(22)
(23)
(23)
(24)
(24)
(25)
(25)
(26)
(26)
Proof.
Multiply Equation (Equation10(10)
(10) ) by
and take expectations to obtain
(27)
(27) To complete the proof, it is required to obtain estimates for
and
These are obtained by multiplying Equation (Equation10
(10)
(10) ) by
and
individually, and taking expectations to obtain
(28)
(28)
(29)
(29)
(30)
(30)
(31)
(31)
(32)
(32)
(33)
(33) Substituting Equations (Equation28
(28)
(28) )–(Equation33
(33)
(33) ) into (Equation27
(27)
(27) ) and re-arranging gives
(34)
(34) Taking into account Equations (Equation21
(21)
(21) )–(Equation23
(23)
(23) ), Equation (Equation34
(34)
(34) ) can be written compactly as
(35)
(35) Again, multiplying Equation (Equation10
(10)
(10) ) by
taking expectations and re-arranging we have
(36)
(36) which taking into account Equations (Equation24
(24)
(24) )–(Equation26
(26)
(26) ) can also be written compactly as
(37)
(37) We may then solve Equations (Equation35
(35)
(35) ) and (Equation37
(37)
(37) ) simultaneously to obtain the desired estimates of
and
Remark 3.2
Given Model (Equation11(11)
(11) ), the variance of the observed process
is
(38)
(38)
Now that the variances and
have been estimated, we estimate the remaining unknowns, φ, β, p and q, using the following iterative technique developed below:
Theorem 3.3
Given the IMA(1) process (Equation10(10)
(10) ) corrupted with convex combination of AR(1) and ARMA(1,1) processes. The parameters φ, β, p and q can be estimated using the Newton–Raphson iterative formula
(39)
(39) where
(40)
(40)
(41)
(41)
(42)
(42) and X,Q,S,Y and S are as defined earlier in Equations (Equation21
(21)
(21) )–(Equation26
(26)
(26) ).
Proof.
From Equation (Equation11(11)
(11) ),
(43)
(43) To obtain expressions for
and
we again multiply Equation (Equation11
(11)
(11) ) by
and
respectively, and take expectations to obtain
(44)
(44)
(45)
(45)
(46)
(46) Updating Equation (Equation43
(43)
(43) ) with (Equation44
(44)
(44) )–(Equation46
(46)
(46) ) and re-arranging, we obtain
(47)
(47) By Equations (Equation41
(41)
(41) ) and (Equation42
(42)
(42) ), Equation (Equation47
(47)
(47) ) may be written compactly as
Substituting for
(see Equation (Equation38
(38)
(38) )),
or
We expect the values of and q to be such that
at the point of convergence.
Remark 3.4
The starting point for the iterative equation (Equation39(39)
(39) ) can be obtained as
(48)
(48)
(49)
(49)
(50)
(50) where
Proof.
Along the line of Eni (Citation2013), set so that Equations (Equation15
(15)
(15) )–(Equation18
(18)
(18) ) respectively become
(51)
(51)
(52)
(52)
(53)
(53)
(54)
(54)
Next, the coefficients in Equations (Equation52(52)
(52) )–(Equation54
(54)
(54) ) are compared and then solved for β, φ and q simultaneously to obtain the desired starting point
and
Remark 3.5
In summary, an algorithm may be developed for the estimation of IMA (1) model corrupted with convex combination of ARMA errors as follows:
Estimate the first three autocovariance values of
for a given set of data. Will be computed using
Obtain the maximum likelihood estimate of
Estimate the remaining parameters φ, β, p and q using the iterative formula (Equation39
Estimate the variance of the observed process
Corollary 3.6
Eni (Citation2013) results correspond to the case p=0 and q=1 in Equation (Equation9(9)
(9) ).
Proof.
Set p=0 and q=1 in Equation (Equation9(9)
(9) ) to get
(56)
(56) then substitute for
in Equation (Equation2
(2)
(2) ) to obtain
(57)
(57) which corresponds to Eni's (Citation2013) Equation (4).
Corollary 3.7
Eni and Mahmud (Citation2008) results correspond to the case p=1 and q=0 in Equation (Equation9(9)
(9) ).
The proof is easily obtained by setting p=1 and q=0 in Equation (Equation9(9)
(9) ) and following similar procedure as highlighted in Corollary (3.6).
4. Empirical results and discussion
The dataset used here are interest rate spread from financial institutions.Footnote1 They therefore inherently contain errors due to aggregation and round-off of figures. The task of an appropriate time series model however is to produce reliable estimates of the unknown parameters. It must be noted that the quality and reliability of these estimates depend upon the the dataset. The first set of data used was obtained from World bank (http://data.worldbank.org/indicator/FR'INR.LNDP). It comprised 138 data points on quarterly ‘interest rate spread’ of Nigeria banks from February 1970 to October 2015. The second data set was on monthly interest rate in USA from January 1950 to February 2017. It was obtained from Federal Bank of Saint Louis (https://fred.stlouisfed.org/series/INTDSRUSM193N), a total of 806 data points. Both data were approximated to two decimal places.
Table presents the estimates of the parameters ,
,
of the autocovariance function (ACF),
,
,
,
,
of the reduced form of IMA(1) model, that is, the ARMA(2,3) model – See Equation (Equation11
(11)
(11) ); and the remaining unknowns φ, β, p and q as given in Equation (Equation10
(10)
(10) ). The computations were carried out via MAPLE, MINITAB and MATLAB Statistical Packages.
Table 1. Estimates of the relevant parameters.
Just as expected, the autocovariances ,
and
presented in Table for both data are all positive. The estimated autocovariances were used to obtain the estimates of the parameters of ARMA (2,3) Model. Given
and
,
and
may be computed by solving Equations (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ) so that for Nigeria,
and
Similarly, for USA,
The remaining parameters φ, β, p and q were obtained as discussed earlier in Theorem 3.3. By Remark 3.4, the set of starting values (
,
,
,
) for (φ, β, p, q) is (0.4657, 2.7658, 0.55, 1.389) and (0.6529, 1.3941, 0.65, 1.3772) for Nigeria and USA, respectively. Recall from Equation (Equation1
(1)
(1) ) that the invertibility parameter
; so that for Nigeria,
and for USA,
. Since
in both cases, our interest that the IMA(1) model be non-invertible is satisfied in both datasets.
Thus, the proposed IMA(1) model corrupted with a convex combination of ARMA errors for both countries are
Nigeria:
(58)
(58) and USA:
(59)
(59)
When p=1 and q=0, Equation (Equation10(10)
(10) ) reduces to Eni and Mahmud (Citation2008) IMA (1) model corrupted with AR (1) error.
Nigeria:
(60)
(60) and USA:
(61)
(61) Also, when p=0 and q=1, Equation (Equation10
(10)
(10) ) reduces to Eni (Citation2013) IMA (1) model corrupted with ARMA (1,1) error.
Nigeria:
(62)
(62) and USA:
(63)
(63)
Furthermore, it can also be inferred from Table that for Nigeria, the transition probability is given as
(64)
(64) This information is summarised in the following matrix:
Clearly, the error associated with the system of interest rates of Nigeria banks easily transits from AR(1) error to ARMA (1,1) error than the converse since Also, the probability that the error is better modelled as AR(1) from year to year between February 1970 and October 2015 is
while the probability that the error system is better modelled uniformly with ARMA (1,1) within the specified period is
This indicates that the error is better modelled with ARMA (1,1) most of the time than with AR (1).
In addition, the aggregate probability of
is easily computed using Equation (Equation5
(5)
(5) ):
and
It is also obvious that
, i=1,2 are non-negative and they add up to 1, an indication that the two conditions imposed for convex combination in Equation (Equation6
(6)
(6) ) are satisfied in the case of Nigeria. Thus the error associated with the Nigerian data is essentially a mixture (0.3934, 0.6066) of AR(1) and ARMA(1,1).
Similarly for USA, the transition probability matrix
Also, it is clearly seen that the error system of housing interest rates in USA easily transits from ARMA(1,1) error to AR (1) error than the converse since
Also, the probability that the system remains in AR(1) permanently from year to year between January 1950 and February 2017 is 0.8025 while the probability that the system is better modelled uniformly with ARMA (1,1) within the specified period is 0.6441. This implies that the error is better modelled with AR (1) most of the time than with ARMA (1,1). We observed further that while the Nigerian error system is likely to change from AR to ARMA with probability 0.4259 and from ARMA to AR with probability 0.2762, the corresponding probabilities for the USA data are 0.1975 and 0.3559, respectively; indicating that the error associated with the Nigerian interest rate changes more swiftly from AR to ARMA but less swiftly from ARMA to AR compared to the USA system.
In addition, for US, and
Obviously, the two conditions imposed for convex combination are also satisfied in this case. Thus the error associated with the USA data is essentially a mixture (0.6431, 0.3569) of AR(1) and ARMA(1,1).
Finally, the variances of and
of the white noise processes
and
(see Equations (Equation19
(19)
(19) ) and (Equation20
(20)
(20) )) for Nigeria are
and
so that
In the same vein,
for USA implies that
4.1. Selection of model of best fit
In order to select the model of best fit, we compared each of the fitted values from the three models of Eni and Mahmud (Citation2008), Eni (Citation2013) and the proposed with the observed using the Kolmogorov–Smirnov test. First the cumulative probability , i=0,1,2,3 for the distribution of observed and fitted data from the three models were computed. Denote
the cumulative probability of the observed,
the cumulative probability from the proposed model,
the cumulative probability from Eni and Mahmud (Citation2008) model (i.e. AR error pattern) and
the probability from Eni (Citation2013) model (i.e. ARMA error pattern). Table presents the absolute deviations of each of
from
for US interest rates while Table displayed those on interest rates in Nigeria. Actual cumulative probabilities for US and Nigerian interest rates data are presented in the Appendix – Tables and .
Table 2. Absolute deviations of cumulative probability frequency of fitted models from the observed for US interest rate spread data.
Table 3. Absolute deviations of cumulative probability frequency of fitted models from the observed for interest rate spread data in Nigeria.
It is easily seen that the proposed (i.e. ) had accurate cumulative probabilities in 7 out of 15 cases with a maximum absolute error of
whereas AR error pattern (i.e.
) had accurate cumulative probabilities in 4 out of 16 cases with a maximum absolute error of
while ARMA error pattern (i.e.
) had accurate cumulative probabilities in 4 out of 16 cases with a maximum absolute error of
Our submission therefore is that
is closer to the observed
than
and
are. Thus, in this case, the order of performance is
Table also presents the absolute deviations of each of from
as displayed in Appendix, Table . It is easily seen that the proposed (i.e.
) had accurate cumulative probabilities in 5 out of 12 cases with a maximum absolute error of
whereas AR error pattern (i.e.
) had accurate cumulative probabilities in 2 out of 12 cases with a maximum absolute error of
while ARMA error pattern (i.e.
) had accurate cumulative probabilities in 4 out of 12 cases with a maximum absolute error of
It can therefore be concluded that
is closer to the observed
than
and
are. Thus the order of performance is
.
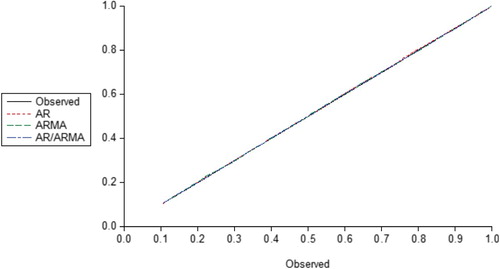
Further comparison was made in terms of the cumulative frequency distribution of the observed and the three models of AR/ARMA, AR and ARMA. Figures and plotted the cumulative frequency distribution of the Observed against each of the three fitted models for Nigerian and US interest rates, respectively. A careful look at Figure in particular shows that the combined AR/ARMA provided the best straight line graph while the other two deviated markedly from the Observed (i.e. the solid line) around 0.4 and 0.9. This is less pronounced for the USA data in Figure . From both plots, it is obvious that the AR/ARMA model produces the best straight line graph compared to AR model and ARMA model which clearly shows that the fitted values from the proposed model are closest to the observed than Eni and Mahmud (Citation2008) and Eni (Citation2013), therefore, the best fit to the data points.
Figure 1. A plot of the cumulative frequency distribution of the observed against each of the three fitted models of AR ARMA and AR/ARMA, respectively, for Interest Rate Spread in Nigeria.
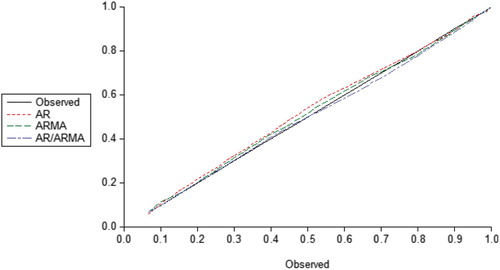
Figure 2. A plot of the cumulative frequency distribution of the observed against each of the three fitted models of AR ARMA and AR/ARMA, respectively, for Interest Rate in USA.
Finally, we conducted a Kolmogorov–Smirnov (K–S) test to confirm our observations from Tables and , and Figures and . The result is presented in Table . In testing the null hypothesis that a model fits the datasets for Nigerian and US interest rates, it is observed that the p-value for the three models were greater than a significant level of which implies that there is no significant evidence against the null. However, we observed further that the proposed had the lowest z-score and consequently, the highest p-value compared to the other two models.Footnote2 This indicates clearly that the generalisation proposed in this study provides more flexible specification to model time series processes in the presence of errors.
Table 4. K–S test values on observed against various models for Nigeria and USA dataset points.
5. Conclusion
This study formulated a credible, flexible and versatile model capable of accounting for errors from different sources and has been able to apply basic tools such as the autocovariance function, maximum likelihood method, Newton–Raphson iterative method and Kolmogorov–Smirnov test statistic to examine and fit the formulated specification to data. Based on the theoretical results and data application, we concluded that the proposed model is a generalisation of the existing models on AR error and ARMA error.
Empirical results from the application of the proposed model to the Nigerian and US interest rates showed that the error associated with Nigerian interest rates system is essentially a mixture (0.3934, 0.6066) of AR and ARMA and has 0.574 and 0.724 chances of being modelled uniformly as AR and ARMA, respectively. The corresponding probabilities for the US data were (0.6431, 0.3569) for mixture and 0.803 for remaining an AR, and 0.644 for remaining an ARMA. Furthermore, while the Nigerian error system is more likely to switch between AR and ARMA errors with probability 0.426, USA's has lower probability of switching between AR and ARMA with a margin of 0.228 relative to Nigerian system. This indicates that the Nigeria data changes more swiftly from AR to ARMA but less swiftly from ARMA to AR compared to US system. The graphical analysis indicated that the proposed model provided the best fit for the two interest rates datasets considered. This was further confirmed with the Kolmogorov–Smirnov test as the proposed model had more accurate cumulative probabilities, gave the least maximum absolute deviations and consequently the lowest z-scores for the error systems of Nigerian and US interest rates, respectively. Thus, the Nigerian interest rates error pattern more likely follows ARMA than AR, while that of USA has a higher probability of being modelled as AR than ARMA.
Finally, this study discussed AR(1), ARMA(1,1) and the convex combination of ARMA errors. It will certainly enhance research if other versions of time series processes like Autoregressive Conditional Heteroskedasticity (ARCH), Generalised Autoregressive Conditional Heteroskedasticity (GARCH), Seasonal Autoregressive Integrated Moving Average (SARIMA), etc., are considered for volatility and seasonality. More data will be required for better results. Also, properties of the error pattern and the variation with different values of the parameters may be investigated. These may include moments, kurtosis and some other parameters.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Notes on contributors
S. A. Komolafe
S. A. Komolafe is a student at the Department of Mathematics, Obafemi Awolowo University, Ile-Ife. He obtained M.Sc. in Statistics in Obafemi Awolowo University, Ile-Ife. His area of research includes time series analysis and econometrics.
T. O. Obilade
T. O. Obilade is a Professor of Statistics at the Department of Mathematics, Obafemi Awolowo University in Ile-Ife, Nigeria. He has taught most of the Mathematics and Statistics courses in the department for several decades. Professor Obilade has written many articles. He has also supervised several M.Sc. and Ph.D. theses.
I. O. Ayodeji
I. O. Ayodeji is a Lecturer at the Department of Mathematics, Obafemi Awolowo University, Ile-Ife. She received her Ph.D. in Statistics from Obafemi Awolowo University, Ile- Ife, in 2015. She has to her credit quality articles published in top journals in economics and statistics, including Communications in Statistics – Theory and Methods, African Development Review and the Journal of Applied Mathematics.
A. R. Babalola
A. R. Babalola is an Assistant Lecturer and a Ph.D. student at the Department of Mathematics, Obafemi Awolowo University in Ile-Ife, Nigeria. His research interests include queueing theory and time series analysis.
Notes
1 Readers interested in simulations and estimations of IMA process under the two error patterns of AR and ARMA may kindly refer to Eni and Mahmud (Citation2008) and Eni (Citation2013).
2 One may argue that the p- and z-values of the proposed are just marginally better than the existing models; however, it is known that when sample size is small, as we have in both illustrations, (i.e. for Nigeria, sample size used in Kolmogorov test is 12 while that of US is 16), Kolmogorov test usually masks the extent of deviation between the two distributions under consideration. Tables and of Absolute deviations displayed clear deviations of the existing two models from the Observed compared to the Proposed.
References
- Ayodeji, I. O. (2016). A three-state Markov-modulated switching model for exchange rates. Journal of Applied Mathematics, 2016, 1–9. doi: 10.1155/2016/5061749
- Barnett, V. D. (1967). A note on linear structural relationships with both residual variances are known. Biometrika, 63, 39–50.
- Box, G., & Jenkins, G. (1976). Time series analysis: Forecasting and control. San Francisco, CA: Holden Day.
- Engel, C., & Hamilton, J. (1990). Long swings in the dollar: Are they in the data and do market know it? American Economic Review, 80, 687–713.
- Eni, D. (2013). Parameter estimation of first order IMA model in the presence of ARMA(1,1) errors. Research Journal in Engineering and Applied Sciences, 2(4), 246–50.
- Eni, D., & Mahmud, S. A. (2008). On the parameter estimation of first order IMA model corrupted with AR (1) errors. Global Journal of Pure and Applied Sciences, 14(1), 115–20. doi: 10.4314/gjpas.v14i1.16783
- Eni, D., Ogban, G., Ekpenyong, B., & Atsu, J. (2007). On error handling for a process following AR(1) with MA(1) errors. Journal of Research in Engineering, 4, 102–4.
- Garcia, R., & Perron, P. (1996). An analysis of the real interest rate under regime shifts. The Review of Economics and Statistics, 78, 111–125. doi: 10.2307/2109851
- Kendall, M. G., & Stuart, A. (1961). The advanced theory of statistics. London: Griffin.
- Lindley, D. V. (1947). Regression lines and the linear functional relationship. Supplement to the Journal of the Royal Statistical Society, 9, 218–44. doi: 10.2307/2984115
- Madansky, A. (1959). The fitting of straight lines when both variables are subject to error. Journal of the American Statistical Association, 54, 173–205. doi: 10.1080/01621459.1959.10501505
- Moran, P.A.P. (1971). Estimating structural and functional relationships. Journal of Multivariate Analysis, 1, 232–255. doi: 10.1016/0047-259X(71)90013-3
- Rudelson, M., & Zhou, S. (2017). Errors-in-variables models with dependent measurements. Electronic Journal of Statistics, 11, 1699–1797. doi: 10.1214/17-EJS1234
- Schneeweiss, H., & Shalabh, H. (2007). On the estimation of the linear relation when the error variances are known. Computational Statistics & Data Analysis, 52, 1143–1148. doi: 10.1016/j.csda.2007.06.018
- Yilmazkuday, H., & Akay, K. (2008). An analysis of Turkish economy under regime shifts. Economic Modelling, 25(5), 885–898. doi: 10.1016/j.econmod.2007.11.013