
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.We congratulate the authors on their innovative and illuminating contribution. Their paper should not only lead to more refined and defensible applications of the Bayesian information criterion (BIC) through their proposed variants, but should also facilitate a deeper understanding of BIC and its theoretical underpinnings.
The development of the prior-based BIC variants, PBIC and PBIC*, results from a reconsideration of the Laplace approximation employed in the large-sample justification for BIC. The authors' more nuanced application of the Laplace approximation leads to the inclusion of terms based on (1) the log of the determinant of the observed information for those parameters that are common to all of the candidate models, (2) standardised estimates of the transformed parameters for those parameters that vary among the candidate models, and (3) an ‘effective sample size’ for each transformed parameter. The terms based on (2) and (3) replace the conventional penalty term of BIC.
An additional refinement to BIC could be incorporated based on terms governed by the prior probabilities assigned to each of the candidate models. To introduce such a correction, we consider the initial stages of the development that leads to BIC.
Assume that the observed is to be described using a model
selected from a set of candidates
. Suppose that each
is uniquely parameterised by a vector
. Let
denote the likelihood for
based on
.
Let denote a discrete prior over the models
, specified so that
for all
, and
. Let
denote a prior on
given the model
.
Through the application of Bayes' Theorem, for the joint posterior of and
, we have
Here, the constant of proportionality, say , depends on the data
, yet not on the constructs for model
.
A Bayesian model selection rule might aim to choose the model which is a posteriori most probable. For the posterior probability for
, we then have
If we consider minimising
as opposed to maximising
, we obtain
Since the term involving
does not vary in accordance with the structure of the model
, for the purpose of model selection, this term can be discarded. We thereby obtain
(1)
(1) The authors' variants of BIC result through a refined approximation of the integral
In comparing candidate models based on differences in (Equation1(1)
(1) ), the terms
are (i) immaterial under a uniform prior distribution
, and (ii) negligible in large-sample settings where the prior probabilities are not markedly different. In the asymptotic justification of BIC, these terms are discarded. However, the terms involving
could play a role in smaller sample settings where candidate models are differentially favoured (e.g. Neath & Cavanaugh, Citation1997).
Additionally, a uniform prior on the candidate models can lead to inconsistency in high-dimensional sparse settings. To further explore this potential problem, consider a regression setting based on potential covariates. Let
refer to the number of true ‘active’ regression parameters in the generating model, and let the saturation level
refer to the proportion of all
parameters that are in the generating model, so that
. The sparsity level (i.e. the proportion of regression parameters that are truly inactive) is simply
.
Assuming a uniform prior on the collection of candidate models induces a marginal distribution on the saturation level that becomes increasingly concentrated about
as
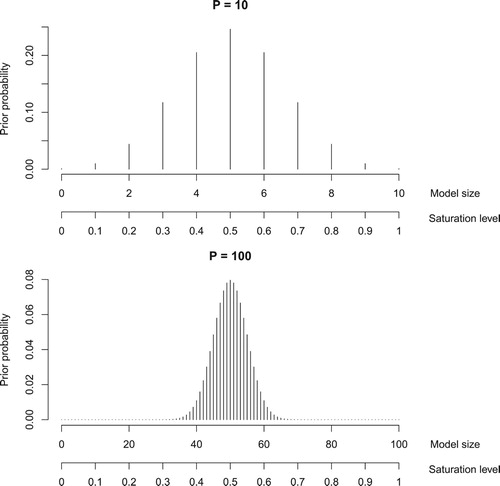
increases. For example, consider performing best-subsets selection with
=10 covariates. One might perceive that a defensible approach for determining the final model would be to choose the fitted model corresponding to the lowest BIC. However, since BIC implicitly imposes a uniform prior on the candidate models, and since there are more models with 5 covariates than with 1 or 2 covariates, BIC favours models of size 5 over models of size 1 or 2. In fact, the prior distribution for model size is centred among values near 5; see Figure . As
grows, this prior becomes increasingly concentrated around
/2. Consequently, the prior distribution on the saturation level becomes progressively more dense around
.
Figure 1. The prior instituted by BIC on the marginal distribution of model size (and, consequently, the saturation level) for (top) and
(bottom).
Chen and Chen (Citation2008) proffer a solution to this problem: the extended Bayesian information criterion (EBIC). EBIC corrects for the prior imbalance in model size by incorporating an additional term in the formulation of BIC that penalises a model in accordance with the number of candidate models of that size. Let denote the dimension of the regression parameter vector for
. In the context of best-subsets selection, EBIC is defined as
The additional penalty term for EBIC can be conveniently conceptualised in the context of the ubiquitous statistical metaphor of balls and urns. In any variable selection problem, each covariate can be viewed as a ball in an urn consisting of balls. Each model
is defined by a random draw, without replacement, of
balls from that urn. There are
ways of selecting the
balls, which provides the reason that this combinatorics term arises in the criterion development.
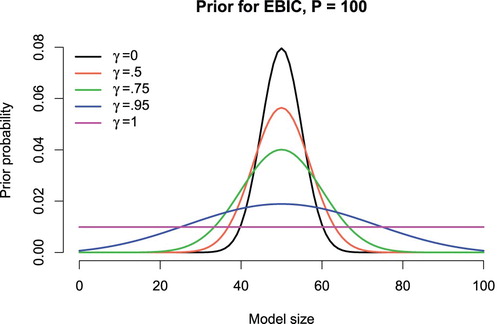
The additional penalty term of EBIC involves a tuning parameter , which is fixed at a value between 0 and 1, inclusive. Different values of
lead to important special cases of the criterion, which are depicted in Figure . If
, EBIC becomes the original BIC. Setting
yields a uniform prior on the marginal distribution of model size (and consequently,
). However, setting
leads to a criterion that can be quite conservative in practice. The specification of
is associated with different consistency properties. Broadly speaking, BIC will be inconsistent when
, and EBIC corrects for this. Note that since
, the penalty for EBIC will always be greater than or equal to BIC; thus, EBIC will always be at least as conservative as BIC, if not more. A more extensive discussion about the specification of
and related consistency implications can be found in Chen and Chen (Citation2008).
In the best-subsets setting, a similar motivation modifies the prior distributions for all of the models to induce a more formal preference for sparse models (Bogdan, Ghosh, & Doerge, Citation2004; Bogdan, Ghosh, & Zak-Szatkowska, Citation2008). The resulting criterion is referred to as the modified Bayesian information criterion (mBIC). Unlike the symmetric priors of BIC and EBIC, the formulation of mBIC utilises a right-skewed prior probability mass function on model size, where the degree of skewness is governed by the saturation level . For mBIC, instead of specifying a
parameter, one must specify the ‘expected’ or ‘central’ saturation level, which we will denote as
. For a central saturation level
, and for a model
with
parameters,
Thus, mBIC views each coefficient as a random draw from an underlying population of effects where
are active and
are inactive, but we do not know which are which a priori.
Figure 2. Marginal distributions for model size resulting from the parameter for EBIC.
Of course, of the two terms in (Equation1(1)
(1) ), the term based on the integral
is of primary importance; the authors have justifiably focussed on refining the approximation of this integral in the development of their BIC variants. However, the inclusion of the additional terms
in PBIC and PBIC* could potentially be beneficial in instances where it is justifiable to employ priors
that differentially favour certain models in the candidate collection.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Ryan A. Peterson http://orcid.org/0000-0002-4650-5798
Joseph E. Cavanaugh http://orcid.org/0000-0002-0514-7664
Additional information
Notes on contributors
Ryan A. Peterson
Dr Ryan A. Peterson recently received his Ph.D. from the Department of Biostatistics in the College of Public Health at the University of Iowa. In the summer of 2019, he will be joining the faculty of the Department of Biostatistics and Informatics in the Colorado School of Public Health at the University of Colorado Anschutz Medical Campus. His methodological research interests include variable selection, model selection, machine learning, high-dimensional data analysis, and computational statistics.
Joseph E. Cavanaugh
Dr Joseph E. Cavanaugh is a Professor of Biostatistics and Head of the Department of Biostatistics in the College of Public Health at the University of Iowa. He holds a secondary appointment in the Department of Statistics and Actuarial Science and is an affiliate professor in the Applied Mathematical and Computational Sciences interdisciplinary doctoral programme. His methodological research interests include variable selection, model selection, time series analysis, modelling diagnostics, and computational statistics.
References
- Bogdan, M., Ghosh, J. K., & Doerge, R. W. (2004). Modifying the Schwarz Bayesian information criterion to locate multiple interacting quantitative trait loci. Genetics, 167, 989–999. doi: 10.1534/genetics.103.021683
- Bogdan, M., Ghosh, J. K., & Zak-Szatkowska, M. (2008). Selecting explanatory variables with the modified version of the Bayesian information criterion. Quality and Reliability Engineering International, 24, 627–641. doi: 10.1002/qre.936
- Chen, J., & Chen, Z. (2008). Extended Bayesian information criteria for model selection with large model spaces. Biometrika, 95, 759–771. doi: 10.1093/biomet/asn034
- Neath, A. A., & Cavanaugh, J. E. (1997). Regression and time series model selection using variants of the Schwarz information criterion. Communications in Statistics – Theory and Methods, 26, 559–580. doi: 10.1080/03610929708831934