
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Ultra-high-dimensional data with grouping structures arise naturally in many contemporary statistical problems, such as gene-wide association studies and the multi-factor analysis-of-variance (ANOVA). To address this issue, we proposed a group screening method to do variables selection on groups of variables in linear models. This group screening method is based on a working independence, and sure screening property is also established for our approach. To enhance the finite sample performance, a data-driven thresholding and a two-stage iterative procedure are developed. To the best of our knowledge, screening for grouped variables rarely appeared in the literature, and this method can be regarded as an important and non-trivial extension of screening for individual variables. An extensive simulation study and a real data analysis demonstrate its finite sample performance.
1. Introduction
Nowadays, grouping predictors arise naturally in many regression problems. It means that we are interested in finding relevant predictors in modelling the response variable, where each predictors may be represented by a group of indictor variables or a set of basis functions. Grouping structures can be introduced into a regression model naturally in hoping that the prior knowledge about predictors may be used to the full. Thus, grouping structure problems become increasingly important in various research fields. One common example is the representation of multi-level analysis-of-variance (ANOVA) in a regression model with a group of derived input variables. The aim of ANOVA is often to select relevant main factors and interactions, that is the selection of groups of derived input variables. Another example is the additive model with nonparametric components, where each component can be expressed a linear combination of a set of basis functions of the original predictors. Thus, in both cases, variable selection amounts to the selection of groups of variables rather than individual derived variables.
Using the penalised method, many researchers have considered the group selection problems in various parametric or nonparametric regression models. These articles include, but are not limited to the following. First, Bakin (Citation1999) proposed the group LASSO in his doctoral dissertation. Yuan and Lin (Citation2006) further studied the group LASSO and related group selection methods, such as the group LARS and the group Garrote, and proposed the corresponding algorithms. But they did not give any asymptotic properties of the group LASSO. Wei and Huang (Citation2010) showed that, under a generalised sparsity condition and the sparse Riesz condition proposed by Zhang and Huang (Citation2008), together with some regularity conditions, the group LASSO can select a model with the same order as the underlying model. They also established the asymptotic properties of the adaptive group LASSO, which can correctly select groups with probability tending to one. Under the assumption of generalised linear models, Breheny and Huang (Citation2009) established a general framework for simultaneous group and individual variable selection, or bi-level selection and the corresponding local coordinate descent algorithm. In addition to the group LASSO, many authors also proposed other methods for various parametric models. For example, Huang, Ma, Xie, and Zhang (Citation2009) showed that simultaneous group and individual variable selection can be conducted by a group bridge method. They showed that it can correctly selected relevant groups with probability tending to one. Moreover, Zhao, Rocha, and Yu (Citation2009) introduced a quite general composite penalty for groups selection by combing different norms to form an intelligent penalty. All these methods are very useful for moderate number of predictors to be smaller than the sample size or comparable with it. However, with rapid progress of computing power and modern technology for data collection, massive amounts of ultra-high-dimensional data are frequently seen in diverse fields of scientific research. Due to the “curse of dimensionality” in terms of simultaneous challenges to computational expediency, statistical accuracy and algorithm stability, the above methods are limited in handling ultra-high-dimensional problems.
In the seminal work of Fan and Lv (Citation2008), a new framework for sure independence screening (SIS) was established. They showed that the method based on Pearson correlation learning possess a sure screening property for linear regressions. That is, all relevant predictors can be selected with probability tending to one even if the number of predictors p can grow much faster than the number of observations n with log for some
. Following Fan and Lv (Citation2008), we call this non-polynomial dimensionality or ultra-high dimensionality. From this on, various screening methods based on model assumption or model free have been developed (Fan & Lv, Citation2008; Fan, Samworth, & Wu, Citation2009; Fan & Song, Citation2010; He, Wang, & Hong, Citation2013; Li, Zhong, & Zhu, Citation2012; Shao & Zhang, Citation2014; Wang, Citation2009; Zhao & Li, Citation2012). However, all these screening methods deal with the individual variables rather than grouped predictors. To the best of our knowledge, screening methods for grouped predictors are quite limited in existing literatures. Thus it is very important to propose a new screening method based on grouped predictors.
Motivated by the theory of SIS, we consider how to deal with these ultra-high-dimensional grouped predictors in the assumption of linear regression model. Considering grouping structures in linear regression model, we have
(1)
(1) where Y is the response variable,
is a
random vector representing the jth group,
is the
parameter vector corresponding to the jth group predictors, and
is the random error with mean 0.
Our method is a two-stage approach. First, an efficient screening procedure is employed to reduce the number of group predictors to a moderate order under sample size, and then the existing group selection methods can be used to recover the final sparse model. Due to fastness and efficiency of the screening method for group predictors, we consider a independence screening method by ranking the magnitude of marginal estimators based on each grouped predictor. That is, we fit p marginal linear regressions of the response Y against the variables of the jth group respectively, and the select the relevant group predictors by a measure of the goodness of fit in its marginal linear regression model. Under some mild conditions, We show that there is a significant difference between relevant group predictors and irrelevant ones, according to the strength of these marginal utility. Thus we can distinguish active group predictors from much more inactive ones. Next, the existing group selection methods, such as the group LASSO, the group SCAD (Breheny & Huang, Citation2015) and the group MCP (Breheny & Huang, Citation2015), can be used to obtain the final sparse model. We refer to our screening procedure as the Group-SIS, and theoretically establish the sure screening property of our approach. In order to further reduce the false-positive rate, we propose a iterative version of algorithm, named ISIS-Group-Lasso. To enhance performance and speed up the computation of ISIS-Group-Lasso, a greedy modification to the above iterative algorithm, named g-ISIS-Group-Lasso is also developed. Our simulation studies indicate that ISIS-Group-Lasso and g-ISIS-Group-Lasso significantly outperform the competitive group selection, such as distance correlation-based screening method and the group LASSO, especially when the dimensionality is ultra-high.
The rest of the article is organised as follows. In Section 2, we introduce a marginal group SIS in linear regression models. Under some mild conditions, the sure screening property and model selection consistency of the Group-SIS will be established in Section 3. In Section 4, simulation studies and a real data analysis are carried out to assess the performance of our method. Concluding remarks are given in Section 5. All technical proofs for the main theoretical results are given in the Appendix.
2. Group SIS and iterative algorithm
2.1. Marginal linear regression based on grouped predictors
Suppose that we have n random sample from model (Equation1(1)
(1) ) of the form
(2)
(2) in which
,
and
are scalar. Let
,
and
, where
is the
design matrix corresponding to the jth group for each
. Then the model (Equation2
(2)
(2) ) can be rewritten as
(3)
(3) For simplicity, the number of variables in each group is uniformly bounded. That is, there exists a positive constant K such that
for
. To rapidly select the relevant grouped predictors, we consider the following J marginal linear regressions against the grouped predictors:
(4)
(4) where
is a
-dimensional vector for each
.
It is easy to see that the minimiser of (Equation4(4)
(4) ) is given by
Then we define the marginal utility of the jth grouped predictors as
(5)
(5) We now select a set of relevant grouped predictors as follows:
where
is a positive constant and
is a pre-specified threshold value which will be given later.
Equivalently, we can also define a screening criterion by ranking the residual sum of squares of the corresponding marginal linear regression. These two ways can reduce the group dimensionality from J to a moderate size . Here, the pre-specified threshold value is crucial in the screening procedure. If we choose it too small, we may select many irrelevant grouped predictors in the final model. On the contrary, we have the risk of losing some important variables. In a word, we should select all of the relevant grouped predictors and control the selected model size simultaneously. In Section 3, we will theoretically show that this group screening approach possesses a sure screening property and the final model size is only of polynomial order. Noted that, our method is the same as traditional feature screening when each group has one variable. In this sense, our method can be regarded as a non-trivial extension of feature screening under the context of single feature screening.
2.2. Iterative group-SIS algorithm
For these ultra-high-dimensional group variable selection problems, we propose a two-stage procedure. That is, we first apply a sure screening method such as Group-SIS to reduce the number of groups from J to a relatively large scale d, where the dimensionality of the selected d group is below sample size n. Then we can use a lower dimensional group-wise variable selection procedure, such as group Lasso, group SCAD or group MCP. In this article, we use group lasso penalty as our group selection strategy. In fact, other group variable selection methods would also work.
However, as Fan and Lv (Citation2008) point out, this marginal independence screening method would still suffer from false negative (i.e., miss some important group predictors that are marginally uncorrelated, but jointly correlated with response), and false positive (i.e., select some unimportant group predictors which have higher marginal correlation than some important group variables). Therefore, we propose an iterative framework to enhance the finite performance of this screening method. That is, we can iteratively use a large-scale group screening and moderate-scale group variable selection strategy.
To obtain a data-driven thresholding for independence group screening, we extend the random permutation idea of Zhao and Li (Citation2012), which select a small proportion of inactive variables to enter the model in each screening step. Let , randomly permute the row of
to get the decouple data
and
. Based on the randomly decoupled data
, which has no relationship between group variables and response, we compute the value of
similar to
for
. These values serve as the baseline of the marginal group screening utilities under the null model (no relationship between group variables and response). To obtain the screening threshold, we choose
as the q-ranked magnitude of
. In our simulation, we uses q=1, namely, the largest marginal group screening utilities under the null model. For the sake of completeness, our ISIS-Group-Lasso algorithm proceeds as follows.
Step 1. Compute J marginal utility , and the initial index subset is chosen as
Step 2. Apply the group Lasso (Breheny & Huang, Citation2009) on the index subset to obtain a subset
. In this step, we choose the regularisation parameter by the Bayesian Information Criterion (BIC) method.
Step 3. Conditioning on , compute the marginal regression
for each
. By randomly permuting only the groups not in
, we obtain a new index subset
similar to step 1. Apply the group LASSO on the index subset
to obtain a new subset
.
Step 4. Repeat the process until we have the final index set such that
or
for some
In order to further reduce false positive and speed up computation, we propose a greedy modification to enhance the finite performance of the above algorithm. Specifically, we restrict the number of the selected groups in the iterative screening steps to be at most , a small positive integer, and the procedure stops when none of the group predictors is recruited. In our simulation, we set
. This greedy version of ISIS-Group-Lasso algorithm is called g-ISIS-Group-Lasso. When
, this method is connected with forward regression screening (Wang, Citation2009), which select at most one new group predictor into the model at a time. However, there is a great difference between the two methods, that is our method includes a deletion step via group selection that can remove multiple group predictors. This makes our procedure more effective, because it is more flexible in terms of recruiting and deleting group predictors. Based on our simulation results in Section 4, g-ISIS-Group-Lasso outperforms other methods in terms of lower false-positive rate, higher percentage of selected the corrected model and small model error.
3. Theoretical properties
Before we establish the sure screening property of our method for linear models, let us introduce some notations first. Denote the Euclidean and the sup norm of a vector by
and
, respectively. For any symmetric matrix A, let
be the infinity norm and
the operator norm. Let
and
be the minimum and maximum eigenvalue of the matrix A. Let
and
. For each
and
, let
be the support of
. Define the index set of the truly model
by
To gain theoretical insights into the Group-SIS, we need to define
, which is the population version of (4), by minimising
with respect to
. Then we have
Similar to (Equation5
(5)
(5) ), we define
Next we collect the technical assumptions to establish the sure screening property of our group screening method.
, for some
For any B>0 and
For
Under condition (i), we obtain the minimum signal of the relevant grouped predictors. That is, the magnitude of these marginal utilities of the grouped predictors can preserve the non-sparsity signal of the real model with the fastest convergence rate. This condition is often seen in screening literatures, which is important as it guarantees that marginal utilities carry information about the relevant covariates in the active set. And, conditions (ii) and (iii) are two mild conditions needed in using Berstein's inequality (Van der Vaart & Wellner, Citation1996). Because we allow increase with n, condition (ii) ensures the convergence of
. Condition (iv) is also easy to be satisfied, for the small number of variables in each grouped predictor.
Remark 3.1
The above assumptions only serve to help us to further understand the new group screening methodology. Thus these conditions are imposed to facilitate the technical proofs, and the weaker condition may be an interesting topic for future research.
The following Theorem 3.1 provides the sure screening property of our group screening method.
Theorem 3.1
Suppose that conditions (i)–(iv) hold. There exists a constant such that we have
Theorem 3.1 indicates that we can select all the relevant grouped predictors with probability tending to 1, and the key to the theorem's proof is on how to obtain the uniform consistence of to
. Denote
. Note that
uniformly, the dimensionality can be handled as high as
That is, under some mild conditions, our method has the sure screening property and can reduce from the exponentially growing dimension p to a relatively moderate scale which will be applied in the next group variable selection. Especially, we should point out that
is very important to our screening procedure. The greater
is, the higher number of groups that our method can deal with.
On the other hand, although we can select the relevant grouped predictors with probability tending to 1, the cardinality of the may be relatively large compared with the sample size. That is, there are many unimportant grouped predictors in the final model. Thus controlling the false-positive rate is also necessary for our method. From the perspective in simulation, we have proposed an iterative algorithm in Section 2.2 to enhance the performance of our method in terms of the false selection rates. Under the same conditions as in Theorem 3.1, we will show theoretically that the size of the final model is as large as
with probability tending to one exponentially.
Theorem 3.2
Suppose that conditions (i)–(iv) hold, there exists some positive constant
Theorem 3.2 shows that, with probability tending to 1, the size of the selected model by our procedure is as large as polynomial order when is of polynomial order. It is crucial to the next group selection stage, which make our two-stage approach much better than traditional group variable selection methods. Because there is no guarantee that existing group selection methods can select the relevant grouped predictors consistently if there are too irrelevant grouped predictors. Thus this theorem, together with Theorem 3.1, implies we can select a model which includes all relevant grouped predictors and a small number of irrelevant ones with high probability.
4. Numerical studies
4.1. Simulation results
In this section, we carry out some simulation studies to demonstrate the finite sample performance of our group screen methods described in Section 2. We consider two group size scenarios of simulation models. In the first scenario, the group sizes are equal. In the second, the group sizes vary. In our simulation, we set all groups with size 5 or 3. We set the sample size n=200, and the following three configurations with 400, 1000 groups are considered for generating the covariates
. For example, when J=200 and group size is 5, the final predictor matrix has the number of variables
To gauge the difficulties of the simulation models, different scenarios of signal-to-noise ratio (SNR) are given in Examples 4.1–4.4, where
It is obviously that the larger the value of SNR, the higher probability that our group screening method can select the relevant groups. In all examples, the simulation results are based on 200 replications for each parameter setup.
To further explore the finite sample performance of our methods, we create some unimportant group variables highly correlated with the response due to the presence of the important group variables associated with the spurious group variables. The correlation between group variables can be specified as follows.
The group vector is where
,
. In the following four examples, we set two different group size and three configurations of the number of groups are considered. For example, we set
for each
. To generate
, we first simulate
random variables
independently from
. Then
are simulated from a multivariate normal distribution with mean 0 and
. For
, the group variable
are generated as
Here, the group components were the relevant variables, while most of components were spurious variables not used in the model but correlated to the relevant group variables. The random error
was generated from a standard normal distribution. To ensure that the theoretical value of SNR was not too weak or strong,
can be multiplied by a constant σ.
Extensive simulation studies have been conducted to demonstrate the finite performance of our group screening method. For comparison purpose, the performance of distance correlation screening (DC-SIS) (Li et al., Citation2012), which is a model-free screening method that uses the distance correlation to replace Pearson correlation in marginal correlation screening, is examined. For the sake of fairness, we propose first to apply DC-SIS to reduce the number of groups to , and a group-wise variable selection procedure such as group Lasso is conducted to recover the final model. We call DC-SIS followed by group Lasso DC-SIS-Group-Lasso. To enhance the performance of DC-SIS, Zhong and Zhu (Citation2015) propose an iterative version of DC-SIS, named by DC-ISIS, which will also be chosen as a comparison. For the sake of fairness, group Lasso is conducted after DC-ISIS, referring to DC-ISIS-Group-Lasso. At the same time, the performance of group Lasso was also examined. Thus, we have five group screening method (i.e., ISIS-Group-Lasso, g-ISIS-Group-Lasso, Group-Lasso, DC-SIS-Group-Lasso, DC-ISIS-Group-Lasso) under consideration. In the following four examples, we report five performance measures: true positive (TP), false positive (FP), median of the model size (MEDIAN), percentage of occasions on which the exactly correct groups are selected (CORRECT) and model error (Yuan & Lin, Citation2006).
Example 4.1
Each group consists of five variables, and the number of the relevant groups is 4. And we generate the response from the following linear model:
where
Example 4.2
Similar to Example 4.1, the number of the relevant groups is 8 with group size 3. We generate the response from the following linear model:
where
Example 4.3
In this example, the group sizes differ across groups. There are half of the groups with size 5 and the other groups with size 3. The group variables are generated the same way as the above examples. The response variable Y is generate from . However, the regression coefficients
Example 4.4
In this example, the group sizes also differ across groups. This example is a more difficult case than Example 4.3, because it has eight groups with more different regression coefficients. There are groups with size 5 and the other groups with size 3. The group variables are generated the same way as the above Example 4.3. The response variable Y is generate from
. However, the regression coefficients
Detailed simulation results of Examples 4.1–4.4 are given in Tables , respectively. Especially, the boxplots of average model size are presented in Figure . Obviously, in all these four examples, the relevant groups can almost be selected for four methods except for DC-SIS-Group-Lasso, which misses more groups most of the time. In terms of true positives (TP), the iterative version of DC-SIS-Group-Lasso performs well at the cost of increasing the size of the model, which leads to large FP and ME. On the other hand, the number of false-positive groups selected by group Lasso is much larger than the other four methods. Compared with distance correlation-based screening methods, our approaches have better finite performance. This may be due to the reasons for their methods based on model-free framework, while our screening methods take full advantage of the assumptions of the linear model. Especially for the greedy modification, g-ISIS-Group-Lasso, the size of final selected model is much smaller than the other four methods in all examples. Just because of this, g-ISIS-Group-Lasso outperforms its competitors in terms of the percentage of correct selected model. On the other hand, the simulations show that the value of SNR has an important impact on the results of the three methods. In Examples 4.2 and 4.4, there are eight relevant groups, while the number of relevant groups in the other two examples is 4. It means that screening relevant groups in these two examples is difficult than the other two. Thus, if we want achieve sure screening, the value of SNR in these two examples is much larger than the other two.
Figure 1. Boxplots of average model sizes for Example 4.1 under different group number.
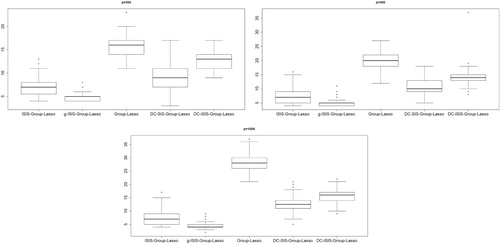
Table 1. Simulation results of MEDIAN, TP, FP, CORRECT and ME for Example 4.1.
Table 2. Simulation results of MEDIAN, TP, FP, CORRECT and ME for Example 4.2.
Table 3. Simulation results of MEDIAN, TP, FP, CORRECT and ME for Example 4.3.
Table 4. Simulation results of MEDIAN, TP, FP, CORRECT and ME for Example 4.4.
4.2. Real example
In this section, we compare ISIS-Group-Lasso, g-ISIS-Group-Lasso and Group-Lasso on colon data (Alon et al., Citation1999). Alon's work reports the application of a two-way clustering method for analysis a data set consisting of the expression patterns of different cell types. For these data, we were interested in finding the genes that are related to colon tumour. In the original colon data, the identity of the 62 samples from colon-cancer patients were analysed with an Affymetrix oligonucleotide Hum6000 array. And these data contain the expression of the 2000 genes with the highest minimal intensity across the 62 tissues, where the genes are placed in order of descending minimal intensity. That is, the original data have 2000 numerical variables. For each continuous variable in the additive model, we use five B-spline basis functions to represent its effect, which is originally used by Yang and Zou (Citation2015) in solving group-lasso penalise learning problems. Thus we obtain 10,000 predictors in 2000 groups after basis function expansion. Three methods are used to select relevant additive components.
Before the analysis, all data are standardised in advance such that each variable has zero mean and unit sample variance. To valuate the performance of the three methods, we used cross-validation and compared the average model size (AMS) and the prediction mean squared error (PE). We randomly partitioned the data into a training data set of 50 observations and a test set of 12 observations. That is, we conduct group screening using 50 observations and the PEs on these 12 test sets. Detailed results based on 100 replications are presented in Table . In addition, the boxplot of the average model size is presented in Figure . As clearly shown in Table , ISIS-Group-Lasso and g-ISIS-Group-Lasso select far fewer genes than Group-Lasso, while the first two methods have a smaller PE. In conclusion, the proposed iterative group screening approach is very useful in high-dimensional scientific studies, which can select a parsimonious model and reveal interesting relationship between group variables.
Figure 2. Boxplot of average model sizes for colon data analysis.
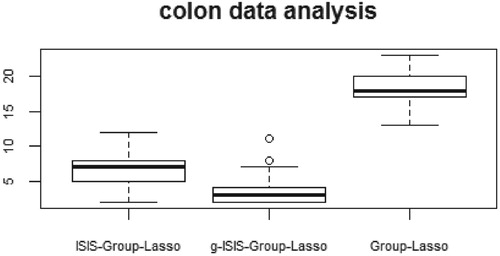
Table 5. Results of AMS and CORRECT for colon data.
5. Concluding remarks
In this article, we have proposed the marginal group sure screening method under the context of ultra-high dimensionality. Unlike most existing literatures, we deal with variables, which can be naturally grouped. Our group screening method respects the grouping structure in the data and is based on a working independence. Theoretically, we establish the sure screening property for this group screening approach. To enhance the finite sample performance, a data-driven thresholding and an iterative procedure, ISIS-Group-Lasso, are developed. A greedy modification to the iterative procedure, g-ISIS-Group-Lasso is also proposed to further reduce the false positive. Simulation results show that these two methods perform well in terms of the five performance measures.
This article leaves the problems of extending the ISIS-Group-Lasso and g-ISIS-Group-Lasso under linear model to the family of generalised linear model and other parametric models. And model-free group screening approach may be appealing for dealing with ultra-high-dimensional data more generally, which avoids the difficult task of specifying the form of a statistical model. These problems are beyond the scopes of this article and are interesting topics for future research.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Yong Niu
Yong Niu is a PhD candidate in the College of Statistics, East China Normal University, Shanghai, China. His research interests include high dimensional data, big data analytics and nonparametric statistics.
Riquan Zhang
Riquan Zhang is a professor and chair of School of Statistics in East China Normal University. His research interests include high dimensional data, big data analytics, functional data analysis, statistical machine learning and nonparametric statistics.
Jicai Liu
Jicai Liu is an associate professor of statistics in the department of mathematics at Shanghai Normal University, China. His research interests include high dimensional data, lifetime data analysis and nonparametric statistics.
Huapeng Li
Huapeng Li is an associate professor of statistics in the school of mathematics and statistics at Datong University, China. His research interests include nonparametric and semiparametric statistics based on empirical likelihood, selection biased data and finite mixture models.
References
- Alon, U., Barkai, N., Notterman, D. A., Gish, K., Ybarra, S., Mack, D., & Levine, A. J. (1999). Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proceedings of the National Academy of Sciences, 96(12), 6745–6750. doi: 10.1073/pnas.96.12.6745
- Bakin, S. (1999). Adaptive regression and model selection in data mining problems (Ph.D. thesis). Australian National University, Canberra.
- Breheny, P., & Huang, J. (2009). Penalized methods for bi-level variable selection. Statistics and its Interface, 2(3), 369. doi: 10.4310/SII.2009.v2.n3.a10
- Breheny, P., & Huang, J. (2015). Group descent algorithms for nonconvex penalized linear and logistic regression models with grouped predictors. Statistics and Computing, 25(2), 173–187. doi: 10.1007/s11222-013-9424-2
- Fan, J., Feng, Y., & Song, R. (2011). Nonparametric independence screening in sparse ultra-high-dimensional additive models. Journal of the American Statistical Association, 106(494), 544–557. doi: 10.1198/jasa.2011.tm09779
- Fan, J., & Lv, J. (2008). Sure independence screening for ultrahigh dimensional feature space (with discussion). Journal of the Royal Statistical Society, Series B: Statistical Methodology, 70(5), 849–911. doi: 10.1111/j.1467-9868.2008.00674.x
- Fan, J., Samworth, R., & Wu, Y. (2009). Ultrahigh dimensional variable selection: Beyond the linear model. Journal of Machine Learning Research, 10, 1829–1853.
- Fan, J., & Song, R. (2010). Sure independence screening in generalized linear models with NP-dimensionality. Annals of Statistics, 38(6), 3567–3604. doi: 10.1214/10-AOS798
- He, X., Wang, L., & Hong, H. G. (2013). Quantile-adaptive model-free variable screening for high-dimensional heterogeneous data. Annals of Statistics, 41(1), 342–369. doi: 10.1214/13-AOS1087
- Huang, J., Ma, S., Xie, H., & Zhang, C. H. (2009). A group bridge approach for variable selection. Biometrika, 96(2), 339–355. doi: 10.1093/biomet/asp020
- Li, R., Zhong, W., & Zhu, L. (2012). Feature screening via distance correlation learning. Journal of the American Statistical Association, 107(499), 1129–1139. doi: 10.1080/01621459.2012.695654
- Shao, X., & Zhang, J. (2014). Martingale difference correlation and its use in high-dimensional variable screening. The American Statistical Association, 109(507), 1302–1318. doi: 10.1080/01621459.2014.887012
- Van der Vaart, A. W., & Wellner, J. A. (1996). Weak convergence and empirical processes. New York: Springer.
- Wang, H. (2009). Forward regression for ultra-high dimensional variable screening. Journal of the American Statistical Association, 104(488), 1512–1524. doi: 10.1198/jasa.2008.tm08516
- Wei, F., & Huang, J. (2010). Consistent group selection in high-dimensional linear regression. Bernoulli, 16(4), 1369–1384. doi: 10.3150/10-BEJ252
- Yang, Y., & Zou, H. (2015). A fast unified algorithm for solving group-lasso penalize learning problems. Statistics and Computing, 2015(6), 1129–1141. doi: 10.1007/s11222-014-9498-5
- Yuan, M., & Lin, Y. (2006). Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society, Series B: Statistical Methodology, 68(1), 49–67. doi: 10.1111/j.1467-9868.2005.00532.x
- Zhang, C. H., & Huang, J. (2008). The sparsity and bias of the lasso selection in high-dimensional linear regression. The Annals of Statistics, 36(4), 1567–1594. doi: 10.1214/07-AOS520
- Zhao, S. D., & Li, Y. (2012). Principled sure independence screening for Cox models with ultra-high-dimensional covariates. Journal of Multivariate Analysis, 105(1), 397–411. doi: 10.1016/j.jmva.2011.08.002
- Zhao, P., Rocha, G., & Yu, B. (2009). The composite absolute penalties family for grouped and hierarchical variable selection. Annals of Statistics, 37(6A), 3468–3497. doi: 10.1214/07-AOS584
- Zhong, W., & Zhu, L.-P. (2015). An iterative approach to distance correlation-based sure independence screening. Journal of Statistical Computation and Simulation, 85(11), 2331–2345. doi: 10.1080/00949655.2014.928820
Appendix 1.
Three lemmas
Next, we state some lemmas which will be used in the proof of Theorems 3.1 and 3.2.
Lemma A.1
Under conditions (i)–(iii), for any
we have
where
and
Proof.
Using Bonferroni's inequality, we can easily prove that
Thus we need to show that
for every
Recall that the support of
is
for
and
we denote
Because
we can obtain that
Next we bound the tails probability of
and
respectively. By condition (ii)–(iii), it is easy to see that
Using the Bernstein's inequality (Van der Vaart & Wellner, Citation1996, lemma 2.2.9 and lemma 2.2.11), we conclude that
(A1)
(A1)
(A2)
(A2) Therefore, we combine the results (EquationA1
(A1)
(A1) ) and (EquationA2
(A2)
(A2) ) with
and
, to obtain that
This concludes the proof of the lemma.
Lemma A.2
Under conditions (ii)–(iv), for any and
, we have
where
and
.
Proof.
For , let
and
be the entry of
. Then we can write
By the fact that , we have
(A3)
(A3) Next we also use Bernstein's inequality to bound the tails probability of
. By condition (ii)–(iii), we can obtain easily that
Using Bernstein's inequality, it follows that
(A4)
(A4) Thus the desired result is obtained from (EquationA3
(A3)
(A3) ) and (EquationA4
(A4)
(A4) ) by taking
and
.
Remark A.1
If A and B are two symmetric matrices of order p, we have the following two results (Fan, Feng, & Song, Citation2011; He et al., Citation2013):
In addition, note that
The above results, together with Lemma 2, imply that
(A5)
(A5)
(A6)
(A6) for
.
Lemma A.3
Suppose conditions (ii)–(iv) hold, there exist some positive constants and
such that
(A7)
(A7) That is, with probability approaching 1, we have
Proof.
Combing condition (iv) and (EquationA5(A5)
(A5) )–(EquationA6
(A6)
(A6) ), it is easy to obtain (EquationA7
(A7)
(A7) ).
Appendix 2.
Proof of Theorem 3.1
Proof of Theorem 3.1.
The key idea of the proof is to show the uniform consistence of under conditions (ii)–(iv). As to the existing literatures, the sure screening property is typically established in this way. Recall that
and
Thus we need to evaluate
By some algebra, we decompose it into three parts
in which
Now, we define a event
on which we have
for
.
Then the above three lemmas indicate that
(A8)
(A8) By the fact that
, we have on
,
Take
, there exists a constant
such that
Choosing
such that
, we can easily obtain that
By invoking condition (i), we have on
for sufficiently large n
If we choose
, it is easy to show that
This, together with (EquationA8
(A8)
(A8) ), indicates that there exists a constant
such that
Appendix 3.
Proof of Theorem 3.2
Proof of Theorem 3.2.
Following the similar argument of the proof of Theorem 3.1, we have on
where
denotes the size of the set. This implies that
By some algebra, it follows that
That is, we have
(A9)
(A9) Thus the key point is to show that
For this purpose, we consider the following linear regression:
with respect to . By least square, we can easily obtain that
in which
is the least square estimator. On the other hand, the orthogonal decomposition of least square implies that
. Because
, we conclude that
(A10)
(A10) Combining (EquationA9
(A9)
(A9) ) and (EquationA10
(A10)
(A10) ), the desired result can be easily obtained.