
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The unified weighing scheme for the local-linear smoother in analysing functional data can deal with data that are dense, sparse or of neither type. In this paper, we focus on the convergence rate of functional principal component analysis using this method. Almost sure asymptotic consistency and rates of convergence for the estimators of eigenvalues and eigenfunctions have been established. We also provide the convergence rate of the variance estimation of the measurement error. Based on the results, the number of observations within each curve can be of any rate relative to the sample size, which is consistent with the earlier conclusions about the asymptotic properties of the mean and covariance estimators.
1. Introduction
In this article, we consider the typical functional data setting, where a sample of n curves are observed over the time range , each at
discrete points for
. When analysing such data, sparsity of the time grid at which the measurements are observed should be taken into account, and proper estimation procedures would be adopted accordingly. Conventionally, pre-smoothing the observations from each subject is viable for dense data before subsequent ?>analysis, whereas the subjects are pooled to borrow information for sparse data; furthermore, two types of estimation procedures present different asymptotic properties (Zhang & Wang, Citation2016). For the essential problem of estimating the mean and covariance functions, we refer to, for example, Ferraty and Vieu (Citation2006), Ramsay and Silverman (Citation2005), Rice and Silverman (Citation1991), Staniswalis and Lee (Citation1998), Zhou, Lin, and Liang (Citation2017) and references therein.
Here we focus on local-linear smoother, which has high popularity due to its conceptual simplicity, attractive local features and ability for automatic boundary correction (Fan & Gijbels, Citation1996). To ensure that the effect of each curve on the optimisers is not overly affected by the denseness of observations, different weighing schemes have been proposed. A scatter plot smoother is employed by Yao, Müller, and Wang (Citation2005), which assigns the same weight to each observation for sparse functional data analysis, referred to as the ‘OBS’ scheme. Alternatively, Li and Hsing (Citation2010) suggested a unified framework in which the number of observations within each curve can be of any rate relative to the sample size, where each subject received the same weight, referred to as the ‘SUBJ’ scheme. More recently, Zhang and Wang (Citation2016) proposed a more general weighing scheme which includes the previous two commonly used schemes as special cases, and provided a comprehensive and unifying analysis of the asymptotic properties for estimation.
In addition to the essential estimation problem, functional principal component analysis (FPCA) has become a common part in functional data analysis, for example, to achieve dimension reduction of functional data by summarising the data in a few functional principal component (FPC) scores, or to interpret the varying trend of individual trajectories with the eigenfunctions. For a comprehensive discussion on FPCA, one may refer to Greven, Crainiceanu, Caffo, and Reich (Citation2010), Hall, Müller, and Wang (Citation2006), James, Hastie, and Sugar (Citation2000), Jiang and Wang (Citation2010), Yao and Lee (Citation2006), and the references therein. Although there has been a lot of literature on FPCA, only a few theoretical studies on FPCA have been made, such as in Hall and Hosseini-Nasab (Citation2006), Hall et al. (Citation2006) and Li and Hsing (Citation2010), and they are all based on ‘OBS’ or ‘SUBJ’ scheme. The convergence rates of the eigenvalues and eigenfunctions for the FPCA have not been studied under the general weighing scheme. The theoretical results in the paper not only provide the upper bounds of the convergence rates of eigenvalues and eigenfunctions under a unified weighing scheme but also provide bases for further theoretical studies on functional clustering and classification based on the FPCA method.
The work of Zhang and Wang (Citation2016) established the asymptotic normality, convergence, and uniform convergence for the mean and covariance estimators, but not the asymptotic properties of the FPC. Under the general weighing scheme, we provide in this article the almost sure convergence rate for eigenvalues and eigenfunctions, and further the convergence rate for the variance estimation of the measurement errors. The rest of the article is organised as follows. Notations, model and methodology including FPCA are included in Section 2. The main results about convergence rate in eigenvalues, eigenfunctions and the variance estimation of measurement errors are established in Section 3, with all technical proofs left to the Appendix. Simulation studies to verify the theoretical results are shown in Section 4. The concluding remarks are given in Section 5.
2. Model and methodology
Consider a random process defined on a fixed interval
with mean function
and covariance function
. Denote with
the error-prone observations of the random process at random points
, that is
where the
s are realisations of X,
are identically distributed measurement errors with mean zero and variance
, and all the
s,
s and
s are assumed to be independent.
2.1. Local-linear smoother
A local-linear estimator of the mean function is obtained by minimising the weighted least squares
with respect to
, where
is a kernel with bandwidth h. It was proposed in Zhang and Wang (Citation2016) to assign weight
to each observation for the ith subject such that
, which is the general weighing scheme. Specifically, assignment
along with
leads to the OBS scheme; assignment
along with
leads to the SUBJ scheme.
To estimate the covariance function , we first estimate
, and then it follows that
(1)
(1) Similarly as before, a local-linear estimator
is obtained by minimising the weighted least squares
where weight
is attached to each
for the ith subject such that
.
Finally to estimate the variance of measurement errors, we start by a local-linear estimator of
, obtained by minimising
We then estimate
by
. Throughout this article, we select the bandwidths
and
by using the leave-one-out cross-validation method.
2.2. Functional principal component analysis
We consider a spectral decomposition of and its approximation. According to Mercer's theorem, the covariance function has the spectral decomposition
where
are the eigenvalues of
, and the
s are the corresponding eigenfunctions, i.e., the principal components, which form an orthonormal system on the space of square-integrable functions on [0,1]. Following the Karhunen–Loève expansion,
is represented as
, where
is referred to as the jth FPC score of the ith subject. For each i, the
s are uncorrelated random variables with
and
.
With the local-linear estimate , we can approximate it with
where
are the estimated eigenvalues, the
s are the corresponding estimated eigenfunctions, and K is the number of principal components selected. We refer to Hall et al. (Citation2006) and Yao et al. (Citation2005) for comprehensive discussions about computation of the eigenvalues and eigenfunctions of an integral operator with a symmetric kernel. We refer to Li, Wang, and Carroll (Citation2013) for intensive discussions about the choice of K and the underlying theory of the functional principal component analysis.
3. Main results about convergence rates
A few more notations are introduced first. Given a positive integer k, we denote ,
,
and
, where the subscript ‘H’ in
suggests a harmonic mean. The asymptotic behaviour of estimated eigenvalues and eigenfunctions is given in Theorem 3.1.
Theorem 3.1
Suppose that the regularity conditions (A1)–(A2), (B1)–(B4), (C1)–(C2) and (D1)–(D2) in the Appendix hold. For any fixed j, we have the following results :
convergence rate of estimated eigenvalue
convergence rate of estimated eigenfunction
In the following, we state in Corollary 3.2 and Corollary 3.3 the specialised results for the OBS and SUBJ schemes, respectively. For either the OBS or SUBJ scheme, convergence rate depends on the order of and
relative to n and the order of bandwidth.
Corollary 3.2
Suppose that the conditions in Theorem 3.1 hold, along with two additional assumptions (C3) and (D3). Then under the OBS scheme, for any fixed j,
Corollary 3.3
Suppose that the conditions in Theorem 3.1 hold. Then under the SUBJ scheme, for any fixed j,
In addition, we provide below the convergence rate of the estimated variance of the measurement error under the general weighing scheme, as well as the special cases of the OBS and SUBJ schemes.
Theorem 3.4
Assume that the conditions in Theorem 3.1, and conditions (C1') and (C2') hold. Then under the general weighing framework,
Corollary 3.5
Suppose that the conditions in Theorem 3.4 hold.
OBS: With an additional assumption (C3),
SUBJ:
4. Simulation
To illustrate the theoretical results in Section 2, we now turn to the numerical performance of the estimators as sample size increases. Choices on and
that satisfy the conditions in the general weighing scheme must be made. Since the ‘OBS’ and ‘SUBJ’ cases are the two most commonly used choices, and our corollaries showed the specific results regarding these two cases, we use these two cases as examples to illustrate the theoretical results. The data are generated from the following model:
where
,
for k = 1, 2 and
. Let
,
,
, set
.
The observation times are generated in the following way. Each individual has a set of ‘scheduled’ time points, , and each scheduled time has a 20% probability of being skipped. The actual observation time is a random perturbation of a scheduled time: a uniform [0,1] random variable is added to a nonskipped scheduled time. This results in different observed time points
per subject.
To illustrate that the convergence rates of the estimated ,
and
have the orders of magnitude shown in Section 2, let
, where
is the derived convergence rate (e.g., under the OBS scheme,
), if the estimated
is actually consistent with
by this order of magnitude, the range of the term
should decrease or remain constant as n increases. Here we set n = 50, 75, 100, 125, 150, 175, 200 for both ‘OBS’ and ‘SUBJ’ cases, and 200 replications were done for each sample size.
The procedure is visualised in Figures –. The number of K in each replication was chosen by the 90% fraction of explained variance. As shown in Figure , the ranges (under ‘OBS’ scheme) for (top two panels) and
(bottom two panels) for k = 1, 2 tend to be stable or go down, as the sample size n increases. This demonstrates that the derived order of magnitude of convergence rate in Corollary 3.2 is reasonable.
Figure 1. This is for the ‘OBS’ case. The top two panels present the values of and
for 200 replications as n increases, respectively. The bottom two panels present the values of
and
for 200 replications as n increases, respectively.
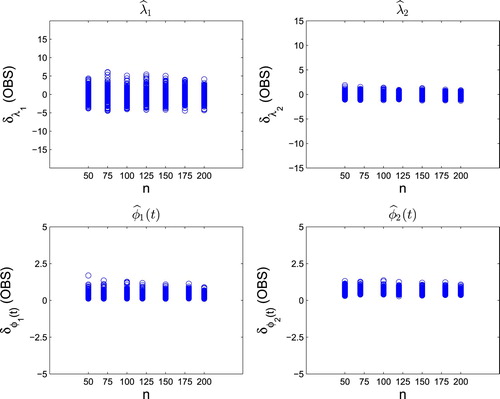
Figure 2. This is for the ‘SUBJ’ case. The top two panels present the values of and
for 200 replications as n increases, respectively. The bottom two panels present the values of
and
for 200 replications as n increases, respectively.
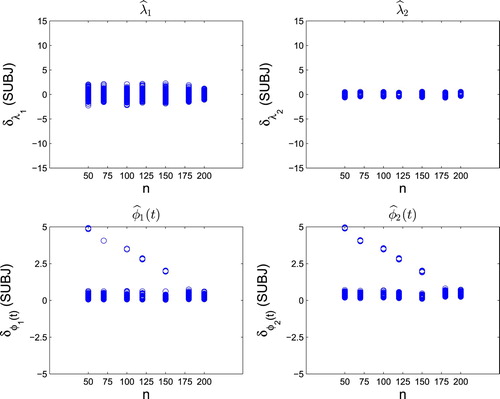
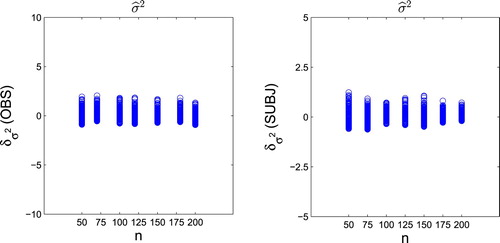
Figure 3. Plots of for ‘OBS’ (the left panel) and ‘SUBJ’ (the right panel), respectively.
A similar phenomenon under the ‘SUBJ’ scheme can be observed in Figure , which shows the converging processes of the estimators and
for k = 1, 2. Although there are some abnormal values in the estimates of eigenfunctions (shown in the left bottom and right bottom panel), generally the fluctuation range tends to be stable. And as expected, the abnormal values disappear as the sample size increases. This shows that the derived convergence rates in Corollary 3.3 is reasonable.
Furthermore, the under the ‘OBS’ and ‘SUBJ; schemes are plotted in Figure . Observe that as the sample size increases, the range of variation of the 200 replications tends to be stable, which demonstrates the results of Corollary 3.5.
5. Discussion
It is common in functional data analysis literature that a method focuses on either dense or sparse data, while discussions about data of neither type are much less. Due to different behaviours of the two types of methods, one needs to choose properly the analysis method when dealing with real data, which is not necessarily as easy as it looks like. For example, we may face a mixture of densely and sparsely observed curves, or even it may be difficult to decide a sampling density. In this sense, methods that can handle any type of data are appreciated. And the method we consider in this article belongs to this category. Specifically, we investigate the almost sure convergence of functional principal component analysis following Zhang and Wang (Citation2016) and complement the unified theoretical framework they set up. We also note that the special case of Corollary 3.3 under SUBJ scheme is consistent with Theorem 3.6 in Li and hsing (Citation2010). The convergence rate of Corollary 3.2 under OBS scheme is better than that of Corollary 1 in Yao et al. (Citation2005), due to different techniques of proofs. We prove with asymptotic expansions of the eigenvalues and eigenfunctions of estimated covariance function (Hall and Hosseini-Nasab (Citation2006) and Hall et al. (Citation2006)) and strong uniform convergence rate of by Lemma 5.1 in this article, which lead to a better convergence rate. It is also of great interest to establish the asymptotic distribution and optimal convergence rate of
under the general weighing framework, which we left for future work. Furthermore, the general weighing framework may be used in functional data regression, classification, clustering, etc., and hence the theoretical results here could be extended to those cases as well. This will also be pursued as future work.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Xingyu Yan
Xingyu Yan is currently a Ph.D. candidate in the School of Statistics at East China Normal University. He is interested in functional data analysis.
Xiaolong Pu
Xiaolong Pu is currently Professor of statistics in the School of Statistics at East China Normal University. He is interested in applied statistics, particularly in statistical testing via sampling, statistical process control, sequential analysis and reliability. He received a Ph.D. in Statistics from East China Normal University.
Yingchun Zhou
Yingchun Zhou is currently Professor of statistics in the School of Statistics at East China Normal University. She is interested in functional data analysis and biostatistics. She received a Ph.D. in Statistics from Boston University and worked as a postdoc at National Institute of Statistical Sciences before moving to East China Normal University.
Xiaolei Xun
Xiaolei Xun is currently holding a visiting position in the School of Data Science at Fudan University. She is interested in functional data analysis, Bayesian methods, modeling of high-dimensional data and biostatistics. She received a Ph.D. in Statistics from Texas A&M University and worked in Novartis for five years as biometrician and statistical methodologist before moving to Fudan University.
References
- Fan, J. Q., & Gijbels, I. (1996). Local polynomial modelling and its applications. London: Chapman and Hall.
- Fan, J. Q., & Zhang, W. Y. (2000). Simultaneous confidence bands and hypothesis testing in varying-coefficient models. Scandinavian Journal of Statistics, 27, 715–731. doi: 10.1111/1467-9469.00218
- Ferraty, F., & Vieu, P. (2006). Nonparametric functional data analysis: Theory and practice. Berlin: Springer.
- Greven, S., Crainiceanu, C. M., Caffo, B. S., & Reich, D. (2010). Longitudinal functional principal component analysis. Electronic Journal of Statistics, 4, 1022–1054. doi: 10.1214/10-EJS575
- Hall, P., & Hosseini-Nasab, M. (2006). On properties of functional principal components analysis. Journal of the Royal Statistical Society, Series B, 68, 109–126. doi: 10.1111/j.1467-9868.2005.00535.x
- Hall, P., Müller, H.-G., & Wang, J.-L. (2006). Properties of principal component methods for functional and longitudinal data analysis. Annals of Statistics, 34, 1493–1517. doi: 10.1214/009053606000000272
- James, G. M., Hastie, T. J., & Sugar, C. A. (2000). Principal component models for sparse functional data. Biometrika, 87, 587–602. doi: 10.1093/biomet/87.3.587
- Jiang, C. R., & Wang, J. -L. (2010). Covariate adjusted functional principal components analysis for longitudinal data. Annals of Statistics, 38, 1194–1226. doi: 10.1214/09-AOS742
- Li, Y. H., & Hsing, T. (2010). Uniform convergence rates for nonparametric regression and principal component analysis in functional/longitudinal data. Annals of Statistics, 38, 3321–3351. doi: 10.1214/10-AOS813
- Li, Y., Wang, N., & Carroll, R. J. (2013). Selecting the number of principal components in functional data. Journal of the American Statistical Association, 108, 1284–1294. doi: 10.1080/01621459.2013.788980
- Ramsay, J. O., & Silverman, B. W. (2005). Functional data analysis. New York: Springer.
- Rice, J. A., & Silverman, B. W. (1991). Estimating the mean and covariance structure nonparametrically when the data are curves. Journal of the Royal Statistical Society, Series B, 53, 233–243.
- Staniswalis, J. G., & Lee, J. J. (1998). Nonparametric regression analysis of longitudinal data. Journal of the American Statistical Association, 93, 1403–1418. doi: 10.1080/01621459.1998.10473801
- Yao, F., & Lee, T. C. M. (2006). Penalized spline models for functional principal component analysis. Journal of the Royal Statistical Society, Series B, 68, 3–25. doi: 10.1111/j.1467-9868.2005.00530.x
- Yao, F., Müller, H.-G., & Wang, J.-L. (2005). Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association, 100, 577–590. doi: 10.1198/016214504000001745
- Zhang, X. K., & Wang, J. -L. (2016). From sparse to dense functional data and beyond. Annals of Statistics, 44, 2281–2321. doi: 10.1214/16-AOS1446
- Zhou, L., Lin, H. Z., & Liang, H (2017). Efficient estimation of the nonparametric mean and covariance functions for longitudinal and sparse functional data. Journal of the American Statistical Association. doi: 10.1080/01621459.2017.1356317.
- Zhu, H. T., Li, R. Z., & Kong, L. L. (2012). Multivariate varying coefficient model for functional responses. Annals of Statistics, 40, 2634–2666. doi: 10.1214/12-AOS1045
Appendix
The following regularity conditions that are used to establish the asymptotic properties of the proposed estimators are imposed mainly for mathematical simplicity and may be modified as necessary. In the following, ,
and
are bandwidths used in estimating
,
and
, respectively.
A.1. Regularity conditions
Kernel function
(A1) is a symmetric probability density function on
and
(A2)
is Lipschitz continuous: There exists
such that
This implies
for a constant
.
Time points and true functions
(B1) {}, are
copies of a random variable T defined on [0,1]. The density
of T is bounded from below and above:
Furthermore,
, the second derivative of
, is bounded.
(B2) X is independent of T and ϵ is independent of T and U.
(B3) , the second derivative of
, is bounded on [0,1].
(B4) ,
and
are bounded on
.
Conditions for mean estimation
(C1) ,
,
.
(C1’) ,
,
.
(C2) For some ,
,
and
(C2') For some
,
,
and
(C3)
Conditions for covariance estimation
(D1),
,
,
.
(D2) For some ,
,
and
(D3)
The above conditions (A1)–(A2) and (B1)–(B4) are commonly used in the literature of the functional data and longitudinal data (see, e.g. Fan Zhang (Citation2000); Zhu, Li, Kong (Citation2012)). Conditions (C1)–(C3) are used to guarantee the consistency of the mean estimators. Conditions (D1)–(D3) are used to guarantee the consistency of the covariance estimators. For the SUBJ estimators, (C3) and (D3) are automatically satisfied, similar versions of (C2) and (D2) were adopted by Li and Hsing (Citation2010). In addition, (C1') and (C2') are used to guarantee the consistency of measurement error variance estimation.
A.2. Proof
To begin, let us give some notations that will be used in the sequel. Denote
where r = 0, 1, 2, and
and
where for p, q = 0, 1, 2. For any univariate function
and a bivariate function
, define the
norm by
and the Hilbert–Schmidt norm by
. The domains of the integrals [0,1] are omitted unless otherwise specified.
First, we present the convergence rate of obtained in (Equation1
(1)
(1) ).
Lemma A.1
Under the conditions in Appendix A.1, we have
Proof.
From (Equation1(1)
(1) ), We note that
By (B3) and Theorem 5.1 in Zhang and Wang (Citation2016), we have
. Thus the result can be derived from Theorem 5.2 in Zhang and Wang (Citation2016).
The following lemma is similar with Lemma 6 of Li and Hsing (Citation2010) and will be used in our following proof repeatedly. Let Δ be the integral operator with kernel .
Lemma A.2
For any bounded measurable function φ on [0,1],
Proof.
By (Equation1(1)
(1) ), it follows that
, where
and
. With minor derivation, we have
where
,
,
,
and
Further, by Taylor's expansion,
(A1)
(A1) Applying the proof of Theorem 5.2 in Zhang and Wang (Citation2016), we obtain, uniformly in s, t,
(A2)
(A2) With further calculation,
(A3)
(A3) and
(A4)
(A4) where
.
We focus on since the other two terms can be dealt with similarly. Specifically,
Note that
Similarly to the proof of Lemma 5 in Zhang and Wang (Citation2016), we can prove the following almost sure uniform rate:
Thus
The term
can be written as
Following Theorem 5.1 in Zhang and Wang (Citation2016), it is easy to see that
Hence, the lemma follows.
Proof of Theorem 3.1.
Proof of Theorem 3.1
Following Hall and Hosseini-Nasab (Citation2006) and Bessel's inequality, we have
where
and
. Lemma A.1 and Lemma A.2 lead to
By (4.9) in Hall et al. (Citation2006), we have
where
and
For
, again it suffices to focus on
. First, we have
By Lemma 5 in Li and Hsing (Citation2010), we have
Following Theorem 5.1 in Zhang and Wang (Citation2016), it can be shown similarly that
This completes the proof for assertion (a). For assertion (b), we have, for any ,
where the last inequality is established by Cauchy-Schwarz inequality. Based on Lemma 6 and assertion (a), assertion (b) holds.
Proof of Theorem 3.4.
Proof of Theorem 3.4
By rearranging the terms, we have
First, we consider . Similarly to (C.1) in Zhang and Wang (Citation2016), we have
(A5)
(A5) where
for
By (D.1) in Zhang and Wang (Citation2016),
has the uniformly rate
a.s. and we can derive that
, where
. One can see that
Thus
We apply (EquationA5
(A5)
(A5) ) but will focus on the leading term
, since the other term is of lower order and can be dealt with similarly. Note that
and by Lemma 5 in Li and Hsing (Citation2010), we have
(A6)
(A6) Next, to consider
we follow the similar expression (C.2) in Zhang and Wang (Citation2016). Again we focus on
. Applying (EquationA2
(A2)
(A2) ), we obtain, uniformly in s, t,
and
where
. Similarly to the proof of Theorem 3.4 in Li and Hsing (Citation2010), it can be shown that
(A7)
(A7) The theorem follows from (EquationA6
(A6)
(A6) ) and (EquationA7
(A7)
(A7) ).