
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this article, a new unit level model based on a pairwise penalised regression approach is proposed for problems in small area estimation (SAE). Instead of assuming common regression coefficients for all small domains in the traditional model, the new estimator is based on a subgroup regression model which allows different regression coefficients in different groups. The alternating direction method of multipliers (ADMM) algorithm is used to find subgroups with different regression coefficients. We also consider pairwise spatial weights for spatial areal data. In the simulation study, we compare the performances of the new estimator with the traditional small area estimator. We also apply the new estimator to urban area estimation using data from the National Resources Inventory survey in Iowa.
1. Introduction
Small area estimation (SAE) is an important problem in survey sampling when the sample sizes are not large enough to provide reliable estimates in small domains or areas. See Rao and Molina (Citation2015) and Pfeffermann (Citation2013) for overviews and recent developments in SAE. One of the model-based approaches for SAE is the unit level model, which was first proposed by Battese, Harter, and Fuller (Citation1988). Unit level models are specified for the individual elements of the population and require the availability of unit level auxiliary information.
Traditional unit level models typically assume a linear relationship between the variable of interest and the auxiliary information, and all the areas share the same regression coefficients to borrow information. Random effects are also considered for each small area. However, different relationships can exist in different areas. That is, subgroups could exist for different areas such that areas in one group have the same regression coefficient and areas in different groups have different regression coefficients.
In the linear regression setting, Ma and Huang (Citation2017), Ma, Huang, and Zhang (Citation2016) developed a method to obtain homogeneous groups based on regression coefficients through the alternating direction method of multiplier algorithm (ADMM, Boyd, Parikh, Chu, Peleato, & Eckstein, Citation2011). In the algorithm, they used pairwise concave penalties based on the smoothly clipped absolute deviation (SCAD) penalty (Fan & Li, Citation2001) and the minimax concave penalty (MCP) (Zhang, Citation2010). Wang, Zhu, and Zhang (Citation2019) extended the problem to a regression setting with repeated measures. They also considered spatial weights in the pairwise penalties and showed that spatial weights perform better than equal weights. However, the model cannot be applied to the SAE problems directly, since random effects are not considered.
In this article, we propose a new SAE estimator that allows different regression coefficients in different subgroups under a linear mixed model framework at the unit level. The ADMM algorithm is applied and the variance parameters are also estimated in the algorithm. As in Wang et al. (Citation2019), we use spatial pairwise weights in the pairwise penalties based on the SCAD penalty. In this algorithm, the number of groups and the group structure are also determined.
The article is organised as follows. In Section 2, we introduce the unit level model with areal regression coefficients and the algorithm to find subgroups. In Section 3, we conduct several simulation studies to compare the performance of the proposed estimator with the traditional estimators. In Section 4, we apply the proposed method to a real data set. Finally, Section 5 contains some conclusion and discussion.
2. The model and the algorithm
In this section, the unit level model with area level regression coefficients and the corresponding algorithm to estimate parameters are introduced.
2.1. The unit level model
Suppose there are M areas with known population size and
is the sample size in area i for
. Let
be the observation of unit h in area i for
,
. Let
be the p dimension auxiliary information vector with area population mean
known. In the traditional unit level model, that is Battese–Harter–Fuller (BHF) model (Battese et al., Citation1988), different areas share the same regression coefficient as in (Equation1
(1)
(1) ),
(1)
(1) where
is the unknown regression coefficient vector,
's are i.i.d areal random effects with mean zero and variance
, and
's are i.i.d random errors with mean zero and variance
. Let
be the set of observed units and
be the set of unobserved units in area i. The predictor for the finite population mean
in area i under model (Equation1
(1)
(1) ) for SAE given in Battese et al. (Citation1988) and the sae package (Molina & Marhuenda, Citation2015) is
(2)
(2) where
is the estimate of
and
is the empirical best linear unbiased prediction of
. In the simulation study, we use the R package sae (Molina & Marhuenda, Citation2015) to obtain the predictions.
Instead of assuming all the areas have the same regression coefficients , we assume that there are K mutually exclusive subgroups
, which is a partition of areas
. First we assume that each area has its own regression coefficient,
(3)
(3) where
is the unknown regression coefficient vector for area i. Let
,
and
. The weighted log likelihood function is
(4)
(4) where
is the covariance matrix based on the random effect structure which has the following form:
and
where
is an
vector with elements 1 and
is an
identity matrix.
If area i and area j are in the same group, then . In order to find the estimated partition
with the estimated number of groups
, the following objective function is considered
(5)
(5) where
denotes the Euclidean norm,
is a penalty function with a fixed value γ and a tuning parameter
. In the penalty function, pairwise weights are considered associated with area i and area j. In this paper, we use the SCAD penalty. In the context of spatial SAE, we define
as
(6)
(6) where ψ is a tuning parameter and
is the neighbour order between area i and area j. As shown in Wang et al. (Citation2019), pairwise spatial weights can help in spatial areal data.
2.2. The ADMM algorithm
For given λ and ψ, the solution of (Equation5(5)
(5) ) is
(7)
(7) The ADMM algorithm is applied to solve (Equation7
(7)
(7) ). Let
, the objective function becomes
where
. The augmented Lagrangian is
where
are Lagrange multipliers and ϑ is the penalty parameter. Let
. Given
,
and
,
and
are updated as follows:
Let
,
and
. The update of
is
where
, ⊗ is the Kronecker product,
with
an
vector with ith element 1 and other elements 0,
and
. When updating
,
is the expected second-order derivative of
in (Equation4
(4)
(4) ) and
The details of
and
are in the appendix. In this step,
can be updated several times within one iteration.
Updating is based on the result of SCAD penalty. Let
, then the solution is
where
and
and
if t>0, 0 otherwise.
Remark 2.1
The convergence criteria is based on that given in Boyd et al. (Citation2011). The primal residual and dual residual are defined as and
. The stopping criterion is
where
where
is an absolute tolerance and
is a relative tolerance. In the simulation study and the application, we use
and
.
2.3. The proposed small area estimator
As in Zhu, Zou, Liang, and Zhu (Citation2016), two small area estimators can be defined. Let and
be the sample mean of the variable of interest and auxiliary information, respectively. The first one is based on the predictions of random effects, which is defined as
(8)
(8) where
is the estimate of
from the proposed algorithm,
and
In the second estimator, the unobserved values in each area are predicted based on the model, which is given by
(9)
(9) where
and
. If
is small, then the predictor in (Equation9
(9)
(9) ) is nearly identical to the predictor in (Equation8
(8)
(8) ).
3. Simulation study
The simulation setup is designed based on the features of the National Resources Inventory (NRI) survey, which monitors status and trend of natural resources characteristics. One of the characteristic is the area of land uses, such as cropland, pastureland and urban (Nusser & Goebel, Citation1997). Each state is divided into ‘segments’ with size of 160 acres. From 1982 to 1997, the full NRI sample was observed in 5-year intervals (1982, 1987, 1992 and 1997) with 300,000 segments. In 2000, the NRI transitioned to an annual sample design with about 70,000 segments.
For the simulation, we construct an artificial population composed of 300,000 segments in 99 counties. The number of counties in the simulated population is the same as the number of counties in Iowa. We treat counties as areas and segments as unit level observations. In the population for the simulation, the number of segments in each county for the 99 counties is between 2210 and 5412. These numbers are the population sizes of segments in counties used in the simulation study. This simulated population maintains features of the NRI data for Iowa. There are around 6000 segments selected in the full sample and around 1500 segments selected in the annual sample in the original NRI design. In the annual sample, fewer segments are sampled, so the accuracy of the estimates is reduced. Thus auxiliary information should be considered to improve the estimator.
We compare the performances of the proposed estimators to the BHF estimator based on 100 simulations. Tuning parameters are selected based on the following modified BIC (Wang, Li, & Tsai, Citation2007):
(10)
(10) where l is defined in (Equation4
(4)
(4) ) and
is a positive number which can depend on M. Here we use
with
as in Wang et al. (Citation2019).
In the simulation study, simple random sampling is used in each county to select segments. As mentioned before, the population size of segments in each county is between 2210 and 5412. Two sampling rates are considered in each area, 1% and 0.5%. When sampling rate is 1%, there are 3067 selected segments in the whole state and the number of segments in each county is between 22 and 54. When sampling rate is 0.5%, there are 1537 selected segments in the whole state and the range of the number of segments in each county is from 11 to 27. with
's simulated from a normal distribution with mean 1 and standard deviation 1 and
's are simulated from a standard normal distribution, that is
. The assumed group structure in Iowa is shown in Figure with three groups. The three groups are aggregated based on the districts available on https://www.nass.usda.gov/Charts_and_Maps/Crops_County/boundary_maps/indexpdf.php
Figure 1. Group information.
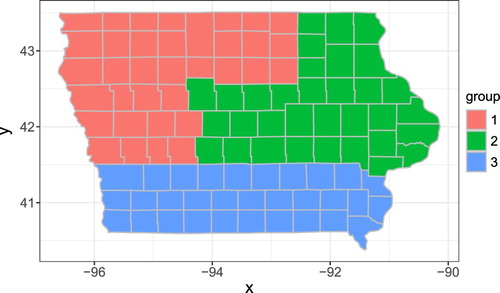
We consider three different sets of parameters.
Case I:
if
Case II:
Case III:
For each set of parameters, are considered and
. For the proposed estimator, we consider both the equal weight (
) and the spatial weight selected based on the modified BIC. Different estimators are compared by
where is the estimated population mean in area i and
is the population mean in the bth simulation, ‘E’ is the index of estimators which can be 1 or 2, and B=100. All the simulations are implemented in the Owens clusters of Ohio supercomputer centre (Ohio Supercomputer Center, Citation2016).
Figures , and show the results of the three sets of parameters when the sampling rate is 1% for 99 areas. ‘direct’ represents the direct estimator, which is the sample mean for simple random sampling. ‘BHF’ is calculated using the sae package provided in (Equation1(1)
(1) ). Under two different weights, we consider two small area estimators described in Section 2.3. ‘equal1’ and ‘sp1’ represent the estimator in (Equation8
(8)
(8) ) with equal weights and spatial weights, respectively. ‘equal2’ and ‘sp2’ represent the estimator in (Equation9
(9)
(9) ) with equal weights and spatial weights, respectively.
Figure 2. RMSE under Case I.
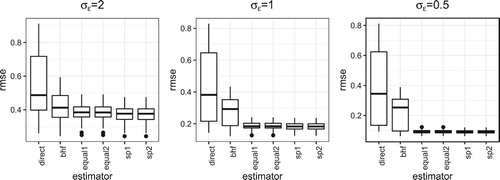
Figure 3. RMSE under Case II.
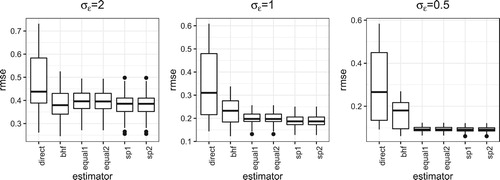
Figure 4. RMSE under Case III.
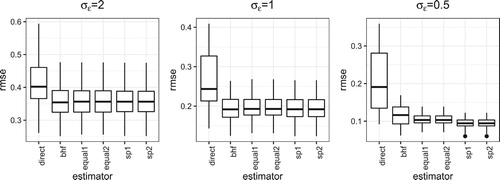
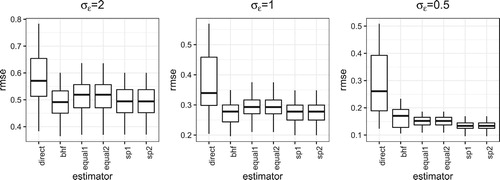
When is large, the proposed new estimator has the similar performance to the BHF estimator when the group difference is small. As
becomes smaller, the performance gain of the proposed new estimator is better than the classical BHF estimator. Besides that, the estimator with spatial weights performs better than the estimator with equal weights. Since the sampling rate is small, thus
is small, there is not much difference between the two estimators in (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ).
Figures , and show the results when the sampling rate is 0.5%. When the sample sizes become smaller and is large, the proposed estimator with equal weights can be worse than the BHF estimator. But the estimator based on spatial weights is still comparable. Similarly to the case with sampling rate 1%, the proposed estimator performs better when the group difference is large or the value of
is small.
Figure 5. RMSE under Case I.
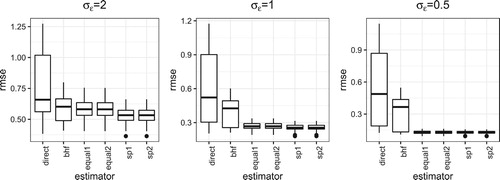
Figure 6. RMSE under Case II.
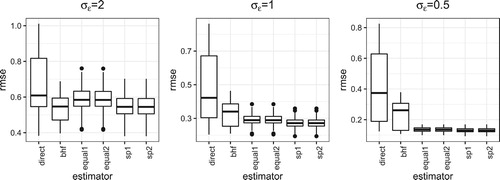
Figure 7. RMSE under Case III.
4. Real data analysis
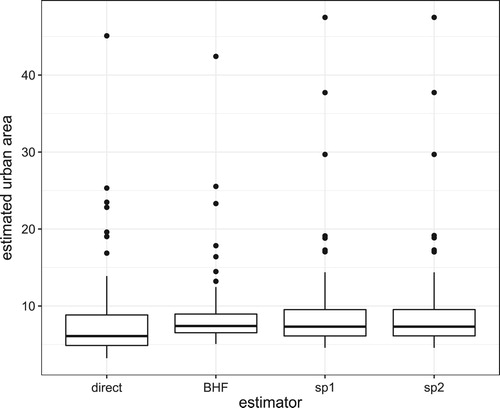
In this section, we apply the proposed method to the NRI Iowa urban data in 2015. The auxiliary information used is based on the Landsat data (Li et al., Citation2018). The Landsat data is matched to the segment level data in the NRI based on segments' locations. The number of segments per county is from 7 to 56. We try different starting values and select the best one with spatial weights. After finding the estimated group structure, we refit the model with known group structure and find the regression coefficients in all groups and then obtain the estimates in each county. Figure shows the estimated group map. And Figure shows the estimated population mean of urban in each county with a comparison with the sample mean and the BHF estimator. The proposed estimates are close to the estimates based on BHF, but with larger variations among different counties due to the fact that more than one groups are used in the estimates.
Figure 8. Estimated group structure.
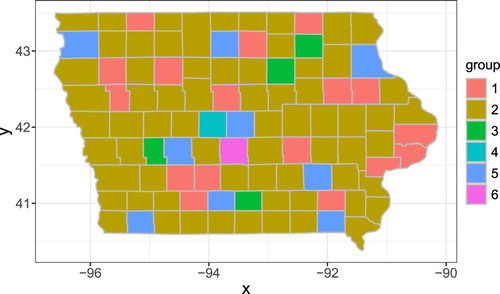
Figure 9. Estimated population mean of urban in each county.
5. Summary and conclusion
In this article, we propose a new unit level small area estimator based on a penalised regression approach. In the new estimator, we can find subgroups of areas and also borrow information from both auxiliary information and areas. Besides that, spatial information is also used in the algorithm. We use simulation studies to compare the performance of the new estimator to traditional estimators under several simulation settings, which show that the proposed estimator can improve the estimates.
Variance estimator is also important in survey sampling. A future work is to develop the variance estimator for the proposed new estimator. Another potential future work is to find subgroups for both regression coefficients and random effects together.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Xin Wang
Xin Wang is currently an Assistant professor in Department of Statistics at Miami University. Her research interests are spatial data analysis, Bayesian statistics, clustering, convergence rates of MCMC algorithms and survey sampling.
Zhengyuan Zhu
Zhengyuan Zhu is currently a Professor in Department of Statistics at Iowa State University, director of Center for Survey Statistics & Methodology. His research interests include spatial statistics, survey statistics, time series analysis, and multivariate analysis.
References
- Battese, G. E., Harter, R. M., & Fuller, W. A. (1988). An error-components model for prediction of county crop areas using survey and satellite data. Journal of the American Statistical Association, 83(401), 28–36.
- Boyd, S., Parikh, N., Chu, E., Peleato, B., & Eckstein, J. (2011). Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3(1), 1–122.
- Fan, J., & Li, R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American statistical Association, 96(456), 1348–1360.
- Li, X., Zhou, Y., Zhu, Z., Liang, L., Yu, B., & Cao, W. (2018). Mapping annual urban dynamics (1985–2015) using time series of Landsat data. Remote Sensing of Environment, 216, 674–683.
- Ma, S., & Huang, J. (2017). A concave pairwise fusion approach to subgroup analysis. Journal of the American Statistical Association, 112(517), 410–423.
- Ma, S., Huang, J., & Zhang, Z (2016). Exploration of heterogeneous treatment effects via concave fusion. arXiv preprint arXiv:1607.03717.
- Molina, I., & Marhuenda, Y. (2015). sae: An R package for small area estimation. The R Journal, 7(1), 81–98.
- Nusser, S. M., & Goebel, J. J. (1997). The national resources inventory: A long-term multi-resource monitoring programme. Environmental and Ecological Statistics, 4(3), 181–204.
- Ohio Supercomputer Center (2016). Owens supercomputer. http://osc.edu/ark:/19495/hpc6h5b1.
- Pfeffermann, D. (2013). New important developments in small area estimation. Statistical Science, 28(1), 40–68.
- Rao, J. N., & Molina, I. (2015). Small area estimation. Hoboken, New Jersey: John Wiley & Sons.
- Wang, H., Li, R., & Tsai, C.-L. (2007). Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika, 94(3), 553–568.
- Wang, X., Zhu, Z., & Zhang, H. H (2019). Spatial automatic subgroup analysis for areal data with repeated measures. arXiv preprint arXiv:11906.01853.
- Zhang, C.-H. (2010). Nearly unbiased variable selection under minimax concave penalty. The Annals of statistics, 38(2), 894–942.
- Zhu, R., Zou, G., Liang, H., & Zhu, L. (2016). Penalized weighted least squares to small area estimation. Scandinavian Journal of Statistics, 43(3), 736–756.
Appendix
In this appendix, details of partial derivative are provided.
where
can be written as
where