
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this research, we propose longitudinal generalised variance functions (LGVFs) to produce convenient estimates of variances by incorporating time effect into modelling. Asymptotic properties of some certain type of estimators are investigated. Simulation studies and implementation of the proposed methods to Current Population Survey (CPS) data show that LGVFs work well in producing standard error estimates.
1. Introduction
In many large-scale sample surveys such as the CPS or the Canadian Labour Force Survey (CLFS), thousands of estimates need to be reported. Calculating standard error for each published estimator involves a large amount of work. In addition, standard error estimates that are not provided by public-use files may also be needed. In a generalised variance function (GVF), we first estimate variances for totals of a group of variables by using balanced repeated replication (BRR), Taylor Series Linearisation (TSL) or other methods. Interested readers in variance estimation of a sample survey can refer to Cohen (Citation1979), Burt and Cohen (Citation1984), Rao and Wu (Citation1988), Rao (Citation1988), and Wolter (Citation2007). Next, we postulate a regression model relating the variance with the estimated totals and derive a fitted regression line for the purpose of predicting the standard errors of potential survey statistics. The GVF method saves a lot of time to produce the government reports.
Johnson and King (Citation1987) studied GVF estimators using a national survey of reading ability among young adults and found out that one way to markedly improve upon the GVF model is to use the prior information about the design effect (deff) of an individual estimator. Valliant (Citation1987) proved that the GVF model produces consistent estimates of the variance for a certain class of superpopulation models. He also mentioned that if the deffs for the group of estimated totals are similar, the GVF variances were often more stable than the direct estimate, as they smooth out some of the variability from variable to variable.
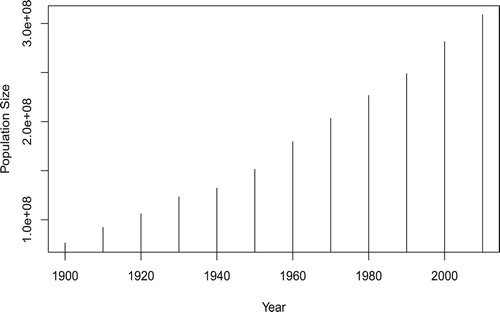
Many current surveys follow the same households at regular time intervals. GVF could be applied to analyse longitudinal data by treating population total as a constant over years. However, as Figure shows, the Census population from 1900 to 2010 exhibits a linear or slight exponential growth trend. Thompson (Citation2015) discussed approaches to incorporate complex designs in longitudinal data inference, as well as the complications introduced by time-in-sample effects. On the other hand, separate GVFs for each year sounds no longer a wise choice as we have longitudinal data. Shook-Sa, Heller, Williams, Couzens, and Berzofsky (Citation2013) mentioned, separate GVFs are currently needed for each year in National Crime Victimization Survey (NCVS), which makes it difficult to manage the analysis. All these request a new method that can produce a convenient formula to estimate the standard errors for longitudinal data. The fitted longitudinal model is expected to be used to predict standard errors of interested variables in the future without estimating GVF parameters.
Figure 1. U.S. population from 1900 to 2010.
In this research, we propose longitudinal generalised variance functions (LGVFs) by incorporating time effect into modelling. In Section 2, we review the GVF model. In Section 3, we set up a framework, propose LGVFs and derive asymptotic properties of the proposed estimators. Section 4 gives simulation studies and implementation of LGVFs with CPS data. Section 5 gives the conclusion of the research.
2. Generalised variance function model
In this section, we briefly review the GVF models. More detailed description can be found in textbooks from Wolter (Citation2007) and Lohr (Citation2010).
Let be a survey statistic, for example, the estimated number of persons employed. Let
be an estimated proportion of employment, with
, where M is the population total from the U.S. Census Bureau. Let d be the design effect of
and m be the sample size. We have
Define relative variance (relvar) of
as
where
and
. Let υ be the estimate of relvar of
, i.e.,
. Postulate a regression model relating a set of
to
by
. Let
and
be the regression estimates of a and b. The GVF relative variance is predicted by the fitted regression function
. A GVF estimate for
is given by the following function:
(1)
(1)
3. Longitudinal generalised variance functions
GVF has been widely used for a long time by many large-scale surveys because of the advantages of time saving and stability of the estimators. For example, it has been used by the CPS since 1947 (U.S. Census Bureau, Citation2006). In this section, we introduce the framework of our research and propose longitudinal generalised variance functions (LGVFs) by incorporating time effects. Properties of certain type of estimators are investigated.
3.1. Framework
Much of the notation in this section follows from Valliant (Citation1987). The main difference is that we have added index for time periods 1 to τ. In a stratified two-stage cluster sampling, we define h as the index for stratum, i as the index for primary sampling unit (psu), and j as the index for secondary sampling units (ssu) within the psu. At the psu level, let
be the number of psus in the population at time t,
be the number of psus in stratum h at time t, so that
. At the ssu level, let
be the number of ssus in psu i within stratum h at time t, so that the total number of units in stratum h at time t is
, and the total number of ssus in the population at time t is
.
Accordingly, at time t, let be the number of psus in the sample. Let
, where
is the number of psus in the sample within stratum h. Assume that
for
. Let
be the number of elements in the sample from ith psu within stratum h. As a result,
, and the total number of units in a sample over all strata
. At time t, let
be the set of sampled psu in stratum h,
be the set of nonsampled psu in stratum h, and
and
be the set of sampled and nonsampled units within psu i in stratum h.
Using a combined inference framework, assume a random variable is associated with each unit in the population at time t. The finite population total at time t is
. A general type of the estimator
can be written as
(2)
(2) where
is the coefficient,
and
, which estimates
. For example, the Horvitz–Thompson estimator when psus are selected with probabilities proportional to
, and an equal probability sample is selected within each sampled psu at time t can be written as follows:
(3)
(3) where
.
The following model assumptions can be applied for prediction purposes:
(4)
(4) Similar formulations can be found from Scott and Smith (Citation1969), Royall (Citation1976, Citation1986), and Burdick and Sielken (Citation1979). We can also apply more complex models such as the one in Cook and Pocock (Citation1983), time series models, or stochastic models. The general variance estimator of
to be studied is based on the one proposed by Royall (Citation1986):
(5)
(5) where
, and
is defined in Equation (Equation2
(2)
(2) ).
Let . Under the condition that
, we can show that
(6)
(6) where
.
3.2. The time effect model
In this section, we propose LGVFs by incorporating time effects. Let V be the number of variables for GVF and LGVF calculation. Let τ be the number of time periods we consider for LGVF. Let be the LGVF parameters we want to estimate. The V variables together with τ time periods provide
observations for regression parameters a and b estimation. Let time effect
, where
. Let
, and
. By Equation (Equation1
(1)
(1) ),
As in GVF, we define a set of relative variances
for
and
. We now have
(7)
(7) Let
,
,
, and
. Now define
as the
design matrix for time t with the first column 1s and second column
. Let
be the design matrix with
. Under the condition that
and
for
,
, time effect model (Equation7
(7)
(7) ) can be written in the matrix form as follows:
(8)
(8) The weighted least square estimators of
is
, where
is the weight associated with variable v at time t, and
is a
matrix with the diagonal element
.
is usually chosen as the reciprocal of variance of
when they are known. Otherwise, we can approximate the weight by reciprocal of squared
.
Consider data pairs for
,
. We can derive the following estimators for a and b:
(9)
(9) and
(10)
(10) where
,
,
, and
. The predicted relvariance of
based on the estimated LGVF is
(11)
(11) Note that model (Equation8
(8)
(8) ) only incorporate
. It doesn't specify what kind of time effect that
has. The simplest case of
could be
, where
is the population total from the U.S. Census Bureau without introducing any modelling. We can also incorporate linear time effect as illustrated in Figure by the following example.
Example
Linear time effect LGVF.
Figure shows that the U.S. population size increased dramatically with a linear trend during the years of 1990–2010. We now fit a simple linear regression model for the population size growth over time t as follows:
(12)
(12) By the fact that
, we have
Replacing
in (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ) by
, we have the LGVF estimates for linear time model (Equation12
(12)
(12) ).
3.3. Properties of proposed estimators
In this section, we consider a certain type of estimators such that in Equation (Equation2
(2)
(2) ) is with a structure of
. For example,
for
in Equation (Equation3
(3)
(3) ). Under assumptions (Equation4
(4)
(4) ), given estimators with the structure of
, asymptotic properties of
,
, and
can be derived when the number of psus in each stratum is large. Lemmas A.1–A.3 (refer to Appendix) are extensions of work by Royall (Citation1986). Under certain conditions, Theorem 3.1 shows that ratios of relative variances and predicted relative variances from proposed LGVFs converge in probability to 1 (refer to Appendix for proof). The asymptotic normality then follows immediately.
Theorem 3.1
Under model (Equation4(4)
(4) ), assumptions (i) to (xiii),
and
for
as
Proof.
Proof is given in Appendix.
Theorem 3.2
Under model (Equation4(4)
(4) ), assumptions (i) to (xiii),
and
for
as
Proof.
The proof is a straightforward extension of work by Royall (Citation1986).
4. Implementation with CPS
In this section, we first use CPS annual social and economic supplement (ASEC) data as a population to perform simulation studies. Next, we apply the proposed methods to analyse ASEC data in conjunction with ASEC public use replicate weight file (ASECREP). The corresponding ASECREP data are merged with ASEC by the link variables (household sequence number) and pppos (trailer portion of unique household ID) for variance estimation purpose in data application. The ASECREP data have weights for the variables according to 160 replications, which are used to calculate variances. Nineteen binary variables from the ‘Source of Income’ section are initially considered, such as self-employment or not, unemployment compensation or not, and so on. Specifically, they are finc_ws, finc_se, finc_fr, finc_uc, finc_wc, finc_ss, finc_ssi, finc_paw, finc_vet, finc_sur, finc_dis, finc_ret, finc_int, finc_div, finc_rnt, finc_ed, finc_csp, finc_fin, and finc_oi.
A person's value of a binary variable is 1 if the person had a particular characteristic, and is 0 otherwise. By examining 2009 ASEC data, the mean of deffs of the 19 variables is 3.754811, and the range of deffs is from 1.593687 to 6.329467. We removed two variables with the low deffs: finc_ss with deff of 1.593687, and finc_sur with deff of 1.809737. We also removed three variables with high deffs: finc_int with deff of 6.329467; finc_div with deff of 6.073850, and finc_fin with deff of 5.559943. The remaining 14 variables are relatively similar regarding deffs with a mean of 3.569623, and a narrower range from 2.059918 to 5.424058. These 14 binary variables are used to construct GVFs (using 2011 ASEC data) and LGVFs (using 2008 to 2010 ASEC data). In the simulation study, we removed variable finc_ws due to its very low relative variance. We restricted our analysis to the state of New Mexico when we apply ASEC and ASECREP data.
4.1. Simulation studies
We treat 2008 (2059 observations), 2009 (2188 observations), and 2010 (2108 observations) ASEC data in New Mexico as finite population. Each household was associated with an ultimate sampling unit (USU) defined for the CPS. However, the USU information is not released to public. To mimic the design, we sorted households from the smallest sequence number to the largest one within each year and combined four households as a USU according to order. This results in 205, 208, and 193 USUs, respectively. Simulation is performed with the following steps:
Within each year, we select n=40 (about 20% sampling rate) and n=100 (about 50% sampling rate) USUs with probabilities proportional to size (PPS) and select
individuals within selected USU i with equal probability.
Calculate estimates for the three samples (2008, 2009 and 2010). Total for variable v at time t is estimated by the Horvitz–Thompson estimator in Equation (Equation3
Apply time adjustment
Apply regression model (Equation7
Record relvar calculated by using formulas (Equation3
Repeat (a)–(e) for 2000 times. For each variable, record average values of the relvar calculated by Equations (Equation3
Simulation results of both cases: PPS 40 USUs and PPS 100 USUs are very close to each other, so we will only report results from the case of PPS 100 USUs. The case of PPS 100 USUs performs slightly better than the other case regarding bias and variance. This is very reasonable as Theorems 3.1 and 3.2 require large and
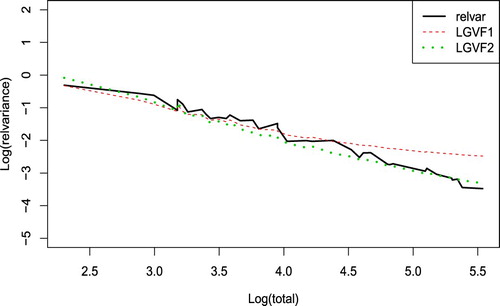
. Figure is the plot of logs of relvars by Equations (Equation3
(3)
(3) ) and (Equation5
(5)
(5) ) (solid line, treated as true values) and estimates from LGVFs 1–2 (dashed line and dotted line) plotted versus logs of population totals. From the plot, we can see that LGVF2 works very well in estimating the true relvars. LGVF1 deviates from the true value quite a bit when the population total of the variables is large.
Figure 2. Logs of estimates of relvar plotted versus logs of population totals.
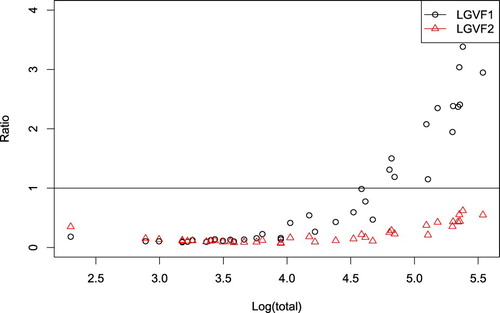
To see how precise our LGVF estimators are, we also plot the ratios of standard error estimates of relvars by LGVFs 1–2 to the standard error estimate of relvars calculated by sampling variability from simulations (see Figure ). Ratios less than 1 indicate that an LGVF is more precise than the sampling variability by simulations. LGVF2 is doing perfect in estimating the variance of relvar with none of the ratios greater than 1. While not surprisingly, LGVF1 has large variance when population total of the variable is large. But LGVF1 is also doing Okay.
Figure 3. Ratio of the SEs (LGVF1–LGVF2/relvar) versus log (totals).
We also investigated the histograms of the binary variables to see how Theorem 3.2 works. We observe that asymptotic normality reveals well with high proportion variable such as finc_se (with a total of 211). While for small total variable such as finc_dis with a total of only 10, the histogram is highly skewed to the left as samples with small totals are frequently selected.
4.2. Data analysis: apply LGVF to the full 2008–2010 data
In this section, we apply our methods to the full data set, which we used as population in simulation studies. The 14 binary variables used to construct GVFs and LGVFs are from the ‘Source of Income’ section of ASEC without the two lowest and three highest deff scores as we discussed in Section 4. In data analysis, variance is calculated by using replicate weights and a formula provided by ASECPEP user's manual (U.S. Census Bureau, Citation2009): , where
is calculated using weights ‘PWWGT0’ for full data, and
are calculated by using the 160 replicate weights ‘PWWGT1’ to ‘PWWGT160’. This is essentially the empirical variance adjusted by a factor of 4. The estimated totals
are calculated by using full data weights ‘PWWGT0’. We then postulate a regression function on the relative variances and the adjusted estimated totals
to derive the estimates of the regression parameters a and b.
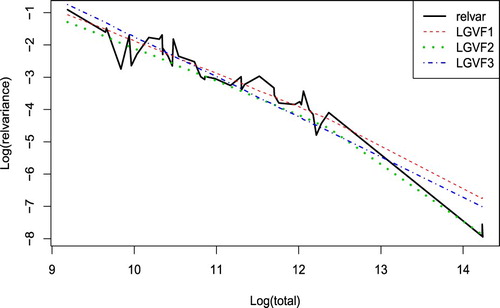
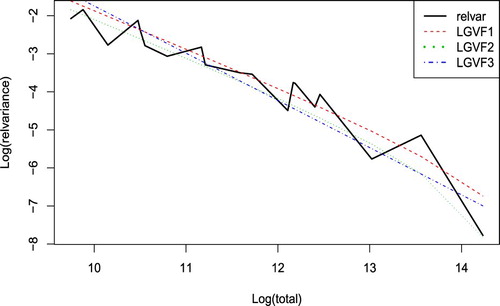
Regression fitting methods, LGVF1: ordinary linear regression, LGVF2: weighted least squares with , and LGVF3: data after log transformation on both y and x are applied. Figure is the plot of logs of estimates of relative variances and the estimates from the LGVFs 1–3 plotted versus logs of population totals. From the plot, we can see that LGVF2 (dotted line) seems to mimic the relative variances most closely. LGVF1 (dashed line) and LGVF3 (dash-dotted line) also work fine, with the tail a little off from the black line.
Figure 4. Logs of estimates of relvar plotted versus logs of population totals.
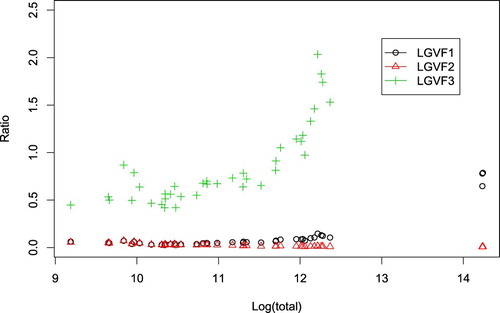
We also plot the ratios of standard error estimates of relative variances by LGVFs 1–3 to the standard error estimate of relative variance by using replicate weights to see how precise the proposed LGVF estimators are. Ratios less than 1 indicate that an LGVF is more precise than υ. LGVF1 and LGVF2 are both precise with none of the ratios greater than 1. The variance of relvar from some variables estimated by using LGVF3 is less precise than the variance estimated using replicate weights, but LGVF3 is also doing well (Figure ).
Figure 5. Ratio of the SEs (LGVF1–LGVF3/relvar) versus log(totals).
Next, we use LGVF models to predict the relative variances of the year 2011 data. These relative variances can be calculated by the replicate weights as we have done before, which are treated as direct calculated relvar. Figure shows the prediction are quite good, with LGVF2 performing the best.
Figure 6. Logs of predicted relvar by using LGVF1–3 plotted versus logs of population totals (11 March).
4.3. Comparison of GVF with LGVF
In this section, we do a brief comparison study of the performance of GVF and LGVF. The GVF models are constructed by the year 2011 data, while the LGVF models are built by using three years (2008–2010) of data with time adjustment. The same regression fitting methods: ordinary least squares (Method 1), weighted least squares (Method 2), and log transformations (Method 3) are applied to GVF modelling. Accordingly, they are called GVF1, GVF2, and GVF3. Fourteen variables are used to construct GVFs and LGVFs, and the remaining five variables are used for predicting. Mean-squared prediction errors are calculated as the average of the sum of the squares of the difference between predicted values and observed values.
Table shows that LGVFs have smaller mean-squared prediction errors. When predicting the five remaining variables, GVFs and LGVFs do not make much difference. However, the case of predicting 19 variables in 2011 is standing out with SE of 0.003108 by LGVF2 compared to SE of 0.01781 by GVF1. It is quite exciting since this is the most common case we want to apply the LGVF methods. That is, we want to use a few years of data to build the LGVF model to make a prediction for future years. Since design effects do not change much over years, therefore, combining the variables from 2009 with the same variables from 2008 and 2010 should result in reasonable results. We also incorporated to adjust for time effect for a longitudinal issue. The LGVF methods, particularly LGVF2, perform very well regarding mean-squared prediction errors.
Table 1. Comparison of GVF and LGVF.
5. Conclusions
In this research, we extended the Generalised Variance Functions (GVFs) to Longitudinal Generalised Variance Functions (LGVFs), which reduce to GVFs when data are cross-sectional. We incorporated time effect into modelling to adjust the dynamic time changes over the years. We show that ratios of relative variances and predicted relative variances from the proposed LGVFs converge in probability to 1 under certain conditions. Based on simulation studies, we would suggest using LGVF2 (the weighted least square regression fitting) to predict relative variances of the variables as it has smaller bias and variance compared to the other two methods. Data application to ASEC supplements using replicate weights provided by ASECPEP reveals similar findings. A comparison study between LGVF and GVF also show that LGVF is efficient in reducing the mean squared prediction errors. Future research may consider adopting mixed models and nonparametric smoothing methods for regression model fitting. In both mixed model and nonparametric application, we can add the prior design effect information into models. This may markedly improve our model as suggested by Johnson and King (Citation1987).
Acknowledgements
The authors thank the referees for helpful comments and constructive suggestions to improve the manuscript.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Notes on contributors
Guoyi Zhang
Dr Guoyi Zhang is an Associate Professor of the Department of Mathematics and Statistics at the University of New Mexico. His research areas are in nonparametric function estimation, statistical computing, and survey sampling.
Yang Cheng
Dr Yang Cheng is a Senior Mathematical Statistician at the Substance Abuse and Mental Health Administration. He works on the areas of sample designs, weighting structure, statistical estimation and modelling.
Yan Lu
Dr Yan Lu is an Associate Professor of the Department of Mathematics and Statistics at the University of New Mexico. Her research areas are in survey sampling and mixed Models.
References
- Burdick, R. K., & Sielken Jr., R. L. (1979). Variance estimation based on a superpopulation model in two-stage sampling. Journal of the American Statistical Association, 74, 438–440.
- Burt, V., & Cohen, S. B. (1984). A comparison of methods to approximate standard errors for complex survey data. Review of Public Data Use, 12, 159–168.
- Cohen, S. B. (1979). An assessment of curve smoothing strategies which yield variance estimates from complex survey. Proceedings of the Survey Research Methods Section of the American Statistical Association, Washington, DC.
- Cook, D. G., & Pocock, S. J. (1983). Multiple regression in geo-graphical mortality studies with allowance for spatially correlated errors. Biometrics, 39, 361–371. doi: 10.2307/2531009
- Johnson, E. G., & King, B. F. (1987). Generalized variance functions for a complex sample survey. Journal of Official Statistics, 3, 235–250.
- Lohr, S. (2010). Sampling: Design and analysis (2nd ed.). Boston, MA: Cengage Learning.
- Rao, J. N. K. (1988). Variance estimation in sample surveys. In P. R. Krishnaiah & C. R. Rao (Eds.), Handbook of statistics (Vol. 6, pp. 427–447). Amsterdam: Elsevier Science Publishers B.V.
- Rao, J. N. K., & Wu, C. F. J. (1988). Resampling inference with complex survey data. Journal of the American Statistical Association, 83, 231–241. doi: 10.1080/01621459.1988.10478591
- Royall, R. M. (1976). The linear least squares prediction approach to two-stage sampling. Journal of the American Statistical Association, 71, 657–664. doi: 10.1080/01621459.1976.10481542
- Royall, R. M. (1986). The prediction approach to robust variance estimation in two-stage cluster sampling. Journal of the American Statistical Association, 81, 119–123. doi: 10.1080/01621459.1986.10478247
- Scott, A. J., & Smith, T. M. F. (1969). Estimation in multi-stage surveys. Journal of the American Statistical Association, 64, 830–840. doi: 10.1080/01621459.1969.10501015
- Shook-Sa, B., Heller, D., Williams, R., Couzens, G. L., & Berzofsky, M. (2013). Comparing generalized variance functions to direct variance estimation for the national crime victimization survey. 2013 research conference, Federal Committee on Statistical Methodology (FCSM), Washington, DC.
- Thompson, M. E. (2015). Using longitudinal complex survey data. The Annual Review of Statistics and Its Application, 2, 305–320. doi: 10.1146/annurev-statistics-010814-020403
- U.S. Census Bureau. (2006). Current population survey: Design and methodology (Technical Paper 66).
- U.S. Census Bureau. (2009). Estimating ASEC variances with replicate weights. Part 1: Instructions for using the ASEC public use replicate weight file to create ASEC variance estimates.
- Valliant, R. L. (1987). Generalized variance functions in stratified two-stage sampling. Journal of the American Statistical Association, 82, 499–508. doi: 10.1080/01621459.1987.10478454
- Wolter, K. M. (2007). Introduction to variance estimation (2nd ed.). New York, NY: Spring-Verlag.
Appendix
For each time period , the following conditions apply as
for
.
Lemmas A.1–A.3 are extensions of work by Royall (Citation1986).
Lemma A.1
Under model (Equation4(4)
(4) ) and conditions (i) to (viii) in Appendix,
where
is defined in Equation (Equation2
(2)
(2) ),
is defined in Appendix, and the symbol ≈ means ‘asymptotically equivalent to’.
Lemma A.2
Under model (Equation4(4)
(4) ) and conditions (i) to (ix),
and
as defined in Equation (Equation5
(5)
(5) ), we have
Lemma A.3
Under model (Equation4(4)
(4) ) and conditions (i) to (viii) and (x),
and the random variables
are mutually independent at each time period t, then
Proof of Theorem 3.1.
Proof of Theorem 3.1
Proof follows Valliant (Citation1987). We first prove that has the same limit as
for any time period t. Next, we prove that the estimated
converges to the same limit.
By Equation (Equation6(6)
(6) ), adding the subscript v and time t, we have
where
and
By the definition of
and the assumption that
, together with conditions (iv), (v), (xii), and (xiii),
Similarly,
Let
for all t and v.
for some constant A.
for all t and v, so
for some constant B. Therefore,
Next we'll show that
has the same limit. Lemma A.3 shows
Therefore,
Together with Lemmas A.1 and A.2, we have
Now multiplying and dividing within the summation by
gives
(A1)
(A1) Next, we want to show that
to complete the proof. Recall that
for all time period t. Consider
and
in Equation (Equation9
(9)
(9) ), by condition (xi), (xii), (xiii), and the result from (EquationA1
(A1)
(A1) ), we have
(A2)
(A2) and
(A3)
(A3) where
By (EquationA2
(A2)
(A2) ) and (EquationA3
(A3)
(A3) ), we have
The convergence of
(EquationA1
(A1)
(A1) ) implies that
As a result,
Therefore, for all time periods