
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In the Fay–Herriot model, we consider estimators of the linking variance obtained using different types of resampling schemes. The usefulness of this approach is that even when the estimator from the original data falls below zero or any other specified threshold, several of the resamples can potentially yield values above the threshold. We establish asymptotic consistency of the resampling-based estimator of the linking variance for a wide variety of resampling schemes and show the efficacy of using the proposed approach in numeric examples.
1. Introduction
A typical survey on any aspect of human behaviour or natural phenomena is limited in scope by feasibility, ethics and cost constraints. Consequently, data are not always obtained in as fine a scale as required by stakeholders. In such cases, small area models are often useful for gathering resources across various domains and variables to obtain estimators and inferences with high precision. Detailed description of small area methods, principles and procedures may be found in the book (Rao & Molina, Citation2015), and in the papers (Chatterjee, Lahiri, & Li, Citation2008; Das, Jiang, & Rao, Citation2004; Datta, Hall, & Mandal, Citation2011; Datta, Rao, & Smith, Citation2005; Jiang & Lahiri, Citation2006; Jiang, Lahiri, & Wan, Citation2002; Li & Lahiri, Citation2010; Molina, Rao, & Datta, Citation2015; Pfeffermann, Citation2013; Pfeffermann & Glickman, Citation2004; Rao, Citation2015; Yoshimori & Lahiri,Citation2014a, Citation2014b).
In small area studies, arguably the most popular choice of a model for the observed data is the Fay–Herriot model (Fay & Herriot, Citation1979). This model is described by the following two-layered framework:
Sampling model: Conditional on the unknown and unobserved area-level effects
, the sampled and observed data
Linking model: The unobserved area-level effects
Suppose and
are mutually independent n-dimensional Gaussian random variables, respectively, denoting the errors and random effects. Then we may express the Fay–Herriot model as
(1)
(1) In the above Fay–Herriot model, the unknown parameters are the regression parameters
and a common linking variance component
. The distribution of the area-level effects
, conditional on the data
, is the primary quantity of interest in the Fay–Herriot model, and this distribution depends on β and ψ. One traditional approach is to estimate these parameters from data, and then use the estimators in subsequent prediction of
, conditional on the data
.
To assess the quality of prediction in a small area context, we may compute the mean squared prediction error or obtain a prediction interval. The typically Monte Carlo computation-driven technique of resampling is quite popular method for obtaining such intervals and errors bounds and a variety of other purposes, see for example, Chatterjee et al. (Citation2008), Datta et al. (Citation2011), Kubokawa and Nagashima (Citation2012). While most of these papers either use the parametric bootstrap or Efron's original bootstrap (Efron, Citation1979), other approaches to resampling are also viable, as discussed later in this paper.
One of the intermediate products in all such resampling computations are multiple copies of the estimators of β and ψ obtained from the resamples. The objective of this paper is to assess the quality of such resampling-driven estimators of the original parameters of the data, and we concentrate only on the linking variance parameter ψ here, since it is more critical in subsequent analysis. The immediate purpose of this study is to explore the possibility of using such resampling-based estimators of ψ in case the estimator from the original data takes too low a value.
We present new estimators of ψ, based on the resampling data in a Fay–Herriot model in Section 2, and related theoretical results in Section 3. Some simulation studies are presented in Section 4. Some concluding remarks are included in Section 5.
In the above description of the Fay–Herriot model and in the rest of this paper, we consider all vectors to be column vectors, and for any vector or matrix A, the notation denotes its transpose. For any vector a, the notation
stands for its Euclidean norm. The notation
will denote the ith element of vector a, similarly
will denote the
th element of matrix A. The notation
denotes the trace of a matrix A,
is the indicator function of measurable set A, and
are symbols denoting probability, expectation and variance generically. Other notations will be introduced and described as they arise.
We assume that p is fixed and p<n holds, and X is full column rank. We use the notation for the ith row of the matrix X, and
for the projection matrix onto the columns of X. In fact, all our results are valid even when p increases with n as long as
, but the proofs require some additional technicalities. We assume that
tends towards a positive definite matrix. We also assume that
that is, the maximum of the diagonal entries of the projection matrix
is of the order of
. These conditions are very traditional and standard. We use the notation
for the diagonal matrix that has the ith diagonal element as
, ie.,
and
share the same diagonal elements but
has all off-diagonal elements to be zero. Additionally, we assume that the sampling variances
's are bounded above, and away from zero.
2. The resampling-based framework
In the Fay–Herriot model, we implement resampling by associating a non-negative random weight, generically referred to as a resampling weight , with the ith observed data point
, for
. We assume that these weights are exchangeable and independent of the data, and
and
, where
. Henceforth we use the notation
to denote resampling-expectation, that is, expectation with respect to the distribution of
conditional on the observed data.
Define
for the centred and scaled version of these resampling weights. In minor abuses of notation, we also define
as a diagonal matrix with the ith diagonal element being
, and similarly W is a diagonal matrix whose ith diagonal element is
. Thus we may write
Let be a pre-specified constant, and
be the set on which the smallest eigenvalue of
is higher than δ. Under standard regularity conditions the probability of the set
is exponentially small, see for example, Chatterjee and Bose (Citation2000). Nevertheless, it is useful to consider the cases
and
separately, since differences arise occasionally with specific choices of
in numeric computations with finite samples.
Using the resampling weights along with the observed data, the estimator for the regression slope parameters are
In the above, the second subscript is to denote that this estimator is obtained in the resampling scenario. In the following we describe the case for the set
only for brevity, the asymptotically negligible case
can be addressed using routine algebra. The above leads to the resampling-based fitted values
, and the resulting residuals
In the rest of the paper, we study two different resampling-driven estimators of ψ. Let
The resampling-based Prasad–Rao estimator for ψ is defined as
(2)
(2)
The above estimator is based on Prasad and Rao (Citation1990), where we fit an ordinary least squares regression on the original data using the covariates X, thus obtaining
. Based on the above estimator for β, define the vector of residuals
. We use the notation
for the ith element of R. The PR estimator for ψis given by
(3)
(3)
The second resampling-based estimator of ψ that we study is a variant of the above. Fix a small that is smaller than the lower bound on ψ. Define the set
The alternative resampling-based estimator that we propose is
Note that on the set
,
is greater than
, consequently
almost surely. Essentially, the cases where the rth resample has
and take an average over the rest of the cases.
This PR estimator is positive almost surely when the intercept is the only covariate but may return a negative value under some circumstances. In fact, an often-encountered challenge in small area studies is to get an estimate of ψ that is positive since standard estimation techniques like the Prasad–Rao method discussed above may result in a potential negative value as an estimate of variance. To address this issue, several techniques have been proposed, see for example Li and Lahiri (Citation2010), Yoshimori and Lahiri (Citation2014a), Hirose and Lahiri (Citation2017), Chatterjee (Citation2018).
Our resampling-based proposed estimators achieve such positive values several times even when . We present some numeric examples in Section 4.
Multiple traditional resampling scheme may be realised as special cases of the above framework. Consider a probability experiment where we have n boxes, and n balls, and we allocate balls to boxes randomly and independently, with each ball having the equal probability of 1/n of being allocated to any of the n boxes. The n-dimensional random vector obtained by counting the number of balls in the ith box, for may be considered as an example of
, with
and
. This example is mathematically identical to the famous paired bootstrap of Efron.
If we modify the above probability experiment slightly, and consider the case where we have only m balls, the above framework obtains that corresponds to the m-out-of-n bootstrap (referred to as moon-bootstrap in the rest of this paper). If we consider the case where
are independent and identically distributed exponential random variables, we obtain variations of the Bayesian bootstrap of Rubin. Other interesting special cases and additional discussion on using resampling weights may be found in Præstgaard and Wellner (Citation1993), Barbe and Bertail (Citation1995), Chatterjee and Bose (Citation2005) and multiple references therein, and in the related chapter of Shao and Tu (Citation1995). The latter classic text, along with the other classic (Efron & Tibshirani, Citation1993) may be consulted for details about resampling in general.
3. Asymptotic consistency of proposed estimators
We assume that the cross moments on the centred and scaled resampling weights, as in for small values of J and
, do not grow very fast with n. Precise rate at which these grow are available in Chatterjee (Citation1998), Chatterjee and Bose (Citation2000), Chatterjee and Bose (Citation2005) and in other places, and it can be shown easily that such conditions hold for the standard choices of resampling weights. Naturally, when the resampling weights are independent, and the above cross moments are bounded and are often zero, easily satisfy such requirements. We omit detailed discussion on these conditions. We assume that γ is bounded, which is also satisfied by several resampling schemes, but not by others like the moon-bootstrap. Our theoretical results are valid even when we use a controlled rate of growth of γ with n that is applicable to the moon-bootstrap, and our numeric studies validate this later in this paper. However, we discuss only the case of bounded γ to simplify some of the proofs. We now present our main results below.
Theorem 3.1
Under the conditions stated above, the resampling-based Prasad–Rao estimator is asymptotically consistent, that is
in probability, as
.
The different resampling-based estimator , constructed by only considering those resamples where
exceeds a threshold, is consistent as well, apart from being always positive. We present this result in the following Theorem:
Theorem 3.2
Under the conditions stated above,
in probability, as
.
Proof of Theorem 3.1
We omit several algebraic details below, especially those relating to proving asymptotically negligible terms are indeed negligible. Thus, the proof below is a sketch of the main arguments. Below, we use for
as generic notation for negligible remainder terms. Also, we use c and K, with our without subscripts, as generic notation for constants.
Define . Then
Thus,
Now notice that
Thus
Thus we have
Here, we have
Note that for any non-zero
Thus all eigenvalues of the expectation of
are
.
This leads us to
where
. We can show that for any non-zero
with
, we have
. This is algebraic, we omit the details.
So that eventually we get
Hence we can write
The exact expression of
is available from the above expansion, we do not re-write it to avoid repetitions.
The resampling-expectation of the above is
Also notice that
with the first term contributing
, the second and third terms contributing
and the last term contributing
.
We can show, using the computations on and
partially presented above, that
This computation is algebraic, we present a few instances of the main arguments we use for this step.
Consider the term
We have
Thus we have
As an example, consider the second component in the last term above. First, let us deal with the case i=j. Then this term becomes
For the case, we have
Thus, we essentially repeatedly leverage the properties of a projection matrix for the algebraic computations. We omit further algebraic details, they are typically routine.
If we now write
the above computations establish that
as
, thus establishing the result.
Proof of Theorem 3.2
This proof contains several calculations in common with the proof of Theorem 3.1, consequently we only discuss the main ideas, and omit most algebraic details.
Recall from the proof of Theorem 3.1 that
For convenience, let us use the notation . We thus have
Our previous computations from the proof of Theorem 3.1 now ensure that as well as
, and hence both the above probabilities tend to zero, we omit some of the algebraic details here. Some additional algebraic details are then required to establish that the expectation of the square of the difference between
and
is also
, thus concluding the proof.
4. Some simulation studies
To understand the finite sample performance of the proposed estimator of ψ, we conducted a simulation study. In this study, we consider a framework based closely on the studies of Datta et al. (Citation2005). We use n=15 observations, and p=3 covariates, one of which is the intercept term, and the other two covariates are random generated in each replication of the experiment and fixed. We fix and
. We conduct the experiments with two different choices of the sampling variances. In Experiment 1, we fix the
's to be 2.0, 0.6, 0.5, 0.4, 0.2, each repeated 3 times. In Experiment 2, we fix the
's to be
, each repeated 3 times.
We consider three different resampling schemes in this study. First, we consider to be the multinomial random variable corresponding to randomly assigning n balls in n boxes, each with equal probability. This corresponds to the paired bootstrap of Efron. Next, we consider
to be the multinomial random variable corresponding to randomly assigning
balls in n boxes, each with equal probability, which corresponds to the moon-bootstrap. Third, we consider each element of
to have an exponential distribution with mean 1, thus realising the Bayesian bootstrap. The resampling Monte Carlo size is fixed at 1000 in all cases. The simulation experiment was replicated 200 times, and the results presented below are based on these 200 replications.
First, we enumerate the percentage of times estimators of ψ took values less than . This number varies on the various parameters used in the simulation experiment, and can approach even
when we change only a single
value or a parameter value within reasonable range.
In Experiment 1, it can be seen from Table that in approximately of the simulated datasets, the Prasad–Rao estimator based on the original data obtained a value less than ϵ. In these
of the simulated datasets where the Prasad–Rao estimator took a value less than ϵ, different resampling schemes obtained between 19% and 25% cases where the Prasad–Rao estimator based on the resampling data were above ϵ. In the other
cases where the Prasad–Rao estimator from the original data was greater than ϵ, its resampling data-based versions were typically
times greater than ϵ as well. This suggests that using the Prasad–Rao estimator based on the resampling data may significantly improve the numeric performance of estimates of the conditional distribution of
given
, or related prediction intervals, conditional expectations and so on. In Experiment 2, it can be seen from Table that in approximately
of the simulated datasets, the Prasad–Rao estimator based on the original data obtained a value less than ϵ. Other details are consistent with the findings from Experiment 1.
Table 1. Percentages of cases where different estimators of ψ was below or above in Experiment 1.
Table 2. Percentages of cases where different estimators of ψ was below or above in Experiment 2.
We obtain several plots from Experiment 2. In Figure , in the top panel, we present in plot (1) the boxplot of from the 200 replications of the simulation experiment. We also select two such replications at random, one corresponding to a dataset where
and the other where
. In the top panel of Figure , plots (2) and (3) are the resampling estimator
obtained using multinomial weights corresponding to the paired bootstrap in the randomly selected dataset for which
. Plot (2) is from all resamples, and plot (3) is based on only the resamples where
. Plots (4) and (5) are
obtained using multinomial weights corresponding to the paired bootstrap in the randomly selected dataset for which
, respectively, based on all resamples and only the resamples where
. Plot (6) is from the ‘Mix’ estimator proposed by Rubin-Bleuer and You (Citation2016), which is always guaranteed to be positive. While the Mix estimator is always positive, notice that is also seems quite biased.
Figure 1. Boxplots of the Prasad–Rao (PR) estimators from Experiment-2. In the top panel, plot (1) is the boxplot of from the 200 replications of the simulation experiment. The rest of the boxplots are from two randomly selected instances of these replications. Plots (2) and (3) are
obtained using multinomial weights corresponding to the paired bootstrap in a case where
. Plots (4) and (5) are
obtained using multinomial weights corresponding to the paired bootstrap in a case where
. Plot (6) is the Mix estimator. In the bottom panel, we consider a randomly selected case where
. The first two boxplots, are from multinomial bootstrap, corresponding respectively to cases where we use all the resamples, and only the ones where
. The third and fourth are from moon bootstrap and fifth and sixth are from Bayesian bootstrap for all resamples and from resamples with
, respectively. Plot (7) is the Mix estimator.
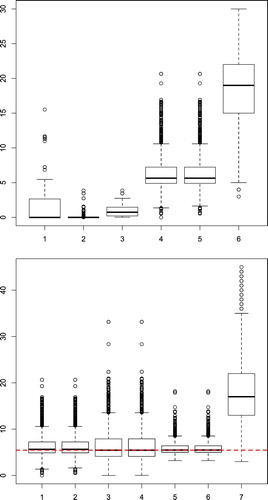
In the bottom panel of Figure , we consider a randomly selected case where . The first two boxplots are from multinomial bootstrap, corresponding, respectively, to cases where we use all the resamples, and only the ones where
. The third and fourth are from moon bootstrap and fifth and sixth are from Bayesian bootstrap for all resamples and from resamples with
, respectively. The last plot is from the Mix estimator, which is again quite biased. The red horizontal line is at the value of
for that dataset. It can be seen that all the resampling estimators perform well, especially in cases where
. For the cases where
, the resampling-based estimators offer the alternative of obtaining a higher value of the estimator, while retaining their theoretical consistency properties. Plots from Experiment 1, which we do not present for brevity, are consistent with the above findings.
5. Conclusions
In this paper, we have only studied the resampling-based estimator for the Prasad–Rao formulation: further studies are needed for other choices of estimators. Considerable additional numeric studies are needed. Studies are needed, both from a theoretical as well as computational viewpoint, on the effect of the choice of a resampling-based ψ for prediction of . One interesting special case of using resampling weights that needs additional exploration is when γ tends to zero with n, as in the case discussed in Chatterjee and Bose (Citation2002).
Acknowledgments
The author thanks the reviewers and editors for their comments, which helped improve the paper.
Disclosure statement
No potential conflict of interest was reported by the author.
ORCID
Snigdhansu Chatterjee http://orcid.org/0000-0002-7986-0470
Additional information
Funding
Notes on contributors
Snigdhansu Chatterjee
Dr. Snigdhansu Chatterjee is Professor in the School of Statistics, and the Director of the Institute for Research in Statistics and its Applications (IRSA, http://irsa.stat.umn.edu/) at the University of Minnesota.
References
- Barbe, P., & Bertail, P (1995). The weighted bootstrap, volume 98 of Lecture Notes in Statistics. New York, NY: Springer-Verlag.
- Chatterjee, S. (1998). Another look at the jackknife: Further examples of generalized bootstrap. Statistics and Probability Letters, 40(4), 307–319.
- Chatterjee, S. (2018). On modifications to linking variance estimators in the Fay-Herriot model that induce robustness. Statistics And Applications, 16(1), 289–303.
- Chatterjee, S., & Bose, A. (2000). Variance estimation in high dimensional regression models. Statistica Sinica, 10(2), 497–516.
- Chatterjee, S., & Bose, A. (2002). Dimension asymptotics for generalised bootstrap in linear regression. Annals of the Institute of Statistical Mathematics, 54(2), 367–381.
- Chatterjee, S., & Bose, A. (2005). Generalized bootstrap for estimating equations. The Annals of Statistics, 33(1), 414–436.
- Chatterjee, S., Lahiri, P., & Li, H. (2008). Parametric bootstrap approximation to the distribution of EBLUP and related prediction intervals in linear mixed models. The Annals of Statistics, 36(3), 1221–1245.
- Das, K., Jiang, J., & Rao, J. N. K. (2004). Mean squared error of empirical predictor. The Annals of Statistics, 32(2), 818–840.
- Datta, G. S., Hall, P., & Mandal, A. (2011). Model selection by testing for the presence of small-area effects, and application to area-level data. Journal of the American Statistical Association, 106(493), 362–374.
- Datta, G. S., Rao, J. N. K., & Smith, D. D. (2005). On measuring the variability of small area estimators under a basic area level model. Biometrika, 92(1), 183–196.
- Efron, B. (1979). Bootstrap methods: Another look at the jackknife. The Annals of Statistics, 7(1), 1–26.
- Efron, B., & Tibshirani, R. J. (1993). An introduction to the bootstrap. Boca Raton, FL: Chapman & Hall/CRC press.
- Fay III, R. E., & Herriot, R. A. (1979). Estimates of income for small places: an application of James-Stein procedures to census data. Journal of the American Statistical Association, 74(366), 269–277.
- Hirose, M. Y., & Lahiri, P (2017). A new model variance estimator for an area level small area model to solve multiple problems simultaneously. arXiv preprint arXiv:1701.04176.
- Jiang, J., & Lahiri, P. (2006). Mixed model prediction and small area estimation (with discussion). Test, 15(1), 1–96.
- Jiang, J., Lahiri, P., & Wan, S.-M. (2002). A unified jackknife theory for empirical best prediction with M-estimation. The Annals of Statistics, 30(6), 1782–1810.
- Kubokawa, T., & Nagashima, B. (2012). Parametric bootstrap methods for bias correction in linear mixed models. Journal of Multivariate Analysis, 106, 1–16.
- Li, H., & Lahiri, P. (2010). An adjusted maximum likelihood method for solving small area estimation problems. Journal of Multivariate Analysis, 101(4), 882–892.
- Molina, I., Rao, J. N. K., & Datta, G. S. (2015). Small area estimation under a Fay–Herriot model with preliminary testing for the presence of random area effects. Survey Methodology, 41(1), 1–19.
- Pfeffermann, D. (2013). New important developments in small area estimation. Statistical Science, 28(1), 40–68.
- Pfeffermann, D., & Glickman, H. (2004). Mean square error approximation in small area estimation by use of parametric and nonparametric bootstrap. ASA Section on Survey Research Methods Proceedings, Alexandria, VA, pp. 4167–4178.
- Prasad, N. G. N., & Rao, J. N. K. (1990). The estimation of the mean squared error of small-area estimators. Journal of the American Statistical Association, 85(409), 163–171.
- Præstgaard, J., & Wellner, J. A. (1993). Exchangeably weighted bootstraps of the general empirical process. The Annals of Probability, 21(4), 2053–2086.
- Rao, J. N. K. (2015). Inferential issues in model-based small area estimation: Some new developments. Statistics in Transition, 16(4), 491–510.
- Rao, J. N. K., & Molina, I. (2015). Small area estimation. New York, NY: Wiley.
- Rubin-Bleuer, S., & You, Y. (2016). Comparison of some positive variance estimators for the Fay–Herriot small area model. Survey Methodology, 42(1), 63–85.
- Shao, J., & Tu, D. (1995). The jackknife and bootstrap. New York, NY: Springer-Verlag.
- Yoshimori, M., & Lahiri, P. (2014a). A new adjusted maximum likelihood method for the Fay–Herriot small area model. Journal of Multivariate Analysis, 124, 281–294.
- Yoshimori, M., & Lahiri, P. (2014b). A second-order efficient empirical Bayes confidence interval. The Annals of Statistics, 42(4), 1233–1261.