
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Estimates of unemployment in the UK are based on data collected in the Labour Force Survey (LFS). The data is collected continuously and the survey design is structured in such a way as to provide quarterly estimates. These quarterly estimates are published each month as ‘rolling quarterly’ estimates. Currently the Office for National Statistics (ONS) publish rolling quarterly estimates, and these have been assessed to be of sufficient quality to be badged as ‘National Statistics’. ONS also publish monthly estimates of a selection of labour force variables, but these are designated ‘Experimental Statistics’ due to concerns over the quality of these data. Due to the sample design of the LFS, monthly estimates of change are volatile as there is no sample overlap. A state space model can be used to develop improved estimates of monthly change, accounting for aspects of the survey design. An additional source of information related to unemployment is administrative data on the number of people claiming unemployment related benefits. This data is more timely than survey data collected in the LFS and can be used to provide early estimates of monthly unemployment.
1. Introduction
The Office for National Statistics publish monthly statistical bulletins on the UK labour market that include estimates of unemployment (see for example ONS, Citation2016b). For a statistical bulletin published in month t the latest available estimates of unemployment relate to the quarter covered by months t−4 to t−2, and estimates of changes for these variables look at the change from the quarter covered by months t−7 to t−5. The aim of this paper is to develop methods to improve estimates of monthly change in terms of two important quality measures, accuracy and timeliness.
The current Labour Force Survey (LFS) is designed to provide accurate quarter on quarter estimates of change due to a rotation pattern where given no non-response there is an 80 per cent overlap in respondents. There is user demand for more timely and higher frequency estimates of unemployment and possible options are considered by Steele (Citation1997). As a result of those investigations a decision was made to publish rolling quarterly estimates, as a full redesign of the survey was considered to be too expensive to implement, as described by Werner (Citation2006) who notes that the proposed monthly redesign would have cost an additional seven to eight million pounds. Therefore, while there is a regular monthly publication, the main headline data is essentially quarterly data.
The LFS is a continuous survey as respondents are interviewed each week of the year. Rather than changing the survey design an alternative option for monthly estimates is to account for the rotation pattern of the survey and derive monthly estimates from a state space model. State space models used for estimation in this paper are comprehensively discussed in texts such as Harvey (Citation1990), Durbin and Koopman (Citation2001) and Commandeur and Koopman (Citation2007). Statistics Netherlands and the Bureau of Labor Statistics in the US both use state space models for estimation of some labour force variables such as unemployment (see for example, Tiller, Citation1992; van den Brakel & Krieg, Citation2015). Other authors have explored the use of state space models using LFS data from the Australian Bureau of Statistics (ABS), such as Pfeffermann, Feder, and Signorelli (Citation1998), for the Brazilian LFS, Silva and Smith (Citation2001) and also for the UK, such as Harvey and Chung (Citation2000).
Pfeffermann et al. (Citation1998) present a method for estimating the survey error autocorrelation from time series of panel estimates, that for the UK context are called wave-specific estimates. While the correlation of the survey errors could be estimated from the survey data, as is suggested in Tiller (Citation1992) the pseudo-survey error autocorrelation method described by Pfeffermann et al. (Citation1998) does not require this. The benefit of the pseudo-survey error autocorrelation method is the simplicity of the approach as the data required for direct estimation may not be readily available. However, alternative methods could be used, including direct estimation as part of a time series model.
Harvey and Chung (Citation2000) develop bivariate state space models for estimating monthly changes in unemployment for the UK using LFS data and claimant count data (an administrative data source) with a simplified approximation for the correlation deriving it from estimated variances of levels and change. The models presented in Harvey and Chung (Citation2000) demonstrate how using the claimant count, which does not measure the same thing as unemployment, along with survey estimates of unemployment can improve estimates of change due to correlation in the error terms of the modelled population processes.
van den Brakel and Krieg (Citation2009) following the approach by Pfeffermann (Citation1991) take a multivariate approach to develop state space models for monthly unemployment in the Dutch LFS, which has a very similar sample design to that of the UK LFS. Their models are further developed in van den Brakel and Krieg (Citation2016) to include auxiliary administrative data related to unemployment, which as with Harvey and Chung (Citation2000), they find improves the precision of monthly estimates. In the multivariate time series model developed in van den Brakel and Krieg (Citation2009), monthly wave-specific design-based estimates and design-based estimates of variance are used as inputs into the model. The use of the design-based variances are to account for the changing variance over time. This is important in the UK context also, as survey months are either four or five weeks long, and therefore the sample sizes vary by month, and over time there has also been an increase in non-response.
Section 2 provides relevant information on the LFS that inform the structure of the models. Section 3 describes the methods used for estimation of the inputs into the model, and developments of the model from a simpler univariate model to more complex multivariate models that address particular issues in the data from survey error autocorrelation, potential bias, and incorporating administrative data to increase the timeliness as well as the accuracy of unemployment estimates. The models are evaluated in Section 4, while Section 5 concludes.
2. Labour force survey
The Labour Force Survey provides among other things estimates of the number of people in different categories of labour market status (employed, unemployed and inactive) for the target population of people resident in the UK. The LFS has collected data since 1973, although the survey has changed a number of times since then in terms of the data collected and also the frequency at which data is collected. Since 1992 the data collected has been essentially quarterly, although from April 1998 a monthly statistical release has been published which includes rolling-quarterly data for the variables studied here (employment, unemployment and inactivity), which is made possible due to the continuous collection. A history of the LFS can be found in ONS (Citation2016a) and Werner (Citation2006).
This section provides a brief overview of important aspects of the Labour Force Survey (LFS) that are relevant to the development of the time series models developed in later sections, in particular the LFS sample design and estimation methods which are used to create the input data (discussed further in Section 3). As one of the aims of developing models for monthly estimates is to improve their timeliness, the current publication schedule of the main LFS variables are also reviewed.
2.1. Sample design
The LFS is a quarterly survey with a rotating panel design. Respondents in a panel remain in the survey for five successive survey periods, where a survey period is composed of thirteen weeks (labeled ‘stints’, one to thirteen) and respondents asked for their labour market status in the same stint at each survey period. Any quarterly sample period covers the UK population; for samples at frequencies less than quarterly there is a clustering effect due to the survey stints. Assuming full response there should be an eighty per cent overlap in the sample at any thirteen week lag (or one quarter lag) and a twenty per cent overlap in the sample at a four quarter lag. One of the main reasons for this design is to use the sample overlap in order to reduce the variance of estimates of quarterly and annual changes. While in theory it is possible to create weekly or monthly estimates (with a month composed of either four weeks or five weeks and not a strict calendar month), given the smaller sample sizes and also the lack of sample overlap at a weekly or monthly lag, estimates of change at a frequency higher than quarterly are volatile.
As households are in the sample for five successive quarters, each quarter (month or week) it is possible to identify the number of periods the household has already been in the sample for. Grouping the data in this way wave 1 households are those that are selected for the first time, wave 2 households are included for the second time and were initially selected thirteen weeks prior to that date and so on. Therefore households in wave 5 will have been selected at four previous periods at thirteen week intervals. When drawing a sample for any particular quarter, households for waves 2 to 5 will have already been determined by the periods when they were selected to be in wave 1. The wave 1 sample is drawn using a fixed interval of a geographically ordered sampling frame. Further details of the sample design and selection can be found in ONS (Citation2016a).
At wave 1 around 17,380 households are selected for the sample. Therefore, around either five and half or six and half thousand households are selected per survey month (either four or five weeks in length). Response rates in wave 1 tend to be slightly higher at around fifty five per cent and slightly lower for subsequent waves at around forty to forty five per cent (ONS, Citation2016a, Table 3.3). Responses are requested for all eligible people in the household.
Prior to quarter three 2010, the main LFS was an equal probability sample. However, since then some modifications to the design, such as rolling forward the wave 1 responses of households where all occupants are over the age of seventy five for all subsequent waves and interviewing only one household from addresses with multiple households means that this is no longer the case. Typically responders in wave 1 are interviewed face-to-face with a computer assisted personal interview (CAPI), and in waves 2 to 5 responders are telephoned for a computer assisted telephone interview (CATI).
The important aspects of the sample design and potential for possible forms of bias due to the mode of collection are used for the development of the time series models for survey error and observed systematic differences between wave-specific estimates.
2.2. Estimation methods
Estimates of employment, unemployment and inactivity use calibrated weights that, for the sample, sum to certain known population totals. The calibration groups used for the regular rolling-quarterly data are relatively detailed due to reasonable sample size available for groups. Three calibration groups are used for the LFS including, geographical groups based on Local Authority Districts, an age by sex classification and a cross-classification using sex, age and Government Office Regions. Full details of the calibration groups used can be found in ONS (Citation2016a, Section 10). The calibration helps to deal with potential non-response bias and can also reduce the standard errors of estimators. Population totals are derived from population projections.
Where there is non-response by an individual in a particular wave a response is imputed from their response in the previous wave if a valid response was provided otherwise the case is ignored and weights are appropriately adjusted. This roll-forward imputation only occurs once. If non-response continues no imputation is done and the unit is ignored. Other than the calibration there is no additional non-response weighting in the LFS.
Estimates of accuracy are produced for the main LFS variables using a jacknife linearization method described by Skinner and Holmes (Citation2011) rather than the methods described in ONS (Citation2016a, Annex B). The jackknife estimation method is preferred by Skinner and Holmes (Citation2011) as it may deal more effectively with increases in variance due to varying survey weights.
2.3. Publications
Each month a statistical bulletin on the UK labour market is published which provides estimates of employment, unemployment, inactivity and other employment related statistics, many of which are derived from the LFS, see for example ONS (Citation2016b). The statistical bulletin starts with a section on the main points for the latest three months. The main points usually include the number of people estimated to be in employment and unemployment and how much more or less the latest three month estimate is compared to the three month period from three months previously and also a year ago. The figures presented are seasonally adjusted using the seasonal adjustment software X-13ARIMA-SEATS, Time Series Research Staff (Citation2017). The method of seasonal adjustment used is the X-11 method.
Following the main points section a summary of the latest labour markets statistics is given, which again focuses on current level of variables, rates and also changes on previous periods (essentially quarterly and annual changes). Further on in the bulletin more detailed analysis of the variables is provided, for example, plots of the seasonally adjusted estimates over time with additional commentary.
Towards the end of the bulletin there is a section on accuracy of the estimates, which provides links to data sets on sampling variability with confidence intervals for estimates of levels, rates and changes. It should be noted that the estimates of sampling variability are for the non-seasonally adjusted series rather than the seasonally adjusted estimates that form the main headline figures. Standard errors for seasonally adjusted estimates are not published.
A separate article is published each month for experimental single month LFS estimates, for example see ONS (Citation2017). The article stresses that due to the small sample sizes and no sample overlap the estimates of monthly change are not reliable estimates of current trends in the labour market. The stated main purpose of the single month estimates is to help interpret movements in the headline three-month average rolling quarterly data. As such the single month estimates are benchmarked to the rolling quarterly data and charts included in the article compare the single month with the three-month moving average data.
3. Methods
Estimation of the underlying parameters of interest involves initial estimates of input data for the model followed by the use of a time series model. The input data for the model include design-based monthly wave-specific estimates of unemployment and estimated variances and also estimates of the sample error autocorrelation. Time series models use the wave-specific estimates and their associated variances as input data for the models. The sample error autocorrelation can either be estimated as a hyperparameter in the model, or derived prior to the model using a design-based estimate or the pseudo-survey error autocorrelation approach of Pfeffermann et al. (Citation1998). The models assume that the observed time series are comprised of unobserved components that are estimated with the Kalman filter in the state space framework.
3.1. Input data
Wave-specific time series are estimated using a simplified version of the calibration weighting used for the published rolling-quarterly data. Wave-specific estimates have been estimated from January 2002 onwards, due to the ease of access of the sample data. The wave-specific estimates can be averaged to provide single month time series. It should be noted that the averaged monthly wave-specific estimates differ slightly to the published single month estimates as the method of estimation differs. Information on the current methods for single month estimates can be found in ONS (Citation2017). The sample at any time period less than a quarter is clustered. The variance estimation for the single month wave-specific estimates is done using the linearized jacknife estimator of Skinner and Holmes (Citation2011) accounting for the clustering, stratification and calibration.
Due to the rotation pattern of the LFS, where in theory there should be an eighty per cent overlap in respondents between a survey reference week τ and survey reference week , there is expected to be a correlation structure to the sampling error. The sampling error autocorrelation of an estimator
from the LFS, is
(1)
(1) Monthly and quarterly estimates are averages of weekly estimates. A quarterly estimate is the average of a thirteen week period, while a monthly estimate is an average of either a four or five week period with three monthly estimates comprising a quarter following a four week plus four week plus five week pattern. If
is an average of weeks
to
then if we assume that the sampling errors follow a stationary process with
and
then for monthly or quarterly estimates as
and only considering lags
(that is to say not considering overlapping rolling periods),
(2)
(2) The expected value of
given no non-response and where there is no change in employment status for those respondents responding at τ and
is given by the proportion of sample overlap at
;
. In practice there is non-response and the methods used for imputation as well as the probability of changing employment status between any two periods will mean that the estimated correlation is unlikely to be the theoretical sample overlap. Nevertheless, we may expect to see higher correlation in variables such as employment and inactivity, compared to unemployment, depending upon the labour market conditions. For example, those defined as unemployed should be actively seeking work, and they may be more likely to change labour market status than those who are employed, or those who are inactive (not actively seeking employment).
Pfeffermann et al. (Citation1998) describe a method of estimating what they term pseudo-survey error autocorrelations. Correlation is calculated not directly from the sample data but from the estimated panel time series, that in this paper are referred to as wave-specific estimates. While we can calculate the pseudo-survey error autocorrelation for the series, , at lags
it is also possible to estimate the cross correlation between wave-specific time series. For example, we may expect zero correlation at negative lags between the wave 1 sampling errors and other waves as this is the first time that those panel members are included in the sample. We would expect a correlation between wave 2 and wave 1 sampling errors at lags of three months due to the expected eighty per cent sample overlap, a slightly lower correlation between wave 3 and wave 1 sampling errors at lags of six months due to the expected sixty per cent over lap and so on. These pseudo-cross correlations will be used in the development of the multivariate time series models.
The Pfeffermann et al. (Citation1998) method of estimating the pseudo survey error autocorrelation includes terms to address potential rotation group bias, whereby wave-specific time series may have a bias in the level, which could be due, for example, to the mode of data collection.
3.2. Time series models
Three models are compared; a univariate basic structural model of a single month estimate, accounting for survey error autocorrelation and a changing variance over time, a multivariate model using only wave-specific monthly data from the LFS, and an extension to this multivariate model that incorporates an administrative data source related to unemployment called the claimant count. A brief description of the models is given in this section with details on model specification in state space form provided in Appendix. Common to all of the models explored, it is assumed that the population process, , follows a basic structural model given by Equation4
(4)
(4) , that allows for stochastic trend, stochastic seasonal and noise. Models for the survey errors are developed to account for the changing variance over time and also for the survey error correlation. For all models a generalised representation is given, but Section 4 assesses restrictions on the models, to test whether certain variables are required and whether a more parsimonious model is sufficient.
All models have been fitted using the KFAS package (Helske, Citation2017) in R (R Core Team, Citation2016). Non-stationary components have diffuse initialization of the Kalman filter, while the unobserved states for the sampling errors have a non-diffuse initialization with mean zero and variance of one. Hyperparameters for the models are estimated using maximum likelihood with the quasi-Newton method BFGS from the optim function in R. Uncertainty arising from the replacement of the unknown true hyperparameters with estimates from maximum likelihood are not accounted for in the standard errors of the estimated unobserved components.
3.2.1. Univariate model
Monthly wave-specific estimates, , for
, have independent samples at time
across waves
, so can be averaged to give a single month estimate,
. It is assumed that this is comprised of an unobserved population process,
, and an autocorrelated survey error process,
. The survey error is modelled as an AR([3]) process, which denotes an autoregressive process of order three where the coefficients on lag one and two are equal to 0. Design-based variance estimates,
, are also used as input data for the model to account for changing variance over time, in a similar way to the multivariate model discussed in van den Brakel and Krieg (Citation2009).
(3)
(3) where the population process follows a basic structural model given by
(4)
(4) with the trend component,
given by
(5)
(5)
(6)
(6) the seasonal component by
(7)
(7) where for
and for j = 6
with
and
uncorrelated, and unless otherwise specified
for all
.
The irregular component is given by
(8)
(8) and the survey error, assuming an AR([3]) process as
(9)
(9) For the purpose of estimation in the state space framework a similar approach to that introduced by Pfeffermann (Citation1991) and also described by van den Brakel and Krieg (Citation2009) is used where
, which leads to
(10)
(10) where an estimate of
should be approximately equal to 1.
Alternative models for the error or population processes could also be experimented with. Under the assumption that any rotation group bias is approximately constant across time estimating the correlation with a univariate model should not be a problem as any bias should only effect the average level of the time series estimates. Note that can either be estimated as part of the model, or be estimated using the pseudo-survey error autocorrelation approach or directly from the survey data.
3.2.2. Multivariate model
The multivariate model using only LFS data assumes that the five wave-specific monthly estimates, for
, are comprised of the common stochastic population process,
, and wave-specific survey errors,
. For this model the wave-specific survey error terms are assumed to be comprised of a rotation group bias term, and sampling error which accounts for correlation in the error terms due to sample overlap. The rotation group bias terms are introduced as the observed wave-specific time series differ in level. Given no compelling evidence that the current level of variables are biased the model for the bias terms assumes that the wave-specific bias terms sum to zero.
Wave-specific design-based variance estimates, for
, are also used as input data for the model to account for changing variance over time, as discussed in van den Brakel and Krieg (Citation2009). The multivariate model is
(11)
(11) where
(12)
(12)
(13)
(13)
(14)
(14)
(15)
(15) Note that in the models
is estimated and should be approximately equal to 1 and with
, therefore
and
.
The model for the wave-specific error is comprised of a wave specific bias term, , which in this case we have assumed sums to zero over all waves, and a wave-specific sampling error. Part of the reason for this assumption is that this is the implicit assumption in the current method of estimation for rolling-quarterly data as no adjustment is made to data for particular waves and the estimator is not considered to be biased. This differs from the assumption made by van den Brakel and Krieg (Citation2009) where wave one is assumed to have no bias and all subsequent waves have a potential bias due to systematic differences in the levels of wave-specific estimates. Alternative models for bias could be considered as discussed in Elliott, Zong, Greenaway, Lacey, and Dixon (Citation2015), which provides some limited evidence that wave one estimates are not found to be biased for the UK. However, it is not possible to conclude from this that other waves are biased and so it is assumed that the bias sums to zero across all waves. The wave specific sampling error,
, follows an AR([3]) process which leads to
. For the purpose of estimation in the state space framework accounting for the design-based variances,
, the same approach as described by van den Brakel and Krieg (Citation2009) is used where
, which leads to
(16)
(16) where again estimates of
should be approximately equal to 1 for all
.
3.2.3. Multivariate model with claimant count
The multivariate model can be developed further, by incorporating additional administrative data that relates to the variable of interest, which is a similar extension performed by Harvey and Chung (Citation2000) in developing a bivariate model. For example, claimant count data is a measure of those claiming out of work benefits, and while it is not a measure of unemployment based on ILO definitions there is the potential to gain additional accuracy in monthly changes by benefiting from any correlation in unobserved components as shown by Harvey and Chung (Citation2000) for the case of a bivariate model. The multivariate model presented above can be extended to include observed claimant count data as part of the vector of observations .
If it is assumed that follows a basic structural model (not the common population process for
) then covariance terms for the errors in the trend and seasonal components can be incorporated to capture similar movements in the series. To distinguish between population process parameters for unemployment (
) and claimant count, superscript
is used. Hence, Equation (Equation4
(4)
(4) ) for claimant count is given by
(17)
(17) Any relationship between the population process for unemployment and claimant count is based on the covariance in error terms,
,
,
, and
,.
4. Results
4.1. Survey error autocorrelation
Figure shows the estimated pseudo-survey error autocorrelations and partial autocorrelations for each variable using UK data. Due to the periods of sample overlap, in the following descriptions a lag of l should be read as a lag of months. The estimate of autocorrelation at lag 1 (three months) from the pseudo-survey error autocorrelation approach is 0.46. Similar values are obtained by estimating it as a hyperparameter in a univariate state space model (0.4) and the approximation from quarterly design-based variance estimates (0.42). This approximation from design-based estimates uses the approximation in Harvey and Chung (Citation2000) where
. The patterns in the autocorrelation and partial autocorrelations are typical of an autoregressive process of order 1. It should be noted that estimating φ in the univariate model, or using the approximation from design-based estimates does not account for any rotation group bias. For this reason the multi-variate models use the pseudo-survey error autocorrelation. The alternatives methods in the univariate models are presented only to demonstrate the similarities in the estimates.
Figure 1. Pseudo-survey error autocorrelation and partial autocorrelation for UK unemployment ages 16 and over. Note a lag of one is three months as there is no sample overlap between month, so lag , corresponds to a lag of
months.
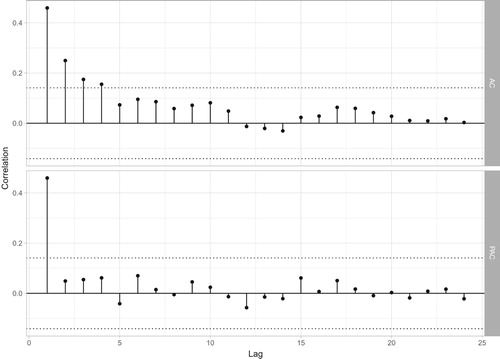
Table shows estimates of wave-specific correlation. There is some evidence of correlation between waves two to five and wave one at the appropriate lag. The correlation between waves is not as high as suggested by sample overlap, which is not surprising as part of the definition of unemployment is actively seeking work. If similar calculations are done for employment or inactivity variables, the correlation tends to be greater. Note when the correlations are calculated on moving windows they are relatively stable over time.
Table 1. Pseudo survey error correlations for unemployment 16 plus by wave. Correlation at lag  for wave is .
for wave is .
4.2. Univariate models
Table shows estimated hyperparameters for variations on the univariate model, while Table presents standard diagnostics for these models. Other variations on model 1 were also tested but have not been included in the results (these included testing models that included variance parameters and
neither of which gave improvements to the models in Table ). There is no evidence of lack of normality, heteroscedasticity or autocorrelation in the standardised one-step ahead forecast errors. AIC suggests a model without variance terms for the level or seasonal is preferred. Much of the volatility in the unemployment series is due to the sampling error, and seaosnality is not particularly strong in the series, although it appears to be stable.
Table 2. Estimated hyperparameters for variations on model 1 (univariate) for UK unemployment aged 16 and over.
Table 3. Diagnostics based on standardised one-step ahead forecast errors for variations of the univariate model of UK unemployment aged 16 and over including skewness (S), kurtosis (K), Bowman and Shenton test for normality (N), test for Heteroscedasticity (H(h), h indicates sample size), lags that are found to be significant at the 5% level using a Ljung-Box Q(k) test for serial correlation at lag k. See Durbin and Koopman (Citation2001, Section 2.12.1) for test details.
A univariate model was also tested for the claimaint count series to help test subsequent extensions to the multivariate model. The claimant count series follows a similar path to the unemployment data, but is siginficantly less volatile, and seasonality is more evident. Moreover, there is a steeper rise in claimant count than unemployment going into the Great Recession in particular the October 2008 to February 2009 period which causes significant problems for the model in terms of lack of normality, and residual autocorrelation. A sequential step-indicator saturation approach similar to Hendry, Doornik, and Pretis (Citation2013) is used to identify shifts in the level of the series, which can be implemented as j impulse indicator variables () in the state equation for the trend component such that
(18)
(18) and coefficients
are the magnitude of the level shifts. The variables
are selected by testing the significance of the estimated coefficients by saturating the first half of the sample, followed by the second half of the sample, and then a sequential selection retaining only those variables that are found to be statistically significant at the 0.1% level. This step-indicator saturation approach indientified level shifts at October 2008 (of magnitude 48,234), November 2008 (40,206), January 2009 (104, 929) and February 2009 (31,944). Table shows the improvements in the model diagnostics from including the level shift variables.
Table 4. Diagnostics based on standardised one-step ahead forecast errors for the univariate models of claimaint (without level shift variables, model 1d and with level shift variables, model 1e) including skewness (S), kurtosis (K), Bowman and Shenton test for normality (N), test for Heteroscedasticity (H(h), h indicates sample size), lags that are found to be significant at the 5% level using a Ljung-Box Q(k) test for serial correlation at lag k. See Durbin and Koopman (Citation2001, Section 2.12.1) for test details.
The seasonality in the claimaint count series is not as stable as that found in the unemployment series. In order to capture the nature of the evolving seasonality sufficiently, frequency-specific seasonal variances are required, as described in Hindrayanto, Aston, Koopman, and Ooms (Citation2013). Based on model selection using AIC, frequency-specific variances include where
and
, in
indicate the seasonal frequencies that have been grouped. Further investigations of alternative models for capturing seasonality in the claimant could would be interesting, as it is a stock recorded on the second Thursday of a calendar month, but are not pursued here as the focus is unemployment, and the model for our purposes is sufficient.
4.3. Multivariate models
A similar model selection process to that used for the univariate model was used to identify variance parameters to include in a multivariate model for wave-specific estimates of unemployment, with the wave-specific correlation parameters estimated using the pseudo-survey error autocorrelation approach. The model is then estimated including the claimant count model described in the univariate results section and compared to alternative models that account for possible correlation between the population process for unemployment and claimant count. Three variations of the multivariate model are compared and the hyperparameters and AIC for each are given in Table .
Table 5. Estimated hyperparameters for multivariate models: model 2 (independence between unemployment and claimant count), model 3 (covariance terms for both level and slope errors) and model 4 (covariance between slope error terms only) of UK unemployment aged 16 and over and claimant count.
Model 2 treats the multivariate model for unemployemnt and the model for claimant count as independent, whereas model 3 and 4 include covariance terms. Note that in order to test for correlation between the error terms in the irregular component () the population irregular variance for the claimant count (
) has been moved into the state equation. The addition of covariance terms improves the model, but there is not strong evidence for including covariance terms for both the irregular and the slope. Similarly variance and covariance terms for other components have been tested and are not required. The AIC for model 3 and model 4 are very similar. However, using a likelihood ratio test there is no evidence that inclusion of the additional terms in model 3 is an improvement over model 4, and therefore a covariance term for the slope error terms only is included with an estimated correlation of 0.97.
Table shows diagnostics for the standardised residuals of the multivariate model including claimant count (model 4) which suggests some slight evidence of heteroscedasticity in waves 2 to 3, some evidence of lack of normality for wave 2 and some residual autocorrelation for lags 18 to 24 for wave 1 and lags 21 to 24 in the claimant count. A plot of the cross-correlation of the residuals does not show any strong evidence of correlation at any lags between the different waves and the Doornik-Hansen test for multivariate normality on the standardised residuals from model 4 has a value of 13.61 (p-value of 0.33). Diagnostics for models 2 and 3 are very similar and so are not included here.
Table 6. Diagnostics for model 4 (multivariate) of UK unemployment aged 16 and over including claimant count for skewness (S), kurtosis (K), test for normality (N), test for Heteroscedasticity (H(h)), and lags k for which Ljung-Box Q(k) is significant at the 5% level from the first 24 lags. See Durbin and Koopman (Citation2001, Section 2.12.1) for test details.
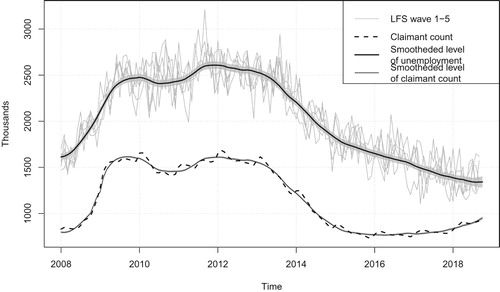
Figure shows the wave-specific estimates for unemployment along with claimant count. The wave-specific estimates are more volatile than published rolling-quarterly data due to the smaller sample sizes. The claimant count is significantly smoother, and the seasonality is more evident. The level of the claimant count is lower than the estimates for unemployment (not all people who are defined as unemployed using the International Labour Organization definition are eligible to claim benefits), but follows similar movements in the trend. Figure also shows the smoothed estimates of the level of unemployment, (note that
, although survey data is only available to September 2018) and claimant count (
), from multivariate model 4, including claimant count, which as shown by the prediction interval provides a more accurate estimate of the underlying level of unemployment than using wave specific estimates.
Figure 2. LFS wave-specific estimates and smoothed estimate of the level of UK unemployment ages 16 and over from a multivariate model (model 4) including claimant count (grey shaded area is a ninety five percent prediction interval), and level of claimant count.
In a regular publication schedule for monthly data, there is often greater user interest in the latest estimates of change. With smoothed estimates, these will be revised for historical data as new input data become available. Therefore, in order to give an indication of the accuracy of estimates of change from the perspective of a regular monthly publication, the filtered estimates of change are examined. Figure shows the filtered estimate of monthly change in unemployment from the multivariate model 4 which includes claimant count, and shows the gain in accuracy for estimates of change. Using filtered estimates of change in the level of the population process, , much of the time for the period from 2008 onwards monthly change is not significantly different from zero at the five percent level. However, by August 2008 the filtered estimate of the level shows three consecutive periods of monthly increases that are significantly different from zero at the five per cent level. If seasonally adjusted single month estimates were used then there are no periods since 2008 where there are three consecutive monthly increases (or decreases) that are significantly different from zero at the five percent level (using the non-seasonally adjusted standard error as an approximate standard error for the seasonally adjusted series). It is interesting to note that using the rolling-quarterly data three consecutive periods of significant increases are observed a month later in September 2008, suggesting that the modelled single month estimates may be useful for more timely detection of turning points.
Figure 3. Month on month change for LFS single month estimate (seasonally adjusted) and filtered estimate of change of UK unemployment ages 16 and over from a multivariate model including claimant count (grey shaded area is a ninety five percent prediction interval), and monthly change in claimant count (seasonally adjusted).
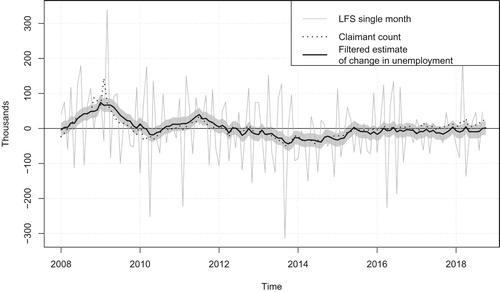
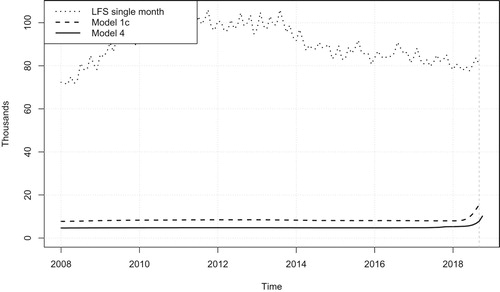
Figure shows the gain in accuracy of the different models compared to the single month estimates. The inclusion of claimant count into the model improves the estimated accuracy of the change in the level component for unemployment. This is due to the correlation in the error terms for the slope components of unemployment and the claimant count. In Figure the multivariate model provides an estimate one month ahead of the univariate model as survey data is not yet available and therefore the estimate from the Kalman filter for the multivariate model borrows some strength from the claimant count which is available one period on from current single month LFS data.
Figure 4. Standard errors of smoothed change in trend from univariate model (model 1c), multivariate model including claimant count (model 4) and original single month, of UK unemployment aged 16 plus.
5. Conclusions
The aim of using time series models is to improve the accuracy and timeliness of single month estimates of unemployment. A simple univariate model that accounts for the survey error autocorrelation structure makes an improvement in accuracy and increases the timeliness compared to the published rolling-quarterly data by one month. Further improvements in accuracy can be gained by using a multivariate model that accounts for both the survey error autocorrelation as well as rotation group bias. An extension to the multivariate model that includes claimant count also improves the accuracy further and also enables an arguably improved one-step ahead forecast of unemployment by drawing on the relationship between unemployment and the claimant count, which would provide an estimate of the level two months ahead of the current rolling-quarter. The gain in accuracy from all models, but particularly the multivariate models, improves the estimates of monthly change which can provide a more timely detection of turning points.
It is interesting to note that there appears to be very little gain in accuracy when extending the univariate model to a multivariate model excluding claimant count, with the larger gains in accuary occuring when claimant count is included. A more parsimonious model, that still benefits from the inclusion of the claimant count might therefore be a bivariate model of unemployment and claimant count as presented in Harvey and Chung (Citation2000). This has not been explored in the current set of models as there is interest from some users and producers of the data in analysing the wave-specific series, and a multivariate model enables a decomposition of this data.
While the inclusion of claimant count appears promising, further research is required on possible discontinuities in the data that have not been picked up in the indicator saturation approach or analysis of the model residuals, as there has been a change to the administration of unemployment related benefits, which might explain the apparent closing of the gap between the average level of unemployment and claimant count.
Common to many of the papers cited throughout this paper, is the assumption that the population process to be measured follows a basic structural model and the sensitivity of this assumption and the implications for estimation of the survey error would be interesting to explore. Some of the papers attempt to deal with changing design-based variance, such as van den Brakel and Krieg (Citation2009), with the assumption that the stochastic nature of the population process itself is not. Depending upon the periods over which the data is analysed, again this may or may not be true and could be difficult to assess what is changes in variance in the survey error and what is changes in variance due to the population process. As noted in the response to Harvey and Chung (Citation2000) by Benoit Quenneville there is the danger than too much of the total variance is assumed to belong to the survey error.
As with many of the papers we find that there is a gain in precision from using the time series model. However, these do not allow for the uncertainty in the maximum likelihood estimates which if accounted for could reduce the impact of such estimated gains. An alternative method that would account for this uncertainty could be to use a Bayesian approach, or a replication technique for estimating the additional uncertainty, as explored for example by Pfeffermann and Tiller (Citation2005).
Acknowledgments
Thanks to two anonymous referees who provided detailed and constructive comments on an earlier submission. Thanks to Danny Pfeffermann for constructive conversations on developing the models. Thanks also to Bethan Russ, Alastair Cameron, Greg Dixon, and Matthew Greenaway for their contributions to providing the wave-specific monthly estimates and variances used as input data for all the modelling.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Notes on contributors
D. J. Elliott
D. Elliott and P. Zong are methodologists at the Office for National Statistics in the UK.
P. Zong
D. Elliott and P. Zong are methodologists at the Office for National Statistics in the UK.
References
- Commandeur, J., & Koopman, S. (2007). An introduction to state space time series analysis. Oxford: OUP.
- Durbin, J., & Koopman, S. (2001). Time series analysis by state space methods. Oxford: Clarendon Press.
- Elliott, D., Zong, P., Greenaway, M., Lacey, A., & Dixon, G. (2015). A state space model for labour force survey estimates: Agreeing the target and dealing with wave specific bias.
- Harvey, A. (1990). Forecasting, structural time series models and the kalman filter. Cambridge: Cambridge University Press.
- Harvey, A., & Chung (2000). Producing monthly estimates of unemployment and employment according to the international labour office definition (with discussion). Journal of the Royal Statistical Society Series A, 160, 5–46.
- Helske, J. (2017). KFAS: Exponential family state space models in R. Journal of Statistical Software, 78(10), 1–39. doi: 10.18637/jss.v078.i10
- Hendry, D., Doornik, J. A., & Pretis, F. (2013, June). Step-indicator saturation.
- Hindrayanto, I., Aston, J. A., Koopman, S. J., & Ooms, M. (2013). Modelling trigonometric seasonal components for monthly economic time series. Applied Economics, 45(21), 3024–3034. Retrieved from https://doi.org/10.1080/00036846.2012.690937
- ONS (2016a). Labour force survey user guide: Volume 1 - lfs background and methodology 2016. Retrieved from https://www.ons.gov.uk/file?uri=/employmentandlabourmarket/peopleinwork/employmentandemployeetypes/methodologies/labourforcesurveyuserguidance/volume12016.pdf
- ONS (2016b). Uk labour market: Nov 2016. Retrieved from https://www.ons.gov.uk/employmentandlabourmarket/peopleinwork/employmentandemployeetypes/bulletins/uklabourmarket/november2016/pdf
- ONS (2017). Single month labour force survey estimates: Jan 2017. Retrieved from https://www.ons.gov.uk/employmentandlabourmarket/peopleinwork/employmentandemployeetypes/articles/singlemonthlabourforcesurveyestimates/jan2017/pdf
- Pfeffermann, D. (1991). Estimation and seasonal adjustment of population means using data from repeated surveys. Journal of Business & Economic Statistics, 9, 163–175.
- Pfeffermann, D., Feder, M., & Signorelli, D. (1998). Estimation of autocorrelations of survey errors with application to trend estimation in small areas. Journal of Business & Economic Statistics, 16, 339–348.
- Pfeffermann, D., & Tiller, R. (2005, November). Bootstrap approximation to prediction mse for state-space models with estimated parameters. Journal of Time Series Analysis, 26, 893–916. doi: 10.1111/j.1467-9892.2005.00448.x
- R Core Team (2016). R: A language and environment for statistical computing [Computer software manual]. Vienna, Austria. Retrieved from https://www.R-project.org/
- Silva, D., & Smith, T. (2001). Modelling compositional time series from repeated surveys. Survey Methodology, 27(2), 205–215. Retrieved from http://uos-app00353-si.soton.ac.uk/30037/
- Skinner, H., & Holmes, D. (2011). Variance estimation for Labour Force Survey estimates of level and change: GSS Methodology Series 21. Retrieved from http://www.ons.gov.uk/ons/guide-method/method-quality/specific/gss-methodology-series/index.html
- Steele, D. (1997). Producing monthly estimates of unemployment and employment according to the international labour office definition (with discussion). Journal of the Royal Statistical Society Series A, 160, 5–46. doi: 10.1111/1467-985X.00044
- Tiller, R. (1992). Time series modeling of sample survey data from the US current population survey. Journal of Official Statistics, 8(2), 149–166.
- Time Series Research Staff (2017). X-13arima-seats reference manual [Computer software manual]. Washington DC, US. Retrieved from https://www.census.gov/ts/x13as/docX13AS.pdf
- van den Brakel, J. A., & Krieg, S. (2009, February). Estimation of the monthly unemployment rate through structural time series modelling in a rotating panel design. Survey Methodology, 35, 177–190.
- van den Brakel, J. A., & Krieg, S. (2015, December). Dealing with small sample sizes, rotation group bias and discontinuities in a rotating panel design. Survey Methodology,, 41, 267–296.
- van den Brakel, J. A., & Krieg, S. (2016). Small area estimation with state space common factor models for rotating panels. Journal of the Royal Statistical Society: Series A (Statistics in Society), 179(3), 763–791. Retrieved from https://rss.onlinelibrary.wiley.com/doi/abs/10.1111/rssa.12158
- Werner, B. (2006). Reflections on fifteen years of change in using the labour force survey. Retrieved from http://www.ons.gov.uk/ons/rel/lms/labour-market-trends–discontinued-/volume-114–no–8/reflections-of-fifteen-years-of-change-in-using-the-labour-force-survey.pdf?format=hi-vis
Appendix. State space models
This appendix provides details of the structure of the univariate and multivariate state space model. State space models enable the estimation of unobserved components of univariate and multivariate time series. The models developed in this paper aim to estimate an underlying stochastic population process and survey error processes, all of which are unobserved. The models used are linear Guassian models.
A.1. State-space framework
The state space framework is comprised of an observation equation and transition equation. The observation equation shows how the unobserved components combine to form the observed values, while the transition equation shows how the unobserved components evolve over time following a first-order Markov process. Following the notation of Harvey (Citation1990) and simplifying slightly to only show aspects that are relevant to the current study the observation and transition equation are respectively
(A1)
(A1) and
(A2)
(A2) where
(A3)
(A3)
(A4)
(A4) The observations,
, may be a multivariate time series with T elements. The state vector of unobserved components is given by
with dimension
. The observation matrix which combines the unobserved components,
is of dimension
and the observation errors,
, is an
vector. In the transition equation,
is the
transition matrix which defines how that state vector changes over time,
is an
matrix determining which elements in the state vector are stochastic, and the transition error,
is an
vector.
,
,
,
and
are system matrices that are non-stochastic. However they may change over time, hence the time subscript and can contain estimated values, for example the hyperparameters. For details on the estimation of unobserved components using the Kalman filter and methods for hyperparameter estimation see for example Harvey (Citation1990), Durbin and Koopman (Citation2001) or Commandeur and Koopman (Citation2007).
The models in this paper are estimated using the KFAS package of Helske (Citation2017) in the software R, R Core Team (Citation2016). The optimiser used in R from the function optim provides various methods of optimization based on Nelder-Mead, quasi-Newton and conjugate-gradient functions. In this paper BFGS (a quasi-Newton method) is used.
A.2. Univariate model
The basic structural model (Equation (Equation4(4)
(4) )) includes models for the trend (Equation (Equation5
(5)
(5) )) and seasonal component (Equation (Equation7
(7)
(7) )), an irregular component as white noise (Equation (Equation8
(8)
(8) )) and sampling error (Equation (Equation9
(9)
(9) )).These equations can be expressed in state space form for monthly data following a similar notation to van den Brakel and Krieg (Citation2009) where
is a matrix of dimension
where each element is equal to
,
is an
identity matrix,
creates a diagonal matrix from the elements in parentheses, while
creates a block diagonal matrix from the elements in parentheses. The model is composed of a population process (θ) and sample error part (e), with the state vector and system matrices given by
(A5)
(A5)
(A6)
(A6)
(A7)
(A7)
(A8)
(A8)
(A9)
(A9)
(A10)
(A10)
(A11)
(A11)
(A12)
(A12)
(A13)
(A13)
(A14)
(A14)
(A15)
(A15)
(A16)
(A16)
(A17)
(A17)
(A18)
(A18) Design-based variance estimates,
can be used to account for the changing variance over time as discussed by van den Brakel and Krieg (Citation2009) and used to help obtain estimates of the sampling error.
(A19)
(A19)
(A20)
(A20)
(A21)
(A21)
(A23)
(A23)
A.3. Multivariate model
When the observed design-based estimates are monthly wave-specific estimates and assuming the wave-specific survey error and bias terms are combined with the basic structural model and combining with claimant count allowing potentially for correlation, a multivariate state space model can be specified for with the state vector and system matrices are given by
(A24)
(A24)
(A25)
(A25)
(A26)
(A26)
(A27)
(A27)
(A28)
(A28)
(A29)
(A29) where
(A30)
(A30)
(A31)
(A31)
(A32)
(A32)
(A34)
(A34)
(A35)
(A35)
(A36)
(A36)
(A37)
(A37)
(A39)
(A39)
(A41)
(A41)
(A42)
(A42)
(A43)
(A43) Note that the multivariate model includes the population irregular term for the claimant count in the observation error. In the paper when correlation is tested between population irregular components, then the system matrices are modified and the irregular moved to the state vector, and an irregular term for the unemployment population process is also included in the state vector. Note also that no covariance terms are included for the seasonal components of unemployment and claimant count in the above equations, as there was no evidence that this was required, but this is also a straigtforward modification to the system matrices.