
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With increasing appearances of high-dimensional data over the past two decades, variable selections through frequentist likelihood penalisation approaches and their Bayesian counterparts becomes a popular yet challenging research area in statistics. Under a normal linear model with shrinkage priors, we propose a benchmark variable approach for Bayesian variable selection. The benchmark variable serves as a standard and helps us to assess and rank the importance of each covariate based on the posterior distribution of the corresponding regression coefficient. For a sparse Bayesian analysis, we use the benchmark in conjunction with a modified BIC. We also develop our benchmark approach to accommodate models with covariates exhibiting group structures. Two simulation studies are carried out to assess and compare the performances among the proposed approach and other methods. Three real datasets are also analysed by using these methods for illustration.
1. Introduction
Over the past two decades, with advanced data collection techniques, a large amount of high-dimensional data continues to appear in various biological, medical, social, and economical studies. A typical example is the microarray data, where thousands or even millions of genes are involved in the data collection but only as few as hundreds or even fewer sampled subjects are available. Researchers believe that the majority of the genes are redundant and only a small subset is useful to predict the response of interest. Hence, it is desired to eliminate the unrelated genes and select important ones, for more accurate prediction as well as better interpretation. Such high-dimensional problems in practice impose great challenge to statistical analysis and motivate various variable selection techniques.
Lots of attempts have been made to solve these problems by regularisation methods, which achieve parameter estimation and variable selection simultaneously, mainly via frequentist approaches. These methods typically involve adding a penalty term on regression coefficients to the loss function, with the purpose of either parameter estimator variance stabilisation or variable selection; see, for example, the ridge regression by Hoerl and Kennard (Citation1970), lasso by Tibshirani (Citation1996), smoothly clipped absolute deviation (SCAD) by Fan and Li (Citation2001), elastic net by Zou and Hastie (Citation2005), fused lasso by Tibshirani et al. (Citation2005), adaptive lasso by Zou (Citation2006), COSSO by Lin and Zhang (Citation2006), SICA by Lv and Fan (Citation2009), MCP by Zhang (Citation2010), truncated L1 by Shen et al. (Citation2011), SELO by Dicker et al. (Citation2011), and references therein.
On the other hand, variable selection via Bayesian approaches is also very active, started with the well-known Bayesian information criterion (BIC) (Schwarz,Citation1978). There exist three types of commonly used Bayesian approaches in variable selection. The first type works on information criterion, such as the BIC and its improvement PBIC proposed by Bayarri et al. (Citation2019). The second type includes the indicator model selection (see, for example, Brown et al., Citation1998; Dellaportas et al., Citation1997; George & McCulloch, Citation1993; Kuo & Mallick, Citation1998; Yuan & Lin, Citation2005), the stochastic search method (e.g., O'Hara & Sillanpää, Citation2009), and the model space method by Green (Citation1995). The third type, which is considered in the current paper, is to apply priors on the regression coefficients that promotes the shrinkage of coefficients towards 0. This last type of approaches is intrinsically connected with frequentist methods in the sense that such priors play the same role as the assumption that the coefficients are sparse for the frequentist approach. Typical examples of this type include the Bayesian lasso (Park & Casella, Citation2008) and Bayesian counterparts for elastic net, group lasso, and fused lasso (Kyung et al., Citation2010).
The shrinkage prior approach, however, does not provide sparse estimates of regression coefficients in general. A Bayesian analysis based on a subset of covariates with size considerably less than the original dimensionality, which is referred to as sparse Bayesian analysis, may produce better results than the Bayesian analysis based on all covariates. Several attempts have been made to obtain sparse Bayesian estimates based on shrinkage priors. For instance, Hoti and Sillanpää (Citation2006) proposed a method based on thresholding; however, the method is based on certain approximations and the choice of threshold is ad hoc. Another example is the sparse Bayesian learning by Tipping (Citation2001), but it involves complicated nonconvex optimisation and assumes that the variance of the error term is known.
Under the framework of shrinkage priors, in this paper, we propose a Bayesian variable selection in a normal linear model via a benchmark variable that serves as a standard and helps us to assess and rank the importance of each covariate based on the posterior distribution of the corresponding regression coefficient. For a sparse Bayesian analysis, we propose a variable selection using benchmark in conjunction with a modified BIC. Furthermore, we develop our benchmark approach to accommodate normal linear models with covariates exhibiting group structures. An additional step is implemented to identify important individual variables within the selected groups. Some simulation studies are carried out to assess and compare the performances among the proposed approach and other methods. Three real datasets are also analysed by using these methods for illustration.
2. Methodology
Let be an n-dimensional vector of responses and, without loss of generality, let
be p centralised n-dimensional vectors of covariates. Conditional on
,
is assumed to be distributed as multivariate normal
, where
,
denotes the transpose of
,
are p + 1 unknown parameters, σ is an unknown positive parameter,
is the n-dimensional vector with all components 1, and
is the identity matrix of order n. Note that components of
can be individual covariate vectors as well as vectors having interaction effects on
such as product terms and, hence, components of
are main effects and interaction effects.
There are various choices of priors that shrink the regression coefficients, components of , towards 0. The most popular one is the Laplace prior considered by Park and Casella (Citation2008) for their Bayesian lasso:
(1)
(1) where
is a hyperparameter. For
and
that are not involved with variable selection, we consider noninformative priors, i.e., the prior of
is the Lebesgue measure and the prior of
has improper density
.
2.1. Benchmark
If the posterior distribution of is nearly the same as that from a noise variable centred at 0, then it is natural to eliminate
as an unimportant covariate. However, the question is how to quantify whether a posterior distribution to be close to that of a noise.
To illustrate our idea, let us first consider an artificial case where a covariate exists and is known to have no effect on
, i.e.,
conditioned on
is distributed as
with
. Although we know
is redundant, we still put a prior on
such that
and
's are independently identically distributed conditioning on
. Under this setting,
could be treated as an unimportant variable if the posterior of
is similar to the posterior of
. In other words, the variable
serves as a benchmark in measuring the importance of
's.
To be more rigorous, a nonzero vector is defined as a valid benchmark if it satisfies the following two conditions:
| (C1) | The posterior distribution of | ||||
| (C2) | The posterior distribution of | ||||
Condition (C1) ensures that the presence of a benchmark variable would not affect the Bayesian analysis concerning unknow , while (C2) guarantees that the benchmark can be used as a standard to assess the importance of covariates in terms of the posterior distributions of
,
.
How do we find a benchmark variable when we do not have a redundant variable at hand? We now show that a universal solution of simultaneously satisfying (C1) and (C2) does exist. Under the Bayesian framework with column-wisely centralised
, the density of
given
is proportional to
where
is the average of the components of
,
is the average of the components of
,
, and
. For the prior of
, we consider it to be
, where
is given by (Equation1
(1)
(1) ).
Since the intercept is not of interest, we integrate it out from the posterior density
. Then,
(2)
(2) Note that marginalisation over
is equivalent to centralising the response
. After integrating out
, the posterior inferences are drawn from the centralised response
instead of the original
. The reason that we introduce
in the model and then integrate it out, instead of eliminating it at the very beginning and directly building a linear regression model as
, is mainly for the mathematical rigorousness, as
is not of full rank and has a degenerate distribution.
The conditional posterior density in (Equation2(2)
(2) ) implies that conditioned on
,
and
are independent if and only if
, and
has mean zero if and only if
. In other words, (C1) and (C2) both hold if and only if
is orthogonal to
. Clearly,
is a direct solution and could be used as a benchmark to assess the importance of
's. Note that when
, the posterior density of
remains the same as its prior, and the posterior density of
is simplified to
(3)
(3) The fact that
can be used as a benchmark does not rely on the form of prior given in (Equation1
(1)
(1) ). If the prior in (Equation1
(1)
(1) ) is replaced by a multivariate normal prior, then the result is related with ridge regression, rather than lasso or Bayesian lasso. Computation might be an issue when the prior is non-normal.
The idea of benchmark in Bayesian framework is similar to the application of pseudo variables in frequentist approach (Breiman 2001, Wu et al. 2007). The only requirement for a pseudo variable is its independence with . Such a pseudo variable is not applicable here since it is likely that the pseudo variable does not satisfy (C1) due to the fact that orthogonality is a stronger assumption than independence in general.
2.2. Example
Even without a well-defined variable selection, we now consider a real data example to illustrate how we utilise a benchmark to assess importance of covariates.
The prostate cancer data originally came from a research conducted by Stamey et al. (Citation1989), and it was studied by Tibshirani (Citation1996) and Zou and Hastie (Citation2005). The goal of the research was to explore the relation between the level of prostate-specific antigen and several clinical measures in men before their hospitalisation for radical prostatectomy. The dataset contains 97 patients with the logarithm of prostate-specific antigen (lpsa) as the response and eight covariates, logarithm of cancer volume (lcavol), logarithm of prostate weight (lweight), age, logarithm of the amount of benign prostatic hyperplasia (lbph), seminal vesicle invasion (svi), logarithm of capsular penetration (lcp), Gleason score (gleason), and percentage Gleason score 4 or 5 (pgg45).
Figure visualises the posteriors. The leftmost boxplot is based on the posterior samples of the coefficient for the benchmark . It is distributed symmetrically around 0 as expected. Other box plots represent the posterior distributions of the coefficients associated with eight covariates. It can be seen that the three posteriors plotted in the far right of Figure are clearly different from the posterior of the benchmark and, hence, we may conclude that the corresponding three covariates, svi, lweight, and lcavol, are useful for the response. On the other hand, the posteriors of three covariates next to the benchmark in Figure are not different from the benchmark posterior and, hence, the covariates pgg45, lcp, and gleason are not useful. The posteriors of lbph and age are just marginally different from that of the benchmark, and we may still consider them to be not useful covariates.
Figure 1. Posterior plots with the prostate cancer data.
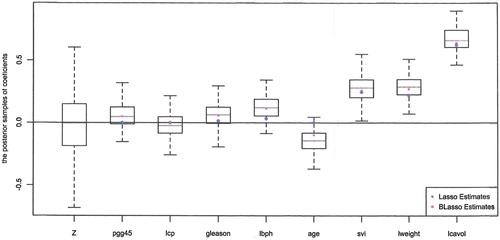
Figure also includes lasso and Bayesian lasso estimates of each coefficients, marked as circles and squares in the figure. The lasso estimates are zero for pgg45, lcp, and age, nonzero for the other five covariates. Thus, the lasso approach agrees with our approach for covariates pgg45, lcp, age, svi, lweight, and lcavol, but does not agree on gleason and lbph. Since the magnitudes of lasso estimates for gleason and lbph are small, another thresholding added to lasso will result in the same conclusion with ours. Meanwhile, the Bayesian lasso evaluates all the coefficients to be nonzero as it does not select variables to promote model sparsity.
2.3. Variable selection
The benchmark serves as a measure to assess the importance of each covariate. To compare the effect of each with that of the benchmark
, we define the importance score
for each
based on the following conditional posterior probability:
(4)
(4) where
denotes the posterior variance of ξ given
. This probability could be evaluated either numerically or theoretically, depending on which prior is put on
. The standardisation over the variances is necessary for the purpose of fair comparison. Intuitively, a
close to 0.5 indicates the effect of
is not much different from the effect of the benchmark and therefore
could be treated as an unimportant variable. With the availability of the estimated importance scores, the covariates
could be ranked from the most important to the least important as
, where
associates with the greatest estimated importance score,
associates with the second largest importance score and etc. It is desired to select covariates that are assessed to be the most important.
Naturally, the next question to be addressed is how to determine the cutoff point such that only the top
variables
are selected. To avoid arbitrary thresholding on the estimated importance scores, we adopt a slighted modified BIC criterion (Chen & Chen, Citation2008). For each integer
, the m most important covariates
are considered in a candidate model with
. The desired cutoff point
is the one that minimises
(5)
(5) over m, where
is the posterior mean of the regression parameter under model m. The original BIC in Chen and Chen (Citation2008) uses
instead of
in (Equation5
(5)
(5) ). This slight modification does not alter the asymptotic properties established in Chen and Chen (Citation2008) but has better simulation performance in our study.
For the prostate cancer example in Section 2.2, we compute 's and BIC
and show them in Table . It can be seen that BIC
reaches its minimum value
when
, i.e., lcavol, lweight, and svi are selected as important covariates, or equivalently, we select covariates whose
values are over 0.9 in this example.
Table 1. Values of  and BIC in prostate cancer example.
and BIC in prostate cancer example.
2.4. Computation
The Laplace prior in (Equation1(1)
(1) ) is a shrinkage prior, but it is not conjugate and, hence, Bayesian computation is complicated. Fortunately, we can follow the approach in Park and Casella (Citation2008) to carry out Bayesian computation using Gibbs sampler and to estimate λ using marginal likelihood. This is based on the fact that the Laplace distribution is a scale mixture of normal distributions where the mixing is through an exponential distribution as follows (Andrews & Mallows, Citation1974),
(6)
(6) Using
as benchmark and applying (Equation6
(6)
(6) ), we obtain that the posterior density in (Equation3
(3)
(3) ) is proportional to
which gives the following conditional distributions for Gibbs sampler:
where
and
is a
diagonal matrix with
as diagonal components. In the kth iteration of the Gibbs sampler, the λ value estimated from the
th iteration is used to get the kth sample and is then updated by the kth sample as
where the conditional expectation is evaluated by the average from Gibbs samples. The derivation is omitted since it is similar to that in Park and Casella (Citation2008).
Once the posterior samples of and
are obtained, the importance score
for each
specified in (Equation4
(4)
(4) ) can be approximated by the corresponding relative frequency
. The ranked
can be obtained by sorting
's descendingly. Finally, we can find the cutoff point
by minimising BIC in (Equation5
(5)
(5) ), with
being the posterior mean of the regression coefficient vector when
.
2.5. Covariates with group structures
In some studies, the covariates exhibit certain group structure. It is then desired to capture the intrinsic relation among variables within a group. In this section, we extend the idea of using a benchmark for variable selection under the Bayesian framework to accommodate the group structures. We perform variable selection in both group and individual variable levels.
Suppose that p covariates can be partitioned into G groups with sizes , respectively, where
. The matrix
could be written as
, where
is a
matrix for the gth group,
. The vector of associated regression coefficients can be written as
, where each
is a vector of length
,
.
The prior in (Equation1(1)
(1) ) does not take the group structure into consideration. Instead, as inspired by the penalty term of group lasso (Yuan & Lin, Citation2005), we consider the following prior density which encourages shrinkage on group level:
(7)
(7) The idea of benchmark can be extended to accommodate group level variable selection. Since a benchmark could be regarded as an individual group with a single covariate, we can assign a Laplace prior to
as in Section 2.1 and consider joint prior of
as
where the prior of
matches the form of prior for
in (Equation7
(7)
(7) ),
. Since the prior does not affect the fact that
is a benchmark as long as the prior of
has mean 0, we can still use
as a benchmark for group variable selection. It follows from (Equation6
(6)
(6) ) that
Then, after integrating out
, we obtain that the posterior density of
is proportional to
which gives the following full conditional distributions:
where
is a diagonal matrix with each
repeating
times in order as the diagonal components,
. The hyperparameter λ is estimated as in Section 2.4 with p replaced by G.
Let , which can be regarded as a measure of the effect of group g. The gth group effect is compared with the benchmark and ranked by
defined as (Equation4
(4)
(4) ) with
replaced by
. These posterior probabilities can be evaluated once the posterior samples for
and
,
are generated form Gibbs sampling. Based on these, the importance order of groups can be obtained. Like before, a BIC criterion specified in Equation (Equation5
(5)
(5) ) can be applied to eliminate groups of covariates that are unimportant.
In the procedure described above, groups are selected in an all-in-all-out fashion. However, not all of the covariates have influence on within an selected group. Hence, it is desired to carry out variable level selection within chosen groups. Let
be the index set of groups selected in the group level selection and let
. We can apply the variable selection procedure described in Section 2.3 to the covariate vector
. Let
be the vector of finally selected covariates. It could happen that some groups in
are entirely eliminated in the variable level selection, i.e., some
's with
are entirely not in
. These groups are then further excluded.
Even if there is no group structure in covariates, this group level selection followed by a variable level selection can be applied for variable selection when p is very large to reduce dimensionality in a fast way because group level selection may eliminate several groups of unimportant covariates simultaneously.
3. Simulation studies
Monte Carlo simulations are carried out to compare the performance of the proposed Bayesian variable selection method via a benchmark, as well as Bayesian lasso (B-lasso) by Park and Casella (Citation2008) and frequentist lasso by Tibshirani (Citation1996), where the penalty parameter is tuned by 10-folds cross-validation.
In the first study, there is no group structure in covariates. Three sets of n and p with increasing ratio of p/n are considered, n = 50, p = 10, n = 50, p = 100, and n = 100, p = 500. The matrix is generated from multivariate normal distribution
, where the
th element of Σ is
,
. Given
, the response vector
is generated from
, where
is p-dimensional with only three non-zero components (the first, second, and fifth), and
is chosen so that
, the signal-to-noise ratio, is 3, 5, 10 when n = 50 and 3, 4, 5, 6 when n = 100. Note that the intercept
is set to be 0. The covariates corresponding to non-zero
components are called important covariates; otherwise they are unimportant.
We consider the following performance measures of the proposed, lasso, and B-lasso methods:
(8)
(8)
(9)
(9)
(10)
(10)
(11)
(11) where PMSE is estimated prediction mean square error based on a test response vector on the test response vector
that is independent of
generated from
with the same
, and
is the posterior mean under the selected model.
The averages of quantities in (Equation8(8)
(8) )–(Equation11
(11)
(11) ) over 1000 simulations are presented in Table , with simulation standard deviations given in parenthesis. In addition, the rate in 1000 simulations of selecting exactly three important covariates are also included in Table .
Table 2. Results for simulation Study 1.
The results in Table illustrate substantial advantages of the proposed variable selection over the other two methods, in terms of measures in (Equation8(8)
(8) )–(Equation11
(11)
(11) ) and the rate of selecting exactly the three important covariates. The lasso selects much more covariates than the proposed method in all cases without improving the prediction error. The B-lasso does not select covariates, has sensitivity 1 and specificity and rate 0 and does not perform well in prediction especially when p/n is large.
In the second simulation study, a group structure is added to covariates and the proposed method in Section 2.5 is considered with a group selection followed by an individual variable selection. For comparison, we include three existing methods, the group lasso (glasso) proposed by Yuan and Lin (Citation2006), which carries out the group level selection in an ‘all-in-all-out’ fashion, the group bridge (gbridge) proposed by Huang et al. (Citation2009) and Zhou and Zhu (Citation2010), which selects groups as well as individual variables, and the sparse-group lasso (sglasso) proposed by Simon et al. (Citation2012).
Similar to the first simulation study, we generate from
and given
, we generate
from
with
. The group structure is from the covariance matrix Σ: components of
within the same group have pairwise correlation 0.5, while components of
from different groups are independent. Two cases with different sample size n, dimension p, and group structures are considered.
Case I. n = 100 and
Case II.
The averages of quantities in (Equation8(8)
(8) )–(Equation11
(11)
(11) ) over 200 simulations are presented in Table for both group and individual variable levels when (Equation8
(8)
(8) )–(Equation10
(10)
(10) ) are considered, with simulation standard deviations given in parenthesis. The rate in 200 simulations of selecting exactly number of important groups and number of important individual covariates are also included in Table .
Table 3. Results for simulation Study 2.
The results in Table demonstrate the advantage of our method in both prediction and variable selection, compared to other three methods.
4. Real data examples
For illustration, in this section, we apply the proposed method to three real datasets and compare it with other methods.
4.1. Prostate cancer
This example is introduced in Section 2.2, with variable selection illustrated in Section 2.3. To check the performance of proposed variable selection and make comparisons, we randomly split the dataset with 97 patients into 2 subsets of sizes 78 and 19, use the subset of size 78 as the training set to carry out variable selection and build regression model, and use the subset of size 19 as the test set to validate the prediction performance in terms of PMSE defined by (Equation11(11)
(11) ). We independently repeat random splitting 100 times and obtain the empirical results of 100 replications in Table .
Table 4. Results based on 100 random splits for the prostate cancer example.
The results in Table elucidates that the proposed method outperforms lasso and B-lasso. First, the proposed selection method highly concentrates on selecting three important covariates as indicated in Figure and Table . The average model size is 2.86. Although lasso agrees with the proposed method in selecting the three most important variables, it tends to select some redundant variables without improving PMSE, the prediction accuracy. Although Bayes lasso has a small PMSE, it does not perform variable selection.
4.2. CCT8 in a genome-wide association study
Research on linking genetic variations and phenotypic variations such as susceptibility to certain disorders is important in genomics as it helps to accelerate the understanding of genetic basis and may shed light on new medical treatments. We consider a high-dimensional dataset with p>n from a genome-wide association study, the expression quantitative trait locus (eQTL) mapping. The performance of high-resolution eQTL mapping on nucleotide level is based on the measurements of genome-wide single nucleotide polymorphism (SNP). Here we consider the eQTL mapping for the gene CCT8 measured by microarray as the response from 90 individuals, 45 Han Chinese from Beijing, China, and 45 Japanese from Tokyo, Japan. The analysis is to detect which SNPs are associated with the CCT8 expression level, from a total of 200 SNPs after an initial screening of many SNPs.
Results based on 100 random splits of the dataset similar to those in the previous example (Table ) are given in Table , with 80 people in the training set and 10 in the test set. In terms of the average model size and PMSE, the results in Table exhibit quite similar yet more dramatic pattern compared with the results in Table for the prostate cancer data. Our variable selection method significantly promotes model sparsity by selecting only around 3.4 variables on average, whereas the lasso method selects nearly 59 variables on the average. The PMSE under our approach is not jeopardised by the simplicity of model, as it is nearly the same as the PMSE for lasso. The Bayesian lasso results in the greatest PMSE, indicating that including all 200 predictors (compared with only 8 variables in the prostate cancer example) without variable selection leads to serious prediction errors when the number of unimportant variables is overwhelming in the model.
Table 5. Results based on 100 random splits for the CCT8 example.
Over 100 random data splits, the top five most frequently selected SNPs by our approach are shown in Table . The highest selection frequency of SNP rs965951 suggests its relevance with the response CCT8, which is in accord with the results from some previous studies (Bradic et al., Citation2009; Deutsch et al., Citation2005; Fan et al., Citation2012). The second most frequently selected SNP rs2245431 was also selected by Bradic et al. (Citation2009). All findings obtained by statistical methodologies are yet to be further validated by relevant genomical analysis.
4.3. ACS breast cancer patient OWB data
Breast cancer is a worldwide common cancer and remains the leading cause of mortality for women. With the continuously improved survival rate and prolonged life expectancy granted by advanced modern therapies, increasing efforts have been devoted to investigating the quality of life for breast cancer patients, as the quality of life plays an important role throughout the treatment and survivorship and, hence, the relevant studies may shed light on innovative intervention designs for disease control and quality of life improvement.
We consider a dataset from a large-scale breast cancer study conducted by American Cancer Society (ACS) at the School of Nursing in Indiana University. We focus on a subset of this study with 623 seniors who were 55–70 years old at diagnosis and were surveyed 3–8 years after completion of chemotherapy and surgery, with or without radiation therapy. The response of interest is overall well being (OWB), a measure captured by Campbell's index of quality of life, which is based on seven questionnaire items (Campbell et al., Citation2008). The objective of this study is to identify the psychological, social, and behaviour factors having important impacts on the well being of the survivors, and to establish the association between these factors and OWB.
The total 57 covariates under consideration include 3 demographic variables and 54 social or behaviour scores quantified by questionnaires which are well studied in literature (Frank-Stromborg & Olsen, Citation2003). The 54 social or behaviour variables are divided to 8 non-overlapping groups, which are personality, physical health, psychological health, spiritual health, active coping, passive coping, social support, and self efficacy. Each contains 4 to 12 individual covariates describing the same aspect of the social or behaviour status from different perspectives. The three demographic variables are treated as three individual groups, which are age at diagnosis, years of education, and number of months the patients were in their initial breast cancer treatment.
As in the first two examples, we randomly split the data set to a training set of size 499 and a test set of size 124, and then show the average or frequency based on 100 splits in Table . Similar to the second simulation study, we compare our proposed method to the glasso, gbridge, and sglasso designed for group variable selection.
Table 6. Results based on 100 random splits for the OWB example.
The first part of Table shows the rate (over 100 random splits) of selecting groups, where the three individual demographic variables are treated as three groups with size 1. The psychological health group is always selected by every method, which strongly suggests its association with the response OWB. It makes intuitive sense as a diagnosis of breast cancer is the most devastating thing a woman can hear, and it is often accompanied with fear of death, loss of control, isolation, and depression (Knobf, Citation2007; Yoo et al., Citation2010), all of which make considerably negative impacts on OWB. The other group that is always selected by our method, glasso and sglasso is social support, which is characterised as combination of emotional, tangible, and informational support (Cohen et al., Citation2000), from any formal, informal, social, professional, structured or unstructured resources (House & Khan, Citation1985). Reviews on the relevant literature reveal that it has been long recognised that social support may affect the OWB of patients in chronic and life-threatening health conditions like breast cancer (Cohen & Syme, Citation1985). Besides the above two groups, our method also selects the spiritual health group at a relatively low frequency, while barely including any other remaining groups. Purnell and Andersen (Citation2009) pointed out that spiritual well-being was significantly associated with quality of life and traumatic stress after controlling for disease and demographic variables. Furthermore, spirituality is regarded as a resource regularly used by patients with cancer coping with diagnosis and treatment Gall et al. (Citation2005).
Our proposed method selects variables within each selected groups. Over 100 random data splits, the middle part of Table shows the rates of top seven most frequently selected variables within the three selected groups. The selected psychological health group contains six variables, five of which are selected with high rates. In Table , tstatAnx and ttraiAnx are short for S-anxiety and T-anxiety scales, respectively, which are used to capture the anxiety level of patients based on 20 questions like ‘I feel nervous and restless’; tbodimg stands for body image total score and is summarised from eight questions such as ‘I am satisfied with the appearance of my body’ and ‘others find me attractive’; tcesd represents the total score for situations during the past week, and the questions associated with this construct are something like ‘I was bothered by things that usually don't bother me’ or ‘my appetite was poor’. In the social support group, only one variable is selected with high frequency, tcommnow, which quantifies the communication quality between the patients and physicians, based on questions like ‘I have a health care provider I trust’ and ‘I have a health care provider who knows me personally’. The high selection frequency of this variable is in accord with the existing research results, which suggests that although the older women obtain information regarding breast cancer from a variety of sources, they often reply heavily on their primary care physicians for support and information (Silliman et al., Citation1998).
While the previous analysis focuses on group and individual variable selection, the last part of Table shows the advantage of our proposed method in terms of the averages of selected groups and variables, and the PMSE over 100 random splits. On the average, our method promotes model sparsity by picking only around 2.4 groups and further reduces model complexity by including less than six variables in selected groups. In contrary, both glasso and sglasso select nearly twice many groups while produce comparable PMSE. The gbridge also chooses significantly more groups than our method, while leads to a slight smaller.
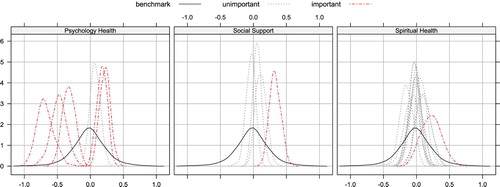
Finally, as we discussed in Section 2.2, our proposed benchmark approach can also be applied by visualising the posteriors. Figure illustrates how to visualise the importance of variables within each three groups, based on the whole data set with 623 patients.
Figure 2. The posteriors of regression coefficients in three groups.
Acknowledgements
Our research was supported by the National Natural Science Foundation of China (11831008) and the U.S. National Science Foundation (DMS-1612873 and DMS-1914411). We would like to thank a referee for a careful review.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Jun Shao
Dr. Jun Shao holds a PhD in statistics from the University of Wisconsin-Madison. He is a Professor of Statistics at the University of Wisconsin-Madison. His research interests include variable selection and inference with high dimensional data, sample surveys, and missing data problems.
Kam-Wah Tsui
Dr. Kam-Wah Tsui is an Emeritus Professor of Statistics at the University of Wisconsin–Madison. His research interests include Bayesian analysis, sample surveys, and general statistical methodology.
Sheng Zhang
Dr. Sheng Zhang holds a Ph.D. in statistics from University of Wisconsin-Madison. She is now a data scientist at Google, Mountain View, California.
References
- Andrews, D. F., & Mallows, C. L. (1974). Scale mixtures of normal distributions. Journal of the Royal Statistical Society, Series B, 36, 99–102.
- Bayarri, M. J., Berger, J. O., Jang, W., Ray, S., Pericchi, L. R., & Visser, L. (2019). Prior-based Bayesian information criterion (PBIC). Statistical Theory and Related Fields, 3(1), 2–13. https://doi.org/10.1080/24754269.2019.1582126
- Bradic, J., Fan, J., & Wang, W. (2009). Penalized composite quasi-Likelihood for ultrahigh-Dimensional variable selection. Journal of the Royal Statistical Society, Series B, 73(3), 325–349. https://doi.org/10.1111/rssb.2011.73.issue-3
- Brown, P. J., Vannucci, M., & Fearn, T. (1998). Multivariate Bayesian variable selection and prediction. Journal of the Royal Statistical Society, Series B, 60(3), 627–641. https://doi.org/10.1111/rssb.1998.60.issue-3
- Campbell, A., Converse, P., & Rodgers, W. (2008). The quality of American life: Perceptions, evaluations, and satisfactions. Russell Sage Foundation.
- Chen, J., & Chen, Z. (2008). Extended Bayesian information criterion for model selection with large model spaces. Biometrika, 95, 759–771. https://doi.org/10.1093/biomet/asn034
- Cohen, S., Gottlieb, B., & Underwood, L. (2000). Social relationships and health. In S. Cohen, L. Underwood, & B. Gottlieb (Eds.), Social support measurement and intervention. Oxford University Press.
- Cohen, S., & Syme, L. (1985). Social support and health (Tech. Rep.). Academic.
- Dellaportas, P., Forster, J. J., & Ntzoufras, I. (1997). On Bayesian model and variable selection using MCMC (Tech. Rep.). Department of Statistics, Athens University of Economics and Business.
- Deutsch, S., Lyle, R., Dermitzakis, E., Attar, H., Subrahmanyan, L., Gehri, C., Parand, L., Gagnebin, M., Rougemont, J., Jongeneel, C., & Antonarakis, S. (2005). Gene expression variation and expression quantitative trait mapping of human chromosome 21 genes. Human Molecular Genetics, 14(23), 3741–3749. https://doi.org/10.1093/hmg/ddi404
- Dicker, L., Huang, B., & Lin, X. (2011). Variable selection and estimation with the seamless-l0 penalty. Statistica Sinica,
- Fan, J., Han, X., & Gu, W. (2012). Estimating false discovery proportion under arbitrary covariance dependence. Journal of the American Statistical Association, 107(499), 1019–1035. https://doi.org/10.1080/01621459.2012.720478
- Fan, J., & Li, R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association, 96(456), 1348–1360. https://doi.org/10.1198/016214501753382273
- Frank-Stromborg, M., & Olsen, S. (2003). Instruments For Clinical Health-Care Research (Jones and Bartlett Series in Oncology, 3rd edition) (Tech. Rep.). Jones & Bartlett Learning.
- Gall, T., Charbonneau, C., Clarke, N., Grant, K., Joseph, A., & Shouldice, L. (2005). Understanding the nature and role of spirituality in relation to coping and health: A conceptual framework. Canadian Psychology, 46(2), 88–104. https://doi.org/10.1037/h0087008
- George, E. I., & McCulloch, R. E. (1993). Variable selection via Gibbs sampling. Journal of the American Statistical Association, 85, 398–409.
- Green, P. J. (1995). Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika, 82, 711–732. https://doi.org/10.1093/biomet/82.4.711
- Hoerl, A., & Kennard, R. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55–67. https://doi.org/10.1080/00401706.1970.10488634
- Hoti, F., & Sillanpää, M. J. (2006). Bayesian mapping of genotype x expression interactions in quantitative and qualitative traits. Heredity, 97(1), 4–18. https://doi.org/10.1038/sj.hdy.6800817
- House, J., & Khan, R. (1985). Measures and concepts of social support. In S. Cohen & S. L. Syme (Eds.), Social support and health (Tech. Rep.).
- Huang, J., Ma, S., Xie, H., & Zhang, C. (2009). A group bridge approach for variable selection. Biometrika, 96, 339–355. https://doi.org/10.1093/biomet/asp020
- Knobf, M. (2007). Psychological responses in brest cancer survivors. Seminars in Oncology Nursing, 23(1), 71–83. https://doi.org/10.1016/j.soncn.2006.11.009
- Kuo, L., & Mallick, B. (1998). Variable selection for regression models. Sankhya Series B, 60, 65–81.
- Kyung, M., Gilly, J., Ghosh, M., & Casella, G. (2010). Penalized regression, standard errors, and Bayesian lassos. Bayesian Analysis, 5(2), 369–411. https://doi.org/10.1214/10-BA607
- Lin, Y., & Zhang, H. (2006). Component selection and smoothing in smoothing spline analysis of variance models. The Annals of Statistics, 34(5), 2272–2297. https://doi.org/10.1214/009053606000000722
- Lv, J., & Fan, Y. (2009). A unified approach to model selection and sparse recovery using regularized least squares. The Annals of Statistics, 37(6A), 3498–3528. https://doi.org/10.1214/09-AOS683
- O'Hara, R. B., & Sillanpää, M. J. (2009). Review of Bayesian variable selection methods: What, how and which. Bayesian Analysis, 4(1), 85–117. https://doi.org/10.1214/09-BA403
- Park, T., & Casella, G. (2008). The Bayesian Lasso. Journal of the American Statistical Association, 103(482), 681–686. https://doi.org/10.1198/016214508000000337
- Purnell, J., & Andersen, B. (2009). Religious practice and spirituality in the psychological adjustment of survivors of breast cancer. Counseling and Values, 53(3), 165–182. https://doi.org/10.1002/(ISSN)2161-007X
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. https://doi.org/10.1214/aos/1176344136
- Shen, X., Pan, W., & Zhu, Y. (2011). Likelihood-based selection and sharp parameter estimation. Journal of the American Statistical Association.
- Silliman, R., Dukes, K., Sullivan, L., & Kaplan, S. (1998). Breast cancer care in older women: Sources of information, social support, and emotional health outcomes. Cancer, 83, 706–711. https://doi.org/10.1002/(ISSN)1097-0142
- Simon, N., Friedman, J., Hastie, T., & Tibshirani, R. (2012). A sparse-group lasso. Journal of Computational and Graphical Statistics.
- Stamey, T., Kabalin, J., McNeal, J., Johnstone, I., Freiha, F., Redwine, E., & Yang, N. (1989). Prostate specific antigen in the diagnosis and treatment of adenocarcinoma of the prostate.II. radical prostatectomy treated patients. Journal of Urology, 141(5), 1076–1083. https://doi.org/10.1016/S0022-5347(17)41175-X
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B, 58, 267–288.
- Tibshirani, R., Saunders, M., Rosset, S., Zhu, J., & Knight, K. (2005). Sparsity and smoothness via the fused lasso. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(1), 91–108. https://doi.org/10.1111/rssb.2005.67.issue-1
- Tipping, M. (2001). Sparse Bayesian learning and the relevance vector machine. Journal OfMachine Learning, 1, 211–244.
- Yoo, G., Levine, E., Aviv, C., Ewing, C., & Au, A. (2010). Older women, breast cancer, and social support. Supportive Care in Cancer, 18, 121521–1530. https://doi.org/10.1007/s00520-009-0774-4
- Yuan, M., & Lin, Y. (2005). Efficient empirical bayes variable selection and esimation in linear models. Journal of the American Statistical Association, 100(472), 1215–1225. https://doi.org/10.1198/016214505000000367
- Yuan, M., & Lin, Y. (2006). Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1), 49–67. https://doi.org/10.1111/rssb.2006.68.issue-1
- Zhang, C. (2010). Nearly unbiased variable selection under minimax concave penalty. The Annals of Statistics, 38(2), 894–942. https://doi.org/10.1214/09-AOS729
- Zhou, N., & Zhu, J. (2010). Group variable selection via a hierarchical lasso and its oracle property. Statistics and Its Inference, 3, 557–574.
- Zou, H. (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101(476), 1418–1429. https://doi.org/10.1198/016214506000000735
- Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, Series B, 67(2), 301–320. https://doi.org/10.1111/rssb.2005.67.issue-2