
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Treatment selection based on patient characteristics has been widely recognised in modern medicine. In this paper, we propose a generalised partially linear single-index mixed-effects modelling strategy for treatment selection and heterogeneous treatment effect estimation in longitudinal clinical and observational studies. We model the treatment effect as an unknown functional curve of a weighted linear combination of time-dependent covariates. This method enables us to investigate covariate-specific treatment effects and make personalised treatment selection in a flexible fashion. We develop a method that combines local linear regression and penalised quasi-likelihood to estimate the weight for each covariate, the unknown treatment effect curve and the parameters for mixed-effects. Based on pointwise confidence intervals for the treatment effect curve, we can make individualised treatment decisions from the information of patient characteristics. A simulation study is conducted to evaluate finite sample performance of the proposed method. We also illustrate the method via analysis of a real data example.
1. Introduction
Personalized or precision medicine, which aims to provide treatment strategies according to the characteristics of individuals or subgroups of the population, has gained much attention from biomedical researchers. The main goal of personalised medicine is to investigate covariate-specific (heterogeneous) effects of treatment, based on which individualised clinical decision can be better made to patients. In recent years, there has been an increasing amount of literature on heterogeneous treatment effect (HTE) estimation. A typical way of exploring heterogeneous treatment effects is to examine patient outcomes in mutually exclusive subgroups defined by observable patient characteristics, see Berger et al. (Citation2014), Ciampi et al. (Citation1995), Negassa et al. (Citation2005), Foster et al. (Citation2011), Su et al. (Citation2008) and Wang et al. (Citation2007). Bonetti and Gelber (Citation2004) introduced a subpopulation treatment effect pattern plot (STEPP), which characterises treatment effects across potentially overlapping intervals of a continuous covariate. Bonetti et al. (Citation2009) indicated that this method is effective only for large sample sizes, and proposed a permutation-based method for inference and achieved better performance for smaller sample sizes. The major limitation of such subgroup approach is that dichotomisation of continuous covariates can be artificial, and thus it may lose important information from the data.
In the literature, some other works apply nonparametric and semiparametric modelling methods to study HTE. These methods impose no or very relaxed assumptions on the model structure, and thus can explore HTE in a flexible fashion. For continuous response, Foster et al. (Citation2015) proposed a two-stage procedure. They obtain nonparametric estimates of treatment effects for each subject in stage 1, and these estimates are used to identify optimal subset for a treatment, thus determine a treatment regime in stage 2. However, this method only applies to situations that the optimal subset is contiguous. For time-to-event data, Ma and Zhou (Citation2014) defined a covariate-specific treatment effect (CSTE) curve, which is used to represent clinical utility of a continuous biomarker. They derived estimate of CSTE curve, and constructed pointwise confidence interval to select the optimal treatment for individual patient, as well as simultaneous confidence band to identify subpopulation who respond well to a treatment. Han et al. (Citation2017) extended the method of Ma and Zhou (Citation2014) to the case of binary response. Both of them only considered a single biomarker. In order to incorporate multivariate or even high-dimensional covariates, Guo et al. (Citation2018) proposed a sparse logistic single-index coefficient model for optimal treatment selection using the CSTE curve. This method offers a flexible way for studying the CSTE curve without a restrictive assumption on the structure of the curve while achieving great dimension reduction of the high-dimensional covariates.
All the above methods were proposed for cross-sectional data with responses measured at one time point. In practice, the patient outcomes are often collected at multiple follow-up times in order to better evaluate the effectiveness of treatments. In this paper, we extend the model considered in Guo et al. (Citation2018) to the longitudinal clinical and observational studies, and consider a generalised partially linear single-index coefficient mixed-effects model (GPLSIMM) for our longitudinal setting. Similar as Guo et al. (Citation2018), we treat the treatment effect as an unknown functional curve of a weighted linear combination of time-varying covariates. The weights for covariates account for their different contributions to the treatment effect, and they are estimated from the data. In longitudinal studies, the repeated measures are correlated within subjects, and thus the estimating method considered in Guo et al. (Citation2018) is not applicable to our proposed GPLSIMM. In our model, we need to estimate the unknown functional curve, the weight of each covariate and the parameters for the mixed-effects. Estimation of generalised semiparametric mixed-effects models has been considered in some existing works. Liang (Citation2009) proposed a local linear regression and penalised quasi-likelihood method for estimation of a generalised partially linear mixed-effects model. Pang and Xue (Citation2012) considered a local linear regression with GEE method for a single-index mixed effects model. Xu and Zhu (Citation2012) and Chen et al. (Citation2014) developed a kernel and a P-spline estimation method, respectively, together with quasi-lilikelhood for longitudinal generalised single-index models.
Based on the methods considered in these works, we see that penalised quasi-likelihood is a commonly used method for estimation of generalised mixed-effects models. It circumvents the calculation of high-dimensional integral in likelihood function (Breslow & Clayton, Citation1993). In our proposed GPLSIMM, we approximate the unknown treatment effect curve by the local linear method and estimate the parameters for the parametric and nonparametric parts through alternatively optimising the local and global penalised quasi-likelihood functions. We then select optimal treatment for a future patient based on pointwise confidence intervals for the CSTE curve.
The rest of the paper is organised as follows. In Section 2, we introduce the proposed model, the CSTE curve and the estimation method. Section 3 gives asymptotic properties of parametric and nonparametric estimates. Section 4 provides the algorithm for model estimation. In Section 5 we evaluate the finite sample properties of the proposed method via simulation studies, while Section 6 illustrates the application of the proposed method in a real data set. All technical proofs are relegated to Appendix.
2. Model and estimation
2.1. Model
Suppose our data are obtained from n independent subjects, and observations of the ith subject is .
is the response,
,
and
are covariates of dimension p, q and s, and
is an indicator of exposure to treatment. We assume the relationship of response and covariates is specified by the following GPLSIMM:
(1)
(1) where
,
and
are known functions, φ is a scale parameter and
is a pre-determined weight for the jth observation of the ith subject.
is an unknown function, and
and
are unknown parameter vectors. For model identifiability, we assume that
and
. We incorporate random effect
to account for the within-subject correlation, where
are
-dimensional random effect vectors. We assume that
.
In this model, we characterise the treatment effect with a single-index term , and the relationship of response and covariates for control group with a generalised linear mixed effect model. When response Y is binary, we can easily see that
(2)
(2) When Y is a count variable and follows Poisson distribution,
(3)
(3) Assume that D = 0 and D = 1 represents standard care and treatment respectively, X and Z are patient characteristics, Y indicates outcome of the study, and the better outcome corresponds to larger value of Y. From (Equation2
(2)
(2) ) and (Equation3
(3)
(3) ),
could be regarded as a measure of treatment effect. We define
as covariate-specific treatment effect (CSTE) curve under this model.
Given the estimate and confidence interval of , we could suggest the optimal treatment for a future patient based on his or her personal characteristics. Taking binary response as an example, we assume that Y = 1 represent a disease being cured, while Y = 0 indicate uncured. Let
be the estimated value of
calculated from personal characteristics of a patient. If the lower bound of confidence interval for
is greater than 0, the treatment is more effective than standard care for the patient. On the other hand, if the upper bound of confidence interval is smaller than 0, standard care is more effective. In this case, we could not recommend the treatment to the patient. If neither of the above cases happen, that is, 0 is contained in the confidence interval, we would draw the conclusion that there's no significant difference between treatment and standard care.
2.2. Estimation
Denote . Let
be the vector after deleting the first element from
. Then
, and we define the Jacobian matrix
Our primary interest is to estimate
,
,
and
.
Suppose that is known. Given
and
, we combine penalised quasi-likelihood with local linear technique to obtain estimates of
and
. If u is in a neighbourhood of
,
can be approximated by
Let
,
, where h is bandwidth,
is a zero-mean symmetric density function. We maximise the following local penalised quasi-likelihood
(4)
(4) with respect to a, b and
, and obtain estimates
and
. Taking derivative on (Equation4
(4)
(4) ) with respect to
and
yields the following estimating equations:
(5)
(5) and for each i,
(6)
(6)
When is known, we obtain estimate of
,
and
by maximising the global penalised quasi-likelihood
(7)
(7) with respect to
,
and
. The corresponding estimating equations are as follows:
(8)
(8)
(9)
(9) and for each
,
(10)
(10)
We obtain the parametric and nonparametric estimates by iteratively maximising quasi-likelihoods (Equation4(4)
(4) ) and (Equation7
(7)
(7) ). The corresponding algorithm is summarised in Section 4 for practical implementation.
3. Asymptotic properties
Denote , and
, k = 1, 2, 3. Let
for j = 1, 2,
and
. We assume n tends to infinity and
's are bounded. Denote
, and
.
In order to obtain asymptotic behaviours of the proposed parametric and nonparametric estimates, we assume the following regularity conditions:
The marginal density of Z is positive and uniformly continuous with a compact support
.
For all x,
The second derivative of
The kernel
As
Denote
Let
be the final estimator of
and
, respectively. Theorem 3.1 gives the asymptotic distributions of
and
.
Theorem 3.1
Under conditions (C1)–(C6),
(11)
(11) where
with
and
Theorem 3.1 indicates that in order to obtain consistent estimates of
and
, we need to undersmooth the nonparametric function
. For any
, we let
be the estimate of
given
and
be the corresponding bandwidth. Theorem 3.2 presents the asymptotic distribution of
.
Theorem 3.2
Under conditions (C1)–(C5), as
and
,
(12)
(12) where
.
4. Computation
Given and
, we solve estimating Equations (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) by Fisher's scoring algorithm (see Wu & Zhang, Citation2006, Section 10.4), and obtain estimates
and
.
When is given, we obtain estimates of
,
and
by solving Equations (Equation8
(8)
(8) ), (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ). Here we apply the quasi-Fisher scoring algorithm to this problem.
Denote
Using the quasi-Fisher scoring algorithm, estimate of
is updated by
(13)
(13) where
with
and for
,
Let
We further denote
Equation (Equation13
(13)
(13) ) can be rewritten as
Note that
and
on the right hand of above equation are calculated from
. For simplicity we suppress their subscripts hereinafter. Denote
. By matrix algebra, we can obtain
(14)
(14) Based on
and
, we can show that
Thus, we update
by
, with
, and
Our algorithm can be summarised as following:
Obtain initial estimate
Given parametric estimate
Obtain
Iterate between Steps 2 and 3 until convergence, and obtain the final estimate
Note that matrix is still unknown. To obtain estimate of
, we apply the maximum likelihood method under the normality assumption, and implement the method by EM algorithm (see Laird & Ware, Citation1982). To be specific, we set the initial value of
to be the identity matrix. After obtaining the estimates of
and
by Steps 1–4, we have an updated estimate of
. We repeat this procedure until convergence, and obtain the final estimate
. Given the estimate
, we derive the estimates of
,
and
by substitution of
for
in Steps 2 and 3.
During the process of implementation, bandwidth h in Step 2 also needs to be selected. Theorem 3.1 indicates that undersmoothing the nonparametric part is necessary to guarantee consistency of parametric estimates. We adopt the ad hoc method in Carroll et al. (Citation1997) to select appropriate bandwidth for Step 2.
5. Simulation
In this section, we assess the finite sample performance of the proposed method via two Monte Carlo simulations with binary and count responses respectively.
In these simulations,
where
and
, with
, and
. We assume the random effect be random intercept, that is,
and
is one-dimensional. We let
follow
. For the covariates, X is distributed as
, where
and
follows
,
, where
are uniform
variables, and the exposure indicator D follows
. We assume
, the number of observations for each subject, is 5, and set the number of subjects n to be 100, 300 and 500. For the response variable, we consider the following two cases:
Case 1 (Binary data):
Case 2 (Count data):
All simulations are repeated for 500 times. For comparison, we ignore the random effects and apply generalised partially linear single-index model (GPLSIM) to the simulated data. The corresponding estimates are obtained using the method in Xu and Zhu (Citation2012). The parametric estimates for binary and count data are summarised in Tables and respectively. We assess the performance of nonparametric estimator by mean integrated squared error (MISE) defined as
Table 1. Simulation results for parametric estimates with binary data.
Table 2. Simulation results for parametric estimates with count data.
Tables and shows mean and standard deviation of MISE for nonparametric function.
Table 3. MISE for nonparametric estimate with binary data.
Table 4. MISE for nonparametric estimate with count data.
From Tables and , MSE of the parametric estimates under our model are generally smaller than that of ignoring the random effects. As the sample size increases, the performance of parametric estimates improves. Similar results hold for nonparametric estimates. The MISE of nonparametric estimates using our method is smaller than those derived under GPLSIM. MISE decreases as the sample size increases.
6. Real data analysis
We apply the proposed method to the US National Alzhemer's Coordinating Center Uniform Data Set (https://www.alz.washington.edu). Our goal is to investigate the effect of heredity on development of Alzheimer's disease (AD) among women. We take the diagnosis of AD in each observation of patients (yes/no) as response. The covariates that may influence the occurrence of AD include age, visit year, years of education (EDUC), indicator of first-degree family member with cognitive impairment (yes/no, FAM), depression (yes/no, DEP), diabetes (yes/no, DIABETES) and mini-mental state exam (MMSE) score. To avoid large computational burden including all the observations, we randomly select 500 subjects with at least 2 follow-up visits from the original data set. Our final sample includes 2491 observations and the median follow-up is 3. The visit year is between 2005 and 2019. The proportion of occurence of AD is 28.3% among all observations, and the proportion of subjects whose family member has cognitive impairment is 64.2%. Note that we repeated the sample selection for several times, and achieved consistent results.
Taking FAM as indicator of treatment, we apply the proposed model and method to the final data set. We include logarithm of age and MMSE score into Z, and intercept, age, visit year, EDUC, DEP, DIABETES and MMSE score into X. The estimate of treatment effect reflects the influence of family heredity on development of AD. Note that in this data set, FAM is not a real treatment indicator, thus the corresponding CSTE curve does not indicate a real treatment effect. This data set is only used to for illustrative purpose.
Table shows the parametric estimates. The standard deviations of parameters are calculated from 500 bootstrap samples. Figure presents estimate of nonparametric function and the corresponding 95% pointwise confidence interval. We construct the confidence interval based on result of Theorem 3.2, and apply the method of Zhang and Peng (Citation2010) to estimate the bias and variance. Figure displays the curve of treatment effect versus MMSE score with age fixed on its mean value, as well as the curve of treatment effect versus age with MMSE score fixed on the mean value.
Figure 1. Estimate of nonparametric function (real line) and its 95% pointwise confidence interval (dashed line).
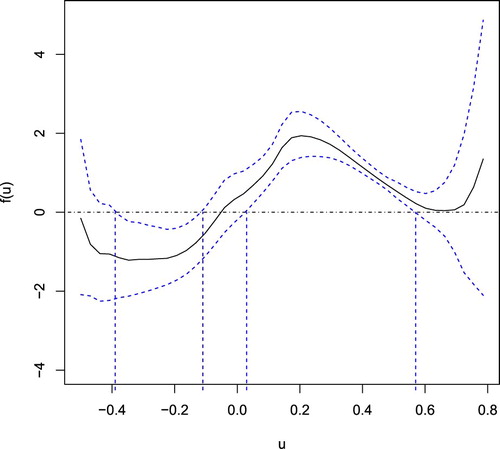
Figure 2. Relationship of treatment effect with MMSE score and Age: the estimated curve represented by real line and the corresponding 95% pointwise confidence interval by dashed line.
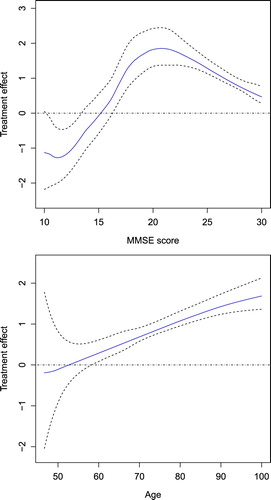
Table 5. Estimated and .
Chen and Zhou (Citation2011) used a generalised linear model to investigate risk factors that influence the occurrence of AD. From their results, age, DEP and MMSE score are significant under four estimation methods. They found that age and DEP have positive associations with the occurence of AD, and MMSE score is negatively correlated with the development of AD. From Table , our result of parametric estimates is consistent with these findings. From Figure , we can clearly see that if the estimated index of a patient is between 0.03 and 0.57, family inheritance of congnitive impairment increases the risk of getting AD. However, if the estimated index is between −0.39 and −0.11, family heredity decreases the risk of AD. Figure shows that the effect of family heredity on occurence of AD has a bell shape association with MMSE score, that is, heredity has lower or even negative influence on risk of AD when the value of MMSE score is small or large. Also, the effect has an increasing trend with age. The effect of family heredity on occurrence of AD is stronger for elderly people.
7. Discussion
This paper focuses on a generalised partially linear single-index mixed effects model for personalised treatment effect estimation and treatment selection in longitudinal studies. In our model, the treatment effect is described as a function of a linear combination of covariates. We develop a method combining local linear regression and penalised quasi-likelihood to estimate the coefficients for each covariate, the treatment effect curve and the parameters for mixed effects. Based on the pointwise confidence intervals for treatment effect curve, we can make individualised treatment decisions from the information of patient characteristics. Our simulation study and real data analysis illustrate effectiveness of the proposed method.
Nonparametric and semiparametric methods provide a flexible way to explore HTE. The previous research in this area mostly focus on cross-sectional data. Our work fills in the gap of semiparametric modelling of HTE with longitudinal data. On the other hand, we develop a new estimation method combining local linear technique and penalised quasi-likelihood, for generalised partially linear single-index model. Pointwise confidence interval can be directly constructed for the estimated treatment effect curve based on its asymptotic normality. The theory of simultaneous confidence band for treatment effect curve can also be established accordingly, and we leave this for future work.
There are still some limitations in our work. We directly apply the method of Zhang and Peng (Citation2010) to estimate bias and variance for the treatment effect curve. It would be more rigorous that the performance of this method in our context be validated via simulation studies. We will include this in our future research. Another limitation of our work is that, based on the pointwise confidence interval of treatment effect curve, we could only make treatment decision for a future patient. To identify subgroup of patients that benefit from each treatment, it is necessary to construct simultaneous confidence band for treatment effect curve. Some possible extensions of our work could also be considered in future research. Our model could be extended to high-dimensional covariates to cope with longitudinal studies in which large number of patient characteristics are recorded. It is also of interest to consider robust regression to limit the impact of outlying observations. An even further extension is a survival model for time-to-event response.
Acknowledgments
We are grateful to the Editor-in-Chief, Prof. Jun Shao, an Associate Editor and anonymous reviewers for their thorough reading of our manuscript and insightful comments that have led to significant improvement of this work. We also thank the US National Alzheimer's Coordinating Center for providing the data.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Yanghui Liu
Yanghui Liu is a Ph.D. candidate in Statistics at East China Normal University.
Riquan Zhang
Riquan Zhang is a Professor in School of Statistics at East China Normal University.
Shujie Ma
Shujie Ma is an Associate Professor in Department of Statistics at University of California, Riverside.
Xiuzhen Zhang
Xiuzhen Zhang is a Ph.D. candidate in Statistics at East China Normal University.
References
- Berger, J. O., Wang, X., & Shen, L. (2014). A Bayesian approach to subgroup identification. Journal of Biopharmaceutical Statistics, 24(1), 110–129. https://doi.org/10.1080/10543406.2013.856026
- Bonetti, M., & Gelber, R. (2004). Patterns of treatment eects in subsets of patients in clinical trials. Biostatistics, 5(3), 465–481. https://doi.org/10.1093/biostatistics/kxh002
- Bonetti, M., Zahrieh, D., Cole, B. F., & Gelber, R. D. (2009). A small sample study of the stepp approach to assessing treatment-covariate interactions in survival data. Statistics in Medicine, 28(8), 1255–1268. https://doi.org/10.1002/sim.v28:8 doi: https://doi.org/10.1002/sim.3524
- Breslow, N. E., & Clayton, D. G. (1993). Approximate inference in generalized linear mixed models. Journal of the American Statistical Association, 88(21), 9–25. https://doi.org/10.1080/01621459.1993.10594284.
- Carroll, R. J., Fan, J., Gijbels, I., & Wand, M. P. (1997). Generalized partially linear single-index models. Journal of the American Statistical Association, 92(438), 477–489. https://doi.org/10.1080/01621459.1997.10474001
- Chen, J., Kim, I., Terrell, G. R., & Liu, L. (2014). Generalized partially linear single-index mixed model for repeated measures data. Journal of Nonparametric Statistics, 26(2), 291–303. https://doi.org/10.1080/10485252.2014.891029
- Chen, B., & Zhou, X. (2011). Doubly robust estimates for binary longitudinal data analysis with missing response and missing covariates. Biometrics, 67(3), 830–842. https://doi.org/10.1111/biom.2011.67.issue-3 doi: https://doi.org/10.1111/j.1541-0420.2010.01541.x
- Ciampi, A., Negassa, A., & Lou, Z. (1995). Tree-structured prediction for censored survival data and the cox model. Journal of Clinical Epidemiology, 48(5), 675–689. https://doi.org/10.1016/0895-4356(94)00164-L
- Cui, X., Härdle, W. K., & Zhu, L. (2011). The EFM approach for single-index models. The Annals of Statistics, 39(3), 1658–2688. https://projecteuclid.org/euclid.aos/1311600279 doi: https://doi.org/10.1214/10-AOS871
- Foster, J. C., Taylor, J. M. G., Kaciroti, N., & Nan, B. (2015). Simple subgroup approximations to optimal treatment regimes from randomized clinical trial data. Biostatistics, 16(2), 368–382. https://doi.org/10.1093/biostatistics/kxu049
- Foster, J. C., Taylor, J. M.G., & Ruberg, S. J. (2011). Subgroup identification from randomized clinical trial data. Statistics in Medicine, 30(24), 2867–2880. https://doi.org/10.1002/sim.v30.24 doi: https://doi.org/10.1002/sim.4322
- Guo, W., Zhou, X., & Ma, S. (2018). Optimal treatment selection using the covariate-specific treatment effect curve with high-dimensional covariates, arXiv:1812.10018.
- Han, K., Zhou, X., & Liu, B. (2017). CSTE curve for selection the optimal treatment when outcome is binary. Scientia Sinica (Mathematica), 47(4), 497–514. https://doi.org/10.1360/SCM-2015-0595
- Laird, N. M., & Ware, J. H. (1982). Random effects models for longitudinal data. Biometrics, 38(4), 963–974. https://doi.org/10.2307/2529876
- Liang, H. (2009). Generalized partially linear mixed-effects models incorporating mismeasured covariates. Annals of the Institute of Statistical Mathematics, 61(1), 27–46. https://doi.org/10.1007/s10463-007-0146-0
- Ma, Y., & Zhou, X. (2014). Treatment selection in a randomized clinical trial via covariate-specific treatment effect curves. Statistical Methods in Medical Research, 26(1), 124–141. https://doi.org/10.1177/0962280214541724
- Negassa, A., Ciampi, A., Abrahamowicz, M., Shapiro, S., & Boivin, J. (2005). Tree-structured subgroup analysis for censored survival data: validation of computationally inexpensive model selection criteria. Statistics and Computing, 15(3), 231–239. https://doi.org/10.1007/s11222-005-1311-z
- Pang, Z., & Xue, L. (2012). Estimation for the single-index models with random effects. Computational Statistics & Data Analysis, 56(6), 1837–1853. https://doi.org/10.1016/j.csda.2011.11.007
- Su, X., Tsai, C., Wang, H., Nickerson, D., & Li, B. (2008). Subgroup analysis via recursive partitioning. Journal of Machine Learning Research, 10, 141–158. https://dl.acm.org/doi/10.5555/1577069.1577074.
- Wang, R., Lagakos, S. W., Ware, J. H., Hunter, D. J., & Drazen, J. M. (2007). Statistics in medicine – Reporting of subgroup analyses in clinical trials. The New England Journal of Medicine, 357(21), 2189–2194. https://doi.org/10.1056/NEJMsr077003
- Wu, H., & Zhang, J. T. (2006). Nonparametric regression methods for longitudinal data analysis. John Wiley & Sons.
- Xu, P., & Zhu, L. X. (2012). Estimation for a marginal generalized single-index longitudinal model. Journal of Multivariate Analysis, 105(1), 285–299. https://doi.org/10.1016/j.jmva.2011.10.004
- Zhang, W., & Peng, H. (2010). Simultaneous confidence band and hypothesis test in generalised varying-coefficient models. Journal of Multivariate Analysis, 101(7), 1656–1680. https://doi.org/10.1016/j.jmva.2010.03.003
Appendix
Proof of Theorem 3.1.
Proof of Theorem 3.1
We use a similar proof strategy with Xu and Zhu (Citation2012). Our proof is divided to three steps.
Step 1: Given , we derive the asymptotic expansion of
.
Let ,
Denote
. By (Equation4
(4)
(4) ),
minimises
with respect to Λ. Using Taylor expansion,
Let
. Then
. Using similar arguments as Section A.1 in Liang (Citation2009),
It is easy to see that . Denote the first element of
by
. Using Taylor expansion,
Using similar arguments, we also have
where
. By the concavity of function
, we obtain that
. Therefore,
Step 2: Derive expression of
From Step 1, ,
satisfy the following equation:
(A1)
(A1) where
and
. Taking derivative with respect to
yields:
From this equation we obtain
with
Taking derivative on (EquationA1
(A1)
(A1) ) with respect to
, we get
It follows that
where
By similar calculations with Cui et al. (Citation2011),
Therefore,
We further denote
It is easy to see that
(A2)
(A2)
Step 3: The asymptotic normality of and
.
From estimating Equations (Equation8(8)
(8) ) and (Equation9
(9)
(9) ),
where
Based on (EquationA2(A2)
(A2) ), we have
By Taylor expansion,
where
From the result of Step 1,
It is easy to see that
By CLT,
has asymptotic normal distribution with zero-mean. Denote
, we have
Using simple calculation,
Denote
,
Therefore, when
,
Denote . An application of multivariate delta-method yields
where
.
Proof of Theorem 3.2
Proof of Theorem 3.2
From Theorem 3.1, . We write
Hence the asymptotic distribution of
is the same as that of
. Based on the result of Step 1, we now derive the asymptotic variance of
. Denote
, we have
where
Therefore, we have
where
.