
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Dose–response experiments and data analyses are often carried out according to an optimal design under a model assumption. A two-parameter logistic model is often used because of its nice mathematical properties and plausible stochastic response mechanisms. There is an extensive literature on its optimal designs and data analysis strategies. However, a model is at best a good approximation in a real-world application, and researchers must be aware of the risk of model mis-specification. In this paper, we investigate the effectiveness of the sequential ED-design, the D-optimal design, and the up-and-down design under the three-parameter logistic regression model, and we develop a numerical method for the parameter estimation. Simulations show that the combination of the proposed model and the data analysis strategy performs well. When the logistic model is correct, this more complex model has hardly any efficiency loss. The three-parameter logistic model works better than the two-parameter logistic model in the presence of model mis-specification.
MSC 2010:
1. Introduction
Dose–response experiments are routinely conducted to study the relationship between the dose of a stimulus and the response of the experiment subjects. Simple and easy-to-interpret models are preferred for the dose–response relationship. The goal of the experiment is often to accurately determine the median dose level: the level of stimulant at which half the recipients respond. Other effective dose levels are also of interest.
There has been much discussion of optimal designs where the dose–response relationship is completely known (Ford et al., Citation1985; Sitter & Fainaru, Citation1997; Sitter & Forbes, Citation1997; Sitter & Wu, Citation1993; Wu, Citation1985). In applications, one may first run a pilot study to obtain an estimate of the dose–response relationship. The optimal design based on the fitted model is then used to guide further experiments (P. Li & Wiens, Citation2011; Wang et al., Citation2013; Wu & Tian, Citation2014). A full sequential approach can also be used: the parameter estimates are updated after each run, and the result is used to suggest dose levels for the subsequent runs.
Naturally, if the model is mis-specified, the optimal design is misguided and the effective dose levels can be poorly estimated. One way to reduce the risk of model mis-specification is to apply a more flexible and hence more complex dose–response model. We seek a trade-off between model flexibility and inference efficacy. A nonparametric model is the most flexible and free from the risk of model mis-specification. However, it likely needs more experiment runs to achieve the same estimation precision as an analysis under approximately valid parametric assumptions. The commonly used logistic or probit models are simple and have good mathematical and statistical properties. They are satisfactory in many applications, but their model assumptions impose restrictions on the dose–response relationship. A slightly more complex model can lower the risk of mis-specification without complicating the issues related to optimal design and data analysis (El-Saidi, Citation1993; G. Li & Majumdar, Citation2008; O'Brien et al., Citation2009).
In this paper, we study the design and analysis problems for a three-parameter logistic regression model. We develop an easy-to-implement iterative numerical algorithm with guaranteed convergence for the maximum likelihood estimate (MLE). We investigate the effectiveness of the sequential ED-design (Yu et al., Citation2016) and the D-optimal design. The ED-design optimises the estimation of targeted effective dose-levels while the D-optimal design targets model parameters. See Sections 3.3 and 3.2. We use the vertex direction method (VDM) to find the D-optimal design.
Simulation studies show that the combination of the proposed model, design, and data analysis strategy performs well. When the logistic model is correct, the three-parameter model has little efficiency loss. When the three-parameter model holds but the logistic model is violated, the new approach is more efficient.
The paper is organised as follows. In Section 2, we introduce the three-parameter logistic model and a numerical algorithm for the MLE. Design problems under this model are discussed in Section 3. In Section 4, we present some simulation results and an example. Section 5 provides concluding remarks.
2. Three-parameter logistic model and the MLE
Consider a dose–response experiment in which a stimulant at level X is applied to a subject. The subject either responds (Y = 1) or does not respond (Y = 0) to the stimulus. The dose–response relationship is defined to be
In most applications, we envisage
as a smooth increasing function of x. Based on data collected on the response values,
, for selected dose levels,
, scientists may be interested in the accurate estimation of a specific dose level
at which
. We use edγ to denote the effective dose level at which the probability of response is
. One may also focus on the shape of
for x between, for example, ed25 and ed75.
If one is interested in a single ED level, effective statistical inference is possible without a parametric assumption on . If a detailed dose–response relationship is desired over a dose range, then a suggested parametric form
is likely necessary and helpful. A commonly employed model for
is the logistic dose–response relationship:
(1)
(1) for parameters α and β. In applications, the dose level may be log-transformed before the logistic or other model is applied (G. Li & Majumdar, Citation2008; O'Brien et al., Citation2009). In addition to its mathematical convenience, the logistic regression model permits the interpretation of the size of β. For example, in epidemiology, when Y stands for catching a disease and x for the exposure level, the value of β is the log-odds ratio of catching the disease when the exposure level is increased by a unit.
Statisticians and scientists are keenly aware that the logistic and other two-parameter models can be poor approximations of the true dose–response relationship. A more flexible model can be advantageous if it is not too complex. One such choice is a three-parameter logistic dose–response model (El-Saidi, Citation1993):
(2)
(2) We require
to ensure that
is between 0 and 1, and we do not place restrictions on α and β.
We note that when , the three-parameter model becomes the commonly used logistic model. In this case, for any
, the model satisfies
assuming
. Such a restriction is hard to justify in applications. The introduction of the parameter λ helps to soften this restriction without overburdening the system. Under this model, the effective dose level at γ is given by
An explicit expression for the dose–response relationship is
As discussed in Yu et al. (Citation2016), many sequential designs, including the ED-design, contain a step to update the estimate of the model parameters. The MLE is a common choice.
2.1. Numerical method for MLE
Let be observations from a dose–response experiment and assume model (Equation2
(2)
(2) ). The log-likelihood based on this data set is given by
where
.
When is fixed, the model becomes the usual logistic model, and
is known to be concave in α and β. The concavity permits a simple numerical solution to the MLE of α and β. We remark that when the
's corresponding to y = 1 are completely separated from those corresponding to y = 0, the maximum point
. This problem is easily avoided by adding informative pseudo-observations, as in Yu et al. (Citation2016), and this is done implicitly in our calculations.
Given any value of λ, the log-likelihood is concave in α and β. Given any α and β, the log-likelihood is concave in λ. Because of these properties, the following two-loop iterative numerical algorithm works nicely. We start with the initial value and set k = 0. Let ε be a small positive value such as
.
Let
. Use an iterative algorithm to solve
Let
In the above presentation, we have used and
as two different functions. The objective functions in both loops are concave, and they thus guarantee the convergence of any sensible iterative procedures that we may use in these two steps, and hence of the entire algorithm. We state the concave conclusions in two lemmas.
Lemma
Function in Step (2) is concave in λ given any data set
for
with
.
Proof.
To prove the concavity, it suffices to show that the second derivative of this function is always nonnegative. Straightforward algebra shows that
and subsequently
since
for all i. Therefore, the function is concave as claimed.
Lemma
Given any data set for
with
, the objective function
in Step (1) is concave in
given any
.
Proof.
For notational simplicity, we will drop the superscript k and subscript n from and denote it simply as
in this proof. We start with the case where n = 1, so we also drop the summation and the subindex i. To prove this result, it suffices to show that the Hessian matrix
is positive definite. We have
and
We now show that the above second derivative is less than or equal to 0. Note that the first factor in
is nonnegative, so we need to determine only the sign of the second factor. We consider the cases y = 1 and y = 0 separately.
When y = 1, the first term in the second factor vanishes, and the second term is clearly less than or equal to 0.
When y = 0, the second factor becomes
Denote its numerator as , with derivative
where we have used the inequality
. Combining this with the fact that
, we find
for all
. This further implies
when y = 0.
Combining (a) and (b), since y is either 0 or 1, we conclude that for all ,
To complete the proof, we note that
Therefore, in the sense of nonnegative definiteness, we find
When the design contains n dose levels, the Hessian matrix is the sum of n nonnegative definite matrices. Hence, it remains nonnegative definite. This completes the proof.
By these two lemmas, is an increasing sequence in k with upper bound 0. Hence,
has a finite limit as
. The corresponding
likely converges to at least a local maximum point. A rigorous discussion of the global maximum can be tedious and distracting; we do not pursue the issue in this paper.
3. Designs for the three-parameter logistic model
The choice of a new model leads to routine derivations rather than new design issues. All the optimality criteria may be applied to the three-parameter logistic model (Equation2(2)
(2) ), and we discuss some specific issues below.
3.1. Up-and-down design
The up-and-down design and its variations do not require a parametric model on the dose–response relationship . This design is used for the purpose of accurately estimating a specific effective dose level edγ such as ed50. It requires the user to choose beforehand a grid of dose levels
for some K based on prior information on
such that
.
The experiment starts by assigning a stimulus at level in Ω to the subject. If the subject responds, the level is decreased to
, and otherwise it is increased to
. Special rules apply if
is on the boundary of Ω. Variations may include staying at
with a specific positive probability related to the target edγ, and a nonparametric estimate of edγ may be used. Our experience shows that such estimators are not efficient. In the simulations, we use the MLE under the assumed model and estimate edγ even though the data are generated according to an up-and-down design.
3.2. D-optimal design and the vertex direction method
The variance–covariance matrix of the MLE of the parameter θ is well approximated by when the number of runs n is large, where
is the Fisher information. A D-optimal design
maximises the determinant of
. Under the (two-parameter) logistic response model,
is a uniform distribution on ed17.6 and ed82.4; and under the probit model,
is a uniform distribution on ed12.8 and ed87.2 (Sitter & Wu, Citation1993).
As far as we are aware, there have been no direct results on the D-optimal design for the three-parameter logistic model. We can apply a numerical method called VDM (Fedorov, Citation1972; Wu, Citation1978; Wynn, Citation1972). We implemented this method via an R function to obtain approximate D-optimal designs for the simulation studies. Some particulars are as follows.
A nonsequential design is composed of a set of dose levels and the numbers of units applied at these levels
. Mathematically, a design is a distribution Ψ on
with probability mass function
where n is the total number of units in the experiment. Let the Fisher information of the observations obtained under Ψ be
, and let
be the design assigning dose level x to all the units. We use
for
. It can be seen that
The popular D-optimal design is defined to be
Define the directional derivative
For the three-parameter logistic regression model (Equation2
(2)
(2) ),
where the constant 3 is the dimension of
. It is known that
is the D-optimal design if and only if
for any x. Starting from an initial design
, VDM searches for
and
It updates
via
until the determinant of the Fisher information stops increasing.
Under the three-parameter logistic model, the optimal design depends on the λ values but not the values. We implement VDM with an R function for the three-parameter logistic model (Equation2
(2)
(2) ). The D-optimal designs for a number of λ values are given in Table . Up to potential round-off error, all the D-optimal designs are found to be uniform distributions on three dose levels. In the future, we hope to show that this is always true.
Table 1. D-optimal design for three-parameter logistic models.
3.3. ED-design
The D-optimal design and many other optimal designs focus on the precision of the parameter estimation under the assumed model. The form of the parameter under consideration is generally that permitting the most convenient analytical presentation of the dose–response model. Under the three-parameter logistic regression model, for instance, one naturally takes as the target parameter. In applications, we are more interested in precisely estimating ed levels. Hence, the ED-design to be introduced is more relevant.
Let for some smooth function g with gradient function
. The variance of its MLE is approximately
(3)
(3) The ED-design aims to minimise
(4)
(4) given m selected ed levels
among all possible designs Ψ. Clearly, the solution depends on the value of the unknown parameter θ. One may avoid this difficulty with a sequential design.
Suppose the experiment has been carried out at dose levels with response values
. Let
be the intermediate MLE of θ based on the data obtained from these i trials. Let
be the Fisher information based on the first i trials and the potential
th trial to be run at dose level x. We choose the next dose level x that minimises
(5)
(5) This rule is applied until a sufficient number of trials is obtained. The outcome is a sequential ED-design.
The sequential ED-design needs an initial set of trials and the corresponding . We recommend and use a uniform initial design on a set of doses
for K = 7, with
and
being equally spaced grids between the perceived ed01 and ed99.
4. Simulation studies
We conduct simulation studies to explore several issues related to the use of the three-parameter logistic regression model (Equation2(2)
(2) ) for the dose–response experiment. We use N = 1000 repetitions for all model/design combinations. The sample sizes are chosen to be n = 30, 60, and 120. We choose three effective dose levels each time as the estimation targets and obtain their MLEs. For each model/design setting, we compute the RMSE of a single ed level as
where
is the estimate of the ED-level
in the rth repetition. The total RMSE is computed as
Three designs are included in the simulation. One is the up-and-down design whose implementation does not depend on the model, but a specific target ed level will be indicated in the summary of the results. We choose a set of doses
, with
and
being equally spaced grids between the anticipated ed01 and ed99. We simulate on the D-optimal design and the sequential ED-design, assuming the relevant knowledge of the dose–response model as discussed in the last section. For the sequential ED-design, we use a uniform initial design on Ω as specified for the up-and-down design.
The simulations answer several questions related to the combination of the ED-design and the three-parameter model for the dose–response experiment. The first question concerns the performance of the ED-design. Does it have any advantages over other designs under a three-parameter model? The results indicate that the ED-design works well. The second question concerns whether or not the three-parameter model is necessary. If the true relationship is the three-parameter rather than the two-parameter logistic model, then using the correct model is expected to be helpful. The results show that for ed levels over a local region, it is important to apply the correct three-parameter model. Finally, if the true dose–response relationship is a two-parameter logistic model, how much efficiency do we lose by using a more complex three-parameter model? The results show that the loss is limited.
4.1. Three-parameter model both true and assumed
We generate data according to the three-parameter logistic regression model (Equation2(2)
(2) ) with
,
,
, and
,
,
in two separate simulations. We target three sets of dose levels: (a) ed25, ed50, ed75; (b) ed10, ed25, ed40; and (c) ed60, ed75, ed90. The corresponding dose–response curves are depicted in Figure .
Figure 1. Dose–response curves in the simulation.
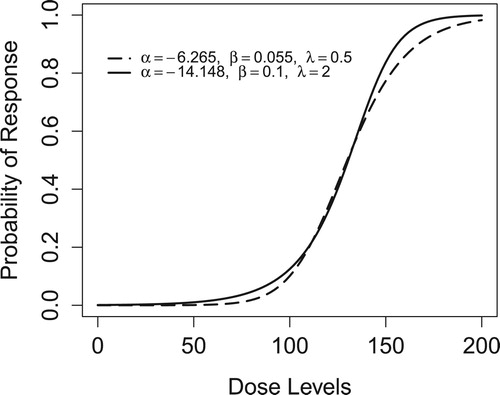
The up-and-down design requires a single target ed level. In the simulation, we always take the middle level as its target. The ed01 and ed99 values under are (74, 211); the ed01 and ed99 values under
are (49, 180). These values are used to determine the first-stage design Ω. The results are reported in Table .
Table 2. RMSEs when fitting data from three-parameter logistic models under a number of designs.
We observe that the RMSEs under each design decrease as n increases. Their sizes are not dramatically different, but those of the D-optimal design are higher. The sequential ED-design has the best overall performance. The up-and-down design gives the lowest RMSEs for a single ed level. This is expected because D-optimality aims for precise estimation of θ, not the ed levels, and the up-and-down design was not intended for the estimation of ed levels under a parametric model. Nevertheless, it is nice to find that the sequential ED-design works well.
4.2. Applying a three-parameter logistic model when two parameters suffice
When the two-parameter logistic model is appropriate but a three-parameter model is assumed, the results are likely suboptimal. In this section, we examine the degree of efficiency loss. We generate dose–response data from the two-parameter logistic regression model and analyse the data under both two-parameter and three-parameter models. We consider only the D-optimal design and the sequential ED-design. The up-and-down design is not included because it does not depend on the model assumption, although the data analysis could be performed under some model assumption.
In this simulation, we generate data from the two-parameter logistic model:
The results are presented in Table . The first two columns are obtained under the correct two-parameter model assumption. The D-optimal design in this case is a uniform distribution on ed17.6 and ed82.4, which is well known but not used in applications. The remaining columns are obtained under the three-parameter model, which is also correct but more complex than necessary.
Table 3. RMSEs when fitting three-parameter model to data from two-parameter model.
These results show that the ED-design has advantages over the D-optimal design: the simulated RMSEs under the former are always lower than those under the latter. The efficiency gain can be as much as 40%.
In addition, the use of the more complex three-parameter model does not significantly reduce the efficiency. When we target ed10, ed25, and ed40, the total RMSE increases from 17.93 to 18.36 when the sample size n = 30. This loss is below 2.5%. The worst case is when n = 120: the efficiency loss is 5.6%.
In comparison, the efficiency of the D-optimal design can be strongly affected. When we target ed60, ed75, and ed90 and n = 120, the efficiency loss is as high as 18%. When n = 30, the use of the more complex model makes the D-optimal design more efficient. This may be because that the initial design takes a large proportion of the number of trials.
Overall, if the ED-design is used, the use of a three-parameter model does not greatly affect the efficiency in the estimation of the ed levels.
4.3. Effects under model mis-specification
In this section, we investigate the effect of two kinds of model mis-specification: (a) the dose–response relationship satisfies the three-parameter logistic regression model with , and (b) the relationship is not a three-parameter logistic model.
In both situations, we compute the RMSEs of the ed estimates in two settings: the design and analysis are done under (i) the three-parameter model assumption, and (ii) the usual two-parameter model assumption. We examine the accuracy of the design and analysis in both cases.
For (a), we generate data from two three-parameter models:
(6)
(6) with
, and
(7)
(7) with
. Under model (Equation6
(6)
(6) ), ed25 = 114, ed50 = 130, and ed75 = 148; and under model (Equation7
(7)
(7) ), ed25 = 114, ed50 = 130, and ed75 = 144. The results are presented in Table . The first two columns are obtained under the two-parameter assumption. The D-optimal design in this case is a uniform distribution on ed17.6 and ed82.4. The remaining columns are obtained under the correct three-parameter assumption.
Table 4. RMSEs when fitting three-parameter model to data from three-parameter model.
We observe that the ED-design is noticeably superior to the D-optimal design in both situations: the simulated RMSEs under the former are always lower than those under the latter. The efficiency gain can be as much as 30%.
In addition, the use of the three-parameter model when the data are generated under that model significantly increases efficiency. When and we target ed25, ed50, and ed75, the total RMSE decreases from 15.57 to 14.02 when n = 30, a gain of 11%. Overall, the use of the three-parameter model makes the ED-design more efficient.
For (b), we generate data from the three-parameter probit model:
(8)
(8) with
, and
(9)
(9) with
. Under this model, ed25 = 114, ed50 = 124, and ed75 = 134 when
; and ed25 = 86, ed50 = 102, and ed75 = 117 when
. The results are presented in Table . The first two columns are obtained under the two-parameter assumption. The D-optimal design in this case is a uniform distribution on ed12.8 and ed87.2. The remaining columns are obtained under the three-parameter assumption. Both model assumptions are incorrect, but is it better to use the three-parameter logistic model with the ED-design?
Table 5. RMSEs when fitting three-parameter model to data from probit model.
Clearly, the ED-design is noticeably superior to the D-optimal design in both situations: the simulated RMSEs under the former are always lower than those under the latter. When and we target ed10, ed25, and ed40, the total RMSE decreases from 12.89 to 8.39 when n = 30, a gain of 54%.
In addition, the use of the more complex model when the data are generated under the three-parameter probit model noticeably increases the efficiency. When we target ed60, ed75, and ed90 with the total RMSE decreases from 8.29 to 7.12 when n = 30, a gain of 16%. Overall, combining the more complex model with the ED-design leads to efficiency gains when the model is mis-specified.
4.4. Example
Brown (Citation1982) assumed a three-parameter logistic response model for the relationship between the wheezing symptom and the age of British coal miners. The number of subjects examined and the number with the symptom can be found in their paper.
We first fit the observed data using model (Equation2(2)
(2) ). The MLEs of the model parameters are
,
, and
. We then fit the observed data using a simple logistic model. The MLEs of the model parameters are
and
. For comparison, Figure shows the observed data and the two fitted curves.
Figure 2. Observed data and fitted curves for British coal miners.
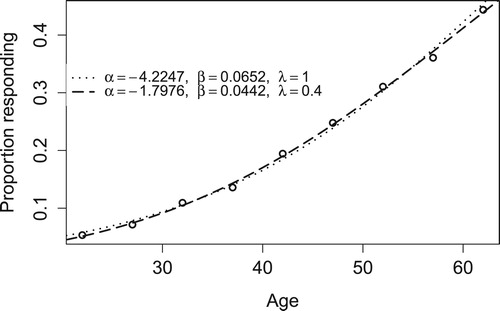
Based on fitted two-parameter and three-parameter models, the age at which 25% coal miners will develop the symptoms is 47.7 and 48.1, respectively. Both match the real data closely. The three-parameter model predicts the ages at which 50% and 75% of miners develop the symptoms are 66.8 and 88.7, respectively. In comparison, these figures are 65.0 and 81.9 based on the two-parameter model. While two models give very different numbers, predicting the proportion based on either model is not reliable at age 80 due to extreme extrapolation. At each observed ED level, we compute the corresponding age based on fitted models and the difference to the observed age. The resulting sum of squares (weighted) is 6906 for the three-parameter model and 15,420 for the two-parameter model. The use of the three-parameter model provides a much-improved fit.
5. Concluding remarks
We have explored the use of a three-parameter logistic regression model for dose–response experiments. The sequential ED-design can easily be applied to this model, and the resulting data analysis is effective.
Simulation results show that the three-parameter logistic regression model is an effective extension of the commonly used two-parameter model that does not lead to more complex data analysis issues. The combination of the ED-design and the data analysis strategy works well. When the logistic model is correct, the more complex model has hardly any efficiency loss. When the three-parameter model holds but the logistic model is violated, the new approach gains substantial ground. It will be a useful addition to the toolbox for dose–response experiments.
Acknowledgments
The authors gratefully acknowledge the fundings from the National Natural Science foundation of China, 11871419 and the Natural Science and Engineering Research Council of Canada.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Xiaoli Yu
Dr. Xiaoli Yu is currently self-employed.
Shaoting Li
Dr. Shaoting Li is an associate professor at the School of Statistics, Dongbei University of Finance and Economics.
Jiahua Chen
Jiahua Chen is Canada Research Chair, tier I at the Department of Statistics, University of British Columbia.
References
- Brown, C. C. (1982). On a goodness of fit test for the logistic model based on score statistics. Communications in Statistics - Theory and Methods, 11(10), 1087–1105. https://doi.org/10.1080/03610928208828295
- El-Saidi, M. A. (1993). A power transformation for generalized logistic response function with application to quantal bioassay. Biometrical Journal, 35(6), 715–726. https://doi.org/10.1002/(ISSN)1521-4036 doi: https://doi.org/10.1002/bimj.4710350609
- Fedorov, V. V. (1972). Theory of optimal experiments. Elsevier.
- Ford, I., Titterington, D. M., & Wu, C. F. J. (1985). Inference and sequential design. Biometrika, 72(3), 545–551. https://doi.org/10.1093/biomet/72.3.545
- Li, G., & Majumdar, D. (2008). D-optimal designs for logistic models with three and four parameters. Journal of Statistical Planning and Inference, 138(7), 1950–1959. https://doi.org/10.1016/j.jspi.2007.07.010
- Li, P., & Wiens, D. P. (2011). Robustness of design in dose-response studies. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 73(2), 215–238. https://doi.org/10.1111/rssb.2011.73.issue-2 doi: https://doi.org/10.1111/j.1467-9868.2010.00763.x
- O'Brien, T. E., Chooprateep, S., & Homkham, N. (2009). Efficient geometric and uniform design strategies for sigmoidal regression models. South African Statistical Journal, 43(1), 49–83. https://journals.co.za/content/sasj/43/1/EJC119263.
- Sitter, R. R., & Fainaru, I. (1997). Optimal designs for the logit and probit models for binary data. Canadian Journal of Statistics, 25(2), 175–190. https://doi.org/10.2307/3315730
- Sitter, R. R., & Forbes, B. (1997). Optimal two-stage designs for binary response experiments. Statistica Sinica, 7(4), 941–955. https://doi.org/10.2307/3315730.
- Sitter, R. R., & Wu, C. (1993). Optimal designs for binary response experiments: Fieller, D, and A criteria. Scandinavian Journal of Statistics, 20(4), 329–341.
- Wang, L., Liu, Y., Wu, W., & Pu, X. (2013). Sequential LND sensitivity test for binary response data. Journal of Applied Statistics, 40(11), 2372–2384. https://doi.org/10.1080/02664763.2013.817546
- Wu, C. (1978). Some algorithmic aspects of the theory of optimal designs. The Annals of Statistics, 6(6), 1286–1301. https://doi.org/10.1214/aos/1176344374
- Wu, C. F. J. (1985). Efficient sequential designs with binary data. Journal of the American Statistical Association, 80(392), 974–984. https://doi.org/10.1080/01621459.1985.10478213
- Wu, C. F. J., & Tian, Y. (2014). Three-phase optimal design of sensitivity experiments. Journal of Statistical Planning and Inference, 149, 1–15. https://doi.org/10.1016/j.jspi.2013.10.007
- Wynn, H. P. (1972). Results in the theory and construction of D-optimum experimental designs. Journal of the Royal Statistical Society, Series B, 34(2), 133–147.
- Yu, X., Chen, J., & Brant, R. (2016). Sequential design for binary dose-response experiments. Journal of Statistical Planning and Inference, 177, 64–73. https://doi.org/10.1016/j.jspi.2016.04.005