
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Gradient descent (GD) algorithm is the widely used optimisation method in training machine learning and deep learning models. In this paper, based on GD, Polyak's momentum (PM), and Nesterov accelerated gradient (NAG), we give the convergence of the algorithms from an initial value to the optimal value of an objective function in simple quadratic form. Based on the convergence property of the quadratic function, two sister sequences of NAG's iteration and parallel tangent methods in neural networks, the three-step accelerated gradient (TAG) algorithm is proposed, which has three sequences other than two sister sequences. To illustrate the performance of this algorithm, we compare the proposed algorithm with the three other algorithms in quadratic function, high-dimensional quadratic functions, and nonquadratic function. Then we consider to combine the TAG algorithm to the backpropagation algorithm and the stochastic gradient descent algorithm in deep learning. For conveniently facilitate the proposed algorithms, we rewite the R package ‘neuralnet’ and extend it to ‘supneuralnet’. All kinds of deep learning algorithms in this paper are included in ‘supneuralnet’ package. Finally, we show our algorithms are superior to other algorithms in four case studies.
1. Introduction
In recent years, the scale of the industrial application system has expanded rapidly and industrial application data generated with the exponential growth due to the recent advance in computer and information technology. Big Data brings allround thinking revolution, industrial revolution, and management revolution because Big Data has vast amounts of data status and cloud service-level data processing ability, and Big Data has Volume, Velocity, Variety, and Veracity (also called 4V) characteristics. The data of enterprises has reached hundreds of TBs or hundreds of PBs which has been far beyond the processing capacity of traditional computing technology and information system. Therefore, to study effective Big Data processing technology, methods, and measurements have become urgent requirements in our daily lives.
Viktor Mayer-Schonberger, who is known as ‘the Prophet of Big Data Era’, lists a large number of detailed cases of Big Data applications in his book ‘Big Data: A Revolution That Will Transform How We Live, Work, and Think (Schonberger & Cukier, Citation2013)’. He analysed and predicted the development and trends of Big Data, and put forward many important ideas and development strategies. He said Big Data opens up a great transformation stage and stated that Big Data will bring great changes. It will change our lives, work and way of thinking, change our business mode, and change our economics, politics, technologies, societies, and so on.
‘The Outline of Promoting Development of Big Data’ was published by the State Council of China in September 2015. The Prime Minister of China Keqiang Li said we should deploy Big Data program systematically. The ‘Outline’ showed us how to promote Big Data development and application, to create accurate control and the collaborative new social governance mode in the next 5 to 10 years. Big Data can establish a new mechanism of economic operation, which is safe, efficient, and operates steadily. Big Data also can construct a new system about public services which is people oriented and benefits all, can open the new pattern of innovation driven which makes more people to have the sense of entrepreneurship and innovation, can cultivate the new environment of industry development which is intelligent, smart, and prosperous.
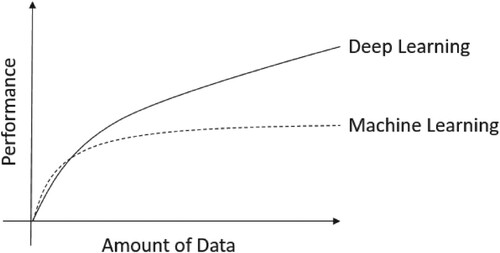
Machine learning and deep learning are very important big data processing technologies. Especially for deep learning, which is very popular in industry and academia in recent years. An important reason is that Google has developed AlphaGo. AlphaGo is the first artificial intelligence system that defeated professional Go players, and the first one defeated the Go world champion. It was developed by a team led by Demis Hassabis from Google's DeepMind company, and its main working principle is ‘deep learning’. AlphaGo uses many new technologies, such as neural networks (Flach, Citation2012), deep learning (Lisa, Citation2015), Monte Carlo tree search (Bishop, Citation2006; Murphy, Citation2012) etc., which has made a substantial power in training data and prediction. The performance of deep learning is shown in Figure . It can be seen from the figure that as the amount of data increases, compared with machine learning, the performance of deep learning becomes better and better.
Figure 1. The performance comparison of deep learning and machine learning.
Feedforward neural networks are the most basic type of artificial neural networks. The connections between neurons in the network do not form a cycle. Feedforward neural networks are the first type of artificial neural networks. The reason why they are called feedforward is because the information in these networks is only forwarded, do not have loops. The information first through the input nodes, then through the hidden nodes (if present), and finally through the output nodes (Nielsen, Citation2019). In industry and academia, a neural network is called deep learning which has at least one hidden layer.
Gradient descent (GD) algorithm is an optimisation algorithm used to minimise some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient. In artificial neural networks, backpropagation is a specific implementation method of the gradient descent algorithm. The name of the backpropogation algorithm originates from the process of calculating the gradient of the neural network, which is actually calculated backward (Rumelhart & McClelland, Citation1986). It is the most extensively used algorithm for training multilayer feedforward neural networks. Given an artificial neural network and an error function, then backpropagation is mainly to calculate the gradient of the error function with respect to the weights of the neural network. However, throughout the current books and literatures (Chen, Citation2016; Gordon, Citation2018; Le, Citation2015; Magoulas et al., Citation1997; Moreira & Fiesler, Citation1995), the mathematical representations of the backpropagation algorithm are different. This paper will present it in the subsequent sections with mathematical formulas.
The actual proceeding is that the gradient of the last layer of weights are calculated first, and the gradient of the first layer of weights are calculated last. When calculating the gradient of the previous layer, the partial derivatives which have been calculated in the current layer can be reused. This technique can be clearly seen when introducing deep learning neural networks in subsequent sections, and it is also very important in programming. It can not only save the time of program running, but also save the memory used by this program. Therefore, the backwards flow of the error information makes the gradient of the weights of each layer can be calculated efficiently, instead of using a very naive method to calculate the gradient separately.
The popularity of backpropagation has been reappeared in recent years, the main reason is that deep neural networks have obvious advantages in image recognition and speech recognition. Backpropagation is an iterative gradient descent algorithm. With the cooperation of Graphics Processing Unit (GPU), its performance has been greatly improved. However, from Churchland and Sejnowski (Citation2016), Rumelhart et al. (Citation1986), it is well known that such a learning scheme can be very slow. So various methods have been created to improve the conventional backpropagation efficiency. Momentum algorithms, first proposed by Polyak (Citation1964), are well known techniques to accelerate deterministic smooth convex optimisation. Recently, Lan (Citation2009, Citation2012) and Deng et al. (Citation2018) have incorporated these techniques into optimisation.
Intuitively, the reason for using the momentum is that the GD algorithm is very slow when the error function surface is a very long and narrow valley. In this case, the gradient direction of the GD algorithm is almost perpendicular to the long axis of the valley. This causes the iteration to oscillate back and forth in the short axis while moving very slowly in the long axis of the valley. Qian (Citation1999) pointed out that the role of momentum is to correct the gradient direction from the short axis to the long axis of the valley.
Besides, other methods have also been proposed for improving the speed of convergence of GD algorithm. The conjugate gradient algorithm has been shown to be superior to the GD algorithm in most applications, see Press et al. (Citation1992). But this algorithm is less biologically plausible and harder to implement on hardware. Qian (Citation1999) indicated the momentum algorithm appears to be dominant in the connectionist learning literature. The Polyak momentum (PM) algorithm does not converge in relatively simple convex optimisation problems. Nesterov (Citation1983, Citation2004) made further improvements to the PM algorithm, which was later called the Nesterov accelerated gradient (NAG) algorithm. Nesterov's idea is that the improved algorithm should have the same acceleration effect as the PM algorithm, but it must converge for general convex functions optimisation problems. Finally, Nesterov proposed a pair of sister sequences which have correction effect on the direction of the iteration points of the algorithm.
In the global optimisation problems, Shah et al. (Citation1964) and Petalas and Vrahatis (Citation2004) used the parallel tangent method to improve the GD algorithm and speed up its convergence. The main idea of the parallel tangent method is that during the iteration, it use the parallel tangent direction occasionally instead of the gradient descent direction . Based on NAG algorithm, parallel tangent method, and some properties of optimal gradient descent with quadratic function, we propose a three-step accelerated gradient (TAG) algorithm, which has three sequences.
This paper mainly researches the TAG algorithm and applies it to deep learning, and compares it with the traditional GD algorithm, PM algorithm, and NAG algorithm. The rest of the paper proceeds as follows. Section 2 introduces GD, PM and NAG algorithms, then the TAG algorithm is developed, implements them to the quadratic function. Then the paper conducts experiments to high-dimensional functions, which help us to understand TAG with the fastest convergence among these four algorithms. Section 3 introduces deep learning and backpropagation algorithm. Then the TAG algorithm is added to the backpropagation algorithm. Since the R language package ‘neuralnet’ only contains the GD algorithm, we write a new package ‘supneuralnet’, which extend the PM algorithm, NAG algorithm, and TAG algorithm to the ‘neuralnet’ package. We also add the stochastic gradient descent (SGD) algorithm to the package, which is convenient to implement these algorithms. Section 4 applies the four algorithms to the iris and spiral data sets in the deep learning framework, to compare their classification effects and convergence speed. The proposed algorithm performs best. Section 5 combines the SGD algorithm with the four algorithms mentioned in Section 2, and applies them to the iris and spiral data sets under the deep learning framework to compare their classification effects and convergence speed. The proposed algorithm also performs best. Finally we draw conclusions in Section 6.
2. Three-step accelerated gradient algorithm
2.1. Gradient descent algorithm
From Yin (Citation2015), we have the main iteration steps of GD algorithm are
(1)
(1) for
. Here
is a differentiable function, its gradient is
, and α is step size.
Assume that A is symmetric and positive definite ( for any
). Consider the quadratic function
(2)
(2) with
(3)
(3) Let
Then we can show GD iteration trajectory.
From Figure , the initial point is . The grey elliptic curves are contour lines which mean the objective function values in each elliptic curve are equal. After first iteration, initial point
jumps to
. Then with the following iteration, the point jumps step by step, finally to the optimal point
.
As we can see from Figures –, all converge to the optimal point . While different learning rates lead to different number of iteration steps, 117, 54, 44 respectively. So the larger learning rate means fewer iteration steps, but too large learning rate will lead to divergency of the algorithm.
Figure 2. Illustration of GD iteration trajectory with learning rate 0.05.
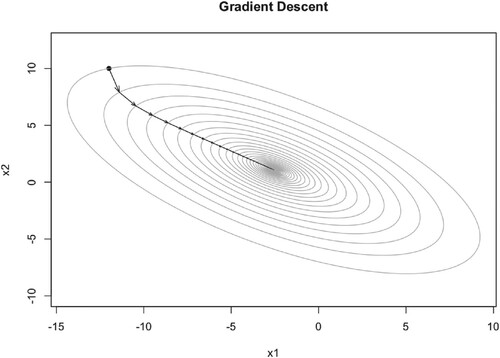
Figure 3. Illustration of GD iteration trajectory with learning rate 0.1.
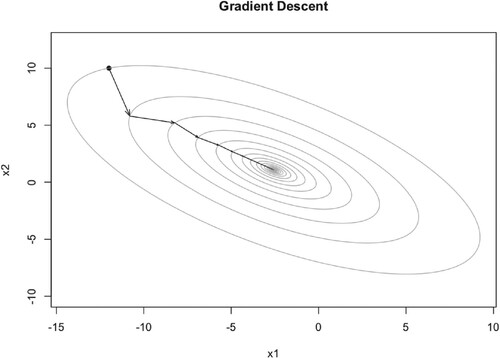
Figure 4. Illustration of GD iteration trajectory with learning rate 0.12.
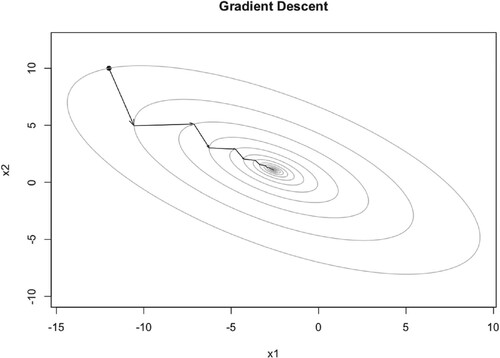
The learning rates above all are constant. Actually we can use alterable learning rate during iteration. The optimal gradient descent (OGD) is an effective method if the function is not difficult.
We start from any , set
(4)
(4) Then
(5)
(5) Equation (Equation5
(5)
(5) ) is the OGD learning rate.
From Figure , we can see that the OGD algorithm converges to the optimal point , and the number of iteration steps is 41.
Figure 5. Illustration of OGD iteration trajectory.
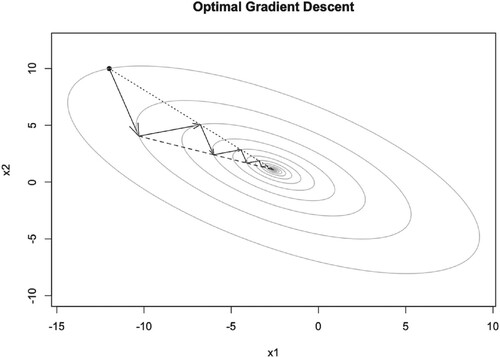
There are some properties of OGD algorithm with quadratic function. We can find that ,
etc. are maybe in one line (dotted lines in Figure ). The same for the dashed lines. If it is true, then we can accelerate GD algorithm. We will discuss it later.
2.2. Polyak momentum algorithm
The learning scheme of the general gradient descent can be very slow sometime. The addition of a momentum term has been found to increase the rate of convergence dramatically, see Qian (Citation1999). With this method, (Equation1(1)
(1) ) takes the form
(6)
(6) for
.
If and
in (Equation6
(6)
(6) ), we call it Polyak momentum (PM) algorithm. PM algorithm is also called heavy-ball method in some literatures, see Polyak (Citation1964). Here μ is the momentum parameter. That is, the modification of the vector at the current time step depends on both the current gradient and the change of the previous step. Intuitively, the rationale for using the momentum term is that the GD algorithm is particularly slow when the error function surface is a very long and narrow valley. In this situation, the gradient direction of the GD algorithm is almost perpendicular to the long axis of the valley. This causes the iteration to oscillate back and forth in the short axis while moving very slowly in the long axis of the valley. Rumelhart and McClelland (Citation1986) also showed the momentum term helps average out the oscillation along the short axis while at the same time adds up contributions along the long axis.
We can also show PM algorithm iteration trajectory with different momentum parameter μ. When , PM algorithm is GD algorithm. That is to say, the GD algorithm is just a special case of PM algorithm.
As we can see, when μ is small, for example , PM algorithm converges to the optimal point
very fast, see Figure . But when μ becomes larger, it converges to the optimal point slowly. However, the iteration points always cross the optimal point, see Figures and . The dashed arrow starts from initial point and we can not use the momentum parameter at this time. The number of iteration steps are given in Tables , which will be discussed later.
Figure 6. Illustration of PM iteration trajectory with and
.
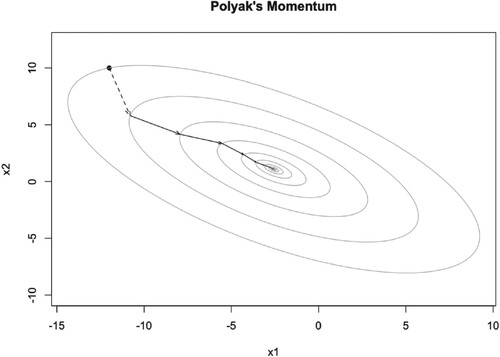
Figure 7. Illustration of PM iteration trajectory with and
.
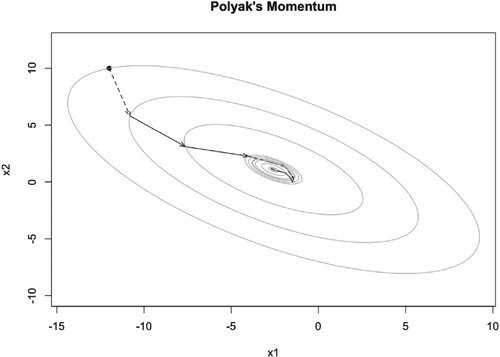
Figure 8. Illustration of PM iteration trajectory with and
.
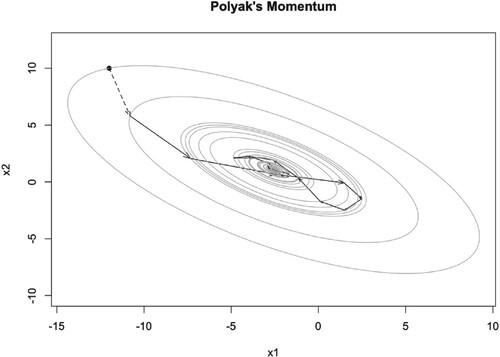
Table 1. Iteration steps of PM, NAG, and TAG algorithms with learning rate , while the steps of GD algorithm is 117.
Table 2. Iteration steps of PM, NAG, and TAG algorithms with learning rate , while the steps of GD algorithm is 54.
Table 3. Iteration steps of PM, NAG, and TAG algorithms with learning rate , while the steps of GD algorithm is 44.
2.3. Nesterov accelerated gradient algorithm
PM algorithm may diverge for relatively simple convex optimisation problems. Mitliagkas (Citation2018) presented an example as follows.
Let f be defined by its gradient as
The proof revolves around the idea that the iterations are stuck in a limit cycle. The following subseries of the iterations tend to three points that are not the optimal value of f.
They show that
,
, and
.
Leveraging the idea of momentum introduced by Polyak, Nesterov solved that problem by finding an algorithm achieving acceleration the same as the PM algorithm, but that can converge for general convex functions. Nesterov gave the Nesterov accelerated gradient (NAG) algorithm in Nesterov (Citation1983), for , the main iteration steps of it are
(7)
(7) The main difference between PM algorithm and NAG algorithm comes from the fact that the latter has two sister sequences working together to produce a corrective movement. Comparing with (Equation6
(6)
(6) ), we see that PM algorithm evaluates the gradient before adding momentum, while NAG algorithm evaluates the gradient after applying momentum.
We show NAG algorithm iteration trajectory with different values of momentum parameter μ in Figures . When , like PM algorithm, NAG algorithm is GD algorithm.
Figure 9. Illustration of NAG iteration trajectory with and
.
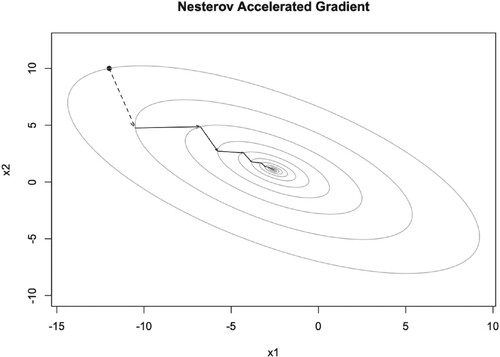
Figure 10. Illustration of NAG iteration trajectory with and
.
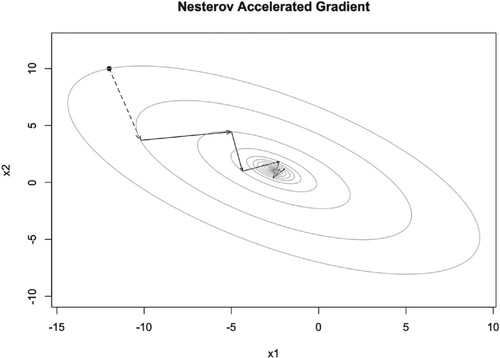
Figure 11. Illustration of NAG iteration trajectory with and
.
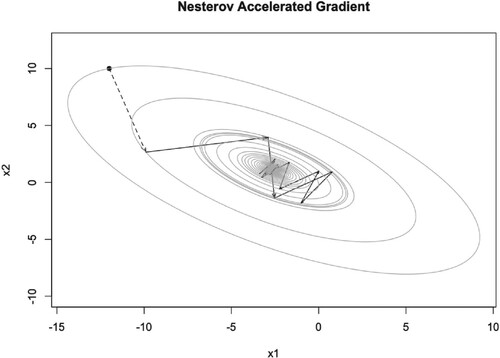
When μ is small, for example or
, NAG algorithm converges to the optimal point
very fast, see Figures –. But when μ becomes larger, it converges to the optimal point slow down, the iteration points always cross the optimal point, see Figure . The dashed arrow starts from the initial point and we can not use the momentum parameter at this time. The number of iteration steps are given in Tables . We will discuss them later.
2.4. Three-step accelerated gradient algorithm
If the dotted lines ,
etc. in Figure are in one line, or the dashed lines
,
etc. are in one line, then we can also accelerate GD algorithm. Because they all point to the optimal point. Actually they are in one line, we prove this in Theorem 2.1.
Theorem 2.1
Three-step Accelerated Gradient Algorithm for Two-dimensional Quadratic Function
Assume that A is symmetric and positive definite for any
. Consider the two-dimensional quadratic function
(8)
(8) with the optimal gradient descent iteration and line search, we need only three steps to get to the optimal point.
Proof.
From (Equation8(8)
(8) ), we can get
Let
Then
Because for the optimal gradient descent,
, so
that is,
Let
be the optimal point, then
so
Then
Similarly,
Let
. When
we have
So both
and
are orthogonal to
.
Because is the optimal point, so
and
are in the same one dimension subspace. Thus they must be in one line.
Let k = 1, with the direction and line search, we can approach
at
. So we need only three steps to get to the optimal point. Thus the result holds.
We show the three-step accelerated gradient (TAG) algorithm iteration trajectory for the two-dimensional quadratic function in Figure . For the line search of last step, we use the R language package ‘pracma’ which was developed by Borchers (Citation2019).
Figure 12. Illustration of TAG iteration trajectory for two-dimensional quadratic function with line search.
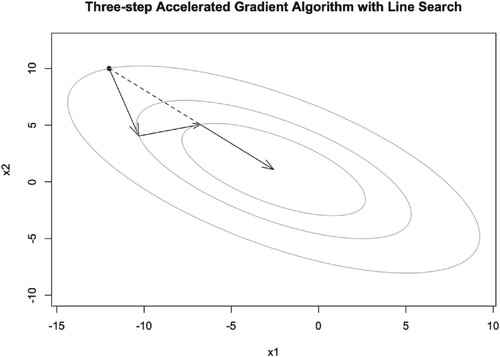
Armijo gave three theorems in Armijo (Citation1966) to illustrate the convergence of the GD algorithm. With the Lipschitz condition in the theorems, we can explain why the algorithms always converge when the learning rate α is small, and will diverge when the learning rate is large.
When the target function is very complex, such as the error function in deep learning, line search may take much time and we still need lots of three-steps to get to the optimal point. So at this time, we use a momentum parameter μ instead of using line search. And based on parallel tangent method proposed by Petalas and Vrahatis (Citation2004), we give TAG algorithm as follows.

The main difference between NAG algorithm and TAG algorithm comes from the fact that the latter has three sequences working together to produce a corrective movement. And based on the idea of Petalas and Vrahatis (Citation2004), the TAG algorithm has more advantages to find out the global optimal value.
We show the TAG algorithm iteration trajectory with different momentum parameter μ in Figures . When , just like the above two algorithms, TAG algorithm is GD algorithm.
Figure 13. Illustration of TAG iteration trajectory with and
.
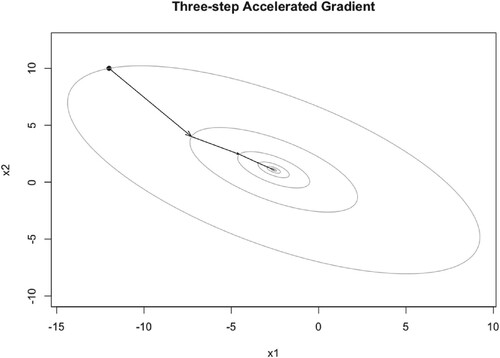
Figure 14. Illustration of TAG iteration trajectory with and
.
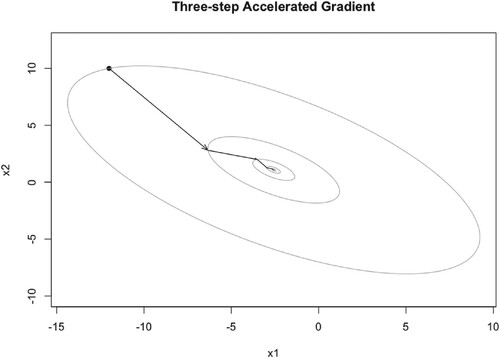
Figure 15. Illustration of TAG iteration trajectory with and
.
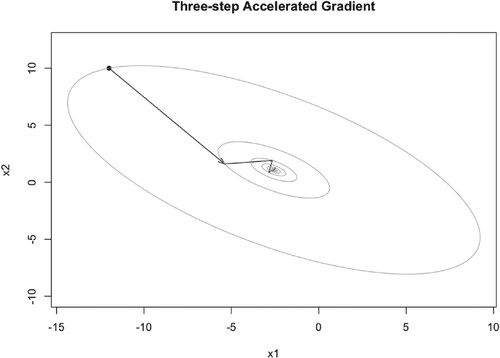
Figure 16. Illustration of TAG iteration trajectory with and
.
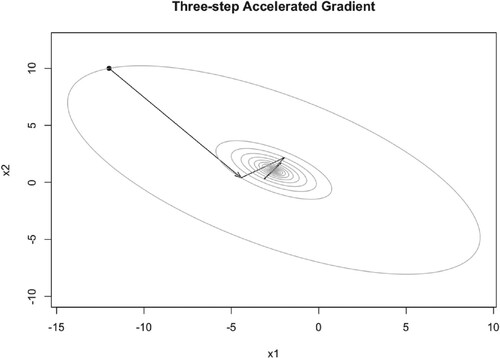
When ,
, and
, TAG algorithm converges to the optimal point
very fast, see Figures –. But when μ becomes larger, it converges to the optimal point slowly, the iteration points always cross the optimal point, see Figure . But unlike PM algorithm and NAG algorithm, even when
, TAG algorithm always converges to the optimal point. The number of iteration steps are given in Tables .
From Tables , we can see that TAG algorithm has more advantages in terms of iteration steps, especially when and
. There have two main reasons. One is that the TAG algorithm has three sequences working together to produce a corrective movement. The other reason is that the objective function is a two-dimensional quadratic function, then Theorem 2.1 shows that the TAG algorithm has more advantages. Furthermore, TAG algorithm is more robust than PM and NAG algorithms, for the latter two algorithms always diverge when
. In order to compare the four algorithms further, we give the following two cases.
2.5. Case studies
In order to compare above four algorithms, GD algorithm, PM algorithm, NAG algorithm, and TAG algorithm, we use two kinds of function to implement, i.e. a high dimension quadratic function and a high dimension nonquadratic function. The symmetric and positive definite matrix A of the quadratic function comes from the R language package ‘pracma’ which was developed by Borchers (Citation2019). All kinds of high-dimensional quadratic function can be generated by this package. For nonquadratic function, FLETCHCR function is used, which comes from CUTE (constrained and unconstrained testing environments, from Association for Computing Machinery) collection (Andrei, Citation2008).
2.5.1. Quadratic function
Tables are the iteration steps and runtime for 10-, 100-, and 500-dimensional quadratic functions. The runtime in ‘second’ is within parentheses. The first row is the value of learning rate α. The sign of ‘–’ means this algorithm is diverging during this scenario.
Table 4. Iteration steps and runtime (within parentheses) of 10-dimensional quadratic function.
Table 5. Iteration steps and runtime (within parentheses) of 100-dimensional quadratic function.
Table 6. Iteration steps and runtime (within parentheses) of 500-dimensional quadratic function.
Tables show that with respect to both iteration steps and runtime, TAG algorithm is superior to NAG algorithm, NAG algorithm is superior to PM algorithm, PM algorithm is superior to GD algorithm. And with the momentum parameter μ, we can find out that TAG is more robust than NAG, NAG is more robust than PM. Notice that when , PM is always diverging. The larger learning rate α, the fewer the iteration steps and the less runtime needed. But too large learning rate will lead to divergency of algorithms. When μ changes from 0 to 1, the iteration steps and runtime decrease then increase, so there may exist an optimal μ for PM, NAG and TAG algorithms. The momentum parameter μ of TAG algorithm can be larger than 1. Next, we implement these four algorithms to the FLETCHCR function and compare them.
2.5.2. FLETCHCR function
The FLETCHCR function is given as follows, which comes from CUTE collection.
(9)
(9)
Tables demonstrate the iteration steps, runtime, and optimal μ with its range for 10-, 100-, and 500-dimensional FLETCHCR functions. The runtime in ‘second’ is within parentheses. The range of μ is within brackets with optimal value on the left.
Table 7. Iteration steps, runtime (within parentheses), and optimal μ with its range (within brackets) for 10-dimensional FLETCHCR function.
Table 8. Iteration steps, runtime (within parentheses), and optimal μ with its range (within brackets) for 100-dimensional FLETCHCR function.
Table 9. Iteration steps, runtime (within parentheses), and optimal μ with its range (within brackets) for 500-dimensional FLETCHCR function.
From Tables , we can obtain that compared with NAG, PM and GD algorithms, TAG algorithm has fewer iteration steps and less runtime, and has longer range of μ, which means TAG algorithm is more robust than other algorithms. The optimal value of μ of TAG algorithm can be larger than 1. PM algorithm and NAG algorithm maybe have the similar performance but both are superior to GD algorithm.
3. TAG algorithm in deep learning
3.1. Why use deep learning?
The development history of deep learning can be seen in Mcculloch and Pitts (Citation1990), Hebb (Citation1949), Rumelhart et al. (Citation1986), Hinton and Salakhutdinov (Citation2006) and Krizhevsky et al. (Citation2017). The reason we consider accelerating backpropagation algorithm in deep learning is because deep learning has excellent effects in classification projects, speech recognition, and image processing. This paper mainly studies classification problems. From Matloff (Citation2017) and Hastie et al. (Citation2015), we can see that multinomial logistic regression (MLR) is the most practical and effective way to solve multi-classification problems, which is a generalisation of logistic regression. The MLR model which has K categories is as follows.
(10)
(10)
(11)
(11) here,
, and
.
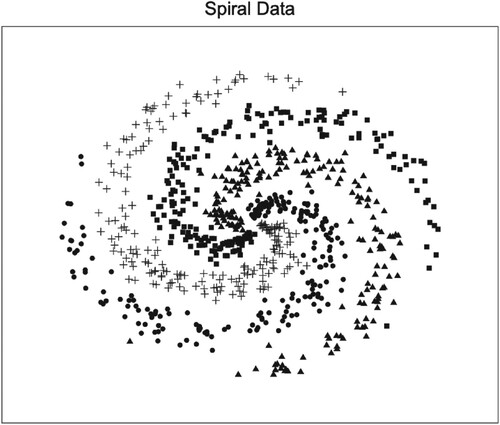
Let us see a spiral data set from the computer science course of Stanford University (Stanford, Citation2019). For the data size of this data set, the input is , the output is
, and the output values are divided into 4 categories. The scatter plot of spiral data is given in Figure , which is plotted by R language package ‘ggplot2’ developed by Wickham (Citation2016).
Figure 17. The scatter plot of spiral data.
Referring to James et al. (Citation2015), we estimate the coefficients of MLR model using the R language packages ‘nnet’ developed by Ripley and Venables (Citation2020) and ‘tidyverse’ developed by Wickham (Citation2014). The classification accuracy of this model is only 0.3188. Obviously, the classification effect is not good. Hastie et al. (Citation2009) pointed out that Support Vector Machines (SVM) is a very effective classification method in statistical learning. It can change each linearly inseparable problem into a separable one. The main part of SVM model is the following constrained optimisation problem.
(12)
(12)
(13)
(13) Here N is the sample size,
is the slack variable, and C is the penalty coefficient.
Referring to Karatzoglou and Meyer (Citation2006), we use the R language package ‘e1071’ developed by Meyer et al. (Citation2019) to train the spiral data set with SVM model. Here the selected kernel function is ‘radial’ with a penalty coefficient of C = 5. After training, 547 support vectors are generated and the classification accuracy is 0.9163, which shows that the classification effect is very good.
Finally, we use the R language package ‘supneuralnet’ developed by ourselves to train the spiral data set with deep learning model. This package will be introduced in detail later, it is rewritten from the R language package ‘neuralnet’ which was developed by Fritsch et al. (Citation2019). Here the neural network contains only one hidden layer, and the hidden layer contains 50 neurons. After 6000 iterations, the classification accuracy reaches 0.98, which has exceeded the SVM model.
Statistics at a crossroads: who is for the challenge? He illustrated this in Berger and He (Citation2019). Research in deep learning is ruinously expensive, and the standard algorithms are ridiculously slow to converge. So the accelerated algorithms in deep learning are very necessary.
3.2. Backpropagation with three-step accelerated gradient
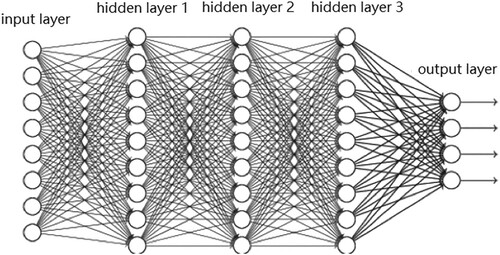
Feedforward neural networks are the first type of artificial neural networks where the connections between neurons do not form a cycle. Feedforward neural networks are simpler than their counterpart, recurrent neural networks. The reason why they are called feedforward is that the information in these networks is only forwarded, do not have loops. The information first through the input neurons, then through the hidden neurons (if present), and finally through the output neurons. In industry and academia, a neural network is called deep learning which has at least one hidden layer. Figure gives the information transmission procedure of a feedforward neural network with 3 hidden layers.
Figure 18. Feedforward neural network with 3 hidden layers.
Throughout the books and literatures on neural networks and deep learning (Anthony & Bartlett, Citation2009; Blum & Rivest, Citation1992; Hinton et al., Citation2006; Hornik, Citation1991; Kawaguchi, Citation2016; Prechelt, Citation1994), the mathematical representations of neural networks are different. The representation in Goodfellow et al. (Citation2016) is very popular. We will combine them and present the mathematical formulas in this paper.
We consider a feedforward neural network has M layers, whose lth layer contains neurons, for
.
represents the output of the jth neuron at the lth layer. When l = 1, which is the input layer, we let
equal to the input vector
of the input layer, that is
(14)
(14) For the 2nd layer to the (M−1)th layer, i.e.
,
is calculated by
(15)
(15)
(16)
(16) where
. Here
is the sum of its weighted inputs.
is the weight from the ith neuron at the (l−1)th layer to the jth neuron at the lth layer.
is the bias of the jth neuron at the lth layer.
is the activation function of the jth neuron at the lth layer. There are many commonly used activation functions, four of them are listed below.
Sigmoid function
(17)
Tangent function
ReLU function
Softplus function
The Softplus function is an approximation of the ReLU function. But the Softplus function is a smooth function, which is easy to get the derivative.
For the Mth layer, which is the output layer, is calculated by
(21)
(21)
(22)
(22) where
. We give the formulas of output layer separately because the backpropagation algorithm starts from the output layer in order to minimise the error function. In the following, a combination of numbers is used to represent the structure of a neural network. For example, the neural network in Figure is represented as a 8-9-9-9-4 type neural network.
The backpropagation algorithm was discovered in the 1970s, but the importance of this algorithm was not recognised until Rumelhart, Hinton, and Williams published a paper on Nature (Rumelhart et al., Citation1986). Backpropagation is short for backward propagation of errors, which is an algorithm for supervised learning of artificial neural networks using gradient descent. It is the most widely used algorithm for training multilayer feedforward neural networks. If an artificial neural network and an error function are given, backpropagation mainly uses the chain rule to calculate the gradient of the error function to weights.
Let the input-output pair of a neural network is , and the sample size is P, then the error function (or loss function) is
(23)
(23) where the error of the pth sample is
(24)
(24) For the error function, (Equation23
(23)
(23) ) is divided by P in some literatures. But it has no effect on minimising error function compared with (Equation23
(23)
(23) ), because P is a constant. And there are many kinds of loss function, this is just the most widely used one.
To simplify the mathematical formulas further, the bias for the jth neuron at the lth layer will be incorporated into the weights as
with a fixed output of
. Thus
(25)
(25) In the backpropagation algorithm, minimisation of E is usually using the gradient descent with constant learning rate α, and the computation of
by applying the chain rule and product rule in differential calculus. The backpropagation algorithm is mainly how to calculate
(26)
(26) According to the chain rule in differential calculus, we have
(27)
(27) Where
Let
(28)
(28) thus
(29)
(29) For the Mth layer, we have
(30)
(30) For the hidden layers, i.e.
, according to Rumelhart et al. (Citation1986),
(31)
(31) Artificial neural networks generally spend a lot of time when training data sets with the backpropagation algorithm. So the acceleration of the backpropagation algorithm is very meaningful. We give the backpropagation with three-step accelerated gradient (BPTAG) algorithm as follows.

3.3. R package supneuralnet
Programming is important after given an algorithm, but the programming of deep learning is difficult. It is relatively easy to program a neural network with only one hidden layer, but this is not versatile, which cannot be used in a neural network with two hidden layers.
R language package ‘neuralnet’ which was developed by Fritsch et al. (Citation2019) is a good package in deep learning. But it only includes the backpropagation with gradient descent (BPGD) algorithm for algorithms in this paper. So we rewrite this package, named ‘supneuralnet’, which includes all algorithms in this paper. In addition to BPGD algorithm, backpropagation with Polyak momentum (BPPM) algorithm, backpropagation with Nesterov accelerated gradient (BPNAG) algorithm, and BPTAG algorithm are added to package ‘supneuralnet’.
The stochastic gradient descent algorithm is also added to package ‘supneuralnet’, then backpropagation with stochastic gradient descent (BPSGD) algorithm, backpropagation with Polyak momentum and stochastic gradient descent (BPPMSGD) algorithm, backpropagation with Nesterov accelerated stochastic gradient (BPNASG) algorithm, and backpropagation with three-step accelerated stochastic gradient (BPTASG) algorithm are automatically added to this package. These will be seen in Section 5.
4. Case studies based on BPTAG algorithm
We apply the BPGD, BPPM, BPNAG, and BPTAG algorithms to two cases, and compare the performances of these algorithms. The purposes of the two cases are different. For iris data set, we control the training accuracy and compare the iteration steps and runtime. For spiral data set, we control the iteration steps and compare the training accuracy. In addition, the performances of linear methods are not bad for iris data set, which can not be accepted for spiral data set.
4.1. Iris data set
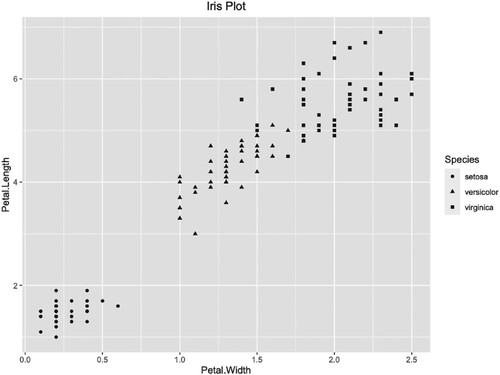
The iris data set is an open source data set in R language (R Core Team, Citation2020), it has 150 rows and 5 columns. The scatter plot of iris petal is given in Figure .
Figure 19. The scatter plot of iris petal.
The ‘supneuralnet’ package is used for training iris data with BPGD, BPPM, BPNAG, and BPTAG algorithms. The data is trained 100 times with the 2-6-3 type neural network for each algorithm, and the optimal one is selected. Figure represents the training results of BPTAG algorithm with learning rate and momentum parameter
. The processor of machine is 3.1 GHz Dual-Core Intel Core i7 with 16 GB memory. The iteration steps and runtime of algorithms with the values of learning rate and momentum are given in Tables . The runtime in ‘second’ is within parentheses.
Figure 20. BPTAG algorithm training results of iris data set with and
.
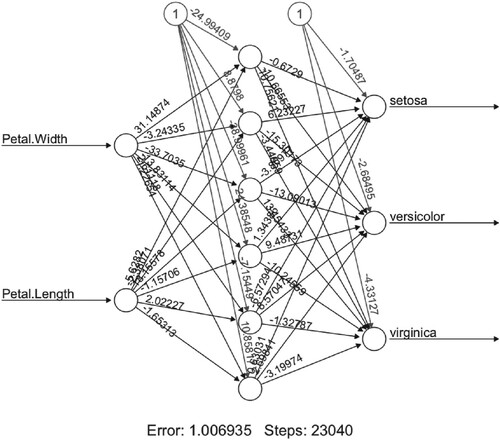
Table 10. Iteration steps and runtime (within parentheses) of BPPM, BPNAG, and BPTAG algorithms with learning rate for iris data set, while the steps and runtime of BPGD algorithm are 64822 and 17.88s respectively.
Table 11. Iteration steps and runtime (within parentheses) of BPPM, BPNAG, and BPTAG algorithms with learning rate for iris data set, while the steps and runtime of BPGD algorithm is 48849 and 11.77s respectively.
Table 12. Iteration steps and runtime (within parentheses) of BPPM, BPNAG, and BPTAG algorithms with learning rate for iris data set, while the steps and runtime of BPGD algorithm is 33503 and 8.09s respectively.
It can be seen from the three tables that the BPPM, BPNAG, and BPTAG algorithms are better than the BPGD algorithm. If α is too large, then it will lead to divergency of algorithms. If α is too small, then it will lead to more iteration steps and runtime of algorithms. The momentum parameter μ has similar variation tendency. This is consistent with the variation tendencies of learning rate and momentum of GD, PM, NAG, and TAG algorithms in Section 2. In fact, during the 100 times training process in Table , some trainings of these algorithms are divergent. Taken together, BPTAG algorithm is better than BPPM and BPNAG algorithms, and it is more robust to momentum parameter μ. Because BPTAG algorithm is still convergent when μ becomes larger. The BPPM algorithm has the similar iteration steps and runtime to the BPNAG algorithm, but the BPNAG algorithm is more robust, because the BPPM algorithm is more likely to diverge when μ becomes larger.
4.2. Spiral data set
The spiral data set has been introduced in Section 3, which can not be classified with the linear models. In this case, the softmax loss function is chosen to train the data, thus
(32)
(32) In order to avoid overfitting, the
regularisation is added to E. Therefore the loss function becomes
(33)
(33) Where λ is the regularisation parameter.
The spiral data set is trained by BPGD, BPPM, BPNAG, and BPTAG algorithms with ReLU activation function. The number of iteration steps is set to 3000 steps with regularisation parameter for all algorithms. The data is trained 100 times with the 2-50-4 type neural network for each algorithm, and the optimal one is selected. The training accuracy of algorithms with the values of learning rate α and momentum μ are given in Tables .
Table 13. Training accuracy of BPPM, BPNAG, and BPTAG algorithms with learning rate for spiral data set, while the accuracy of BPGD algorithm is 0.8775.
Table 14. Training accuracy of BPPM, BPNAG, and BPTAG algorithms with learning rate for spiral data set, while the accuracy of BPGD algorithm is 0.8950.
Table 15. Training accuracy of BPPM, BPNAG, and BPTAG algorithms with learning rate for spiral data set, while the accuracy of BPGD algorithm is 0.8975.
It can be seen from the three tables that the four algorithms have the highest accuracy when . As the learning rate α decreases to 0.5, and then to 0.25, the training accuracy of the four algorithms decreases slowly. If momentum μ is too large or too small, then it will lead to lower accuracy for BPPM and BPNAG algorithms. In particular, the training accuracy of BPPM algorithm is 0.25 when
, which means that it classifies all the training data into one class. And the training accuracy of BPNAG algorithm is 0.25 occasionally when
, it is very low. At the same time, the training accuracy of the BPTAG algorithm is particularly high, even reaching 0.99, which is a great advantage. Once again, this proves that the BPTAG algorithm is more robust than BPPM and BPNAG algorithms for the momentum parameter μ. In general, the performances of the four algorithms are still the same as the iris data set. The BPTAG algorithm has the highest training accuracy, the BPGD algorithm has the lowest training accuracy, and the training accuracy of BPPM algorithm and BPNAG algorithm is almost the same.
5. Three-step accelerated stochastic gradient algorithm in deep learning
5.1. Backpropagation with three-step accelerated stochastic gradient
The gradient descent algorithm needs to use all the data in each iteration during training, which brings challenges to solve the optimisation problems of large scale data. Given an artificial neural network, in order to update the weights, the BPGD algorithm needs to use all the training data every time. When P is large, it requires lots of computational resources and computing time, which is not feasible in the actual production process. So the stochastic gradient descent (SGD) algorithm is proposed to solve this problem.
The SGD algorithm is to use the minibatch data instead of all data to calculate the gradient every time. That is to say, SGD algorithm randomly selects Q samples from P samples when calculating the gradient in each iteration, where .
In practical application, parameter tuning is used to obtain the optimal Q. Generally, it can take full advantage of matrix operation in the computer program when , such as 16, 32, 64, 128, 256, and so on.
Since the backpropagation with stochastic gradient descent (BPSGD) algorithm uses part of the data set in each iteration, it should take more iteration steps to converge. So the acceleration of BPSGD algorithm is very helpful for the big data computing. BPSGD algorithm, backpropagation with Polyak momentum and stochastic gradient descent (BPPMSGD) algorithm, backpropagation with Nesterov accelerated stochastic gradient (BPNASG) algorithm, and backpropagation with three-step accelerated stochastic gradient (BPTASG) algorithm have been added to the R language package ‘supneuralnet’, see Section 3. The BPTASG algorithm is given as follows.

5.2. Iris data set
The ‘supneuralnet’ package is used for training iris data with BPSGD, BPPMSGD, BPNASG, and BPTASG algorithms. The data is trained 100 times with the 2-6-3 type neural network and minibatch Q = 64 for each algorithm, and the optimal one is selected. According to the results of Section 4, we choose learning rate . Figure represents the training results of BPTASG algorithm with momentum parameter
. The iteration steps and runtime of algorithms with the value of momentum are given in Table . The runtime in ‘second’ is within parentheses.
Figure 21. BPTASG algorithm training results of iris data set with and
.
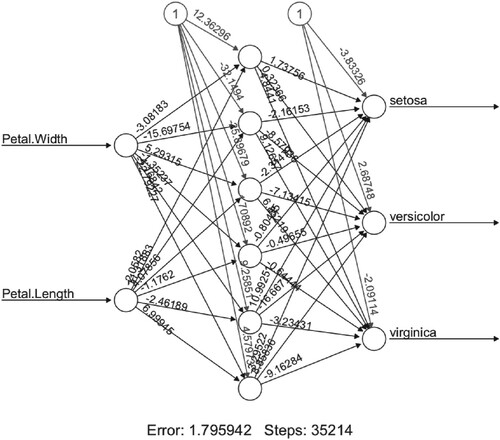
Table 16. Iteration steps and runtime (within parentheses) of BPPMSGD, BPNASG, and BPTASG algorithms with learning rate for iris data set, while the steps and runtime of BPSGD algorithm is 123859 and 22.13s respectively.
Compared with Table , it can be seen that the BPSGD algorithm requires 123859 steps to converge, which is 2.5 times the iteration steps of BPGD algorithm. At the same time, BPSGD algorithm requires 22.13 seconds to converge, which is about 2 times the runtime of BPGD algorithm. The iteration steps required by accelerated algorithms are almost twice the iteration steps of using the full data set. Some are just less than two times, such as the BPTASG algorithm with momentum . The runtime required by accelerated algorithms are almost 1.5 times the runtime of using the full data set. This shows that the accelerated algorithms have really nice effects, and the BPPMSGD algorithm also converges when
. In general, too large momentum μ or too small momentum μ will lead to more iteration steps and runtime for BPPMSGD, BPNASG, and BPTASG algorithms. The BPTASG algorithm has the least iteration steps and runtime, the BPSGD algorithm has the most iteration steps and runtime, and BPPMSGD algorithm and BPNASG algorithm are almost the same.
5.3. Spiral data set
According to the results of Section 4, we choose learning rate . The spiral data set is trained by BPSGD, BPPMSGD, BPNASG, and BPTASG algorithms with ReLU activation function, softmax loss function, and the
regularisation. The number of iteration steps is set to 3000 steps with regularisation parameter
for all algorithms. The data is trained 100 times with the 2-50-4 type neural network and minibatch Q = 128 for each algorithm, and the optimal one is selected. The training accuracy of algorithms with the value of momentum μ is given in Table .
Table 17. Training accuracy of BPPMSGD, BPNASG, and BPTASG algorithms with learning rate for spiral data set, while the accuracy of BPSGD algorithm is 0.8887.
Compared with the Table , we find out that with only 3000 iterations, the SGD algorithm reduces the training accuracy. Actually, it needs more iteration steps to reach the training accuracy in Table . But the runtime is much shorter after adding the SGD algorithm, and the accuracy is high enough. It can be seen from Table that too large momentum μ or too small momentum μ will lead to lower accuracy for accelerated algorithms. In particular, the training accuracy of BPPMSGD algorithm is 0.25 when , which means that it classifies all the training data into one class. And the training accuracy of BPNASG algorithm is 0.3075 at this time, which is very low. While the training accuracy of the BPTASG algorithm is very high, which is a great advantage. This proves that the BPTASG algorithm is more robust than BPPMSGD and BPNASG algorithms for the momentum parameter μ. Overall, BPTASG algorithm is superior to BPNASG algorithm, BPNASG algorithm is superior to BPPMSGD algorithm, and BPPMSGD algorithm is superior to BPSGD algorithm.
6. Conclusion
This paper proposes the TAG algorithm and applies it to deep learning. Firstly, we introduce GD algorithm, and give the applications of it to a quadratic function, then state PM and NAG algorithms, give the TAG algorithm, and implement them to the quadratic function. The paper conducts experiments to high-dimensional functions that help us to understand TAG with the fastest convergence among these four algorithms. Secondly, we introduce deep learning and backpropagation algorithm. Then the TAG algorithm is added to the backpropagation algorithm. Since the R language package ‘neuralnet’ only contains the GD algorithm of the algorithms in this paper, we rewrite the ‘neuralnet’ package, named ‘supneuralnet’. The PM algorithm, NAG algorithm, and TAG algorithm are added. We also add the SGD algorithm, so that SGD and other algorithms can be combined with freedom. Thirdly, we apply the four algorithms to the iris and spiral data sets in the deep learning framework, compare their classification effects and convergence speed. We find out that our algorithm is the best. Finally, we combine the SGD algorithm with the above four algorithms, and apply them to the iris and spiral data sets in the deep learning framework, compare their classification effects and convergence speed. We also find out that our algorithm is the best. Moreover, we can do more research for the scalability of BPTASG algorithm with more datasets in the future. The theoretical convergence analysis of BPTASG algorithm is also well worth studying.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Yongqiang Lian
Yongqiang Lian is a Ph.D. candidate in Statistics at East China Normal University.
Yincai Tang
Yincai Tang is a Professor in School of Statistics at East China Normal University.
Shirong Zhou
Shirong Zhou is a Ph.D. student in Statistics at East China Normal University.
References
- Andrei, N. (2008). An unconstrained optimization test functions collection. Advanced Modeling and Optimization, 10(1), 147–161.
- Anthony, M., & Bartlett, P. L. (2009). Neural network learning: Theoretical foundations. Cambridge University Press.
- Armijo, L. (1966). Minimization of functions having Lipschitz continuous first partial derivatives. Pacific Journal of Mathematics, 16(1), 1–3. https://doi.org/https://doi.org/10.2140/pjm
- Berger, J., & He, X. (2019). Statistics at a crossroads: Challenges and opportunities in the data science era. https://hub.ki/groups/statscrossroad/overview.
- Bishop, C. M. (Ed.). (2006). Pattern recognition and machine learning. Springer.
- Blum, A. L., & Rivest, R. L. (1992). Training a 3-node neural network is NP-complete. Neural Networks, 5(1), 117–127. https://doi.org/https://doi.org/10.1016/S0893-6080(05)80010-3
- Borchers, H. W. (2019). pracma: Practical numerical math functions [Computer software manual]. https://CRAN.R-project.org/package=pracma (R package version 2.2.9).
- Chen, K. K. (2016). The upper bound on knots in neural networks. arXiv:1611.09448.
- Churchland, P. S., & Sejnowski, T. J. (2016). The computational brain. The MIT Press.
- Deng, Q., Cheng, Y., & Lan, G. (2018). Optimal adaptive and accelerated stochastic gradient descent. arXiv:1810.00553.
- Flach, P. (2012). Machine learning: The art and science of algorithms that make sense of data. Cambridge University Press.
- Fritsch, S., Guenther, F., Wright, M. N., Suling, M., & Mueller, S. M. (2019). Neuralnet: Training of neural networks [Computer software manual]. https://CRAN.R-project.org/package=neuralnet (R package version 1.44.2).
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
- Gordon, M. (2018). My attempt to understand the backpropagation algorithm for training neural networks (Tech. Rep.). https://www.cl.cam.ac.uk/archive/mjcg/plans/Backpropagation.pdf.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction. Springer.
- Hastie, T., Tibshirani, R., & Wainwright, M. (2015). Statistical learning with sparsity: The lasso and generalizations. CRC Press.
- Hebb, D. O. (1949). The organization of behavior: A neuropsychological theory. John Wiley & Sons Inc.
- Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural Computation, 18(7), 1527–1554. https://doi.org/https://doi.org/10.1162/neco.2006.18.7.1527
- Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504–507. https://doi.org/https://doi.org/10.1126/science.1127647
- Hornik, K. (1991). Approximation capabilities of multilayer feedforward networks. Neural Networks, 4(2), 251–257. https://doi.org/https://doi.org/10.1016/0893-6080(91)90009-T
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2015). An introduction to statistical learning: With applications in R. Springer.
- Karatzoglou, A., & Meyer, D. (2006). Support vector machines in R. Journal of Statistical Software, 15(9), 1–28. https://doi.org/https://doi.org/10.18637/jss.v015.i09
- Kawaguchi, K. (2016). Deep learning without poor local minima. arXiv:1605.07110.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). Imagenet classification with deep convolutional neural networks. Communications of the ACM.
- Lan, G. (2009). Convex optimization under inexact first-order information [Unpublished doctoral dissertation].
- Lan, G. (2012). An optimal method for stochastic composite optimization. Mathematical Programming, 133(1), 365–397. https://doi.org/https://doi.org/10.1007/s10107-010-0434-y
- Le, Q. V. (2015). A tutorial on deep learning (Research Report No. 06.3). Google Brain, Google Inc.
- Lisa, L. (2015). Deep learning tutorial release 0.1. http://deeplearning.net/tutorial/contents.html.
- Magoulas, G. D., Vrahatis, M. N., & Androulakis, G. S. (1997). Effective backpropagation training with variable stepsize. Neural Networks, 10(1), 69–82. https://doi.org/https://doi.org/10.1016/S0893-6080(96)00052-4
- Matloff, N. (2017). Statistical regression and classification: From linear models to machine learning. CRC Press.
- Mcculloch, W. S., & Pitts, W. (1990). A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biology, 52(1–2), 99–115. https://doi.org/https://doi.org/10.1016/S0092-8240(05)80006-0
- Meyer, D., Dimitriadou, E., & Hornik, K. (2019). e1071: Misc Functions of the Department of Statistics, Probability Theory Group [Computer software manual]. https://CRAN.R-project.org/package=e1071 (R package version 1.7-3).
- Mitliagkas, I. (2018). Theoretical principles for deep learning (Tech. Rep.). University of Montreal.
- Moreira, M., & Fiesler, E. (1995). Neural networks with adaptive learning rate and momentum terms (Tech. Rep.). IDIAP.
- Murphy, K. P. (2012). Machine learning: A probabilistic perspective. MIT Press.
- Nesterov, Y. (1983). A method of solving a convex programming problem with convergence rate O(1k2) A method of solving a convex programming problem with convergence rate o(1k2). Doklady Akademii Nauk SSSR, 27(2), 372–376.
- Nesterov, Y. (2004). Introductory lectures on convex optimization: A basic course. Kluwer Academic Publishers.
- Nielsen, M. A. (2019). Neural networks and deep learning. http://neuralnetworksanddeeplearning.com/index.html.
- Petalas, Y. G., & Vrahatis, M. N. (2004). Parallel tangent methods with variable stepsize. 2004 IEEE international joint conference on neural networks (IEEE Cat. No. 04ch37541) (Vol. 2, pp. 1063–1066). IEEE.
- Polyak, B. T. (1964). Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 4(5), 1–17. https://doi.org/https://doi.org/10.1016/0041-5553(64)90137-5
- Prechelt, L. (1994). Proben1: A set of neural network benchmark problems and benchmarking rules (Tech. Rep.). University Karlsruhe.
- Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. (1992). Numerical recipes in C. Cambridge University Press.
- Qian, N. (1999). On the momentum term in gradient descent learning algorithms. Neural Networks, 12(1), 145–151. https://doi.org/https://doi.org/10.1016/S0893-6080(98)00116-6
- R Core Team (2020). R: A language and environment for statistical computing [Computer software manual]. https://www.R-project.org/
- Ripley, B., & Venables, W. (2020). NNET: Feed-forward neural networks and multinomial log-linear models [Computer software manual]. https://CRAN.R-project.org/package=nnet (R Package Version 7.3-13).
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by backpropagating errors. Nature, 323, 533–536. https://doi.org/https://doi.org/10.1038/323533a0
- Rumelhart, D. E., & McClelland, J. L. (1986). Parallel distributed processing. MIT Press.
- Schonberger, V. M., & Cukier, K. (2013). Big data: A revolution that will transform how we live, work, and think. Houghton Mifflin Harcourt.
- Shah, B. V., Buehler, R. J., & Kempthorne, O. (1964). Some algorithms for minimizing a function of several variables. Journal of the Society for Industrial and Applied Mathematics, 12(1), 74–92. https://doi.org/https://doi.org/10.1137/0112007
- Stanford, C. C. (2019). Cs231n: Convolutional neural networks for visual recognition. Stanford University. http://cs231n.github.io.
- Wickham, H. (2014). Advanced R. Chapman & Hall/CRC.
- Wickham, H. (2016). GGPLOT2: Elegant graphics for data analysis. Springer.
- Yin, W. (2015). Optimization: Gradient methods (Tech. Rep.). Department of Mathematics, University of California.