
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This review paper discusses advances of statistical inference in modeling extreme observations from multiple sources and heterogeneous populations. The paper starts briefly reviewing classical univariate/multivariate extreme value theory, tail equivalence, and tail (in)dependence. New extreme value theory for heterogeneous populations is then introduced. Time series models for maxima and extreme observations are the focus of the review. These models naturally form a new system with similar structures. They can be used as alternatives to the widely used ARMA models and GARCH models. Applications of these time series models can be in many fields. The paper discusses two important applications: systematic risks and extreme co-movements/large scale contagions.
1. Introduction
Extreme value theory and methods are commonly applied in many research fields, e.g., finance, insurance, health, climate, and environmental studies. Vast applications can be found in Mikosch et al. (Citation1997), Embrechts et al. (Citation1999), McNeil and Frey (Citation2000), S. Coles et al. (Citation2001), Finkenstädt and Rootzén (Citation2004), Castillo et al. (Citation2005), Salvadori et al. (Citation2007), Dey and Yan (Citation2016), amongst many excellent books. On the theoretical side, Galambos (Citation1987), Leadbetter et al. (Citation1983), Resnick (Citation1987), de Haan (Citation1993), Beirlant et al. (Citation2006) and de Haan and Ferreira (Citation2007) contain many rigorous and fundamental results. In the statistical inference of maximum likelihood estimation of parameters from the extreme value distributions, there have been quite many developments, e.g., Smith (Citation1985), Drees et al. (Citation2004), Zhou (Citation2008), Bücher and Segers (Citation2017) amongst others. Besides the maximum likelihood estimation, other inference methods, e.g., probability weighted moments, generalised method of moments, have also been developed, which are not detailed here.
In the era of big data, the classical extreme value theory finds its limitations in fitting data generated from multiple sources with complex structures. To attack new challenging problems in extreme value studies, many new methodologies, new models, and new theories have also been developed. Here are some examples. Zhang and Smith (Citation2010) proposed the multivariate maxima of moving maxima (M4) processes and applied the method to model jumps in returns in multivariate financial time series and predicted the extreme co-movements in price returns. Meinguet (Citation2012) studied maxima of moving maxima of continuous functions. Martins and Ferreira (Citation2014) studied the extremal properties of M4 models. Ferreira and Ferreira (Citation2018) constructed estimators for the extremal index through local dependence. Reich and Shaby (Citation2019) proposed a spatial Markov model for climate extremes. Pereira and Fonseca (Citation2019) studied statistical methods for assessing the contagion of spatial extreme events among regions. Deng and Zhang (Citation2018, Citation2020) studied haze extremes in a vast region in China.
There are many other advances in new theory, methodology, and applications, which are not listed in this review paper. The focus of this review paper is on time series models for maxima and extreme observations and tail dependence modeling. The time series models include moving maxima models in Sections 4.1, 4.3, 4.5, 4.6, max-autoregressive models in Section 4.2, and autoregressive conditional Fréchet models in Section 4.8. The paper also briefly discusses the most recently introduced probability foundations for these advanced statistical models in Section 3. In studying high dimensional extremes and extreme clusters in time series, the core is how to measure tail dependence between random variables. Section 3 is also discussing some of the proposed tail dependence measures in the literature. For completeness, Section 2 briefly reviews classical extreme value theory. Section 5 presents two data examples. Section 6 concludes.
2. Classical extreme value theory: brief review
In this section, we briefly review some fundamental properties in classical extreme value theory. There have been many developments in the field. Many results cannot be discussed in this review section, and readers are referred to the references included and beyond.
2.1. Univariate extreme value theory
2.1.1. Independent sequence
Suppose is a sequence of independent and identically distributed (i.i.d.) random variables with the distribution function
and let
(1)
(1) Then
has the distribution function
(2)
(2) It is clear that the maximum of a sample simply tends to the right endpoint of the distribution support almost surely, no matter whether it is finite or infinite. Throughout the paper, we denote the right endpoint as
for the distribution function F and similarly for other distribution functions. What we are interested in is the limit form:
(3)
(3) for suitable norming constants
and
.
If (Equation3(3)
(3) ) holds, we say F (or X) belongs to the (maximum) domain of attraction of H and write
(or
). H has one of the following three parametric forms (which are generally called extreme value distributions):
In II and III, α is any positive number. The three types are also often called the Gumbel type, Fréchet type and Weibull type, respectively.
The following theorems are very useful in finding the of F and the suitable norming constants. The proofs of the theorems can be found in Leadbetter et al. (Citation1983), Resnick (Citation1987), Galambos (Citation1987) etc.
Theorem 2.1
Let and suppose that for suitable norming constants
and
,
such that
(4)
(4) then
(5)
(5) Conversely, if (Equation5
(5)
(5) ) holds for some τ,
, then (Equation4
(4)
(4) ) holds.
Theorem 2.2
Necessary and sufficient conditions for the distribution F belongs to the MDA of
Type I:
,
Type II:
Type III:
For illustrative purpose, let's consider the Pareto distribution
We have
so F belongs to MDA of a Type II extreme value distribution. By setting
we have
By putting
for
, we have
so
The extreme value distributions are max-stable distributions. We say a non-degenerate distribution H is max-stable, if
holds for some constants
and
for each
. The next result (Theorem 1.4.1 in Leadbetter et al., Citation1983) shows the relation.
Theorem 2.3
Every max-stable distribution is of extreme value type, i.e., equal to for some a>0 and
; Conversely, each distribution of extreme value type is max-stable.
The three types of extreme value distributions can be represented by a generalised extreme value (GEV) distribution form (which is very useful for statistical purposes):
(6)
(6) where
,
and
are arbitrary. The case
is interpreted as the limit
, that is
(7)
(7) Types II and III correspond to
and
respectively. Smith (Citation1990) has a detailed review of statistical treatments, applications and estimations, of the GEV.
2.1.2. Stationary sequence
Suppose now is a stationary sequence with a continuous marginal distribution function
and
is the so-called associated sequence of i.i.d. random variables with the same marginal distribution function F.
stands for the maximum as usual, defined by (Equation1
(1)
(1) ), while
denotes the corresponding maximum of
. The limit distribution of
can be related to the limit distribution of
via a quantity θ defined below.
If for every there exists a sequence of thresholds
such that
(8)
(8) and under quite mild additional conditions,
(9)
(9) Then θ is called the extremal index of the sequence
. This concept originated in papers by Cartwright (Citation1958), Newell (Citation1964), Loynes (Citation1965) and O'Brien (Citation1974). Leadbetter (Citation1983) gave a formal definition.
The index θ can take any values in [0,1] and is interpreted as the mean cluster size of exceedance over some high threshold. When
, it corresponds to a strong dependence (infinite cluster sizes) but not so strong that all the values can be the same. While
is a form of asymptotic independence of extremes, but it does not mean that the original sequence is independent.
If (Equation9(9)
(9) ) holds for some τ and corresponding
, then it holds for all
(equal or not equal to τ) and its corresponding
. Estimators of the extremal index have been proposed by Leadbetter et al. (Citation1989), Nandagopalan (Citation1990) and Hsing (Citation1993). Smith and Weissman (Citation1994) gave a review of estimating the extreme index and proposed two estimating methods, i.e., blocks method and runs method. Other references include Chapter 8 in the book by Embrechts et al. (Citation1997).
2.2. Multivariate extreme value theory
2.2.1. Independent sequence
Suppose is a D-dimensional i.i.d. random process with distribution
and marginal distributions
. Let
denote the vector of pointwise maxima, where
. If there exist norming constants
and
such that
(10)
(10) as
and for the limit distribution H being non-degenerate such that each
, is non-degenerate and must be in the GEV family, then the distribution H is called a D-dimensional multivariate extreme value distribution, and F is said to belong to the domain of attraction of H, which we write
.
These distributions received theoretical consideration in works back to 1970s and 1980s by de Haan and Resnick (Citation1977), de Haan (Citation1985), Pickands (Citation1981) and Resnick (Citation1987). In the characterisation of the multivariate extreme value distribution, like the univariate case, max-stable (or min-stable) distributions play a central role. We say a distribution is max-stable if for every t>0 there exist functions
and
such that
(11)
(11) The following theorem describes the equivalence between multivariate extreme value distributions and max-stable distributions.
Theorem 2.4
The class of multivariate extreme value distributions is precisely the class of max-stable distribution functions with non-degenerate marginals.
This is Proposition 5.9 in Resnick (Citation1987). After slight modification of Pickands' representation of a min-stable multivariate exponential into a representation for a max-stable multivariate Fréchet distribution, we have
Theorem 2.5
Suppose is a limit distribution satisfying (Equation10
(10)
(10) ), then
(12)
(12) where G is a positive finite measure on the unit simplex
and G satisfies
(13)
(13)
Note is called the exponent measure by de Haan and Resnick (Citation1977).
2.2.2. Stationary sequence
Some of the results for the univariate stationary sequences can be extended in the multivariate context. Suppose now is a D-dimensional stationary stochastic processes with distribution function F and marginals
. Also let
be the associated sequence of i.i.d. random vectors having the same distribution function F.
and
are both pointwise maxima of
and
respectively. Suppose
(14)
(14) both exist and are nonzero, then a quantity that (Nandagopalan, Citation1990, Citation1994) called the multivariate extremal index can relate the extreme value properties of a stationary process to those of i.i.d. sequence. The multivariate extremal index
is defined by
(15)
(15) where
satisfies
Smith and Weissman (Citation1996) pointed out that these properties are not sufficient to characterise the function . They also argued two reasons why one needs to obtain a more precise characterisation to cover a much broader range of processes and to correspond to real stochastic processes, for instance, multivariate maxima of moving maxima processes which will be reviewed next. The first reason is that ‘the number of examples for which the multivariate extreme index has been calculated is currently very small (Nandagopalan, Citation1994; Weissman, Citation1994) and it is important to be able to extend this class to cover a much broader range of processes’. The second reason is that ‘why we need a characterisation is statistical: crude estimators of
are easy to construct, but would not correspond to multivariate extreme index of any real stochastic process’.
2.2.3. The copula representations of multivariate extreme value distributions
In this subsection, we study some basic properties of multivariate extreme value (MEV) distribution functions. The following two lemmas are very general, not restricted to MEV, and they are Theorems 5.1.1 and 5.2.1 in Galambos (Citation1987).
Lemma 2.6
Let be a D-dimensional distribution function with marginals
. Then, for all
,
Lemma 2.7
Let be a sequence of D-dimensional distribution functions,
be the dth univariate marginal of
. If
converges weakly to a nondegenerate continuous distribution function
, then, for each d with
,
converges weakly to dth marginal
of
.
The Copula, or dependence function, is a very useful concept in the investigation of limit distributions for normalised extremes. It is a multivariate distribution with all marginals being uniform .
Definition 2.8
Let be a D-dimensional distribution function, with dth univariate margin
. The copula associated with F, is a distribution function
that satisfies
Write
over the unit cube
.
Based on the function , we now re-state theorems which connect the univariate marginals and the multivariate or dependence structure of the limit distributions.
Theorem 2.9
If (Equation10(10)
(10) ) holds, then the dependence function
of the limit
satisfies
where
is an arbitrary integer. (This is Theorem 5.2.1 of Galambos, Citation1987).
Theorem 2.10
A D-dimensional distribution function is a limit of (Equation10
(10)
(10) ) if and only if its univariate marginals are of the same type as one of three type distributions and its copula
satisfies the condition of Theorem 2.9. (This is Theorem 5.2.4 of Galambos, Citation1987).
Theorem 2.10 tells in principle that if we want to determine and
we just need to determine the components from the marginal limit convergence forms. Let's look at a simple example to illustrate how Theorem 2.10 works.
Example 2.1
Let have a bivariate exponential distribution function
. If
converges weakly to a nondegenerate distribution function
, we can choose
For finding functions, there are many copula dependence theories and examples in Joe (Citation2014); see also Zhang (Citation2009) for constructing extreme value copula, and Yang et al. (Citation2011) for a flexible MGB2 copula family. In Section 4, copulas will be embedded in time series models for extreme values and tail dependent observations.
3. Recent advances on tail (in)dependence and new extreme value theory
From Section 2.2, we can see that the limit multivariate extreme value distribution does not exist in a unified parametric form. To model a multivariate extreme value distribution function is in fact to model the measure function G in (Equation12(12)
(12) ). de Haan (Citation1985) gave a simple nonparametric procedure for modeling the measure function. S. G. Coles and Tawn (Citation1991) argued that parametric models are preferable when one wants to simultaneously estimate the exponent measure and the dependence structure.
In parametric modeling, identifying the dependence between two random variables in the tails determines how good is the chosen model. In the next section, we discuss the tail dependence, its probabilistic properties, and its statistical developments.
3.1. Tail equivalence and tail (in)dependence
Definition 3.1
Two identically distributed random variables X and Y with distribution function F are called tail independent, if
(16)
(16) is 0. The quantity λ, if exists, is called the bivariate tail dependence index; it quantifies the amount of dependence of the bivariate upper tails. If
, X and Y are called tail dependent, and we say that there are extreme co-movements between X and Y in time series modeling and inference.
Besides the definition of tail (in)dependence, in the literature, the asymptotic (in)dependence, and the extremal (in)dependence have also been used. The asymptotic independence is more in mathematics, while the other two are more in applications. Sometimes, the upper tail dependence may also be regarded as the tail dependence. In many applications, they are used interchangeably. Sibuya (Citation1959) introduced the idea of asymptotic independence between two random variables with identical marginal distributions, and de Haan and Resnick (Citation1977) extended it to the multivariate case, see also S. Coles et al. (Citation1999). Examples of tail dependence indices of bivariate random variables were presented in Embrechts et al. (Citation2002). For instance, the tail dependence index of a bivariate normal (Gaussian) random vector is zero as long as the corresponding correlation coefficient is less than one; the tail dependence index of a bivariate t random vector with a positive correlation is greater than zero. Many financial analysts, for example Salmon (Citation2012), blamed a mathematical formula, the Gaussian copula, as the major cause of the 2007–2008 financial crisis mainly because Gaussian random variables are tail independent. This example indicates that tail (in)dependence modeling is of practical importance, see also Embrechts et al. (Citation2002) for properties and pitfalls of correlations and dependence measures. Zhang (Citation2005, Citation2008b) extended the definition of tail dependence between two random variables to lag-k tail dependence of a sequence of random variables with identical marginal distribution. The definition of lag-k tail dependence for a sequence of random variables is given below.
Definition 3.2
A sequence of sample is called lag-k tail dependent if
(17)
(17) Then
is called lag-k tail dependence index.
When , the joint limit distribution of bivariate maxima is the product of marginal limit distributions. The following Proposition 3.3 is from Proposition 5.27 in Resnick (Citation1987).
Proposition 3.3
Suppose is a D-dimensional i.i.d. random process with a common distribution F and a common marginal distribution
for
. Let
denote the vector of pointwise maxima, where
. Suppose
is in the domain of attraction of some univariate extreme value distribution
, i.e., there exist
such that
The following are equivalent.
F is in the domain of attraction of a product measure:
For all
For
With any
From this proposition, we can see that identifying or not is a very important task as it concerns the final form of the limit distribution. When
is confirmed, we just need to find the univariate limit, i.e., not the joint dependence structure.
In practice, dependent random variables are not necessarily tail dependent. It is thus of importance to check or test whether any two sequences of data are tail dependent or tail independent before choosing a certain class of models for the data. In statistical modeling of tail dependent variables, a significant step is due to (Ledford & Tawn, Citation1996, Citation1997). They introduced a class of models for tail dependence and near tail independence, and constructed test statistics for the null hypothesis of tail dependence using the coefficient of tail dependence (defined as η); see Heffernan (Citation2001) for a directory of coefficients of tail dependence. Peng (Citation1999) constructed a non-parametric estimator for the η and a test statistic of testing the hypothesis of tail dependence. Contrary to their null hypothesis, Zhang (Citation2008b) and Zhang et al. (Citation2017) introduced an empirically efficient test statistic for the null hypothesis of tail independence based on the tail quotient correlation coefficient (TQCC), where the underlying threshold can be a constant and/or a random variable that diverges to infinity. We note that the null and alternative hypotheses in Ledford and Tawn (Citation1996, Citation1997) are reversed in Zhang (Citation2008b), Hüsler and Li (Citation2009) and Zhang et al. (Citation2017). Next, we introduce the TQCC and its properties.
In the literature, Pearson's linear correlation coefficient ρ can be interpreted in thirteen ways (Rodgers & Nicewander, Citation1988). We now consider a new way of relating ρ to a simple form of variable decomposition.
Example 3.1
Suppose a bivariate random vector can be expressed as
where
,
,
and
are independent standard normal random variables. Then
Analog to Example 3.1 of stable law of random variables, we construct an extreme value type example of max-stable law of random variables.
Example 3.2
Suppose a bivariate random vector can be expressed as
where
are nonnegative satisfying
,
,
and
are independent unit Fréchet random variables with the distribution function
for x>0. Then
The sample based correlation coefficient of a sequence of bivariate observations
with both
and
having finite second moment (not necessarily normally distributed) can be expressed as an inner product of two normalised random vectors:
(18)
(18) where
,
and
are the sample means of
's and
's respectively.
is a vector with all elements being 1.
Continue Example 3.2 and assume that a sequence of independent bivariate random variables can be decomposed as
where
, are an independent array of unit Fréchet random variables. Then a quotient correlation coefficient is defined
(19)
(19) The quantities
and
in
are asymptotically positive and are interpreted as the maximum relative errors of
's to
's and
's to
's, respectively.
Looking at (Equation18(18)
(18) ), we can see that
is associated to the absolute errors of
's to the center of
's and
's to the center of
's. Clearly
and
measure different variable dependencies. Zhang et al. (Citation2011) proved that
and
are asymptotically independent and demonstrated that a combination of them outperforms many popular test statistics of testing hypothesis of independence.
We note that the definition of requires
and
are identically distributed as unit Fréchet. In fact, the definition can be extended to any positive random variables. In terms of the definition λ in (Equation16
(16)
(16) ), Heffernan et al. (Citation2007) showed that X and Y do not have to be identically distributed as long as they are tail equivalent in the sense of the following Lemma 3.4 which is Lemma 14 in Heffernan et al. (Citation2007).
Lemma 3.4
Suppose X and Y satisfy as x tends to infinity.
is the marginally transformed random variable of Y, i.e.,
for some increasing monotone function G; and
has the same distribution as X has. Then
(20)
(20) as long as one of the above two limits exists.
Using the tail equivalence, the can be extended to tail quotient correlation coefficient (TQCC) (Zhang et al., Citation2017) defined next.
Definition 3.5
If is a random sample of random variables being tail equivalent to unit Fréchet random variables
,
(21)
(21) is the tail quotient correlation coefficient
where
is varying thresholds that tend to infinity.
We present some theoretical results from Zhang et al. (Citation2017) related to the limit distribution of in cases of two random thresholds
:
in Theorem 3.7;
with
,
and
as
in Theorem 3.8. The following assumption is needed.
Assumption T1: For , paired tail independent random variables
satisfy
Remark 3.1
Assumption 3.1 is natural since the tail independence of (also
) implies
and
, will hug
in each axis direction when the threshold value
is sufficiently large.
The following proposition is Proposition 2 in Zhang et al. (Citation2017).
Proposition 3.6
If , where
is a slowly varying function, as defined in Ledford and Tawn (Citation1997), then T1 holds for
when
, T1 does not hold when
.
Theorem 3.7
Suppose for given t>1, all random variables ,
, and
are independent, where
and
are unit Fréchet random variables, and
has the distribution function
for x>0. If
, then
for z>0,
Further,
Theorem 3.8
Suppose are independent unit Fréchet random variables and
satisfies
,
, and
as
, where
is a constant. Then
.
Theorems 3.7 and 3.8 are Theorems 3 and 4 in Zhang et al. (Citation2017). in Zhang et al. (Citation2017) is chosen to be a high threshold of the observed and transformed sequence. A practical rank transformation method of transforming
's to unit Fréchet was proposed in Zhang et al. (Citation2011) where the transformation is based on a simulation idea. We will apply this rank transformation in our data section.
In dealing with tail dependence, clearly and
have the simplest explicit formulas compared with other measures that are implicitly specified. They hold very simple interpretability. Their computability is straightforward. They also hold stability as their limits converge to their corresponding population quantities in (Equation19
(19)
(19) ). It's hardly finding any other sample based tail measures to share all of these properties. TQCC has been successfully applied to studies in financial risk contagions, precipitation extremes, haze extremes, and medical studies. In this paper, we further illustrate its usages in describing extreme-comovement and market contagions in Section 5.
3.2. New extreme value theory for heterogeneous populations
In the era of big data, data generated from multiple sources meet in a common place (cloud). Certainly, the data from each individual source has its own data generating process, i.e., a probability distribution. As such, classical extreme value theory reviewed in Section 2 cannot meet the need of big data extremes.
Considering the daily risk of high-frequency trading in a stock market, one can partition the data into hourly data (from 9:00am to 4:00pm). Suppose each hourly maxima of negative returns can be approximately modeled by an extreme value distribution
. It is clear that
is better modeled by a function of
i.e., not a single
. We use the following simple example with k = 2 to illustrate the idea.
Example 3.3
The sequence is generated by
, where
,
,
and
are independent, and
and
are two corresponding distribution functions. Then
.
Remark 3.2
The form is the simplest case in the general mixture models introduced in Zhao and Zhang (Citation2018). It is also the simplest case in the copula structured M4 models studied by Zhang and Zhu (Citation2016).
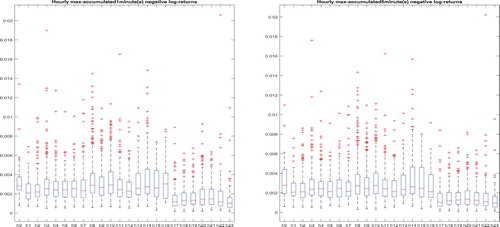
Figure presents Euro dollar against US dollar exchange rate negative return hourly maxima boxplots calculated from 1-minute returns and 5-minute returns in 24 1-hour intervals (h0 - (12:00 AM- 1:00 AM), h1 - (1:00 - 2:00 AM), …, h23 (11:00 PM - 11:59 PM)) from 01/01/2003 - 12/31/2018. Clearly, the trading behaviors in different time intervals are different. The daily maxima can fall in any of those 24 hourly intervals. As a result, the daily maxima is a mixture of hourly maxima. Motivated from this kind of observations, Cao and Zhang (Citation2020) developed new extreme value theory for maxima of maxima.
Figure 1. Euro dollar against US dollar exchange rate hourly maxima of 1 min (left panel) and 5 min (right panel) negative returns. The x-tickers are (h0 - (12:00 AM- 1:00 AM), h1 - (1:00 - 2:00 AM), …, h23 (11:00 PM - 11:59 PM) from left to right, respectively.
Suppose that the mixed sequence is composed of k subsequences
,
as
and
. Denote
as the maximum of each subsequence,
. Suppose
, i.e.,
has the following limit distribution with some norming constants
,
(23)
(23) Define
. Questions can be asked: (1) whether or not (Equation3
(3)
(3) ) holds with appropriately chosen norming constants
; (2) if (1) holds, whether or not
are equivalent to any of
; (3) whether or not
is a function of
; (4) if all (1)–(3) hold, which one is the best method to be used in practice. We include some new results from Cao and Zhang (Citation2020) in the next.
Theorem 3.9
If and
satisfy (Equation23
(23)
(23) ) for j = 1, 2, the limit distribution of
as
can be determined in the following cases:
Case 1. If
Case 2. If
Definition 3.10
For the independent sequence with two subsequences
and
defined as above, suppose (Equation23
(23)
(23) ) is satisfied with j = 1, 2 and norming constants
, i.e.,
(26)
(26) and
(27)
(27) Then we call
the accelerated max-stable distribution, which is the product of two max-stable distributions.
Since and
are max-stable distributions, for any
and
, there are constants
,
,
,
such that
.
In equation (Equation27(27)
(27) ), we considered the convergence of
instead of the traditional
. If
and
are sufficiently large, by (Equation26
(26)
(26) ) we have
and
, then
(28)
(28) where
is of the same type as
, j = 1, 2.
Theorem 3.11
Suppose is an independent sequence which is mixed with two subsequences
and
with underlying distributions
and
,
and
as
. Let
and
and
are two sequences of real numbers such that
(29)
(29) Then
(30)
(30) Conversely, if (Equation30
(30)
(30) ) holds for some
, then so does (Equation29
(29)
(29) ).
Remark 3.3
Since is the probability that
exceeds level
, equation (Equation29
(29)
(29) ) means that the expected number of exceedances of
by
and
by
in total converges to τ. When the sequence is generated from one distribution
, Theorem 3.11 can be reduced to the classical result by choosing
. That is
(31)
(31) if and only if
(32)
(32) as
.
These new developments together with those in Cao and Zhang (Citation2020) shed the light of new researches in extreme values from heterogeneous populations. They provide the probability foundation to models introduced in the next section.
4. Transforming ARMA models to models for extreme value observations
The additive structures in traditional time series models, e.g., ARMA models, and their extensions, e.g., GARCH models, cannot describe the extremal clusters and tail dependence satisfactorily in many applications. To solve this issue, alternative models have been proposed in the extreme value literature. These models transform the additive structures in ARMA models to the competing structures in extreme observations (hidden and/or observable). Several such transformations are discussed in the following subsections.
4.1. Moving minimum corresponding process
Deheuvels (Citation1983) defined what he called the moving minimum (MM) corresponding process as
where
, and
are i.i.d. standard exponential random variables. The main theorem of Deheuvels (Citation1983) is exactly stated as the following theorem.
Theorem 4.1
If follows a joint multivariate extreme value distribution for minima with standard exponentially distributed marginal random variables, then there exist m + 1 sequences
depending on
of positive numbers, such that, if
,
, then
converges in distribution to
as
.
The results of Deheuvels (Citation1983) are very strong, but the model itself is still not easily tractable for the estimation of parameters. Notice that the reciprocal of gives the moving maximum processes as
where
are i.i.d. unit Fréchet random variables.
4.2. Max-autoregressive moving average process
Davis and Resnick (Citation1989) studied what they called the max-autoregressive moving average (MARMA) process of a stationary process
which satisfies the MARMA recursion,
for all n, where ∨ is a maximum operator, i.e.,
,
and
is i.i.d. with common distribution function
. For any given
, the corresponding process is a max-stable process. They have argued “it is unlikely that another subclass of the max-stable processes can be found which is as broad and tractable as the MARMA class”. Some basic properties of the MARMA processes have been shown and the prediction of a max-stable process has been studied relatively completely. However, much less is known about estimation of MARMA process. For prediction, see also Davis and Resnick (Citation1993). A naive estimation procedure for
's when the order q = 1 is given in Davis and Resnick (Citation1989).
4.3. Multivariate maxima of moving maxima process
Smith and Weissman (Citation1996) extended Deheuvels' MM process to a more general framework which is called multivariate maxima of moving maxima (henceforth M4) process. The definition is
(33)
(33) where
are an array of independent unit Fréchet random variables. The constants
are nonnegative constants satisfying
(34)
(34) As we see that M4 processes deal with D dimensional random processes whereas MM processes deal with univariate processes (D = 1). Under the model (Equation33
(33)
(33) ), Smith and Weissman (Citation1996) have shown very attractive results. Some are parallel to the results of Deheuvels (Citation1983). Although MM processes are only specified over one index there are possibilities to easily extend to over two indexes. The extension of MM processes to M4 processes results in hopes to estimate model parameters easily. Following de Haan (Citation1984), (Equation33
(33)
(33) ) defines max-stable processes because for any finite number r and positive constants
we have
(35)
(35)
This is (2.5) of Smith and Weissman (Citation1996) and we have
which tells that
are max-stable. They have argued that the extreme values of a multivariate stationary process may be characterised in terms of a limit max-stable process under quite general conditions. They also showed that a very large class of max-stable processes may be approximated by the M4 processes mainly because those processes have the same multivariate extremal index (Theorem 2.3 in Smith & Weissman, Citation1996). The theorem and conditions appear below.
Now fix with
. Let
be a sequence of thresholds such that
under the model assumption. Since
is unit Fréchet we can take
. Denote
and
the σ-field generated by the events
for
. Define
(36)
(36) where the supremum is taken over
and two respective σ-fields. If there exists a sequence
such that
(37)
(37) the mixing condition
is said to hold (Nandagopalan, Citation1994; Smith & Weissman, Citation1996). Further assuming there exists a sequence
such that
(38)
(38) Let
be the integer part of
. We now exactly state a lemma and a theorem (Lemma 2.2 and their main theorem Theorem 2.3 of Smith & Weissman, Citation1996.)
Lemma 4.2
Suppose (Equation36(36)
(36) )–(Equation38
(38)
(38) ) hold. Then
(39)
(39) Alternatively, if we assume
(40)
(40) then (Equation39
(39)
(39) ) is equivalent to
(41)
(41)
This lemma is basically a restatement of results of O'Brien, for example O'Brien (Citation1987).
Theorem 4.3
Suppose and (Equation40
(40)
(40) ) hold for
, so that the multivariate extremal index
is given by (Equation41
(41)
(41) ). Suppose also the same assumptions hold for
(with the same
,
sequences). So the multivariate extremal index
is also given by (Equation41
(41)
(41) ) with
replacing
everywhere. Then
.
The extremal index of the process defined by (Equation33(33)
(33) ) is
(42)
(42) However,
is not easy to obtain with observed data as one has to estimate all parameters
, which is not straightforward.
We see that Sections 4.1–4.3 deal with probabilistic aspects of time series models for observed extreme value processes. Although theoretical results have been obtained, the estimation of parameters in both MARMA and M4 processes are not well developed and the applications of the two processes are very limited. In the next four subsections, we discuss statistical inference and applications.
4.4. Statistical inference of moving maximum models
Hall et al. (Citation2002) discussed moving maximum models
where the distribution of
is assumed either
or the generalised Pareto distribution
. Then for a finite number of parameters, they chose
to minimise
(43)
(43) where the integral is over
and
(44)
(44) and w is a nonnegative weight function. We state their main theorem as follows.
Theorem 4.4
Under conditions:
F has support on the positive half-line, and is in the domain of attraction of a Type II extreme value distribution;
each
Then
(45)
(45) where
is defined by
and
are solutions of (4.4), and
has distribution function
. Moreover, if
for
sufficiently large, the rate of convergence in (Equation45
(45)
(45) ) is
for all
.
4.5. Finite representations of M4 processes
It can be seen that models having too many parameters to be estimated and/or having a complicated framework and hence lack of interpretability are hardly applicable to real data with a finite number of observations. This section reviews finite representations of M4 processes and their applications.
A finite dimensional M4 process can be written as follows:
(46)
(46) where
for
.
Under model (Equation46(46)
(46) ), it is possible that a big value of
dominates all other Z values within a certain period of length
and creates a moving pattern, i.e.,
for i close to k. A moving pattern is known as a signature pattern. Zhang and Smith (Citation2004) gave a full investigation of probabilistic properties of model (Equation46
(46)
(46) ). Zhang and Smith (Citation2010) studied the estimation of the model, and considered the bivariate joint probabilities. A general joint probability formula of (Equation46
(46)
(46) ) is
(47)
(47) where
when the triple subindex is outside the range defined in (Equation46
(46)
(46) ). Besides this general formula, it follows immediately that
, which establishes that
is itself a unit Fréchet random variable, and the following two special cases are used to construct estimators:
(48)
(48) and
(49)
(49) It is clear that for each d, we can define new piecewise linear functions:
and
, where the notation A: = B means that A is denoted as B, and the points where these piecewise linear functions change slopes are at
or
. This suggests that if we can identify the functions
or
, we may be able to identify all the parameters
.
Relating (Equation48(48)
(48) ) and (Equation49
(49)
(49) ) to their empirical distribution counterparts, Zhang and Smith (Citation2010) solves a system of piecewise linear functions to construct parameter estimators. The consistency and asymptotic normality of the estimators are established. A financial application of value at risk (VaR) is conducted. A new extreme co-movement measure is defined as
(50)
(50) and
(51)
(51) The idea in (Equation50
(50)
(50) ) is to estimate the maximum number of joint exceedances in the time period t to T given at least one exceedance in
. The case t = T = 0 and D = 2 is the usual tail dependence function in the literature (Embrechts et al., Citation2003). Zhang and Smith (Citation2010) demonstrated that (Equation50
(50)
(50) ) is a meaningful market extreme co-movement measure. The tail dependence index λ, the coefficient of tail dependence η, the lag-k tail dependence index
, the extremal index
, and the extreme co-movement measure
can be very useful in studying market crisis and contagions.
4.6. Sparse representations of M4 processes
To increase the estimation efficiency, a common strategy in statistical inference is to reduce the model complexity, i.e., to reduce the number of parameters. Examples include the variable selections in linear regression models, and the sparsity assumption in high-dimensional covariance matrix estimation. In time series, the number of parameters in an auto-regressive model is often less than the number of parameters in a moving average model when they both are fitted to a time series. To reduce the number of unknown parameters in (Equation46(46)
(46) ), Zhang (Citation2008a) considered using geometric moving patterns to study extreme sea wave movements. The number of parameters in Zhang (Citation2008a) is much smaller than the number of parameters in the model studied by Zhang and Smith (Citation2010). This section discusses three scenarios that further simplify model (Equation33
(33)
(33) ) or (Equation46
(46)
(46) ) to more interpretable and workable models.
4.6.1. Markov chain MM process
In this section, we consider univariate time series model. Under model (Equation33(33)
(33) ), we have the following lag-k tail dependence index formula (drop the index d):
(52)
(52) Obviously, as long as both
and
are non-zero,
and
are dependent, and of course tail dependent as can be seen from (Equation52
(52)
(52) ). Zhang (Citation2005) considered the matrix of weights
to have the following structure:
(53)
(53) Now the number L corresponds to the maximal lag of tail dependencies within the sequence; the lag-k tail dependence index is characterised by the coefficients
and
. The coefficient
represents the proportion of the number of observations which are drawn from an independent process
. In other words, a very large value at time 0 has no future impact when the large value is generated from
. If both
and
are not zero, then a very large value at time 0 has impact at time k when the large value is generated from
. If there is strong lag-k tail dependence for each k, the value of
will be small. Using the structure of (Equation53
(53)
(53) ), Zhang (Citation2005) proposed three models for financial times. They are presented next.
Model 4.1
Combining MM (used to model scales) with a Markov process (used to model signs): two models for transformed negative returns and positive
returns are
where the superscript
means that the model is for negative returns only, and
means that the model is for positive returns only. In the following, we only discuss the model for negative returns, and the model for positive returns is obtained by simply replacing
by
. Constants
are nonnegative and satisfy
. The matrix of weights is
is an independent array, where random variables
are identically unit Fréchet distributed. Let
(54)
(54) where the process
is independent of
and takes values in a finite set {0, 1} – i.e.,
is a sign process. Here
is an MM process,
is a simple Markov process.
is the negative return process. For simplicity, Model (Equation54
(54)
(54) ) is regarded as MCMM processes.
Remark 4.1
If is an independent process, then
as
for i>0, r>0, i.e., no tail dependence exists. This phenomenon tells that if there are tail dependencies in the observed process, the model with time dependence (through a Markov chain) only can not model the tail dependence if the random variables used to model scales are not tail dependent.
Remark 4.2
Empirical studies show that negative returns and positive returns
are asymmetric, and conclude that models for positive returns should be different from models for negative returns. Notice that at any time i, one can only observe one of the
and
. The other one is missing. By introducing the Markov processes
and
, both
and
in (Equation54
(54)
(54) ) are observable. We use
and
to construct parameter estimators.
Model 4.2
An MCMM process model for returns: with the established notations in (Equation54(54)
(54) ), let
(55)
(55) where the process
is a simple Markov process which is independent of
and takes values in a finite set
.
is the return process.
Remark 4.3
The processes ,
may be Bernoulli processes or Markov processes taking values in a finite set. The process
may be considered as an independent process or a Markov process taking values in a finite set.
Remark 4.4
In Model (Equation55(55)
(55) ), as long as
,
, and
are determined,
is determined.
Remark 4.5
In many applications, only positive observed values are concerned. Insurance claims, annual maxima of precipitations, file sizes, durations in internet traffic at a certain point are some of those examples having positive values only. Even in our negative return model, the values have been converted into positive values.
4.6.2. Sparse random coefficient M4 processes
One feature in M4 processes is its signature patterns. To fit the data better, we may need a large number of patterns. One way to get rid of this feature is to set moving coefficients to be random. Tang et al. (Citation2013) considered a sparse M4 random coefficient model (SM4R), which has a parsimonious number of parameters, and it can potentially capture the major stylised facts exhibited by devolatised financial time series found in empirical studies. They demonstrated through real data analysis that the SM4R model can effectively be used to improve the estimates of the value at risk for portfolios consisting of multivariate financial returns while ignoring either temporal or cross-sectional tail dependence could potentially result in a serious underestimate of market risk.
The SM4R model is defined as
(56)
(56)
where
is a sequence of i.i.d. D-dimensional random vectors (across t) having a multivariate extreme value distribution function with unit Fréchet margins,
are i.i.d. unit Fréchet random variables for
,
,
and
,
,
,
are i.i.d. random variables on interval
,
are positive constants with
for any d, and
,
, and
are independent with each other.
The cross-sectional tail dependence at time t is characterised by the copula function of and tuned by
. With this setup, all kinds of parametric multivariate extreme value distributions can naturally be incorporated into the SM4R structure so that a parsimonious model with satisfactory level of generality can be achieved. This contrasts with the classical M4 setting where all components depend on the same set of shock variables
, which inherently restricts the dependence structure to a given type and often requires a large number of parameters to achieve satisfactory performance.
For any and positive constants
, the joint distribution function of
conditional on the generic random vector
representing all the
's involved is
(57)
(57) where
is defined as
is the multivariate extreme value distribution of
, and
is called the exponent measure of
(e.g., Resnick, Citation1987). A proof of (Equation57
(57)
(57) ) can be found in Tang et al. (Citation2013). The marginal distribution of
is still unit Fréchet and the multivariate distribution function of
is
(58)
(58) a new multivariate extreme value distribution function whose dependence is characterised by a mixture of independent and extreme value copulas.
One of the most popular multivariate extreme value distributions in practice is the logistic distribution (Gumbel-Hougaard copula with unit Fréchet margins) defined as:
(59)
(59) where
. When
, the joint distribution function (Equation58
(58)
(58) ) becomes
(60)
(60) When D = 2, the cross-sectional bivariate distribution defined by (Equation60
(60)
(60) ) is just the asymmetric logistic distribution proposed by Tawn (Citation1988). Interestingly, the copula function of (Equation60
(60)
(60) ) is
where
and
are the Gumbel-Hougaard copula and independent copula, respectively. In general, if
are P D-dimensional copulas and
are any positive constants satisfying
for
, then the function
constructed as
is still a copula function associated with a D-dimensional distribution function. To see this, consider the process
defined as
for
, where
are i.i.d. D-variate random vectors with copula
and unit Fréchet margins. It can be checked that
is the copula of
.
Besides the above discussed properties of model (Equation56(56)
(56) ), there are many other related properties and developments of the model can be found in Tang et al. (Citation2013). The estimators for the model parameters are constructed using GMM approach. We refer the details to Tang et al. (Citation2013).
4.6.3. Copula structured M4 processes
Statistical applications of classical parametric max-stable processes are still sparse mostly due to lack of (1) efficiency of statistical estimation of many parameters in the processes, (2) flexibility of concurrently modeling asymptotic independence, and asymptotic dependence among variables, and (3) capability of fitting real data directly. Zhang and Zhu (Citation2016) studied a more flexible model, i.e., a class of copula structured M4 (multivariate maxima and moving maxima) processes, and hence CSM4 for short. CSM4 processes are constructed by incorporating sparse random coefficients and structured extreme value copulas in asymptotically (in)dependent M4 (AIM4) processes. It is shown that the new model overcomes all of the aforementioned three constraints. They illustrated new features and advantages of the CSM4 model using simulated examples and real data of intra-daily maxima of high-frequency financial time series. They also studied the probabilistic properties of the proposed model and its statistical inference.
In Zhang and Zhu (Citation2016), they first proposed a new model that is good for marginally transformed observations. It is defined as:
(61)
(61) where
;
is a sequence of i.i.d. D-dimensional random vectors following logistic distribution defined the same as (Equation59
(59)
(59) ) with
and
.
is a sparse random loading matrix having the form:
with
,
for each d, and
being i.i.d. nondegenerated random variables on
. For
,
is an independent array, with
's being unit Fréchet random variables;
represents the componentwise products between matrices
and
at time t, and
takes the maximum over all elements of matrix
.
,
and
are assumed to be independent of each other.
In the second step, assuming that is an observable multivariate stationary time series, they generalised (Equation61
(61)
(61) ) to a directly applicable model:
(62)
(62) where
is a scale parameter,
is a shape parameter for
.
Proposition 4.5
For a CSM4 process defined by (Equation61(61)
(61) ), the serialFootnote1 and cross-sectional asymptotic dependence index
(here,
stands for the tail dependence index between
and
) and the cross-sectional asymptotic dependence index
are presented in Table ; When r>L,
.
Table 1. The asymptotic dependence index , and
.
The main differences between SM4R model (Equation56(56)
(56) ) and CSM4 model (Equation62
(62)
(62) ) are that model (Equation62
(62)
(62) ) can be directly applied to real data, and it can handle both asymptotic independence and asymptotic dependence as shown in Table . Like the inference of SM4R models, the parameter estimation is also based on the generalised method of moments approach; see Zhang and Zhu (Citation2016) for details.
4.7. Approximating a general process by a finite representation: theory
Approximating (Equation33(33)
(33) ) by a finite representation in Sections 4.5 and 4.6 needs theoretical justifications. This section provides the necessary theoretical results. For completeness, proofs of the theoretical results are provided. More details can be found in Zhang (Citation2009).
4.7.1. Convergence in probability for the finitely discrete time domain processes
Lemma 4.6
Suppose , and
where
are i.i.d. unit Fréchet random variables, K is a fixed number, and
. Let
then for any
(63)
(63)
Proof.
First, we have
It is easy to check that
have the distributions:
Since
then
which proves the assertion.
Remark
(Equation63(63)
(63) ) means that for sufficiently small δ, random variables
satisfy
(64)
(64)
Lemma 4.7
Suppose , and
where n is a finite number,
are i.i.d. unit Fréchet random variables, and K is a fixed number. Let
then
(65)
(65)
Proof.
From Lemma 4.6, we have
for each i. Since
which proves (Equation65
(65)
(65) ).
Remark
(Equation65(65)
(65) ) implies for a fixed K, if
is sufficiently small, the process
can be closely approximated by the process
in the sense of
(66)
(66)
Lemma 4.8
Suppose , and
where
are i.i.d. unit Fréchet random variables. Let
then for any
, there exist
and finite number
such that
(67)
(67)
Proof.
Follow the lines in the Proof of Lemma 4.6, we have
It is easy to check that
is a strictly monotone increasing function and
, so there exists
such that
So
Since
, there exists a finite number
such that
where
so
and the proof is then completed.
The following lemma is immediate.
Lemma 4.9
Suppose , and
where n is a finite number and
are i.i.d. unit Fréchet. Let
then for any
, there exist
and a finite number
such that
(68)
(68)
Remark
if is sufficiently small, the process
can be closely approximated by the process
in the sense of
4.7.2. Some results on almost sure convergence and infinitely discrete time domain
In Section 4.7.1, we considered convergence in probability as . In this section we will consider a sequence of
which has the property that
as
, and convergence for infinitely discrete time domain and finitely discrete time domain.
Lemma 4.10
For any given and
, let
be small and satisfy
For a fixed K, let
Then
(69)
(69)
Proof.
First we have
Since ϵ is arbitrary, we have
which shows (Equation69
(69)
(69) ).
Lemma 4.11
Suppose ,
are defined the same as in Lemma 4.10, let
then for each i,
and
(70)
(70)
Proof.
By Lemma 4.10, it is obvious for each i, . Since the index set on i is a countable set (Equation70
(70)
(70) ) is immediate.
Lemma 4.12
For finitely discrete time domain and the conditions in Lemma 4.11, we have
(71)
(71)
Proof.
Since for any finite n
Lemma 4.13
Suppose ,
are defined the same as in Lemma 4.10, let
then
(72)
(72)
Proof.
From Lemma 4.6 we have
for each i. Since
which proves (Equation72
(72)
(72) ).
Since (Equation70(70)
(70) ) implies
(73)
(73) we now generalise (Equation73
(73)
(73) ) to a more general case and state a theorem which shows how a finite moving range model arbitrarily closely approximates an infinite range moving process. The proof is just a generalisation of the arguments above.
Theorem 4.14
Suppose , and
where
is a finite index set,
(74)
(74)
(75)
(75) where
for each
. And
for
, then there exist
,
as
, such that
Therefore, we conclude
for all i and d with probability one.
4.8. Autoregressive models with additive errors and competing errors
Using the result of logarithm transformation of Fréchet random variables to Gumbel random variables, Naveau et al. (Citation2011) proposed the following time series model:
(76)
(76) where μ is a location parameter, and both
and
are Gumbel distributed,
is positive α stable distributed. We can regard (Equation76
(76)
(76) ) as a time series model with log of positive α stable noises
and hidden max Gumbel shocks
. The idea is as follows. Suppose that
for all t. Then model (Equation76
(76)
(76) ) is a pure autoregressive signal process. Alternatively, suppose that
in (Equation76
(76)
(76) ) at time t. If the signal value of
is stronger than the signal resulted from the autoregressive signal process, then
is the new observed signal value, i.e., the signal process is altered by a hidden (max) Gumbel shock. This model may also be regarded as an autoregressive model with an infinite number of change points. We note that
is a Gumbel type random variable according to Fougéres et al. (Citation2009). As a result,
is Gumbel distributed. A Gumbel distributed random variable can be used to model asymmetric heavy tailed observations, e.g., the deseasonalised weekly maxima of river flow rates in Naveau et al. (Citation2011).
Considering the simplest autoregressive structure and the apparent interpretability of (Equation76(76)
(76) ), model (Equation76
(76)
(76) ) can serve as an alternative model to models (Equation33
(33)
(33) ) and (Equation46
(46)
(46) ).
5. Systematic risks, extreme co-movements and risk contagions
Risk analysis and management permeate in our daily life in almost all aspects. Building a good risk model and a good risk measure reduces the probability of a failure of a system. There have been many developments in this subject in many application areas. For example, value at risk (VaR) is a popular risk measure in the banking industry and the insurance industry. Chen et al. (Citation2019) compared several popular risk measures and proposed a new mark to market value at risk (MMVaR) measures to deal with settlements being taken daily during the holding period. For details of VaR and other risk measures, we refer to Chen et al. (Citation2019) and references therein.
Systematic risk (or systemic risk) is a contemporary research topic. Systematic risk can occur in almost every area (system), e.g., flooding, forest fire, earthquake, market crash, financial crisis, economic crisis, global disease pandemic (like CoVID-19), among many others. There are many challenges in modeling systematic risks caused by some rare events. Models discussed in Section 4 for modeling extreme values and rare events can certainly be suitable for many applications. In this section, we discuss a recently proposed framework for studying systematic risk in an integrated time series model. We present some computational results for studying extreme co-movements and risk contagions in Dow Jones stock market. The methodology can be applied to many other scenarios.
5.1. Autoregressive tail-index models
There are many ways to characterise and describe systematic risk and risk contagions. Various models have been developed for modeling systematic risks. Some recent developments include (Kelly, Citation2014; Mao & Zhang, Citation2018; Massacci, Citation2016; Zhang & Schwaab, Citation2017; Zhao et al., Citation2018) amongst others. We review one of these models in this section and point out its connections to models discussed in Section 4.
Let's consider a system that contains hundreds or thousands of subsystems. As long as one subsystem fails, the whole system fails. As such, the systematic risk will be the dominating risk from one sub-system among all components at any given time. Examples of such system with systematic risk include those mentioned earlier in Section 5.
The above arguments can be described as: Suppose a financial system/portfolio contains p stocks. The stock return time series are . We consider two types of such multivariate time series (high dimensional). The first type is that
are a set of panel time series, and we are interested in modeling the cross-sectional maxima
. Such problems arise in many applications, including modeling the maximum daily loss across a group of stocks in a portfolio. The second type is that
denote the p intra-period observations for a univariate time series within period t, and we are interested in modeling the intra-period maxima
. For example, one may be interested in the intra-day maxima of high-frequency trading losses that occur on the same day.
With the established theory in Sections 2 and 3, may be modeled by a GEV distribution or a product of extreme value distributions. For the rest of the paper, we consider the following model:
(77)
(77)
(78)
(78)
(79)
(79) where
is a sequence of i.i.d. unit Fréchet random variables,
,
,
,
, and
.
We note that 's are assumed i.i.d. in this section. They can be tail (in)dependent and modeled using the models discussed in Section 4, and hence the modeling accuracy may be increased. We leave this task for future researches.
We now present an analysis of Dow Jones' 30 (DJI30) stock negative returns. Due to two stocks were just added less than two years. The actual number of stocks is 28. The data is downloaded from Yahoo Finance within the time window 1 January 2000 to 21 March 2020. We first fit a GARCH(1,1) model with t distributed innovations to each individual return series. Using the negative return series divided by the fitted volatilities, we get standardised negative return series for each stock. Taking the maximum value of the 28 standardised negative returns each day, we obtain a time series, i.e., . We fit
to model (Equation77
(77)
(77) )–(Equation79
(79)
(79) ). The fitted parameter values and standard deviations are presented in Table .
Table 2. MLE for cross-sectional maxima of negative standardised daily log-returns for DJI30 from 1 January 2000 to 21 March 2020.
From Table , we can see that except , all other coefficients are significant, which is an indication that (Equation77
(77)
(77) )–(Equation79
(79)
(79) ) is suitable for the cross-sectional maxima data. Figure plots the recovered tail indexes
(left) and scale parameters
(right).
Figure 2. Estimated tail indexes (left) and scale parameters
(right) from 1 January 2000 to 21 March 2020 for Dow Jones 30.
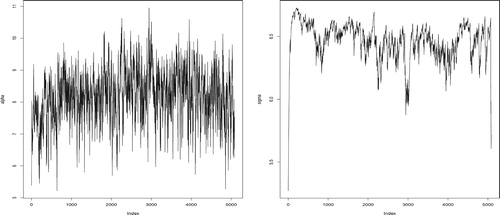
From Figure , we can see that and
vary all the time, i.e., they cannot be constant.
and
are affected by the observed extreme values from previous days. Together with Table , one can see that (Equation77
(77)
(77) )–(Equation79
(79)
(79) ) are good for describing the extreme movements in Dow Jones market. Additional analysis results and inference can be done using the fitted model as discussed in Zhao et al. (Citation2018).
We will use the recovered value to study extreme co-movements in the next section.
5.2. Extreme co-movements and risk contagions
Extreme co-movements refer to extreme values co-occur during a short time period. Risk contagions stand for that risk variables impact each other at extreme values. We use TQCC to study stock price extreme co-movements and risk contagions among Dow Jones' 30 stocks. In the literature, among many applications, Wu et al. (Citation2012) illustrated the idea of studying the equity market index extreme co-movement using TQCC, and Deng and Zhang (Citation2020) used TQCC to study haze extreme contagions in a vast region in China. In their applications, a generalised extreme value (GEV) fitting was implemented. In this section, we adopt a rank transformation using simulated data advocated in Zhang et al. (Citation2011). The computation procedure is shown next.
Consider two stocks A and B among 28 stocks in Dow Jones 30. Denote their standardised negative return series derived from GARCH(1,1) fitting as and
, respectively; denote the sorted (from smallest to largest) series of the recovered
series from the fitted model (Equation77
(77)
(77) ) as
; denote
.
For k = 1:1000,
Simulate a sequence of unit Fréchet random variables
Sort
Set
Set
Compute
Set
Repeat the above process for all combinations of all 28 stocks.
For comparison, we also compute linear correlation coefficients between two standardised time series
and
. We use
and
to generate dendrograms in Figures and .
Figure 3. Dendrograms based on TQCC (left) and linear correlation coefficients (right) using the complete linkage.
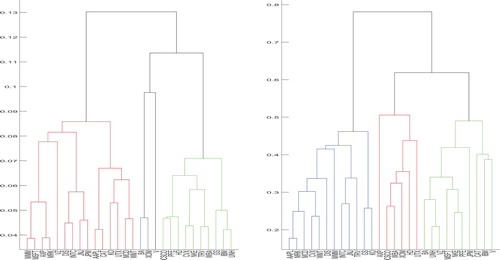
Figure 4. Dendrograms based on TQCC (left) and linear correlation coefficients (right) using the single linkage.
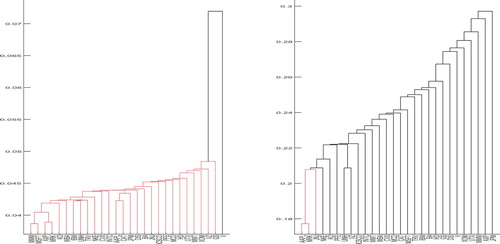
From Figures and , we can immediately see that the stock clusters based on TQCC and the stock clusters based on correlation coefficients are different. It is clear correlation coefficients measure the relationship in the middle parts of the data. However, TQCC can reveal the relation in the tails. In Figure , the left panel based on TQCC can reveal the highest probability that given one stock price plunges within the left sub-branch of clustered compounds, one stock price also plunges within the right sub-branch of clustered compounds. In Figure , the left panel based on TQCC can reveal the smallest probability that given one stock price plunges within the left sub-branch of clustered compounds, one stock price also plunges within the right sub-branch of clustered compounds. Such information can help investors make better trading decisions and form better portfolios during volatile market movements.
6. Conclusions
In this review paper, a series of models and tail dependence measures have been discussed. These models can be applied to many research studies as long as extreme values and rare events are concerned. They can be used as alternative models and/or enhanced models to ARMA and GARCH models. They can be further extended to much more advanced models to meet the need for more complex data. In the literature, there are many other models that can be excellent candidate models for studying extremes, e.g., Brown-Resnick processes (Brown & Resnick, Citation1977; Huser & Davison, Citation2013). The new extreme value theory discussed in Section 3 can open a broad area of research. The autoregressive models with additive errors and competing errors and the autoregressive tail-index models can be extended to high order and high-dimensions. As to statistical inference, Bayesian inference of these models is also a promising research direction. In the literature of extreme value and moving maxima models, Kunihama et al. (Citation2012) applied particle filter method to study moving maxima models. Idowu and Zhang (Citation2017) applied a hybrid MCMC approach in a class of SM4R models. It can be expected that more researches using the discussed models will be rooted in many research areas.
Acknowledgments
The author thank Editor Jun Shao and two referees for their valuable comments. The work was partially supported by NSF-DMS-1505367 and NSF-DMS-2012298.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Zhengjun Zhang
Zhengjun Zhang is Professor of Statistics at the University of Wisconsin. His main research areas of expertise are in financial time series and rare event modeling, virtual standard currency, risk management, nonlinear dependence, asymmetric dependence, asymmetric and directed causal inference, gene-gene relationship in rare diseases.
Notes
1 If we let , then the first three cases in the second column of Table correspond to the serial asymptotic dependence index
.
References
- Beirlant, J., Goegebeur, Y., Segers, J., & Teugels, J. (2006). Statistics of extremes: Theory and applications. John Wiley & Sons.
- Brown, B. M., & Resnick, S. I. (1977). Extreme values of independent stochastic processes. Journal of Applied Probability, 14(4), 732–739. https://doi.org/10.2307/3213346
- Bücher, A., & Segers, J. (2017). On the maximum likelihood estimator for the generalized extreme-value distribution. Extremes, 20(4), 839–872. https://doi.org/10.1007/s10687-017-0292-6
- Cao, W., & Zhang, Z. (2020). New extreme value theory for maxima of maxima. Statistical Theory and Related Fields. https://doi.org/10.1080/24754269.2020.1846115
- Cartwright, D. E. (1958). On estimating the mean energy of sea waves from the highest waves in a record. Proceedings of the Royal Society of London, Series A, 247(1248), 22–28.https://doi.org/10.1098/rspa.1958.0168
- Castillo, E., Hadi, A. S., Balakrishnan, N., & Sarabia, J. M. (2005). Extreme value and related models with applications in engineering and science. Wiley Series in Probability and Statistics.
- Chen, Y., Wang, Z. C., & Zhang, Z. (2019). Mark to market value at risk. Journal of Econometrics, 208(1), 299–321. https://doi.org/10.1016/j.jeconom.2018.09.017
- Coles, S., Bawa, J., Trenner, L., & Dorazio, P. (2001). An introduction to statistical modeling of extreme values (vol. 208). Springer.
- Coles, S., Heffernan, J., & Tawn, J. (1999). Dependence measures for extreme value analyses. Extremes, 2(4), 339–365. https://doi.org/10.1023/A:1009963131610
- Coles, S. G., & Tawn, J. A. (1991). Modeling extreme multivariate events. Journal of the Royal Statistical Society, Series B, 53(2), 377–392.https://doi.org/10.1111/j.2517-6161.1991.tb01830.x
- Davis, R. A., & Resnick, S. I. (1989). Basic properties and prediction of max-ARMA processes. Advances in Applied Probability, 21(4), 781–803. https://doi.org/10.2307/1427767
- Davis, R. A., & Resnick, S. I. (1993). Prediction of stationary max-stable processes. The Annals of Applied Probability, 3(2), 497–525. https://doi.org/10.1214/aoap/1177005435
- de Haan, L. (1984). A spectral representation for max-stable processes. The Annals of Probability, 12(4), 1194–1204. https://doi.org/10.1214/aop/1176993148
- de Haan, L. (1985). Extremes in higher dimensions: The model and some statistics. In Proceedings of the 45th session international statistic institute. International Statistical Institute.
- de Haan, L. (1993). Extreme value statistics. In Janos Galambos, James Lechner, & Emil Simiu (Eds.), Extreme value theory and applications (pp. 93–122). Kluwer Academic.
- de Haan, L., & Ferreira, A. (2007). Extreme value theory: An introduction. Springer.
- de Haan, L., & Resnick, S. I. (1977). Limit theory for multivariate sample extremes. Zeitschrift für Wahrscheinlichkeitstheorie und Vrwandte Gebiete, 40(4), 317–337. https://doi.org/10.1007/BF00533086
- Deheuvels, P. (1983). Point processes and multivariate extreme values. Journal of Multivariate Analysis, 13(2), 257–272. https://doi.org/10.1016/0047-259X(83)90025-8
- Deng, L., & Zhang, Z. (2018). Assessing the features of extreme smog in China and the differentiated treatment strategy. Proceedings of the Royal Society A, 474, 220920170511. https://doi.org/10.1098/rspa.2017.0511
- Deng, L., & Zhang, Z. (2020). The haze extreme co-movements in Beijing-Tianjin-Hebei region and its extreme dependence pattern recognitions. Science Progress, 103(2), 36850420916315. https://doi.org/10.1177/0036850420916315
- Dey, D. K., & Yan, J. (2016). Extreme value modeling and risk analysis: Methods and applications, (EDS). Chapman & Hall/CRC.
- Drees, H., Ferreira, A., & de Haan, L. (2004). On maximum likelihood estimation of the extreme value index. Annals of Applied Probability, 14(3), 1179–1201. https://doi.org/10.1214/105051604000000279
- Embrechts, P., Klüppelberg, C., & Mikosch, T. (1997). Modelling extremal events for insurance and finance. Springer.
- Embrechts, P., Lindskog, F., & McNeil, A. (2003). Modelling dependence with copulas and applications to risk management. In S. Rachev (Ed.), Handbook of heavy tailed distributions in finance (pp. 329–384). Elsevier.
- Embrechts, P., McNeil, A., & Straumann, D. (2002). Correlation and dependence in risk management: Properties and pitfalls. In M. A. H. Dempster (Ed.), Risk management: Value at risk and beyond (pp. 176–223). Cambridge University Press.
- Embrechts, P., Resnick, S. I., & Samorodnitsky, G. (1999). Extreme value theory as a risk management tool. North American Actuarial Journal, 3(2), 30–41. https://doi.org/10.1080/10920277.1999.10595797
- Ferreira, H., & Ferreira, M. (2018). Estimating the extremal index through local dependence. Annales de l'Institut Henri Poincaré, Probabilités et Statistiques, 54(2), 587–605. https://doi.org/10.1214/16-AIHP815
- Finkenstädt, B., & Rootzén, H. E. (2004). Extreme values in finance, telecommunications, and the environment. Chapman & Hall/CRC.
- Fougéres, A.-L., Nolan, J. P., & Rootzén, H. (2009). Models for dependent extremes using stable mixtures. Scandinavian Journal of Statistics, 36, 42–59. https://doi.org/10.1111/j.1467-9469.2008.00613.x
- Galambos, J. (1987). Asymptotic theory of extreme order statistics (2nd ed.). Krieger.
- Hall, P., Peng, L., & Yao, Q. (2002). Moving-maximum models for extrema of time series. Journal of Statistical Planning and Inference, 103(1–2), 51–63. https://doi.org/10.1016/S0378-3758(01)00197-5
- Heffernan, J. E. (2001). A directory of coefficients of tail dependence. Extremes, 3(3), 279–290. https://doi.org/10.1023/A:1011459127975
- Heffernan, J. E., Tawn, J. A., & Zhang, Z. (2007). Asymptotically (in)dependent multivariate maxima of moving maxima processes. Extremes, 10(1-2), 57–82. https://doi.org/10.1007/s10687-007-0035-1
- Hsing, T. (1993). Extremal index estimation for a weakly dependent stationary sequence. The Annals of Statistics, 21(4), 2043–2071. https://doi.org/10.1214/aos/1176349409
- Huser, R., & Davison, A. C. (2013). Composite likelihood estimation for the Brown–Resnick process. Biometrika, 100(2), 511–518. https://doi.org/10.1093/biomet/ass089
- Hüsler, J., & Li, D. (2009). Testing asymptotic independence in bivariate extremes. Journal of Statistical Planning and Inference, 139(3), 990–998. https://doi.org/10.1016/j.jspi.2008.06.003
- Idowu, T., & Zhang, Z. (2017). An extended sparse max-linear moving model with application to high-frequency financial data. Statistical Theory and Related Fields, 1(1), 92–111. https://doi.org/10.1080/24754269.2017.1346852
- Joe, H. (2014). Dependence modeling with copulas. Chapman & Hall/CRC Monographs on Statistics & Applied Probability. Chapman & Hall/CRC.
- Kelly, B. (2014). The dynamic power law model. Extremes, 17(4), 557–583. https://doi.org/10.1007/s10687-014-0193-x
- Kunihama, T., Omori, Y., & Zhang, Z. (2012). Efficient estimation and particle filter for max-stable processes. Journal of Time Series Analysis, 33(1), 61–80. https://doi.org/10.1111/jtsa.2011.33.issue-1
- Leadbetter, M. R. (1983). Extremes and local dependence in stationary sequences. Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete, 65(2), 291–306. https://doi.org/10.1007/BF00532484
- Leadbetter, M. R., Lindgren, G., & Rootzén, H. (1983). Extremes and related properties of random sequences and processes. Springer Science & Business Media.
- Leadbetter, M. R., Weissman, I., de Haan, L., & Rootzén, H. (1989). On clustering of high values in statistically stationary seriess. In J. Sanson (Ed.), Proceedings of the 4th international meeting on statistical climatology. New Zealand Meteorological Service.
- Ledford, A. W., & Tawn, J. A. (1996). Statistics for near independence in multivariate extreme values. Biometrika, 83(1), 169–187. https://doi.org/10.1093/biomet/83.1.169
- Ledford, A. W., & Tawn, J. A. (1997). Modeling dependence within joint tail regions. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 59(2), 475–499. https://doi.org/10.1111/rssb.1997.59.issue-2
- Loynes, R. M. (1965). Extreme values in uniformly mixing stationary stochastic processes. The Annals of Mathematical Statistics, 36(3), 993–999. https://doi.org/10.1214/aoms/1177700071
- Mao, G., & Zhang, Z. (2018). Stochastic tail index model for high frequency financial data with Bayesian analysis. Journal of Econometrics, 205(2), 470–487. https://doi.org/10.1016/j.jeconom.2018.03.019
- Martins, A. P., & Ferreira, H. (2014). Extremal properties of M4 processes. Test, 23(2), 388–408. https://doi.org/10.1007/s11749-014-0358-6
- Massacci, D. (2016). Tail risk dynamics in stock returns: Links to the macroeconomy and global markets connectedness. Management Science, 63(9), 1–18.https://doi.org/10.1287/mnsc.2016.2488
- McNeil, A. J., & Frey, R. (2000). Estimation of tail-related risk measures for heteroscedastic financial time series: An extreme value approach. Journal of Empirical Finance, 7(3–4), 271–300. https://doi.org/10.1016/S0927-5398(00)00012-8
- Meinguet, T. (2012). Maxima of moving maxima of continuous functions. Extremes, 15(3), 267–297. https://doi.org/10.1007/s10687-011-0136-8
- Mikosch, T., Embrechts, P., & Klüppelberg, C. (1997). Modelling extremal events for insurance and finance. Springer Verlag.
- Nandagopalan, S. (1990). Multivariate extremes and the estimation of the extremal index [PhD thesis]. University of North Carolina, Chapel Hill, Dept. Of Statistics.
- Nandagopalan, S. (1994). On the multivariate extremal index. Journal of Research of the National Institute of Standards and Technology, 99(4), 543–550. https://doi.org/10.6028/jres.099.052
- Naveau, P., Zhang, Z., & Zhu, B. (2011). An extension of max autoregressive models. Statistics and Its Interface, 4(2), 253–266. https://doi.org/10.4310/SII.2011.v4.n2.a19
- Newell, G. F. (1964). Asymptotic extremes for m-dependent random variables. The Annals of Mathematical Statistics, 35(3), 1322–1325. https://doi.org/10.1214/aoms/1177703288
- O'Brien, G. L. (1974). Limit theorems for the maximum term of a stationary process. Annals of Probability, 2(3), 540–545. https://doi.org/10.1214/aop/1176996673
- O'Brien, G. L. (1987). Extreme values for stationary and Markov sequences. Annals of Probability, 15(1), 281–291. https://doi.org/10.1214/aop/1176992270
- Peng, L. (1999). Estimation of the coefficient of tail dependence in bivariate extremes. Statistics & Probability Letters, 43(4), 399–409. https://doi.org/10.1016/S0167-7152(98)00280-6
- Pereira, L., & Fonseca, C. (2019). Statistical methods for assessing the contagion of spatial extreme events among regions. Communications in Statistics - Theory and Methods, 48(13), 3208–3218. https://doi.org/10.1080/03610926.2018.1473612
- Pickands, J. (1981). Multivariate extreme value distributions. In Proceedings 43rd session of the international statistical institute (Vol. 49, pp. 859–878).
- Reich, B. J., & Shaby, B. A. (2019). A spatial Markov model for climate extremes. Journal of Computational and Graphical Statistics, 28(1), 117–126. https://doi.org/10.1080/10618600.2018.1482764
- Resnick, S. I. (1987). Extreme values, regular variation, and point processes. Springer.
- Rodgers, J. L., & Nicewander, W. A. (1988). Thirteen ways to look at the correlation coefficient. American Statistician, 42(1), 59–66. https://doi.org/10.2307/2685263
- Salmon, F. (2012). The formula that killed wall street. Significance, 9(1), 16–20. https://doi.org/10.1111/j.1740-9713.2012.00538.x
- Salvadori, G., De Michele, C., Kottegoda, N. T., & Rosso, R. (2007). Extremes in nature: An approach using copulas. Springer. Complexity.
- Sibuya, M. (1959). Bivariate extreme statistics, I. Annals of the Institute of Statistical Mathematics, 11(2), 195–210.
- Smith, R. L. (1985). Maximum likelihood estimation in a class of nonregular cases. Biometrika, 72(1), 67–90. https://doi.org/10.1093/biomet/72.1.67
- Smith, R. L. (1990). Extreme value theory. Handbook of Applicable Mathematics, 7, 437–471.
- Smith, R. L., & Weissman, I. (1994). Estimating the extremal index. Journal of the Royal Statistical Society, Series B, 56(3), 515–528.
- Smith, R. L., & Weissman, I. (1996). Characterization and estimation of the multivariate extremal index. Technical report, University of North Carolina-Chapel Hill.
- Tang, R., Shao, J., & Zhang, Z. (2013). Sparse moving maxima models for tail dependence in multivariate financial time series. Journal of Statistical Planning and Inference, 143(5), 882–895. https://doi.org/10.1016/j.jspi.2012.11.008
- Tawn, J. A. (1988). Bivariate extreme value theory: Models and estimation. Biometrika, 75(3), 397–415.
- Weissman, I. (1994). On the extremal index of stationary sequences. Technical report, The Conference on Multivariate Extreme Value Estimation with Applications to Economics and Finance, Erasmus University, Rotterdam.
- Wu, J., Zhang, Z., & Zhao, Y. (2012). Study of the tail dependence structure in global financial markets using extreme value theory. Journal of Reviews on Global Economics, 1(1), 62–81.
- Yang, X., Frees, E. W., & Zhang, Z. (2011). A generalized beta copula with applications in modeling multivariate long-tailed data. Insurance: Mathematics and Economics, 49(2), 265–284. https://doi.org/10.1016/j.insmatheco.2011.04.007
- Zhang, Z. (2005). A new class of tail-dependent time series models and its applications in financial time series. Advances in Econometrics, 20(B), 323–358.
- Zhang, Z. (2008a). The estimation of M4 processes with geometric moving patterns. Annals of the Institute of Statistical Mathematics, 60(1), 121–150. https://doi.org/10.1007/s10463-006-0078-0
- Zhang, Z. (2008b). Quotient correlation: A sample based alternative to Pearson's correlation. The Annals of Statistics, 36(2), 1007–1030. https://doi.org/10.1214/009053607000000866
- Zhang, Z. (2009). On approximating max-stable processes and constructing extremal copula functions. Statistical Inference for Stochastic Processes, 12(1), 89–114. https://doi.org/10.1007/s11203-008-9027-2
- Zhang, Z., Qi, Y., & Ma, X. (2011). Asymptotic independence of correlation coefficients with application to testing hypothesis of independence. Electronic Journal of Statistics, 5, 342–372. https://doi.org/10.1214/11-EJS610
- Zhang, X., & Schwaab, B. (2017). Tail risk in government bond markets and ECB asset purchases. Working paper.
- Zhang, Z., & Smith, R. L. (2004). The behavior of multivariate maxima of moving maxima processes. Journal of Applied Probability, 41(4), 1113–1123. https://doi.org/10.1239/jap/1101840556
- Zhang, Z., & Smith, R. L. (2010). On the estimation and application of max-stable processes. Journal of Statistical Planning and Inference, 140(5), 1135–1153. https://doi.org/10.1016/j.jspi.2009.10.014
- Zhang, Z., Zhang, C., & Cui, Q. (2017). Random threshold driven tail dependence measures with application to precipitation data analysis. Statistica Sinica, 27(2), 685–709.https://doi.org/10.5705/ss.202015.0421
- Zhang, Z., & Zhu, B. (2016). Copula structured M4 processes with application to high-frequency financial data. Journal of Econometrics, 194(2), 231–241. https://doi.org/10.1016/j.jeconom.2016.05.004
- Zhao, Z., & Zhang, Z. (2018). Semi-parametric dynamic max-copula model for multivariate time series. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 80(2), 409–432. https://doi.org/10.1111/rssb.12256
- Zhao, Z., Zhang, Z., & Chen, R. (2018). Modeling maxima with autoregressive conditional Fréchet model. Journal of Econometrics, 207, 2325–351. https://doi.org/10.1016/j.jeconom.2018.07.004
- Zhou, C. (2008). A two-step estimator of the extreme value index. Extremes, 11(3), 281–302. https://doi.org/10.1007/s10687-008-0058-2