
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This article considers the problem of selecting two-level designs under the baseline parameterisation when some two-factor interactions are important. We propose a minimum aberration criterion, which minimises the bias caused by the non-negligible effects. Using this criterion, a class of optimal designs can be further distinguished from one another, and we present an algorithm to find the minimum aberration designs among the D-optimal designs. Sixteen-run and twenty-run designs are summarised for practical use.
1. Introduction
Fractional factorial designs, due to their run size economy, are widely used in many industrial or scientific areas. Particularly, two-level fractional factorial designs have received the most attention among practitioners. The experimenter often has some prior knowledge that allows a model containing certain important factorial effects to be postulated. While the most commonly used definition of factorial effects is given by a set of mutually orthogonal contrasts, which we refer to as the orthogonal parameterisation, an alternative considered in this article is the baseline parameterisation. Baseline parameterisation is more appropriate when each factor has a default or null state, and its usefulness has been increasingly recognised in recent years. For example, Yang and Speed (Citation2002), Kerr (Citation2006), and Banerjee and Mukerjee (Citation2008) investigated factorial designs under the baseline parameterisation in the context of cDNA microarray experiments.
Firstly proposed by Fries and Hunter (Citation1980), the minimum aberration is a popular criterion for selecting two-level fractional factorial designs. One justification for minimum aberration designs, given by Tang and Deng (Citation1999), is that they provide a protection for the estimation of main effects by minimising the bias caused by the non-negligible interactions. The minimum aberration criterion can further distinguish orthogonal arrays, which are universally optimal (Cheng, Citation1980) under the main effect model. When the baseline parameterisation is under consideration, this idea leads to the minimum K-aberration criterion (Mukerjee & Tang, Citation2012).
In the present paper, we consider how to select baseline designs when, in addition to the main effects, some two-factor interactions are also important. Knowledge of important two-factor interactions arise in many applications. For example, in robust parameter designs, the estimation of interactions between the control and noise factors is crucial for the experimental objectives. Clearly, the minimum K-aberration criterion is not appropriate in this situation, so we propose a modified criterion that sequentially minimises the contamination caused by the non-negligible effects. The modified criterion is then used to further distinguish a class of optimal designs, and an algorithm is given to find out the best designs of sixteen and twenty runs.
This paper is organised as follows. Section 2 introduces notation and provides the definitions of the basic concepts, including factorial effects, minimum aberration criterion, and D-optimality criterion. Section 3 presents an algorithm for searching for minimum aberration baseline designs among D-optimal designs, which is then applied to designs of sixteen and twenty runs. Section 4 is the concluding section.
2. Notation and definitions
2.1. Factorial effects
Consider a two-level factorial involving m factors . Let
denote the mean response at the level combination
, where
or 1 (
). A factorial effect measures the impact on the mean response caused by the level changing of involved factor(s), and is defined by a treatment contrast. Let
be the collection of all possible level combinations. Under the most commonly used orthogonal parmeterisation, for a subset
of
, the h-factor interaction
(the main effect if h = 1) is
(1)
(1) We let
, the grand mean. In the present paper, we focus on the alternative baseline parameterisation. For convenience, here and after we will also denote
by
, and similar notation applies to any other
. Under the baseline parameterisation, the main effect of
is
, and the two-factor interaction
is
. More generally, for a subset
of S, the h-factor interaction
under the baseline parameterisation is
(2)
(2) where
stands for the cardinality of a set. We let
. The main distinction between the orthogonal and baseline parameterisations is that the former defines the effects in an overall sense, while the later defines the effects in a way that the non-involved factors are kept at their baseline levels.
The baseline parameterisation arises naturally in the experiments in which each factor has a default or null state. For example, in a toxicological study, each factor is a toxin, and each treatment is a mix of several toxins. Then, absence and presence can be represented by levels 0 and 1, respectively. The baseline parameterisation is also more appropriate if only a few factors are allowed to change their settings. Consider a situation in which the experimenter wants to improve an industrial process by changing only a few factors' current setting. Let levels 0 and 1 be the current and new settings, respectively. In this case, the baseline effects are more relevant and useful to the experimenter.
2.2. Minimum aberration criteria
An N-run and m-factor design with
or 1 is represented by an
matrix in which a row corresponds to an experimental run and a column to a factor. Let Y be the vector of N observations. Under design D, the main effect model is
where
with
being the all-ones vector, and
. We assume as usual that all observations are uncorrelated and have a common variance. If the interactions cannot be ignored, the true model under D is
(3)
(3) where for
,
is the vector of all interactions involving j factors and
is the corresponding matrix obtained by taking all j-column products from D. Let
be the least square estimator of
under the main effect model, which is biased under model (Equation3
(3)
(3) ), and the bias can be found by
where
,
. The contribution of
to the bias is
, where
is unknown and
depends on the design. To minimise the bias in the estimation of main effects caused by the non-negligible j-factor interactions, Mukerjee and Tang (Citation2012) proposed the minimum K-aberration criterion, which selects designs by sequentially minimising
, a size measure of
, where
is the matrix obtained by deleting the first row of
. Following the same path, we consider the model that contains the intercept, all main effects and some two-factor interactions that are presumably important, as given by
(4)
(4) where
contains all the main effects and the important two-factor interactions, and W is
plus the corresponding columns of
. If the effects outside this model cannot be ignored, the true model is
(5)
(5) where
contains the non-important two-factor interactions and
is the corresponding matrix. Let
be the least square estimator of
under model (Equation4
(4)
(4) ), which is biased under model (Equation5
(5)
(5) ), and the bias can be found by
where
and
, for
. We now define a new criterion, called minimum Q-aberration criterion, which is used to select baseline designs under model (Equation4
(4)
(4) ). Let
,
, and
, the Q-aberration of D. For any two competing designs D and
, let s be the smallest integer such that D and
have different
values. If D has smaller
value than
, we say D has less Q-aberration than
. A design is said to have minimum Q-aberration if there is no other design that has less Q-aberration than it.
Though similar, our approach is slightly different from that of Mukerjee and Tang (Citation2012). The situations considered in Mukerjee and Tang (Citation2012) are screening experiments and they therefore focussed on the estimation of main effects by excluding the intercept from consideration. Our situations are different. If we are able to specify some important two-factor interactions, then we are reasonably confident that the model containing the intercept, main effects and important two-factor interactions is approximately correct. This means that all the parameters in the specified model are important and should be estimated to the best extent possible.
2.3. Optimality criterion
When a model is postulated, the experimenter would like to find designs that enjoy certain optimality properties. The optimality criterion considered in this article is the D-efficiency. Consider model (Equation4(4)
(4) ), the D-efficiency criterion is to minimise
, where p is the number of columns of W, which minimises the volume of the confidence region of
.
In a similar study, Ke and Tang (Citation2003) considered regular designs under the orthogonal parameterisation. Regular designs are guaranteed to have the full efficiency provided they can estimate the fitted model.
Let be the counterpart model of model (Equation4
(4)
(4) ) under the orthogonal parameterisation. That is, the column of X that is associated with
is the ith column of 2D−1, and the column associated with
is the Hadamard product of the ith and jth columns of 2D−1. According to C. Y. Sun and Tang (Citation2020), the two models are equivalent. We have the following lemma, which is a special case of Theorem 3 of C. Y. Sun and Tang (Citation2020).
Lemma 2.1
Consider model (Equation4(4)
(4) ). If D is a baseline design such that X is orthogonal, then it is D-optimal among all competing designs. Moreover, such a D minimises
if there is no
in the model such that w is a proper subset of u.
C. Y. Sun and Tang (Citation2020) considered a model that is more general than model (Equation4(4)
(4) ), and they call
a cap effect if there is no
in the model such that w is a proper subset of u. For example, under the main effect model, all main effect are cap effects. Under model (Equation4
(4)
(4) ), the important two-factor interactions are cap effects, so are the main effects of those factors that are not involved in any important two-factor interaction. As indicated by C. Y. Sun and Tang (Citation2020), the cap effects should be the first in line to be tested for their significance when one seeks a simpler model in the analysis stage.
3. Searching for best baseline designs
In this section, we present an algorithm to search for minimum Q-aberration designs among the D-optimal designs under model (Equation4(4)
(4) ). The first two subsections introduce two necessary concepts, and the algorithm and results are given in the third subsection. The last subsection provides an illustrative example.
3.1. Design isomorphism
Under the orthogonal parameterisation, two designs are isomorphic if one can be obtained from the other by (i) row permutation, (ii) column permutation, (iii) level permutation, or any combination of these three. Mukerjee and Tang (Citation2012) suggest a different definition of isomorphism for baseline designs, which is similarly defined except for that level permutations are not allowed, since the two levels are not symmetric under the baseline parameterisation. To avoid ambiguity, we call the former the combinatorial isomorphism. Clearly, two designs are combinatorially isomorphic if they are isomorphic, but the converse is not true. A two-level orthogonal array is an matrix with entries from a set of two symbols, such that for every two columns, all level-combinations appear equally often. A complete catalogue of combinatorially non-isomorphic two-level orthogonal arrays with
are available in D. X. Sun et al. (Citation2008). A more comprehensive catalogue of orthogonal arrays can be found at http://www.pietereendebak.nl/oapackage/series.html. Based on the catalogue given by D. X. Sun et al. (Citation2008), we will conduct a complete search on the class of baseline designs that are orthogonal arrays, called orthogonal baseline designs for convenience.
3.2. Non-isomorphic models
There are a huge number of models that are given by (Equation4(4)
(4) ). Among these models, many share the same structures. The graph theory is a convenient tool to deal with the model structure. For example, the models with
and
can be represented by the graphs in Figure (a,b), respectively. In such a graph, a vertex stands for a factor, and a line connects two vertices if their interaction is included in the model. Note that the factors (vertices) not involved in any important two-factor interaction do not appear in the graph. We say two models are isomorphic if one can be obtained from the other by relabelling the factors. Let k denote the number of two-factor interactions in model (Equation4
(4)
(4) ). All non-isomorphic models for different values of
are given in Figures . The cases for
are not considered because of the large number of possible models, and also because k tends to be small in practice due to the effect sparsity principle (Wu & Hamada, Citation2011, pp. 173).
Figure 1. Model containing one interaction (k = 1).
Figure 2. Models containing two interactions (k = 2).
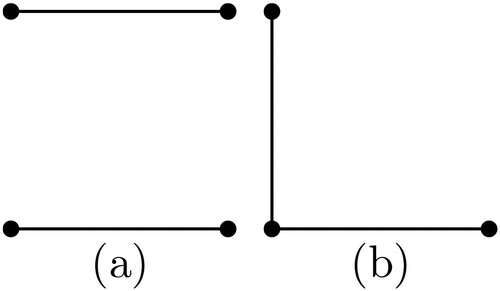
Figure 3. Models containing three interactions (k = 3).
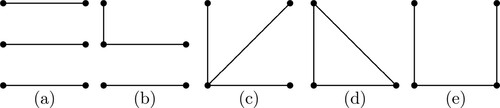
For a given graph and a design matrix, there are many possible ways to assign the columns to the vertexes, and the resulting design efficiency and Q-aberration may be different. To conduct a complete search, all possible column-to-vertex assignments need to be considered, as we will see in the next subsection.
3.3. Algorithm and results
Suppose N experimental runs are allowed to study m factors under a model whose structure is given by a graph R. Let be the combinatorially non-isomorphic
orthogonal arrays in the catalogue given by D. X. Sun et al. (Citation2008), where each
consists of 1 and
. The algorithm proceeds as follows, starting with i = 1.
Set
. If i = 1, set
Switch the two levels 0 and 1 for a subset of factors.
For the resulting baseline design matrix, assign the columns to the vertexes of R.
Obtain the resulting model matrix W and compute the D-efficiency. Compare
Go back to step 3 with another possible column-to-vertex assignment. When all possible assignments are considered, go back to step 2 with another possible subset. When all possible subsets are considered, go back to step 1 with
This algorithm finds a minimum Q-aberration design that is D-optimal among all orthogonal baseline designs. Such a design may not be unique, and is the first one found by the algorithm. In our algorithm, some isomorphic designs may be considered more than once, but no orthogonal baseline design will be missed. If a complete catalogue of non-isomorphic orthogonal baseline designs is available, a more efficient algorithm can be presented.
We apply this algorithm to all models given by Figures – and the for N = 16 and 20 are summarised in Tables . For N = 20, the tables only cover the designs with
, since the required computation increases rapidly when m>7. In each of these tables, the second, third, and the fourth columns indicate, which
should be used, which two-factor interactions should be included in the model, and for which design columns the level switching should be conducted, respectively. The A-efficiency of
is also calculated for the readers' information, where the A-efficiency is
, but it is not used in the search algorithm.
Table 1. Sixteen-run MA baseline designs for the model with k = 1.
Table 2. Sixteen-run MA baseline designs for the models with k = 2.
Table 3. Sixteen-run MA baseline designs for the models with k = 3.
Table 4. Twenty-run MA baseline designs for the model with k = 1.
Table 5. Twenty-run MA baseline designs for the models with k = 2.
Table 6. Twenty-run MA baseline designs for the models with k = 3.
Consider Lemma 2.1. For a given N, m, and a model structure, if there exists a baseline design such that X is orthogonal, then step 4 in the algorithm can be replaced by step below to save the computation. For example, when N = 16 and
, we use it to obtain Tables .
| 4'. | Obtain the counterpart model matrix X under the orthogonal parameterisation. If X is orthogonal and | ||||
Finally, we note that by Lemma 2.1, all the designs given by Tables are D-optimal among all competing designs because the model matrix X has orthogonal columns. The designs in Tables are D-optimal among all 20-run orthogonal arrays as our search is complete.
3.4. An example
We consider a cake baking experiment in which the experimenter wants to improve a cake recipe. There are eight factors: baking time (Time), baking temperature (Temp), the number of eggs, and the amounts of baking powder, flour, sugar, milk (M) and butter. For each factor, there are two settings: the currently used setting and the new setting. The experimenter can only afford a sixteen-run design. Two two-factor interactions are important based on prior knowledge: the temperature-by-time and milk-by-time interactions. In this case, k = 2, N = 16, and m = 8, and the model has the structure 2(b). By Table , the experimenter should start with and set
, and then switch the two levels 0 and 1 for columns 1 and 6. Next, the factors Time, Temp, and M have to be assigned to columns 6, 7, and 8 (or 6, 8, and 7), respectively. All the remaining factors can be randomly assigned to the other columns. By Lemma 2.1, this design guarantees D-optimality among all competing designs; and except for the main effects of Time, Temp, and M, each of the other effects can be estimated with a minimal variance. Among all optimal designs, this design also minimises the contamination to the estimation of
caused by non-negligible effects.
4. Concluding remarks
In our algorithm, we first use D-optimality, and then use the minimum aberration. One can also do it in a reversed order. In fact, the designs that have minimum Q-aberration among all competing designs are generally not orthogonal arrays. Examples are Rechtschaffner designs; see C. Y. Sun and Tang (Citation2020) for details. In our search algorithm, the D-optimality can also be replaced by the A-optimality if one wishes, which is to minimise the A-efficiency and thus minimises . One possible future work is to develop an efficient algorithm that allows us to obtain more designs without complete search. Li et al. (Citation2014) considered this problem for main effects models. Some of the ideas in that paper should be useful for the situations where some two-factor interactions are important.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Anqi Chen
Anqi Chen, is currently studying biostatistics, working towards her PhD at Simon Fraser University. She obtained her BSc and MSc in 2017 and 2019, respectively, from the same institution.
Cheng-Yu Sun
Cheng-Yu, a PhD student in statistics, is working towards his PhD at Simon Fraser University. His research interest is in experimental design, and has published one paper prior to this one.
Boxin Tang
Boxin Tang, a professor of statistics at Simon Fraser University, conducts research in the area of experimental design. He is an elected Fellow of ASA and IMS, and has published more than 60 papers in refereed journals.
References
- Banerjee, T., & Mukerjee, R. (2008). Optimal factorial designs for cDNA microarray experiments. The Annals of Applied Statistics, 2(1), 366–385. https://doi.org/10.1214/07-AOAS144
- Cheng, C. S. (1980). Orthogonal arrays with variable numbers of symbols. The Annals of Statistics, 8(2), 447–453. https://doi.org/10.1214/aos/1176344964
- Fries, A., & Hunter, W. G. (1980). Minimum aberration 2k−p designs. Technometrics, 22(4), 601–608. https://doi.org/10.1080/00401706.1980.10486210
- Ke, W., & Tang, B. (2003). Selecting 2m−p designs using a minimum aberration criterion when some two-factor interactions are important. Technometrics, 45(4), 352–360. https://doi.org/10.1198/004017003000000186
- Kerr, K. F. (2006). Efficient 2k factorial designs for blocks of size 2 with microarray applications. Journal of Quality Technology, 38(4), 309–318. https://doi.org/10.1080/00224065.2006.11918620
- Li, P., Miller, A., & Tang, B. (2014). Algorithmic search for baseline minimum aberration designs. Journal of Statistical Planning and Inference, 149, 172–182. https://doi.org/10.1016/j.jspi.2014.02.009
- Mukerjee, R., & Tang, B. (2012). Optimal fractions of two-level factorials under a baseline parameterization. Biometrika, 99(1), 71–84. https://doi.org/10.1093/biomet/asr071
- Sun, D. X., Li, W., & Ye, K. Q. (2008). Algorithmic construction of catalogs of non-isomorphic two-level orthogonal designs for economic run sizes. Statistics and Applications, 6, 141–155.
- Sun, C. Y., & Tang, B. (2020). Relationship between orthogonal and baseline parameterizations and its applications to design constructions. Statistica Sinica. Accepted.
- Tang, B., & Deng, L. Y. (1999). Minimum G2-aberration for nonregular fractional factorial designs. Annals of Statistics, 27(6), 1914–1926. https://doi.org/10.1214/aos/1017939244
- Wu, C. J., & Hamada, M. S. (2011). Experiments: planning, analysis, and optimization (Vol. 552). John Wiley & Sons.
- Yang, Y. H., & Speed, T. (2002). Design issues for cDNA microarray experiments. Nature Reviews Genetics, 3(8), 579–588. https://doi.org/10.1038/nrg863