
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
As a classical problem, covariance estimation has drawn much attention from the statistical community for decades. Much work has been done under the frequentist and Bayesian frameworks. Aiming to quantify the uncertainty of the estimators without having to choose a prior, we have developed a fiducial approach to the estimation of covariance matrix. Built upon the Fiducial Berstein–von Mises Theorem, we show that the fiducial distribution of the covariate matrix is consistent under our framework. Consequently, the samples generated from this fiducial distribution are good estimators to the true covariance matrix, which enable us to define a meaningful confidence region for the covariance matrix. Lastly, we also show that the fiducial approach can be a powerful tool for identifying clique structures in covariance matrices.
2010 Mathematics Subject Classifications:
1. Introduction
Estimating covariance matrices has historically been a challenging problem. Many regression-based methods have emerged in the last few decades, especially in the concept of ‘large p small n’. Among the notable methods, there are the graphical LASSO algorithms (Friedman et al., Citation2008, Citation2010; Rothman, Citation2012). Pourahmadi provided a detailed overview on the progress of covariance estimation (Pourahmadi, Citation2011). The Positive Definite Sparse Covariance Estimators (PDSCE) method (Rothman, Citation2012) has grained great popularity due to its performance comparing to other current methods, although it only produces a point estimator.
Aiming to have a distribution of good covariance estimators, we propose a generalised fiducial approach. The ideas underpinning fiducial inference were introduced by Fisher (Citation1922,Citation1930,Citation1933,Citation1935), whose intention was to overcome the need for priors and other issues with Bayesian methods perceived at the time. The procedure of fiducial inference allows to obtain a measure on the parameter space without requiring priors and defines approximate pivots for parameters of interest. It is ideal when a priori information about the parameters is unavailable. The key recipe of the fiducial argument is the data generating equation. Roughly, the generalised fiducial likelihood is defined as the distribution of the functional inverse of the data generating mechanism.
One great advantage of the fiducial approach to covariance matrix estimation is that, without specifying a prior, it produces a family of matrices that are close to the true covariance with a probabilistic characterisation using the fiducial likelihood function. This attractive property enables a meaningful definition for matrix confidence regions.
We are particularly interested in a high-dimensional multivariate linear model setting with possibly an atypical sparsity constraint. Instead of classical sparsity assumptions on the covariance matrix, we consider a type of experimental design that enforces sparsity on the covariate matrix. This phenomenon often arises in the studies of metabolomics and proteomics. One example of this setup is modelling the relationship between a set of gene expression levels and a list of metabolomic data. The expression levels of the genes serve as the predictor variables while the response variables are a variety of metabolite levels, such as sugar and triglycerides. It is known that only a small subset of genes contribute to each metabolite level, and each gene can be responsible for just a few metabolite levels.
Under the sparse covariate setting, we derive the generalised fiducial likelihood of the covariate matrix based on given observations and prove its asymptotic consistency as the sample size increases. For the covariance with community structures (cliques), we prove the necessary conditions for achieving accurate clique structure estimation. Samples from the fiducial distribution of a covariate matrix can be generated using Monte Carlo methods. In the general case, a reversible jump Markov chain Monte Carlo (RJMCMC) algorithm may be needed. Similar to the classic likelihood functions, fiducial distributions favour models with more parameters. Therefore, in the case where the exact sparsity structure of the covariate is unclear, a penalty term needs to be added. To obtain a family of covariance estimators in the general case, we adapt a zeroth-order method and develop an efficient RJMCMC algorithm that samples from the penalised fiducial distribution.
The rest of the paper is arranged as follows. In Section 2, we will provide a brief background and development on fiducial inference. Then we will introduce the fiducial model for covariance estimation and derive the Generalised Fiducial Distribution (GFD) for the covariate and covariance matrices and examine the asymptotic property of the GFD of the covariance matrix under minor assumptions in Section 3. Some toy examples on sampling from GFD will also be shown. Section 4 focuses on the clique model, where we show some theoretical results for the clique model and how the fiducial approach can be applied to uncover clique structures. Finally, Section 5 concludes the paper with a summary and a short discussion on the relationship of our approach to Bayesian methods.
2. Generalised fiducial inference
2.1. Brief background
Fiducial inference was first proposed by Fisher (Citation1930) when he introduced the concept of a fiducial distribution of a parameter. In the case of a single parameter family of distributions, Fisher gave the following definition for a fiducial density of the parameter based on a single observation x for the case where the cumulative distribution function
is a monotonic decreasing function of θ:
(1)
(1) A fiducial distribution can be viewed as a Bayesian posterior distribution without hand picking priors. In many single parameter distribution families, Fisher's fiducial intervals coincide with classical confidence interval. For families of distributions with multiple parameters, the fiducial approach leads to confidence set. The definition of fiducial inference has been generalised in the past decades. Hannig et al. (Citation2016) provide a detailed review on the philosophy and current development on the subject.
The generalised fiducial approach has been applied to a variety of models, both parametric and nonparametric, both continuous and discrete. These applications include bioequivalence (Hannig et al., Citation2006), variance components (Cisewski & Hannig, Citation2012; Lidong et al., Citation2008; Li et al., Citation2018), problems of metrology (Hannig et al., Citation2007,Citation2003; Wang et al., Citation2012; Wang & Iyer, Citation2005, Citation2006a, Citation2006b), inter laboratory experiments and international key comparison experiments (Hannig et al., Citation2018; Iyer et al., Citation2004), maximum mean of a multivariate normal distribution (Wandler & Hannig, Citation2011), multiple comparisons (Wandler & Hannig, Citation2012), extreme value estimation (Wandler & Hannig, Citation2012), mixture of normal and Cauchy distributions (Glagovskiy, Citation2006), wavelet regression (Hannig & Lee, Citation2009), high-dimensional regression (Lai et al., Citation2015; Williams & Hannig, Citation2018), item response models (Liu & Hannig, Citation2016,Citation2017), non-parametric survival function estimation with censoring (Cui & Hannig, Citation2019), Other related approaches include Martin and Liu (Citation2015); Schweder and Hjort (Citation2016); Xie and Singh (Citation2013).
2.2. Generalised fiducial distribution
The idea underlying generalised fiducial inference is built upon a data generating algorithm expressing the relationship between the data X and the parameters θ:
(2)
(2) where U is the random component of this data generating algorithm whose distribution is known. The data X are assumed to be created by generating a random variable U and plugging it into the data generating algorithm above.
The GFD inverts Equation (Equation2(2)
(2) ). Assume that
is continuous, and the parameter
. Under the conditions provided in Hannig et al. (Citation2016), fiducial distribution is shown to have density
(3)
(3) where
is the likelihood, and
(4)
(4) Here
is the
Jacobian matrix. The exact form of
depends on the choices made in the process of inverting (Equation2
(2)
(2) ). In this manuscript, we concentrate on what Hannig et al. (Citation2016) calls the
-norm choice:
(5)
(5) where
denotes the matrix transpose of M. Other choices, in particular the
-norm that was often used in the past, leads to similar results is studied in detail in Shi (Citation2015).
3. A fiducial approach to covariance estimation
In this section, we will derive the GFD for the covariance matrix of a multivariate normal random variable. For this problem, various regularised estimators were proposed under the assumption that the true covariance matrix is sparse (Avella-Medina et al., Citation2018; Bickel & Levina, Citation2008a, Citation2008b; Cai & Liu, Citation2011; Furrer & Bengtsson, Citation2007; Huang & Lee, Citation2016; Huang et al., Citation2006; Lam & Fan, Citation2009; Levina et al., Citation2008; Rothman et al., Citation2009, Citation2010; Wu & Pourahmadi, Citation2003). While many of these estimators have been shown to enjoy excellent rates of convergence, so far little work has been done to quantify the uncertainties of their corresponding estimates.
Let denote the transpose of a matrix/vector Q. Denote a collection of n observed p dimensional objects
. For the rest of the paper, we assume p is fixed, unless stated otherwise. Consider the following data generating equation:
(6)
(6) where A is a
matrix of full rank;
are independent and identically distributed (i.i.d)
random vectors following multivariate normal distribution
. Hence,
's are i.i.d random vectors centred at 0 with covariance matrix
,
(7)
(7) Consequently, we have the likelihood for observations
:
(8)
(8) where
is the corresponding sample covariance matrix and
is the trace operator.
We propose to estimate the covariance matrix Σ through the GFD of covariate matrix A:
(9)
(9) Define the stacked observation vector
. Denote
, such that
. Let
be the
-th entry of matrix A, i.e.,
. The corresponding Jacobian
derived from (Equation4
(4)
(4) ) is then
(10)
(10) where
is an
matrix
and
is given by (Equation5
(5)
(5) ).
Often some are known to be zero; a common example is the lower triangular matrix A for which
for l>k. Additionally, sparsity on the covariate model can be introduced by having most of the
known to be zero as a part of the model. Note that if
is known to be zero, as implied by model, then the corresponding
th column is dropped. Therefore, depending on the sparsity model, the dimension of
varies.
Recall, that there is a one-to-one mapping between positive definite matrices Σ and lower triangular matrices A with positive entries on the main diagonal. While we are not assuming A is lower triangular, in order to alleviate some identifiability issues we will assume that all diagonal entries of A are positive, i.e., .
3.1. Jacobian for full models
Suppose that none of the entries of A is fixed at zero, namely, the parameter space Θ for A is . We will refer this to a full model. Under a full model,
consists of p blocks, each of dimension
. Every row of
has non-zero entries in only one block.
By swapping rows in the matrix and plugging
, we obtain the
matrix P:
(11)
(11) where
Notice that P breaks into p blocks,
, where
,
denotes a zero matrix with dimension
.
Since as a consequence of Cauchy–Binnet formula (see also Hannig et al. (Citation2016)), swapping rows do not change the value of the Jacobian function (Equation10(10)
(10) ). Therefore
can be expressed using matrix P:
(12)
(12) where
is the MLE estimator of the covariance matrix.
By (Equation9(9)
(9) ), the GFD is proportional to
(13)
(13) By transforming the GFD of A, we conclude that the GFD of
has the inverse Wishart distribution with n degrees of freedom and parameter
3.2. Jacobian for the general case
While having a closed form for the GFD of Σ for the full model, the covariance estimation requires sufficient number of observations (roughly at least ) to maintain reasonable power. In the cases where n is small, we reduce the parameter space by introducing a sparse structure
, which determines which entries of A are known to be zero. Recall, that we only consider A with positive diagonal entries.
Now assume the general case with a sparse model , where some entries of A are known to be zero. Denote the
th entry of A as
. Define the zero index set for the ith row as
(14)
(14) The set
indicates which entries of A in the ith row are fixed at zero.
Then Equation (Equation10(10)
(10) ) becomes
(15)
(15) where
is the matrix P with correct corresponding columns dropped, i.e., block
is obtained from block
with
columns removed.
Let be the number of nonzero entries in the ith row of A, and
be the sub-matrix of U excluding columns in
, i.e.,
. Consequently, Equation (Equation15
(15)
(15) ) becomes
(16)
(16)
3.3. Consistency of fiducial distribution
In general, there is no one-to-one correspondence between the covariance matrix Σ and the covariate matrix A. However, if A is sparse enough, e.g., a lower triangular matrix with positive diagonal entries, the identifiability problem vanishes. In this section, we will show that, if there is one-to-one correspondence between Σ and A, then the GFD of the covariate matrix achieves a fiducial Bernstein–von Mises Theorem (Theorem 3.1), which provides theoretical guarantees of asymptotic normality and asymptotic efficiency for the GFD (Hannig et al., Citation2016).
The results here are derived based on FM-distance (Förstner & Moonen, Citation1999). For two symmetric positive definite matrices M and N, with the eigenvalues from
, the FM-distance between the two matrices M and N is
(17)
(17) This distance measure is a metric and invariant with respect to both affine transformations of the coordinate system and an inversion of the matrices (Förstner & Moonen, Citation1999).
The Bernstein–von Mises Theorem provides conditions under which the Bayesian posterior distribution is asymptotically normal (van der Vaart, Citation1998; Ghosh & Ramamoorthi, Citation2003). The fiducial Bernstein–von Mises Theorem is an extension that includes a list of conditions under which the GFD is asymptotically normal (Sonderegger & Hannig, Citation2012). Those conditions can be divided into three parts to ensure each of the following:
the Maximum Likelihood Estimator (MLE) is asymptotically normal;
the Bayesian posterior distribution becomes close to that of the MLE;
the fiducial distribution is close to the Bayesian posterior.
It is clear that the MLE of Σ is asymptotically normal. Under our model, the conditions for (b) hold due to Proposition A.1 and the construction of the Jacobian formula; the conditions for (c) are satisfied by Propositions A.2, 3.1. Statements and proofs of the propositions are included in Appendix A.1. Here we state only Proposition 3.1 that contains notation needed in the statement of the main Theorem.
Proposition 3.1
The Jacobian function uniformly on compacts in A, where
is a function of A, independent of the sample size and observations, but depending on the true
. Moreover
is continuous.
Closely following Sonderegger Hannig (Citation2012), we arrive at Theorem 3.1.
Theorem 3.1
Asymptotic Normality
Let be an vectorized observation from the fiducial distribution
and denote the density of
by
, where
is the vectorized version of a maximum likelihood estimator. Let
be the Fisher information matrix of the vectorized version of matrix (A). If the sparsity structure is such, that there is one-to-one correspondence between the true covariance matrix
and the covariate matrix
,
is positive definite,
, then
(18)
(18)
See Appendix A.2 for the proof.
Remark 3.1
Since we assume that the diagonal entries of A are positive, the assumption of one-to-one correspondence between and
is satisfied if rows and columns of A can be permuted so that the resulting matrix is lower triangular matrix with positive entries on diagonal.
There are other highly sparse matrices for which there might be a finite number of different so that
. Of course in this case we cannot distinguish between these
based on data. However, Theorem 3.1 will still be true if we restrict the domain of A to a small enough Euclidean neighbourhood of any of the
. Each of these neighbourhoods being selected with a chance proportional to
.
3.4. Sampling in the general case
Given the true model , standard Markov chain Monte Carlo (MCMC) methods can be utilised for the estimation of the covariance matrix. Under the full model and clique model, the GFD of Σ follows either an inverse Wishart distribution or a composite of inverse Wishart distributions (see Section 3). Sampling from the GFD becomes straight forward and it can be done through one of the inverse Wishart random generation functions, e.g., InvWishart (MCMCpack, R) or iwishrnd (Matlab).
When p is small and n is large, the estimation of Σ can always be done through this setting, regardless if there are zero entries in A. The concept of having entries of A fixed at zero is to impose sparsity structure and allow estimation under a high dimensional setting without requiring large number of observations. As in practice the true sparse structure is often unobserved, we will focus on the cases where is not given.
For the general case, if the sparse model is unknown, we propose to utilise a reversible jump MCMC (RJMCMC) method to efficiently sample from Equation (Equation20(20)
(20) ) and simultaneously update
.
RJMCMC is an extension of standard Markov chain Monte Carlo methods that allows simulation of the target distribution on spaces of varying dimensions (Green, Citation1995). The ‘jumps’ refers to moves between models with possibly different parameter spaces. More details on RJMCMC can be found in Shi (Citation2015). Since is unknown, namely the number and the locations of fixed zeros in the matrix A are unknown, the property of jumping between parameter spaces with different dimension is desired for estimating
. Because the search space for RJMCMC is both within parameter space and between spaces, it is known for slower convergence. To improve efficiency of the algorithm, we adapt the zeroth-order method (Brooks et al., Citation2003) and impose additional sparse constrains.
Assuming that there are fixed zeros in A, then for a matrix A, the number needed to be estimated is less than
. If there are many fixed zeros, then this number is much smaller, hence the estimation is feasible even if the number of observations n is less than p. In other words, the sparsity assumption on A allows estimations under a large p small n setting. Suppose the zero entry locations of A are known. The rest of A can be obtain via standard MCMC techniques, such as Metropolis–Hastings.
Figure considers a case with . It shows the confidence curve plot per Markov chain for each statistic of interest. In addition to D2Sig, LogD and Eigvec angle as before, we have GFD (
without the normalising constant). The initial states for the four Markov chains are SnPa (
restricted to maxC (see Section 3.6), in blue), dcho (diagonal matrix of Cholesky decomposition, in cyan), diag (diagonal matrix of
, in yellow) and oracle (true A, in green). In addition, we include the statistics for Σ,
, and the PDSCE estimator in comparison with the confidence curves. They are shown as vertical lines as in the previous example.
Figure 1. All the chains show good estimation of covariance matrix. The estimators are better than both the sample covariance matrix and the PDSCE estimator.
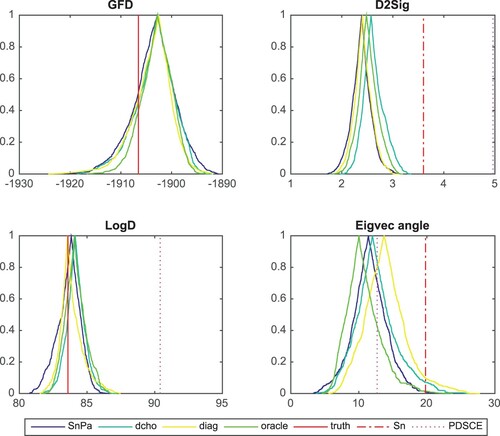
The fiducial estimators have confidence curves peak around the truth in Panels GFD and LogD. In the right two panels, the (majority of) fiducial estimators lie on the left of the dotted-dashed lines, indicating that the estimators are closer to the truth than the sample covariance. The PDSCE estimator falls on the right edge of the Panel D2Sig shows that it is not as close to the truth. As before, the PDSCE estimator overestimates the covariance determinant. Here, burn in = 5000, window = 10,000.
3.5. Model selection for the general case
Often time in practice, to obtain enough statistical power or simply for feasibility, sparse covariates/covariances assumptions are imposed. The exact sparse structure is usually unknown, model selection is required to determine the appropriate parameter space.
Since GFD behaves like the likelihood function, in order to avoid over-fitting, a penalty term on the parameter space needs to be included in the model selection process (Hannig et al., Citation2016).
For the general case, we propose the following penalty function that is based on the Minimum Description Length (MDL) Rissanen (Citation1978) for a model :
(19)
(19) where
corresponds to a
matrix with
many non-fixed-zero elements in its ith row, and n is the number of observations.
The penalised GFD of A is therefore
(20)
(20)
3.6. Sampling in the general case with sparse locations unknown
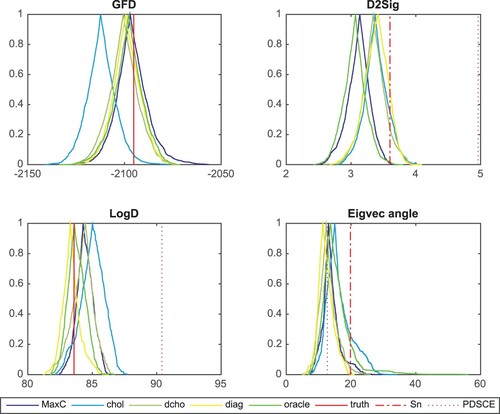
In the general case with sparse locations unknown, we further assume that there is a maximum number of nonzeros per column allowed, denoted as maxC. This additional constraint can be viewed as each predictor only contribute to few tuples of the multivariate response. This assumption has been implemented to reduce the search space for RJMCMC. The starting states include MaxC (, restricted to maxC, in blue) along with chol (in cyan), dcho (in artichoke), diag (in yellow) and true (in green) as before. We will revisit the example discussed in Section 3.4.
(See Figure ). In the left two panels, the fiducial estimators peak at the true fiducial likelihood and covariance determinant. The distance comparison plot (top right) show that the estimators are closer to the truth than both the sample covariance matrix and the PDSCE estimator. Bottom right panel shows that the leading eigenvector of the estimators are as close to the truth as for sample covariance and the PDSCE estimator as in Figure . Here, burn in = 50,000, window = 10,000.
Figure 2. Similar to Figure , the fiducial estimators are better than both the sample covariance matrix and the PDSCE estimator in this case.
Additional simulations are included in the supplementary document.
4. Clique model
4.1. Jacobian for the clique model
Assume that the coordinates of are broken into cliques, i.e., coordinates i and j are correlated if i, j belong to the same clique and independent otherwise. By simply swapping rows and columns of the covariate matrix, we can arrive at a block diagonal form. Without loss of generality, suppose that A is a block diagonal matrix with block sizes
. Then its model
defines the parameter space
. Given
, as an extension of the full model, the GFD function in this case becomes a composite of inverse Wishart distributions:
(21)
(21) where
and
are the sample covariance and covariance component of the ith clique, and
is the
dimensional multivariate gamma function.
4.2. Theoretic results for the clique models
Recall that under the full model,
For clique model selection, we need to evaluate the normalising constant.
(22)
(22) The detailed derivation is provided in Appendix A.3.
Let us denote by a clique model; a collection of k cliques – sets of indexes that are related to each other. The coordinates are assumed independent if they are not in the same cliques. For any positive-definite symmetric matrix S, whose dimension is compatible with
, we denote
as the matrix obtained from S by setting the off-diagonal entries that corresponds to pairs of indexes not in the same clique within
to zero. Note that
is a block diagonal (after possible permutations of rows and columns) positive-definite symmetric matrix.
The classical Fischer–Hadamard inequality (Fischer, Citation1908) implies that for any positive definite symmetric matrix S and any clique model Ipsen Lee (Citation2011) provides a useful lower bound. Let ρ be the spectral radius and λ be the smallest eigenvalue of
,
(23)
(23) Assume the clique sizes are
Then the GFD of the model is
(24)
(24) where
denotes the Jacobian constant term
computed only using the observations in the ith clique.
In the remaining part of this section, we consider the dimension of as a fixed number p and the sample size
. Similar arguments could be extended to
with
.
Given two clique models and
. We write
if cliques in
are obtained by merging cliques in
. Consequently,
has fewer cliques and these cliques are larger than
. Let
be the ‘true’ clique model and covariance matrix used to generate the observed data. We will call all the clique models
satisfying
compatible with the true covariance matrix. We assume that
for all clique models compatible with
.
The following theorem provides some guidelines for choosing penalty function . Its proof is included in the appendix. Define the penalised GFD of the model as
.
Theorem 4.1
For any clique model that is not compatible with
, assume
and the penalty
for all a>0 as
.
For any clique model compatible with
assume that
is bounded.
Then as with p held fixed
The exact form of the penalty function depends on the norm choice for the Jacobian. Under the -norm, the following penalty function works well.
(25)
(25) It is easy to check that Equation (Equation25
(25)
(25) ) satisfies Theorem 4.1.
4.3. Sampling from a clique model
The estimation of cliques is closely related to applications in network analysis, such as communities of people in social networks and gene regulatory network. Recall the penalised clique model GFD introduced in Section 4.2,
Assuming that both the number of cliques k and the clique sizes
's are unknown, the clique structure can be estimated via Gibbs sampler. The first example shows the simulation result for a
covariance matrix (Figure ). We consider the covariance matrix to be with 1's on the diagonal and
th entry being 0.5 if the coordinate
belongs to a clique. From top down, left to right, Figure shows the trace plot for
without normalising constant, true covariance Σ, sample covariance
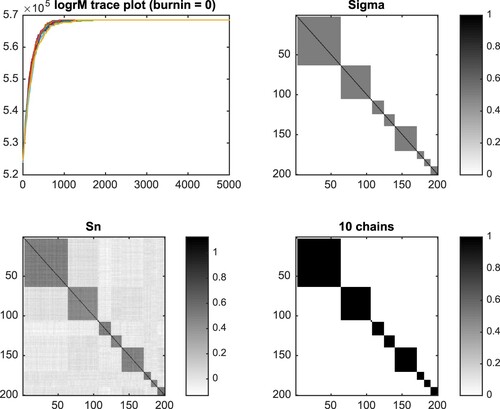
, and the fiducial probability of the estimated cliques based on the 10 Gibbs sampler Markov chains with random initial states. The trace plot helps to monitor the convergence. The fiducial probability of cliques panel reveals the clique structure precisely. The last panel is the aggregate result of 4000 iterations with burn in = 1000 from the 10 Markov chains.
Figure 3. Result for k = 10, p = 200, n = 1000. The trace plot (top left) shows that the chains converge quickly. Although is small, the sample covariance (bottom left) roughly captures the shape of true covariance (top right). The last panel (bottom right) shows that the fiducial estimate captures the true clique structure perfectly.
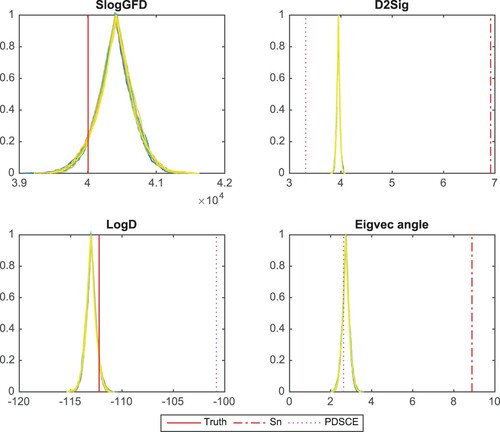
The covariance estimators can be obtained by sampling from inverse Wishart distributions based on the estimated clique structure. Figure shows the confidence curves of four statistics for estimated covariance matrix : log-transformed generalised fiducial likelihood (SlogGFD), distance to Σ (D2Sig), log-determinant (LogD), and angle between the leading eigenvectors of
and Σ (Eigvec angle). The truth for SlogGFD and LogD is shown as red solid vertical lines. In D2Sig and Eigvec angle panels, we include comparisons to sample covariance as red dotted-dashed vertical lines. In addition, we compute the point estimation via the Positive Definite Sparse Covariance Estimators (PDSCE) method introduced in Rothman (Citation2012). Its corresponding statistics are shown as magenta dotted vertical lines. In this example, the fiducial estimates peak near the truth in Panels SlogGFD and LogD. The estimated covariance matrices all appear to be more similar to Σ than
as shown in panels D2Sig and Eigvec angle. The PDSCE estimator is even closer to Σ in terms of FM-distance; it however greatly overestimates
.
Figure 4. Confidence curve plots for estimated covariance matrix. k=10,p=200,n= 1000. Comparing to the sample covariance, the estimators are closer to Σ. The PDSCE estimator shows even smaller FM-distance to Σ, it, however, greatly overestimates .
The PDSCE method produces a good point estimator to the covariance matrix. It is worth noting that our method shows similar performance with the benefit of producing a distribution of estimators.
With the same underlying clique model, we generate 200 data sets. Then we apply our method with a random Markov chain starting point and compute the one-sided p-values for the estimate covariance log determinant. With the same true covariance matrix, a new set of 1000 observations are generated for each simulation. Figure shows the quantile–quantile plot of the p-values against the uniform [0,1] distribution. The dotted-dashed envelope is the 95% coverage band. It shows a well-calibrated 95% confidence interval. The p-value curve (in green) is well enclosed by the envelope, indicating good calibration of the coverage.
Figure 5. 95% coverage plots for 200 repeated simulations. k=10,p=200,n= 1000. The p-values (in green) roughly follow a uniform [0,1] distribution, and they lie inside of the envelope.
![Figure 5. 95% coverage plots for 200 repeated simulations. k=10,p=200,n= 1000. The p-values (in green) roughly follow a uniform [0,1] distribution, and they lie inside of the envelope.](/cms/asset/eb1e8be7-c3e5-4070-8760-5d5d13f6b865/tstf_a_1877950_f0005_oc.jpg)
5. Discussion
Covariance estimation is an important problem in statistics. In this manuscript, we propose to look into this classical problem via a generalised fiducial approach. We demonstrate that, under mild assumptions, the GFD of the covariate matrix is asymptotically normal. In addition, we discuss the clique model and show that the fiducial approach is a powerful tool for identifying clique structures, even when the dimension of the parameter space is large and the ratio n/p is small. To identify the covariance structure for non-clique models, in contrast to typical sparse covariance/precision matrix assumptions, we look at cases where the ratio n/p is small and the covariate matrix is sparse. This ‘unusual’ sparsity assumption arises in applications where multiple dependent variables contribute to several response variables collaboratively. The fiducial approach allows us to obtain a distribution of covariance estimators that are better than sample covariance and comparable to the PDSCE estimator. The distances to true covariance matrix show that as dimension increases, the fiducial estimators become closer to the true covariance matrix.
Similar to Bayesian approaches, generalised fiducial inference produces a distribution of estimators, yet the two methods differ fundamentally. Bayesian methods rely on prior distributions on the parameter of interest, while fiducial approaches depend on the data generating equation. In the framework discussed here, the data generating mechanism is natural to establish than choosing appropriate priors while some other times priors are easier to construct.
Estimating sparse covariance matrix without knowing the fixed zeros is a hard problem. While our approach shows promising results for the clique model, for the general case it still suffers from a few drawbacks: (1) due to the nature of RJMCMC, the computational burden can be significant if the matrix is not very sparse; (2) to limit the search space, a row/column-wise sparsity upper bound needs to be chosen based on prior knowledge of the data type; (3) the results presented in this manuscript assume a squared covariate matrix, which can be limited to direct applications to high-throughput data. Furthermore, a more sophisticated way of choosing initial states and mixing method can improve the efficiency of our algorithm. It is possible and well worth it to extend our current work to more general cases.
Supplemental Material
Download PDF (2.7 MB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
W. Jenny Shi
W. Jenny Shi obtained her PhD in Statistics from the University of North Carolina. From 2015 to 2018, she was a National Institute of Health postdoctoral fellow at the University of Colorado. She is now a Quantitative Strategist at MassMutual, specializing in financial modeling and strategic initiatives.
Jan Hannig
Jan Hannig received his Mgr (MS equivalent) in mathematics in 1996 from the Charles University, Prague, Czech Republic. He received Ph.D. in statistics and probability in 2000 from Michigan State University under the direction of Professor A.V. Skorokhod. From 2000 to 2008 he was on the faculty of the Department of Statistics at Colorado State University where he was promoted to an Associate Professor. He has joined the Department of Statistics and Operation Research at the University of North Carolina at Chapel Hill in 2008 and was promoted to Professor in 2013. He is an elected member of International Statistical Institute and a fellow of the American Statistical Association and Institute of Mathematical Statistics.
Randy C. S. Lai
Randy C. S. Lai obtained his Ph.D. in Statistics from the University of California, Davis (UC Davis). In 2015–2019 he was an Assistant Professor at the University of Maine. He is now a Visiting Assistant Professor at UC Davis, and he will join Google as a Data Scientist in Spring 2021. His research interests include fiducial inference and statistical computing.
Thomas C. M. Lee
Thomas C. M. Lee is Professor of Statistics and Associate Dean for the Faculty in Mathematical and Physical Sciences at the University of California, Davis. He is an elected Fellow of the American Association for the Advancement of Science (AAAS), the American Statistical Association (ASA), and the Institute of Mathematical Statistics (IMS). From 2013 to 2015 he served as the editor-in-chief for the Journal of Computational and Graphical Statistics, and from 2015 to 2018 he served as the Chair of the Department of Statistics at UC Davis. His recent research interests include astrostatistics, fiducial inference, machine learning, and statistical image and signal processing.
References
- Abramowitz, M., & Stegun, I. A. (1964). Handbook of mathematical functions: with formula, graphs and mathematical tables. Courier Corporation.
- Avella-Medina, M., Battey, H. S., Fan, J., & Li, Q. (2018). Robust estimation of high-dimensional covariance and precision matrices. Biometrika, 105, 271–284. https://doi.org/https://doi.org/10.1093/biomet/asy011
- Bickel, P. J., & Levina, E. (2008a). Covariance regularization by thresholding. The Annals of Statistics, 36, 2577–2604. https://doi.org/https://doi.org/10.1214/08-AOS600
- Bickel, P. J., & Levina, E. (2008b). Regularized estimation of large covariance matrices. The Annals of Statistics, 36, 199–227. https://doi.org/https://doi.org/10.1214/009053607000000758
- Brooks, S. P., Giudici, P., & Roberts, G. O. (2003). Efficient construction of reversible jump Markov chain Monte Carlo proposal distributions. Journal of the Royal Statistical Society, 65(1), 3–39. https://doi.org/https://doi.org/10.1111/rssb.2003.65.issue-1
- Cai, T., & Liu, W. (2011). Adaptive thresholding for sparse covariance matrix estimation. Journal of the American Statistical Association, 106, 672–684. https://doi.org/https://doi.org/10.1198/jasa.2011.tm10560
- Cisewski, J., & Hannig, J. (2012). Generalized fiducial inference for normal linear mixed models. The Annals of Statistics, 40(4), 2102–2127. https://doi.org/https://doi.org/10.1214/12-AOS1030
- Cui, Y., & Hannig, J. (2019). Nonparametric generalized fiducial inference for survival functions under censoring, with discussion and rejoinder by the author. Biometrika, 106, 501–518. https://doi.org/https://doi.org/10.1093/biomet/asz016
- Fischer, E. (1908). Uber den hadamardschen determinantensatz. Archiv D Math U Phys, 13, 32–40.
- Fisher, R. A. (1922). On the mathematical foundations of theoretical statistics. Philosophical Transactions of the Royal Society of London. Series A, 222, 309–368. https://doi.org/https://doi.org/10.1098/rsta.1922.0009
- Fisher, R. A. (1930). Inverse probability. Proceedings of the Cambridge Philosophical Society, 26, 528–535. https://doi.org/https://doi.org/10.1017/S0305004100016297
- Fisher, R. A. (1933). The concepts of inverse probability and fiducial probability referring to unknown parameters. Proceedings of the Royal Society of London Series A, 139, 343–348.
- Fisher, R. A. (1935). The fiducial argument in statistical inference. The Annals of Eugenics, 6, 91–98.
- Förstner, W., & Moonen, B. (1999). A metric for covariance matrices. In Quo vadis geodesia? Festschrift for Erik W. Grafarend on the occasion of his 60th birthday, Schriftenreihe der Institute des Studiengangs Geodäsie und Geoinformatik (pp. 113–128). IAGB, Stuttgart.
- Friedman, J., Hastie, T., & Tibshirani, R. (2008). Sparse inverse covariance estimation with the graphical lasso. Biostatistics (Oxford, England), 9(3), 432–441. https://doi.org/https://doi.org/10.1093/biostatistics/kxm045
- Friedman, J., Hastie, T., & Tibshirani, R. (2010). Applications of lasso and grouped lass to estimation of sparse graphical models. Technical Report, Standford University.
- Furrer, R., & Bengtsson, T. (2007). Estimation of high-dimensional prior and posterior covariance matrices in Kalman filter variants. Journal of Multivariate Analysis, 98, 227–255. https://doi.org/https://doi.org/10.1016/j.jmva.2006.08.003
- Ghosh, J. K., & Ramamoorthi, R. V. (2003). Bayesian nonparametrics. Springer Series in Statistiscs. Springer-Verlag.
- Glagovskiy, Y. S. (2006). Construction of fiducial confidence intervals for the mixture of cauchy and normal distributions(Master's thesis). Colorado State University.
- Green, P. J. (1995). Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika, 82(4), 711–732. https://doi.org/https://doi.org/10.1093/biomet/82.4.711
- Hannig, J., Feng, Q., Iyer, H., Wang, C., & Liu, X. (2018). Fusion learning for inter-laboratory comparisons. Journal of Statistical Planning and Inference, 195, 64–79. https://doi.org/https://doi.org/10.1016/j.jspi.2017.09.011
- Hannig, J., Iyer, H. K., Lai, R. C. S., & Lee, T. C. M. (2016). Generalized fiducial inference: a review and new results. Journal of the American Statistical Association, 111, 1346–1361. https://doi.org/https://doi.org/10.1080/01621459.2016.1165102
- Hannig, J., Iyer, H. K., & Wang, J. C. M. (2007). Fiducial approach to uncertainty assessment: account for error due to instrument resolution. Metrologia, 44, 476–483. https://doi.org/https://doi.org/10.1088/0026-1394/44/6/006
- Hannig, J., & Lee, T. C. M. (2009). Generalized fiducial inference for wavelet regression. Biometrika, 96, 847–860. https://doi.org/https://doi.org/10.1093/biomet/asp050
- Hannig, J., Lidong, E., Abdel-Karim, A., & Iyer, H. K. (2006). Simultaneous fiducial generalized confidence intervals for ratios of means of lognormal distributions. Austrian Journal of Statistics, 35, 261–269. https://doi.org/https://doi.org/10.17713/ajs.v35i2&3.372
- Hannig, J., Wang, J. C. M., & Iyer, H. K. (2003). Uncertainty calculation for the ratio of dependent measurements. Metrologia, 4, 177–186. https://doi.org/https://doi.org/10.1088/0026-1394/40/4/306
- Huang, H.-C., & Lee, T. C. M. (2016). High-dimensional covariance estimation under the presence of outliers. Statistics and Its Interface, 9, 461–468. https://doi.org/https://doi.org/10.4310/SII.2016.v9.n4.a6
- Huang, J. Z., Liu, N., Pourahmadi, M., & Liu, L. (2006). Covariance matrix selection and estimation via penalised normal likelihood. Biometrika, 93, 85–98. https://doi.org/https://doi.org/10.1093/biomet/93.1.85
- Ipsen, I. C., & Lee, D. J. (2011). Determinant approximations. arXiv preprint arXiv:1105.0437.
- Iyer, H. K., Wang, C. M. J., & Mathew, T. (2004). Models and confidence intervals for true values in interlaboratory trials. Journal of the American Statistical Association, 99, 1060–1071. https://doi.org/https://doi.org/10.1198/016214504000001682
- Jameson, G. (2013). Inequalities for gamma function ratios. The American Mathematical Monthly, 120(10), 936–940. https://doi.org/https://doi.org/10.4169/amer.math.monthly.120.10.936
- Lai, R. C. S., Hannig, J., & Lee, T. C. M. (2015). Generalized fiducial inference for ultrahigh dimensional regression. Journal of American Statistical Association, 110, 760–772. https://doi.org/https://doi.org/10.1080/01621459.2014.931237
- Lam, C., & Fan, J. (2009). Sparsistency and rates of convergence in large covariance matrix estimation. The Annals of Statistics, 37, 42–54. https://doi.org/https://doi.org/10.1214/09-AOS720
- Levina, E., Rothman, A. J., & Zhu, J. (2008). Sparse estimation of large covariance matrices via a nested lasso penalty. The Annals of Applied Statistics, 2, 245–263. https://doi.org/https://doi.org/10.1214/07-AOAS139
- Li, X., Su, H., & Liang, H. (2018). Fiducial generalized p-values for testing zero-variance components in linear mixed-effects models. Science China Mathematics, 61(7), 1303–1318. https://doi.org/https://doi.org/10.1007/s11425-016-9068-8
- Lidong, E., Hannig, J., & Iyer, H. K. (2008). Fiducial intervals for variance components in an unbalanced two-component normal mixed linear model. Journal of the American Statistical Association, 103, 854–865. https://doi.org/https://doi.org/10.1198/016214508000000229
- Liu, Y., & Hannig, J. (2016). Generalized fiducial inference for binary logistic item response models. Psychometrica, 81, 290–324. https://doi.org/https://doi.org/10.1007/s11336-015-9492-7
- Liu, Y., & Hannig, J. (2017). Generalized fiducial inference for logistic graded response models. Psychometrica, 82, 1097–1125. https://doi.org/https://doi.org/10.1007/s11336-017-9554-0
- Martin, R., & Liu, C. (2015). Inferential models: reasoning with uncertainty. CRC Press.
- Pourahmadi, M. (2011). Covariance estimation: the GLM and regularization perspectives. Statistical Science, 26(3), 369–387. https://doi.org/https://doi.org/10.1214/11-STS358
- Rissanen, J. (1978). Modeling by shortest data description. Automatica, 14(5), 465–658. https://doi.org/https://doi.org/10.1016/0005-1098(78)90005-5
- Rothman, A. (2012). Positive definite estimators of large covariance matrices. Biometrika, 99(3), 733–740. https://doi.org/https://doi.org/10.1093/biomet/ass025
- Rothman, A. J., Levina, E., & Zhu, J. (2009). Generalized thresholding of large covariance matrices. Journal of the American Statistical Association, 104, 177–186. https://doi.org/https://doi.org/10.1198/jasa.2009.0101
- Rothman, A. J., Levina, E., & Zhu, J. (2010). A new approach to Cholesky-based covariance regularization in high dimensions. Biometrika, 97, 539–550. https://doi.org/https://doi.org/10.1093/biomet/asq022
- Schweder, T., & Hjort, N. L. (2016). Confidence, likelihood, probability. Cambridge University Press.
- Shi, W. J. (2015). Bayesian modeling for viral sequencing and covariance estimation via fiducial inference (PhD thesis). University of North Carolina at Chapel Hill.
- Sonderegger, D., & Hannig, J. (2012). Bernstein–von Mises theorem for generalized fiducial distributions with application to free knot splines. Preprint.
- van der Vaart, A. W. (1998). Asymptotic statistics, volume 3 of Cambridge series in Statistical and Probabilistic Mathematics. Cambridge University Press.
- Wandler, D. V., & Hannig, J. (2011). Fiducial inference on maximum mean of a multivariate normal distribution. Journal of Multivariate Analysis, 102, 87–104. https://doi.org/https://doi.org/10.1016/j.jmva.2010.08.003
- Wandler, D. V., & Hannig, J. (2012). A fiducial approach to multiple comparisons. Journal of Statistical Planning and Inference, 142, 878–895. https://doi.org/https://doi.org/10.1016/j.jspi.2011.10.011
- Wandler, D. V., & Hannig, J. (2012). Generalized fiducial confidence intervals for extremes. Extremes, 15, 67–87. https://doi.org/https://doi.org/10.1007/s10687-011-0127-9
- Wang, J. C. M., Hannig, J., & Iyer, H. K. (2012). Pivotal methods in the propagation of distributions. Metrologia, 49, 382–389. https://doi.org/https://doi.org/10.1088/0026-1394/49/3/382
- Wang, J. C. M., & Iyer, H. K. (2005). Propagation of uncertainties in measurements using generalized inference. Metrologia, 42, 145–153. https://doi.org/https://doi.org/10.1088/0026-1394/42/2/010
- Wang, J. C. M., & Iyer, H. K. (2006a). A generalized confidence interval for a measurand in the presence of type-a and type-b uncertainties. Measurement, 39, 856–863. https://doi.org/https://doi.org/10.1016/j.measurement.2006.04.011
- Wang, J. C. M., & Iyer, H. K. (2006b). Uncertainty of analysis of vector measurands using fiducial inference. Metrologia, 43, 486–494. https://doi.org/https://doi.org/10.1088/0026-1394/43/6/002
- Williams, J., & Hannig, J. (2018). Non-penalized variable selection in high-dimensional linear model settings via generalized fiducial inference. Annals of Statistics, 47(3), 1723–1753. https://doi.org/https://doi.org/10.1214/18-AOS1733
- Wu, W. B., & Pourahmadi, M. (2003). Nonparametric estimation of large covariance matrices of longitudinal data. Biometrika, 90, 831–844. https://doi.org/https://doi.org/10.1093/biomet/90.4.831
- Xie, M., & Singh, K. (2013). Confidence distribution, the frequentist distribution estimator of a parameter: a review. International Statistical Review, 81, 3–39. https://doi.org/https://doi.org/10.1111/insr.2013.81.issue-1
Appendix
A.1. Regularity conditions and Jacobian formula
Before proving the theorem on consistency of the GFD, we will first define the δ-neighbourhood of and establish some regularity conditions on the likelihood function and Jacobian formula (Propositions A.1, A.2, 3.1).
Definition A.1
For a fixed covariate matrix and
, define the δ-neighbourhood of
as the set
. Recall that
is the FM-distance (Equation17
(17)
(17) ).
Proposition A.1
For any there exists
such that
where
Proof.
Let . Denote
as the sample covariance matrix as before,
. Since
is the maximum likelihood estimator, we have
Define
. For an arbitrary
assume that
's and
's are the eigenvalues of
and
, respectively. Suppose that
, then
So there exists
, such that
, then
due to the fact that the function
is concave with unique maxima
;
.
Meanwhile,
This implies
Let
. Then
. Notice that
Therefore,
Proposition A.2
Let be as above. Then for any
where
is the joint likelihood of p observations
.
Proof.
Note that
For any
, denote
and let t>0, we have
Note that the numerator goes to
at most as fast as
. Meanwhile, for a fixed n and any
,
By Proposition (A.1),
i.e., the denominator goes to infinity at least as fast as
.
Proof of Proposition 3.1.
Proof of Proposition 3.1
Given an ordered index vector , let
, where each
is a
vector with 1 in the
th tuple and 0 everywhere else. Denote
.
Under the -norm,
where
is the list of indexes of fixed zeros in the ith row of A.
By the Strong Law of Large Numbers for and continuity of
,
Note that both
and
are polynomials of entries of
If the domain of A is in compact, the coefficients of
converge to the coefficients of
uniformly. Furthermore, the derivative is bounded, hence
is equicontinuous. We have
uniformly on compacts in A.
A.2. Proof of Theorem 3.1
Proof.
Proposition 3.1 implies
Notice that
It suffices to show that
(A1)
(A1) Let
be the ijth entry of C, where
. By Taylor Theorem,
for some
. Notice that
. Given any
and t>0, the parameter space
can be partitioned into three regions:
On
,
Since
is a proper prior on the region
, the second term goes to zero by the Bayesian Bernstein–von Mises Theorem (see the proof of Theorem 1.4.2 in Ghosh and Ramamoorthi (Citation2003)).
Next we notice that
Since
, we have
Furthermore,
so the integral converges in probability to 1. Since
and
, the term goes to 0 in probability.
Turning our attention to , notice that
The last integral goes to zero in
because
.
For each , let
be
Note that as n goes to infinity, the first two product terms,
and
, are both bounded; the exponent term goes to
by Proposition A.2, so the integral goes to zero in probability.
Having shown Equation (EquationA1(A1)
(A1) ), we now follow Ghosh and Ramamoorthi (Citation2003) and let
Then the main result to be proven Equation (Equation18
(18)
(18) ) becomes
(A2)
(A2) Because
and (EquationA1
(A1)
(A1) ) implies that
. It is sufficient to show that the integral in Equation (EquationA2
(A2)
(A2) ) goes to 0 in probability. This integral is less than
, where
and
Equation (EquationA1
(A1)
(A1) ) shows that
in probability.
Since
we have
A.3. Derivation of the normalising constant (22)
Using a substitution with the Jacobian
we have
The last equality follows from the fact that for a
matrix of independent standard normal normal variables Z we have
A.4. Lemmas for the clique model
Lemma A.1
Under the -norm, for any clique model
with k cliques of sizes
, we have
where
is the sample covariance computed using only observations within clique i under the model
, and
denotes the ith block component of
.
Proof.
The Strong Law of Large Numbers implies a.s. for each
and the results follow by continuity.
Lemma A.1 provides the limits of the constant as sample size increases. The next lemma shows how the ratio
behaves when sample size increases.
Lemma A.2
Let and
be integers such that
. Then as
Proof.
It is well known (Abramowitz & Stegun, Citation1964) that
(A3)
(A3) Recall
Since both numerator and denominator include a product of p gamma functions, the result of the lemma then follows directly from Equation (EquationA3
(A3)
(A3) ). Note that Equation (EquationA3
(A3)
(A3) ) will be sufficient when p is fixed. More precise bounds available in Jameson (Citation2013) could be used when p is growing with n.
Lemma A.3
Let be a clique model.
If
, then there is a>0, such that
If
Proof.
If , set
By the Strong Law of Large Numbers,
Thus eventually a.s.
and the statement of the lemma follows.
If is compatible with
, by the Central Limit Theorem
By Slutsky's theorem the spectral radius and minimum eigenvalue of
satisfy
and
respectively. Consequently by (Equation23
(23)
(23) )
A.5. Proof of Theorem 4.1
Theorem 4.1
For any clique model that is not compatible with
assume
and the penalty
for all a>0 as
.
For any clique model compatible with
assume that
is bounded.
Then as with p held fixed
Proof.
Because for any fixed p there are finitely many clique models, we only need to prove that for any ,
.
Denote by , the size of cliques in
and
, the size of cliques in
.
By Lemma (A.1), (A.2) we have as
where K is a constant independent of n.
If is not compatible with
by assumption and Lemma A.3(i), we have
a.s.
If is compatible with
notice that
is obtained by pooling together some cliques of
. Therefore
. Consequently
by assumption and Lemma A.3(ii).