
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Semiparametric mixed-effects double regression models have been used for analysis of longitudinal data in a variety of applications, as they allow researchers to jointly model the mean and variance of the mixed-effects as a function of predictors. However, these models are commonly estimated based on the normality assumption for the errors and the results may thus be sensitive to outliers and/or heavy-tailed data. Quantile regression is an ideal alternative to deal with these problems, as it is insensitive to heteroscedasticity and outliers and can make statistical analysis more robust. In this paper, we consider Bayesian quantile regression analysis for semiparametric mixed-effects double regression models based on the asymmetric Laplace distribution for the errors. We construct a Bayesian hierarchical model and then develop an efficient Markov chain Monte Carlo sampling algorithm to generate posterior samples from the full posterior distributions to conduct the posterior inference. The performance of the proposed procedure is evaluated through simulation studies and a real data application.
1. Introduction
Semiparametric mixed-effects double (SPMED) regression models can be viewed as a useful extension to semiparametric mixed-effects models and provide a more flexible framework for analysis of longitudinal data in a wide range of disciplines, such as biological studies, econometrics, fiance, and social sciences. Compared to that of traditional semiparametric mixed-effects models, they allow researchers to simultaneously model the mean and variance of the mixed-effects as a function of predictors. In many practical applications, we shall be interested in modeling heteroscedastic data by assuming that both the location and scale parameters depend on a set of predictors. For example, in Taguchi-type designed experiments, the researchers are interested in dealing with the scale structures and modeling the source of variability in the observed data.
Many estimation methods have recently been developed for jointly modeling the mean and variance of semiparametric mixed-effects models from both frequentist and Bayesian perspectives. Examples include (Aitkin, Citation1987) for the maximum likelihood (ML) estimation for the mean and variance in normal regression models, Cepeda and Gamerman (Citation2000) for Bayesian analysis of modeling of variance heterogeneity in normal regression models, Lombardia and Sperlich (Citation2007) for the ML estimation of generalized mixed-effects models, Chen and Tang (Citation2010) for Bayesian analysis of semiparametric reproductive dispersion mixed-effects models, Chen and Ye (Citation2009, Citation2011) for Bayesian hierarchical modeling methods on dual response surfaces. Tang and Duan (Citation2012) for Bayesian analysis of semiparametric generalized partial linear mixed models, to name a just few. We observe that estimation of the mean parameters in these models often depends on the normality assumption for the errors, which implies that the results may not be robust when the data exhibit heavy-tailed behavior and/or contain outliers. To tackle this issue, we may employ some heavy-tailed distributions for the errors, which should be less insensitive to heteroscedasticity and outliers and thus make the statistical analysis more robust; see, for example, Fonseca et al. (Citation2008); Kang et al. (Citation2018); Wu et al. (Citation2017).
Alternatively, quantile regression (QR) may be employed to deal with these problems, as it is insensitive to heteroscedasticity and a number of error distributions; see, for example, Koenker and Bassett (Citation1978); Koenker et al. (Citation2018). QR can be view as a type of regression analysis, as it depicts the effects of the predictors on the conditional quantile function of the response variable and thus provides information that the classical mean regression may fail to reflect. In recent decades, the parameter estimation in QR has drawn increasingly attention in the literature, such as the Majorize-Minimization algorithm of Hunter and Lange (Citation2000), the Expectation–Maximization of Tian et al. (Citation2014), and Bayesian method of Yu andMoyeed (Citation2001).
It is worth noting that due to a close relationship between the models with the asymmetric Laplace distribution (ALD) for the errors and the QR analysis (e.g., Yu and Moyeed (Citation2001)), Bayesian QR analysis has been widely studied by specifying the ALD as a working likelihood function. Such a specification is based on the fact that the problem of estimating the regression coefficients in linear QR models is equivalent to that of maximizing the likelihood function in linear models with the ALD for the errors. Furthermore, the utilization of the ALD could make the statistical analysis more robust than the normal distributed error and its mixture representation (Kozumi & Kobayashi, Citation2011)) allows researchers to develop a Bayesian hierarchical model for conducting the posterior inference; see, for example, Alhamzawi and Ali (Citation2018); Kotz et al. (Citation2001); Tian and Song (Citation2020). Yang et al. (Citation2016) discussed the asymptotic validity of posterior inference of pseudo-Bayesian quantile regression methods when the ALD is used as the working likelihood function. Bayesian QR analysis has also been studied in linear mixed-effects models. For instance, Waldmann et al. (Citation2013) studied Bayesian semiparametric additive regression models. Tian et al. (Citation2016) studied Bayesian joint QR analysis for mixed-effects models with different data features. Zhang et al. (Citation2019) investigated Bayesian quantile regression-based partially linear mixed-effects models for analysis of longitudinal data.
As seen in many practical applications, the assumptions of equal variances and normality for the errors may not be appropriate for modeling the data that exhibit heteroscedasticity and have tails heavier than those of a normal distribution. To avoid these assumptions, we may consider semiparametric mixed-effect models (e.g., Geraci (Citation2019); Geraci and Bottai (Citation2014)) or SPMED models (e.g., Xu et al. (Citation2016)) with flexible errors. The main difference between the two types of models is that SPMED models jointly consider the quantile of the response variable and the variance structures of random-effects as a function of the predictors. This framework allows researchers to model various quantiles and the variance based on the same set of the predictors through using parametric linear models that have been extensively studied in the literature. In addition, it is not only insensitive to heteroscedasticity and outliers, but also allows researchers to develop an efficient Markov chain Monte Carlo (MCMC) algorithm for performing the posterior inference. To be best of my knowledge, not much work has been done for conducting Bayesian QR analysis for the SPMED models under the ALD for the error. In this paper, we fill this gap by developing a Bayesian hierarchical SPMED model based on an assumption that both the quantile and variance parameters rely on a set of predictors under consideration, which could depict the effects of a set of predictors on the complete conditional distribution of a response variable.
The remainder of this paper is organized as follows. In Section 2, we briefly overview SPMED regression models and discuss the specification of the ALD as a working likelihood for the errors. In Section 3, we discuss prior distributions of the model parameters and develop an efficient MCMC-based sampling algorithm for drawing the posterior inference of all unknown parameters. In Section 4, we conduct simulation studies to investigate the performance of the proposed methods. In Section 5, a real-data application is provided for illustrative purposes, and finally, some concluding remarks are given in Section 6 with the Metropolis-Hastings algorithm provided in the Appendix.
2. Quantile semiparametric mixed-effects double regression models
In this section, we introduce quantile SPMED regression models in Section 2.1 and discuss Bayesian analysis of quantile SPMED regression models under the ALD error in Section 2.2.
2.1. Quantile SPMED regression models
Consider the semiparametric mixed-effects model of the form (1)
(1)
where
is the response variable of the ith subject on the jth measurement,
is a
vector of predictor variables,
is a
vector of unknown regression coefficients,
is an unknown smooth function associated with a univariate observed covariate at time
,
is a random-effect of the ith subject with
while
being the heterogeneity variance, and
is the error term. Here, the superscript T represents the transpose of a matrix or a vector. To avoid the need of an intercept, it is assumed that the response
is zero centered. In practical applications, there often exists the variability related to predictors. This motivates us to assume the existence of variance heterogeneity for each subject, in which
is related to a set of predictors
, such that
, where
is a known function and
is a
vector of regression coefficients. There are several known forms for
, such as the log-linear model or the power product model (e.g., Xu et al. (Citation2016)).
Numerous techniques such as the smoothing splines and the kernel methods can be adopted to handle the nonparametric function in (Equation1
(1)
(1) ); see, for example, Fan and Gijbels (Citation1996); Kai et al. (Citation2011), among others. In this paper, we consider the B-spline approximation to convert
into a linear function, which consists of a set of basis functions. Without loss of generality, we assume that
can be partitioned as
, where
is an internal knot. There are
normalized B-spline basis functions
of order M that form a basis for the linear spline space, where
is the kth basis function for
. By following the idea of He et al. (Citation2005), we may set the number of knots to be the integer part of
with
. The model (Equation1
(1)
(1) ) can then be simply linearized as
(2)
(2)
where
is a
vector of basis functions and
is a
vector of the regression coefficients for the basis functions.
We observe from Kozumi and Kobayashi (Citation2011) that if the distribution function of the error in (Equation2
(2)
(2) ) is restricted to have the τth quantile equal to zero, such that
, where
is the probability density function (pdf) of the error, then the τth quantile regression estimator for
and
can be obtained by minimizing the following objective loss function
(3)
(3)
where
is a given quantile level, and the check loss function
is defined as
where
denotes the indicator function. Since the estimators cannot be directly obtained by differentiating the objective function in (Equation3
(3)
(3) ), we may employ numerical methods to calculate these quantile regression estimators; see, for example, Koenker and Park (Citation1996).
2.2. Bayesian quantile SPMED regression models
Within a Bayesian QR framework, we need to specify a density function for the error in (Equation2
(2)
(2) ). Owing to an equivalence between the minimization problem in (Equation3
(3)
(3) ) and the maximization of the likelihood function with the ALD for the errors (e.g., Yu and Moyeed (Citation2001)), we may assume the error in (Equation2
(2)
(2) ) to be the ALD, denoted by
, whose pdf is given by
where μ is the location, θ is the scale, and
stands for the skewness. Analogous to Kozumi and Kobayashi (Citation2011), we can represent the ALD as a normal-exponential mixture summarized in the following proposition.
Proposition 2.1
Let and
be two independent random variables, where
represents an exponential distribution with mean ϑ. If
, then it can be represented by
where
and
.
According to Proposition 2.1, the model in (Equation2(2)
(2) ) under the ALD for the errors can be rewritten as
(4)
(4)
where
and
are independent of each other.
Let be the vector of all response observations with
,
be the time sequence vector with
,
be the design matrix with
,
with
,
with
, and
with
. Denote
with
, where ⊗ is the Kronecker product and
is a vector consisting of
1s. Then the model in (Equation4
(4)
(4) ) can be rewritten as a matrix form
(5)
(5)
where the symbol ‘’ is the Hadamard product that takes two matrices of the same dimensions to multiply element by element. The likelihood function of all model parameters is given by
(6)
(6)
where
with
for
,
is a known function and
is the matrix with its argument on the diagonal,
is a
vector of the regression coefficients,
,
,
, and
with
.
3. Posterior inference
Bayesian analysis begins with prior specifications for the unknown parameters () in (Equation6
(6)
(6) ). We assume that
are independently distributed as multivariate normal distributions, such that
,
, and
, respectively, where
,
,
,
, and
are the prespecified hyperparameters and
is the identity matrix, and
follows an inverse Gamma distribution, denoted by
, where the shape parameter
and the scale parameter
are known positive constants. We assume that
, where
and
are known positive constants. The resulting joint posterior distribution of the unknown parameters
is given by
(7)
(7)
which is indirectly tractable for performing the posterior inference. To tackle this issue, we first derive the full conditional distributions of the unknown parameters and then construct the Gibbs sampler with the Metropolis–Hastings sampling algorithms to generate posterior samples from their full conditional distributions as follows.
Full conditional distribution of
:
Since
Full conditional distribution of
Since
Full conditional distribution of
Since
Full conditional distribution of θ:
Since
Full conditional distribution of
Since
Full conditional distribution of
Since
Full conditional distribution of
The conditional posterior
According to the conditional posteriors from (Equation8(8)
(8) ) to (Equation14
(14)
(14) ), we an construct an efficient MCMC-based sampling algorithm for generating posterior samples from the full conditional distributions of the unknown parameters summarized in Algorithm 1.
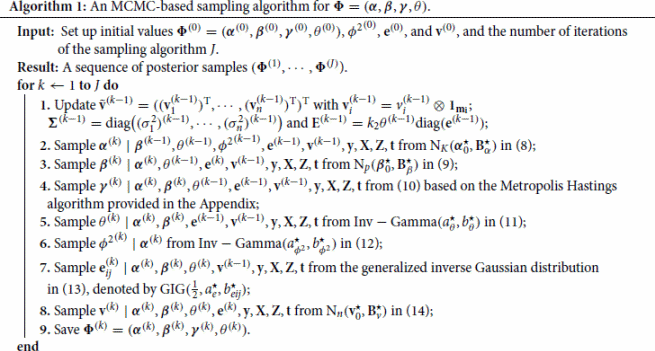
It is worth noting that except the conditional distribution of in Step 4, the sampling schedules for other parameters are based on known distributions and can thus be easily implemented. After the burn-in period, we may assume that the posterior samplers from Algorithm 1 have converged to the joint posterior distribution in (Equation7
(7)
(7) ). Then we collect a total number of M MCMC samples
, for
with M<J. The posterior means of the parameters
can be estimated as follows
respectively.
4. Simulation study
In this section, we conduct simulation studies to evaluate the performance of the proposed Bayesian procedure with respect to different choices of prior information in Section 4.1 and several types of errors in Section 4.2. We here adopt the cubic spline approximation (i.e., M = 4) for the nonparametric function in (Equation1(1)
(1) ). Since the cubic B-spline has two continuous derivatives and a piecewise polynomial of degree three behaves numerically well, it should be sufficient to lead to smooth approximations. All the results were based on 10,000 iterations after discarding the first 2,000 as the burn-in period. There is no evidence of lack of convergence in MCMC simulations according to the run length control diagnostic due to Raftery and Lewis (Citation1992) and the convergence diagnostic test statistic (at a significance level of 5
) proposed by Geweke (Citation1992).
4.1. Quantile regression models with the ALD error
In the simulation study, we consider the model (Equation1(1)
(1) ) of the form
(15)
(15)
where we set
and m = 4. We generate
's from a uniform distribution on (0, 1),
is a
vector, whose elements are independently sampled from N
, and
. For the random effect
, we consider a log-linear structure, such that
with
and
, where
and
are independently sampled from N
. Then
is generated from N
. Since
, we have
with
. We can generate
from
with
.
We conduct the sensitivity analysis of the proposed method with respect to three different choices of the hyperparameters for and
as follows:
Type I: Accurate prior information with
Type II: Inaccurate prior information with
Type III: No prior information with
Other hyperparameters are set as ,
,
,
, and
to reflect weak prior information. It deserves mentioning that we can easily incorporate available prior information into the proposed Bayesian procedure by specifying different values of the hyperparameters. In each type, we consider
and quantile levels
. We generate 100 replications from each combination under consideration.
Figures and depict the true sine curve against its estimated one based on the cubic B-spline approximation. We observe that all estimated curves are close to the true ones, indicating that the cubic B-spline approximation performs well for estimating in (Equation15
(15)
(15) ). Table provides the simulation results for θ,
,
, and
, including the estimated bias and the mean squared error (MSE) under different quantile levels, sample sizes, and the three types of prior information. Several conclusions from this table can be summarized as follows:
As one expects, the bias and MSE of all the parameters decrease significantly at each quantile level as the sample size increases. For instance, there is no significant difference between n = 80 and n = 160. This illustrates that the proposed method could provide accurate estimates even when the sample size is moderate (e.g., n = 80).
We observe that Bayesian estimates are quite robust for the prior specifications for the unknown parameters. The bias and MSE of the parameters do not have distinct difference across three types of considered prior information. We also observe that initial values of parameters and the prior inputs do not affect the performance of the proposed Bayesian method.
It is worth noting that Bayesian estimates of
The results of bias and MSE of all the parameters clearly show that the performance of the proposed Bayesian method is quite satisfactory for any specific combination of sample size and prior information among different quantiles under consideration.
Figure 1. The true sine curve versus its estimated one when n = 80 and . Type I (left panel), Type II (middle panel), and Type III (right panel).
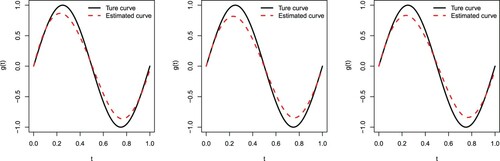
Figure 2. The true sine curve versus the estimated curve when n = 160 and . Type I (left panel), Type II (middle panel), and Type III (right panel).
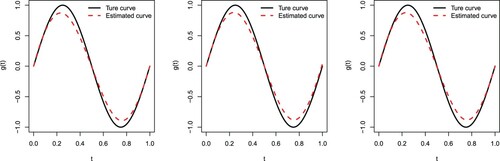
Table 1. Bias and MSE (in parenthesis) of the Bayesian estimates under ALD error distributions.
4.2. Quantile regression models with the non-ALD errors
To further illustrate the performance of the proposed Bayesian method, we consider the following three distributions for the errors
Type A:
Type B:
Type C:
Other simulation settings and the choices of the hyperparameters keep the same as the ones in Section 4.1. We consider n = 80 and . We consider noninformative priors by setting
and
. Numerical results are provided in Table . It can be seen that under Type C, the MSEs of Bayesian estimates are smaller for all the parameters, especially for
and that Bayesian estimates are quite accurate regardless of the errors under consideration.
Table 2. Bias and MSE (in parenthesis) of the Bayesian estimates under non-AL error distributions.
5. Real data application: the multiCenter AIDS cohort study
In this section, we consider the MultiCenter AIDS Cohort Study (MACS) data, which is available in the ‘timereg’ package (Scheike & Zhang, Citation2011). The MACS data set consists of 283 human immunodeficiency virus (HIV) status of homosexual men. This data set has been widely used to study the mean CD4 percentage depletion over time and the effects of other physical status, including age of the patient at the start of the trial, smoking status, and the post-infection CD4 percentage; see, for example, Fan and Li (Citation2004); Xu et al. (Citation2016); Zhao and Xue (Citation2010). Owing to the difference of the trend of CD4 depletion between high CD4 percentage and low CD4 percentage patients, this data set is of specific interest to us for the implementation of the proposed Bayesian quantile SPMED models.
Let be the observation of CD4 percentage at the current visit,
be the smoking status (0 for non-smoker and 1 for smoker),
be the age of the patient at the start of the trial, and
be the post-infection CD4 percentage. To avoid the need of an intercept, it is assume that the response
is zero centered. We also assume that the variance of the random effect
has a linear relationship with two predictors
and
. The Bayesian quantile SPMED regression model can be written as
where
,
,
, and
. Here,
,
, and
with
for
.
We are interested in investigating the relationship between the mean CD4 percentage and time
at different quantile levels
. Due to a lack of prior knowledge, we set all the hyperparameters to be small and let initial values of all the unknown parameters be 0. For the implementation of the Metropolis-Hastings algorithm for sampling
, we set
to achieve approximate acceptance rates of about 35% (Gelman & Gilks, Citation1996). For each quantile level, we run the proposed MCMC-based sampling algorithm 55,000 iterations, discard the first 5,000 as the burn-in period, and then perform a thinning factor of 10, leading to a total number of 5,000 samples for conducting the posterior inference.
Figures and depict the trace and density plots of 5,000 posterior samples of the model parameters. It can be seen from these figures that the MCMC chains of all the parameters rapidly converge to their stationary distributions. Furthermore, we present the autocorrelation function (ACF) plot to in Figure check the autocorrelations between the posterior samples of all the parameters, which shows that the autocorrelations between posterior samples decline to zero at a very fast rate. Similar results are also observed with respect to other quantiles and are not shown here for simplicity. We also conduct the run length control diagnostic of Raftery and Lewis (Citation1992) and the convergence diagnostic test statistic of Geweke (Citation1992) at a significance level of 5, which reconfirm that there is no evidence of lack of convergence of all the MCMC chains.
Figure 3. The trace plot and density plot of 5,000 posterior samples of () when
.
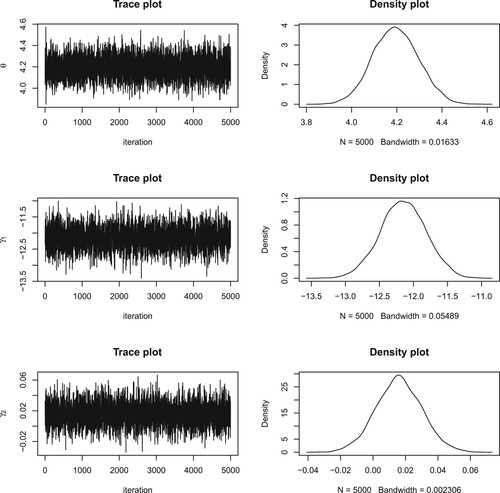
Figure 4. The trace plot and density plot of 5,000 posterior samples of () when
.
Figure 5. The ACF plot of 5,000 posterior samples of the unknown parameters when .
Table summarizes Bayesian estimates (EST) of the unknown parameters and their standard deviation estimates (SD). Figure depicts the estimated CD4 depletion trends under five different quantile levels. As one expects, the CD4 depletion trends are quite distinct among diverse groups of patients. For instance, for the patients who have a high CD4 level around 50, their CD4 percentages almost get back to their original level after 6 years. Other patients' CD4 percentages could decrease quickly after an infection, whereas they would increase at the end. This observation indicates drug usage can be distributed according to the patients' starting CD4 percentages. It deserves mentioning that our results at
are in good agreement with the ones by fitting the local linear fitting method of Fan and Li (Citation2004) and by using the semiparametric varying-coefficient partially linear models of Zhao and Xue(Citation2011).
Figure 6. The mean CD4 percentage vs time
at the 5 different quantile levels.
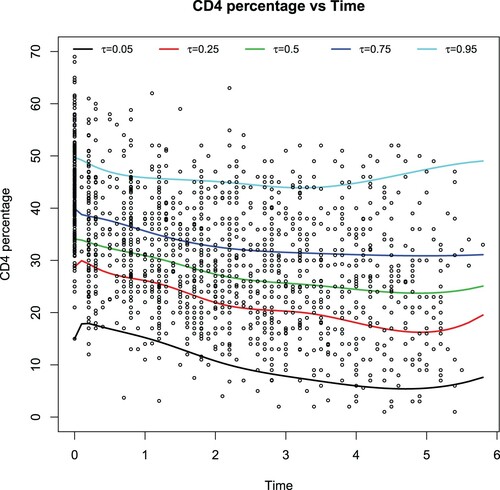
Table 3. The Bayesian estimates of the unknown parameters in the MACS data.
6. Concluding remarks
In this paper, we developed Bayesian methods for parameter estimation in quantile semiparametric mixed-effects double regression models by modeling the variance of the mixed-effects as a function of predictors. A Bayesian hierarchical model was developed and an efficient MCMC-based sampling algorithm was proposed for performing the full posterior inference. Numerical results from both simulation studies and a real data application showed that the proposed procedures perform well in general settings and can accurately estimate the parameters of interest under different scenarios. It is known that variable selection is as important as parameter estimation in modeling the longitudinal data, and for future work, we conduct Bayesian variable selection in quantile semiparametric mixed-effects double regression models.
Acknowledgements
The authors greatly appreciate the two reviewers for their thoughtful comments and suggestions, which have improved the quality of the manuscript. This work was based on the first author's dissertation research which was supervised by the corresponding author. Dr. Wu was supported by the National Natural Science Foundation of China under grant 11861041. Drs. Keying Ye and Min Wang were partially supported by a grant from the UTSA Vice President for Research, Economic Development, and Knowledge Enterprise at the University of Texas at San Antonio.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Duo Zhang
Duo Zhang is a statistician and his research interests include quantile regression, statistical analysis, and applications.
Liucang Wu
Liucang Wu is a professor of Statistics in the Faculty of Science at Kunming University of Science and Technology. His research interests include Bayesian analysis, statistical decision theory, multivariate analysis, and statistical applications.
Keying Ye
Keying Ye is a professor of Statistics in the Department of Management Science and Statistics at the University of Texas at San Antonio. His research interests include Bayesian analysis, statistical inference and decision theory, and statistical applications.
Min Wang
Min Wang is an associate professor of Statistics in the Department of Management Science and Statistics at the University of Texas at San Antonio. His research interests include Bayesian statistics, high dimensional inference, statistical applications, and machine learning.
References
- Aitkin, M. (1987). Modelling variance heterogeneity in normal regression using GLIM. Applied Statistics, 36(2), 332–339. https://doi.org/https://doi.org/10.2307/2347792
- Alhamzawi, R., & Ali, H. (2018). Bayesian quantile regression for ordinal longitudinal data. Journal of Applied Statistics, 45, 815–828. https://doi.org/https://doi.org/10.1080/02664763.2017.1315059
- Cepeda, E., & Gamerman, D. (2000). Bayesian modeling of variance heterogeneity in normal regression models. Brazilian Journal of Probability and Statistics, 14, 207–221. https://doi.org/https://doi.org/10.2307/43600978
- Chen, X., & Tang, N. (2010). Bayesian analysis of semiparametric reproductive dispersion mixed-effects models. Computational Statistics & Data Analysis, 54, 2145–2158. https://doi.org/https://doi.org/10.1016/j.csda.2010.03.022
- Chen, Y., & Ye, K. (2009). Bayesian hierarchical modelling on dual response surfaces in partially replicated designs. Quality Technology & Quantitative Management, 6, 371–389. https://doi.org/https://doi.org/10.1080/16843703.2009.11673205
- Chen, Y., & Ye, K. (2011). A Bayesian hierarchical approach to dual response surface modelling. Journal of Applied Statistics, 38, 1963–1975. https://doi.org/https://doi.org/10.1080/02664763.2010.545106
- Chib, S., & Greenberg, E. (1994). Bayes inference in regression models with ARMA (p,q) errors. Journal of Econometrics, 64, 183–206. https://doi.org/https://doi.org/10.1016/0304-4076(94)90063-9
- Fan, J., & Gijbels, I. (1996). Local polynomial modelling and its applications. In Monographs on statistics and applied probability, vol. 66. Chapman & Hall.
- Fan, J., & Li, R. (2004). New estimation and model selection procedures for semiparametric modeling in longitudinal data analysis. Journal of the American Statistical Association, 99, 710–723. https://doi.org/https://doi.org/10.1198/016214504000001060
- Fonseca, T., Ferreira, Marco A., & Migon, H. (2008). Objective Bayesian analysis for the student-t regression model. Biometrika, 95, 325–333. https://doi.org/https://doi.org/10.1093/biomet/asn001
- Gelman, A. R., & Gilks, W. (1996). Efficient metropolis jumping rules. In Bayesian statistics, 5 (Alicante, 1994), (pp. 599–607). Oxford Sci. Publ. Oxford University Press.
- Geraci, M. (2019). Additive quantile regression for clustered data with an application to children's physical activity. Journal of the Royal Statistical Society. Series C, Applied Statistics, 68, 1071–1089. https://doi.org/https://doi.org/10.1111/rssc.2019.68.issue-4
- Geraci, M., & Bottai, M. (2014). Linear quantile mixed models. Statistics and Computing, 24, 461–479. https://doi.org/https://doi.org/10.1007/s11222-013-9381-9
- Geweke, J. (1992). Evaluating the accuracy of sampling-based approaches to the calculation of posterior moments. In Bayesian statistics, 4 (Peñíscola, 1991) (pp. 169–193). Oxford University Press.
- He, X., Fung, W. K., & Zhu, Z. (2005). Robust estimation in generalized partial linear models for clustered data. Journal of the American Statistical Association, 100, 1176–1184. https://doi.org/https://doi.org/10.1198/016214505000000277
- Hunter, D., & Lange, K. (2000). Quantile regression via an MM algorithm. Journal of Computational and Graphical Statistics, 9, 60–77. https://doi.org/https://doi.org/10.2307/1390613
- Kai, B., Li, R., & Zou, H. (2011). New efficient estimation and variable selection methods for semiparametric varying-coefficient partially linear models. The Annals of Statistics, 39, 305–332. https://doi.org/https://doi.org/10.1214/10-AOS842
- Kang, S., Liu, G., Qi, H., & Wang, M. (2018). Bayesian variance changepoint detection in linear models with symmetric heavy-tailed errors. Computational Economics, 52, 459–477. https://doi.org/https://doi.org/10.1007/s10614-017-9690-8
- Koenker, R., & Bassett, Jr. G. (1978). Regression quantiles. Econometrica, 46, 33–50. https://doi.org/https://doi.org/10.2307/1913643
- Koenker, R., Chernozhukov, V., He, X., & Peng, L. (2018). Handbook of quantile regression. In Chapman & Hall/CRC handbooks of modern statistical methods. CRC Press.
- Koenker, R., & Park, B. (1996). An interior point algorithm for nonlinear quantile regression. Journal of Econometrics, 71, 265–283. https://doi.org/https://doi.org/10.1016/0304-4076(96)84507-6
- Kotz, S., Kozubowski, T. J., & Podgórski, K. (2001). The laplace distribution and generalizations: A revisit with applications to communications, economics, engineering, and finance. Birkhäuser Boston, Inc.
- Kozumi, H., & Kobayashi, G. (2011). Gibbs sampling methods for Bayesian quantile regression. Journal of Statistical Computation and Simulation, 81, 1565–1578. https://doi.org/https://doi.org/10.1080/00949655.2010.496117
- Lombardia, M. J., & Sperlich, S. (2007). Semiparametric inference in generalized mixed effects models. Journal of the Royal Statistical Society. Series B. Statistical Methodology, 70, 913–930. https://doi.org/https://doi.org/10.1111/j.1467-9868.2008.00655.x
- Raftery, A., & Lewis, S. (1992). [Practical Markov Chain Monte Carlo]: comment: one long run with diagnostics: implementation strategies for Markov Chain Monte Carlo. Statistical Science, 7, 493–497. https://doi.org/https://doi.org/10.1214/ss/1177011143
- Scheike, T. H., & Zhang, M. -J. (2011). Analyzing competing risk data using the R timereg package. Journal of Statistical Software, 38, 1–15. https://doi.org/https://doi.org/10.18637/jss.v038.i02
- Tang, N., & Duan, X. (2012). A semiparametric Bayesian approach to generalized partial linear mixed models for longitudinal data. Computational Statistics & Data Analysis, 56, 4348–4365. https://doi.org/https://doi.org/10.1016/j.csda.2012.03.018
- Tian, Y., Li, E., & Tian, M. (2016). Bayesian joint quantile regression for mixed effects models with censoring and errors in covariates. Computational Statistics, 31, 1031–1057. https://doi.org/https://doi.org/10.1007/s00180-016-0659-1
- Tian, Y., & Song, X. (2020). Bayesian bridge-randomized penalized quantile regression. Computational Statistics & Data Analysis, 144, 106876, 16. https://doi.org/https://doi.org/10.1016/j.csda.2019.106876
- Tian, Y., Tian, M., & Zhu, Q. (2014). Linear quantile regression based on EM algorithm. Communication in Statistics – Theory and Methods, 43, 3464–3484. https://doi.org/https://doi.org/10.1080/03610926.2013.766339
- Waldmann, E., Kneib, T., Yue, Y. R., Lang, S., & Flexeder, C. (2013). Bayesian semiparametric additive quantile regression. Statistical Modelling, 13, 223–252. https://doi.org/https://doi.org/10.1177/1471082X13480650
- Wu, L., Tian, G.-L., Zhang, Y.-Q., & Ma, T. (2017). Variable selection in joint location, scale and skewness models with a skew-t-normal distribution. Statistics and Its Interface, 10, 217–227. https://doi.org/https://doi.org/10.4310/SII.2017.v10.n2.a6
- Xu, D., Zhang, Z., & Wu, L. (2016). Bayesian analysis for semiparametric mixed-effects double regression models. Hacettepe Journal of Mathematics and Statistics, 41, 279–296.
- Yang, Y., Wang, H. J., & He, X. (2016). Posterior inference in Bayesian quantile regression with asymmetric Laplace likelihood. International Statistical Review, 84, 327–344. https://doi.org/https://doi.org/10.1111/insr.12114
- Yu, K., & Moyeed, R. A. (2001). Bayesian quantile regression. Statistics & Probability Letters, 54, 437–447. https://doi.org/https://doi.org/10.1016/S0167-7152(01)00124-9
- Zhang, H., Huang, Y., Wang, W., Chen, H., & Langland-Orban, B. (2019). Bayesian quantile regression-based partially linear mixed-effects joint models for longitudinal data with multiple features. Statistical Methods in Medical Research, 28, 569–588. https://doi.org/https://doi.org/10.1177/0962280217730852
- Zhao, P., & Xue, L. (2010). Variable selection for semiparametric varying coefficient partially linear errors-in-variables models. Journal of Multivariate Analysis, 101, 1872–1883. https://doi.org/https://doi.org/10.1016/j.jmva.2010.03.005
- Zhao, P., & Xue, L. (2011). Variable selection for semiparametric varying-coefficient partially linear models with missing response at random. Acta Mathematica Sinica, English Series, 27, 2205–2216. https://doi.org/https://doi.org/10.1007/s10114-011-9200-1
Appendix
The Metropolis–Hastings algorithm for sampling in Algorithm 1 is summarized as follows. We choose the commonly used multivariate normal distribution as the proposal distribution (Chib & Greenberg, Citation1994), denoted by
with
where
is the Hessian matrix and
is chosen such that the average acceptance rate is between 0.25 and 0.45 (Gelman & Gilks, Citation1996). For the
th iteration, we sample
by the following two steps:
Generate a new candidate
Let