
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Extreme value theory provides essential mathematical foundations for modelling tail risks and has wide applications. The emerging of big and heterogeneous data calls for the development of new extreme value theory and methods. For studying high-dimensional extremes and extreme clusters in time series, an important problem is how to measure and test for tail dependence between random variables. Section 3.1 of Dr. Zhang's paper discusses some newly proposed tail dependence measures. In the era of big data, a timely and challenging question is how to study data from heterogeneous populations, e.g. from different sources. Section 3.2 reviews some new developments of extreme value theory for maxima of maxima. The theory and methods in Sections 3.1 and 2.3 set the foundations for modelling extremes of multivariate and heterogeneous data, and we believe they have wide applicability. We will discuss two possible directions: (1) measuring and testing of partial tail dependence; (2) application of the extreme value theory for maxima of maxima in high-dimensional inference.
1. Partial tail dependence
Identifying the tail dependence between random variables can be helpful for determining appropriate multivariate extreme value distributions. Section 3.1 of Dr. Zhang's article reviews a series of work on tail dependence. Particularly, a test for tail independence based on the tail quotient correlation coefficient (TQCC) was introduced. The TQCC measurement has nice properties, including the simple interpretation and computation, and it has been successfully applied to financial risk studies, precipitation extremes, and so on. The method and theory are based on the assumption that is a random sample of
, and the aim is to study the tail dependence between X and Y. However, in some applications, both X and Y may depend on some other covariates Z. For example, Wang et al. (Citation2012) showed that in the study of downscaling of precipitation, the coarser-resolution predictor variables generated from a global climate model can be used to predict the local extreme precipitations. For joint modelling and prediction of precipitation with other meteorological variables such as temperature, it will be important to assess the conditional tail dependence of these variables given Z, the global climate model outputs.
For any two random variables X and Y, which may not be identically distributed, the (upper) tail dependence index is defined as
where
and
are the τth quantiles of Y and X, respectively. Dr. Zhang and his collaborators proposed the TQCC for measuring and testing the tail dependence. Suppose that there exist confounding variables Z which are likely to be related with X and Y, using the TQCC may lead to misleading conclusions. To account for the confounding factors, we can define the following partial tail dependence index
where
and
are the τth conditional quantiles of Y and X given Z, respectively. We conjecture that the index
can capture the tail dependence between X and Y after accounting for the effect of Z. It would be interesting to study the interpretation and properties of
, together with its connections and distinctions from λ.
Suppose that we are interested in testing against the alternative hypothesis
. There are two possible ways to extend the TQCC-based method in Zhang et al. (Citation2017) to test for the partial tail independence. Such tests can also be useful for the selection of orders in autoregressive models; see the discussion of quantile partial correlation in Li et al. (Citation2015) for some related applications.
The first approach is a plug-in method. The idea is to remove the effects of Z on Y and X separately, and then assess the dependence of the estimated residuals. This approach will require specific forms for the two regression models. For instance, we may consider the following location-scale shift linear regression models,
(1)
(1) where
are random errors,
are the unknown location and scale parameters, and
, j = 1, 2. Given a random sample of
, we can estimate the parameters
by
using existing regression methods, for instance, the method in He (Citation1997). Denote
and
. We can then define the partial tail quotient correlation coefficient as
where
is varying thresholds that tend to infinity. Under the model assumptions in (Equation1
(1)
(1) ), it can be shown that the partial tail dependence
is the same as the tail dependence index between
and
. One limitation of this approach is that it relies on the location-scale shift model assumption and thus may be susceptible to model misspecifications, though we can increase the flexibility by modelling the location and scale functions nonparametrically; see for instance (He, Citation1997; Keilegom & Wang, Citation2010; Pang et al., Citation2015).
The second approach is a quantile-regression-based method, which requires modelling the tail conditional quantiles of X and Y given Z. Let and
be the estimated conditional τth quantile of X and Y given Z, respectively, which can be obtained from either parametric (Wang et al., Citation2012) or semiparametric quantile regression (Xu et al., Citation2020). Then we can define a second version of the partial tail quotient correlation coefficient as
where
,
, and
as
Similar to TQCC, the partial TQCC and
can be used to test whether X and Y are tail independent after adjusting for the effect of Z. Theorem 4 in Zhang et al. (Citation2017) establishes the limiting distribution of TQCC under
. The measurement
assumes the location-scale shift models. If the location and scale functions are estimated consistently with a certain rate, we conjecture that
has the similar asymptotic properties as
in Zhang et al. (Citation2017), so inference can be conducted by using the asymptotic
distribution. The asymptotic properties of
would require more careful investigation.
We conduct a small simulation study by generating data from the following model:
where
,
and
are independent standard Fréchet random variables, and
. We let n = 1000 and consider two cases: the homoscedastic case with
and heteroscedastic case with
. The simulation is repeated 1000 times for each scenario. For
, we take
as the maximum of the 95th percentiles of the estimated residuals
and
. For
, we let
. Figure plots the empirical density of
obtained under the null model with
and the density of
. Results show that, as in Theorem 3.8 of Dr. Zhang's paper for
,
provides a good approximation to the normalised
under
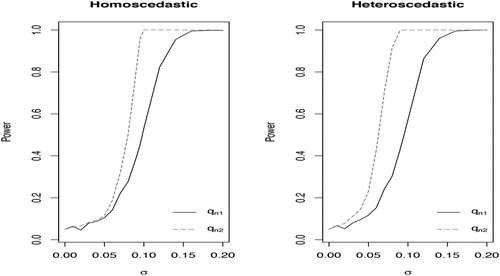
. Figure plots the power curves of tests based on
and
using the Monte Carlo critical values against σ. The power of both tests increases gradually with σ, while
exhibits higher power than
for detecting the partial tail dependence. It would be interesting to further study the theoretical and empirical properties of
.
Figure 1. The empirical density of under
and the density of
.
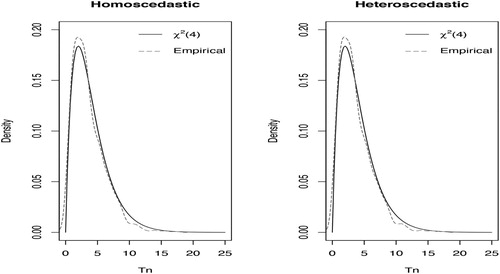
Figure 2. Power of tests based on and
for testing the partial tail independence between X and Y given Z.
2. Maxima of maxima for high-dimensional inference
In Section 3.2, Dr. Zhang introduces some newly developed extreme value theory for the maxima of k maxima, from either different variables or subsequences of the same variable. Denote ,
and
. Section 3.2 reviews some new results for the limiting distribution of
. We believe such results would be very useful for high-dimensional inference with multivariate responses.
Maximum-type statistics and extreme value theory have been used in many high-dimensional inference problems. Some examples include testing for high-dimensional mean differences (Cai et al., Citation2014; Xu et al., Citation2016), inference on high-dimensional correlation matrix (Jiang, Citation2004; Xiao & Wu, Citation2013), testing and identification of significant predictors (Tang & Pan, Citation2020), just to name a few. In these works, the test statistics are defined as the maximum of a high-dimensional independent or dependent random variables, e.g., the sample correlations (Jiang, Citation2004) or the normalised squared differences of sample covariances of p variables from two populations (Cai et al., Citation2013), the squared sample mean differences of p variables from two populations (Cai et al., Citation2014), or the squared score statistics capturing the impacts of p predictors on the response variable (Tang & Pan, Citation2020; Wu et al., Citation2019), where p is often larger than the sample size n. The hypothesis testing is then conducted by using the limiting distribution of the maximum-type statistic, that is, the Type I extreme value distribution. One typical application is in genome-wide association studies, where one main interest is in comparing the means or covariances of a large number of single nucleotide polymorphisms (SNPs) between treatment and control, or detecting possible associations between a phenotype or disease and gene pathways.
In some applications, the researcher may be interested in assessing the association between p SNPs and multiple diseases or phenotypes jointly. The new extreme value theory of maxima of maxima in Dr. Zhang's work could be helpful to develop valid testing procedures for such applications. For simplicity, we will use k = 2 to illustrate the possible application in this context. Let denote the squared normalised score test statistic measuring the effect of the jth SNP on the lth phenotype, where
and l = 1, 2. Under some regularity conditions, it can often be shown that
are asymptotically normal variables that are likely to be correlated. Suppose that we want to test the null hypothesis
: none of the SNPs from a gene pathway is associated with the two phenotypes against the alternative
: there exists at least one SNP that has an association with either or both phenotypes. One natural test statistic is
and we would reject
with large
. Theorem 3.11 in Dr. Zhang's work can help determine the critical value or calculate the p-value. Let
and
be the cumulative distributions of
and
for
. In this context,
and
are approximately
distribution under
. Let
and
be the observed values of
and
. Define
. Then based on Theorem 3.11, we can approximate the p-value with
(2)
(2) where
and
.
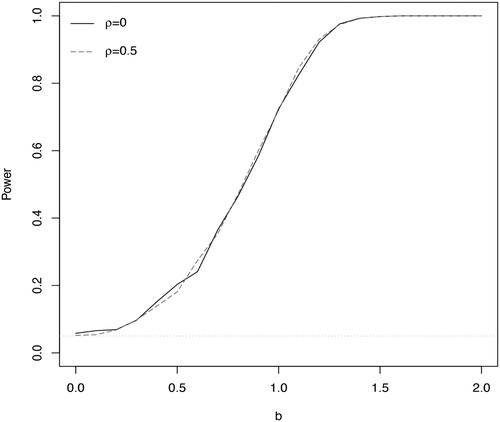
We conduct a small simulation study to try out this idea. We generate and
from the bivariate normal distribution with means b, unit variance and correlation ρ, where
Figure shows the power curves of this test against b for
and 0.5. The simulation results suggest the test based on the extreme value theory for maxima of maxima performs well: the type I error is controlled around the nominal level of 0.05, and the power increases gradually with the signal b. However, as mentioned above, in the GWAS applications,
are often correlated across l and
, so further research is needed to provide rigorous justification for applying the maxima of maxima theory to the multivariate high dimensional inference problems.
Figure 3. Power curve of the test based on the maxima of maxima theory for high-dimensional inference with two phenotype. The parameter ρ corresponds to the correlation used in the simulation. The x-axis represents the deviation from the null hypothesis. The horizontal line dotted corresponds to the 0.05 nominal level.
Acknowledgments
We congratulate Dr. Zhang for a stimulating and interesting article on the important topics of extreme values with nonlinear time series models and tail dependence measures and thank Professor Jun Shao for giving us the opportunity to discuss this work.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Wen Xu
Wen Xu is a Phd candidate of Fudan University.
Huixia Judy Wang
Huixia Judy Wang is a Professor of The George Washington University.
References
- Cai, T. T., Liu, W., & Xia, Y. (2013). Two-sample covariance matrix testing and support recovery in high-dimensional and sparse settings. Journal of the American Statistical Association, 108, 265–277. https://doi.org/10.1080/01621459.2012.758041
- Cai, T. T., Liu, W., & Xia, Y. (2014). Two-sample test of high dimensional means under dependence. Journal of the Royal Statistical Society, Series B, 76, 349–372. https://doi.org/10.1111/rssb.2014.76.issue-2
- He, X. (1997). Quantile curves without crossing. The American Statistician, 51(2), 186–192. https://doi.org/10.1080/00031305.1997.10473959
- Jiang, T. (2004). The asymptotic distributions of the largest entries of sample correlation matrices. The Annals of Applied Probability, 14(2), 865–880. https://doi.org/10.1214/105051604000000143
- Keilegom, I. V., & Wang, L. (2010). Semiparametric modeling and estimation of heteroscedasticity in regression analysis of cross-sectional data. Electronic Journal of Statistics, 4, 186–192. https://doi.org/10.1214/09-EJS547
- Li, G., Li, Y., & Tsai, C. (2015). Quantile correlations and quantile autoregressive modeling. Journal of the American Statistical Association, 110(509), 246–261. https://doi.org/10.1080/01621459.2014.892007
- Pang, L., Lu, W., & Wang, H. (2015). Local Buckley-James estimator for the heteroscedastic accelerated failure time model. Statistica Sinica, 25, 863–877. https://doi.org/10.5705/ss.2013.313
- Tang, Y., & Pan, Q. (2020). Conditional marginal test for high dimensional quantile regression. Statistica Sinica. to appear.
- Wang, H., Li, D., & He, X. (2012). Estimation of high conditional quantiles for heavy-tailed distributions. Journal of the American Statistical Association, 107, 1453–1464. https://doi.org/10.1080/01621459.2012.716382
- Wu, C., Xu, G., & Pan, W. (2019). An adaptive test on high-dimensional parameters in generalized linear models. Statistica Sinica, 28, 1226–1255. https://doi.org/10.5705/ss.202017.0354
- Xiao, H., & Wu, W. (2013). Asymptotic theory for maximum deviations of sample covariance matrix estimates. Stoch Process and Their Applications, 123(7), 2899–2920. https://doi.org/10.1016/j.spa.2013.03.012
- Xu, W., Li, D., & Wang, H. (2020). Extreme quantile estimation based on the tail single-index model. Statistica Sinica. https://doi.org/10.5705/ss.202020.0051
- Xu, G., Lin, L., Wei, P., & Pan, W. (2016). An adaptive two-sample test for high-dimensional means. Biometrika, 103(3), 609–624. https://doi.org/10.1093/biomet/asw029
- Zhang, Z., Zhang, C., & Cui, Q. (2017). Random threshold driven tail dependence measures with application to precipitation data analysis. Statistica Sinica, 27(2), 421–453. https://doi.rog/10.5705/ss.202014.0421