
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
For stochastic loss reserving, we propose an individual information model (IIM) which accommodates not only individual/micro data consisting of incurring times, reporting developments, settlement developments as well as payments of individual claims but also heterogeneity among policies. We give over-dispersed Poisson assumption about the moments of reporting developments and payments of every individual claims. Model estimation is conducted under quasi-likelihood theory. Analytic expressions are derived for the expectation and variance of outstanding liabilities, given historical observations. We utilise conditional mean square error of prediction (MSEP) to measure the accuracy of loss reserving and also theoretically prove that when risk portfolio size is large enough, IIM shows a higher prediction accuracy than individual/micro data model (IDM) in predicting the outstanding liabilities, if the heterogeneity indeed influences claims developments and otherwise IIM is asymptotically equivalent to IDM. Some simulations are conducted to investigate the conditional MSEPs for IIM and IDM. A real data analysis is performed basing on real observations in health insurance.
1. Introduction
In the background of stochastic reserving, loss reserving is referred to a procedure to predict incurred outstanding liabilities in general insurance companies. It is well known that chain-ladder method proposed by Mack (Citation1993) and its related versions can be easily performed by using pencil and paper because of the simple aggregate data structure called run-off triangle and hence are popular in practice. However, as England and Verrall (Citation2002) mentioned, the advantages of aggregate data models are at the cost of prediction accuracy because of information loss caused by simply aggregating individual or micro data, which records incurring time, reporting time, settlement time as well as payment processes of individual claims. In risk management of insurance companies, with the modern computer technology, it is urgent for actuaries to explore the usage of related information to improve the accuracy in predicting the liabilities, which also attracts increasing interests of many scholars from actuarial science. Antonio and Plat (Citation2014), Pigeon et al. (Citation2013, Citation2014) demonstrated by an empirical analysis that loss reserving based on individual data had more prediction accuracy than aggregate models. Huang, Qiu, Wu, Zhou (Citation2015), Huang, Qiu, Wu (Citation2015) and Huang et al. (Citation2016) revealed that individual loss reserving had more accuracy than methods using aggregate data in sense that the former produced a smaller mean square error.
A small stream of earlier literature about IDMs, for example, Arjas (Citation1989) and Norberg (Citation1993, Citation1999) formulated a probabilistic framework for the developments of individual claims. Most recently, Yu and He (Citation2016) modelled the individual claim development process by marked Cox processes (also known as double stochastic processes). As we all know, it is challenging to acquire analytic expressions for the moments of outstanding liabilities under continuous-time IDMs. Perhaps partly for this reason, there is a great deal of work that has been done under discrete-time IDMs, see, e.g., Pigeon et al. (Citation2013, Citation2014), Verrall et al. (Citation2010), Huang, Qiu, Wu, Zhou (Citation2015), Huang, Qiu, Wu (Citation2015) and Huang et al. (Citation2016). Zhao and Zhou (Citation2010) considered the R-delays so as to predict the incurred but not settled outstanding liabilities. Unfortunately, IDMs also confront information loss caused by neglecting individual information, i.e., information from policy or policyholder. It is not clear so far how much accuracy in predicting the outstanding liabilities is sacrificed, when the individual information is neglected. In the present paper, we will explore how much improvement in the accuracy that will be measured by conditional MSEP can be achieved by incorporating the useful individual information into modelling under discrete time framework similar as Huang, Qiu, Wu, Zhou (Citation2015), Huang, Qiu, Wu (Citation2015) and Huang et al. (Citation2016). Besides, we avoid the strong Poisson distribution assumption for the number of individual claims assumed in Huang, Qiu, Wu, Zhou (Citation2015), Huang, Qiu, Wu (Citation2015) and Huang et al. (Citation2016) and instead extend to weak assumptions about the first two moments so that parameters estimation can be conducted under quasi-likelihood theory (cf. McCullagh & Nelder, Citation1989).
The conditional MSEP is broadly used to compare different models for loss reserving. It is well known that the conditional MSEP is the sum of process variance caused by the randomness of outstanding liabilities and estimation error originating from uncertainty of parameters estimators. It is theoretically feasible to estimate it by bootstrap method. There were some examples which discussed the MSEP under collective models – for instance, Mack (Citation1993), Mack (Citation2000) (comparing three methods – Benktander, Bornhuetter–Ferguson and chain-ladder under the criteria of MSEP), Alai et al. (Citation2009, Citation2010) (Bornhuetter–Ferguson method under generalised linear model) and Wüthrich and Merz (Citation2008) (comprehensive summary of the details of methods based on aggregate data). Besides, Lindholm et al. (Citation2020) introduced a semi-analytic approximation method to estimate the conditional MSEP, where the method is illustrated by loss reserving based on aggregate data. Examples that have applied the approximation method are Wahl (Citation2019), who computed explicit moments of outstanding liabilities by applying discretisation scheme under the framework of Antonio and Plat (Citation2014), and Wahl et al. (Citation2019) who modelled individual data on aggregate level. In the present paper, we also use the approximation method for the MSEP, which is derived under IIM, because of its simplification.
The paper is organised as follows. In Section 2, we describe the data structure and display the mathematical expression of outstanding liabilities caused by a risk portfolio at a given evaluation date. In Section 3, we separately model reporting developments, settlement delays and payments of claims and in each part, we formulate the model assumptions as well as estimation for the model parameters. Section 4 mainly derives the formulas of loss reserve and conditional variance of outstanding liabilities given historical observations, and studies the improvement of accuracy achieved by IIM with respect to IDM. Section 5 reports some simulation results and a real data analysis. Section 6 concludes the paper with a few remarks.
2. Data structure
Claim events incurred by some policy are usually reported to the insurer in some time periods (reporting delays) after their occurrence and the reported claims are finally settled with some time lags (settlement delays) between their reports and final settlements. Before going further, it is necessary to discuss the supports of reporting and settlement delays. In the following assumption, we assume that there exists maximum reporting delay and settlement delay
. Actually, there are basically two cases for the supports of the delays: finite and infinite. It would be a known priori (generally read from the items of the insurance contracts) if the supports are finite or infinite before any loss reserving is taken care of. Even for the case the delays take unrestricted values, if the probability to take values over certain limits is quite small, one can safely assume a capped delays by cutting off the tails with probability small enough. As a result, the assumption of capped delays is reasonable in many real insurance businesses, especially for such insurance without very much high claims payments. An example is the general health insurance. The assumption of capped delays has been extensively adopted in such traditional methods as chain-ladder algorithm. If the tails cannot be safely cut off, however, the models such as the one proposed in Crevecoeur et al. (Citation2019) or some others would be more suitable. From the statistical point of view, for their distributions to be reasonably estimated with observations over a finite number of years, at least one of the two assumptions is necessary: they take only a finite number of values with arbitrary probabilities (but subject to normalisation) or countably infinitely many values but with their distribution functions identified by finite many parameters. Whatever the case, the number of unknown parameters that need to be estimated must be finite. Here the former is taken, whereas Crevecoeur et al. (Citation2019), for example, took the latter.
Then we specify the data structure used in our model. It is in discrete time version as, e.g., Huang, Qiu, Wu (Citation2015) did. Typically, the data for modelling is organised through periods with fixed length such as 1 year, one season or 1 month depending on lines of business. Conventionally, those periods are referred to ‘(accident) years’. This is also a way widely adopted by insurers to predict the incurred outstanding liabilities in practice. Specifically, the whole observation horizon is made of n accident years and loss reserving is evaluated at the end of nth accident year. In year i, , there are
insurance policies, each of which is coded by
,
.
Every individual is associated with a random risk exposure
and d-dimensional vector of covariate
whose first entry is 1 and other entries indicating the individual information/features that influence the developments of individual claims. The developments of claims incurred by individual
are detailed as follows.
The reporting developments of claims are recorded by
,
For
Payments for each claim are assumed to be paid for only once at its final settlement. For
Then the random element associated with individual is denoted by
, which are i.i.d. from the population
which can be considered as a complete observation of a representative policy in year i.
Following conventional terms, a claim, which has been reported to the insurer but not settled, is known as RBNS claim and a claim, which has been incurred but not reported to the insurer, is known as IBNR claim. For accident year i, the individual observed data is as follows.
The reporting developments of a representative policy in year i are truncated in sense that we can only observe
For
For
Then individual observation is the union of
,
,
and
, that is
and the historical observations of all policies in the portfolio, denoted by
, is just the union of policy-specified observation that is
, where
is the policy-specified realisations of
in year i that is
It is well known that RBNS and IBNR claims of the risk portfolio naturally result in outstanding liabilities to the insurer. Specifically, the total of future payments for all the RBNS and IBNR claims can be represented as
(3)
(3) where
are RBNS and IBNR liabilities incurred in year i, respectively. Thoroughly, we take the convention
if
.
3. Model specification
This section separately specifies the models for the reporting developments, settlement developments and payments of claims. In each part, we first give model assumptions and then detail the parameter estimations under both IIM and IDM. The model assumptions in this section are all given under the condition that risk exposure r and covariates are known.
3.1. Modelling reporting developments of claims
Model assumption for reporting developments of claims is given as follows. It is mainly about the first and second moments of reporting developments of claims. The assumption involves vectors of parameters , which are all d-dimensional vector.
Assumption 3.1
For an individual with assume that
are independent,
and
where
with
and
,
as well as
.
Remark 3.1
In order to make be reasonably estimated, the condition
is necessary.
By independence among policies and assumption above, one can construct the quasi-likelihood function of reported claims as follows,
(4)
(4) where
is policy-specified quantities of
that is
One can refer to McCullagh and Nelder (Citation1989) for more details about quasi-likelihood theory. Similar to maximum likelihood estimation, parameters
can be estimated by maximising
with respect to the parameters. Denote by
and stack
s as a vector
such that entry
is corresponding to
in vector
. The quasi-score function, i.e., partial derivatives of
with respect to the parameters is
(5)
(5) where
. To determine the block entries of
, one needs the unit vector
with 1 at component s (any positive integer) and
, of which dimensions can be read from context, and the following partial derivatives
where
and ⊗ is the Kronecker product.
The covariance matrix of , which is also the negative expected value of
, is
(6)
(6) The parameters
are estimated by Newton–Raphson with Fisher scoring starting with initials
and updating estimated parameters in the following way:
where
and
are obtained by replacing
with
. Write the estimated parameters as
. To estimate dispersion parameter ϕ, we adopt conventional method–moment estimation that is,
where
s are plug-in estimates of
that is
IDM considers that policy's feature information has no effect on reporting developments that is the coefficients of
are thought to be zero. Obviously, IDM is a misspecified model if the feature information indeed influence those developments. Therefore, in IDM, λ and
are thought to keep fixed among all policies and then
is same for the policies. By maximising function
in (Equation4
(4)
(4) ) with respect to
, one can obtain that
(7)
(7) where
representing total number of reported claims with reporting delay u and
meaning total exposures in the first n−u years.
3.2. Modelling settlement delays
In IIM, the settlement developments of individual claims after their reporting to the insurer have the following assumption. The assumption involves vectors of parameters , which are all d-dimensional vector.
Assumption 3.2
Assume that given
follows multinomial distribution with parameters
and
where
with
, as well as
and the tuples
are independent.
Remark 3.2
Similar to the condition in Remark 3.1, the condition is necessary to make
be reasonably estimated. Therefore, it is enough to assume
.
For (
) reported claims of representative policy in year i, one can only observe
and
(the number of RBNS claims with settlement delays no less than n−i−u), where
if
. According to the assumption above, the individual log-likelihood of settlement developments is
(8)
(8) where
is the tail probability of settlement delays no less than v. Obviously, an alternative form of term in the last term in the first line of (Equation8
(8)
(8) ) is
. Further, if we write
, which means number of settled claims with settlement delay v, (Equation8
(8)
(8) ) becomes
(9)
(9) To estimate
by Newton–Raphson with Fisher scoring, we need the identities in the following proposition.
Proposition 3.1
The gradient of with respect to
is
and conditional expectation of Hessian matrix of
given
is
(10)
(10) where
and
We estimate by maximising overall log-likelihood function
which is the summation of individual log-likelihood
, that is
is obtained as follows:
where
To obtain
, similar as previous section, we use Newton–Raphson with Fisher scoring which needs the following gradients
and its covariance matrix
, where
(11)
(11)
In IDM, similar as in the section above, probabilities
are thought to keep fixed among all policies that is
is independent of
. By MLE again, we have
(12)
(12) where
with
3.3. Modelling claim payments
We give some assumptions about payments of individual claims as follows. The assumptions involve a -dimensional vector of parameters
.
Assumption 3.3
Claim payments
are independent, independent of
and also assume that conditional mean and variance satisfy
with
where
is a
-dimensional vector of covariates.
Arrange all settled payments of the risk portfolio into the set , where
is covariate associated with payments
and
is the total number of settled claims. Construct quasi-likelihood by independence among policies and assumption above,
(13)
(13) where
. Denote
and
. The quasi-score function–partial derivatives of
with respect to the parameters is
(14)
(14) where
.
The covariance matrix of , which is also the negative expected value of
, is
(15)
(15) The parameters
are estimated by iteratively re-weighted least square (IRLS) algorithm, which is as follows,
Initialise
Compute adjusted response
Update
To estimate dispersion parameter , we also adopt conventional method–moment estimation that is,
where
.
In IDM, the coefficients of covariates about individual features are considered to be zero, i.e., , and
s only depended on reporting and settlement delays, which means it just needs to estimate
by the similar procedure as stated above. Therefore, estimator
for
is a maximiser of the
, which is the function of
that is under
, and
in Equation (Equation13
(13)
(13) ) is independent of individual information and only takes one of the following forms:
(16)
(16) Then the estimate of
under IDM is denoted by
, which is a policy-free estimate.
4. Prediction for outstanding liabilities
In this section, the terminologies ‘loss reserve’ and ‘loss reserving’ are precisely specified, measurement of accuracy of loss reserving is then discussed and we also shows the improvement of accuracy of loss reserving basing on IIM with respect to IDM.
4.1. Loss reserve and loss reserving
Recalling the total outstanding liability R defined in (Equation3(3)
(3) ), by ‘loss reserve’, we refer to the projection
(17)
(17) of R on the observations
by the evaluation date n, where the subscript ‘
’ indicates portfolio size, since loss reserve is based on specific risk portfolio. One can see that
is a function of unknown parameters
and hence it needs to be estimated.
To derive moments about outstanding liabilities R and conditional variance of R, the following quantities are needed. For , denote by
(18)
(18) where
is conditional moment of claim payments given
, reporting delays u and settlement delays no less than v, so that corresponding policy-specified quantities are
(19)
(19) Then we derive the following theorem which provides formulas to compute not only the loss reserve
but also variance of outstanding liabilities R given observations
.
Theorem 4.1
Under the model formulated by Assumptions 3.1–3.3, the loss reserve is (20)
(20) and the variance of R given observations
is
It can be clearly seen that loss reserve depends on not only the information from observed data in terms of the number of RBNS claims and policy's feature information but also unknown parameters
, which results in the need for estimating
. Accordingly, the term ‘loss/claims reserving’ is used for certain reasonable estimate of the loss reserve. Formally, after getting certain reasonable estimates
of the unknown parameters from the observed data, as, for example, what has been done in the previous section, we have the following theorem.
Theorem 4.2
By loss reserving we refer to the (random) quantity (21)
(21) where
s and
s are obtained by substituting unknown parameters with their estimates.
According to the theorem above, it is easy to obtain loss reserving under IDM by simply replacing s and
s in (Equation21
(21)
(21) ) with policy-free estimates
s and
s, respectively. Specifically, to distinguish two different estimates for reserve, we use symbol
to indicate loss reserving under IDM, which is
(22)
(22) where
,
and
4.2. Measurement of prediction accuracy
It is essential to measure accuracy of loss reserving and especially accuracy improvement of loss reserving by considering useful individual information with respect to the one without this information. To measure the prediction accuracy of some reserve estimate , which is
measurable, a natural idea is conditional mean square error of prediction (MSEP) which is defined as
(23)
(23) For loss reserving
, which includes individual information, and
without individual information, their MSEPs are
and
, respectively. To measure the difference in prediction accuracy of
and
, we use the following ratio:
(24)
(24) It is well known that individual information model performs better in terms of prediction accuracy than individual data model, if
, but it is hard to compute
with unknown parameters. Fortunately, we can compare
and number 1 when portfolio size m is large enough. It is notable that individual data model is nested in individual information model. Then we have the following theorem under some regular conditions (see Van der Vaart, Citation2000), which illustrates the advantages of individual information model over individual data model.
Theorem 4.3
When portfolio size m tends to infinity, where
means converging in probability, if the individual data model is true, that is the coefficients of
are zero. Otherwise,
(25)
(25) where
with
(26)
(26) and if the asymptotic bias
.
The theorem above shows that IIM is asymptotically equivalent to IDM, if IDM is true and otherwise the former has higher prediction accuracy than the latter when portfolio size is large enough. One can intuitively understand that as portfolio size tends to infinity, both models can capture all the information included in observations when IDM holds true, since IIM is a generalised version of IDM. However, individual data model fails to capture the effects of policy's feature information and thus leads to greater bias when IIM holds true.
An important issue one concerns is how much prediction accuracy of loss reserving can be improved, if IIM holds true, in a fixed risk portfolio that is one cares about actual value of
under true IIM. However, there are unknown parameters
in
and
. An approximation method that comes to one's mind is substituting estimated parameters
to them, which however needs to further take estimation error of
into account. We directly use the method named semi-analytical approximation for
(One can refer to Lindholm et al. (Citation2020) for more details), which is also discussed in Wahl (Citation2019) under micro data model. Then the approximations for
and
are
(27)
(27) so that
(28)
(28) where
is the gradient of loss reserve
with respect to
computed at
and
is asymptotic covariance of
. It is easily known that
where and
are plug-in estimates and
is obtained by inserting
into
in Equation (Equation11
(11)
(11) ). One can refer to Chapter 9 in McCullagh and Nelder (Citation1989) for more details.
Proposition 4.4
The gradient of with respect to
is
the gradient of
with respect to
is
where
,
and
, and the gradient of
with respect to
is
where
5. Simulations and real data analysis
Reported in this section include the results from a few small simulations conducted to further investigate . A real data in health insurance was also analysed to show the application of IIM and the accuracy improvement by using IIM with respect to IDM in practice.
5.1. Simulation
In this simulation, the risk exposures associated with every individuals were drawn from the uniform distribution on , the covariates were produced by multivariate standard normal distribution and we simulated the random developments of claims for a fixed risk portfolio. In each run, we directly compute
according to Equation (Equation24
(24)
(24) ) so that we can know how much accuracy is improved by using IIM with respect to IDM under the fixed risk portfolio.
Because there are only assumptions about mean and variance for reporting developments and payments of claims, we need additional distributional assumptions to generate them, which arise as follows. First, for individual reporting developments s, we generated them by the additional assumption which says that
follows Poisson distribution with mean
. Second, for individual payments
, similarly, we generated them by assuming that
follows Poisson distribution with mean
. Each run in the simulation was conducted with the setting: n = 5,
,
, a risk portfolio size
i.e., 10, 000 policies in each year, and any combination of parameters which varied according to the setting in the following two examples.
Example 5.1
Dimension d = 3 and the parameters varied in an auxiliary parameter t ranging in by step 0.01 as
Parameters for reporting developments:
Parameters for settlement developments:
Parameters for payments:
Covariates were produced by bivariate standard normal distribution in this example.
Example 5.2
Dimension d = 4 and parameters varied over t ranging in by step 0.01 as
Parameters for reporting developments:
Parameters for settlement developments:
Parameters for payments:
Covariates were produced by ternary standard normal distribution in this example.
In each run, we estimated loss reserve by both IIM and IDM using the simulated data that is we computed by Equation (Equation21
(21)
(21) ) as well as
by (Equation22
(22)
(22) ) and true parameters were used to compute
and
according to Theorem 4.1. Then we computed
by inserting the computed
,
,
and
into Equation (Equation24
(24)
(24) ). At last, we plotted the simulated results in Figure .
Figure 1. The simulated over varying coefficients of covariates. (a) Example 5.1 and (b) Example 5.2.
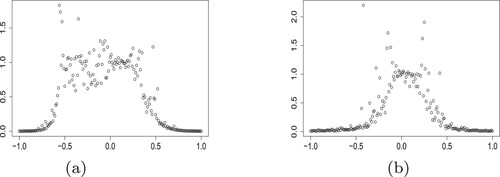
We obtained the results consistent with Theorem 4.3 from the simulations above.
When the coefficients of
When those coefficients are away from zero,
5.2. Real data analysis
In this section, we analysed a dataset, which was collected by a commercial insurance company in China. The dataset recorded writing and expiring dates of policies, individual information, see Table , and developments of reported claims between 1/1/2019 and 8/31/2019.
Table 1. The individual information in real data analysis.
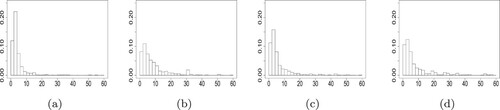
To visualise the effects of individual information on the developments of claims, for example, the histograms of reporting and settlement delays measured in days were provided under a few combinations of covariate values including gender, geographical location and age, as presented in Figures and . It was strongly proposed that the individual information had impacts on the distributions of reporting and settlement delays.In the dataset, all the reporting delays were not more than 150 days (5 months). By China Banking and Insurance Regulatory Commission, the reported claims in health insurance are generally required to be settled within 2 months if no disagreement exists. It is appropriate to take 1 month as the time unit (‘accident year’ in previous sections). Thus the maximum reporting and settlement delays were safely set to and
(the real data supported this assumption).
Figure 2. Histograms of reporting delays (in days): (a) Female, Region III, age 9–20; (b) Male, Region I, age 45–50; (c) Male, Region VI, age 20–40; (d) Male, Region III, age >55.
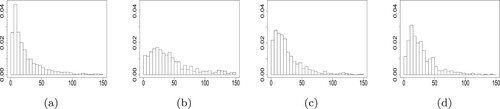
Figure 3. Histograms of settlement delays (in days): (a) Female, Region III, age 9–20; (b) Male, Region I, age 45–50; (c) Male, Region VI, age 20–40; (d) Male, Region III, age >55.
To illustrate the proposed model for loss reserving, evaluation date was set as 8/31/2019. That is, we worked with n = 8, and
(months). There are four factors organised into eight features
, as shown in Table . Besides, reporting and settlement delays, which were regarded as factors to model claim payments as Assumption 3.2 formulated, were respectively organised into five features
,
and three features
.
The estimated parameters for the reporting developments under IIM, their standard errors and p-values of significance test were displayed in Table , while the corresponding estimated results under IDM, i.e., ,
in (Equation7
(7)
(7) ) are
respectively. Besides, the estimated dispersion parameter
. These results in () provide obvious evidence that individual information has effects on the reporting developments of claims in sense that most covariates associated with individual information are significant at significance level 0.05.
Similar results for settlement developments and payments are listed in Tables and . These results also provide obvious evidence that individual information has effects on settlement developments and payments of claims. Besides, the estimated dispersion parameter and the estimates under IDM are
Table 2. Estimated parameters for reporting developments, their standard errors and p-values.
Table 3. Estimated parameters for settlements developments, their standard errors and p-values.
Table 4. Estimated parameters for payments, their standard errors and p-values.
In Table , the columns with names ‘IBNR’, ‘RBNS’ and ‘Loss reserving’ correspond to estimates of IBNR reserve, RBNS reserve and total loss reserve, respectively. The square roots of approximated conditional MSEPs under IIM and IDM are in the fourth column of Table . The rightmost column in this table showed the computed by (Equation28
(28)
(28) ). We can see that loss reserving by IIM provides more stable prediction of outstanding liabilities than that by IDM since the former has smaller conditional MSEP and after incorporating useful individual information into loss reserving, the prediction accuracy is greatly increased by
.
6. Conclusion
This paper explored the improvement of accuracy in predicting outstanding liabilities, which are incurred by general insurance companies, by incorporating useful individual information into modelling. The reporting developments and payments of individual claims were given weak assumptions about their first two moments and modelled under quasi-likelihood theory, while settlement delays were modelled by multinomial logistic regression. Based on the model specification, loss reserve and conditional variance of outstanding liabilities were derived, which were further used to compute loss reserving and conditional MSEP. It was theoretically proved that loss reserving incorporating useful individual information shows higher accuracy than that under IDM, where the accuracy is measured by the conditional MSEP, when portfolio size is large enough. The conclusion is also supported by the simulations and real data analysis.
Table 5. Reserving, accuracy of prediction and accuracy improvement of IIM with respect to IDM.
While the proposed model is basically a parametric model in statistical context, some one may be concerned with the limitation that the model is subjective and thus question its robustness in practical applications. Regarding this aspect, a possible next step is to study this problem under a nonparametric framework. Especially, it is more interesting to model the dependence of claims development on individual information by machine learning (including deep learning).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Zhigao Wang
Zhigao Wang is a Ph.D. candidate in Statistics at East China Normal University.
Xianyi Wu
Xianyi Wu is a professor in School of Statistics at East China Normal University.
Chunjuan Qiu
Chunjuan Qiu is an associate professor in School of Statistics at East China Normal University.
References
- Alai, D. H., Merz, M., & Wüthrich, M. V. (2009). Mean square error of prediction in the Bornhuetter–Ferguson claims reserving method. Annals of Actuarial Science, 4(1), 7–31. https://doi.org/https://doi.org/10.1017/S1748499500000580
- Alai, D. H., Merz, M., & Wüthrich, M. V. (2010). Prediction uncertainty in the Bornhuetter–Ferguson claims reserving method: Revisited. Annals of Actuarial Science, 5(1), 7–7. https://doi.org/https://doi.org/10.1017/S1748499510000023
- Antonio, K., & Plat, R. (2014). Micro-level stochastic loss reserving for general insurance. Scandinavian Actuarial Journal, 2014(7), 649–669. https://doi.org/https://doi.org/10.1080/03461238.2012.755938
- Arjas, E. (1989). The claims reserving problem in non-life insurance: Some structural ideas. ASTIN Bulletin: The Journal of the IAA, 19(2), 139–152. https://doi.org/https://doi.org/10.2143/AST.19.2.2014905
- Crevecoeur, J., Antonio, K., & Verbelen, R. (2019). Modeling the number of hidden events subject to observation delay. European Journal of Operational Research, 277(3), 930–944. https://doi.org/https://doi.org/10.1016/j.ejor.2019.02.044
- England, P. D., & Verrall, R. J. (2002). Stochastic claims reserving in general insurance. British Actuarial Journal, 8(3), 443–544. https://doi.org/https://doi.org/10.1017/S1357321700003809
- Huang, J., Qiu, C., & Wu, X. (2015). Stochastic loss reserving in discrete time: Individual vs. aggregate data models. Communications in Statistics-Theory and Methods, 44(10), 2180–2206. https://doi.org/https://doi.org/10.1080/03610926.2014.976473
- Huang, J., Qiu, C., Wu, X., & Zhou, X. (2015). An individual loss reserving model with independent reporting and settlement. Insurance: Mathematics and Economics, 64(1), 232–245. https://doi.org/https://doi.org/10.1016/j.insmatheco.2015.05.010
- Huang, J., Wu, X., & Zhou, X. (2016). Asymptotic behaviors of stochastic reserving: Aggregate versus individual models. European Journal of Operational Research, 249(2), 657–666. https://doi.org/https://doi.org/10.1016/j.ejor.2015.09.039
- Lindholm, M., Lindskog, F., & Wahl, F. (2020). Estimation of conditional mean squared error of prediction for claims reserving. Annals of Actuarial Science, 14(1), 93–128. https://doi.org/https://doi.org/10.1017/S174849951900006X
- Mack, T. (1993). Distribution-free calculation of the standard error of chain ladder reserve estimates. ASTIN Bulletin: The Journal of the IAA, 23(2), 213–225. https://doi.org/https://doi.org/10.2143/AST.23.2.2005092
- Mack, T. (2000). Credible claims reserves: The Benktander method. ASTIN Bulletin: The Journal of the IAA, 30(2), 333–347. https://doi.org/https://doi.org/10.2143/AST.30.2.504639
- McCullagh, P., & Nelder, J. A. (1989). Generalized linear models (2nd ed). Chapman and Hall.
- Norberg, R. (1993). Prediction of outstanding liabilities in non-life insurance 1. ASTIN Bulletin: The Journal of the IAA, 23(1), 95–115. https://doi.org/https://doi.org/10.2143/AST.23.1.2005103
- Norberg, R. (1999). Prediction of outstanding liabilities II. Model variations and extensions. ASTIN Bulletin: The Journal of the IAA, 29(1), 5–25. https://doi.org/https://doi.org/10.2143/AST.29.1.504603
- Pigeon, M., Antonio, K., & Denuit, M. (2013). Individual loss reserving with the multivariate skew normal framework. ASTIN Bulletin: The Journal of the IAA, 43(3), 399–428. https://doi.org/https://doi.org/10.1017/asb.2013.20
- Pigeon, M., Antonio, K., & Denuit, M. (2014). Individual loss reserving using paid-incurred data. Insurance: Mathematics and Economics, 58(2), 121–131. https://doi.org/https://doi.org/10.1016/j.insmatheco.2014.06.012
- Van der Vaart, A. W. (2000). Asymptotic Statistics. Cambridge University Press.
- Verrall, R. J., Nielsen, J. P., & Jessen, A. H. (2010). Prediction of RBNS and IBNR claims using claim amounts and claim counts. Astin Bulletin, 40(2), 871–887. https://doi.org/https://doi.org/10.2143/AST.40.2.2061139
- Wahl, F. (2019). Explicit moments for a class of micro-models in non-life insurance. Insurance: Mathematics and Economics, 89(7), 140–156. https://doi.org/https://doi.org/10.1016/j.insmatheco.2019.10.001
- Wahl, F., Lindholm, M., & Verrall, R. (2019). The collective reserving model. Insurance: Mathematics and Economics, 87(7), 34–50. https://doi.org/https://doi.org/10.1016/j.insmatheco.2019.04.003
- Wüthrich, M. V., & Merz, M. (2008). Stochastic Claims Reserving Methods in Insurance. John Wiley and Sons.
- Yu, X., & He, R. (2016). Individual claims reserving models based on marked Cox processes. Chinese Journal of Applied Probability and Statistics 32(2), 201-219. http://aps.ecnu.edu.cn/EN/Y2016/V32/I2/201
- Zhao, X., & Zhou, X. (2010). Applying copula models to individual claim loss reserving methods. Insurance: Mathematics and Economics, 46(2), 290–299. https://doi.org/https://doi.org/10.1016/j.insmatheco.2009.11.001
Appendix
Proof
Proof of Proposition 3.1
To derive the following gradient and Hessian matrix, we need the identities , which gives that
Then we have the following gradient according to formulas above, which is
By some algebraic computation, it follows that
Because
is just the number of those reported claims incurred in accident year i,
Observe further that
for
and
Therefore,
(A1)
(A1)
Let v = n−i−u and note that
Then, Equation (EquationA1
(A1)
(A1) ) gives rise to the desired result.
Proof
Proof of Theorem 4.1
By (Equation3(3)
(3) ), the loss reserve can be computed as
According to Assumption 3.2, for a representative policy in year i, given
with
,
follows multinomial distribution with parameters
and
. Then by Assumption 3.3, the RBNS loss reserve is
It can be easily proved that IBNR claims are independent of historical observation
by Assumption 3.1–3.3. Hence, IBNR loss reserve is computed by
According to independence assumptions in Assumptions 3.1–3.3, the developments of RBNS claims are independent of developments of IBNR claims, which results in the independence between
and
. Then the variance of R given
is
First, for
, we compute
For
, compute
which is equal to
which can be computed as follows:
Then by independence among policies and Assumptions 3.2 and 3.3, the variance of RBNS loss reserve given
is
Because IBNR claims are independent of historical observation
, variance of IBNR loss reserve given
is computed by
Proof
Proof of Theorem 4.3
Expand about true parameters
by Taylor expansion. Then we have
One knows that
. Write
and
,
and
. To compute the partial derivative in the Taylor expansion above, we need the following partial derivatives:
By the law of large numbers, it can be proved that
, where
, where denoting
(A2)
(A2)
It is well known that under some regular conditions and hence
. Besides,
If individual data model hold true, one can similarly prove that
. Therefore,
in this case. If individual information model holds true, we can easily prove that
is asymptotically biased, which results from the following arguments. The law of large numbers readily gives
and
. Further, we have
and
. We have
where
and then
Apparently,
and by the law of large numbers and some simple algebra operations, we show that
Therefore, if asymptotic bias Δ is not zero,
. Then we complete the proof.