
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In stepped wedge cluster randomised trials (SW-CRTs), clusters of subjects are randomly assigned to sequences, where they receive a specific order of treatments. Compared to conventional cluster randomised studies, one unique feature of SW-CRTs is that all clusters start from control and gradually transition to intervention according to the randomly assigned sequences. This feature mitigates the ethical concern of withholding an effective treatment and reduces the logistic burden of implementing the intervention at multiple clusters simultaneously. This feature, however, presents challenges that need to be addressed in experimental design and data analysis, i.e., missing data due to prolonged follow-up and complicated correlation structures that involve between-subject and longitudinal correlations. In this study, based on the generalised estimating equation (GEE) approach, we present a closed-form sample size formula for SW-CRTs with a binary outcome, which offers great flexibility to account for unbalanced randomisation, missing data, and arbitrary correlation structures. We also present a correction approach to address the issue of under-estimated variance by GEE estimator when the sample size is small. Simulation studies and application to a real clinical trial are presented.
1. Introduction
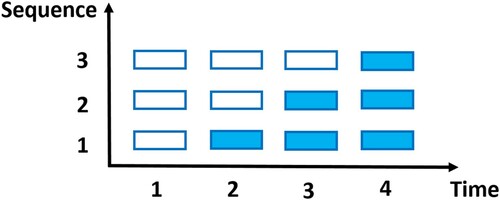
Recently, stepped wedge cluster randomised trials (SW-CRTs) are gaining popularity in large-scale biomedical and healthcare studies (Bacchieri et al., Citation2010; Bailet et al., Citation2009; Lenguerrand et al., Citation2020; Scalia et al., Citation2019; van Holland et al., Citation2012). Clusters of subjects are randomly assigned to different treatment sequences. Within each sequence, all clusters receive the control initially, but switch to the intervention at a particular step, as illustrated in Figure . There are two main types of SW-CRTs. One is the closed-cohort SW-CRT, which follows the same cohort of subjects through the treatment sequences. i.e., each subject contributes a set of longitudinal measurements. The other is the cross-sectional SW-CRT, which enrols a new panel of subjects at each step, i.e., each subject only contributes one measurement (Beard et al., Citation2015; Copas et al., Citation2015; Martin et al., Citation2016). SW-CRTs are considered advantageous in that (1) all clusters eventually receive the intervention, mitigating the ethical concern of withholding the effective intervention; (2) clusters switch from control to intervention in one direction only, which is more convenient in terms of washout compared to crossover studies with multiple periods; (3) they reduce the logistic burden of implementing the intervention simultaneously at many centres or facilities (Edwards, Citation2013; Zhou et al., Citation2020).
Figure 1. A diagram of an SW-CRT with 4 time points and 3 sequences (shaded and blank cells represent intervention and control, respectively.)
At the design stage, it is important to determine the number of clusters to ensure that clinical trials are adequately powered to detect effective interventions. Hussey and Hughes (Citation2007) proposed a sample size estimation approach based on mixed-effect models for cross-sectional SW-CRTs with continuous outcomes, which also extends to binary outcomes. This approach assumes the correlation between any pairs of measurements from the same cluster to be identical, regardless of whether they are observed during the same period or not. This assumption might over-simplify reality because the correlation between concurrent observations is likely stronger than that between non-concurrent ones. Furthermore, among non-concurrent observations, the correlation might decay as observations become temporally further apart. Hooper et al. (Citation2016) derived a sample size formula based on multilevel models for closed-cohort and cross-sectional SW-CRTs with continuous outcomes. Within clusters, a separate exchangeable correlation is assumed for concurrent and non-concurrent observations, with the former stronger than the latter. Kasza et al. (Citation2019) proposed a sample size method that allows the correlation between non-concurrent observations to decay exponentially. Li et al. (Citation2018) proposed sample size procedures for closed-cohort SW-CRTs with continuous and binary responses under the framework of generalised estimating equations (GEE), which employs a block exchangeable within-cluster correlation structure and this procedure can be extended to cross-sectional SW-CRTs. Zhou et al. (Citation2020) developed a numerical power analysis method for SW-CRTs with binary outcomes based on the maximum-likelihood approach. Other developments in sample size calculation for SW-CRTs include, but are not limited to, Hemming et al. (Citation2015), Woertman et al. (Citation2013), Moulton et al. (Citation2007), and Baio et al. (Citation2015).
Most of the existing sample size methods assume relatively simpler correlation structures and no missing data, which might not hold in real SW-CRTs. Especially in closed-cohort SW-CRTs, with prolonged follow-up, the correlation structures that simultaneously involve between-subject and within-subject (longitudinal) correlations can be complicated and the problem of missing data cannot be ignored. In this study, based on the GEE approach (Liang & Zeger, Citation1986), we present a closed-form sample size formula for SW-CRTs with a binary outcome. It is generally applicable to both cross-sectional and closed-cohort SW-CRTs. It also provides great flexibility to account for design issues frequently encountered by practitioners including unbalanced randomisation, different severity and patterns of missing data, and complicated correlation structures.
This article is organised as follows. In Section 2, we describe the model and derive a closed-form formula to calculate the required number of clusters in SW-CRTs with binary outcomes. In Section 3, we conduct extensive simulations to evaluate the performance of the proposed method and to explore the impact of different design parameters on sample size requirement. In Section 4, we apply this method to the design of a postoperative delirium study. In Section 5, we conclude with a discussion.
2. Method
Suppose in a closed-cohort SW-CRT with T time points, n clusters are randomly assigned to S sequences (S = T−1). These clusters are randomly assigned to the sth sequence with probability (
), where
. The resulting number of clusters assigned to the sth sequence is denoted by
, with
. The cluster size (number of subjects per cluster) is denoted by J. Let
denote the binary measurement obtained from the jth subject (
) within the ith cluster (
) under the sth sequence (
) at time t (
. We define
and
is modelled by
Here
is the time-specific intercept,
is the treatment indicator with 0/1 indicating control/intervention, and ζ represents the intervention effect, which is assumed to be constant over time. The specification of
(
) allows us to account for temporal trends of arbitrary shapes. As for the second moment, first we have
. For the vector of longitudinal observations from each individual,
, we define
to be the within-subject (longitudinal) correlation matrix with diagonal elements
(
). Furthermore, we use
to denote correlation between subjects from the same clusters. It can be considered as the matrix version of ICC (intracluster correlation coefficient). Define
to be the collection of measurements from the
th cluster. The correlation matrix of
is
where ⊗ is the Kronecker product operator,
is a
identity matrix, and
is a vector of length J with all elements being 1. Finally, the observations are assumed to be independent across clusters. Hence, we complete the model specification for the first two moments of
, as is required by the GEE approach (Liang & Zeger, Citation1986).
Define to be the vector of parameters. Based on the GEE approach with an independent working correlation structure, the estimate
can be solved from the score function
using the Newton–Raphson method, where
with
, and
is the design matrix with
. Liang and Zeger (Citation1986) proved that as
,
asymptotically follows a multivariate normal distribution with zero mean and covariance matrix
, where
and
Here
is a
diagonal matrix with the
th element being
for
and
for a matrix
. In practice,
and
can be estimated by
and
where
is the residual vector with
, and
is
diagonal with elements being
.
Let be the estimator of ζ and
be the
th element of
. Based on the test statistic
, to reject the null hypothesis
with a power of
at a two-sided significance level of α, the required number of clusters can be computed by
(1)
(1) where
is the true intervention effect,
,
is the weighted proportion of subjects receiving intervention at time t,
, and
is the
th percentile of the standard normal distribution with 0<c<1. Details of derivation are presented in Appendix .
In closed-cohort SW-CRTs, longitudinal measurements are planned on each subject at pre-specified time points. However, in real clinical trials with prolonged follow-up, the occurrence of missing data is usually inevitable. Ignoring missing data in sample size calculation will lead to under-powered studies. To address this problem, we introduce the missing indicator if
is observed/missing. We assume that the occurrence of missing data only depends on time and define the marginal observational probability
. To accommodate different missing data patterns, we also introduce the joint observational probability
, which is the probability that a subject contributes observations both at time t and
(
). For example, under the independent missing (IM) pattern, the occurrences of missing data are independent between t and
, hence
. On the other hand, under the monotone missing (MM) pattern, a subject having missing data at t would miss all subsequent observation, hence
for
. Under the assumption of missing completely at random,
and
can be rewritten as
and
respectively. Here
indicates the operation of Hadamard product,
is a
diagonal matrix with diagonal elements being
, and
is a
matrix with the diagonal
th element being
and off-diagonal (
)th element being
. Then the generalised formula for the number of clusters accounting for missing data is
(2)
(2) Formula (Equation2
(2)
(2) ) offers great flexibility to accommodate various missing data patterns (through
), complicated correlation structures (through
), and unbalanced randomisation (through
). On the other hand, given n and the true treatment effect
, the anticipated power can be evaluated by
where Z is a standard normal variable.
We have described the sample size calculation method for closed-cohort SW-CRTs with binary outcomes. In practice, many SW-CRTs are cross-sectional, where new panels of subjects are measured at each time point. Using the same notation framework, the proposed method easily accommodates cross-sectional SW-CRTs. Specifically, we consider the cluster size under a cross-sectional SW-CRT to be JT. At each time point, J subjects are selected from each cluster for measurements, and these subjects will not be selected again in the future. It implies that between-period correlation in
is equivalent to within-period correlation
in
. The required number of clusters can be similarly calculated using Equation (Equation2
(2)
(2) ).
3. Simulation studies
We conducted simulation studies to evaluate the performance of the proposed sample size method. Suppose we are planning a closed-cohort SW-CRT with T = 4 time points and cluster size J = 15. We assume balanced randomisation to the S = 3 sequences, i.e., . We set the time-specific intercepts
for
. We explore two values for the intervention effect
: 0.41 and 0.59, which corresponded to odds ratios of 1.5 and 1.8, respectively. Different correlation structures are explored: for the longitudinal correlation matrix (
), we investigate the CS and AR(1) structures, with off-diagonal elements being
and
, respectively; for the between-subject correlation matrix, we specify
with diagonal ICC being
and off-diagonal between-subject between-period correlation
being 0.005. We also explored different correlation values
. For missing data, we considered four sets of marginal observational probabilities as follows:
represents the scenario where all subjects contribute complete observations, while
represents scenarios of various trends in missing data, but with the same attrition rate (0.3) at the end of the study. The IM and MM missing data patterns will be explored, which leads to different joint observational probabilities (see Section 2). The null hypothesis is
. We set the power
and two-sided type I error rate
. For each combination of design parameters, we calculate the required number of clusters (n) and conducted simulations to evaluate the empirical power and type I error. The simulation algorithm is outlined as follows:
Calculate the required number of clusters (n) using Equation (Equation2
(2)
Generate the numbers of clusters randomised to the three sequences (
For each cluster, generate a vector of correlated binary measurements based on true effect
Generate missing indicators under different missing patterns and marginal observational probabilities
Calculate
Repeat Steps 2–5 5000 times. The empirical power is calculated as the proportion of iterations that reject the null hypothesis. The empirical type I error is evaluated similarly except for setting
In Tables and , the columns under ‘GEE’ present the simulation results. Each cell presents the required number of clusters as well as the empirical power and type I error. We have several observations. First, more clusters are required when longitudinal correlation () and between-subject correlation (
) get larger. For example, in the first row of Table , the required number of clusters changes from 45 to 46 when the longitudinal correlation (
) increases from 0.1 to 0.2. On the other hand, in the first cell of Tables and , the required number of clusters increases from 45 to 53 when the between-subject correlation (
) increases from 0.03 to 0.05. Second, the longitudinal correlation structures affect the required number of clusters, which can be shown by comparing the CS and AR(1) panels in each table. Third, different missing patterns and observational probabilities affect the required number of clusters. Given the same attrition rate at the end of the study, scenarios with greater dropout initially lead to more missing data and larger sample size requirements. For example, sample sizes under
are always the largest among
–
. Furthermore, under the MM missing pattern, missing data tend to concentrate on a few subjects, which leads to greater information loss and larger sample size requirement. Finally, compared with the nominal type I error of 0.05, the empirical type I errors are generally inflated (up to 0.0868). The reason is that when the number of clusters is relatively small, the conventional GEE approach tends to underestimate the variance of the treatment effect (Morel et al., Citation2003).
Table 1. Required number of clusters (empirical power, empirical type I error) for closed-cohort studies with .
Table 2. Required number of clusters (empirical power, empirical type I error) for closed-cohort studies with .
To address the issue of underestimated variance, we have explored different correction methods, including Mancl and DeRouen (Citation2001), Kauermann and Carroll (Citation2001), Ziegler and Vens (Citation2010), Morel et al. (Citation2003), Fay and Graubard (Citation2001) and Pan and Wall (Citation2002). We find that the combination of Morel et al. (Citation2003) (MBN) and Donner and Klar's (Citation2000) methods achieves a good balance between satisfactory performance and easy implementation in practice. Specifically, the MBN method modifies the GEE covariance estimator with an additional term
Donner and Klar's (Citation2000) method suggests adding one cluster to each treatment arm. The results under this combination approach are presented in Tables and under the columns of ‘Adjusted GEE’. The empirical powers and type I errors are very close to their nominal values of 0.8 and 0.05, respectively. For example, in Table when the number of clusters is less than 30, the type I errors without adjustment are all severely inflated (larger than 0.07). After adjustment, all the type I errors are close to the nominal level 0.05.
We also conduct simulations to investigate the performance of the proposed method in cross-sectional SW-CRTs. Because each subject only contributes one measurement, the issue of missing data does not apply. We set and
. Two values are explored for ρ: 0.03 and 0.05. Table presents the required number of clusters with empirical power and type I error for cross-sectional SW-CRTs. Similar to the observations from the closed-cohort SW-CRTs, a smaller correlation (ρ) is associated with a smaller sample size requirement. Furthermore, the proposed correction approach performs well in maintaining the empirical powers and type I errors at their nominal levels.
Table 3. Required number of clusters (empirical power, empirical type I error) for cross-sectional studies.
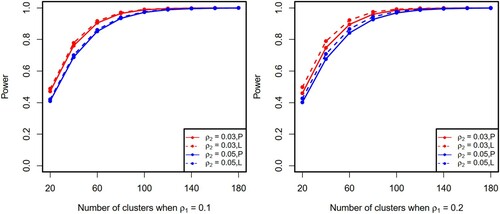
We performed additional simulations to evaluate the relationship between the required number of clusters and power. We used the same parameter settings as described above for closed-cohort studies with the CS correlation structures. Under different combinations of design parameters, as shown in Figure (solid lines), testing power increases as the number of clusters increases. Furthermore, we compared the proposed method with an existing method (Li et al., Citation2018). Since Li's method does not account for missing data, we only consider the scenario of complete observations. To maximise the usability of the proposed sample size method in pragmatic settings, we assume that when analysing trial data researchers do not know the true correlation structure and make inference using GEE with independent working correlation. This practical solution is slightly less efficient than Li's method which uses the true correlation (see Figure ). We believe the proposed method nonetheless provides a useful sample size solution for the design of pragmatic SW-CRTs because it compensates for a slight loss in efficiency by advantages in (1) a closed-form sample size formula; (2) accommodation of missing data; and (3) not requiring the true correlation to be known during inference.
Figure 2. Relationship between the number of clusters and power (P and L denote the proposed method and Li's method, respectively).
4. Example
We apply the proposed method to a cross-sectional SW-CRT study (Mouchoux et al., Citation2011), which was designed to evaluate whether a multifaceted programme (including consulting and training, etc.) could decrease postoperative delirium in patients aged 75 and older. The outcome of interest is the occurrence of delirium within seven days after surgery. Suppose this study is conducted over a six-month period with T = 4 pre-specified time points and surgical wards are assigned to S = 3 sequences with balanced randomisation. At each time point, 15 patients per surgical ward will receive assigned intervention and the delirium outcome will be recorded. It is hypothesised that the multifaceted programme can reduce the occurrence of delirium from 60% to 40%, which corresponds to an odds ratio of 0.44 and a constant time effect of 0.41. By assuming in
and
, we will need 16 wards to achieve 80% power at a two-sided significance level of 0.05. If 30 patients are selected per surgical ward for measurements, 12 wards will be needed.
5. Discussion
In this study, we propose a sample size and power calculation method that is generally applicable to both closed-cohort and cross-sectional SW-CRTs with binary outcomes. We directly incorporate several design issues encountered in pragmatic trials into power analysis and were able to provide a closed-form sample size solution. Through different specifications of correlation matrices and
, the proposed method offers great flexibility to account for different types of SW-CRTs and correlation structures. The inclusion of parameters
allows researchers to employ unbalanced randomisation. Furthermore, our method maintains the desired power in the presence of missing data through the specification of marginal observational probabilities at population level (
), and the missing pattern at subject level (
). In simulation studies, we have investigated the independent (IM) and monotone (MM) missing patterns. In practice, a clinical trial might encounter different types of missing patterns. For example, it is possible that some subjects miss a few appointments due to accidents (IM), while some subjects drop out in the middle of study (MM). The proposed sample size method can accommodate such scenarios by specifying a mixture of IM and MM, where
and
where w and 1−w are weights for IM and MM, respectively. Finally, we have present a correction approach to address the issue of underestimated variance by the GEE method when the number of clusters is limited in SW-CRTs.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Bacchieri, G., Barros, A. J., Gonçalves, H., & Gigante, D. P. (2010). A community intervention to prevent traffic accidents among bicycle commuters. Revista De Saude Publica, 44(5), 867–875. https://doi.org/10.1590/S0034-89102010000500012
- Bailet, L. L., Repper, K. K., Piasta, S. B., & Murphy, S. P. (2009). Emergent literacy intervention for prekindergarteners at risk for reading failure. Journal of Learning Disabilities, 42(4), 336–355. https://doi.org/10.1177/0022219409335218
- Baio, G., Copas, A., Ambler, G., Hargreaves, J., Beard, E., & Omar, R. Z. (2015). Sample size calculation for a stepped wedge trial. Trials, 16(1), 354. https://doi.org/10.1186/s13063-015-0840-9
- Beard, E., Lewis, J. J., Copas, A., Davey, C., Osrin, D., Baio, G., Thompson, J. A., Fielding, K. L., Omar, R. Z., Ononge, S., Hargreaves, J., & Prost, A. (2015). Stepped wedge randomised controlled trials: systematic review of studies published between 2010 and 2014. Trials, 16(1), 353. https://doi.org/10.1186/s13063-015-0839-2
- Copas, A. J., Lewis, J. J., Thompson, J. A., Davey, C., Baio, G., & Hargreaves, J. R. (2015). Designing a stepped wedge trial: three main designs, carry-over effects and randomisation approaches. Trials, 16(1), 352. https://doi.org/10.1186/s13063-015-0842-7
- Donner, A., & Klar, N. (2000). Design and analysis of cluster randomization trials in health research. Arnold.
- Edwards, S. J. (2013). Ethics of clinical science in a public health emergency: Drug discovery at the bedside. The American Journal of Bioethics, 13(9), 3–14. https://doi.org/10.1080/15265161.2013.813597
- Emrich, L. J., & Piedmonte, M. R. (1991). A method for generating high-dimensional multivariate binary variates. The American Statistician, 45(4), 302–304. https://doi.org/10.2307/2684460
- Fay, M. P., & Graubard, B. I. (2001). Small-sample adjustments for Wald-type tests using sandwich estimators. Biometrics, 57(4), 1198–1206. https://doi.org/10.1111/j.0006-341X.2001.01198.x
- Hemming, K., Haines, T. P., Chilton, P. J., Girling, A. J., & Lilford, R. J. (2015). The stepped wedge cluster randomised trial: Rationale, design, analysis, and reporting. BMJ (Clinical Research Ed.), 350, h391. https://doi.org/10.1136/bmj.h391
- Hooper, R., Teerenstra, S., de Hoop, E., & Eldridge, S. (2016). Sample size calculation for stepped wedge and other longitudinal cluster randomised trials. Statistics in Medicine, 35(26), 4718–4728. https://doi.org/10.1002/sim.v35.26
- Hussey, M. A., & Hughes, J. P. (2007). Design and analysis of stepped wedge cluster randomized trials. Contemporary Clinical Trials, 28(2), 182–191. https://doi.org/10.1016/j.cct.2006.05.007
- Kasza, J., Hemming, K., Hooper, R., Matthews, J., & Forbes, A. (2019). Impact of non-uniform correlation structure on sample size and power in multiple-period cluster randomised trials. Statistical Methods in Medical Research, 28(3), 703–716. https://doi.org/10.1177/0962280217734981
- Kauermann, G., & Carroll, R. J. (2001). A note on the efficiency of sandwich covariance matrix estimation. Journal of the American Statistical Association, 96(456), 1387–1396. https://doi.org/10.1198/016214501753382309
- Lenguerrand, E., Winter, C., Siassakos, D., MacLennan, G., Innes, K., Lynch, P., Cameron, A., Crofts, J., McDonald, A., McCormack, K., Forrest, M., Norrie, J., Bhattacharya, S., & Draycott, T. (2020). Effect of hands-on interprofessional simulation training for local emergencies in Scotland: The thistle stepped-wedge design randomised controlled trial. BMJ Quality & Safety, 29(2), 122–134. https://doi.org/10.1136/bmjqs-2018-008625
- Li, F., Turner, E. L., & Preisser, J. S. (2018). Sample size determination for GEE analyses of stepped wedge cluster randomized trials. Biometrics, 74(4), 1450–1458. https://doi.org/10.1111/biom.v74.4
- Liang, K. Y., & Zeger, S. L. (1986). Longitudinal data analysis for discrete and continuous outcomes using generalized linear models. Biometrika, 84, 3–32. https://doi.org/10.2307/2531248
- Mancl, L. A., & DeRouen, T. A. (2001). A covariance estimator for GEE with improved small-sample properties. Biometrics, 57(1), 126–134. https://doi.org/10.1111/biom.2001.57.issue-1
- Martin, J., Taljaard, M., Girling, A., & Hemming, K. (2016). Systematic review finds major deficiencies in sample size methodology and reporting for stepped-wedge cluster randomised trials. BMJ Open, 6(2), e010166. https://doi.org/10.1136/bmjopen-2015-010166
- Morel, J. G., Bokossa, M., & Neerchal, N. K. (2003). Small sample correction for the variance of GEE estimators. Biometrical Journal, 45(4), 395–409. https://doi.org/10.1002/bimj.200390021
- Mouchoux, C., Rippert, P., Duclos, A., Fassier, T., Bonnefoy, M., Comte, B., Heitz, D., Colin, C., & Krolak-Salmon, P. (2011). Impact of a multifaceted program to prevent postoperative delirium in the elderly: The CONFUCIUS stepped wedge protocol. BMC Geriatrics, 11(1), 1157. https://doi.org/10.1186/1471-2318-11-25
- Moulton, L. H., Golub, J. E., Durovni, B., Cavalcante, S. C., Pacheco, A. G., Saraceni, V., King, B., & Chaisson, R. E. (2007). Statistical design of THRio: A phased implementation clinic-randomized study of a tuberculosis preventive therapy intervention. Clinical Trials, 4(2), 190–199. https://doi.org/10.1177/1740774507076937
- Pan, W., & Wall, M. M. (2002). Small-sample adjustments in using the sandwich variance estimator in generalized estimating equations. Statistics in Medicine, 21(10), 1429–1441. https://doi.org/10.1002/(ISSN)1097-0258
- Scalia, P., Durand, M.-A., Forcino, R. C., Schubbe, D., Barr, P. J., O'Brien, N., O'Malley, A. J., Foster, T., Politi, M. C., Laughlin-Tommaso, S., Banks, E., Madden, T., Anchan, R. M., Aarts, J. W. M., Velentgas, P., Balls-Berry, J., Bacon, C., Adams-Foster, M., Mulligan, C. C., …, Elwyn, G. (2019). Implementation of the uterine fibroids option grid patient decision aids across five organizational settings: A randomized stepped-wedge study protocol. Implementation Science, 14(1), 100. https://doi.org/10.1186/s13012-019-0933-z
- van Holland, B. J., de Boer, M. R., Brouwer, S., Soer, R., & Reneman, M. F. (2012). Sustained employability of workers in a production environment: Design of a stepped wedge trial to evaluate effectiveness and cost-benefit of the POSE program. BMC Public Health, 12(1), 1003. https://doi.org/10.1186/1471-2458-12-1003
- Woertman, W., de Hoop, E., Moerbeek, M., Zuidema, S. U., Gerritsen, D. L., & Teerenstra, S. (2013). Stepped wedge designs could reduce the required sample size in cluster randomized trials. Journal of Clinical Epidemiology, 66(7), 752–758. https://doi.org/10.1016/j.jclinepi.2013.01.009
- Zhou, X., Liao, X., Kunz, L. M., Normand, S.-L. T., Wang, M., & Spiegelman, D. (2020). A maximum likelihood approach to power calculations for stepped wedge designs of binary outcomes. Biostatistics (Oxford, England), 21(1), 102–121. https://doi.org/10.1093/biostatistics/kxy031
- Ziegler, A., & Vens, M. (2010). Generalized estimating equations. Methods of Information in Medicine, 49(05), 421–425. https://doi.org/10.3414/ME10-01-0026
Appendix. Derivation of Equation (1)
First we have
As
,
approaches
On the other hand, we have
As
,
approaches
We are only interested in
, which is the
-component of
. The last row of
can be simplified as
where
,
is the weighted proportion of subjects receiving intervention at time t, and
. Then, we have
The required number of clusters is