
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
To test variance homogeneity, various likelihood-ratio based tests such as the Bartlett's test have been proposed. The null distributions of these tests were generally derived asymptotically or approximately. We re-examine the restrictive maximum likelihood ratio (RELR) statistic, and suggest a Monte Carlo algorithm to compute its exact null distribution, and so its p-value. It is much easier to implement than most existing methods. Simulation studies indicate that the proposed procedure is also superior to its competitors in terms of type I error and powers. We analyse an environmental dataset for an illustration.
1. Introduction
Homogeneity of variances among populations or factor levels plays a fundamental role in analysis of variance (ANOVA) and many statistical analysis approaches. For example, ANOVA inferences are generally slightly affected by unequal variances if the model contains only fixed factors and has equal or almost equal sample sizes. On the other hand, the inference results based on the ANOVA models with random effects or unequal sample sizes can be substantially affected by the inequality of variances. Bartlett (Citation1937) developed a modified likelihood-ratio test and derived the associated asymptotic distribution of the test, which can control type I error under the normality assumption. However, its performance in small sample sizes is not attractive as pointed out by Bishop and Nair (Citation1939) and Hartley (Citation1940). Since then various efforts have been made to improve Bartlett's test. Representative work includes (Boos & Brownie, Citation1989; Box, Citation1953; Brown & Forsythe, Citation1974; Cochran, Citation1951; Hartley, Citation1950; Levene, Citation1960; Pardo et al., Citation1997). Recently, there is recognition that variability itself can be a major issue. For instance, Teschendorff and Widschwendter (Citation2012) argued that in cancer genomics, differential variability can be as important as differential means for predicting disease phenotypes, and indicates that understanding heterogeneity can be crucial.
Since the common critical values are given using chi-squared distribution approximation, various variants from large-sample or numerical approximation-based aspects have been proposed. These tests generally work well in the large-sample sense, but they are not exact tests in the sense of frequency.
In order to obtain an exact (or nearly exact) test for checking homogeneity of variances under normal distribution, additional efforts have further been made in several ways. For example, Wu and Wong (Citation2003) provided a critical value approximation approach through the saddle point approximation. Bhandary and Dai (Citation2009) proposed a test (BDT) based on Benforroni type adjustment procedure on the ordered p-value. Liu and Xu (Citation2010) proposed a generalized p-value test (GPT) by employing the generalized inference (Tian, Citation2005, Citation2007; Weerahandi, Citation2004). Ma et al. (Citation2015) suggested an adjusted Bartlett's test (ABT) on the basis of the equal mean principle. Gokpinar and Gokpinar (Citation2017) re-examined the computational approach test (CAT), that was originally introduced by Pal et al. (Citation2007). Each of these methods has their own merits under certain favourable circumstances. Gokpinar and Gokpinar (Citation2017) compared the four tests, BAR, BDT, GPT and CAT, in terms of the type I error rate and the power, and concluded that CAT appears to be more powerful than other three tests when the group size is small or moderate, and further confirmed that BAR could not maintain type I error rates as well as could be conservative in small sample sizes.
In this paper, we develop a practically useful procedure to calculate the null distribution; i.e., the p-value, of the restrictive maximum likelihood-ratio (RELR) statistic. The procedure has nice statistical properties as aforementioned Bartlett type of tests in large sample sizes. Its small-sample performance is attractive and superior to its competitors in most situations. Most importantly, it is very easily implemented and computationally expedient from practical perspectives.
The paper is organized as follows. Section 2 briefly describes the framework and introduces Bartlett test. In Section 3, we re-examine the RELR statistic and suggest a Monte Carlo algorithm for computing its p-value. Section 4 presents simulation results to evaluate the small-sample performance of the proposed test and to compare with some existing methods. We analyse a real dataset to compare the six tests for illustrating the utility of the proposed test in Section 5, and remark the paper with a discussion in Section 6.
2. Framework and Bartlett test
Let be k groups of independent random samples from the normal populations
for
The test of variance homogeneity can be formulated as
(1)
(1) Let
and
be the sample mean and variance of the ith population,
, and
be the total sample size. It is well-known that the restrictive maximum likelihood-ratio (RELR) test statistic for the hypothesis (Equation1
(1)
(1) ) is
(2)
(2) and the p-value of the test is given by
where
(3)
(3) with
being the observed
based on the data. Since it is generally impossible to derive the exact distribution of
, Bartlett (Citation1937) modified
to
and showed that
is asymptotically chi-squared with degrees of freedom k−1 as
, though this approximation is not necessary when k = 2 because the corresponding RELR statistic is a monotonic function of the
ratio. Consequently, the null hypothesis is suggested to be rejected if
given the significance level α.
3. The proposed procedure
Under the null hypothesis , let
, and note that the RELR statistic given in (Equation2
(2)
(2) ) can be expressed as follows.
this expression motivates us to introduce a new quantity as
is not a statistic any more because it contains parameters
's. Since
are independently chi-squared variables with
degrees of freedom, for
. Write
,
could be rewritten as a new quantity
(4)
(4) which is independent of all unknown
's. Therefore, we may derive the distribution of
, equivalently the distribution of
, under
. Consequently, we can calculate the p-value of the test (Equation1
(1)
(1) ) as
Hence, the power function of the test could be given by
It may not be easy to derive the distribution of
in practice, we therefore alternatively calculate the p-value by Monte Carlo simulation. Specifically, we calculate the power via the following algorithm.

4. Simulation studies
In this section, we report simulation results to evaluate the performance of the proposed testing procedure. For the comparison purpose, we examine the following tests: Bartlett test (BAR, Bartlett, Citation1937), the adjusted Bartlett's test (ABT, Ma et al., Citation2015), the generalized p-value test (GPT, Liu & Xu, Citation2010), the Bhandary and Dai's test (BDT, Bhandary & Dai, Citation2009), the computational approach test (CAT, Pal et al., Citation2007), and the RELR test. The criterion for analysing the performance of the methods is to compare the type I error and power properties of tests.
In what follows, we set ,
, and denote
.
stands for a vector, in which
are replicated r times, and
means to remain the first K elements of
when it contains more than K elements. For example,
,
; and
.
To examine the performance of these tests, the parameter setting of the simulation studies are as follows: (1) The number of samples equals 2, 5, 10, 15, 30, 50; (2) Different combinations of group size k and sample sizes n are given in the first two columns of Table ; (3) We set for
for calculating the type I errors, and consider various degrees of variance heterogeneity listed in the following box for the power comparison.
Table 1. Simulated type I errors.
| (a1) | k = 2, | ||||
| (a2) | k = 2, | ||||
| (b1) | k = 5, | ||||
| (b2) | k = 5, | ||||
| (c1) | k = 10, | ||||
| (c2) | k = 10, | ||||
| (d1) | k = 15, | ||||
| (d2) | k = 15, | ||||
| (e1) | k = 30, | ||||
| (e2) | k = 30, | ||||
| (f1) | k = 50, | ||||
| (f2) | k = 50, | ||||
For each pattern and parameter, we generated N = 5000 simulation data sets. For each simulated data set and the real data set in the next section, we let to obtain the p-value of the GPT, CAT and RELR test. The empirical or power is the proportion of rejecting the null hypothesis among
simulation runs. We used the nominal significance level of
in our simulation studies.
Table reports type I errors of the six tests under different parameter configurations. As can be seen, the Bartlett's test is generally conservative in all configurations, while CAT often fails to control the type I error rate. The type I errors of other competitors are generally smaller than that of CAT but larger than that of BAR except when their type I errors all close to the nominal level. These numerical results indicate that ABT, GPT, BDT, and RELR have good type I error control for almost all the situations.
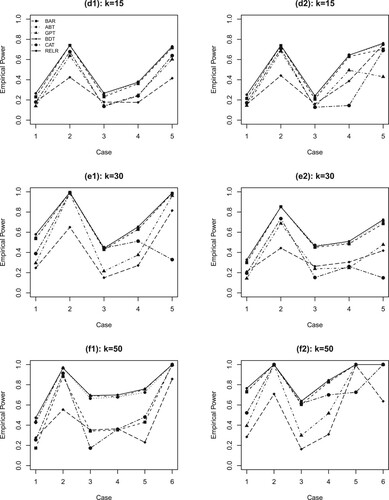
Figures and present the powers of the six tests for the 12 situations, (a1)–(f2), against the cases (specified in the 3rd column of Table .) From the results we can conclude that when the group size k is small , all tests yield a similar power pattern. This indicates that their performance very closes. When the group size k increases to moderate size like 10 or 15, the powers of BAR, ABT and RELR still show a similar pattern, and are higher than those of GPT, BDT and CAT. This indicates that BAR, ABT and RELR are superior to GPT, BDT and CAT. This superiority become more distinctive when the group size k increases to 30 or 50. For example, When k = 50,
,
, the powers of CAT, BDT and GPT are 0.70, 0.517 and 0.309, respectively, while the powers of BAR, ABT and RELR are 0.827, 0.830, and 0.844, respectively (corresponding to case 4 of (f2) in Figure ). Overall, RELR can effectively control the type I error, and its power is higher (or at least the same) than the other five tests for almost all configurations.
Figure 1. Simulation results for Settings (k = 2, 5, 10) corresponding to various cases. BAR: Bartlett's test (red line with filled square); ABT: Ma et al.'s test ; GPT: Liu & Xu's test; BDT: Bhandary & Dai's test; CAT: Gokpinar & Gokpinar's test; and LRT.
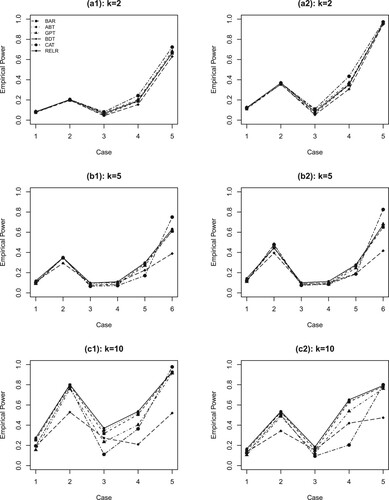
Figure 2. Simulation results for Settings (k = 15, 30, 50) corresponding to various cases. The caption is the same as in Figure .
5. Real data example
In this section, we analyse the dataset for the detrended particulate matter (pm) of Maryland in 1990 by using the six tests to investigate the seasonal effect on pm
variability. After removing missing observations, we have 88, 88, 97, and 74 observations within Spring, Summer, Fall, and Winter. Let
be their variances for i = 1, 2, 3, 4, respectively. This concern can then be formulated as the null hypothesis:
.
We compute the p-value using the six tests with M = 10000. The corresponding p-values for BAR, ABT, GPT, CAT, RELR are ,
,
,
and
, and BDT indicates that we fail to reject the null hypothesis for given
significant level. So all tests except the proposed RELR suggest that we could not reject the null hypothesis, while only RELR suggest a rejection, though these p-values are slightly different. Recalling our simulation results, we prefer the result based on RELR, and conclude that the variances among the four seasons are not homogeneous.
6. Concluding remarks
In this paper, we have proposed a procedure for calculating the p-value of the restrictive likelihood ratio test for variance homogeneity. The procedure is very easy to implement and performs promising. Given the optimality of the likelihood ratio principle, we conjecture that the test could be most efficient, which warrants a further investigation. This paper provides a means to calculate the p-value when it is difficult, if not impossible, to derive (asymptotic) distribution of the proposed test statistic. However, there is no a general guideline to reformulate in (Equation2
(2)
(2) ). So deriving a quantity similar to
may be case by case. Whether the proposed procedure can be applied to high-dimensional (in the sense of diverging with the sample size) situations is unclear and also warrants further research.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Juan Wang
Juan Wang is an assistant professor of School of Mathematics and Statistics at Qingdao University.
Xinmin Li
Xinmin Li is a professor of School of Mathematics and Statistics at Qingdao University.
Hua Liang
Hua Liang is a professor of Department of Statistics at George Washington University.
References
- Bartlett, M. S. (1937). Properties of sufficiency and statistical tests. Proceedings of the Royal Society. Series A, Mathematical and Physical Sciences, 160, 268–282. https://doi.org/https://doi.org/10.1098/rspa.1937.0109
- Bhandary, M., & Dai, H. (2009). An alternative test for the equality of variances for several populations when the underlying distributions are normal. Communications in Statistics Simulation and Computation, 38(1–2), 109–117. https://doi.org/https://doi.org/10.1080/03610918.2014.955110
- Bishop, D., & Nair, U. (1939). A note on certain methods of testing for the homogeneity of a set of estimated variances. Supplement to the Journal of the Royal Statistical Society, 6(1), 89–99. https://doi.org/https://doi.org/10.2307/2983627
- Boos, D. D., & Brownie, C. (1989). Bootstrap methods for testing homogeneity of variances. Technometrics, 31(1), 69–82. https://doi.org/https://doi.org/10.1080/00401706.1989.10488477
- Box, G. E. P. (1953). Non-normality and tests on variances. Biometrika, 40, 318–335. https://doi.org/https://doi.org/10.1093/biomet/40.3-4.318
- Brown, M. B., & Forsythe, A. B. (1974). Robust tests for the equality of variances. Journal of the American Statistical Association, 69(346), 364–367. https://doi.org/https://doi.org/10.1080/01621459.1974.10482955
- Cochran, W. G. (1951). Testing a linear relation among variances. Biometrics, 7, 17–32. https://doi.org/https://doi.org/10.2307/3001601
- Gokpinar, E., & Gokpinar, F. (2017). Testing equality of variances for several normal populations. Communications in Statistics Simulation and Computation, 46(1), 38–52. https://doi.org/https://doi.org/10.1080/03610918.2014.955110
- Hartley, H. O. (1940). Testing the homogeneity of a set of variances. Biometrika, 31, 249–255. https://doi.org/https://doi.org/10.1093/biomet/31.3-4.249
- Hartley, H. O. (1950). The maximum F-ratio as a short-cut test for heterogeneity of variance. Biometrika, 37, 308–312. https://doi.org/https://doi.org/10.2307/2332383
- Levene, H. (1960). Contributions to probability and statistics: Essays in honor of Harold Hotelling, In I. Olkin, S. G. Ghurye, W. Hoeffding, W. G. Madow, H. B. Mann (Eds.), Stanford studies in mathematics and statistics (Vol. 2). Stanford University Press.
- Liu, X., & Xu, X. (2010). A new generalized p-value approach for testing the homogeneity of variances. Statistics & Probability Letters, 80(19-20), 1486–1491. https://doi.org/https://doi.org/10.1016/j.spl.2010.05.017
- Ma, X.-B., Lin, F.-C., & Zhao, Y. (2015). An adjustment to the Bartlett's test for small sample size. Communications in Statistics Simulation and Computation, 44(1), 257–269. https://doi.org/https://doi.org/10.1080/03610918.2013.773347
- Pal, N., Lim, W. K., & Ling, C.-H. (2007). A computational approach to statistical inferences. Journal of Applied Probability and Statistics, 2(1), 13–35.
- Pardo, J., Pardo, M., Vicente, M., & Esteban, M. (1997). A statistical information theory approach to compare the homogeneity of several variances. Computational Statistics & Data Analysis, 24(4), 411–416. https://doi.org/https://doi.org/10.1016/S0167-9473(96)00080-1
- Teschendorff, A. E., & Widschwendter, M. (2012). Differential variability improves the identification of cancer risk markers in dna methylation studies profiling precursor cancer lesions. Bioinformatics (Oxford, England), 28, 1487–1494. https://doi.org/https://doi.org/10.1093/bioinformatics/bts170
- Tian, L. (2005). Inferences on the mean of zero-inflated lognormal data: The generalized variable approach. Statistics in Medicine, 24(20), 3223–3232. https://doi.org/https://doi.org/10.1002/(ISSN)1097-0258
- Tian, L. (2007). Inferences on standardized mean difference: The generalized variable approach. Statistics in Medicine, 26(5), 945–953. https://doi.org/https://doi.org/10.1002/(ISSN)1097-0258
- Weerahandi, S. (2004). Generalized inference in repeated measures. Wiley-Interscience [John Wiley & Sons].
- Wu, J., & Wong, A. C. M. (2003). A note on determining the p-value of Bartlett's test of homogeneity of variances. Communications in Statistics Theory and Methods, 32(1), 91–101. https://doi.org/https://doi.org/10.1081/STA-120017801