
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider sparsity selection for the Cholesky factor L of the inverse covariance matrix in high-dimensional Gaussian DAG models. The sparsity is induced over the space of L via non-local priors, namely the product moment (pMOM) prior [Johnson, V., & Rossell, D. (2012). Bayesian model selection in high-dimensional settings. Journal of the American Statistical Association, 107(498), 649–660. https://doi.org/10.1080/01621459.2012.682536] and the hierarchical hyper-pMOM prior [Cao, X., Khare, K., & Ghosh, M. (2020). High-dimensional posterior consistency for hierarchical non-local priors in regression. Bayesian Analysis, 15(1), 241–262. https://doi.org/10.1214/19-BA1154]. We establish model selection consistency for Cholesky factor under more relaxed conditions compared to those in the literature and implement an efficient MCMC algorithm for parallel selecting the sparsity pattern for each column of L. We demonstrate the validity of our theoretical results via numerical simulations, and also use further simulations to demonstrate that our sparsity selection approach is competitive with existing methods.
1. Introduction
Covariance estimation and selection is a fundamental problem in multivariate statistical inference. In recent years, high-throughput data from various applications is being generated rapidly. Several promising methods have been proposed to interpret the complex multivariate relationships in these high-dimensional datasets. In particular, methods inducing sparsity in the Cholesky factor of the inverse have proven to be very effective in applications. These models are also referred to as Gaussian DAG models. In particular, consider i.i.d. observations obeying a multivariate normal distribution with mean vector
and covariance matrix Σ. Let
be the unique modified Cholesky decomposition of the inverse covariance matrix
, where L is a lower triangular matrix with unit diagonals, and D is a diagonal matrix with all diagonal entries being positive. A given sparsity pattern on L corresponds to certain conditional independence relationships, which can be encoded in terms of a directed acyclic graph
on the set of p variables as follows: if the ith and jth variables do not share an edge in
, then
(see Section 2 for more details). In this paper, we focus on imposing sparsity on the Cholesky factor of the inverse covariance matrix through a class of non-local priors.
Non-local priors were first introduced by Johnson and Rossell (Citation2010) as densities that are identically zero whenever a model parameter is equal to its null value in the context of hypothesis testing. Non-local priors discard spurious covariates faster as the sample size n increases compared with local priors, while preserving exponential learning rates to detect nontrivial coefficients. These non-local priors including the product moment (pMOM) non-local prior are extended to Bayesian model selection problems in Johnson and Rossell (Citation2012) and Shin et al. (Citation2018) by imposing non-local priors on regression coefficients. Wu (Citation2016) and Cao et al. (Citation2020) consider a fully Bayesian approach with the pMOM non-local prior and an appropriate Inverse-Gamma prior on the hyperparameter (the so-called hyper-pMOM prior), and discuss the potential advantages of using hyper-pMOM priors and establish model selection consistency in regression setting.
In the context of Gaussian DAG models, Altamore et al. (Citation2013) deal with structural learning for Gaussian DAG models from an objective Bayesian perspective by assigning a prior distribution on the space of DAGs, together with an improper product moment prior on the Cholesky factor corresponding to each DAG. However, objective priors are often improper and cannot be used to directly compute the Bayes factors, even when the marginal likelihoods are strictly positive and finite. The authors therefore utilize the fractional Bayes factor (FBF) approach and implement an efficient stochastic search algorithm to deal with data sets having sample size smaller than the number of variables. Cao et al. (Citation2019) further establish consistency results under these objective priors under rather restrictive conditions.
To the best of our knowledge, a rigorous investigation of high-dimensional posterior consistency properties with either pMOM prior or the hyper-pMOM prior has not been undertaken for either undirected graphical models or DAG models. Hence, our first goal was to investigate if high-dimensional consistency results could be established under these two more diverse and algebraically complex class of non-local priors in the Gaussian DAG model setting. Our second goal was to investigate if these consistency results can be obtained under relaxed or comparable conditions. Our third goal was to develop efficient algorithms for exploring the massive candidate space containing models. These were challenging goals of course, as the posterior distributions are not available in closed form for both the pMOM prior and the hyper-pMOM prior.
As the main contributions of this paper, we establish high-dimensional posterior ratio consistency for Gaussian DAG models with both the pMOM prior as well as the hyper-pMOM prior on the Cholesky factor L, and under a uniform-like prior on the sparsity pattern in L (Theorems 4.2–7.3). Following the nomenclature in Lee et al. (Citation2019) and Niu et al. (Citation2019), this notion of consistency also referred to as consistency of posterior odds implies the maximal ratio between the marginal posterior probability assigned to a ‘non-true’ model and the posterior probability assigned to the ‘true’ model converges to zero. That also indicates that the true model will be the posterior mode with probability tending to 1. As indicated in Shin et al. (Citation2018), since the pMOM priors already induce a strong penalty on the model size, it is no longer necessary to penalize larger models through priors on the graph space like Erdos–Renyi prior (Niu et al., Citation2019), beta-mixture prior (Carvalho & Scott, Citation2009), or multiplicative prior (Tan et al., Citation2017). Also, through simulation studies where we implement an efficient parallel MCMC algorithm for exploring the sparsity pattern of each column of L, we demonstrate that the models studied in this paper can outperform existing state-of-the-art methods including both penalized likelihood and Bayesian approaches in different settings.
The rest of the paper is organized as follows. Section 2 provides background material regarding the Gaussian DAG model and introduces the pMOM Cholesky distribution. In Section 3, we present our hierarchical Bayesian model and the parameter class for the inverse covariance matrices. Model selection consistency results for both the pMOM Cholesky prior and the hyper-pMOM Cholesky prior are stated in Sections 4 and 7 respectively, with proofs provided in the supplement. In Section 6 we use simulation experiments to illustrate the model selection consistency, and demonstrate the benefits of our Bayesian approach and computation procedures for Cholesky factor selection vis-a-vis existing Bayesian and penalized likelihood approaches. We end our paper with a discussion session in Section 8.
2. Preliminaries
In this section, we provide the necessary background material from graph theory, Gaussian DAG models, and also introduce our pMOM Cholesky prior.
2.1. Gaussian DAG models
We consider the multivariate Gaussian distribution
(1)
(1)
where Ω is a
inverse covariance matrix. Any positive definite matrix Ω can be uniquely decomposed as
, where L is a lower triangular matrix with unit diagonal entries, and D is a diagonal matrix with positive diagonal entries. This decomposition is known as the modified Cholesky decomposition of Ω (Pourahmadi, Citation2007). By considering this decomposition, one can place an appropriate prior over the diagonals of D to construct a hierarchical model. In addition, the unit diagonals resulting from the modified Cholesky decomposition can benefit the posterior calculation and proof of consistency.
A directed acyclic graph (DAG) consists of the vertex set
and an edge set E such that there is no directed path starting and ending at the same vertex. As in Ben-David et al. (Citation2016) and Lee et al. (Citation2019), we will without loss of generality assume a parent ordering, where that all the edges are directed from larger vertices to smaller vertices. Applications with natural ordering of variables include estimation of causal relationships from temporal observations, or settings where additional experimental data can determine the ordering of variables, and estimation of transcriptional regulatory networks from gene expression data (Huang et al., Citation2006; Khare et al., Citation2017; Shojaie & Michailidis, Citation2010; Yu & Bien, Citation2017). The set of parents of i, denoted by
, is the collection of all vertices which are larger than i and share an edge with i.
A Gaussian DAG model over a given DAG denoted by
consists of all multivariate Gaussian distributions which obey the directed Markov property with respect to a DAG
. In particular, if
and
, then
for each
. For the connection between the Cholesky factor L and the underlying DAG
, if
is the modified Cholesky decomposition of Ω, then
is a Gaussian DAG model over
if and only if
whenever
.
2.2. Notations
Consider the modified Cholesky decomposition , where L is a lower triangular matrix with all the unit diagonal entries and
, where
's are all positive and
represents the ith diagonal entry of D. We introduce latent binary variables
for
to indicate whether
is active, i.e.,
if
and 0, otherwise.
In this way, we are viewing the binary variable Z as the indicator for the sparsity pattern in L. For each , let
, a subset of
, be the index set of all non-zero components in
.
explicitly gives the support of the Cholesky factor and the sparsity pattern of the underlying DAG. Denote
as the cardinality of set
for
.
For any matrix A, denote
as a subset of A defined by rows in set
and columns in set
. Following the definition of Z, for any
matrix A, denote the column vectors
and
Also, let
,
In particular,
.
Next, we provide some additional required notations. For , let
and
represent the standard
and
norms. For a
matrix A, let
be the ordered eigenvalues of A and denote
In particular,
2.3. pMOM Cholesky prior
Johnson and Rossell (Citation2012) introduce the product moment (pMOM) non-local prior for the regression coefficients with density given by
(2)
(2)
Here
is a
nonsingular matrix, r is a positive integer referred to as the order of the density and
is the normalizing constant independent of τ and
, where τ is some positive constant. Variations of the density in (Equation2
(2)
(2) ), called the piMOM and peMOM density, have also been developed in Johnson and Rossell (Citation2012), Rossell et al. (Citation2013) and Shin et al. (Citation2018). Adapted to our framework, we place the following non-local prior on the Cholesky factor L corresponding to pMOM prior for a certain sparsity pattern Z,
(3)
(3)
for
, where similarly,
is a
positive definite matrix, r is a positive integer,
, and
is the normalizing constant independent of τ and
, but dependent on
.
can not be explicitly written in closed form by can be bounded below and above by a function of
. We refer to (Equation3
(3)
(3) ) as our pMOM Cholesky priors. To introduce a hierarchical model on the Cholesky parameter
, we will impose an Inverse-Gamma prior on the diagonal entries of D. Note that to obtain our desired asymptotic consistency results, appropriate conditions for all the aforementioned hyperparameters will be introduced in Section 4.1.
3. Model specification
Let be the observed data and
denote the sample covariance matrix. The class of pMOM Cholesky distributions (Equation3
(3)
(3) ) can be used for Bayesian sparsity selection of the Cholesky factor through the following hierarchical model,
(4)
(4)
(5)
(5)
(6)
(6)
The proposed hierarchical model now has five hyperparameters: the scale parameter
, the order r and positive definite matrix A in model (Equation5
(5)
(5) ) for the pMOM Cholesky prior, the shape parameter
and scale parameter
in model (Equation6
(6)
(6) ) for the Inverse-Gamma prior on
. Further restrictions on these hyperparameters to ensure desired consistency will be specified in Section 4.1.
Remark 3.1
Note that in the currently presented hierarchical model, we have not assigned any specific form to the prior over the sparsity patterns of L (essentially the space of Z). Some standard regularity assumptions for this prior will be provided later in Section 4.1. In fact, we will essentially impose a uniform-like prior on Z. Because of the strong penalty induced on the model size by the pMOM prior, it is no longer necessary to penalize larger models through priors on the graph space like the Erdos–Renyi prior (Niu et al., Citation2019), the complexity prior (Lee et al., Citation2019), or the multiplicative prior (Tan et al., Citation2017).
Note that under the hierarchical model (Equation4(4)
(4) )–(Equation6
(6)
(6) ), we can conduct posterior inference for the sparsity pattern of each column of L independently, which will benefit the computation significantly in the sense that it allows for parallel searching. In order to show the posterior ratio consistency
, we need the following lemma that establishes the marginal posterior probability.
Lemma 3.1
Under the hierarchical model (Equation4(4)
(4) )–(Equation6
(6)
(6) ), the resulting (marginal) posterior probability for
is given by
(7)
(7)
where
is some normalized constant independent of
,
,
and
denotes the expectation with respect to a multivariate normal distribution with mean
, and covariance matrix
.
Here we provide the proof of Lemma 3.1.
Proof of Lemma 3.1
By (Equation4(4)
(4) )–(Equation6
(6)
(6) ) and Bayes' rule, under the pMOM Cholesky prior, the resulting posterior probability for
is given by,
(8)
(8)
Note that
Therefore, it follows from (Equation8
(8)
(8) ) that
where
. Hence, by (Equation8
(8)
(8) ), we have
(9)
(9)
In particular, these posterior probabilities can be used to select a model by computing the posterior mode defined by
(10)
(10)
4. Main results
In this section we aim to investigate the high-dimensional asymptotic properties for the proposed model in Section 3. For this purpose, we will work in a setting where the data dimension and the hyperparameters vary with the sample size n and
. Assume that the data is actually being generated from a true model specified as follows. Let
be independent and identically distributed multivariate variate Gaussian vectors with mean
and true covariance matrix
, where
is the modified Cholesky decomposition of
. The sparsity pattern of the true Cholesky factor
is uniquely encoded in the true binary variable set denoted as
.
In order to establish our asymptotic consistency results, we need the following mild assumptions with corresponding discussion/interpretation. Denote as the maximum number of non-zero entries in each column of
. Let
as the smallest (in absolute value) non-zero off-diagonal entry in
, and can be interpreted as the ‘signal size’. For sequences
and
,
means
for some constant c>0. Let
represent
as
.
4.1. Assumptions
Assumption 1
There exists , such that for every
.
Assumption 2
as
.
Assumption 3
as
.
Assumption 4
For each , a uniform prior is placed over all models of size less than or equal to
, i.e.,
, where
.
Assumption 5a
The hyperparameters , τ,
,
in (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) satisfy
and
. Here
are constants not depending on n.
Assumption 1 has been commonly used for establishing high-dimensional covariance asymptotic properties (Banerjee & Ghosal, Citation2014, Citation2015; Bickel & Levina, Citation2008; El Karoui, Citation2008; Xiang et al., Citation2015). Assumption 2 essentially allow the number of variables to grow slower than
compared to previous literatures with rate
(Banerjee & Ghosal, Citation2014, Citation2015; Xiang et al., Citation2015). Assumption 2 also states the maximum number of parents for all the nodes for the true model (i.e.,
) must be at a smaller order than
.
Assumption 3 also known as the ‘beta-min’ condition provides a lower bound for the minimum values of that is needed for establishing consistency. This type of condition has been used for the exact support recovery of the high-dimensional linear regression models as well as Gaussian DAG models (Khare et al., Citation2017; Lee et al., Citation2019; Yang et al., Citation2016). Assumption 4 essentially states that the uniform-like prior on the space of the
possible models, places zero mass on unrealistically large models. Since Assumption 2 already restricts
to be
, Assumption 4 does not affect the probability assigned to the true model. See similar assumptions in Johnson and Rossell (Citation2012) and Shin et al. (Citation2018) in the context of regression.
Assumption 5a is standard which assumes the eigenvalues of the scale matrix in the pMOM Cholesky prior are uniformly bounded in n. Note that for the default value of , Assumption 5a is immediately satisfied. See similar assumptions in Shin et al. (Citation2018) and Johnson and Rossell (Citation2012). This assumption also states the hyperparameter τ in pMOM Cholesky prior and
in the Inverse-Gamma prior are bounded by a constant.
For the rest of this paper, ,
,
,
will be denoted as p,
,
,
,
,
by leaving out the superscript for notational convenience. Let
and
denote the probability measure and expected value corresponding to the ‘true’ model specified in the beginning of Section 4, respectively.
4.2. Posterior ratio consistency
Since the posterior probabilities in (Equation7(7)
(7) ) are not available in closed form, we need to leverage the following lemma that gives the upper bound for the Bayes factor between any ‘non-true’ model
and the true model
. Proof for this lemma will be provided in the supplement.
Lemma 4.1
Under Assumptions 1–5a, for each , the Bayes factor between any ‘non-true’ model
and the true model
under the pMOM Cholesky prior will be bound above by,
(11)
(11)
for some positive constant M, where
.
The upper bound for the Bayes factor in Lemma 4.1 can be used to prove posterior ratio consistency. This notion of consistency implies that the true model will be the posterior mode with probability tending to 1.
Theorem 4.2
Under Assumptions 1–5a, the following holds: for all ,
Proof of this result is provided in the supplement. If one is interested in a point estimate of , the most apparent choice would be the posterior mode defined as
(12)
(12)
By noting that
we have the following corollary.
Corollary 4.1
Under Assumptions 1–5a, the posterior mode is equal to the true model
with probability tending to 1, i.e., for all
,
4.3. Strong model selection consistency
Next we establish a stronger notion of consistency (compared to Theorem 4.2) that is referred to as strong selection consistency. which implies that the posterior mass assigned to the true model converges to 1 in probability (Lee et al., Citation2019; Narisetty & He, Citation2014). For achieving the strong selection consistency, we need the following assumption instead of Assumption 5a on τ. Proof for this theorem is provided in the supplement.
Assumption 5b
The hyperparameters , τ,
,
in (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) satisfy
,
and
, for some
. Here
are constants not depending on n.
Theorem 4.3
Under Assumptions 1–5b, the following holds: for all ,
Remark 4.1
Not that neither Theorem 4.2 nor Corollary 4.1 requires any restriction on the rate of the scale parameter τ in the pMOM Cholesky prior that will be growing, this requirement is only needed for Theorem 4.3. As noted in Johnson and Rossell (Citation2012), the scale parameter τ is of particular importance, as it reflects the dispersion of the non-local prior density around zero, and implicitly determines the size of the regression coefficients that will be shrunk to zero. Shin et al. (Citation2018) treat τ as given, and consider a setting where p and τ vary with the sample size n. In the context of linear regression, they show that high-dimensional model selection consistency is achieved under the peMOM prior under the assumption that τ grows larger than .
4.4. Comparison with existing methods
We compare our results and assumptions with those of existing methods in both Bayesian and frequentist literature. Assumption 2 is a weaker assumption for high-dimensional covariance asymptotic than other Bayesian approaches including Xiang et al. (Citation2015) and Banerjee and Ghosal (Citation2014, Citation2015). However, compared with methods based on penalized likelihood, Assumption 2 is stronger than the condition for some constant
in Yu and Bien (Citation2017) and van de Geer and Bühlmann (Citation2013), which also study the estimation of Cholesky factor for Gaussian DAG models with and without the known ordering condition, respectively. In terms of undirected graphical models, Assumption 2 is also more restrictive compared to the complexity assumptions
in Cai et al. (Citation2011) and
for some constant
in Zhang and Zou (Citation2014).
Interested readers may also find Assumption 4 to be stronger compared with Condition (P) in Lee et al. (Citation2019) where for some constant
. This is actually a result of the uniform-like prior imposed on the
. If we replace the uniform prior with the Erdos–Renyi prior or the complexity prior, this restriction can be relaxed to encompass a larger class of models. However, the simulation results will be compromised by always favouring the sparest model, since the penalty on larger models has already been induced through the pMOM prior itself.
In the context of estimating DAGs using non-local priors, Altamore et al. (Citation2013) deal with structural learning for Gaussian DAG models from an objective Bayesian perspective by assigning a prior distribution on the space of DAGs, together with an improper pMOM prior on the Cholesky factor corresponding to each DAG. The authors in Altamore et al. (Citation2013) proposed the FBF approach, but did not take the opportunity to examine the theoretical consistency. The major contributions of this paper are to fill the gap of high-dimensional asymptotic properties for pMOM and hyper-pMOM priors in Gaussian graphical models, and to develop efficient algorithms for exploring the massive candidate space containing models, as we discuss in the next section.
5. Computation
In this section, we will take on the task to illustrate the computational strategy for the proposed model. The integral formulation in (Equation7(7)
(7) ) is quite complicated, and the posterior probabilities can not be obtained in closed form. Hence, we use the Laplace approximation to compute
. Detailed formulas are provided in the supplement. A similar approach to compute posterior probabilities based on Laplace approximations has been used in Johnson and Rossell (Citation2012) and Shin et al. (Citation2018). In practice, when the computation burden for Laplace approximation becomes intensive as p increases, we also suggest using the upper bound of the posterior ((A.5) in the supplement) as an approximation, since our proofs are based on these upper bounds and the consistency results are therefore already guaranteed. Based on these approximations, we consider the following MCMC algorithm for exploring the model space:
Set the initial value
.
For each
Given the current
changing a non-zero entry in
changing a zero entry in
Compute
Draw
Repeat (a)–(c) until a sufficiently long chain is acquired.
Note that the inference for Z, the steps 2-(a) and 2-(d) in the above algorithm can be parallelized for each column of Z. For more details about the parallel MCMC algorithm, we refer the interested readers to Lee et al. (Citation2019), Bhadra and Mallick (Citation2013) and Johnson and Rossell (Citation2012). The above algorithm is coded in R and publicly available at https://github.com/xuan-cao/Non-local-Cholesky.
6. Simulation studies
In this section, we demonstrate our main results through simulation studies. To serve this purpose, we consider several different combinations of including both the low-dimensional and high-dimensional cases. For each fixed p, a
lower triangular matrix with unit diagonals is constructed. In particular, we randomly choose 4% or 8% of the lower triangular entries of the Cholesky factor and set them to be non-zero values according to the following three scenarios. The remaining entries are set to zero. We refer to this matrix as
. The matrix
also reflects the true underlying DAG structure encoded in
.
Scenario 1: All the non-zero off-diagonal entries in
Scenario 2: All the non-zero off-diagonal entries in
Scenario 3: Each non-zero off-diagonal entry is set to be 0.25, 0.5 or 0.75 with equal probability.
Next, we generate n i.i.d. observations from the distribution, and set the hyperparameters as r = 2,
,
. The above process ensures all the assumptions are satisfied. Since our posterior ratio consistency in Theorem 4.2 and strong model selection consistency in Theorem 4.3 require different constraints on the scale parameter τ, we also consider three values for τ: (a)
; (b)
; (c)
. Then, we perform model selection on the Cholesky factor using the four procedures outlined below.
Lasso-DAG with quantile based tuning: We implement the Lasso-DAG approach in Shojaie and Michailidis (Citation2010) by choosing penalty parameters (separate for each variable i) given by
ESC Metropolis–Hastings algorithm: We implement the Rao-Blackwellized Metropolis–Hastings algorithm for the empirical sparse Cholesky (ESC) prior introduced in Lee et al. (Citation2019) for exploring the space of the Cholesky factor. The hyperparameters and the initial states are taken as suggested in Lee et al. (Citation2019). Each MCMC chain for each row of the Cholesky factor runs for 5000 iterations with a burn-in period of 2000. All the active components in L with inclusion probability larger than 0.5 are selected.
FBF Fractional Bayes factor approach: We implement the stochastic search algorithm based on fractional Bayes factors for non-local moment priors suggested in Altamore et al. (Citation2013). The stochastic search algorithm is similar to that proposed by Scott and Carvalho (Citation2008), which includes re-sampling moves, local moves and global moves. The rationale can be summarized by saying that edge moves which already improved some models are likely to improve other models as well. The final model is constructed by collecting the entries with inclusion probabilities greater than 0.5.
pMOM Cholesky MCMC algorithm: We ran the MCMC algorithm outlined in Section 5 with
The model selection performance of these four methods is then compared using several different measures of structure such as false discovery rate, true positive rate and Mathews correlation coefficient (average over 100 independent repetitions). False Discovery Rate (FDR) represents the proportion of true non-zero entries among all the entries detected by the given procedure, True Positive Rate (TPR) measures the proportion of true non-zero entries detected by the given procedure among all the non-zero entries from the true model. FDR and TPR are defined as
Mathews Correlation Coefficient (MCC) is commonly used to assess the overall performance of binary classification methods and is defined as
where TP, TN, FP and FN correspond to true positive, true negative, false positive and false negative, respectively. Note that the value of MCC ranges from −1 to 1 with larger values corresponding to better fits (−1 and 1 represent worst and best fits, respectively). One would like the FDR values to be as close to 0 and TPR values to be as close to 1 as possible. The results are provided in Tables –, corresponding to different simulation settings.
Table 1. Model selection performance table under Scenario 1 with 4% non-zero entries.
Table 2. Model selection performance table under Scenario 1 with 8% non-zero entries.
Table 3. Model selection performance table under Scenario 2 with 4% non-zero entries.
Table 4. Model selection performance table under Scenario 2 with 8% non-zero entries.
Table 5. Model selection performance table under Scenario 3 with 4% non-zero entries.
Table 6. Model selection performance table under Scenario 3 with 8% non-zero entries.
Note that this cutoff value of 0.5 for obtaining the posterior estimator in our MCMC procedure is a natural default choice and could be changed in different contexts. However, it turns out that compared with other methods, our results are quite robust with respect to the thresholding value as we draw out the ROC curves under the setting with non-zero entries given in Figure . In particular, we observe the fixed
pMOM Cholesky model overall outperforms the other three methods including the pMOM model with growing
, especially when n and p increase.
Figure 1. ROC curves for sparsity selection. Top: n = 100; bottom: n = 200. (a) p = 100, (b) p = 200, (c) p = 500, (d) p = 200, (e) p = 400 and (f) p = 1000.
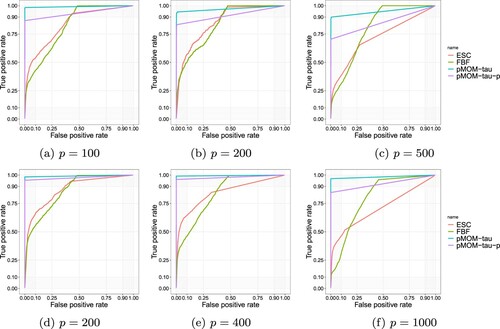
It is clear that our hierarchical Bayesian approach with pMOM Cholesky prior under two different values of τ outperforms Lasso-DAG, ESC and FBF approaches based on almost all measures. The FDR values for our Bayesian pMOM Cholesky approaches are mostly below 0.3 except when p = 1000, while the ones for the other methods are around or beyond 0.5. The TPR values for the proposed approaches are all beyond 0.6 in most cases, while the ones for the penalized likelihood approaches and other two Bayesian approaches are all below 0.55 in most scenarios. For the most comprehensive measure of MCC, our proposed Bayesian approach outperforms all the other three methods under all the cases of and two different sparsity settings. It is also worthwhile to compare the simulation performance between three different values of τ under the pMOM Cholesky prior. We can tell that the higher order of
though could guarantee the strong model selection consistency (Theorem 4.3), compared with the constant
and
case, the selection performance slightly suffers from the strong penalty induced by both the pMOM prior itself and the larger
value. The performance under
and
are very similar with a slightly better performance given by
. Hence, from a practical standpoint, one would prefer treating τ as a smaller constant (not growing with p) for better estimation accuracy.
It is also meaningful to compare the computational runtime between different methods. In Figure , we plot the run time comparison among our pMOM Cholesky approach, ESC and FBF. We can see that the run time for pMOM is significantly lessened compared to ESC and FBF, especially under the setting where we ran each ESC-based chain for 5000 iterations, while for pMOM, we ran 10,000 iterations. The computational cost of ESC is also extremely expensive in the sense that it requires not only additional run time, but also larger memory (more than 30 GB when ).
Figure 2. Run time comparison.
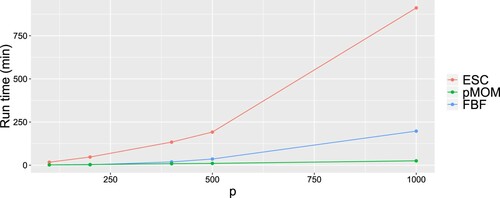
Overall, this experiment illustrates that the proposed hierarchical Bayesian approach with our pMOM Cholesky prior can be used for a broad yet computationally feasible model search, and at the same time can lead to a much more significant improvement in model selection performance for estimating the sparsity pattern of the Cholesky factor and the underlying DAG.
7. Results for hyper-pMOM Cholesky prior
In the generalized linear regression setting, Wu (Citation2016) proposes a fully Bayesian approach with the hyper-pMOM prior where an appropriate Inverse-Gamma prior is placed on the parameter τ in the pMOM prior. Following the nomenclature in Wu (Citation2016), we refer to the following mixture of priors as the hyper-pMOM Cholesky prior,
(13)
(13)
(14)
(14)
(15)
(15)
where
and
are positive constants.
Note that as indicated in Wu (Citation2016) and Cao et al. (Citation2020), compared to the pMOM density in (Equation2(2)
(2) ) with given τ, the marginal hyper-pMOM now possesses thicker tails that induce prior dependence. In addition, this type of mixture of priors could achieve better model selection performance especially for small samples (Liang et al., Citation2008).
By (Equation13(13)
(13) )–(Equation15
(15)
(15) ), under the hyper-pMOM Cholesky prior, the resulting posterior probability for
is given by,
(16)
(16)
where
,
and
denotes the expectation with respect to a multivariate normal distribution with mean
, and covariance matrix
. Since these posterior probabilities are still not available in closed, we have the following lemma that provides the upper bound for the Bayes factor under the following assumption.
Assumption 5c
The hyperparameters ,
in (Equation13
(13)
(13) )–(Equation15
(15)
(15) ) satisfy
and
. Here
are constants not depending on n.
Lemma 7.1
Under Assumption 1–5c, for each , the Bayes factor between any ‘non-true’ model
and the true model
under the hyper-pMOM Cholesky prior will be bound above by,
(17)
(17)
for some constants
.
The upper bound in (Equation17(17)
(17) ) can be used to show the posterior ratio consistency illustrated in the following theorem.
Theorem 7.2
Under Assumptions 1–5c, if we assume and
are some fixed positive constants, the following holds under the hyper-pMOM Cholesky prior: for all
,
In order to achieve strong model selection consistency, we need the following assumption on the hyperparameter instead of Assumption 5c.
Assumption 5d
The hyperparameters ,
in (Equation13
(13)
(13) )–(Equation15
(15)
(15) ) satisfy
,
and
, for some
. Here
are constants not depending on n.
The next theorem establishes the strong selection consistency under the hyper-pMOM Cholesky prior. See proofs for Theorems 7.2 and 7.3 in the supplement.
Theorem 7.3
Under Assumptions 1–5d, for the hyper-pMOM Cholesky prior, the following holds: for all ,
Note that for the hyper-pMOM Cholesky prior with the extra layer of prior on τ, the Newton-type algorithm used for optimizing the likelihood could be quite time consuming, and the estimation accuracy will be compromised, especially when the size of the model and the dimension p are large. Therefore, from a practical standpoint, we would still prefer the pMOM Cholesky prior for carrying out the model selection.
8. Discussion
In this paper, we investigate the theoretical consistency properties for the high-dimensional sparse DAG models based on proper non-local priors, namely the pMOM Cholesky and the hyper-pMOM Cholesky priors. We establish both posterior ratio consistency and strong model selection consistency under comparably more general conditions than those in the existing literature. In addition, by putting a uniform-like prior over the space of sparsity pattern for Cholesky factors, we avoid the potential issues of the model being stuck in rather sparse space caused by the priors over the graph space aiming to penalize larger models like the Erdos–Renyi prior, the beta-mixture prior or the multiplicative prior. Also, through simulation studies where we implement an efficient parallel MCMC algorithm for exploring the sparsity pattern of each column of L, we demonstrate that the models studied in this paper can outperform existing state-of-the-art methods including both penalized likelihood and Bayesian approaches in different settings.
Acknowledgments
We would like to thank the Editor, the Associate Editor and the reviewer for their insightful comments which have led to improvements of an earlier version of this paper.
Additional information
Funding
References
- Altamore, D., Consonni, G., & La Rocca, L. (2013). Objective Bayesian search of gaussian directed acyclic graphical models for ordered variables with non-local priors. Biometrics, 69(2), 478–487. https://doi.org/https://doi.org/10.1111/biom.v69.2
- Banerjee, S., & Ghosal, S. (2014). Posterior convergence rates for estimating large precision matrices using graphical models. Electronic Journal of Statistics, 8(2), 2111–2137. https://doi.org/https://doi.org/10.1214/14-EJS945
- Banerjee, S., & Ghosal, S. (2015). Bayesian structure learning in graphical models. Journal of Multivariate Analysis, 136, 147–162. https://doi.org/https://doi.org/10.1016/j.jmva.2015.01.015
- Ben-David, E., Li, T., Massam, H., & Rajaratnam, B. (2016). High dimensional Bayesian inference for Gaussian directed acyclic graph models (Tech. Rep.). http://arxiv.org/abs/1109.4371
- Bhadra, A., & Mallick, B. (2013). Joint high-dimensional Bayesian variable and covariance selection with an application to eQTL analysis. Biometrics, 69(2), 447–457. https://doi.org/https://doi.org/10.1111/biom.v69.2
- Bickel, P. J., & Levina, E. (2008). Regularized estimation of large covariance matrices. Annals of Statistics, 36(1), 199–227. https://doi.org/https://doi.org/10.1214/009053607000000758
- Cai, T., Liu, W., & Luo, X. (2011). A constrained ℓ1 minimization approach to sparse precision matrix estimation. Journal of the American Statistical Association, 106(494), 594–607. https://doi.org/https://doi.org/10.1198/jasa.2011.tm10155
- Cao, X., Khare, K., & Ghosh, M. (2019). Posterior graph selection and estimation consistency for high-dimensional Bayesian DAG models. Annals of Statistics, 47(1), 319–348. https://doi.org/https://doi.org/10.1214/18-AOS1689
- Cao, X., Khare, K., & Ghosh, M. (2020). High-dimensional posterior consistency for hierarchical non-local priors in regression. Bayesian Analysis, 15(1), 241–262. https://doi.org/https://doi.org/10.1214/19-BA1154
- Carvalho, C. M., & Scott, J. G. (2009). Objective Bayesian model selection in Gaussian graphical models. Biometrika, 96(3), 497–512. https://doi.org/https://doi.org/10.1093/biomet/asp017
- El Karoui, N. (2008). Spectrum estimation for large dimensional covariance matrices using random matrix theory. Annals of Statistics, 36(6), 2757–2790. https://doi.org/https://doi.org/10.1214/07-AOS581
- Huang, J., Liu, N., Pourahmadi, M., & Liu, L. (2006). Covariance selection and estimation via penalised normal likelihood. Biometrika, 93(1), 85–98. https://doi.org/https://doi.org/10.1093/biomet/93.1.85
- Johnson, V., & Rossell, D. (2010). On the use of non-local prior densities in Bayesian hvoothesis tests hypothesis. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 72(2), 143–170. https://doi.org/https://doi.org/10.1111/rssb.2010.72.issue-2
- Johnson, V., & Rossell, D. (2012). Bayesian model selection in high-dimensional settings. Journal of the American Statistical Association, 107(498), 649–660. https://doi.org/https://doi.org/10.1080/01621459.2012.682536
- Khare, K., Oh, S., Rahman, S., & Rajaratnam, B. (2017). A convex framework for high-dimensional sparse Cholesky based covariance estimation in Gaussian DAG models [Preprint, Department of Statisics, University of Florida].
- Lee, K., Lee, J., & Lin, L. (2019). Minimax posterior convergence rates and model selection consistency in high-dimensional DAG models based on sparse Cholesky factors. Annals of Statistics, 47(6), 3413–3437. https://doi.org/https://doi.org/10.1214/18-AOS1783
- Liang, F., Paulo, R., Molina, G., Clyde, A. M., & Berger, O. J. (2008). Mixtures of g priors for Bayesian variable selection. Journal of the American Statistical Association, 103(481), 410–423. https://doi.org/https://doi.org/10.1198/016214507000001337
- Narisetty, N., & He, X. (2014). Bayesian variable selection with shrinking and diffusing priors. Annals of Statistics, 42(2), 789–817. https://doi.org/https://doi.org/10.1214/14-AOS1207
- Niu, Y., Pati, D., & Mallick, B. (2019). Bayesian graph selection consistency under model misspecification. arxiv:1901.04134
- Pourahmadi, M. (2007). Cholesky decompositions and estimation of a covariance matrix: Orthogonality of variance–correlation parameters. Biometrika, 94(4), 1006–1013. https://doi.org/https://doi.org/10.1093/biomet/asm073
- Rossell, D., Telesca, D., & Johnson, V. E. (2013). High-dimensional Bayesian classifiers using non-local priors. In Statistical models for data analysis. Springer.
- Scott, J. G., & Carvalho, C. M. (2008). Feature-inclusion stochastic search for gaussian graphical models. Journal of Computational and Graphical Statistics, 17(4), 790–808. https://doi.org/https://doi.org/10.1198/106186008X382683
- Shin, M., Bhattacharya, A., & Johnson, V. (2018). Scalable Bayesian variable selection using nonlocal prior densities in ultrahigh-dimensional settings. Statistica Sinica, 28(2), 1053–1078. https://doi.org/https://doi.org/10.5705/ss.202016.0167
- Shojaie, A., & Michailidis, G. (2010). Penalized likelihood methods for estimation of sparse high-dimensional directed acyclic graphs. Biometrika, 97(3), 519–538. https://doi.org/https://doi.org/10.1093/biomet/asq038
- Tan, L. S. L., Jasra, A., De Iorio, M., & Ebbels, T. M. D. (2017). Bayesian inference for multiple gaussian graphical models with application to metabolic association networks. The Annals of Applied Statistics, 11(4), 2222–2251. https://doi.org/https://doi.org/10.1214/17-AOAS1076
- van de Geer, S., & Bühlmann, P. (2013). ℓ0-penalized maximum likelihood for sparse directed acyclic graphs. The Annals of Statistics, 41(2), 536–567. https://doi.org/https://doi.org/10.1214/13-AOS1085
- Wu, H.-H. (2016). Nonlocal priors for Bayesian variable selection in generalized linear models and generalized linear mixed models and their applications in biology data [PhD thesis, University of Missouri].
- Xiang, R., Khare, K., & Ghosh, M. (2015). High dimensional posterior convergence rates for decomposable graphical models. Electronic Journal of Statistics, 9(2), 2828–2854. https://doi.org/https://doi.org/10.1214/15-EJS1084
- Yang, Y., Wainwright, M. J., & Jordan, M. I. (2016). On the computational complexity of high-dimensional Bayesian variable selection. Annals of Statistics, 44(6), 2497–2532. https://doi.org/https://doi.org/10.1214/15-AOS1417
- Yu, G., & Bien, J. (2017). Learning local dependence in ordered data. Journal of Machine Learning Research, 18(42), 1–60.
- Zhang, T., & Zou, H. (2014). Sparse precision matrix estimation via lasso penalized D-trace loss. Biometrika, 101(1), 103–120. https://doi.org/https://doi.org/10.1093/biomet/ast059