
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper deals with the conditional density estimator of a real response variable given a functional random variable (i.e., takes values in an infinite-dimensional space). Specifically, we focus on the functional index model, and this approach represents a good compromise between nonparametric and parametric models. Then we give under general conditions and when the variables are independent, the quadratic error and asymptotic normality of estimator by local linear method, based on the single-index structure. Finally, we complete these theoretical advances by some simulation studies showing both the practical result of the local linear method and the good behaviour for finite sample sizes of the estimator and of the Monte Carlo methods to create functional pseudo-confidence area.
1. Introduction
The nonparametric estimation of the conditional density function plays a crucial role in statistical analysis. This subject can be approached from multiple perspectives depending on the complexity of the problem. Many techniques were studied in the literature to treat these various situations but all treat only real or multidimensional explanatory random variables.
Focusing on functional data for the kernel-type, the first results on the nonparametric estimate of this model were got by Ferraty and Vieu (Citation2006). They have studied the almost complete convergence the estimator of the conditional density and its derivates. Laksaci (Citation2007) studied quadratic error of this estimator, and we return to Ferraty et al. (Citation2010) which established the uniform almost complete convergence of this model always.
Now, we show a few results on the local linear smoothing for functional data, actually these results have been considered by many authors. Baìllo and Grané (Citation2009) first proposed a local linear smoothing of the regression estimator in a Hilbert space, and coming after them Barrientos-Marin et al. (Citation2010) developed this method of local linear estimation of the regression in the semi-metric space for independent and identically distributed. Demongeot et al. (Citation2013, Citation2014), has used this method to estimate conditional distribution and density function. In the case of spatial data (Laksaci et al., Citation2013) they established pointwise almost complete convergence rates.
Furthermore, the functional index model plays a major role in statistics. The interest of this approach comes from its use to reduce the dimension of the data by projection in fractal space. The literature on this topic is closely limited, the first work which was interested in the single-index model on the nonparametric estimation is Ferraty et al. (Citation2003) which stated for i.i.d. variables and obtained the almost complete convergence under some conditions. Based on the cross-validation procedure, Ait Saidi et al. (Citation2008) proposed an estimator of this parameter, where the functional single-index is unknown. Recently, Attaoui et al. (Citation2011) considered the nonparametric estimation of the conditional density in the single functional model. They established its pointwise and uniform almost complete convergence (a.co.) rates. In the same topic, Attaoui and Ling (Citation2016) proved the asymptotic results of a nonparametric conditional cumulative distribution estimator for time series data. More recently, Tabti and Ait Saidi (Citation2018) obtained the almost complete convergence and the uniform almost complete convergence of a kernel estimator of the hazard function with quasi-association condition when the observations are linked with functional single-index structure.
In this paper, we focus on the local linear estimation with the single-index structure to compute under some conditions, the quadratic error of the conditional density function estimator. In practice, this study has great importance, because, it permits to construct a prediction method based on the maximum risk estimation with a single functional index.
In Section 2, We introduce the estimator of our model in the single functional index. In Section 3, we introduce assumptions and asymptotic properties are given. Simulations are given in Section 4. Finally, Section 5 is devoted to the proofs of the results.
2. The model
Let be n random variables, independent and identically distributed as the random pair
with values in
where
is a separable real Hilbert space with the norm
generated by an inner product
. We consider the semi-metric
associated to the single-index
defined by
. Assume that the explanation of Y given X is done through a fixed functional index θ in
. In the sense, there exists a θ in
(unique up to a scale normalization factor) such that:
. The conditional density of Y given X = x denoted by
exists and is given by
In the following, we denote by
, the conditional density of Y given
and we define the local linear estimator for single-index structure
of
by
with
and
with
is a known bi-functional operator from
into
where K and H are kernel functions and
(resp.
) is a sequence that decreases to zero as n goes to infinity.
3. Assumptions and mains results
Throughout the paper, we will denote by C, and
some strictly positive generic constants and
,
,
and we will use the notation
, the ball centred at x with radius
. Moreover, to find the results in our paper we denote
, for any
.
In order to study our asymptotic results, we need the following assumptions:
| (H1) |
| ||||
| (H2) | For any | ||||
| (H3) | The bi-functional | ||||
| (H4) | The kernel K is a positive, differentiable function and its derivative | ||||
| (H5) | The kernel H is a differentiable function and bounded, such that
| ||||
| (H6) | The bandwidths
| ||||
Comments on assumptions: Notice that, (H1) and (H2) are a simple adaptation of the conditions in Ferraty et al. (Citation2007) on the regression operator, when we replace the semi-metric by some bi-functional . The second part of the condition (H3) is unrestrictive and is verified, for instance, if
; moreover
Assumptions (H4)–(H6) are classical in this context of quadratic errors and asymptotic normality in functional statistic.
3.1. Mean square convergence
In this part, we are going to show the asymptotic results of quadratic-mean convergence.
Theorem 3.1
Under assumptions (H1)–(H6), we obtain
where
and
with
We set
where
and
The following lemmas will be useful for proof of Theorem 3.1.
Lemma 3.2
Under the assumptions of Theorem 3.1, we obtain
Lemma 3.3
Under the assumptions of Theorem 3.1, we obtain
Lemma 3.4
Under the assumptions of Theorem 3.1, we get
Lemma 3.5
Under the assumptions of Theorem 3.1, we get
3.2. Asymptotic normality
This section contains results on the asymptotic normality of Before announcing our main results, we introduce the quantity
, which will appear in the bias and variance dominant terms:
Then, we have the following theorem
Theorem 3.6
Under assumptions (H1)–(H6), we obtain
(1)
(1) where
(2)
(2) and
(3)
(3) with
denoting the convergence in distribution.
Proof
Proof of Theorem 3.6
Inspired by the decomposition given in Masry (Citation2005), we set
If we denote
(4)
(4) since
then the proof of this theorem will be completed from the following expression
(5)
(5) and the following auxiliary results which play a main role and for which proofs are given in the appendix.
Lemma 3.7
Under assumptions (H1)–(H5), we have
where
denotes the convergence in probability.
So Lemma 3.7 implies that . Moreover,
as
because of the continuity of
. Then, we obtain that
Lemma 3.8
Under assumptions (H1)–(H5), we have
(6)
(6)
where is defined by (2).
Remark 3.9
As mentioned in Demongeot et al. (Citation2013), the function can be empirically estimated by
where
denote the cardinality of the set A. So, if we take advantage of the following assumptions and (H6)
we can cancel the bias term and obtain the following corollary.
Corollary 3.10
Under the assumptions of Theorem 3.6, we get
4. Simulation study
We first construct the simulation of the explanatory functional variables. In the second part, we focus on the ability of the nonparametric functional regression to predict response variables from functional predictors. Finally we illustrate the Monte-Carlo methodology to test the efficiency of the asymptotic normality results parallel the practical experiment and build functional pseudo-confidence area.
For this purpose, we consider the following process explanatory functional variables for n = 350
where
and
are n independent real random variables (r.r.v.) uniformly distributed over
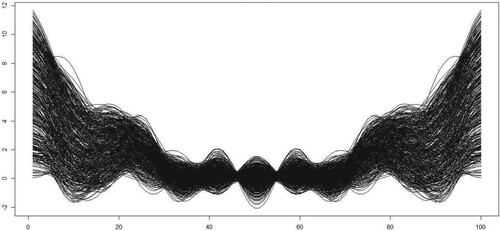
(resp. [1; 3]), and it is assumed that these curves are observed on a discretization grid of 100 points in the interval. These functional variables are represented in Figure .
Figure 1. The curves
For response variables , we consider the following model for all
and
:
where
and ϵ is a centred normal variable and assumed to be independent of
. Then, we can get the corresponding conditional density, which is explicitly defined by
Our goal in this illustration is to show the usefulness of conditional density in a context of forecasting. Thus the use of optimal parameters of the conditional density is without theoretical validity.
Now, we precise the different parameters of our estimators. Indeed, first of all, it is clear that the shape of the curves allows us to use
We choose particularly the quadratic kernels defined by
In this illustration, we select the functional index
on the set of eigenvectors of the empirical covariance operator.
Indeed, we recall that the ideas of Ait Saidi et al. (Citation2008) can be adapted to find a method of practical selection for
. However, this adaptation in the case of the conditional density requires tools and additional preliminary results (See the discussion Attaoui et al. (Citation2011) and Attaoui (Citation2014)).
For this purpose, we divide our observations on two packets learning sample and test sample
. For the choice of smoothing parameters
and
, we will adopt the selection criterion used by Ferraty et al. (Citation2006) in the case of the kernel method for which
and
are obtained by minimizing the next criterion
(7)
(7) where
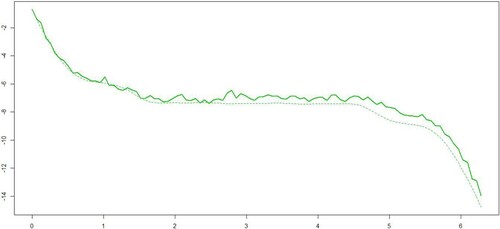
A first way of assessing the quality of prediction is to compare predicted functional responses (
for any X in the testing sample) versus the true of conditional density operator (i.e.,
) as in Figure .
Figure 2. Predicted functional responses (solid lines); observed functional responses (dashed lines).
For the next simulation algorithm, we used:
Simulate a sample of size n.
Calculate the smoothing parameters
and
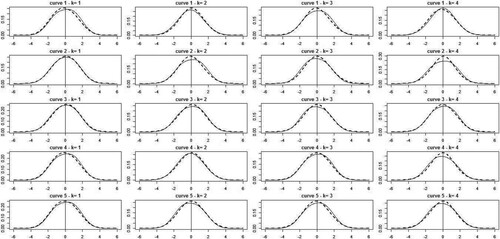
Compute for k = 1, 2, 3, 4 the quantities
Compute a standard density estimator by local linear method.
Compute the estimated
The obtained results are shown in Figure . It can be seen that both densities are very well approximated and have good behaviours with respect to the standard normal distribution.
Figure 3. Representation of the estimated density for k = 1, 2, 3, 4.
An application of results of Theorem 3.6 is to build the functional pseudo-confidence areas. To this aim, let us set for any component k, and
with
, confidence intervals
such that
where
with
being a data-driven orthonormal basis, the K eigenfunctions associated to the K largest eigenvalues of Γ.
The results from the asymptotic normality of the conditional density are expressed in Corollary 3.10 and we can approximate confidence interval of
by
where
denotes the
quantile of the standard normal
.
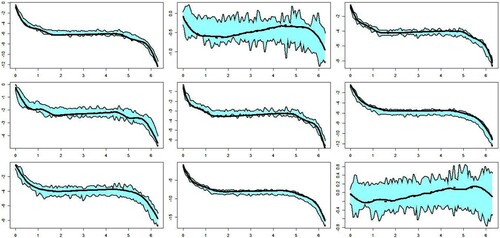
Figure represents a functional pseudo-confidence zone for 9 different fixed curves with and K = 4. We see that
and its K-dimensional projection onto
are very close. This conclusion shows the good performance of our asymptotic normality. Indeed, when one replaces the data-driven basis with the eigenfunctions of Γ, one gets very similar functional pseudo-confidence areas.
Figure 4. Functional pseudo-confidence areas.
5. Conclusion
In this paper, we are mainly interested in the nonparametric estimation of the conditional density function by the local linear method for a variable explanatory functionally conditioned to an actual response variable via a functional single-index model. We show that the estimator provides good predictions under this model. One of the main contributions of this work is the choice of the semi-metric. Indeed, it is well known that, in nonparametric functional statistics, the semi-metric of the projection type is very important for increasing the concentration property. The functional index model is a special case of this family of semi-metrics because it is based on the projection on a functional direction which is important for the implementation of our method in practice. Therefore, we can draw zones of functional pseudo-confidence, which is a very interesting tool for assessing the quality of the prediction.
Acknowledgments
The authors are very grateful to the Editor and the anonymous reviewers for their comments which improved the quality of this paper. The authors wish to thank two anonymous referees for their helpful comments and suggestions, which greatly improved the quality of this paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Ait Saidi, A., Ferraty, F., Kassa, P., & Vieu, P. (2008). Cross-validated estimations in the single functional index model. Statistics, 42(6), 475–494. https://doi.org/10.1080/02331880801980377
- Attaoui, S. (2014). Strong uniform consistency rates and asymptotic normality of conditional density estimator in the single functional index modeling for time series data. AStA Advances in Statistical Analysis., 98(3), 257–286. https://doi.org/10.1007/s10182-014-0227-3
- Attaoui, S., Laksaci, A., & Ould Said, F. (2011). A note on the conditional density estimate in the single functional index model. Statistics & Probability Letters, 81(1), 45–53. https://doi.org/10.1016/j.spl.2010.09.017
- Attaoui, S., & Ling, N. (2016). Asymptotic results of a nonparametric conditional cumulative distribution estimator in the single functional index modeling for time series data with applications. Metrika, 79(3), 485–511. https://doi.org/10.1007/s00184-015-0564-6
- Baìllo, A., & Grané, A. (2009). Local linear regression for functional predictor and scalar response. Journal of Multivariate Analysis, 100(1), 102–111. https://doi.org/10.1016/j.jmva.2008.03.008
- Barrientos-Marin, J., Ferraty, F., & Vieu, P. (2010). Locally modelled regression and functional data. Journal of Nonparametric Statistics, 22(5), 617–632. https://doi.org/10.1080/10485250903089930
- Bosq, D., & Lecoutre, J. P. (1987). Théorie de l'estimation fonctionnelle. Ed. Economica.
- Demongeot, J., Laksaci, A., Madani, F., & Rachdi, M. (2013). Functional data: local linear estimation of the conditional density and its application. Statistics: A Journal of Theoretical and Applied Statistics., 76(2), 328–355. https://doi.org/10.1080/02331888.2011.568117
- Demongeot, J., Laksaci, A., Rachdi, M., & Rahmani, S. (2014). On the local linear modelization of the conditional distribution for functional data. Sankhya: The Indian Journal of Statistics., 76(2), 328–355. https://doi.org/10.1007/s13171-013-0050-z
- Ferraty, F., Laksaci, A., Tadj, A., & Vieu, P. (2010). Rate of uniform consistency for nonparametric estimates with functional variables. Journal of Statistical Planning and Inference, 140(2), 335–352. https://doi.org/10.1016/j.jspi.2009.07.019
- Ferraty, F, Laksaci, A, & Vieu, P. (2006). Estimating some characteristics of the conditional distribution in nonparametric functional model. Statistical Inference for Stochastic Processes , 9(1), 47–76. https://doi.org/10.1007/s.11203-004-3561-3
- Ferraty, F., Mas, A., Vieu, P., & Vieu, P. (2007). Advances in nonparametric regression for functional variables. Australian & New Zealand Journal of Statistics, 49(1), 1–20. https://doi.org/10.1111/j.1467-842X.2006.00454.x
- Ferraty, F., Peuch, A., & Vieu, P. (2003). Modéle à indice fonctionnel simple. Comptes Rendus Mathématique de l'Académie des Sciences Paris, 336(12), 1025–1028. https://doi.org/10.1016/S1631-073X(03)00239-5(in French)
- Ferraty, F., & Vieu, P. (2006). Nonparametric functional data analysis. Theory and Practice. Springer Series in Statistics.
- Laksaci, A. (2007). Convergence en moyenne quadratique de l'estimateur a noyau de la densité conditionnelle avec variable explicative fonctionnelle. Publications de l'Institut de statistique de l'Université de Paris, 51(3), 69–80.
- Laksaci, A., Rachdi, M., & Rahmani, S. (2013). Spatial modelization: local linear estimation of the conditional distribution for functional data. Spatial Statistics, 6(4), 1–23. https://doi.org/10.1016/j.spasta.2013.04.004
- Masry, E. (2005). Nonparametric regression estimation for dependent functional data: asymptotic normality. Stochastic Processes and their Applications, 115(1), 155–177. https://doi.org/10.1016/j.spa.2004.07.006
- Sarda, P., & Vieu, P. (2000). Kernel regression. Wiley Series in Probability and Statistics (pp. 43–70).
- Tabti, H., & Ait Saidi, A. (2018). Estimation and simulation of conditional hazard function in the quasi-associated framework when the observations are linked via a functional single-index structure. Communications in Statistics -- Theory and Methods, 47(4), 816–838. https://doi.org/10.1080/03610926.2016.1213294
Appendix
Proof
Proof of Theorem 3.1
We know the theorem is a consequence of separately computing two quantities (bias and variance) of , and we have
By classical calculations, we obtain
which implies that
Under the assumption (H5), we can bound
by a constant C>0 where
. Hence
Now, by similar techniques as those of Sarda and Vieu (Citation2000) and by Bosq and Lecoutre (Citation1987), the variance term is
Proof
Proof of Lemma 3.2
We have
By using a Taylor's expansion and under assumption (H5), we have
Now, we can rewrite the above equation as
Thus, we obtain
According to Ferraty et al. (Citation2007), for
, we show that
Since
, we obtain
Then we get
Therefore, it remains to determine the quantities
and
. According to the definition of
, the two quantities
and
are based on the evaluation asymptotic of
. To do that, we treat firstly, the case b = 1. For this case, we use the assumptions (H3) and (H4) to get
So, we obtain that,
(A1)
(A1) Moreover, for all b>1, and after simplifications of the expressions, it is permitted to write that
Concerning the first term, we write
Finally, under assumptions (H1), we get
(A2)
(A2) So,
Hence,
Proof
Proof of Lemma 3.3.
We know (A3)
(A3) By direct calculations, we get
Clearly, the latter term in the above equation is the leading one, and can be evaluated in (EquationA3
(A3)
(A3) ) by using
By the same arguments used in the proof of Lemma 3.2, we obtain
(A4)
(A4) Observe that
Thus, by the change of variables
, we get
By using Taylor's expansion of order 1 of
we get
Then
Also, by the same steps in the proof of Lemma 3.2, we obtain
which give that
(A5)
(A5) Finally, we obtain from (EquationA2
(A2)
(A2) ), (EquationA4
(A4)
(A4) ) and (EquationA5
(A5)
(A5) ), that
Proof
Proof of Lemma 3.4
The proof of this Lemma is similar to the proof of Lemma 3.3. We can write
By direct calculations, we get
Since
, we obtain
Proof
Proof of Lemma 3.5
We have that
Similarly to the proof of Lemma 3.3, we get
We have as
,
(see Ferraty et al., Citation2007). Then, we can write finally
Proof
Proof of Lemma 3.8
We have
Then, combined with (Equation4
(4)
(4) ) implies that
Denote
It remains to show that,
Hence by Slutsky's theorem, to show (EquationA3
(A3)
(A3) ), it suffices to prove the following two claims:
(A6)
(A6)
(A7)
(A7)
Proof of (EquationA6
(A6)
(A6) ) We can write that
By Slutsky's theorem, we get the following intermediate results:
(A8)
(A8) and
(A9)
(A9) Concerning the proof of (EquationA8
(A8)
(A8) ), by applying the Bienaymé–Tchebychv's inequality, we obtain for all
Then, the Cauchy–Schwarz inequality implies that
On one side, by using (EquationA1
(A1)
(A1) ) and (EquationA2
(A2)
(A2) ), we obtain
And on the other side, we obtain
Thus
which implies that
. Then, as
, we get
Concerning the proof of (EquationA9
(A9)
(A9) )
where
By the fact that
are i.i.d., it follows that
Thus
(A10)
(A10) Concerning the second term on the right-hand side of (EquationA10
(A10)
(A10) ), we have
where
(A11)
(A11) Now let us return to the first term of the right hand of (EquationA10
(A10)
(A10) ). We have
By using (EquationA9
(A9)
(A9) ), we have as
Combining (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ), we obtain as
Therefore, by using (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ), Equation (EquationA10
(A10)
(A10) ) becomes
Now, in order to end the proof of (EquationA6
(A6)
(A6) ), we focus on the central limit theorem. So, the proof of (13) is completed if Lindberg's condition is verified. In fact, Lindberg's condition holds since, for any
as
Proofs of (EquationA7
(A7)
(A7) ) To use the same arguments as those invoked to prove (EquationA6
(A6)
(A6) ), let us write
By applying Bienaymé–Tchebychv's inequality, we obtain for all
And the Cauchy–Schwarz inequality implies that
Taking into account the assumptions H(Equation5
(5)
(5) ) and H(Equation6
(6)
(6) ), we get
On the other hand,
It remains to show
which implies that
Therefore,
So, to prove (EquationA6
(A6)
(A6) ), it suffices to show
, while
We arrive finally at
This last result together with (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) leads directly to
which allows finishes the proof.