
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Depending on the asymptotical independence of periodograms, exponential tilted (ET) likelihood, as an effective nonparametric statistical method, is developed to deal with time series in this paper. Similar to empirical likelihood (EL), it still suffers from two drawbacks: the non-definition problem of the likelihood function and the under-coverage probability of confidence region. To overcome these two problems, we further proposed the adjusted ET (AET) likelihood. With a specific adjustment level, our simulation studies indicate that the AET method achieves a higher-order coverage precision than the unadjusted ET method. In addition, due to the good performance of ET under moment model misspecification [Schennach, S. M. (2007). Point estimation with exponentially tilted empirical likelihood. The Annals of Statistics, 35(2), 634–672. https://doi.org/10.1214/009053606000001208], we show that the one-order property of point estimate is preserved for the misspecified spectral estimating equations of the autoregressive coefficient of AR(1). The simulation results illustrate that the point estimates of the ET outperform those of the EL and their hybrid in terms of standard deviation. A real data set is analyzed for illustration purpose.
1. Introduction
For the parametric inference of moment estimating equations, empirical likelihood (EL) is popular because of its small bias and its higher-order efficiency after correction (Newey & Smith, Citation2004). Similar to EL, exponential tilted (ET) attaches mounting attention according to its interpretation as a distance between the estimated probabilities with the empirical ones and as one member of one-step generalized moment methods (GMM) (Imbens, Citation2002; Kitamura & Stutzer, Citation1997). Under over-identified moment model misspecification, the influence function of ET makes its estimates relatively robust when the estimating functions are unbounded, but EL estimator would not be consistent to the pseudo-true value of the parameter vector, which minimizes the population discrepancy corresponding to the empirical version used in the estimating procedure (Imbens et al., Citation1998; Schennach, Citation2007). ET also allows an easy-going computation under the misspecified cases (Kitamura, Citation2000). Hence, the ET method has been widely applied in practice. For example, Schennach (Citation2005, Citation2007) conducted the so-called ETEL method, a hybird of ET and EL, to avoid such shortcoming of EL in model misspecification cases. Zhu et al. (Citation2009) applied ET for analyzing morphometric measures to prove the validity of adjusted correction. Caner (Citation2010) used ET estimator for weak instruments under a nonlinear model. Tang et al. (Citation2018) extended the penalized ET method for growing dimensional and misspecified unconditional moment models with a diverging number of parameters.
In terms of computation, ET still suffers from two undesirable properties for moderate and small sample sizes, namely, its non-definition and its large coverage error, which are same as EL. However, for EL, the large coverage error issue can be alleviated to some extent by Bartlett correction (Chan & Liu, Citation2010; DiCiccio et al., Citation1991). In addition, the adjusted EL (AEL) proposed by Chen et al. (Citation2008) can simultaneously eliminate both the non-definition and under-coverage resulted from non-definition. Liu and Chen (Citation2010) showed that AEL achieved the same high-order precision as the Bartlett corrected EL when the adjustment level was half the Bartlett correction factor. Unfortunately, Jing and Andrew (Citation1996) showed that ET could not be Bartlett corrected. Then the adjustment technique may be one possible way to correct the ET-based coverage error.
Originally, both ET and EL are only designed for independent samples because in such a case, its variance estimation within likelihood ratio is automatically corrected, which is driven by data, see Owen (Citation1988, Citation1990, Citation2001). Hence, it is difficult to directly extend them to dependent data, such as time series. However, Kitamura (Citation1997) developed time domain blockwise EL by data blocking for weakly dependent time series with rapidly decreasing correlations. Such EL is so limited that it is not appropriate to the long range dependent time series. Based on asymptotically independent periodogram ordinates, Monti (Citation1997) derived a widely applied frequent domain EL method for time series. This frequent domain EL was extended for long range models because the dependence of periodogram only exists a small portion and goes to zero in long-memory time series (Yau, Citation2012). For more general normalized spectral parameters, a new frequency domain EL ratio statistic was proposed by combining the periodogram with spectral estimating equations (Nordman & Lahiri, Citation2006). This work also pointed out that the Monti's EL is only appropriate to the models with Gaussian error terms and emphasized that their suggested EL is more preferable in view of confidence region. For more comprehensive understanding of EL applied in time series, we refer the readers to Nordman and Lahiri (Citation2014). However, as a powerful tool as EL, very little work has been done on time series analysis via the ET method.
In this paper, one of our work is to corroborate the adjustment technique that is valid to enhance the coverage probability of ET-based confidence region for stationary short- and long-memory time series. We derive the ET and adjusted ET (AET) likelihood ratios to construct the confidence regions for the spectral parameters defined as Nordman and Lahiri (Citation2006). The proposed likelihood ratios are shown to converge to a chi-square distribution. From Monte Carlo simulation results, it obviously indicates that AET-based confidence regions have larger and more accurate coverage probabilities than those based on ET under small sample. The other work is to investigate how well does ET point estimator work under the misspecified moment models of the spectral parameters. We derive the ET estimating procedure based on the over-identified moment estimating equations of autoregressive coefficient of AR(1). The desirable one-order asymptotic property is shown to be preserved. And the good performance of ET estimator under the model misspecification is exhibited in simulations by its standard deviations (SDs).
The rest parts of this paper are organized as follows. In Section 2, we first depict the ET and AET likelihood ratios for constructing confidence regions and then derive the one-order asymptotic property of the ET point estimate under the misspecified moment model. The simulation results of coverage probabilities and the point estimates under model misspecification are reported in Section 3. A real example is analyzed in Section 4. All of the proofs are given in Appendix.
2. ET for stationary time series
In this section, first, we derive the asymptotic distributions of the ET and AET likelihood ratio statistics for constructing confidence regions. Second, we derive the first-order asymptotic properties for the point estimates under the model misspecification. To deduce the formulation of likelihood ratio, we start from introducing the moment estimating functions obtained from the Whittle likelihood (Whittle, Citation1953).
2.1. Exponential titled likelihood of β
The stationary autoregressive fractionally integrated moving-average (ARFIMA(p, d, q)) models (Granger & Joyeux, Citation1980; Hosking, Citation1981) and autoregressive moving-average (ARMA(p, q)) models (d) (Brillinger, Citation1981) are defined as
where d is called memory parameter. If d = 0, the model is short memory, otherwise, it is long -memory. B is the backward operator satisfying
;
and
are operator polynomials of B; their corresponding equations have no common roots and all of their roots lie outside the unit circle to ensure the processes are stationary; and
is the white noise with mean zero and unknown variance
often treated as a nuisance parameter, where we profile
out of the Whittle likelihood function. Then by taking derivative of the Whittle likelihood with respect to our interesting parameters
, the moment estimating equations are obtained as
where the spectral density
and the periodogram
where
and
is the mean of realization
,
.
The nonparametric ET likelihood ratio is depicted as the divergence from mass to empirical frequency
subject to some restrictions. More specifically, for parameter vector β, the ET log-likelihood is defined by
For a given β, if the convex hull
contains 0, by the Lagrange multiplier method, the
's can be closely expressed as
where the Lagrange multiplier
is the solution to
(1)
(1) Then ET log-likelihood ratio statistic is
(2)
(2) We assert that the asymptotical property of the likelihood ratio
follows the result of EL (Nordman & Lahiri, Citation2006), i.e.
Theorem 2.1
If is the true parameter value, under the assumptions of A1–A4 (Nordman & Lahiri, Citation2006), we have
where k is the dimension of the unknown parameter vector β and
means convergence in distribution.
Accordingly, the ET-based confidence region for β can be constructed as
where
is the
quantile of chi-square distribution with k degree of freedom.
2.2. Adjusted exponential titled likelihood of β
Similar to EL, the ET likelihood ratio will not be well defined when the origin lies outside the convex hull . To completely eliminate this dilemma, we develop the AET to ensure the existence of the definition and to reduce the coverage errors partly resulted from the non-definition. The key of AET is also to add a pseudo-observation
to the original set
, where we let the adjustment level
proposed by Chen et al. (Citation2008). Then adjusted ET log-likelihood ratio under the new data set is defined by
(3)
(3) where
and
is determined by
(4)
(4) Piyadi Gamage et al. (Citation2017a, Citation2017b) showed that the AEL statistics also follow
asymptotically at the true value
for short- and long-memory time series. We assert that this result also holds for AET likelihood ratio.
Theorem 2.2
Under the same assumptions as those in Theorem 1, we have
Then, the AET-based confidence regions can be directly constructed as
whose coverage error is smaller than that of ET in theory. In the next section, we will use simulations to verify such finite-sample properties of ET- and AET-based confidence regions.
2.3. ET estimates for autoregressive coefficient of AR(1)
As stated in introduction, when the number of estimating equations is larger than that of the unknown parameters, the ET point estimate is more robust than the EL counterpart. Here, we consider the autoregressive coefficient of AR(1). To obtain the over-identified estimating equations, we derive the estimating functions from the autocorrelation function equations of AR(1)
In order to match the uniformity, we note the estimating functions as
where
; then the ET estimator
of β can be obtained by
The empirical discrepancy for ET is
Then the pseudo-true value
can be obtained by maximizing
with respect to β, where
is the unique solution to equation
(which is because the function
is strictly convex in λ). We assert that the first-order asymptotical property of ET estimator
also holds for the misspecified moment models in stationary AR(1).
Assumption 2.1
The function
can attain its maximum at a unique pseudo-true value
There is a function
These conditions contained in Assumption 1 are regular under model misspecification. Then the asymptotic theories can be stated as follows.
Theorem 2.3
Under Assumptions 2.1, we have
Let
The result in Theorem 2.3(i) indicates that the consistency of ET estimate holds but there is not a convergence rate because of the misspecified moment model.
3. Numerical studies
In this section, we carry out Monte Carlo simulations to study the ET-based confidence regions of parameters in terms of coverage probability and investigate the performance of the ET point estimate under the situation of the misspecified models.
3.1. Coverage accuracy
For verifying the adjustment technique improves the coverage accuracy, we investigate ET- and AET-based coverage accuracy by studying six stationary ARFIMA(p, d, q) processes with four innovations, including standard normal, student t, chi-square and exponential noises with means zero. In all cases, 5000 replications are generated to evaluate the coverage properties under series length T = 100, 200, 300, respectively. In fact the sample size is though the length of the original time series
is T. Significant level is
.
The simulation results are reported in Tables . We find that
Table 1. Coverage probabilities for ARMA(1,1) models.
Table 2. Coverage probabilities for ARFIMA(1,d,0) models.
Table 3. Coverage probabilities for ARFIMA(2,d,0) models.
Table 4. Coverage probabilities for ARFIMA(0,d,1) models.
Table 5. Coverage probabilities for ARFIMA(0,d,2) models.
Table 6. Coverage probabilities for ARFIMA(1,d,1) models.
With the increasing sample size, the coverage probabilities of both ET and AET get close to the nominal coverage level.
Under the same sample size, the AET outperforms the ET in view of coverage probability for all cases. When the sample size is relatively small, the AET often substantially improves the coverage probabilities but the improvement is not quite obvious when the sample size gets larger.
The less the unknown parameters are, the larger the coverage probabilities are for both ET and AET.
3.2. Point estimates under moment model misspecification
In this section, we only investigate the performance of ET point estimate under model misspecification because the adjustment technique barely affects ET point estimate. That is, there is no difference between AET point estimate and ET point estimate. To highlight the robustness of the ET estimate, we compare it with EL and ETEL.
The over-identified moment model arises naturally for the autocorrelation coefficient. In our simulations, we set and k = 2. The correct and misspecified estimating functions are, respectively, defined as
Note that in this experiment, we set
, then the periodograms
are asymptotically exponential distributed, which makes the estimating functions unbounded. Therefore, the comparison of ET with EL and ETEL is meaningful.
Table exhibits the biases, SDs, and root mean square errors (RMSEs) of point estimates of ϕ with true values . For all cases, we evaluate with 5000 replications under series length
50, 100, 200, 500, respectively.
Table 7. Performance of point estimates of the autoregression parameter ϕ in AR(1) under model misspecification.
From the simulation results in Table , we observe that
When the moment functions are correctly specified, there is little difference among the three methods for all cases.
As expected, when model is misspecified, the ET estimate is shown to be more robust than the other two kinds of estimates, that is, the SDs of ET are always less than those of the other two methods. So do the RMSEs.
For the case of
For all cases, both the SDs and RMSEs decrease with the increasing series length.
3.3. A real example
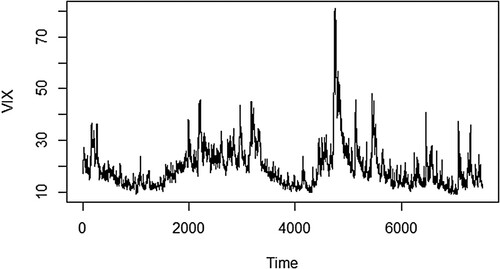
In this section, we take S&P 500 VIX as an example to investigate the performance of our proposed method. VIX is a real-time index also known as Fear Index derived from the price inputs of option. As a forward looking index, it represents the market's expectations for volatility over the coming 30 days. It is a measurement for investors to make investment decision by the level of market risk, fear or stress because there is a strong negative correlation between volatility and the stock market returns demonstrated by historical data. It is also useful for traders to price its derivatives by VIX values. Moreover, if it is extended to the price observations of the broader market level index, such as the S&P 500 index, we will get a peek into volatility of the larger market. Hence, for comparing the possible price moves and the risk easily, it is meaningful to find a standard quantitative measure for volatility. The data are collected from 2/1/1990 to 21/11/2019 and available from https://finance.yahoo.com/quote/%5EVIX/history?p=%5EVIX. The VIX series trajectory is shown in Figure . By the autocorrelation test, we find that the series is stationary and with long-memory.
Figure 1. The SP 500 VIX series.
Our aim of this study is to verify the validity of our proposed ET method for constructing confidence region. When we use an ARFIMA(1, d,0) model with parameter to fit the data, the ET point estimates of parameters listed in Table do not change the original characteristics of the data even the moment model may be misspecified and just-identified. However, the EL and ETEL estimates of
violate the stationary and long memory properties of this series. This is consistent of the theory we stated in Section 2.3; ET method is more superior in the case of model misspecification than the EL and ETEL method. The data-driven AET-based confidence region is depicted in Figure .
Figure 2. 95% confidence region of the parameters for fitted ARFIMA(1,d,0) of the S&P 500 VIX series.
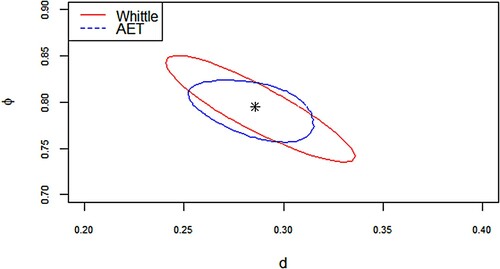
Table 8. Point estimates of the parameter vector by the three methods.
4. Conclusion
In this paper, we propose ET method to infer the spectral parameters in stationary time series models. By comparing the coverage probabilities, we find that the adjusted technique also plays the best utility while enhancing computational efficiency and estimation accuracy for ET, which illustrates that the adjustment technique is useful and not limited to EL. Moreover, in view of point estimate, we highlight that the ET method outperforms EL and ETEL methods under the misspecified over-identified moment models. And the superiority of our proposed method is verified in numerical studies.
It is interesting to develop the other corrected ET to make the based coverage regions more accurate under the small sample size case. One possible way may be modifying the adjustment procedure. It can be carried out through adding two or more pseudo samples, which makes the solution of estimating equations exist and further improves the under-coverage. Another possible improvement may be realized by obtaining the estimating functions from other ways such as de-biased Whittle likelihood or tapered periodogram which make estimate of the parameter with a smaller bias. Another direction of our future study is extending the ET method in stationary time series model with time-varying variances, which is motivated by recent work of Han and Zhang (Citation2021).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Brillinger, D. R. (1981). Time series: Data analysis and theory. Holden-Day.
- Caner, M. (2010). Exponential tilting with weak instruments: Estimation and testing. Oxford Bulletin of Economics and Statistics, 72(3), 307–325. https://doi.org/10.1111/obes.2010.72.issue-3
- Chan, N. H., & Liu, L. (2010). Bartlett correctability of empirical likelihood in time series. Journal of the Japan Statistical Society, 40(2), 221–238. https://doi.org/10.14490/jjss.40.221
- Chen, J. H., Variyath, A. M., & Abraham, B. (2008). Adjusted empirical likelihood and its properties. Journal of Computational and Graphical Statistics, 17(2), 426–443. https://doi.org/10.1198/106186008X321068
- DiCiccio, T., Hall, P., & Romano, J. (1991). Empirical likelihood is Bartlett correctable. The Annals of Statistics, 19(2), 1053–1061. https://doi.org/10.1214/aos/1176348137
- Granger, C. W. J., & Joyeux, R. (1980). An introduction to long-memory time series models and fractional differencing. Journal of Time Series Analysis, 1(1), 15–29. https://doi.org/10.1111/j.1467-9892.1980.tb00297.x
- Han, Y., & Zhang, C. M. (2021). Empirical likelihood inference in autoregressive models with time-varying variances. Statistical Theory and Related Fields. https://doi.org/10.1080/24754269.2021.1913977
- Hosking, J. R. M. (1981). Fractional differencing. Biometrika, 68(1), 165–176. https://doi.org/10.1093/biomet/68.1.165
- Imbens, G. W. (2002). Generalized method of moments and empirical likelihood. Journal of Business and Economic Statistics, 20(4), 493–506. https://doi.org/10.1198/073500102288618630
- Imbens, G. W., Spady, R. H., & Johnson, P. (1998). Information-theoretic approaches to inference in moment condition models. Econometrica, 66(2), 333–357. https://doi.org/10.2307/2998561
- Jing, B. Y., & Andrew, T. A. (1996). Exponential empirical likelihood is not Bartlett correctable. The Annals of Statistics, 24(1), 365–369. https://doi.org/10.1214/aos/1033066214
- Kitamura, Y. (1997). Empirical likelihood methods with weakly dependent processes. The Annals of Statistics, 25(5), 2084–2102. https://doi.org/10.1214/aos/1069362388
- Kitamura, Y. (2000). Comparing misspecified dynamic econometric models using nonparametric likelihood. Department of Economics, University of Wisconsin.
- Kitamura, Y., & Stutzer, M. (1997). An information-theoretic alternative to generalized method of moments estimation. Econometrica, 65(4), 861–874. https://doi.org/10.2307/2171942
- Liu, Y. K., & Chen, J. H. (2010). Adjusted empirical likelihood with high-order precision. The Annals of Statistics, 38(3), 1341–1362. https://doi.org/10.1214/09-aos750
- Monti, A. C. (1997). Empirical likelihood confidence regions in time series models. Biometrika, 84(2), 395–405. https://doi.org/10.1093/biomet/84.2.395
- Newey, W. K., & McFadden, D. (1994). Large sample estimation and hypothesis testing (4th ed.). North-Holland, pp. 2111–2245.
- Newey, W. K., & Smith, R. J. (2004). Higher order properties of GMM and generalized empirical likelihood estimators. Econometrica, 72(1), 219–255. https://doi.org/10.1111/ecta.2004.72.issue-1
- Nordman, D. J., & Lahiri, S. N. (2006). A frequency domain empirical likelihood for short- and long-range dependence. The Annals of Statistics, 34(6), 3019–3050. https://doi.org/10.1214/009053606000000902
- Nordman, D. J., & Lahiri, S. N. (2014). A review of empirical likelihood methods for time series. Journal of Statistical Planning and Inference, 155, 1–18. https://doi.org/10.1016/j.jspi.2013.10.001
- Owen, A. B. (1988). Empirical likelihood ratio confidence intervals for a single functional. Biometrika, 75(2), 237–249. https://doi.org/10.1093/biomet/75.2.237
- Owen, A. B. (1990). Empirical likelihood ratio confidence regions. The Annals of Statistics, 18(1), 90–120. https://doi.org/10.1214/aos/1176347494
- Owen, A. B. (2001). Empirical likelihood. Chapman & Hall.
- R. D. Piyadi Gamage, Ning, W., & Gupta, A. K. (2017a). Adjusted empirical likelihood for long-memory time series models. Journal of Statistical Theory and Practice, 11(1), 220–233. https://doi.org/10.1080/15598608.2016.1271373
- Piyadi Gamage, R. D., Ning, W., & Gupta, A. K. (2017b). Adjusted empirical likelihood for time series models. Sankhya series B, 79(2), 336–360. https://doi.org/10.1007/s13571-017-0137-y
- Schennach, S. M. (2005). Bayesian exponentially tilted empirical likelihood. Biometrika, 92(1), 31–46. https://doi.org/10.1093/biomet/92.1.31
- Schennach, S. M. (2007). Point estimation with exponentially tilted empirical likelihood. The Annals of Statistics, 35(2), 634–672. https://doi.org/10.1214/009053606000001208
- Tang, N. S., Yan, X. D., & Zhao, P. Y. (2018). Exponentially tilted likelihood inference on growing dimensional unconditional moment models. Journal of Econometrics, 202(1), 57–74. https://doi.org/10.1016/j.jeconom.2017.08.018
- Whittle, P. (1953). Estimation and information in stationary time series. Arkiv för Matematik, 2(5), 423–434. https://doi.org/10.1007/BF02590998
- Yau, C. Y. (2012). Empirical likelihood in long-memory time series models. Journal of Time Series Analysis, 33(2), 269–275. https://doi.org/10.1111/jtsa.2012.33.issue-2
- Zhu, H., Zhou, H., Chen, J., Li, Y., Lieberman, J., & Styner, M. (2009). Adjusted exponentially tilted likelihood with applications to brain morphology. Biometrics, 65(3), 919–927. https://doi.org/10.1111/j.1541-0420.2008.01124.x
Appendix
In this section, we give the brief proof of the main results. To simplify the notation in all of the proofs, we introduce some notes. Let ,
,
,
,
,
, the equalities evaluate at point
with superscript
.
Proof of Theorem 2.1.
Note , then
. In fact,
By dominated convergence theorem, we have
when
and
. By the Theorem 3 of Newey and Smith (Citation2004), we immediately have
. Next we will show that
converges to a chi-square distribution. Note
, then by Taylor expansion,
Then,
where λ satisfies Eq. (Equation1
(1)
(1) ). By Taylor expansion of Eq. (Equation1
(1)
(1) ), we have
(A1)
(A1) In fact, because Whittle estimate
satisfies
, then
Substituting
and
in λ, we have
Then substituting
and
into
, by Lemma 6 of Nordman and Lahiri (Citation2006), we have
which converges to the chi-square distribution with degree k of freedom.
Proof of Theorem 2.2.
By the proof of Theorem 2.1 and Eq. (Equation4(4)
(4) ), we have
where
. Thus, we have
Similar to the proof of Theorem 2.1, because
, we expand
as
Then
in distribution.
For proving Theorem 2.3, we require the additional lemma stated as follows. By introducing the additional parameters, the construction of the equations is equivalent to that of the just-identified GMM procedure (Schennach, Citation2007).
Lemma A.1
Let be the ET estimator of
where
with
. Then,
is the solution to
where
Proof of Lemma A.1.
It is obvious that holds by its definition and λ satisfies the equation
. Because
minimizes the likelihood ratio
, then the first-order condition for β can be expressed by equation
, that is,
. Then we complete the proof.
Proof of Theorem 2.3.
In this proof, all the elements with superscript mean the values corresponding to pseudo-true value
. The proof of Theorem 2.3(i) is completely similar to the proof of Theorem 10 (Schennach, Citation2007), hence is omitted. For proving 2.3(ii), we restrict our attention to the just-identified equations of Lemma A.1. Applying Theorem 3.4 of Newey and McFadden (Citation1994), we only need to show that
Since then ψ, Ψ and V represent the elements of ,
and
, respectively. All of the components of the matrix
take the form of
for
and
, where α represents the products of elements of θ which are bounded for
. Then by Assumption 2.1, we have
This is because . Similarly, the elements of matrix
take the form of
with
and
. Hence, the similar procedure implies (II).