
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With the development of modern science and technology, more and more high-dimensional data appear in the application fields. Since the high dimension can potentially increase the complexity of the covariance structure, comparing the covariance matrices among populations is strongly motivated in high-dimensional data analysis. In this article, we consider the proportionality test of two high-dimensional covariance matrices, where the data dimension is potentially much larger than the sample sizes, or even larger than the squares of the sample sizes. We devise a novel high-dimensional spatial rank test that has much-improved power than many existing popular tests, especially for the data generated from some heavy-tailed distributions. The asymptotic normality of the proposed test statistics is established under the family of elliptically symmetric distributions, which is a more general distribution family than the normal distribution family, including numerous commonly used heavy-tailed distributions. Extensive numerical experiments demonstrate the superiority of the proposed test in terms of both empirical size and power. Then, a real data analysis demonstrates the practicability of the proposed test for high-dimensional gene expression data.
1. Introduction
High-dimensional data are nowadays more and more common in bioinformatics, material science, astronomy and other application fields, as data collection technology rapidly evolves (Bühlmann & van de Geer, Citation2011). However, due to limited resources available to replicate observations, the sample sizes are usually much smaller than the dimension, which makes most traditional statistical approaches no longer appropriate. Under such an embarrassing background, scientists in many application fields urgently need powerful approaches to gather the greatest scientific insight from data. Testing equality of the distributions of two populations is a crucial problem in high-dimensional statistics, which is extremely complex and far more challenging than that for fixed-dimensional data. Due to this extreme complexity, it is usually replaced by a simpler problem, i.e. testing equality of some numerical characteristics, such as means and covariances, of the two populations, which is very useful but much easier to implement.
There is already a large number of literature on detecting the difference between the means of two high-dimensional populations, such as Bai and Saranadasa (Citation1996), Chen and Qinm (Citation2010), and Feng et al. (Citation2016), to name just a few. In contrast, there are much fewer studies on high-dimensional covariance matrix test of two high-dimensional populations. Hence, in this article, we focus on comparing the covariance matrices among two populations, which is strongly motivated for high-dimensional data, as high data dimensions can potentially increase the complexity of the covariance structure (Li & Chen, Citation2012). In particular, we consider the testing problem of the proportionality of two high-dimensional covariance matrices, which investigates the simplest heteroscedasticity of the population covariance matrices (Xu et al., Citation2014). It is often a preparation procedure before the case–control analysis of genomic data. Let and
be two p-dimensional populations with the mean vectors
,
and the covariance matrices
,
, respectively. The proportionality test of two population covariance matrices is formulated as follows:
(1)
(1) where c is an unknown scalar.
The proportionality testing problem in (Equation1(1)
(1) ) has been widely studied in various areas, such as in discriminant analysis and principal component analysis (Flury & Riedwyl, Citation1988; Schott, Citation1991), and there is a lot of early literature on its methodological researches, such as Eriksen (Citation1987), Federer (Citation1951), Flury (Citation1986), Kim (Citation1971), Rao (Citation1983), and Schott (Citation1999). For example, the most traditional test statistic is
where
are obtained by an iterative algorithm proposed in Flury (Citation1986) and
are the corresponding sample covariance matrices, respectively. These researches are constructed based on the classical limit theorems, assuming that the sample sizes tend to infinity and the dimension is fixed, hence have difficulties to analyse the high-dimensional data, where the dimension is much larger than the sample sizes. To alleviate such difficulties, Xu et al. (Citation2014) proposed to use a pseudo-likelihood ratio test by extending the traditional likelihood ratio test with the statistic
which allows the dimension to increase proportionally with each sample size; furthermore, Liu et al. (Citation2014) proposed an improved method, which allows the dimension to be larger than one of the sample sizes. In addition, for the special case of
in (Equation1
(1)
(1) ), Li and Chen (Citation2012) proposed a test statistic
where
As mentioned in Li and Chen (Citation2012),
is an unbiased estimation of
. Despite some progress, there are also drawbacks: first, these methods may have extremely poor performance for heavy-tailed distributions; second, the sample covariance matrices, which need to be inverted in the construction of the test statistic, are singular when the dimension is larger than both of the sample sizes.
To overcome these two drawbacks, more attention has been paid to nonparametric testing methods based on the multivariate sign or rank. Just recently, for testing the proportionality of two high-dimensional covariance matrices, Cheng et al. (Citation2018) proposed to use a test procedure based on the multivariate sign and demonstrated its good performance in high-dimensional data analysis, especially for the heavy-tailed distributions. Recall that for fixed-dimensional data, the multivariate sign and rank are widely used to construct robust tests (Oja, Citation2010). However, most of these tests cannot be effective for high-dimensional data. Therefore, many researches extend the traditional multivariate sign- or rank-based testing methods to the high-dimension data, such as Feng and Sun (Citation2016) and Wang et al. (Citation2015) for one-sample problems; Feng et al. (Citation2016) for two-sample problems; Feng and Liu (Citation2017) and Zou et al. (Citation2014) for sphericity testing problems. These researches clearly demonstrate the advantages of the high-dimensional multivariate sign- or rank-based methods in high-dimensional and heavy-tailed cases.
Unfortunately, due to the bias caused by estimating the location parameters, the test procedure based on the multivariate sign can only allow the dimension to be the squares of the sample sizes at most (Cheng et al., Citation2018), which makes the test procedure too restrictive for various practical applications, hence greatly affects the validity of the test procedure. For example, in genomic data analysis, genomic data typically carry thousands of dimensions for measurements on the genome, where the dimension can be much larger than the squares of the sample sizes. Therefore, it is very urgent to develop a new method to deal with the proportionality testing problem in (Equation1(1)
(1) ) for the high-dimensional data, where the dimension is much higher than the squares of the sample sizes. This is the motivation and intention of this article.
The rest of the article is organized as follows. In Section 2, we introduce the proposed high-dimensional spatial rank test and establish its asymptotic normality under the elliptically symmetric populations. Then, we demonstrate the numerical performance of the proposed test in Sections 3, followed by a real data analysis in Section 4. Finally, we conclude this article in Section 5 and relegate the technical proofs to Appendix.
2. Method
2.1. The proposed test
A p-dimensional random vector is said to follow an elliptically symmetric distribution, denoted by
, if it has the following stochastic representation:
where
is the p-dimensional mean vector, ξ is a non-negative random variable,
is the cumulative distribution function of ξ,
is independent of ξ and is uniformly distributed on the unit sphere
and
is a deterministic
-dimensional matrix satisfying
with
. It is known that the covariance matrix
and shape matrix
of the elliptical symmetric population
will satisfy the equation
.
Let and
denote the samples of two p-dimensional random vectors
and
, which are generated from the two independent elliptically symmetric populations
and
, respectively. From Section 3.1 in Magyar and Tyler (Citation2014), it is known that
and
have the same eigenvectors for each
under the assumption of elliptically symmetric distribution. Also, from Equation 3.9 in Magyar and Tyler (Citation2014), it is known that when the eigenvalues of the covariance matrices
and
are proportional, the spatial sign covariance matrices
and
have the same eigenvalues. Theorem 1 in Cheng et al. (Citation2018) showed that when
and
have the same eigenvalues, the eigenvalues of
and
are proportional. Hence, the hypotheses in (Equation1
(1)
(1) ) are equivalent to the following hypotheses:
(2)
(2) where
,
are the spatial sign covariance matrices of
,
, respectively, and
for each
is the spatial sign function with
denoting the
-norm and
denoting the indicator function. On this ground, Cheng et al. (Citation2018) suggested to use a test statistics based on the square Frobenius norm of
, i.e.
.
The proposed spatial rank test in this article is also based on the square Frobenius norm of , which is a high-dimensional extension of Kendall's tau test for the hypotheses in (Equation2
(2)
(2) ) (Oja, Citation2010). Specifically, the test statistic is
(3)
(3) where
denotes summation over distinct indexes
or
. Note that recently many developed versions of Kendall's tau test are frequently used on many related issues (Barber & Kolar, Citation2018; Cai & Zhang, Citation2016; Han et al., Citation2017; Leung & Drton, Citation2018).
In deriving the asymptotic properties of , we impose the following two conditions used in Cheng et al. (Citation2018):
as
Note that: (1) Condition (C1) is a commonly used condition in high-dimensional two sample testing problems; (2) Condition (C2) is similar to Condition (A2) in Li and Chen (Citation2012); (3) If all the eigenvalues of and
are bounded, Condition (C2) holds.
Remark 2.1
Note that the above Conditions (C1) and (C2) do not contain any restriction on p and ,
, since such restriction is not needed to control the following terms:
which have been removed from
. That is to say, we remove all the items that include at least one pair of identical vectors, such as
,
and so on. Such type of strategy was previously used in Chen and Qinm (Citation2010). By removing the terms
and
from the test statistic proposed by Chen and Qinm (Citation2010), no restriction on p,
and
is needed.
Under the above two conditions, the limiting null distribution of is given in the following theorem.
Theorem 2.1
Under Conditions (C1), (C2) and , as
,
,
,
where
with
.
Moreover, we obtain the limiting distribution of under
.
Theorem 2.2
Under Conditions (C1), (C2) and , as
,
,
,
where
Due to the fact that for l = 1, 2 obtained by Cheng et al. (Citation2018), we propose to use the following estimator of
:
where
As presented by the following proposition,
is a consistent estimator of
under
.
Proposition 2.1
Under Conditions (C1), (C2) and ,
.
Therefore, the proposed test with a nominal α level of significance rejects if
, where
is the upper α-quantile of
. The asymptotic power function of
is
where
denotes the cumulative probability function of
.
2.2. Relationship with the test proposed in Cheng et al. (Citation2018)
The proposed spatial rank test seems to be more complex than the existing ones, such as the spatial sign test proposed by Cheng et al. (Citation2018). This is a price that we have to pay for making the proposed method powerful in testing the high-dimensional data, where the data dimension is potentially much larger than the squares of the sample sizes, especially for the data generated from heavy-tailed distributions. Below we will explain the motivation of the proposed method in detail.
First, we recall Lemma B.1 in Han and Liu (Citation2018).
Lemma 2.3
Let ,
, where
and
are independent, then
By Lemma 2.3, we have that
for each
with
, where
is the so-called population multivariate Kendall's tau matrix of
(Oja, Citation2010). Similarly,
for each
with
, where
is the population multivariate Kendall's tau matrix of
. Lemma 2.3 suggests that for each of the two populations, the population multivariate Kendall's tau matrix is the same as the spatial sign covariance matrix. As a result, testing equality of the two spatial sign covariance matrices is identical to testing equality of the two population multivariate Kendall's tau matrices.
Moreover, it can be seen that the three components of the Frobenius norm of the difference between and
,
, have the following equivalent representations:
for each
, where i, j, k, l are not equal to each other;
for each
, where i, j, k, l are not equal to each other;
for each
with
and each
with
. These representations finally enlighten us to construct
as that in the above subsection, which is actually a consistent estimator of
.
Unlike the spatial sign covariance matrix, to estimate the multivariate Kendall's tau matrix, it is not necessary to estimate the spatial medians, whose estimators may bring a bias hence strengthens the condition imposed on the dimension p. That is the reason why we propose to use a new test procedure based on the multivariate Kendall's tau matrix rather than the spatial sign covariance matrix. Therefore, the condition imposed on the dimension p can be released to some extent, which makes the proposed test procedure powerful in high-dimensional data, even with the dimension much larger than the sample sizes.
In fact, in the spatial sign test proposed by Cheng et al. (Citation2018), to test the equality of the two spatial sign covariance matrices and
, the test statistic is
where
and
for
,
. Here,
and
are the spatial median estimators of
and
, respectively, obtained by using the estimation method proposed in Mottonen and Oja (Citation1995).
is an estimator of
, but unfortunately
, due to the spatial median estimators
and
(see Lemma 2 in Cheng et al., Citation2018). To obtain a consistent estimator of the bias
, the condition
was imposed in Cheng et al. (Citation2018), which limits the application of
for the high-dimensional data where the dimension is much larger than the squares of sample sizes.
3. Simulation study
In this section, we will present some numerical results to demonstrate the performance of the proposed test (abbreviated as HT) in high-dimensional cases, in comparison with two existing popular tests, the test proposed by Li and Chen (Citation2012) (abbreviated as LZ) and the spatial sign test proposed by Cheng et al. (Citation2018) (abbreviated as SS). The following three scenarios are considered.
Multivariate normal distribution:
Multivariate t-distribution:
Multivariate mixture normal distribution:
For all the above scenarios, let and
with
, 0.6, 0.7. Then,
corresponds to the situation where the null hypothesis is true, while
or 0.7 corresponds to the situation where the alternative hypothesis is true. Note that all the following simulation results are obtained based on 1000 replications.
First, to observe the influence of the dimension p to the potential bias of the methods involved, we summarize the results of the mean-standard deviation-ratio and the variance estimator ratio
under the null hypothesis in Table for each
with
and p = 100, 200, 400, 800, 1200, where
is the test statistic proposed in Li and Chen (Citation2012). Since the exact value of
and
are difficult to calculate, we replace them with their Monte-Carlo estimators respectively, using 1000 repeated samplings.
Table 1. Comparison of the mean-standard deviation-ratio and the variance estimator ratio at the 5% level with and p = 100, 200, 400, 800, 1200.
Table indicates that SS has worse mean-standard deviation-ratio results than the other two methods in high-dimensional situations, particularly when . This is most likely due to the fact that in
the bias correction process is limited by the condition that
. On the other hand, suggested by the variance estimator ratio results of Table , the estimated variances of LZ are eventually larger than the real ones, particularly in non-normal situations. In contrast, HT has better performance in these two aspects.
Then, we will compare the performance of the three methods in empirical size and empirical power. Let , 20, 30 and p = 100, 200, 400, 800, 1200. Tables summarize the empirical size and power results of the three methods. First, the empirical size results in Tables , corresponding to the setting of
, suggest that LZ fails to control the empirical size in the non-normal cases. Moreover, when comparing HT with SS, we find that their performance is very similar, except in the cases where the dimension is comparable to or larger than the squares of the sample sizes, i.e.
. In such cases, SS may lose control of the empirical size, which is consistent with the conclusion made by analysing Table . In the above results about the empirical size, in a few cases, the empirical size is slightly larger than 5%, but still within a reasonable range. To comprehensively compare the empirical size and power of the three tests, in Figure , we present the receiver operating characteristic curves (ROCs) for the three tests with
. Suggested by Figure , these tests have similar performance under the multivariate normal distributions, while under the remaining heavy-tailed distributions, the area under ROC (AUC) of the proposed HT test is larger than the AUCs of its competitors. This further demonstrates the advantages of the proposed test.
Figure 1. ROC curves of the involved tests under the three scenarios with .
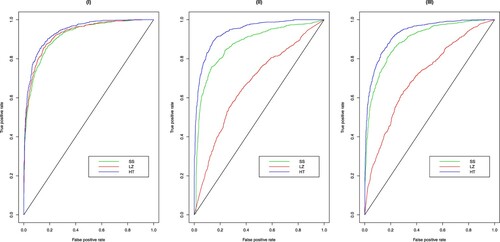
Table 2. Empirical size and power comparison at the 5% level with and p = 100, 200, 400, 800, 1200.
Table 3. Empirical size and power comparison at the 5% level with and p = 100, 200, 400, 800, 1200.
Table 4. Empirical size and power comparison at the 5% level with and p = 100, 200, 400, 800, 1200.
Next, we consider an alternative structure of the covariance matrices, i.e. for each
, where
for each
and the remaining entries of
are all zeros. Note that
is the corresponding covariance matrix of
following the MA
model:
where
's are i.i.d. random variables with mean zero and variance
. Under the null hypothesis, we set
, while under the alternative hypothesis, we set
and
for instance. The other settings are all the same as the above. Tables and report the empirical sizes and power of these three methods, respectively. Although Table suggests that the performance of empirical power of the three methods is similar, Table suggests that the abilities of LZ and SS to control the empirical size are weakening much more quickly than HT with the increase of p for fixed
and
, especially when the dimension is comparable to or larger than the squares of the sample sizes.
Table 5. Empirical size comparison at the 5% level with the MA(2) covariance matrices with , 20, 30 and p = 100, 200, 400, 800, 1200.
Table 6. Empirical power comparison at the 5% level with the MA(2) covariance matrices with , 20, 30 and p = 100, 200, 400, 800, 1200.
Overall, the comprehensive numerical results suggest that the proposed HT test has obvious advantages in terms of controlling empirical size over the existing two methods. Such gain is especially clear when the original distribution deviates from normality, and when the dimension is larger than the squares of sample sizes.
4. Application
In this section, we apply the proposed testing method to a gene dataset, which contains the expression of the 2000 genes with the highest minimal intensity across the 62 tissues. Each entry in the dataset is a gene intensity derived using the filtering process proposed in Alon et al. (Citation1999). The dataset was previously studied by Alon et al. (Citation1999), and now can be freely downloaded at the following website: http://genomics-pubs.princeton.edu/oncology/affydata/index.html.
Among the 62 tissues, there are 22 normal tissues and 40 tumour colon tissues. We aim to test the hypothesis that the tissues in the tumour group and those in the normal group have the proportional covariance matrices in terms of the expression levels of the 2000 genes, where the dimension 2000 is larger than the squares of the sample sizes, 484 and 1600.
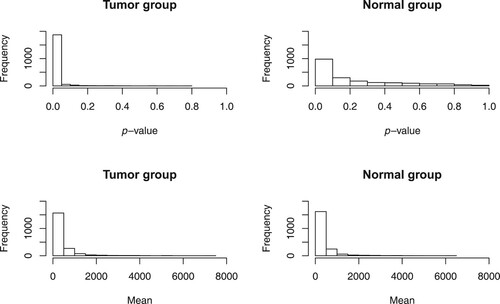
First, the normal distribution was tested for the expression data of each gene, using the Shapiro–Wilk test. The top two panels of Figure present the histograms of the p-values of the normality tests for the tumour group and the normal group, respectively, which indicate that for a large number of genes the expression data are non-normal. In fact, under the significance level of 0.05, the overall rejection rates of all the normality tests are and
for the tumour group and the normal group, respectively. This motivates us to use a nonparametric approach for testing the above hypothesis, which can deal with the high-dimensional data from non-normal distributions.
The bottom two panels of Figure indicate that there exist some genes with very high values of sample mean in terms of expression. We see that the sample means vary largely for each of the two groups and recall that the dimension is larger than the squares of the sample sizes, which raises a concern that using a spatial sign-based approach may lead to an uncontrollable bias. Hence, in theory, a spatial rank-based approach is more appropriate for this dataset.
Figure 2. Histograms of the p-values of the normality tests and the gene expression means, for the tumour group and the normal group, respectively.
Based on the above reasons, we apply the proposed HT test to this dataset. The test statistic and p-value of the HT test are 4.823 and respectively, hence the null hypothesis is rejected, which suggests that the covariance matrix of the gene expression levels of the tumour group is significantly not proportional to that of the normal group. This result can also be intuitively verified by comparing the sample correlation matrices of the two groups. As a convenience and for demonstration purposes, in , we only plot the heatmaps of the sample correlation matrices of the two groups as well as the difference of the two matrices using the first 100 genes in the original data. The heatmaps demonstrate that there are some intuitive differences between the two sample correlation matrices, which tends to support our result of rejecting the null hypothesis.
Figure 3. Heatmaps of the sample correlation matrices of the two groups as well as the difference of the two matrices, which are constructed via the first 100 genes in the original data. (a) Normal group, (b) tumour group and (c) difference of two groups.

5. Conclusion
We have proposed the HT test, a new high-dimensional spatial rank test, for the proportionality testing problem of two high-dimensional covariance matrices, which is a high-dimensional extension of Kendall's tau test. It inherits the robustness advantage of the traditional spatial rank-based methods, and also has strong potential in dealing with the high-dimensional data, where the dimension can be potentially much larger than the squares of the sample sizes. We establish the asymptotic distributions of the proposed method rigorously. In comparison with some existing test procedures, the gain in empirical power and empirical size of HT is especially clear in high-dimensional and heavy-tailed data, shown by many numerical evidence. The real data analysis shows the applicability and pertinence of the proposed method to high-dimensional gene expression data.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alon, U., Barkai, N., Notterman, D. A., Gish, K., Ybarra, S., & Levine, D. M. J. (1999). Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proceedings of the National Academy of Sciences of the United States of America, 96(12), 6745–6750. https://doi.org/https://doi.org/10.1073/pnas.96.12.6745
- Bai, Z., & Saranadasa, H. (1996). Effect of high dimension: By an example of a two sample problem. Statistica Sinica, 6(2), 311–329.
- Barber, R. F., & Kolar, M. (2018). Rocket: Robust confidence intervals via Kendall's tau for transelliptical graphical models. The Annals of Statistics, 46(6B), 3422–3450. https://doi.org/https://doi.org/10.1214/17-AOS1663
- Bühlmann, P, & van de Geer, S. (2011). Statistics for High-dimensional Data: Methods, Theory and Applications (1st ed.). Springer Publishing Company, Incorporated.
- Cai, T. T., & Zhang, A. (2016). Inference for high-dimensional differential correlation matrices. Journal of Multivariate Analysis, 143(6009), 107–126. https://doi.org/https://doi.org/10.1016/j.jmva.2015.08.019
- Chen, S. X., & Qinm, Y. L. (2010). A two-sample test for high-dimensional data with applications to gene-set testing. Annals of Statistics, 38(2), 808–835.https://doi.org/https://doi.org/10.1214/09-AOS716
- Cheng, G., Liu, B., Peng, L., Zhang, B., & Zheng, S. (2018). Testing the equality of two high-dimensional spatial sign covariance matrices. Scandinavian Journal of Statistics, 46(1), 257–271. https://doi.org/https://doi.org/10.1111/sjos.v46.1
- Eriksen, P. S. (1987). Proportionality of covariance matrices. Annals of Statistics, 15(2), 732–748. https://doi.org/https://doi.org/10.1214/aos/1176350372
- Fang, K. T., Kotz, S., & Ng, K. W. (1990). Symmetric Multivariate and Related Distributions. Chapman and Hall.
- Federer, W. T. (1951). Testing proportionality of covariance matrices. Annals of Mathematical Statistics, 22(1), 102–106. https://doi.org/https://doi.org/10.1214/aoms/1177729697
- Feng, L., & Liu, B. (2017). High-dimensional rank tests for sphericity. Journal of Multivariate Analysis, 155, 217–233. https://doi.org/https://doi.org/10.1016/j.jmva.2017.01.003
- Feng, L., & Sun, F. (2016). Spatial-sign based high-dimensional location test. Electronic Journal of Statistics, 10(2), 2420–2434. https://doi.org/https://doi.org/10.1214/16-EJS1176
- Feng, L., Zou, C., & Wang, Z. (2016). Multivariate-sign-based high-dimensional tests for the two-sample location problem. Journal of the American Statistical Association, 111(514), 721–735. https://doi.org/https://doi.org/10.1080/01621459.2015.1035380
- Flury, B. K. (1986). Proportionality of k covariance matrices. Statistics and Probability Letters, 4(1), 29–33. https://doi.org/https://doi.org/10.1016/0167-7152(86)90035-0
- Flury, B. K., & Riedwyl, H. (1988). Multivariate Statistics: A Practical Approach. Chapman and Hall.
- Hall, P. G., & Hyde, C. C. (1980). Martingale Central Limit Theory and Its Applications. Academic Press.
- Han, F., Chen, S., & Liu, H. (2017). Distribution-free tests of independence in high dimensions. Biometrika, 104(4), 813–828. https://doi.org/https://doi.org/10.1093/biomet/asx050
- Han, F., & Liu, H. (2018). ECA: High-dimensional elliptical component analysis in non-Gaussian distributions. Journal of the American Statistical Association, 113(521), 252–268. https://doi.org/https://doi.org/10.1080/01621459.2016.1246366
- Kim, D. Y. (1971). Statistical inference for constants of proportionality between covariance matrices. Technical Report 59, Stanford University.
- Leung, D., & Drton, M. (2018). Testing independence in high dimensions with sums of rank correlations. The Annals of Statistics, 46(1), 280–307. https://doi.org/https://doi.org/10.1214/17-AOS1550
- Li, J., & Chen, S. X. (2012). Two sample tests for high dimensional covariance matrices. Annals of Statistics, 40(2), 908–940.https://doi.org/https://doi.org/10.1214/12-AOS993
- Liu, B., Xu, L., Zheng, S., & Tian, G. (2014). A new test for the proportionality of two large-dimensional covariance matrices. Journal of Multivariate Analysis, 131(1), 293–308. https://doi.org/https://doi.org/10.1016/j.jmva.2014.06.008
- Magyar, A., & Tyler, D. (2014). The asymptotic inadmissibility of the spatial sign covariance matrix for elliptically symmetric distributions. Biometrika, 101(3), 673–688. https://doi.org/https://doi.org/10.1093/biomet/asu020
- Mottonen, J., & Oja, H. (1995). Multivariate spatial sign and rank methods. Journal of Nonparametric Statistics, 5(2), 201–213. https://doi.org/https://doi.org/10.1080/10485259508832643
- Oja, H. (2010). Multivariate nonparametric methods with R. Springer.
- Rao, C. R. (1983). Likelihood ratio tests for relationships between two covariance matrices. In S. Karlin, T. Amemiya, & L. A. Goodman (Eds.), Studies in Econometrics, Time Series and Multivariate Statistics (pp. 529–543). Academic Press.
- Schott, J. R. (1991). Some tests for common principal component subspaces in several groups. Biometrika, 78(4), 771–777. https://doi.org/https://doi.org/10.1093/biomet/78.4.771
- Schott, J. R. (1999). A test for proportional covariance matrices. Computational Statistics and Data Analysis, 32(2), 135–146. https://doi.org/https://doi.org/10.1016/S0167-9473(99)00032-8
- Wang, L., Peng, B., & Li, R. (2015). A high-dimensional nonparametric multivariate test for mean vector. Journal of the American Statistical Association, 110(512), 1658–1669. https://doi.org/https://doi.org/10.1080/01621459.2014.988215
- Xu, L., Liu, B., Zheng, S., & Bao, S. (2014). Testing proportionality of two large-dimensional covariance matrices. Computational Statistics and Data Analysis, 78, 43–55. https://doi.org/https://doi.org/10.1016/j.csda.2014.03.014
- Zou, C. L., Peng, L. H., Feng, L., & Wang, Z. J. (2014). Multivariate sign-based high-dimensional tests for sphericity. Biometrika, 101(1), 229–236. https://doi.org/https://doi.org/10.1093/biomet/ast040
Appendix
Define
Before proving the main theorem, below we recall some necessary lemmas.
Lemma A.1
Under Conditions (C1) and (C2), for any symmetric matrix
,
Note that Lemma A.1 is the same as Lemma 1 of Wang et al. (Citation2015).
Lemma A.2
Let be a random vector uniformly distributed on the unit sphere of
, then we have that
for any
In Lemma A.2, the first statement has been proved in Section 3.1 of Fang et al. (Citation1990) and the second statement has been proved in Zou et al. (Citation2014).
Now, we are ready to present the proof of Theorem 2.2. Then, the proof of Theorem 2.1 can be directly obtained.
Proof of Theorem 2.2:
Define
Hence we have that
and
. According to Lemma 1 in Feng and Liu (Citation2017), we have that
as p goes to infinity and
. The same goes for
and
. On this ground, by Lemma A.1, we have that
As a result, the first part of
has the following decomposition:
According to Lemma A.2 and the fact that
as p goes to infinity, we similarly have that
and
. Using the similar techniques, we can decompose the rest two parts of
, hence conclude that
Therefore, we have that
Below we will consider each item in
one by one. Before we can get the further expression of
, we need to study
first. We have that
Using the same proof techniques as in Cheng et al. (Citation2018), we can get the following equations:
On this ground, we have that
Similarly, we have that
To sum up, we conclude that
.
Define a sequence of random variables as follows:
Let
denote the conditional expectation conditional on
. Define
, then
. As a result, the sequence
constitutes a martingale difference with respect to the σ-fields
. To use the martingale central limit theorem, we need to get the following results first:
(A1)
(A1) where
.
Proof
Proof of the first part of (EquationA1(A1) (A1) )
As , we only need to show that as
,
. Define
for each
, and define
for each
. For each
, we have that
and
For each
, we have that
and
Thus, for each
,
and for each
,
Hence
where
is a constant, and
Moreover, to calculate the order of
, we need to evaluate
. Since
where
and
are constants, we have that
Based on the fact that
and the following inequality
for some constant K, we conclude that
which indicates that
. By using similar techniques, we conclude that
for each
, based on which we finally conclude that
.
Proof
Proof of the second part of (EquationA1(A1) (A1) )
For ,
where
is some constant. Then
Similarly, for
,
where is some constant. Then we have that as
,
By using the martingale central limit theorem (Hall & Hyde, Citation1980), we finally conclude that
Proof of Proposition 2.1:
Using the same techniques as in the proof of Theorem 2.1, we have that and
Therefore,
, and similarly,
, hence
.