
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we propose generalized fiducial methods and construct four generalized p-values to test the existence of quantitative trait locus effects under phenotype distributions from a location-scale family. Compared with the likelihood ratio test based on simulation studies, our methods perform better at controlling type I errors while retaining comparable power in cases with small or moderate sample sizes. The four generalized fiducial methods support varied scenarios: two of them are more aggressive and powerful, whereas the other two appear more conservative and robust. A real data example involving mouse blood pressure is used to illustrate our proposed methods.
1. Introduction
In medical and biological genetic research, quantitative trait locus (QTL) mapping is important in studies of the traits of all types of organisms. For example, QTLs can be identified and mapped to analyse the genetic factors contributing to blood pressure in animals (Sugiyama et al., Citation2001) or to the length of rice grains (Huang et al., Citation1997; R. Wu et al., Citation2007). As a standard process at the beginning of QTL mapping studies, tests for the existence of QTL effects – that is, whether the gene related to the traits is on the specified chromosome – should be deployed.
Interval mapping, proposed by Lander and Botstein (Citation1989), is a popular method for detecting QTLs. Suppose that a putative QTL, denoted by Q, is located between the left and right flanking markers, M and N, in a backcross design. For individuals in the backcross population, the possible genotypes are MM and Mm at M, NN and Nn at N, and QQ and Qq at Q. Hence, the individuals in the backcross population have four marker genotypes: MM/NN, Mm/NN, MM/Nn, and Mm/Nn, where Mm/NN and MM/Nn are recombinant types. For each individual, M and N can be observed but Q cannot. A testing method based on these data for detecting a QTL in the interval M–N is referred to the interval mapping method.
Let r, , and
be the recombination frequencies – that is, the proportions of recombinant genotypes – between M and N, between M and Q, and between Q and N, respectively. In this paper, we only consider backcross designs without double recombination or interference between two-marker-QTL intervals, i.e.,
(R. Wu et al., Citation2007). Denote by C the coding variable for the genotypes at the two markers, with C = 1, 2, 3, 4 representing the genotypes MM/NN, Mm/NN, MM/Nn, and Mm/Nn, respectively. The probabilities of QTL genotypes are shown in Table ; see also Chen and Chen (Citation2005), R. Wu et al. (Citation2007) and Zhang et al. (Citation2008).
Table 1. Probabilities of QTL genotypes.
Let and
be the phenotype density functions corresponding to two QTL genotypes QQ and Qq. Denote by
,
,
, and
the phenotype data corresponding to the marker genotypes MM/NN, Mm/NN, MM/Nn, and Mm/Nn, respectively. Then, we have the following statistical model under the considered background:
(1)
(1) where
and
are trait values corresponding to C = i,
,
. Here, r is known, as the two markers M and N are pre-specified, whereas
and
are unknown as the location of Q is unknown. Then,
and
are modelled by mixture distributions because of the recombination of non-sister chromatids in these individuals. Denoting the total sample size by
, we have
when each
tends to ∞ at the same rate (R. Wu et al., Citation2007).
Under model (Equation1(1)
(1) ), testing the existence of QTL effects is equivalent to testing the null hypothesis:
(2)
(2) The null hypothesis in (Equation2
(2)
(2) ) means that there are no QTL effects. In the literature, parametric methods are usually applied by assuming the specific distributions of
and
. For example, Chen and Chen (Citation2005) and Zhang et al. (Citation2008) assume that
and
have normal distributions with the same variance, although in fact a QTL effect in variance may be more crucial (Korol et al., Citation1996; Liu et al., Citation2020). Recently, Liu et al. (Citation2020) extended the likelihood ratio (LR) test to detect QTL effects where
and
are from a general location-scale family with unknown locations and/or scales, i.e.,
with
. Here,
is a known probability density function, and μ and σ are the location and scale parameters, respectively. Then, the hypothesis test problem in (Equation2
(2)
(2) ) is transformed into:
(3)
(3) In particular, under the assumption that
, the testing problem in (Equation3
(3)
(3) ) becomes
(4)
(4) For the null hypotheses (Equation3
(3)
(3) ) and (Equation4
(4)
(4) ), Liu et al. (Citation2020) proposed explicit representations of the limiting distribution of LR statistics and obtained more accurate asymptotic p-values than those of Rebai et al. (Citation1994, Citation1995). The LR test in Liu et al. (Citation2020) was shown to be more powerful than the Kolmogorov–Smirnov test and Anderson–Darling test. However, we found that the LR test inflated type I errors when the sample size was small or moderate, as shown in our simulation study in Section 3.
Based on the above discussion, it is desirable to develop new methods that control type I errors more accurately while retaining powerful performance with small or moderate sample sizes. One efficient method is the generalized fiducial inference developed by Hannig et al. (Citation2006) and Hannig (Citation2009), which constructs generalized p-values for the null hypotheses (Equation3(3)
(3) ) and (Equation4
(4)
(4) ) under a fiducial inference frame introduced by Fisher (Citation1930). In the literature, the generalized fiducial inference is widely applied in homogeneous data, i.e., assuming that all labels of samples are known. Recent research includes Lai et al. (Citation2015), Hannig et al. (Citation2016), Li et al. (Citation2018), Cui and Hannig (Citation2019), and Williams and Hannig (Citation2019). However, generalized fiducial inference has not received much attention as a means of testing QTL effects under model (Equation1
(1)
(1) ). In this paper, generalized fiducial inference is applied by constructing four types of generalized p-values to test the null hypotheses (Equation3
(3)
(3) ) and (Equation4
(4)
(4) ). Our methods have two advantages. (i) They can control type I errors more accurately than LR methods, especially for small and moderate sample sizes, although they may not be optimal in a conventional sense. (ii) They retain power comparable with or even greater than that of the LR methods.
The remainder of this article is organized as follows. In Section 2, four generalized fiducial methods are proposed for the null hypothesis (Equation3(3)
(3) ). In Section 3, we develop comparisons of these proposed methods with the method of Liu et al. (Citation2020) through simulated examples. In addition, a real genetic dataset is analysed by applying our methods in Section 4. Finally, Section 5 concludes the article. The proof of Theorem 2.1 and additional comparisons among some generalized pivotal quantities (GPQs) are provided in the supplementary material.
2. New test
The generalized fiducial inference is one of the most important ways to construct generalized p-values. In the following, we explain the general procedure proposed by Li et al. (Citation2007, Citation2018) for obtaining generalized p-values based on a data-generating equation (DGE).
Let be a random vector following a known distribution
, where
is an unknown parameter vector. Suppose
, where
is the parameter of interest and
is the nuisance parameter vector. An observation of
is denoted by
. Suppose we have the DGE
where
is a random variable that has a known distribution. The observed version of DGE
has a unique solution for
, i.e.,
. Then, the random quantities
and
are the GPQs of
and
, and the distributions of
and
are the fiducial distributions of
and
. Furthermore, if
has a unique solution for any
and
,
is a generalized test variable of
, so that the generalized p-value for the one-sided hypothesis
is
.
Denote by the GPQ of the parameter vector
. Based on the ideas of the above methods, if
can be obtained by fiducial inference, we can find the GPQs of the parameters of interest
and
, denoted by
and
. Thus, the generalized p-values for the hypotheses
and
are
(5)
(5) and
(6)
(6) According to Theorem 2.1 in Section 2.1,
and
follow the standard uniform distribution
independently. Then, according to Fisher's combined method (Fisher, Citation1932), the generalized p-value for testing the hypothesis in (Equation3
(3)
(3) ) is
(7)
(7) For a given significance level α, the null hypothesis (Equation3
(3)
(3) ) is rejected if
. Similarly, under the condition
, the generalized p-value for the hypothesis test problem in (Equation4
(4)
(4) ) becomes
(8)
(8) where
is the GPQ of
(k = 1, 2) under same-scale conditions. The null hypothesis (Equation4
(4)
(4) ) is rejected if
.
For the mixture distribution frame in (Equation1(1)
(1) ), the DGEs for the sample data
are
(9)
(9) where
and
independently, for
, i = 1, 2, 3, 4. The explicit expressions of
,
,
,
, and
are difficult to obtain based on the observed version of (Equation9
(9)
(9) ), as the labels of observations
and
are missing. Our solution is to introduce a random configuration assignment for
and
, i.e., to randomly assign
and
to the distribution
or
(Hannig, Citation2009). Inspired by the Bayesian method of McLachlan and Peel (Citation2000) and Frühwirth-Schnatter (Citation2006), we obtain the GPQs through a two-block design. Specifically, in the first step, we find the GPQs conditional on a given configuration assignment, which can be obtained much more easily, and denote them by
,
,
,
, and
. In the second step, the new configuration assignment can be randomly generated based on Bernoulli random numbers
, and
, where
(10)
(10) and
(11)
(11) For example, we randomly generate
from
and assign
according to
, that is, we specify that
is generated from the distribution
if
or the distribution
if
,
. According to
and
, we may update
,
,
,
, and
. By iterating the steps above, five Markov chains can be obtained to approximate the distributions of
,
,
,
, and
. Then, the generalized p-values in (Equation5
(5)
(5) ), (Equation6
(6)
(6) ), and (Equation7
(7)
(7) ) can be obtained. A similar method can be applied for the generalized p-value in (Equation8
(8)
(8) ).
Sections 2.1 and 2.2 provide the constructions of GPQs conditional on the configuration assignment. The Gibbs algorithm for the computation of the generalized p-values is explained in Section 2.3.
2.1. GPQs of location and scale parameters conditional on assignment
To find the GPQs of , we combine the observations
,
, and
into
, where
,
, and
are the observed values of
and
. Here,
provides the information for
. Similarly,
contains the information for
, where
. In this sense, we make a configuration assignment of the observations into two groups to infer
and
, respectively. Denote by σ the common scale of the data. Conditional on this configuration assignment, under the null hypothesis (Equation3
(3)
(3) ), we have the following conditional DGEs:
(12)
(12) where
,
, and
are the MLEs determined by
,
, and their combination, respectively, and
and
have known distributions that are, respectively, identical to those of the MLEs
and
, based on a sample of
observations and their combined sample from a standard location-scale distribution
. Hence, the GPQs of
under the null hypothesis (Equation3
(3)
(3) ) should be (Nkurunziza & Chen, Citation2011; Xu & Li, Citation2006)
(13)
(13) where
and
are the observed values of
and
. Here,
and
are independent because of the independence of
,
, and
. In particular, in the normal distribution case,
is the random element following
, and
and
are the random elements following
and
, respectively. Our method, given the configuration assignment in the normal distribution case, is identical to that of Perng and Littell (Citation1976).
Theorem 2.1 indicates the null distributions of and
. The proof of the theorem is obtained by the distributions of the conditional GPQs
and
, which is given in Section A of the supplementary material with some simulated results.
Theorem 2.1
The generalized p-values and
defined in (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) follow
independently.
In particular, under , given the configuration assignment, the GPQs are
(14)
(14) where
are the observed values of
, and
have the same distributions as the MLEs
based on a combined sample of observations
and
from
.
2.2. GPQs of the mixing proportion conditional on assignment
The GPQ of the mixing proportion θ given the configuration assignment is not unique. In the literature, several GPQs have been developed. Among them, three types of GPQs are popular because they have been shown to have relatively good properties even for small and moderate-sized samples.
The mixture-beta generalized variable recommended by Efron (Citation1998) and Hannig (Citation2009), called GVM hereafter, is
(15)
Jeffreys' generalized variable recommended by Cai (Citation2005) and Krishnamoorthy and Lee (Citation2010), called GVJ hereafter, is
Wilson's generalized variable proposed by Li et al. (Citation2013), called GVW hereafter, is
Besides the quantities above, we propose a new generalized variable by modifying the variance-stabilizing transformation of θ.
W. H. Wu and Hsieh (Citation2014) and Bebu et al. (Citation2016) constructed a generalized variable with variance-stabilizing transformation for binomial proportion, called GVV hereafter. For , by the asymptotic normality,
(18)
(18) where
. However, if this result is applied directly to construct the GVV, the result
will become inaccurate, as can be seen in the simulation results in Section B of the supplementary material, because (Equation18
(18)
(18) ) only holds when
. Here,
and
stands for convergence in distribution.
To avoid the problem of liberality in the Wald confidence interval for the binomial proportion in small or moderate sample size cases, Agresti and Coull (Citation1998), Agresti and Caffo (Citation2000), and Schaarschmidt et al. (Citation2008) considered adding some numbers of pseudo variables, half of which were ‘successful’ variables. The frequentist properties of their methods were thus much better than those of the Wald interval. In fact, Schaarschmidt et al. (Citation2008) pointed out that this kind of adjustment was ‘not motivated by statistical theory but determined on a rather heuristic basis’.
Motivated by the results above, we consider adding one or two variables to adjust the GVV of W. H. Wu and Hsieh (Citation2014) and Bebu et al. (Citation2016) based on a variance-stabilizing transformation. To compare the frequentist properties among GVV and its two modifications, we construct generalized confidence intervals for the binomial proportion θ; the coverage probabilities and average lengths are given in Section B of the supplementary material. The results show that this kind of adjustment can improve the frequentist properties of GVV, and the coverage probabilities when adding one pseudo variable have the smallest oscillations when the sample size is not more than 15, although its average lengths are greater than those when two pseudo variables are added. Therefore, we choose to add one pseudo variable, containing 0.5 ‘success’ and 0.5 ‘failure’, which resulting in the following result:
where
. Note that
is identical to the Bayesian estimator based on Jeffreys' prior
, and this convergence is identical to (Equation18
(18)
(18) ) when
. This modified variance-stability transformation generalized variable, called GVMV hereafter, is
(19)
(19) where
is the observed value of
.
2.3. Gibbs algorithm
According to Gelman et al. (Citation2014), a Markov chain Monte Carlo method can be used to obtain approximate distributions to the real ones of the GPQs. For convenience, we consider the two-block Gibbs sampler used by McLachlan and Peel (Citation2000) and Frühwirth-Schnatter (Citation2006). The initial and
can be determined by
where
, with
Then, iterate the following steps for
.
Randomly generate
Under the random assignment in Step 1, generate
Obtain
Generate a random sample with size
Generate
Update
After repeating Step 1 to Step 2 B times, the Markov chains of the GPQs with size B can be obtained. Then, the generalized p-value (Equation7(7)
(7) ) can be obtained by calculating
and
where
denotes the indicator function.
Similarly, under the condition , the Markov chains of the GPQs,
,
and
,
, can be produced by the above steps; then, the generalized p-value (Equation8
(8)
(8) ) can be obtained.
3. Simulations
In this section, we compare the generalized p-values (Equation7(7)
(7) ) and (Equation8
(8)
(8) ) of the hypothesis test problem (Equation3
(3)
(3) ) with the p-values of the LR methods proposed in Liu et al. (Citation2020) via Monte Carlo simulation. As the four generalized fiducial methods differ only in their mixing proportions, we use the abbreviations GVJ, GVM, GVW, and GVMV to represent the generalized fiducial methods. Suppose the significance level is
. Consider the total sample sizes n to be 30, 50, 100, 200, and 300. The recombination frequency r is determined by the Haldane map
, where d is the map distance defined as ‘the expected number of crossovers occurring between them on a single chromatid during meiosis’ and is measured in centiMorgans (R. Wu et al., Citation2007). As the value of d is usually not large in practice (Zhang et al., Citation2008), we set d to 5, 10, or 20 according to Liu et al. (Citation2020), with the corresponding values of r being 0.048, 0.091, and 0.165. The four sample sizes
are generated from
.
First, the type I errors of the five approaches are compared under repeated simulations, and the data are generated from standard normal and logistic distributions, i.e.,
and
. Under the nominal significance level
, the standard error of this Monte Carlo simulation is
. The distributions of the GPQs are approximated by Markov chains with size B = 5000 as described in Section 2.3, whereas those of the two LR statistics are approximated by generating
simulated quantities from Equations (6) and (7) in Liu et al. (Citation2020). The type I errors and their standard errors (%) are shown in Table . The sizes of the generalized p-values proposed here are more conservative than those of the LR method. In large sample size cases, the type I errors of the five methods are close to the significance level. As the total sample size n decreases, the LR method becomes more liberal and can no longer well control type I errors when
. On the contrary, the generalized p-values become more conservative as the sample size n decreases. GVJ and GVMV give generalized p-values relatively close to the nominal level, whereas GVM and GVW are more conservative.
Table 2. Type I errors (%) and standard errors (%) of the five methods.
Further, we compare the power of these methods. To control the type I errors of the LR method successfully, we take the above 10,000 LR quantities of each settings under n and d as the empirical distributions of the LR method under hypotheses (Equation3(3)
(3) ) and (Equation4
(4)
(4) ). After correction, the p-values of the LR method are close to the nominal level. The four types of generalized p-values are calculated by generating B = 5000 simulated quantities. As the type I errors of the four generalized p-values are controlled successfully, no corrections are required for these methods. For
and 0.7, the powers of these tests are obtained by N = 2000 repetitions from each of the six mixture distributions below, using settings similar to those of Liu et al. (Citation2020).
Case I: and
;
Case II: and
;
Case III: and
;
Case IV: and
;
Case V: and
;
Case VI: and
.
Note that in Cases II and V, and
differ only in their scale parameters; therefore, all of the test methods are insignificant. Thus, these two cases are not compared when
.
As shown in Tables , as the sample size increases, the power of the five types of methods also increases. The power is very similar in most cases. Under condition , the four generalized fiducial methods are slightly more powerful than the LR method. Comparing the four generalized fiducial methods, GVMV has the greatest power, although GVJ and GVW are typically very close to GVMV.
Table 3. Powers (%) of the five methods for Normal mixture model.
Table 4. Powers (%) of the five methods for Logistic mixture model.
Table 5. Powers (%) of the five methods for mixture model under .
In summary, the LR method becomes liberal in the case of small and moderate sample sizes (), whereas GVM and GVW become slightly conservative, and GVMV and GVJ show better performance.
4. Real example
In this section, we apply the generalized fiducial methods to a real QTL analysis and further develop a comparison with the LR method.
Sugiyama et al. (Citation2001) performed a QTL analysis on male mice from a reciprocal backcross between the salt-sensitive C57BL/6J (B6) and the normotensive A/J (A) inbred strains after they had been provided with water containing 1% salt for 2 weeks. They were mainly concerned with the genetic control of salt-induced hypertension. Here, we use the five methods to analyse blood pressure data in the 250 male backcross mice typed at 174 markers; the data are available in R package ‘qtl’ with the name ‘hyper’ or can be downloaded from https://phenome.jax.org/projects/Sugiyama2. The detailed process of the experiment can be found in Sugiyama et al. (Citation2001). In this example, we only focus on the QTL locations, not the QTL–QTL interactions, in chromosome 1. This chromosome is divided by 22 markers, where each of the 21 intervals corresponds to four groups of data. For and
in each interval, we apply the Shapiro–Wilk test to determine whether the observations are from the normal distributions. The results show that the
s and
s in 10 of the 21 intervals are normal distributions; their p-values from the Shapiro–Wilk test are listed in Table . Then, QTL detection in these 10 intervals can be modelled by Equation (Equation1
(1)
(1) ) under normal distributions.
Table 6. p-values of Shapiro–Wilk test.
Table provides the sample sizes of the 10 intervals. Nine of them have small or moderate sample sizes (n<50). The asymptotic distributions of the LR method are approximated by simulated realizations (Liu et al., Citation2020), and the lengths of the Markov chains of the four GPQs are set to B = 5000. Taking the interval D1Mit156–D1Mit178 as an example, we can obtain the recombination proportion
, the locations
and
, and the scales
and
. The observed value of the LR statistic is 4.867 and its p-value is 0.1678. The trace plots of Markov chains for the four generalized p-value methods are shown in Figure ; the p-values for GVJ, GVM, GVW, and GVMV are 0.1039, 0.1078, 0.1033, and 0.1009, respectively. Therefore, under a significance level of
, the null hypothesis (Equation3
(3)
(3) ) cannot be rejected by the five methods and the existence of QTL effects cannot be confirmed in this interval.
Figure 1. The trace plot of Markov chains of the four generalized p-values methods for D1Mit156-D1Mit178.
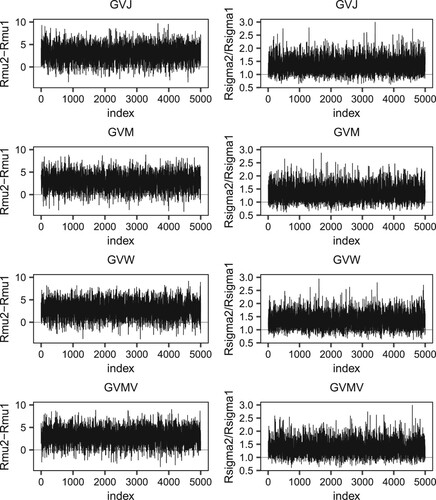
Table 7. Sample sizes of 10 intervals.
Similarly, the results for the remaining nine intervals are shown in Tables and . The four generalized fiducial methods lead to the same conclusions as the LR method. The QTL effect exists in the D1Mit14–D1Mit105 interval at least with respect to the mean. The D1Mit105–D1Mit159 and D1Mit159–D1Mit267 intervals contain QTLs that affect the variance but not the mean. Note that in the interval D1Mit267–D1Mit15, without the equal-scale assumption, the p-value (0.0673) of the LR method is much smaller than those of the four generalized fiducial methods. When the significance level is 0.1, the LR method declares that a QTL effect exists in the variance but not in the mean. However, as shown in Figure , and
are distributed closely, and the p-value of the F-test for comparing the variances of
and
is 0.3982, much larger than the nominal significance level 0.05. From this perspective, the results of the four generalized p-value methods are more reliable, whereas the LR test method is liberal to some degree.
Figure 2. The boxplot of and
for D1Mit267-D1Mit15.
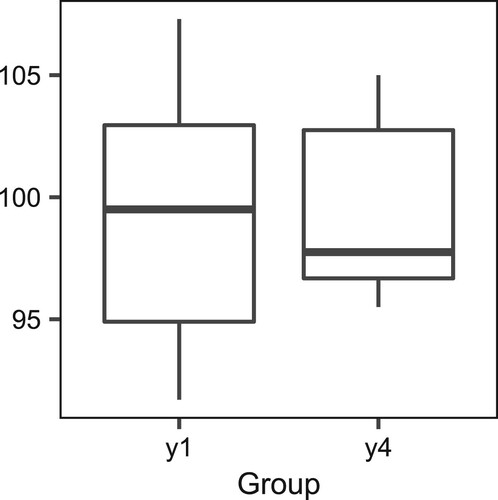
Table 8. Five kinds of p-values in 10 intervals.
Table 9. Five kinds of p-values in 10 intervals under assumption.
5. Conclusion
In this paper, we propose four generalized fiducial methods to test the existence of QTL effects between two flanking markers. Based on the simulation results, we find that the generalized fiducial methods can control type I errors fairly well even when sample sizes are less than 50. These four generalized fiducial methods have almost the same power as the LR method under a fair comparison, and they are slightly more powerful than the LR method when . The four methods can be extended to test the existence of QTL effects with occurring double recombination, where the data from each of the four groups are from a mixture distribution in both location and scale. Meanwhile, more efficient algorithms should be explored, as our two-block algorithm is somewhat time-consuming. We leave these as directions for future research.
Acknowledgments
We are grateful to the Associate Editor and two reviewers for their thorough reading of our manuscript and the constructive comments that lead to significant improvement of our work.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Agresti, A., & Caffo, B. (2000). Simple and effective confidence intervals for proportions and differences of proportions result from adding two successes and two failures. The American Statistician, 54(4), 280–288. https://doi.org/https://doi.org/10.1080/00031305.2000.10474560
- Agresti, A., & Coull, B. A. (1998). Approximate is better than ‘exact’ for interval estimation of binomial proportions. The American Statistician, 52(2), 119–126. https://doi.org/https://doi.org/10.2307/2685469
- Bebu, I., Luta, G., Mathew, T., & Agan, B. K. (2016). Generalized confidence intervals and fiducial intervals for some epidemiological measures. International Journal of Environmental Research and Public Health, 13(6), 605. https://doi.org/https://doi.org/10.3390/ijerph13060605
- Cai, T. T. (2005). One-sided confidence intervals in discrete distributions. Journal of Statistical Planning and Inference, 131(1), 63–88. https://doi.org/https://doi.org/10.1016/j.jspi.2004.01.005
- Chen, Z., & Chen, H. (2005). On some statistical aspects of the interval mapping for QTL detection. Statistica Sinica, 15(4), 909–925.
- Cui, Y., & Hannig, J. (2019). Nonparametric generalized fiducial inference for survival functions under censoring. Biometrika, 106(3), 501–518. https://doi.org/https://doi.org/10.1093/biomet/asz016
- Efron, B. (1998). RA Fisher in the 21st century. Statistical Science, 13(2), 95–122. https://doi.org/https://doi.org/10.1214/ss/1028905930
- Fisher, R. A. (1930). Inverse probability. In B. J. Green (Ed.), Mathematical Proceedings of the Cambridge Philosophical Society (Vol. 26, pp. 528–535). Cambridge University Press.
- Fisher, R. A. (1932). Statistical Methods for Research Workers (4th ed.). Oliver & Boyd.
- Frühwirth-Schnatter, S. (2006). Finite Mixture and Markov Switching Models. Springer.
- Gelman, A., Stern, H. S., Carlin, J. B., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2014). Bayesian Data Analysis (3rd ed.). Chapman and Hall/CRC.
- Hannig, J. (2009). On generalized fiducial inference. Statistica Sinica, 19(2), 491–544.
- Hannig, J., Iyer, H., Lai, R. C., & Lee, T. C. (2016). Generalized fiducial inference: A review and new results. Journal of the American Statistical Association, 111(515), 1346–1361. https://doi.org/https://doi.org/10.1080/01621459.2016.1165102
- Hannig, J., Iyer, H., & Patterson, P. (2006). Fiducial generalized confidence intervals. Journal of the American Statistical Association, 101(473), 254–269. https://doi.org/https://doi.org/10.1198/016214505000000736
- Huang, N., Parco, A., Mew, T., Magpantay, G., McCouch, S., Guiderdoni, E., Xu, J., Subudhi, P., Angeles, E. R., & Khush, G. S. (1997). RFLP mapping of isozymes, RAPD and QTLs for grain shape, brown planthopper resistance in a doubled haploid rice population. Molecular Breeding, 3(2), 105–113. https://doi.org/https://doi.org/10.1023/A:1009683603862
- Korol, A., Ronin, Y., Tadmor, Y., Bar-Zur, A., Kirzhner, V., & Nevo, E. (1996). Estimating variance effect of QTL: An important prospect to increase the resolution power of interval mapping. Genetical Research, 67(2), 187–194. https://doi.org/https://doi.org/10.1017/S0016672300033632
- Krishnamoorthy, K., & Lee, M. (2010). Inference for functions of parameters in discrete distributions based on fiducial approach: Binomial and Poisson cases. Journal of Statistical Planning and Inference, 140(5), 1182–1192. https://doi.org/https://doi.org/10.1016/j.jspi.2009.11.004
- Lai, R. C., Hannig, J., & Lee, T. C. (2015). Generalized fiducial inference for ultrahigh-dimensional regression. Journal of the American Statistical Association, 110(510), 760–772. https://doi.org/https://doi.org/10.1080/01621459.2014.931237
- Lander, E. S., & Botstein, D. (1989). Mapping mendelian factors underlying quantitative traits using RFLP linkage maps. Genetics, 121(1), 185–199. https://doi.org/https://doi.org/10.1093/genetics/121.1.185
- Li, X., Su, H., & Liang, H. (2018). Fiducial generalized p-values for testing zero-variance components in linear mixed-effects models. Science China Mathematics, 61(7), 1303–1318. https://doi.org/https://doi.org/10.1007/s11425-016-9068-8
- Li, X., Xu, X., & Li, G. (2007). A fiducial argument for generalized p-value. Science in China Series A: Mathematics, 50(7), 957–966. https://doi.org/https://doi.org/10.1007/s11425-007-0067-7
- Li, X., Zhou, X., & Tian, L. (2013). Interval estimation for the mean of lognormal data with excess zeros. Statistics & Probability Letters, 83(11), 2447–2453. https://doi.org/https://doi.org/10.1016/j.spl.2013.07.004
- Liu, G., Li, P., Liu, Y., & Pu, X. (2020). Hypothesis testing for quantitative trait locus effects in both location and scale in genetic backcross studies. Scandinavian Journal of Statistics, 47(4), 1064–1089. https://doi.org/https://doi.org/10.1111/sjos.v47.4
- McLachlan, G., & Peel, D. (2000). Finite Mixture Models. John Wiley & Sons.
- Nkurunziza, S., & Chen, F. (2011). Generalized confidence interval and p-value in location and scale family. Sankhya B, 73(2), 218–240. https://doi.org/https://doi.org/10.1007/s13571-011-0026-8
- Perng, S., & Littell, R. C. (1976). A test of equality of two normal population means and variances. Journal of the American Statistical Association, 71(356), 968–971. https://doi.org/https://doi.org/10.1080/01621459.1976.10480978
- Rebai, A., Goffinet, B., & Mangin, B. (1994). Approximate thresholds of interval mapping tests for QTL detection. Genetics, 138(1), 235–240. https://doi.org/https://doi.org/10.1093/genetics/138.1.235
- Rebai, A., Goffinet, B., & Mangin, B. (1995). Comparing power of different methods for QTL detection. Biometrics, 51(1), 87–99. https://doi.org/https://doi.org/10.2307/2533317
- Schaarschmidt, F., Sill, M., & Hothorn, L. A. (2008). Approximate simultaneous confidence intervals for multiple contrasts of binomial proportions. Biometrical Journal, 50(5), 782–792. https://doi.org/https://doi.org/10.1002/bimj.v50:5
- Sugiyama, F., Churchill, G. A., Higgins, D. C., Johns, C., Makaritsis, K. P., Gavras, H., & Paigen, B. (2001). Concordance of murine quantitative trait loci for salt-induced hypertension with rat and human loci. Genomics, 71(1), 70–77. https://doi.org/https://doi.org/10.1006/geno.2000.6401
- Williams, J. P., & Hannig, J. (2019). Nonpenalized variable selection in high-dimensional linear model settings via generalized fiducial inference. The Annals of Statistics, 47(3), 1723–1753. https://doi.org/https://doi.org/10.1214/18-AOS1733
- Wu, R., Ma, C., & Casella, G. (2007). Statistical Genetics of Quantitative Traits: Linkage, maps and QTL. Springer.
- Wu, W. H., & Hsieh, H. N. (2014). Generalized confidence interval estimation for the mean of delta-lognormal distribution: An application to New Zealand trawl survey data. Journal of Applied Statistics, 41(7), 1471–1485. https://doi.org/https://doi.org/10.1080/02664763.2014.881780
- Xu, X., & Li, G. (2006). Fiducial inference in the pivotal family of distributions. Science in China Series A, 49(3), 410–432. https://doi.org/https://doi.org/10.1007/s11425-006-0410-4
- Zhang, H., Chen, H., & Li, Z. (2008). An explicit representation of the limit of the LRT for interval mapping of quantitative trait loci. Statistics & Probability Letters, 78(3), 207–213. https://doi.org/https://doi.org/10.1016/j.spl.2007.05.020