
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we study optimal model averaging estimators of regression coefficients in a multinomial logit model, which is commonly used in many scientific fields. A Kullback–Leibler (KL) loss-based weight choice criterion is developed to determine averaging weights. Under some regularity conditions, we prove that the resulting model averaging estimators are asymptotically optimal. When the true model is one of the candidate models, the averaged estimators are consistent. Simulation studies suggest the superiority of the proposed method over commonly used model selection criterions, model averaging methods, as well as some other related methods in terms of the KL loss and mean squared forecast error. Finally, the website phishing data is used to illustrate the proposed method.
1. Introduction
Model selection is a traditional data analysis methodology. By minimizing a model selection criterion, such as Akaike information criterion (AIC) (Akaike, Citation1973), Bayesian information criterion (BIC) (Schwarz, Citation1978) and Mallow's C (Mallows, Citation1973), one model can be chosen from a number of candidate models. After that, one can make statistical inferences under the selected model. In this progress, we ignore the additional uncertainty or even bias introduced by the model selection produce, and thus often underreport the variance of inferences, as discussed in H. Wang et al. (Citation2009). Instead of focusing on one model, the model averaging approach considers a series of candidate models and gives higher weights to the better models. It is an integrated progress that avoids ignoring the uncertainty introduced by the model selection procedure and reduces the risk in regression estimations.
Model averaging can be classified as Bayesian model averaging (BMA) and Frequentist model averaging (FMA). Compared with the FMA approach, there has been an enormous literature about the BMA method, See Hoeting et al. (Citation1999) for a comprehensive review. Unlike the BMA approach which considers the model uncertainty by giving a prior probability to each candidate model, FMA approach does not require priors and the corresponding estimators are totally determined by the data itself. Therefore, the current studies pay more attention to the FMA approach in statistics and econometrics.
In recent years, optimal model averaging methods have received a substantial amount of interests. Hansen (Citation2007) proposed a Mallows model averaging (MMA) method for linear regression models with independent and homoscedastic errors. He developed its asymptotic optimality for a class of nested models by constraining the model weights in a special discrete set. A. T. Wan et al. (Citation2010) provided a more flexible theoretical framework for the MMA which kept its asymptotic optimality for continuous weights and non-nested models. Hansen and Racine (Citation2012), Liu and Okui (Citation2013) developed a jackknife model averaging (JMA) method and heteroscedasticity-robust C model averaging (HRC
) for the linear regression with independent and heteroscedastic errors, respectively. Zhang et al. (Citation2013) broadened the JMA to the linear regression with dependent errors. Cheng et al. (Citation2015) provided a feasible autocovariance-corrected MMA method to select weights across generalized least squares for the linear regression with time series errors. Zhu et al. (Citation2018) proposed the MMA for multivariate multiple regression models.
Hansen's approach and the subsequent extensions listed above mainly focus on linear models. Recently, some optimal model averaging literatures for nonlinear models have also been developed, including optimal model averaging criterion for partially linear models (Zhang & Wang, Citation2019), quantile regressions (Lu & Su, Citation2015), generalized linear models and generalized linear mixed-effects models (Zhang et al., Citation2016), varying coefficient models (Li et al., Citation2018), varying-coefficients partially linear models (Zhu et al., Citation2019), spatial autoregressive models (Zhang & Yu, Citation2018), and others. All of these methods are asymptotically optimal in the sense of achieving the lowest loss in the large sample case. To the best of our knowledge, there are few optimal averaging estimations for a multinomial logit model that allows all candidate models to be possibly misspecified. The main contribution of this paper is to fill this gap.
The multinomial logit model is widely used in marketing research (Guadagni & Little, Citation1983), risk analysis (Bayaga, Citation2010), credit ratings (Ederington, Citation1985) and other fields including categorical data. A. T. Wan et al. (Citation2014) developed the ‘approximately optimal’ (A-opt) method for the multinomial logit model under a local misspecification model assumption but did not establish asymptotic optimality of the resulting model averaging estimator. Besides, there have been many debates concerning the realism of the local misspecification assumption, e.g., Raftery and Zheng (Citation2003). After that, S. Zhao et al. (Citation2019) proposed M-fold cross-validation (MCV) criterion for the multinomial logit model and yielded forecasting superior to the strategy proposed by A. T. Wan et al. (Citation2014). Then, its asymptotic optimality is proved for the dimension of covariates being fixed.
These two papers for multinomial logit models listed above both concerned a squared estimation error-based risk. Different from squared errors, the KL loss was produced to measure the closeness between the model and the true data generating process. Then, there are amounts of criterion developed from the KL loss, such as Generalised information criteria (GIC) (Konishi & Kitagawa, Citation1996), Kullback–Leibler information criteria (KIC) (Cavanaugh, Citation1999) and an improved version of a criterion based on the Akaike information criterion (AIC) (Hurvich et al., Citation1998). In addition, Zhang et al. (Citation2015) clarified that the model averaging methods based on the KL loss yield better forecasts than these model averaging approaches in terms of squared errors under linear regressions. Motivated by these facts, to propose a novel model averaging method based on the KL loss seems to be potentially interesting. Our simulation study demonstrates that the model averaging method based on the KL loss has strong competitive advantages than the model averaging strategy by considering the squared estimation error for the multinomial logit model.
In order to develop an optimal model averaging method for the multinomial logit model, the weights are obtained through minimizing the KL loss. That is, we use a plug-in estimator of the KL loss plus a penalty term as the weight choice criterion, which is equivalent to penalizing the negative log-likelihood. It is interesting to note that this criterion reduces to the Mahalanobis Mallows criterion of Zhu et al. (Citation2018) where they assume that the distribution of multiple responses is multivariate normal. The asymptotic optimality based on the KL loss of the proposed method is built on the consistency of estimators in misspecified models which is more flexible than the above-mentioned local misspecification assumption. Moreover, the asymptotic optimality will be established for the dimension of covariates being either fixed or diverging.
This article is the first study that proposes optimal model averaging estimation for multinomial logit models based on the KL loss. When the number of candidate models is small, the corresponding numerically solutions obtained are nearly instantaneous. If the number of candidate models is large, the computational burden of our model averaging procedure will be heavy. In this case, a model screening step prior to model averaging is desirable. That is, we use penalized regression with LASSO (Friedman et al., Citation2010) to prepare candidate models. Different tuning parameters may results in different models, which will be included in our resulting candidate models. Using the website phishing data, we demonstrate the superiority of our proposed method.
Our work is related to Zhang et al. (Citation2016), which developed the model averaging method for univariate generalized linear models. We differ from this study by establishing the asymptotic optimality based on some original conditions, while they prove the asymptotic optimality by assuming some conclusions are valid. Moreover, we discuss the case when the true model is one of the candidate models and prove that the model averaging estimators based on our weight choice criterion are consistent.
The remainder of this article is organized as follows. In Section 2, we first describe the multinomial logit model. Then, we introduce the model averaging estimation for the multinomial logit model and propose a weight choice criterion by considering the KL loss. The asymptotic optimality of the proposed method and the estimation consistency are discussed in Sections 3 and 4, respectively. Sections 5 and 6 present the numerical results through various simulations and a real data example, respectively. Technical proofs of the main results are presented in the Appendix.
2. Model framework and weight choice
2.1. Multinomial logit model
Consider a general discrete choice model with n independent individuals and d nominal alternatives. And means individual i selects alternative j. We use a multinomial logit regression to describe the discrete choice model (A. T. Wan et al., Citation2014). The corresponding assumption is that the log odds of category j relative to the reference category (without losing generality, we regard alternative d as reference) are determined by a linear combination of regressors. Thus, the choice probabilities for the ith individual can then be expressed as
(1)
(1)
where
is an
covariate matrix with full column rank,
is constructed from the ith row of
, and
is an unknown parameter vector. We first assume k to be fixed and discuss the diverging situation in Section 3. Formula (Equation1
(1)
(1) ) can be rewritten as an exponential family form.
(2)
(2)
where
is a parameter vector, with the canonical parameter
connecting the parameters
and the k-dimension covariate vector in the form
. And
, where ⊗ is a Kronecker product,
is a
identity matrix, and
, which is a
parameter vector. Besides,
is a vector-valued function,
, and
is an indicator function.
2.2. Model averaging estimator
We denote a set of S candidate models by
(3)
(3)
where S is fixed, and
is an
matrix containing
columns of
with full column rank, whose rows are
. Under the sth candidate model, the maximum-likelihood estimator of the regression coefficients is
. And let
be the subvector containing estimators in
. Note that the rest components of
are restricted to be zeros. Let
be the true value of
. And
is not required that there exists a
so that
. Thus, each of the candidate models can be misspecified. After their maximum-likelihood estimators are obtained, we need to determine the weight of each candidate model. Let
be a weight vector in the unit simplex of
. Then the model averaging estimator of
is
Let ,
be
matrices,
be an
parameter matrix and
be the true value of
. We put the model estimator in vector form by using the vectoring operation
, which creates a column vector by stacking the column vectors of below one another. Then, the model averaging estimator can be expressed as
(4)
(4)
where
, which is an
matrix.
2.3. KL loss-based weight choice criterion
For linear models, the weight choice criterion is based on squared prediction error. In this paper, we use the KL divergence as a replacement for the squared prediction error to establish the asymptotic optimality. The KL loss of is
where
is another realization from
,
is independent of
,
,
,
, and
.
Because of the relationship between and
, we can obtain
to minimize
instead of
. In practice, minimizing
is infeasible because the value of
is unknown. A intuition idea is that we can plug
into
instead of
. That is, we can get
by minimizing
. But, this progress will lead to overfitting. Motivated by that
equals the corresponding negative log-likelihood of
. We add a penalty term
to
, where
, and
is the number of columns of
used in the sth candidate model. And the weight choice criterion is introduced as
The resultant weight vector is defined as
. Because
is convex in
, the global optimization can be performed efficiently through constrained optimization programming. For example, the fmincon of MATLAB can be applied for this purpose. Note that when we restrict one element of
to 1 others 0, then
is equivalent to AIC and BIC in the sense of choosing weights when
and
, respectively. In addition, when
, the criterion
can reduce to the Mahalanobis Mallows criterion of Zhu et al. (Citation2018) where they assume that the distribution of multiple responses is multivariate normal.
3. Asymptotic optimality
This section presents the main theoretic results of this paper, which demonstrates the asymptotic optimality of the model averaging estimator . We define the pseudo true regression parameter vector as
which minimizes the KL divergence between the true model and the sth candidate model. From Theorem 3.2 of White (Citation1982), when the dimension of
, k, is fixed, under some regularity conditions, we have
(5)
(5)
Before we provide the relevant theorems, we first list the relevant notations in this paper. Let
,
,
,
be the ith row of
,
and
, where
,
and
denote the covariance, the maximum and minimum eigenvalues of a matrix, respectively. Note that all the limiting properties here and throughout the text hold under
. The following conditions will be made:
| R.1 | There exist constants | ||||
| R.2 |
| ||||
| R.3 |
| ||||
| R.4 |
| ||||
Remark 3.1
Conditions R.1 and R.2 are regular. Condition R.1 is the same as condition C.2 and the second part of condition C.3 of Zhang et al. (Citation2020). The first part of Condition R.2 is the same as the first part of condition C.3 of Zhang et al. (Citation2020). The second part of Condition R.2 assumes the covariance matrix of is positively definite. Condition R.3 requires
grows at a rate no slower than
. And both
and
satisfy Condition R.4, which means that if one prefers AIC or BIC, this can be achieved by choosing
or
. Condition R.4 is also used by Theorem 2 of Zhang et al. (Citation2020).
The following theorem illustrates the asymptotic optimality of the model averaging estimators for fixed k situation.
Theorem 3.1
For fixed k, if Equation (Equation5(5)
(5) ) and the regularity Conditions R.1–R.4 hold. Then
is asymptotically optimal in the sense that
(6)
(6)
where the convergence is in probability.
Remark 3.2
Theorem 1 of S. Zhao et al. (Citation2019) is based on the squared loss. The squared loss only concerns on the point distance. Different from them, the KL loss measures the closeness between the model and the true data generating process, which concerns on the full distribution. In addition, from , we know that the KL loss pays more attention to these points with high probability. However, the squared loss considers all points are equally important.
Considering for diverging k, let be the corresponding subvector of
and define
Let
,
and
, which are
and
matrices, respectively. We list the following conditions required for the case with diverging k.
| R.5 | There exists a constant | ||||
| R.6 | There exists a constant | ||||
| R.7 |
| ||||
Remark 3.3
Condition R.5 is implied by condition A.1(iii) of Lu and Su (Citation2015). Condition R.6 guarantees that ), which is an extension of the first part of condition C.4 of Zhang et al. (Citation2016). Condition R.7 is an extension of Condition R.3 under the diverging k situation. Condition R.7 allows k to increase with n, but restricts its rate. Obviously, as k increases,
decreases. Therefore, the smaller k is easier to satisfy Condition R.7. In practice, we can exclude redundant variables from the candidate set prior to model averaging to control k.
Theorem 3.2
For diverging k, if Conditions R.1–R.2 and R.4–R.7 are satisfied, then (Equation6(6)
(6) ) remains valid as
.
Remark 3.4
Note that both and
satisfy Condition R.4. In Section 4, the numerical analysis shows that both of them outperform alternative model selection methods (AIC and BIC) and model averaging methods (Smoothed AIC and Smoothed BIC), respectively. And, when the sample size is small, the optimal value of
increases as the level of the model misspecification improves.
4. Estimation consistency
Here we would like to comment on the case when the true model is included in the candidate models. That is,
where
is the true value of
and the number of non-zero coefficients of
is
. Let
be a weight vector in which the element corresponding to the true model is 1, and all others are 0. When k is fixed, from chapter 3.4.1 of Fahrmeir and Tutz (Citation2013), under some regularity conditions, we have
(7)
(7)
For diverging k, from Theorem 2.1 of Portnoy (Citation1988), under some regularity conditions, we can obtain
(8)
(8)
Denote
. In order to prove the estimation consistency, we further impose the following condition.
| R.8 | There exists | ||||
Remark 4.1
Condition R.8 states that most do not degenerate, in the sense that their inner products with
do not approach zero, which is implied by
, uniformly for
and
, and the first part of condition R.1. Our asymptotic study mainly requires Condition R.8 so that the positive definition of
is not necessary.
We now describe the performance of the weighted estimator when the true model is among the candidate models.
Theorem 4.1
When k is fixed and the true model is one of the candidate models, if Conditions R.1, R.2, R.4, R.8 and Equation (Equation7(7)
(7) ) are satisfied, then the weighted estimator satisfies
(9)
(9)
Remark 4.2
Theorem 4.1 states that . I conjecture that it may be possible to extend the converge rate of the weighted estimator to
, similar to Theorem 2 of Zhang and Liu (Citation2019).
Theorem 4.2
For diverging k, if , Conditions R.1, R.2, R.4, R.8 and Equation (Equation8
(8)
(8) ) are satisfied, then the weighted estimator satisfies
(10)
(10)
5. Monte Carlo simulations
In this section, we evaluate the empirical performance of our proposed model averaging strategy for the multinomial logit model. We use two versions of our proposed model averaging method named OPT1-KL with and OPT2-KL with
to compare with some alternative FMA methods and model selection strategies. Model selection methods include AIC, BIC, and LASSO proposed by Friedman et al. (Citation2010), where the tuning parameter,
, is selected by cross-validation. Model averaging strategies include A-OPT (A. T. Wan et al., Citation2014), MCV (S. Zhao et al., Citation2019)), Smoothed AIC (SAIC) and Smoothed BIC (SBIC) (Buckland et al., Citation1997). The SAIC strategy assigns the weight
to the sth model and SBIC allocates weights similarly.
We use the KL loss for assessment and generate 1000 simulated data. For the convenient comparison, we normalize all KL losses by dividing the KL loss corresponding to the best method. The sample size varies at 100, 200. Note that MCV and A-OPT are the model averaging methods to average estimate of the probability . Which leads to computing the KL loss is infeasible. Therefore, we compare our methods with MCV and A-OPT in terms of the mean squared forecast error (MSFE) instead of the KL loss. Without loss of generality, we also normalize all MSFEs by dividing the MSFE corresponding to the best method.
Two situations of simulations are used. In the first situation, when the candidate models do not contain the true model, we examine the effect of the changing magnitude of coefficients and the changing level of the model misspecification. Moreover, we consider the case when the number of covariates is diverging with the sample size. Note that all candidate models are misspecified in this situation, so there does not exist the full model. It implies that the A-OPT method is not feasible for this situation. In the second situation, when the candidate models include the true model, we compare our methods with other competitive methods and validate the estimation consistency.
Setting 1. We generate from the setup of the multinomial logit model (Equation2
(2)
(2) ) with the following specifications:
,
follow normal distributions with mean zeros, variance ones and the correlation between different components of
is
, and
, where
In order to imitate that all candidate models are misspecified, we pretend the last covariate missed. Let
contain in all candidate models. So there are
candidate models to combine. The parameter
is used to control the magnitude of coefficients, and we let it vary in the set
.
Simulation results are shown in Table . One remarkable aspect of the results is that OPT1-KL and OPT2-KL yield smaller mean and standard deviance (SD) values than the other four competitions (SAIC, SBIC, AIC and BIC) in different magnitudes of coefficients. In the majority of cases, FMA approaches are superior to model selection methods. This pattern appears to be more obvious when is small than when it is large. For example, when
= 0.5, all model averaging methods deliver smaller mean values than model selection strategies. When
increases to 2, for n = 200, AIC has marginal advantages than SBIC regarding the mean values. This result is reasonable, because when
is small, and the non-zero coefficients in the true model are all close to zero, which makes it difficult to distinguish the non-zero coefficients from a false model that contains many zeros. As a result, model selection criterion scores can be quite similar for different candidate models and the choice of models becomes unstable. On the other hand, when the absolute values of the non-zero coefficients are large, and a model selection criterion can identify a non-zero coefficient more readily.
Table 1. Simulations results of the KL loss for setting 1.
In addition, we calculate the means of by methods of OPT1-KL and OPT2-KL with
. The values of mean, presented in Figure , decrease and approach to 1 as the sample size n increases. This feature verifies asymptotic optimality numerically.
Then, we compare our strategy with MCV in terms of MSFE. We generate 100 observations as the training sample and 10 observations as the test sample under setting 1 with
. And the simulation results are based on 1000 replications.
where
is the forecast of
, which represents the probability that the vth test observation selects alternative j for the rth replication.
Figure 1. The means of ratio by methods of OPT1-KL and OPT2-KL with .
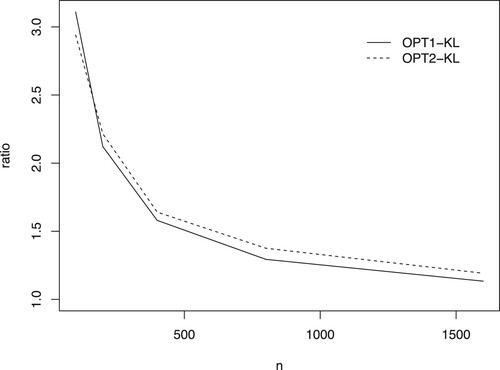
Table shows that our proposed approaches outperform other strategies. Then, SAIC and SBIC perform better than MCV. Note that MCV is the model averaging method based on the squared loss, and our strategy is based on the KL loss. It implies that the approach based on the KL loss has a strong competitive advantage than this approach based on the square loss for a multinomial logit model.
Table 2. Simulation results of MSFE.
Setting 2. In order to examine the effects of the changing level of the model misspecification, we set ,
, and
where
,
have the same specification as the previous design,
controls the level of the model misspecification, we study it in the set
. We take the multinomial logit model (Equation3
(3)
(3) ) to fit the data. We still omit the last covariate
and consider
candidate models.
The simulation results under different levels of the model misspecification are shown in Table . It is seen that OPT1-KL and OPT2-KL always deliver better performances than their competitors SAIC/AIC and SBIC/BIC in terms of mean values, respectively. Focusing on SD values, OPT1-KL always performs much better than SAIC and AIC, and OPT2-KL outperforms SBIC and BIC in most cases. It demonstrates the superiority of our methods.
Table 3. Simulations results of the KL loss for setting 2.
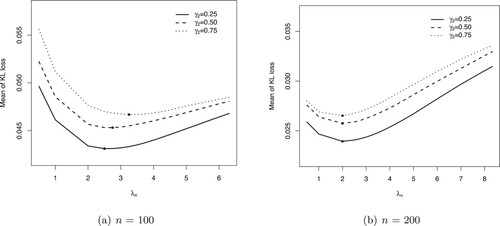
In addition, we explore our strategies with other values of differing from 2 and
. That is, we vary
from 0.5 to
. The simulation results are presented in Figure . For cases of
and 0.75, when n = 100, the means of KL loss are minimized at
,
and
, respectively. It states that when the level of the model misspecification improves, the optimal value of
increases slightly for the small sample size. For a larger sample size n = 200, the optimal values of
are same for all cases with
.
Figure 2. The relationship between the mean of KL loss and . The points with the smallest losses are indicated by the filled circle •. (a) n = 100 and (b) n = 200.
Setting 3. This setup discusses the case when the number of covariates is diverging. The data generate progress is the same as those in setting 1. Except that we adapt the covariance matrix to with
, for that the model screening method is not suitable for the case when the covariances have strong dependence which is implied by the first part of Lemma 3.2 in Ando and Li (Citation2014). Then,
and
are chosen according to the following cases:
Similar to setting 1, we also pretend the last covariate was missed. Then, there are
candidate models. The computation burden will be heavy. Therefore, a screening method to screen candidate models is desirable. That is, we use penalized regression with LASSO (Friedman et al., Citation2010) to prepare candidate models. Different tuning parameters may result in different models, which will be included in our resulting candidate models. Obviously, the resulting candidate model contains lots of redundant variables when the tuning parameter is very small. In order to avoid the generated candidate models including a lot of redundant variables, we use tuning parameters larger than
to prepare candidate models.
Simulation results are provided in Table . Focusing on the mean values, Table shows that OPT1-KL always performs better than SAIC and AIC, and OPT2-KL still outperforms SBIC and BIC, respectively. In addition, OPT2-KL always outperforms LASSO. It implies the advantages of our proposed method comparing with other competitive methods.
Table 4. Simulations results of the KL loss for setting 3.
Setting 4. This setup verifies the estimation consistency. The data generate progress is the same as those in setting 3. Except that we choose and
as follows:
and
All candidate models include
. Thus, we consider a total of
candidate models. Note that the true model is included in the candidate models. We compare our proposed method with other competitive methods based on the KL loss and MSFE. The results are presented in Tables and , respectively. These results show that OPT2-KL always obtain the smallest KL loss and MSFE among these methods, which validates the superiority of our method.
Table 5. Simulations results of the KL loss for setting 4.
Table 6. Simulations results of MSFE for setting 4.
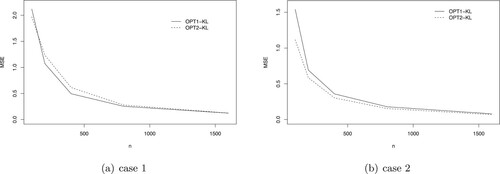
Also, we calculate the mean squared error (MSE) by methods of OPT1-KL and OPT2-KL.
where
represents the estimator of
for the rth replication and
. The MSE curves, shown in Figure , decrease and approach zero with the increase of sample size n. The feature confirms estimation consistency numerically.
Figure 3. Assessing the estimation consistency of OPT1-KL and OPT2-KL. (a) case 1 and (b) case 2.
6. An empirical application
In this part, we apply the proposed method to the website phishing data, which was previously used by Abdelhamid et al. (Citation2014). This data set contains three types of website (702 phishing websites, 548 legitimate websites and 103 suspicious websites). The dependent variables consist of Server Form Handler, Using Pop-Up Window, Fake HTTPs protocol, Request URL, URL of Anchor, Website Traffic, URL Length, Age of Domain and Having IP address. These variables are categorical (or binary). We transform this information into indicator variables. After this operation, the total number of predictors is 16. After the screening method, we analyse this dataset using candidate multinomial logit models. We randomly select 677 observations as the training sample and predict the remaining instances. We repeat this progress 500 times. We use the following KL-type prediction loss to measure the prediction performance.
where
are testing observations, and
is the predicted probability of the vth test observation taking on j.
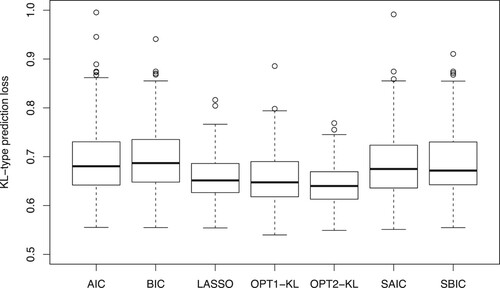
Figure shows the box plot of all KL-type prediction losses by seven methods. It is observed that our proposed methods of OPT1-KL and OPT2-KL produce better performances than their competitions SAIC/AIC and SBIC/BIC, respectively. In addition, OPT2-KL outperforms LASSO in terms of the KL loss.
Figure 4. Boxplots of KL-type prediction losses by seven methods in the website phishing data.
In addition, we evaluate the prediction performance based on the hit-rate, which is computed by dividing the number of correct predictions by the size of the test sample. The prediction value of an observation is if the predicted probability of this observation taking on j has the largest value among the three predicted probability values. In addition, we also calculate the optimal rate (OPR) and the worst rate (WOR) of each method, which is the proportion of times with the largest hite-rate and the smallest hit-rate. Table presents mean values of hit-rate (HRV), OPR and WOR corresponding to these methods, which shows that OPT1-KL and OPT2-KL methods obtain the larger HRV, OPR and smaller WOR than other competitions SAIC, SBIC, AIC, BIC and LASSO, demonstrating the superiority of our proposed strategies.
Table 7. Out-of-sample performances in the website phishing data.
Table reports the Diebold–Mariano test (Diebold & Mariano, Citation2002) results for the differences in hit-rate. Note that a positive Diebold–Mariano statistic indicates that the estimator in the numerator produces a larger hit-rate than the estimator in the denominator. The test statistics and p-values show that the differences in hit-rate between our methods and other strategies are all statistically significant.
Table 8. Diebold–Mariano statistics of hit-rate in the website phishing data.
7. Discussion
In the context of multinomial logit model, we proposed model averaging estimator and weight choice criterion based on KL loss with a penalty term. And we proved the asymptotic optimality of the resulting model averaging estimator under some regularity conditions. When the true model is one of the candidate models, the averaged estimators are consistent. Also, in order to reduce the computational burden, we applied a model screening step before averaging. Numerical experiments were performed to demonstrate the superiority of the proposed methods over other commonly used model selection strategies, model averaging methods, MCV, Lasso in terms of KL loss and MSFE.
While we consider the multinomial logit model, the extension to other models, such as ordered logit model, warrants further investigation. And the data structure of the regressors further complicates this issue. Another interesting question is how to choose an optimal . Shen et al. (Citation2004) have proposed an adaptive method to choose
for model selection criterion in generalized linear models. Building similar methods for our proposed model averaging method to choose an optimal
warrants future researches.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
References
- Abdelhamid, N., Ayesh, A., & Thabtah, F. (2014). Phishing detection based associative classification data mining. Expert Systems with Applications, 41(13), 5948–5959. https://doi.org/10.1016/j.eswa.2014.03.019
- Akaike, H. (1973). Maximum likelihood identification of Gaussian autoregressive moving average models. Biometrika, 60(2), 255–265. https://doi.org/10.1093/biomet/60.2.255
- Ando, T., & Li, K. C. (2014). A model-averaging approach for high-dimensional regression. Journal of the American Statistical Association, 109, 254–265. https://doi.org/10.1080/01621459.2013.838168
- Bayaga, A. (2010). Multinomial logistic regression: Usage and application in risk analysis. Journal of Applied Quantitative Methods, 5, 288–297.
- Buckland, S. T., Burnham, K. P., & Augustin, N. H. (1997). Model selection: An integral part of inference. Biometrics, 53(2), 603–618. https://doi.org/10.2307/2533961
- Cavanaugh, J. E. (1999). A large-sample model selection criterion based on Kullback's symmetric divergence. Statistics & Probability Letters, 42(4), 333–343. https://doi.org/10.1016/S0167-7152(98)00200-4
- Cheng, T. C. F., Ing, C. K., & Yu, S. H. (2015). Toward optimal model averaging in regression models with time series errors. Journal of Econometrics, 189(2), 321–334. https://doi.org/10.1016/j.jeconom.2015.03.026
- Diebold, F. X., & Mariano, R. S. (2002). Comparing predictive accuracy. Journal of Business & Economic Statistics, 20, 134–144. https://doi.org/10.1198/073500102753410444
- Ederington, L. H. (1985). Classification models and bond ratings. Financial Review, 20, 237–262. https://doi.org/10.1111/fire.1985.20.issue-4
- Fahrmeir, L., & Tutz, G. (2013). Multivariate statistical modelling based on generalized linear models. Springer Science & Business Media.
- Friedman, J., Hastie, T., & Tibshirani, R. (2010). Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33, 1–22. https://doi.org/10.18637/jss.v033.i01
- Guadagni, P. M., & Little, J. D. C. (1983). A logit model of brand choice calibrated on scanner data. Marketing Science, 2, 203–238. https://doi.org/10.1287/mksc.2.3.203
- Hansen, B. E. (2007). Least squares model averaging. Econometrica, 75, 1175–1189. https://doi.org/10.1111/ecta.2007.75.issue-4
- Hansen, B. E., & Racine, J. S. (2012). Jackknife model averaging. Journal of Econometrics, 167, 38–46. https://doi.org/10.1016/j.jeconom.2011.06.019
- Hoeting, J. A., Madigan, D., Raftery, A. E., & Volinsky, C. T. (1999). Bayesian model averaging: A tutorial. Statistical Science, 14, 382–417. https://doi.org/10.1214/ss/1009212519
- Hurvich, C. M., Simonoff, J. S., & Tsai, C. L. (1998). Smoothing parameter selection in nonparametric regression using an improved Akaike information criterion. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 60, 271–293. https://doi.org/10.1111/1467-9868.00125
- Konishi, S., & Kitagawa, G. (1996). Generalised information criteria in model selection. Biometrika, 83, 875–890. https://doi.org/10.1093/biomet/83.4.875
- Li, C., Li, Q., Racine, J., & Zhang, D. Q. (2018). Optimal model averaging of varying coefficient models. Statistica Sinica, 28, 2795–2809. https://doi.org/10.5705/ss.202017.0034
- Liu, Q., & Okui, R. (2013). Heteroskedasticity-Robust Cp model averaging. Econometrics Journal, 16(3), 463–472. https://doi.org/10.1111/ectj.12009
- Lu, X., & Su, L. (2015). Jackknife model averaging for quantile regressions. Journal of Econometrics, 188, 40–58. https://doi.org/10.1016/j.jeconom.2014.11.005
- Mallows, C. L. (1973). Some comments on Cp. Technometrics, 15, 661–675. https://doi.org/10.1080/00401706.1973.10489103
- Portnoy, S. (1988). Asymptotic behavior of likelihood methods for exponential families when the number of parameters tends to infinity. The Annals of Statistics, 16(1), 356–366. https://doi.org/10.1214/aos/1176350710
- Raftery, A. E., & Zheng, Y. (2003). Discussion: Performance of Bayesian model averaging. Journal of the American Statistical Association, 98(464), 931–938. https://doi.org/10.1198/016214503000000891
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. https://doi.org/10.1214/aos/1176344136
- Shen, X., Huang, H. C., & Ye, J. (2004). Adaptive model selection and assessment for exponential family distributions. Technometrics, 46(3), 306–317. https://doi.org/10.1198/004017004000000338
- Wan, A. T., Zhang, X., & Wang, S. (2014). Frequentist model averaging for multinomial and ordered logit models. International Journal of Forecasting, 30(1), 118–128. https://doi.org/10.1016/j.ijforecast.2013.07.013
- Wan, A. T., Zhang, X., & Zou, G. (2010). Least squares model averaging by Mallows criterion. Journal of Econometrics, 156(2), 277–283. https://doi.org/10.1016/j.jeconom.2009.10.030
- Wang, H., Zhang, X., & Zou, G. (2009). Frequentist model averaging estimation: A review. Journal of Systems Science and Complexity, 22(4), 732–748. https://doi.org/10.1007/s11424-009-9198-y
- White, H. (1982). Maximum likelihood estimation of misspecified models. Econometrica, 50(1), 1–25. https://doi.org/10.2307/1912526
- Zhang, X., & Liu, C. A. (2019). Inference after model averaging in linear regression models. Econometric Theory, 35(4), 816–841. https://doi.org/10.1017/S0266466618000269
- Zhang, X., Wan, A. T., & Zou, G. (2013). Model averaging by jackknife criterion in models with dependent data. Journal of Econometrics, 174(2), 82–94. https://doi.org/10.1016/j.jeconom.2013.01.004
- Zhang, X., & Wang, W. (2019). Optimal model averaging estimation for partially linear models. Statistica Sinica, 29, 693–718. https://doi.org/10.5705/ss.202015.0392
- Zhang, X., Yu, D., Zou, G., & Liang, H. (2016). Optimal model averaging estimation for generalized linear models and generalized linear mixed-effects models. Journal of the American Statistical Association, 111(516), 1775–1790. https://doi.org/10.1080/01621459.2015.1115762
- Zhang, X., & Yu, J. (2018). Spatial weights matrix selection and model averaging for spatial autoregressive models. Journal of Econometrics, 203(1), 1–18. https://doi.org/10.1016/j.jeconom.2017.05.021
- Zhang, X., Zou, G., & Carroll, R. J. (2015). Model averaging based on Kullback-Leibler distance. Statistica Sinica, 25, 1583–1598. https://doi.org/10.5705/ss.2013.326
- Zhang, X., Zou, G., Liang, H., & Carroll, R. J. (2020). Parsimonious model averaging with a diverging number of parameters. Journal of the American Statistical Association, 115(530), 972–984. https://doi.org/10.1080/01621459.2019.1604363
- Zhao, P., & Li, Z. (2008). Central limit theorem for weighted sum of multivariate random vector sequences. Journal of Mathematics, 28, 171–176. https://doi.org/10.1007/s12033-007-0073-6
- Zhao, S., Zhou, J., & Yang, G. (2019). Averaging estimators for discrete choice by M-fold cross-validation. Economics Letters, 174, 65–69. https://doi.org/10.1016/j.econlet.2018.10.014
- Zhu, R., Wan, A. T., Zhang, X., & Zou, G. (2019). A mallows-type model averaging estimator for the varying-coefficient partially linear model. Journal of the American Statistical Association, 114(526), 882–892. https://doi.org/10.1080/01621459.2018.1456936
- Zhu, R., Zou, G., & Zhang, X. (2018). Model averaging for multivariate multiple regression models. Statistics, 52(1), 205–227. https://doi.org/10.1080/02331888.2017.1367794
Appendix
Proof
Proof of Theorem 3.1
Let . It's obvious that
and ℘ are equivalent in the sense of choosing weights. From the proof of Theorem 1 in Zhang et al. (Citation2016), Theorem 3.1 is valid if the following holds:
(A1)
(A1)
and
(A2)
(A2)
By Equation (Equation5
(5)
(5) ), we can know that uniformly for
(A3)
(A3)
From (EquationA3
(A3)
(A3) ),
, Condition R.1 and Taylor expansion uniformly for
(A4)
(A4)
where
is between
and
. From
, we can obtain
, which along with (EquationA3
(A3)
(A3) ),
and Condition R.1, we have
(A5)
(A5)
where
is the jth column of
. Note that
, which combined with central limit theorem, Condition R.1, and the second part of Condition R.2, we obtain
. From
and (EquationA3
(A3)
(A3) ), we have
(A6)
(A6)
From Condition R.1 and the first part of Condition R.2, we have
and
These along with Theorem 1 in P. Zhao and Li (Citation2008) and the second part of Condition R.2, we know that uniformly for
(A7)
(A7)
Therefore, (EquationA4
(A4)
(A4) ) and (EquationA5
(A5)
(A5) ) indicate that
(A8)
(A8)
And (EquationA4
(A4)
(A4) ), (EquationA5
(A5)
(A5) ), (EquationA6
(A6)
(A6) ), (EquationA7
(A7)
(A7) ) indicate that
(A9)
(A9)
Now, from (EquationA8
(A8)
(A8) ), (EquationA9
(A9)
(A9) ) and Conditions R.3 and R.4, we can get (EquationA1
(A1)
(A1) ) and (EquationA2
(A2)
(A2) ). This completes the proof of Theorem 3.1.
Proof
Proof of Theorem 3.2
From the result of Theorem 3.1, it suffices to prove that (EquationA10(A10)
(A10) )–(EquationA14
(A14)
(A14) ), as
(A10)
(A10)
(A11)
(A11)
(A12)
(A12)
(A13)
(A13)
(A14)
(A14)
First of all, we show that for any fixed
, there exists
such that for all sufficiently large n
Write
, where
is a
vector. The quasi true value
minimizes the KL divergence so that
which implies that
. Then, by using first-order Taylor expansion of
at
, we can get
which implies
, then
where
between
and
. It follows Condition R.6 and sufficiently large n
By taking
, we can obtain
, and thus
(A15)
(A15)
From (EquationA15
(A15)
(A15) ) and Condition R.5, we can show that uniformly for
(A16)
(A16)
and similar to the proof of (EquationA5
(A5)
(A5) ), we can obtain
(A17)
(A17)
By combining (EquationA16
(A16)
(A16) ), (EquationA17
(A17)
(A17) ) and Condition R.7, we obtain (EquationA10
(A10)
(A10) ) and (EquationA11
(A11)
(A11) ). By using
, central limit theorem, Condition R.1, and the second part of Condition R.2, we obtain
, which combined with (EquationA15
(A15)
(A15) ) implies
(A18)
(A18)
From Condition R.1 and the first part of Condition R.2, we obtain
and
These along with Theorem 1 in P. Zhao and Li (Citation2008), and the second part of Condition R.2, we know that uniformly for
(A19)
(A19)
Using (EquationA18
(A18)
(A18) ), (EquationA19
(A19)
(A19) ) and Conditions R.4, R.7, the claims(EquationA12
(A12)
(A12) )–(EquationA14
(A14)
(A14) ) are obtained. This completes the proof of Theorem 3.2.
Proof
Proof of Theorem 4.1
Note that the true value minimizes the KL divergence so that
which implies that
(A20)
(A20)
where
, which is a
vector. Then by using second order Taylor expansion of
at
, we have
(A21)
(A21)
where
. From every element of symmetric matrix
bound, (EquationA20
(A20)
(A20) ), (EquationA21
(A21)
(A21) ), (Equation7
(7)
(7) ) and Condition R.1, we have
(A22)
(A22)
In addition, let
be the set of i such that the inequality in Condition R.8 holds. From Condition R.8, and the second-order Taylor expansion of
at
, we have
(A23)
(A23)
where
is the number of elements in
, and from Condition R.8 we know that
has the same order as n. Note that
and
(A24)
(A24)
These along (EquationA22
(A22)
(A22) ), (EquationA24
(A24)
(A24) ) and
, we have
which follows that
Note that
, which along with central limit theorem, Condition R.1, and the second part of Condition R.2, we obtain
. From
, (EquationA23
(A23)
(A23) ) and (Equation7
(7)
(7) ), we can know
Thus, there exists ,
, such that
This lead to
and thus,
which implies that
This completes the proof of Theorem 4.1.
Proof
Proof of Theorem 4.2
The proof of Theorem 4.2 can be treated analogously to the proof of Theorem 4.1.