
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper studies the inference problem of index coefficient in single-index models under massive dataset. Analysis of massive dataset is challenging owing to formidable computational costs or memory requirements. A natural method is the averaging divide-and-conquer approach, which splits data into several blocks, obtains the estimators for each block and then aggregates the estimators via averaging. However, there is a restriction on the number of blocks. To overcome this limitation, this paper proposed a computationally efficient method, which only requires an initial estimator and then successively refines the estimator via multiple rounds of aggregations. The proposed estimator achieves the optimal convergence rate without any restriction on the number of blocks. We present both theoretical analysis and experiments to explore the property of the proposed method.
1. Introduction
Single-index models provide an efficient way of coping with high-dimensional nonparametric estimation problem and avoid the ‘curse of dimensionality’ by assuming that the response is only related to a single linear combination of the covariates. Because of its usefulness in several areas such as discrete choice analysis in econometrics and dose–response models in biometrics, we restrict our attention to the single-index model in the following form:
(1)
(1) where
is the univariate response and
is a vector of the p-dimensional covariates. The function
is an unspecified and nonparametric smoothing function;
is the unknown index vector coefficient. For identifiability, one imposes certain conditions on
, and we assume that
with
. This ‘remove-one-component’ method for
has also been applied in Christou and Akritas (Citation2016), Delecroix et al. (Citation2006) and Ichimura (Citation1993).
is assumed to be independent and identically distributed random error with
.
In single-index model (Equation1(1)
(1) ), the primary parameter of interest is the coefficient
in the index
, since
makes explicit relationship between the response variable
and the covariate
. Various strategies for estimating
have been proposed in the literature, see Jiang et al. (Citation2013), Jiang et al. (Citation2016), Tang et al. (Citation2018), Wu et al. (Citation2010), and Xia et al. (Citation2002) and so on.
The development of modern technology has enabled data collection of unprecedented size. For instance, Facebook had 1.55 billion monthly active users in the third quarter of 2015. In recent years, statistical analysis of such massive dataset has become a subject of increased interest. However, when the sample size is excessively large, there are two major obstacles. First, the data can be too big to be held in a computer's memory. Second, the computing task can take too long to wait for the results. Some statisticians have made important contributions. One of these methods, called the averaging divide-and-conquer (ADC) has been widely adopted. The main idea of ADC is to first compute local estimators on each block and then take the average, see Chen and Xie (Citation2014), Chen et al. (Citation2019), Jiang et al. (Citation2020), Lin and Xi (Citation2011) and so on.
These averaging-based, ADC approaches suffer from one drawback. In order for the averaging estimator to achieve the optimal convergence rate that utilizes all data points at once, each block must have access to at least samples, where n is the sample size of the full data set. In other words, the number of blocks should be much smaller than
, which is a highly restrictive assumption. Jordan et al. (Citation2019) proposed the communication-efficient surrogate likelihood procedure to solve distributed statistical learning problem, which relaxes the condition on the number of blocks. However, their methods cannot be applied to estimate unknown index vector coefficient in the single-index model (Equation1
(1)
(1) ), according to the unknown nonparametric function.
This paper proposes an iterative divide-and-conquer (IDC) method for estimating the unknown index vector coefficient in model (Equation1(1)
(1) ) under massive dataset, which reduces the required primary memory and computation time. The proposed IDC method can remove the constraint on the number of blocks in ADC method, which only requires an initial estimator and then successively refines the estimator via multiple rounds of aggregations. The resulting estimator is as efficient as the estimator by the entire dataset.
The remainder of the paper is organized as follows. In Section 2, we introduce the proposed procedures for model (Equation1(1)
(1) ). Both the simulation examples and the applications of two real datasets are given in Section 3 to illustrate the proposed procedures. Final remarks are given in Section 4. All the conditions and their discussions as well as technical proofs are relegated to the Appendix.
2. Methodology and main results
2.1. Iterative divide-and-conquer method
We first review the estimation method for full data (Wang et al., Citation2010), which can be analysed by one single machine. Let be an independent identically distributed (i.i.d.) sample from
. We can obtain the estimator
of
by minimizing
(2)
(2) where
,
,
(3)
(3)
, for l = 0, 1, 2, s = 0, 1, r = 1, 2,
,
is a symmetric kernel function and h is a bandwidth.
However, for massive dataset, we cannot obtain the estimator of , because a computer can't store or spend a long time to solve the optimization problem of (Equation2
(2)
(2) ).
Let us assume that n samples are partitioned into M subsets. In particular, we split the data index set into
, where
denotes the set of indices on the m-th block,
. Without loss of generality, each block has the sample size
, where
should be an integer.
The averaging divide-and-conquer (ADC) method for can be obtained by Jiang et al. (Citation2020) as follows:
(4)
(4) where
is obtained by minimizing (Equation2
(2)
(2) ) with the subset
.
Sensor network data are naturally collected by many sensors. However, by the results of Theorem 4.1 in Jiang et al. (Citation2020), for to achieve the optimal convergence rate
, the number of machines M has to be fixed. It is a highly restrictive assumption. In this section, we will propose a method for the case of
, and it is also valid for fixed M.
Note that in (Equation3
(3)
(3) ) may not be a linear function, solving (Equation2
(2)
(2) ) is a nonlinear optimization problem, and the computation can be challenging. Instead, we use a local linear approximation of
around an initial value
, where
. This yields
where
is the
-dimensional vector consisting of coordinates
of
and
(5)
(5) We denote
and
for simplicity. Then, the proposed estimator is obtained by minimizing the following least squares function,
(6)
(6) where
.
By the forms of (Equation3(3)
(3) ) and (Equation5
(5)
(5) ), for given
, it is easy to estimate
and
under massive dataset.
in (Equation3
(3)
(3) ) and (Equation5
(5)
(5) ) can be rewritten as
(7)
(7) where l = 0, 1, 2, s = 0, 1 and r = 1, 2. Thus, by (Equation3
(3)
(3) ), (Equation5
(5)
(5) ) and (Equation7
(7)
(7) ), we can obtain the estimators of
and
for massive dataset. Note that the estimators are the same as the estimators in (Equation3
(3)
(3) ) and (Equation5
(5)
(5) ) which are computed directly by the full data. Thus, we can use (Equation3
(3)
(3) ), (Equation5
(5)
(5) ), (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ) to iteratively update the estimate of
until convergence.
2.2. Asymptotic normality of the resulting estimator
To establish the asymptotic property of the proposed estimator, the following technical conditions are imposed.
| (C1) | The density function of | ||||
| (C2) |
| ||||
| (C3) |
| ||||
| (C4) | The kernel | ||||
Remark 2.1
Conditions (C1)–(C4) are commonly used in the literature, see Wang et al. (Citation2010). Condition (C1) is used to bound the density function of away from zero. This ensures that the denominators of
and
are, with high probability, bounded away from 0 for
, where
and
is near
. The Lipschitz condition and the two derivatives in conditions (C1) and (C2) are standard smoothness conditions. Condition (C3) is a necessary condition for the asymptotic normality of an estimator. Condition (C4) is a usual assumption for kernel function.
Theorem 2.1
Suppose conditions (C1)–(C4) hold, with
, and
,
,
, and
. Then, the estimator
of the Q-th iteration,
where
stands for convergence in the distribution,
and
The initial estimator
can be obtained by the method in Ichimura (Citation1993) based on
, which satisfies
under some regularity conditions.
Theorem 2.1 shows that achieves the same asymptotic efficiency as estimator in (Equation2
(2)
(2) ) computed directly on all the samples, see Theorem 2 in Wang et al. (Citation2010). Compared to the averaging divide-and-conquer method that also can achieve the convergence rate
but under the condition fixed M, our approach removes the restriction on the number of machines M by applying multiple rounds of aggregations. It is also important to note that the required number of rounds Q is usually quite small. For example, if
and
, then Q = 3.
After obtaining the estimation of
, for any given point u, we can estimate
in model (Equation1
(1)
(1) ) with massive dataset by (Equation3
(3)
(3) ).
2.3. Algorithm
Based on the above analysis, we now introduce an iterative divide-and-conquer method for estimating .
Step 1: Without loss of generality, the entire data set is partitioned into M subsets: .
Step 2: Calculate the initial estimator based on
.
Step 3: Compute the estimators
and
where
l = 0, 1, 2,
Step 4: Compute the estimator :
where
and
Step 5: Iterate times of Steps 3 and 4.
3. Numerical studies
In this section, we first use Monte Carlo simulation studies to assess the finite sample performance of the proposed procedures and then demonstrate the application of the proposed methods with two real data analyses. All programs are written in R code and our computer has a 3.3 GHz Pentium processor and 8G memory.
The Epanechnikov kernel is used in this section. When calculating the estimator
in (Equation6
(6)
(6) ), according to Wang et al. (Citation2010), we choose the bandwidths:
and
. We can use the method in Ichimura (Citation1993) to obtain
in (Equation4
(4)
(4) ), which can be obtained by ‘npindexbw’ in R. All the simulations are run for 100 replicates.
3.1. Simulation example 1: effect of M with fixed n
In this example, we fix the total sample size n = 10000 and vary the number of blocks M from , to access the influence of M on the proposed estimation method. The model for the simulated data is
(8)
(8) where
is uniformly distributed on
,
,
and
.
We compare the proposed iterative divide-and-conquer (IDC) method for with the oracle procedure (Oracle) which is obtained by solving (Equation2
(2)
(2) ) by the full data, and averaging divide-and-conquer (ADC) method.
Table depicts the mean squared errors , and Absolute Bias (
) of the estimate
to assess the accuracy of the estimation methods. From Table , the following conclusions can be drawn.
All the estimators are close to the true value because the results of Absolute Bias are very small.
Based on MSE, the performances of IDC estimator are better than those of ADC when M = 100, and are worse than those of ADC when M = 10 and M = 50.
t in Table is the average computing time in seconds used to estimate the index parameter. From t, we see that the operation times of ADC and IDC are faster than that of Oracle. Moreover, IDC is faster than ADC under case of M = 10.
Table 1. The means of Absolute Bias, MSE (standard deviation) and t for simulation Example 1.
3.2. Simulation example 2: effect of M with fixed 
To compare the effects of the three methods on the number of blocks with fixed sample size on each block (), we consider M of {10,20,…,100}. The model for the simulated data is also from (Equation8
(8)
(8) ).
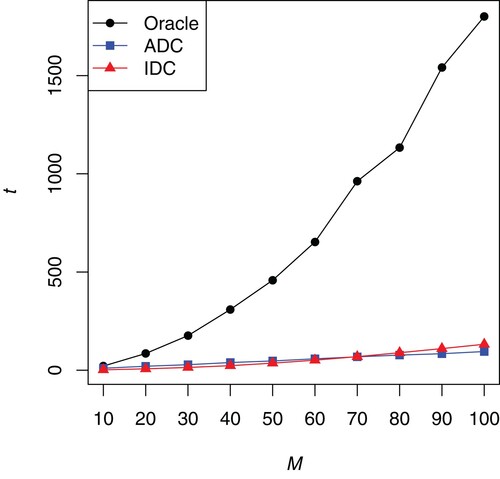
The results of MSE are presented in Figure . The average computing time in seconds used to estimate the index parameter is presented in Figure . From Figures and , the following conclusions can be drawn.
From Figure , we can see that the performances of Oracle method are the best of the three methods under different M. However, by Figure , the operation times of Oracle method are much greater than those of ADC and IDC under different M.
As the number of blocks M continues to increase, the MSEs of Oracle and IDC decrease. However, ADC doesn't have this pattern.
If the number of blocks is less than 30, the MSEs of the ADC method are less than that of IDC. However, as the number of blocks continues to increase, IDC can significantly outperform the ADC method. Furthermore, if the number of blocks is less than 60, the operation times of the IDC method are less than that of ADC.
Figure 1. Comparison of MSE versus the number of blocks M with for three methods for simulation Example 3.2.
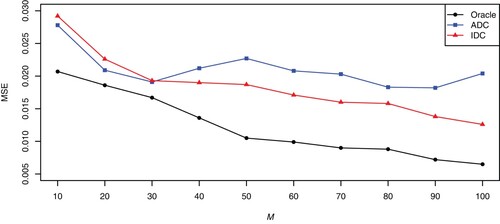
Figure 2. The mean computing time of (in seconds) for simulation Example 3.2.
3.3. Simulation example 3: effect of n
To examine the effect of increasing the sample size, n = 5000, 10000 and 20000 are considered. The following single-index model is considered:
(9)
(9) where
is a two-dimensional standard normal variable, the correlation between
and
is 0.5,
,
and
.
Table presents the averages of Absolute Bias and computing time t over the 100 data sets along with its estimated standard error. By varying the sample size, as expected, the Absolute Bias becomes smaller and computing time t becomes bigger as the sample size grows.
Table 2. The means of Absolute Bias (standard deviation) and t for simulation Example 3.
3.4. Real data example 1: combined cycle power plant data
We apply the proposed method to combined cycle power plant data. The dataset contains 9568 data points collected from a Combined Cycle Power Plant over 6 years (2006–2011), when the power plant was set to work with full load. Features consist of hourly average ambient variables Temperature (AT), Ambient Pressure (AP), Relative Humidity (RH) and Exhaust Vacuum (V) to predict the net hourly electrical energy output (EP) of the plant. The data set is obtained from online site: https://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant.
In this study, the following single-index model is used to fit the data:
(10)
(10) where all the data are normalized. We considered the number of blocks
; hence, the respective values of the local sample size are
. Table summarizes the estimated coefficients for the above model, showing that AP has the smallest effect on EP among the four covariates and AT is the most important covariate. Figure shows the estimated EP by the Oracle method along with the observations, illustrating that single-index model (Equation10
(10)
(10) ) is very suitable to the combined cycle power plant data. Furthermore, we evaluate the performances of three estimators based on mean square fitting error (
), where
is the fitted value of
by (Equation3
(3)
(3) ). From Table , the following conclusions can be drawn.
The MSFEs of IDC under different M are very close to that of Oracle method. Thus the performances IDC are well.
As the number of blocks M continues to increase, the MSFEs of ADC increase. The performances of IDC estimator are better than those of ADC when M = 92 and are worse than those of ADC when M is small.
t in Table is the average computing time in seconds used to estimate the index parameter. From t, we see that the operation times of IDC are faster than that of Oracle and ADC.
Figure 3. Estimated single index function for the combined cycle power plant data. The dots are the observations EP and the curve is the estimated EP by the Oracle method.
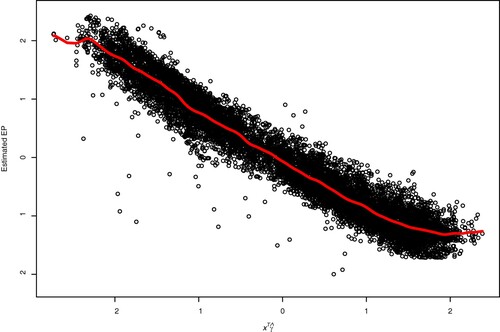
Table 3. The coefficient estimates and MSFE for the combined cycle power plant data.
3.5. Real data example 2: airline on-time data
Airline on-time performance data from the 2009 ASA Data Expo are used as a case study. These data are publicly available (http://stat-computing.org/dataexpo/2009/the-data.html). This dataset consists of flight arrival and departure details for all commercial flights within the United States from October 1987 to April 2008. About 12 million flights were recorded with 29 variables. In this section, we only consider the data of year 2008 (the number of samples is 1011963). The first 1000000 data points are used for the estimation and the remaining 11963 data are used for the prediction.
Schifano et al. (Citation2016) developed a linear model that fits the data as follows:
(11)
(11) where
is the arrival delay (ArrDelay), which is a continuous variable found by modelling
,
is the departure hour (range 0 to 24),
is the distance (in 1000 miles),
is the dummy variable for a night flight (1 if departure between 8 p.m. and 5 a.m., 0 otherwise), and
is the dummy variable for a weekend flight (1 if departure occurred during the weekend, 0 otherwise).
In this study, the following single-index model is used to fit the data:
(12)
(12) For comparison purposes, we use the least squares (LS) method to estimate
in model (Equation11
(11)
(11) ), and use the ADC and IDC methods proposed in Section 2 to estimate
in model (Equation12
(12)
(12) ). The number of blocks is 1000 for these three methods. Furthermore, we evaluate the performance of these estimators based on their out-of-sample prediction with the mean absolute prediction error (MAPE) of the predictions,
where
is the fitted value of
,
with n = 11, 963.
can be obtained by (Equation3
(3)
(3) ). Table presents the estimated coefficients and MAPEs of the three methods. From Table , we can see that the IDC method performs better than LS and ADC according to the smaller MAPE.
Table 4. The coefficient estimates and MAPE for the airline on-time data.
Disclosure statement
We proposed a divide-and-conquer method to deal with single-index model for massive dataset. The proposed method significantly reduces the required amount of primary memory and enjoys a very low computational cost. The proposed method achieves the same asymptotic efficiency as the estimator using all the data. Furthermore, it allows a weak condition on the sample size as a function of memory size.
Additional information
Funding
References
- Chen, X., Liu, W., & Zhang, Y. (2019). Quantile regression under memory constraint. The Annals of Statistics, 47(6), 3244–3273. https://doi.org/10.1214/18-AOS1777
- Chen, X. Y., & Xie, M. G. (2014). A split-and-conquer approach for analysis of extraordinarily large data. Statistica Sinica, 24(4), 1655–1684. https://doi.org/10.5705/ss.2013.088
- Christou, E., & Akritas, M. (2016). Single index quantile regression for heteroscedastic data. Journal of Multivariate Analysis, 150, 169–182. https://doi.org/10.1016/j.jmva.2016.05.010
- Delecroix, M., Hristache, M., & Patilea, V. (2006). On semiparametric M-estimation in single-index regression. Journal of Statistical Planning and Inference, 136(3), 730–769. https://doi.org/10.1016/j.jspi.2004.09.006
- Ichimura, H. (1993). Semiparametric least squares (SLS) and weighted SLS estimation of single-index models. Journal of Econometrics, 58(1-2), 71–120. https://doi.org/10.1016/0304-4076(93)90114-K
- Jiang, R., Guo, M. F., & Liu, X. (2020). Composite quasi-likelihood for single-index models with massive datasets. Communications in Statistics – Simulation and Computation, 51(9), 5024–5040. https://doi.org/10.1080/03610918.2020.1753074
- Jiang, R., Qian, W. M., & Zhou, Z. G. (2016). Weighted composite quantile regression for single-index models. Journal of Multivariate Analysis, 148, 34–48. https://doi.org/10.1016/j.jmva.2016.02.015
- Jiang, R., Zhou, Z. G., Qian, W. M., & Chen, Y. (2013). Two step composite quantile regression for single-index models. Computational Statistics & Data Analysis, 64, 180–191. https://doi.org/10.1016/j.csda.2013.03.014
- Jordan, M., Lee, J., & Yang, Y. (2019). Communication-efficient distributed statistical learning. Journal of the American Statistical Association, 14(526), 668–681. https://doi.org/10.1080/01621459.2018.1429274
- Lin, N., & Xi, R. (2011). Aggregated estimating equation estimation. Statistics and Its Interface, 4(1), 73–83. https://doi.org/10.4310/SII.2011.v4.n1.a8
- Schifano, E., Wu, J., Wang, C., Yan, J., & Chen, M. H. (2016). Online updating of statistical inference in the big data setting. Technometrics, 58(3), 393–403. https://doi.org/10.1080/00401706.2016.1142900
- Tang, Y., Wang, H., & Liang, H. (2018). Composite estimation for single-index models with responses subject to detection limits. Scandinavian Journal of Statistics, 45(3), 444–464. https://doi.org/10.1111/sjos.v45.3
- Wang, J. L., Xue, L., Zhu, L., & Chong, Y. (2010). Estimation for a partial-linear single-index model. The Annals of Statistics, 38(1), 246–274. https://doi.org/10.1214/09-AOS712
- Wu, T., Yu, K., & Yu, Y. (2010). Single-index quantile regression. Journal of Multivariate Analysis, 101(7), 1607–1621. https://doi.org/10.1016/j.jmva.2010.02.003
- Xia, Y., Tong, H., Li, W., & Zhu, L. X. (2002). An adaptive estimation of dimension reduction space. Journal of the Royal Statistical Society Series B, 64(3), 363–410. https://doi.org/10.1111/rssb.2002.64.issue-3
- Zhu, L., & Xue, L. (2006). Empirical likelihood confidence regions in a partially linear single-index model. Journal of the Royal Statistical Society: Series B, 68(3), 549–570. https://doi.org/10.1111/rssb.2006.68.issue-3
Appendix
Proof
Proof of Theorem 2.1
We denote the first iteration , and note that (Equation6
(6)
(6) ) can be equivalently written as
where
,
, and
. Note that
We first show that
. Let
denote the s-th component of
. Then, we have
Note that
in (Equation3
(3)
(3) ) can be rewritten as
where
Thus
can be rewritten as
where
Hence, by Lemma 1 in Zhu and Xue (Citation2006) and conditions (C2) and (C3),
is a consistent estimate of
and by the Cauchy–Schwarz inequality, for
and
big enough, we have
For
, by Lemma 2 in Zhu and Xue (Citation2006), for
and
big enough, we have
We now consider
. Note that
and
when
; by Lemma 2 in Zhu and Xue (Citation2006), for
and
big enough, we have
By the condition
, we have
Combining the above results, the s-th moment of
converges to 0. By the Markov inequality, we have
We prove that the mean and the variance of
tend to 0. Using
and condition (C2), we have
Using conditions (C1)–(C4) and the (A.35) of Chang et al. (2010), we obtain
This proves that
We now consider
.
By Lemma 3 in Zhu and Xue (Citation2006) and Markov inequality, for any
,
Hence, we have, uniformly over
,
Similarly,
Thus we have
Noting that
, we obtain
For
, by a Taylor expansion, we get
where
is a point between
and
. By the condition
and using
, we have
and
Thus we can obtain
. Therefore,
Finally, we consider
.
where
and
We rewrite
as
For
, by a Taylor expansion, we get
. Similar to the proof of
, we get
and
Hence,
Therefore, we have
Similar to the proof of
, we can obtain
where
. Thus
Note that one round of aggregation enables a refinement of the estimator with its bias reducing from
to
. Therefore, an iterative refinement of the initial estimator will successively improve the estimation accuracy. The q-th iterative divide-and-conquer method
satisfies
Thus, after Q iterations, where
, we have
By the central limit theorem, we can prove Theorem 2.1.