
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The outbreak of COVID-19 on the Diamond Princess cruise ship has attracted much attention. Motivated by the PCR testing data on the Diamond Princess, we propose a novel cure mixture nonparametric model to investigate the detection pattern. It combines a logistic regression for the probability of susceptible subjects with a nonparametric distribution for the detection of infected individuals. Maximum likelihood estimators are proposed. The resulting estimators are shown to be consistent and asymptotically normal. Simulation studies demonstrate that the proposed approach is appropriate for practical use. Finally, we apply the proposed method to PCR testing data on the Diamond Princess to show its practical utility.
1. Introduction
The epidemic of the novel coronavirus disease (COVID-19) outbroke in December 2019 in Wuhan, China. Since its outbreak, the epidemic has progressed rapidly and has emerged in more than two hundred countries. It has become an unprecedented global epidemic crisis. The transmissibility patterns in open spaces like households, offices and public places are quite different from those in confined spaces such as aeroplanes, trains and cruise ships. Among the outbreaks of COVID-19 all over the world, one of the most well-known eruptions is the one on the Diamond Princess cruise ship. The high contagiousness of COVID-19 on the Diamond Princess cruise has attracted much attention (Mizumoto et al., Citation2020; Sekizuka et al., Citation2020; Zhang et al., Citation2020). Its speciality can be observed through Johns Hopkins' daily released confirmed cases over the world, where the infected number of cases on Diamond Princess ship is reported separately adjacent to that of Japan.
The Diamond Princess cruise ship started on January 20, 2020 in Yokohama, Japan, visited five places including Hong Kong and returned Yokohama on February 3 (Sekizuka et al., Citation2020). During this period, an 80-year-old passenger who disembarked on January 25 in Hong Kong, was confirmed for COVID-19 on February 1. After the disembarkation of Diamond Princess at Yokohama, Japanese government asked 3711 individuals, including 2666 passengers and 1045 crew members, to stay onboard to carry out a 14-day quarantine period from February 5 to February 19. The health status of all individuals on board was investigated, making daily time series of PCR testing data, including number of tests and number of patients testing positive each day, publicly available (Mizumoto et al., Citation2020). Table reports the daily time series data with number of tested individuals and individuals with positive results.
Table 1. Number of tests and number of individuals testing positive for passengers and crews on the Diamond Princess cruise ship, Yokohama, Japan, February 2020 (n = 3711).
The vessel with confined spaces offered a rare opportunity to understand features of the COVID-19 that are otherwise hard to investigate. This is different from studying the spread in a wider population, where only some people, typically with severe symptoms, are tested and monitored. Closed confines like cruise ship are an ideal place to study how COVID-19 behaves, since almost the whole population and the PCR testing result for everyone are known (Mallapaty, Citation2020). Testing almost all of the passengers and crews helps us to understand a key blind spot in COVID-19 outbreaks. The comprehensive key information on the Diamond Princess allows us to investigate the infection patterns, including infections with no symptoms. Outbreaks seed easily on cruise ships because of the close environments and high proportions of older people, who tend to be more vulnerable to the disease. Since the Diamond Princess, at least 25 other such vessels and aircraft carriers have confirmed a high number of COVID-19 cases (Mallapaty, Citation2020).
Hence, studying the extent of transmission of COVID-19 in encompassed spaces like Diamond Princess cruise is of great importance to understand the disease progression and to manage the epidemic. It has major implications for controlling and anticipating the trajectory and impact of the pandemic. Precise knowledge of the infection distribution is crucial for the prevention and control of these diseases. Correct understanding of the virus transmission pattern might give some guidelines when designing the passenger cabins and making the cruise travel more safe in the future.
The available data on the Diamond Princess have unique features because at the beginning, the upper-respiratory specimens were collected from symptomatic individuals and their close contacts for PCR testing. Starting from February 11, due to the expansion of laboratory capacity, quarantine officers systematically collected respiratory specimens from all passengers by age group, starting with those aged 80 years and older as well as individuals with comorbidities, such as diabetes or a heart condition. This means that a non-random sampling was implemented in the selection for PCR test. In addition, the individual data are not observed. The only available data are the aggregated data, which provides weak information and brings difficulty in statistical inference.
Taking the feature of selection bias and the incomplete aggregated data into account, the main purpose of this paper is to propose a novel mixture model to fully characterize the data structure. We introduce a cure mixture model that combines the nonparametric distribution for the detection time with logistic regression modelling the cure fraction, where the detection time is defined as the time the infected individual begins to be detected by PCR test. The maximum likelihood approach is introduced to jointly estimate the probabilities in nonparametric infection distribution and parameters in logistic regression. The proposed model can also estimate the distribution of detection time and total numbers of infection that can be detected after 14 days of quarantine based on PCR test data performed on the Diamond Princess cruise.
The rest of this paper is organized as follows. Section 2 introduces the proposed cure mixture model and the maximum likelihood estimation approach. The large sample properties, including consistency and asymptotic normality, of the proposed estimator are given in Section 3. Finite sample performances of the proposed estimator are investigated via simulation studies in Section 4. In Section 5, we apply the proposed method to the Diamond Princess cruise ship PCR testing data to illustrate its practical utility. Finally, some remarks are concluded in Section 6. All the technical proofs are relegated to the Appendix.
2. Methodology
2.1. Model
The COVID-19 data collected on the diamond princess cruise were very limited. All information was summarized in Table . The information only includes the number of tests and number of individuals testing positive each day during the quarantine. There were 3711 individuals, including 2666 passengers and 1045 crew members, on the cruise. However, according to Table , the total number of tests is 3063. Therefore, we assume each individual was only tested once and the sensitivity of the test was 100%. We will discuss the limitation in Section 6.
Suppose there are subjects (including passengers and crew members) on the Diamond Princess cruise ship who have experienced a quarantine period that lasted 14 days. Each day a number of subjects were chosen for PCR testing. Let
and
be the number of testing positive cases and number of tests at day i, respectively. This means,
subjects have PCR testing results, but
individuals do not have.
Denote the detection time as the time the infected individual begins to be detected by PCR test. Let be the detection time of the j-th subject who was tested at day i,
. Let
be the cumulative distribution function of detection time ξ calculated from February 4. Therefore
is the probability of the detection time occurring before day i starting from February 4. That is,
is the probability that an infected individual can be detected by PCR test at day i. For example,
represents the probability of testing positive on February 5. According to the non-decreasing property of the distribution function,
should satisfy the constraint
.
In the real data, instead of observing the exact detection time , we observe the number of testing positive individuals
, which is equal to
with conditional expectation
. Let
indicate whether the detection occurred before day i. Then
.
If there is no selection bias, it is a standard current status data problem discussed extensively in the statistical literature, for example, (Sun, Citation2006). The nonparametric likelihood method can be used directly to estimate . The observed likelihood function is
(1)
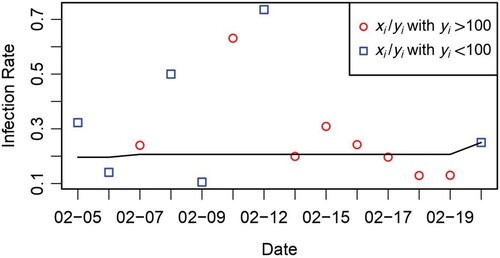
(1) However, Figure shows that the observed frequency and estimated probability on each day have a large discrepancy, especially in the first week. This demonstrates that the random selection process was violated.
Figure 1. Comparison of the observed detection rates and estimated ones if the selection bias is ignored.
represents number of patients that were tested positive at day i, and
is the total number of tests at day i. Scatter points are the rate of
, where red and blue colours differentiate whether
or not. Black line shows the estimated detection rates
.
Next, we provide a novel mixture modelling strategy that fully utilizes the non-random sampling. Before the quarantine, people were unaware of the existence of virus on the Diamond Princess cruise ship. The cruise had shows and dance parties and opened public facilities that attracted large crowds, including fitness clubs, theatres, casinos, bars and buffet-style restaurants. During this period, all passengers and crew members were susceptible to the COVID-19. After the quarantine, people gradually realized the high contagiosity of the virus and began to take actions to avoid the infection. The anti-epidemic measures became stricter as time went on. Passengers with confirmed cases were reported to be taken ashore for treatment. Some individuals even left the cruise in advance. Therefore, it is reasonable to assume some individuals were insusceptible at this stage. Taking the above facts and the incubation period into account, we suppose the detection patterns of the first week and second week of the quarantine period are different. We divide subjects into susceptible and insusceptible individuals and suppose the two weeks have different compositions. All the people in the first week are susceptible, and the proportion of insusceptible individuals in the second week grows.
We assume a cure mixture model (Farewell, Citation1982) for the detection time . Specifically, the mixture modelling of the cure rate assumes a decomposition of the detection time,
(2)
(2) where
denotes the detection time of a susceptible subject, and
indicates, by the value 1 or 0, whether the sampled subject is susceptible or not.
It is worthy notifying that the observed data of most infectious diseases, including COVID-19 on the Diamond Prince cruise ship, are aggregated data. The individual data are unavailable. Therefore, models on specific subjects are impossible to be identified. We have the aggregated data on each testing day. The detection results of each day should follow different patterns, because the anti-epidemic measures became stricter and the insusceptible proportions increased as time went on. Thus, we assume the susceptible proportion and the distribution function of detection time depend only on testing day i. Let , the proportion of susceptible patients among tested subjects at day i. At each day i, we suppose that tested individuals are a mixture of a proportion of
susceptible individuals who eventually get infected and a proportion of
who are not susceptible to COVID-19 and will never get infected. Let
be the distribution function of detection time of a susceptible subject, that is,
. Model (Equation2
(2)
(2) ) is equivalent to
For notation simplicity, we write
.
is the probability that a susceptible infected individual can be detected by PCR test on day i. The proposed model is useful since a proportion of tested subjects will never be infected by COVID-19. This model is like survival models with cure rate, which have arisen in many disciplines (e.g. biomedical sciences, economics, sociology, engineering science, etc) and have received much attention (Lu & Ying, Citation2004; Wang et al., Citation2020).
Motivated by the priority in choosing symptomatic or high-risk groups, all chosen people in the first week were likely to be infected and detected, and the susceptible probabilities maintained a high level nearly 1. Since symptomatic and vulnerable individuals were tested first and some sick individuals disembarked at the end of first week, it is expected that the proportions of non-susceptible individuals became larger as time went by. In other words, starting from the second week, , decrease. We suppose the mixture proportion
varies across i in the logistic form to add model flexibility. Specifically, we assume
, and
(3)
(3) with unknown parameters
and
. It is easy to see that suspectable proportions in the first week are supposed to be the same, and the suspectable probabilities
in the second week have a logistic regression form and decrease as i increases. Different forms of
are designed to account for the data collection difference between the two weeks. Under the proposed model, the true detected number during the quarantine period, N, is
In summary, we formulate a cure model by assuming that the underlying population on the Diamond Princess cruise ship is a mixture of susceptible and non-susceptible subjects. All susceptible subjects are vulnerable to be infected and detected by COVID-19, while the nonsusceptible ones are never infected and detected. Thus, we model separately the detection distribution for susceptible individuals and the fraction of nonsusceptible ones.
2.2. Estimation
The proposed mixture model uses a nonparametric approach to estimate the detection distribution F and a parametric approach to estimate the suspectable proportion λ. Since , the conditional expectation of
is
. The observed data are summarized as
, which are constituted by
independent and identically distributed random replications. The observed likelihood is then written as
Suppose
. The log-likelihood is
We view F as a piecewise constant non-decreasing nonparametric function that only jumps at
. So far we have 16 unknown parameters
and
but only have 14 pairs of observed data. To ensure identifiability, we impose the constraints
and
. Then
The maximum likelihood estimators (MLEs)
are derived by maximizing
, that is,
Then, we can estimate N by
where
for
.
Remark 2.1
We only have 14 days aggregated data, but 28 unknown parameters, ,
,
. To overcome the non-identifiability, we carefully account for the data characteristics, estimate
nonparametrically with two constraints, and impose a parametric model on
. Logistic regression is the most common model for the proportion. The logistic model provides an approximation for the susceptible proportion. We set one regression coefficient as negative to describe the decreasing trend. One may also use other parametric models, for example, the probit model. We have fitted the probit model
to the Diamond Princess cruise ship data and found the estimated number of cumulative infection cases was 1072, which is almost the same with the estimated number 1074 using the logistic model. This shows the robustness and rationality of the imposed assumptions. If we impose strict assumptions on
and constraints on some
, one may also estimate
nonparametrically.
Remark 2.2
The two constraints and
are imposed according to the preliminary data analysis. We can impose other alternative constraints. For example, we assume a Weibull distribution for F which is commonly used in epidemical modelling. Suppose
Maximum likelihood is used for parameter estimation. Applying this parametric approach to the Diamond Princess cruise data, the estimated total infected number at the end of quarantine is 1036, which is quite close to the estimated number using the proposed nonparametric method. This shows the robustness and rationality of the imposed constraints.
3. Asymptotic results
In this section, we give the large sample properties of the proposed estimators. Write
where
.
For notation simplicity, let . Denote the true value of
as
, and denote
as
. The likelihood function
is differentiable with respect to each component of
. Define
,
, where the specific form of
is given in the Appendix.
We impose the following regularity conditions.
| (C1) | The parameter space | ||||
| (C2) |
| ||||
| (C3) |
| ||||
Theorem 3.1
Under the regularity conditions (C1)–(C3), converges to
almost surely.
Theorem 3.2
Under the regularity conditions (C1)–(C3), converges asymptotically to a normal distribution
.
Based on the theoretical results for established in Theorems 3.1 and 3.2, we can follow the delta method to easily get the asymptotic properties of
and
.
4. Simulation studies
In this section, we conduct simulation studies to assess the finite sample performance of the proposed method. We generate data to mimic the PCR testing data on Diamond Princess cruise ship. Specifically, suppose the total number of people (include passengers and crew members) on the cruise for quarantine is . There are 14 pairs of observations
, where
is consisted by the number of total tests each day. The susceptible probabilities
with
,
. Given
,
is generated from Binomial distribution B
with success probability
, where
are set as
=(0.208, 0.208, 0.208, 0.208, 0.208, 0.631, 0.696, 0.696, 0.850, 0.900, 0.950, 0.950, 1.000, 1.000)
.
Under this configuration, the true number of infections is N = 1042. We simulate 500 datasets and use bootstrap to derive estimated standard errors and confidence intervals of the unknown parameters. 100 bootstrap samples are generated based on the nonparametric mixture model with estimated parameters. The 95% confidence intervals (CI) are derived through normal approximation, where the estimated standard errors are calculated as the standard deviation of bootstrap sample estimators.
Table 2. Simulation results.
5. Real data analysis
In this Section, we apply the proposed method to the Diamond Princess cruise data to show its practical utility. We use the time series daily report PCR testing data, including the number of tests and number of patients testing positive each day during the quarantine period, to estimate the distribution of detection time, and the varying proportions of susceptible individuals, along with the total number of infections that can be detected. The data are publicly available, for example, in of Mizumoto et al. (Citation2020).
In the real data, 14 pairs of are observed. As stated in Section 2, we impose the constraints
and
to solve the potential identifiability problem. Under the proposed nonparametric mixture modelling framework, the maximum likelihood estimators (MLEs) are derived by maximizing the joint log-likelihood with time series daily report data. The nlm() function in R is employed to estimate
,
, and
. Let
and
. The proportion of susceptible individuals incorporated in the PCR test at day i,
, can be derived from the logistic regression form with estimated
and
. We use the estimated parameters to simulate bootstrap samples, which include time series daily data of number of tests and confirmed cases. 200 bootstrap samples are generated to estimate the standard errors, and the confidence intervals are based on normal approximation. Table lists the estimators
,
,
,
, the corresponding estimated standard errors and confidence intervals. The estimated
is about 0.2 and
is close to 1 (Table ), which means that about 20% of susceptible individuals will be detected at the beginning of quarantine. And 9 days later, all the susceptible individuals on the board will be detected.
Table 3. MLEs and the corresponding confidence intervals in real data analysis.
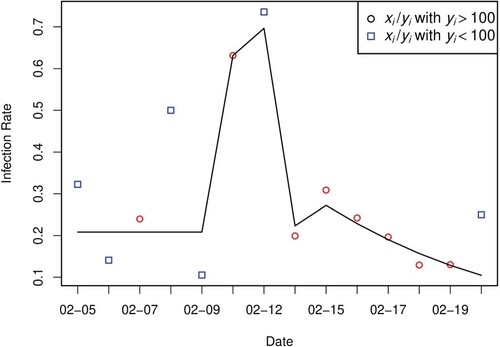
Figure presents the observed detection rates (scatter points), along with the fitted detection rates
(black solid line). We use different colours and different symbols to demonstrate
with
or
, respectively. For example, red circles represent scatter points
with
, while blue squares describe scatter points
with
. Figure suggests that the estimated nonparametric distribution
and the parametric susceptible proportion
characterize the pattern of detection quite well. This shows the plausibility of the assumption that
decreases with i in the logistic regression form.
In contrast to the officially reported 634 individuals with PCR-positive results after the 14 days quarantine, which as of April 27, 2020 had increased to 712 as released by the Johns Hopkins University, we conclude that the estimated total number should be 1064. Zhang et al. (Citation2020) used a completely different method to estimate the reproductive number (R0) of the novel virus in the early stage of the outbreak and estimate the cumulative cases on the ship. They estimated the cumulative cases as 1514 (1384–1656) if the R0 value remained 2.28 as the early stage on the ship. If R0 value was reduced by 25% and 50%, the estimated total number of cumulative cases would be reduced to 1081 (981–1177) and 758 (697–817), respectively. A great deal of the transmission on the ship had occurred before the quarantine when people were even not notified about the virus. As the containment measures became stricter, it is expected that the R0 value reduced. We estimated the total number as 1064 (984–1144), which is almost in accordance with the number when the R0 value was reduced by 25%.
Figure 2. Comparison of the observed detection rates and fitted ones based on the proposed nonparametric mixture model.
represents number of patients that were tested positive at day i, and
is the total number of tests at day i. Scatter points are the rates of
, where red and blue colours differentiate whether
or not. Black line shows the fitted detection rates
.
6. Concluding remarks
In this paper, motivated by the real PCR testing data on the Diamond Princess cruise ship, we propose a novel mixture model to estimate the distribution of detection time among susceptible subjects and the susceptible proportion among tested people each day. As a by-product, the total number that can be detected after the quarantine period is estimated as 1064, which means that 42.5% of infected cases were undetected on the cruise. The estimated number 1064 is larger than the released 712. The discrepancy might be caused by the false-negative result of the PCR test (Kucirka et al., Citation2020) or the occurrence of infection after the test. Some asymptomatic cases may be missed due to the imperfect sensitivity of the PCR test, and they had the high transmissibility. We conclude that COVID-19 spread in the cruise ship is easier and faster than in open spaces. Strict containment efforts should be scaled up prior to local outbreak.
Like all medical papers, we have to acknowledge the possible weakness in our approach. The COVID-19 data collected on the Diamond Princess cruise were very limited. All information was summarized in Table . We assume that each selected individual was tested by PCR only once and assume that the sensitivity of the test was 100%. This might be not true because small proportion of individuals may be tested twice or more, and there may be false positives. Our method should be modified if additional relevant testing information was available. Nevertheless, we believe our approach has at least reduced the possible bias in the data collection process, though our solution may not be a perfect one. We would be happy to read other innovative approaches from other authors in the future. During the outbreak of a pandemic, it would be useful to make quick statistical inference based on very limited information, though, it may not be a very accurate one. Besides, in the second week of the quarantine, the number of symptomatic and asymptomatic patients testing positive was publicly available. However, we did not take these information into consideration. Incorporating such data in statistical modelling warrants future research.
Acknowledgments
The authors thank the Editor, Professor Jun Shao, an Associate Editor and three reviewers for their insightful comments and suggestions that greatly improved the article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Farewell, V. T. (1982). The use of mixture models for the analysis of survival data with long-term survivors. Biometrics, 38(4), 1041–1046. https://doi.org/10.2307/2529885
- Kucirka, L., Lauer, S., Laeyendecker, O., Boon, D., & Lessler, J. (2020). Variation in false-negative rate of reverse transcriptase polymerase chain reaction–based SARS-CoV-2 tests by time since exposure. Annals of Internal Medicine, 173(4), 262–267.
- Lu, W., & Ying, Z. (2004). On semiparametric transformation cure models. Biometrika, 91(2), 331–343. https://doi.org/10.1093/biomet/91.2.331
- Mallapaty, S. (2020). What the cruise-ship outbreaks reveal about covid-19. Nature, 580(18). doi: 10.1038/d41586-020-00885-w.
- Mizumoto, K., Kagaya, K., Zarebski, A., & Chowell, G. (2020). Estimating the asymptomatic proportion of coronavirus disease 2019 (COVID-19) cases on board the diamond princess cruise ship, Yokohama, Japan, 2020. Eurosurveillance, 25(10), 2000180. https://doi.org/10.2807/1560-7917.ES.2020.25.10.2000180
- Sekizuka, T., Itokawa, K., Kageyama, T., Saito, S., Takayama, I., Asanuma, H., Naganori, N., Tanaka, R., Hashino, M., & Takahashi, T., et al. (2020). Haplotype networks of SARS-CoV-2 infections in the diamond princess cruise ship outbreak. Proceedings of the National Academy of Sciences, 117(33), 20198–20201. https://doi.org/10.1073/pnas.2006824117
- Sun, J. (2006). The statistical analysis of interval censored failure time data. Springer.
- van der Vaart, A., & Wellner, J. (1996). Weak convergence and empirical processes: with applications to statistics. Springer.
- Wang, Y., Zhang, J., & Tang, Y. (2020). Semiparametric estimation for accelerated failure time mixture cure model allowing non-curable competing risk. Statistical Theory and Related Fields, 4(1), 97–108. https://doi.org/10.1080/24754269.2019.1600123
- Zhang, S., Diao, M., Yu, W., Pei, L., Lin, Z., & Chen, D. (2020). Estimation of the reproductive number of novel coronavirus (COVID-19) and the probable outbreak size on the diamond princess cruise ship: A data-driven analysis. International Journal of Infectious Diseases, 93, 201–204.
Appendix
Proof of Theorem 3.1.
Proof of Theorem 3.1.
Write
where
,
is a 14-dimensional vector with
where the last two equalities hold since
and
for
.
It is easy to show that , where
. According to the regularity condition (C1),
is a Glivenko–Cantelli class (van der Vaart & Wellner, Citation1996). It follows from the Glivenko–Cantelli theorem (van der Vaart & Wellner, Citation1996) that
(A1)
(A1) almost surely. Note that
is the maximizer of
, and
is differentiable in terms of
. Hence
. This, combined with (EquationA1
(A1)
(A1) ), implies that
. Then, according to the regularity condition (C3),
converges to
almost surely.
Proof of Theorem 3.1.
Proof of Theorem 3.2.
Expanding the first derivative of around the true value
, we get
(A2)
(A2) where
lies between
and
, and the last equality follows from the continuity of
. Note that
as
, where
,
. According to the regularity condition (C1) and the law of large numbers,
, where each element of the matrix
is given as follows:
Write
(A3)
(A3) where
. By the regularity condition C1 and the Central Limit Theorem,
converges asymptotically to Normal distribution
, where
. According to the properties of the likelihood function, we can easily show that
. Then, it follows from (EquationA2
(A2)
(A2) ) and condition (C2) that
converges asymptotically to normal distribution
.