
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose two simple regression models of Pearson correlation coefficient of two normal responses or binary responses to assess the effect of covariates of interest. Likelihood-based inference is established to estimate the regression coefficients, upon which bootstrap-based method is used to test the significance of covariates of interest. Simulation studies show the effectiveness of the method in terms of type-I error control, power performance in moderate sample size and robustness with respect to model mis-specification. We illustrate the application of the proposed method to some real data concerning health measurements.
1. Introduction
Most regression models have been developed to describe the relationship between the expected value of response(s) and a number of covariates (predictors). In some situations, it is desired to understand the influence of covariates on the strength of Pearson correlation between two responses. For example, in some psychological study, it is of interest to understand the impact of age and/or sex on the association between physical functionality and mental functionality of the elder (Thomas et al., Citation2016).
One traditional measure for such association is the partial correlation coefficient, i.e., the correlation coefficient of two responses after removing the covariate effect (Anderson, Citation2003). However, its inference depends on the normality assumption and it misses the connection to the actual values of the covariates which is supposed to have different effects on the association. In terms of the rank-based counterpart, Liu et al. (Citation2018) proposed covariate-adjusted partial Spearman's rank correlation using probability scale residuals, which is particularly useful for ordinal responses.
Another method is to use a conditional approach to assess the correlation at different levels of the covariates. Bartlett (Citation1993) proposed to model the Fish z-transformed correlation by a polynomial regression of a single covariate z. His model builds a linear regression up on paired observations of ,
, where
is the sample correlation coefficient of two responses at
over K distinct levels of z. One clear drawback of this method is that it requires repeated measures of responses at
, which would lead to the demand of a large total sample size and even larger when multiple covariates are included. Other studies along this direction include Yu and Dunn (Citation1982) and Paul (Citation1989). Wilding et al. (Citation2011) proposed a model to relate a transformed correlation coefficient of two normal responses (
and
) with a linear combination of covariates (
) through the probit link, i.e.,
, where
and Φ is the distribution function of the standard normal variable. (Restricted maximum likelihood corrected LRT is used to test the significance of covariates.) We point out that the linear transformed correlation
guarantees the range for a distribution function. However, it can lose efficiency when ρ is known positive (since it can be modelled directly without transformation).
All the aforementioned methods consider the continuous responses. In many situations, there are only binary responses available, e.g., after dichotomization. In this paper, we propose two simple regression models of Pearson correlation coefficient of two normal responses and two binary responses (Section 2). Specifically, when the correlation coefficient is known positive, the logistic link function is used and when the correlation coefficient is arbitrary in , the hyperbolic tangent (or Fisher z-transformation) link function is used. Likelihood-based inference is developed to estimate the regression coefficients (Section 3). We demonstrate the performance of the proposed method by simulation in Section 4 and illustrate the applications in great detail to a real data concerning physical functionality and mental functionality of the elder (Section 5). We defer the technical details in Appendix.
2. Model
Let be a pair of responses of a subject with correlation coefficient
. Let
denote p associated covariates of the paired responses, which follow a joint distribution
. Consider modelling ρ as a monotonic function of the linear combination of these covariates through
(1)
(1)
where
and
. When
, we use the logistic function
, referred by link 1. When
, we use the hyperbolic tangent function
, referred by link 2. We adopt these two commonly used link functions to map the real line to intervals
and
, respectively, as they are analytically simple. Other links can also be used, e.g., the probit link for
. When the correlation is known positive, the logistic function is preferred as it is more efficient for estimation and easy for interpretation. Let
and
denote the first and second derivatives of h, respectively. Our goal is to assess model (Equation1
(1)
(1) ).
2.1. Bivariate normal responses
Assume that and
follow a bivariate normal distribution with marginal distributions
and
, respectively. For j = 1, 2, we further model the expected value of
by a linear regression, i.e.,
where
. Denote
as the collection of all nuisance parameters.
The log-likelihood function is
(2)
(2)
where
(3)
(3)
, and
. The first and second derivatives of ℓ with respect to
are, respectively
(4)
(4)
where a, b, c, u, v and w are given in Table . By the fact that
and
, we have
, where
is the zero vector.
Table 1. Some functions under two link functions.
2.2. Bivariate binary responses
Assume that both and
are binary responses. Let
and
. For a, b = 0, 1, let
, where
is the indicator function, and
. Clearly,
. By definition, we have
Inversely, given
,
and ρ, we can obtain
(5)
(5)
For j = 1, 2, we further model the expected value of
by a logistic regression through
, where
is as defined in Section 2.1. Denote
. (Through (Equation1
(1)
(1) ) and (Equation5
(5)
(5) ),
is a function of
.)
By (Equation5(5)
(5) ), the log-likelihood is
where
Then, the first and second derivatives of ℓ with respect to
are, respectively
(6)
(6)
where
The detailed expressions of
and
under the two models of h are given in Appendix. When
, we have
.
3. Inference
Let denote independent samples of
of size n. For
and j = 1, 2, denote
,
,
and
.
The gradient (first derivative) and the Hessian matrix (second derivative) of the log-likelihood over n independent samples with respect to are
and
, respectively, where
and
are obtained by replacing
in (Equation4
(4)
(4) ) or (Equation6
(6)
(6) ) by
for the ith subject.
In addition, let . Denote
and
, where the expectation is taken with respect to the joint distribution of
. Let
denote the Fisher information matrix with respect to
. It is noted that unlike the usual regression of the mean value of response, the regularity condition does not hold for the model (Equation1
(1)
(1) ) (Tsiatis, Citation2006, Theorem 3.2). (It can be easily verified that
.)
Let be the maximum likelihood estimate (MLE) of
obtained from the marginal models. For instance, the marginal MLEs of the nuisance parameters under the bivariate normal response case are
,
, where
. By large sample theory, we have
and
, where
is the covariance matrix.
Next, we estimate by using the Newton–Raphson method through iterating
(7)
(7)
where
is the estimate of
at the rth iteration. The convergence of Newton–Raphson method depends on the initial point and the negative definitiveness of the Hessian matrix, which guarantees the (unique) global maximizer of the log-likelihood function. The initial estimate
can be chosen such that
is in the range of ρ. However, the Hessian matrix involves the plug-in estimators of the nuisance parameters. It is not trivial to show its negative definitiveness theoretically. Nevertheless, numerical study shows the condition holds with all eigenvalues being negative. Denote the root of the Newton–Raphson method by
.
Theorem 3.1
Suppose that the conditions of Lemma A.1 for the bivariate normal responses or those of Lemma A.2 for the bivariate binary responses hold. Lemmas A.1 and A.2 are given in Appendix.
Suppose the iteration (Equation7
(7)
(7) ) converges. (i)
is a consistent estimator of
, i.e.,
, and (ii)
, where Σ is the covariance matrix given in the proof.
The significance of the overall model is assessed by testing the hypothesis . Denote the Wald statistic
, where
and
is the estimate of the covariance of
. By Theorem 3.1, under the null hypothesis, W follows a chi-square distribution of degrees of freedom p asymptotically. The significance of individual covariate
(
) is assessed by testing the hypothesis
using the statistic
, where
is the estimate of the standard deviation of
, which is the square root of the
th element of
. The null distribution of
is asymptotically standard normal. Since the exact expression of Σ is rather complicated, we use bootstrap to estimate it in practice.
4. Simulation study
We conduct simulations to examine the performance of the proposed model for making inference in estimation and testing.
4.1. Setup
Unlike possible large numbers of covariates for the mean model, a small number of relevant covariates are usually adequate for modelling the correlation coefficient. Consider the number of covariates p to be two and three, respectively. Set the sample size n to be 100, 200, 400 and 1000, respectively.
For bivariate normal responses, set the marginal variances . For both bivariate normal responses and bivariate binary responses, we set both
and
to be a vector of p + 1 zeros for the marginal mean models. It simplifies the data generation without simplifying the estimation procedure. Let
be independent uniform random variables in (0,1).
For the correlation coefficient model, set . Under the nonnull model, set
,…,
under two link functions as in Table , where only the first covariate is significant. Under the null model, simply set all
to be zeros. We set
as the initial values for
under both link functions.
Table 2. Specifications of under p = 2, 3 and two link functions.
Throughout, we set the significant level to be 0.05 for both the global test and individual test, and set the number of replications, B, to be 1000.
4.2. Results
First, denote the empirical root of mean square error of by
, where
is the estimate of
in the bth replication. It measures the performance of the estimation in terms of magnitude. Second, denote the directional consistency rate (CR) by
, where
is the true correlation coefficient in the bth replication and
. It measures the performance of estimation in terms of sign direction.
Table presents the type-I error of the global test and individual tests under the null model. It is seen that the proposed resampling test controls the type-I error well at the nominal level.
Table 3. Type-I errors (in %) of the global test (for the model significance) and individual test (for the significance of the covariates) under two types of responses, two link functions and various sample sizes.
Columns 4–5 and 9–10 of Table present the ERMSE and CR under the nonnull model considered in Section 4.1. It is seen that as the sample size increases the ERMSE decreases while the CR increases as expected. The CR ranges from 85% to 100% indicating that the proposed model yields a good fit in the sign direction of the correlation coefficient. Columns 7–9 and 12–15 of Table present the powers of the global test and individual tests of the covariates. It is seen that both the global test and the individual test for the significant covariate (i.e., ) gain power as the sample size increases as desired. The rejection rates for the insignificant covariates (i.e.,
and
) are close to the nominal level as desired. We note that the power performance depends on the actual model. In general, we see the proposed method works well under moderate sample size.
Table 4. ERMSE, CR and testing power of β's of models considered in Table with various sample sizes.
4.3. Sensitivity analysis
We adopt the simulation model from Wilding et al. (Citation2011) for bivariate normal responses, where ,
and their correlation coefficient is given by
with
being a uniform random variable in
. Consider
to be 0, 0.5 and 1, respectively, to represent the null case and two nonnull cases. Set n to be 30, 60 and 150, respectively.
We compute the rejection rate for testing the significance of using the proposed method with link 2 in comparison with Wilding et al. (Citation2011)'s method by which the model is correctly specified. This serves as a sensitivity analysis under model mis-specification. Table reports the rejection rates under the considered cases. It is seen that under the null case when
the proposed method controls the type-I error well. Under the nonnull cases when
and 1 the proposed method is less powerful than Wilding et al.'s method when the sample size is 30 and becomes comparable in power when the sample size gets larger (
).
Table 5. Rejection rates (in %) of Wilding et al. (Citation2011)'s method and the proposed method for testing the significance of the covariate.
5. Real data application
Our data are taken from the survey of National Health Measurement Study in 2005–2006 (Fryback, Citation2009). It collects responses to health-related quality of life questionnaires and health status questions through Short Form SF-36 questionnaires from 3844 older adults in the continental United States (1641 males and 2203 females).
5.1. Bivariate normal responses
First, we illustrate the application of the proposed model to the bivariate normal responses case. The SF-36 items were aggregated into eight health concepts, which were further summarized into the physical component summary (PCS) and the mental component summary (MCS), both in the range of with higher scores indicating better physical and mental health functions, respectively [28]. Several medical studies showed that the PCS declined significantly with age, but that the MCS did not change with age (Kim, Citation2016; Ware Jr et al., Citation1994). To continue along these lines, we applied the proposed method to further investigate the effect of gender and marital status. We used the Fisher z-transformation (i.e., tanh link) to accommodate negative value of correlation. The estimate model for the correlation between PCS and age is found to be
where MARRIED is 1 if married or living with a partner and 0 otherwise, and SEX is 1 if female and 0 if male. The corresponding p-values for marital status and gender are
and 0.592, respectively, indicating strong significance of marriage and insignificance of gender. The negative coefficient of MARRIED implies that the status of being married or living with a partner aggravates the declination of PCS with age (
for people married or living with a partner and
for people living by themselves). In other words, the people who are married or living with a partner have relatively lower physical functionality than the people who live by themselves when they age in general. On the other hand, our model concurred with the conclusion of insignificant correlation between MCS and age. In addition, neither gender nor marital status has significant effect on this correlation. (The details are omitted.)
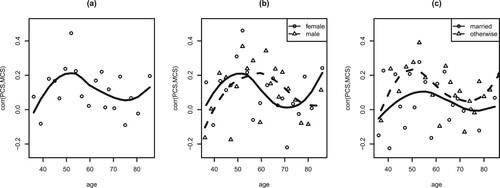
Moreover, we applied the proposed model to study the age effect on the correlation of PCS and MCS. (Throughout this section the observations of age are standardized, denoted by AGE, before fitting the model as covariate.) Insignificant result is found and supported by the visual inspection of the correlations over 20 age intervals determined by the percentiles (Figure (a)). This result is different from the finding of Wilding et al. (Citation2011), who showed a nonlinear downward trend of the correlation coefficient over age based on the 2003–2004 Health Outcome Survey data. When we further include gender and marital status as covariates, there is no significant gender effect either (p-value 0.312) as also seen in Figure (b). However, there appears a very mild effect of marital status (p-value 0.236) in the way that the status of being married or living with a partner slightly reduces the correlation from otherwise slight positive to the level of near zero (Figure (c)). (The fitted model is
.)
Figure 1. (a) Correlation of PCS and MCS over 20 age groups, (b) correlation of PCS and MCS over 20 age groups with different genders, (c) correlation of PCS and MCS over 20 age groups with different marital status.
5.2. Bivariate binary responses
Second, we applied the proposed method to model the correlation of two binary indicators of stroke (STR) and diabetes (DIA) using the covariates of age, gender and marital status. Since the correlation is known positive, the logistic link is used. The estimated model which includes the second-order age effect is
with strong significance of the linear age effect (p-value
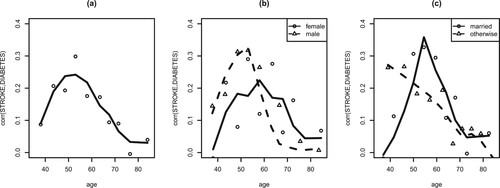
) and marriage effect (p-value 0.028) and insignificance of the second-order term of age (p-value 0.786) and gender effect (p-value 0.675). It is seen from Figure (a) that the correlation exhibits a parabola shape in age where the largest value (about 0.25) occurs around age 55 and then starts to decline afterwards. This indicates that the association of stroke and diabetes is strongly age dependent. The diabetes becomes a less significant risk factor to stroke after a certain age, e.g., 70 (Kim, Citation2016). The status of married or living with a partner contributes significantly to the positive correlation (0.145 for married vs 0.106 for otherwise) especially for people who are more than 50 years old (Figure (c)), which could be explained by the evidence of low physical functionality found before.
Figure 2. (a) Correlation of STROKE and DIABETES over 10 age groups, (b) correlation of STROKE and DIABETES over 10 age groups with different genders, (c) correlation of STROKE and DIABETES over 10 age groups with different marital status.
6. Concluding remarks
We propose two simple regression models of Pearson correlation coefficient of two continuous responses or two binary responses. Likelihood-based inference is developed to estimate the model and test the significance of covariates. Our method for the binary response case is new to the literature and is useful for analysing data when outcomes are observed in binary form (such as yes or no) as seen in many psychological and sociological studies. The proposed method is easy to implement and computationally affordable. (The Newton–Raphson iteration converges in a few steps.) We have made R package available upon request.
It is noted that for the binary response case, the correlation ρ actually has a restricted range given by , where
and
(Qaqish, Citation2003). A more precise model than the Fisher z-transformation is warranted to further improve the efficiency.
The limitation of the present paper is that the proposed method does not handle the case of mixed responses, i.e., one continuous response and one binary response, or more generally an ordinal response categorized from a latent variable, such as ‘mild’, ‘moderate’, ‘severe’. Regression model of correlation involving latent variable(s) is worth investigation. We will report the result in a separate work.
Disclosure statement
All authors declare no conflict of interest.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon request.
References
- Anderson, T. (2003). An introduction to statistical multivariate analysis. 3rd ed. Wiley.
- Bartlett, R. F. (1993). Linear modelling of Pearson's product moment correlation coefficient: An application of Fisher's z-transformation. Journal of the Royal Statistical Society: Series D, 42(1), 45–53.
- Fryback, D. G. (2009). United States National Health Measurement Study, 2005-2006. Inter-University Consortium for Political and Social Research.
- Kim, D. (2016). Correlation between physical function, cognitive function, and health-related quality of life in elderly persons. Journal of Physical Therapy Science, 28(6), 1844–1848. https://doi.org/10.1589/jpts.28.1844
- Liu, Q., Li, C., Wanga, V., & Shepherd, B. E. (2018). Covariate-adjusted Spearman rank correlation with probability-scale residuals. Biometrics, 74(2), 595–605. https://doi.org/10.1111/biom.v74.2
- Newey, W. K., & McFadden, D. (1994). Large sample estimation and hypothesis testing. Handbook of Econometrics, 4, 2111–2245. https://doi.org/10.1016/S1573-4412(05)80005-4
- Paul, S. (1989). Test for the equality of several correlation coefficients. Canadian Journal of Statistics, 17(2), 217–227. https://doi.org/10.2307/3314850
- Qaqish, B. F. (2003). A family of multivariate binary distributions for simulating correlated binary variables with specified marginal means and correlations. Biometrika, 90(2), 455–463. https://doi.org/10.1093/biomet/90.2.455
- Thomas, P., Jolanda, L., Antonius, J. M. d. C., Joris, P. J. S., & Rudi, G. J. W. (2016). Impact of physical and mental health on life satisfaction in old age: A population based observational study. BMC Geriatrics, 16(1), 194. https://doi.org/10.1186/s12877-016-0365-4
- Tsiatis, A. A. (2006). Semiparametric theory and missing data. Springer.
- Ware Jr, J. E., Kosinski, M., & Keller, S. D. (1994). SF-36 physical and mental summary scales: A user's manual. The Health Institute, New England Medical Center.
- Wilding, G. E., Cai, X., Hutson, A., & Yu, Z. (2011). A linear model-based test for the heterogeneity of conditional correlations. Journal of Applied Statistics, 38(10), 2355–2366. https://doi.org/10.1080/02664763.2011.559201
- Yu, M., & Dunn, O. (1982). Robust tests for the equality of two correlation coefficients: A monte carlo study. Educational and Psychological Measurement, 42(4), 987–1004. https://doi.org/10.1177/001316448204200407
Appendix. Technical details
A.1. Details of  and
and
The expressions of and
under two link functions of h are, respectively
and
A.2. Lemmas
Lemma A.1
Assume that under the bivariate normal response model in Section 2.1, there exist constants ,
,
, and
such that
,
,
for j = 1, 2. Then, (i)
, and (ii)
.
Proof.
Note that we cannot apply the weak law of large number as s and
s are neither independent nor identically distributed.
(i) Let and
. First, by the assumptions of
and
for j = 1, 2, we have
Second, by the assumption of
, there exists a positive constant
such that
,
, and
are all bounded by
. Since
, then, there exists a function
such that
and
, where
is the Euclidean norm (i.e.,
). Clearly,
is continuous in
.
By Lemma 2.4 of Newey and McFadden (Citation1994), we have . Since
(because
and
is between
and
),
and Θ is continuous in
, by Tsiatis (Citation2006, Section 3.2), the result of (i) follows.
(ii) By (Equation2(2)
(2) ) and (Equation3
(3)
(3) ), we have
and
By the assumptions, we can find a function
such that
and
. And
is continuous in
. Using the similar argument as in the proof for (i), by Lemma 2.4 of Newey and McFadden (Citation1994)
. Since
and
is continuous in
, the result of (ii) follows.
Lemma A.2
Assume that under the bivariate Bernoulli response model in Section 2.2 there exist constants such that
,
for all
,
, for j = 1, 2,
. Then, (i)
, and (ii)
.
Proof.
(i) By the assumptions, there exists such that
for all a, b = 0, 1 and
. Then, there exists a function
such that
and
. Clearly,
is continuous in
. By Lemma 2.4 of Newey and McFadden (Citation1994),
.
Since ,
and Θ is continuous in
, by Tsiatis (Citation2006) Section 3.2, the result of (i) follows.
(ii) Observe that
By the logistic model defined in Section 2.2,
. The expressions of
and
are obtained as follows.
By the assumptions, we can find a function
such that
and
. And,
is continuous in
. Using the similar argument as in the proof for (i), by Lemma 2.4 of Newey and McFadden (Citation1994)
. Since
in probability and
is continuous in
, the result of (ii) follows.
A.3. Proof of Theorem 3.1
By the standard theory of regression, we have .
By the fact that solves
, expand
(with respect to
) around
as
(A1)
(A1)
where
is between
and
component-wise.
Second, expand (with respect to
) around
as
(A2)
(A2)
where
is between
and
component-wise.
Combining (EquationA1(A1)
(A1) ) and (EquationA2
(A2)
(A2) ),
is expressed as
(A3)
(A3)
By Lemma A.1 for the bivariate normal response case or Lemma A.2 for the bivariate Bernoulli response case,
(A4)
(A4)
And by the central limit theorem,
. Then, by Slusky theorem,
(A5)
(A5)
and
(A6)
(A6)
Combining (EquationA3
(A3)
(A3) ), (EquationA5
(A5)
(A5) ), and (EquationA6
(A6)
(A6) ),
is asymptotically normal with zero mean vector and covariance matrix given by