
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The two-parameter Waring is an important heavy-tailed discrete distribution, which extends the famous Yule-Simon distribution and provides more flexibility when modelling the data. The commonly used EFF (Expectation-First Frequency) for parameter estimation can only be applied when the first moment exists, and it only uses the information of the expectation and the first frequency, which is not as efficient as the maximum likelihood estimator (MLE). However, the MLE may not exist for some sample data. We apply the profile method to the log-likelihood function and derive the necessary and sufficient conditions for the existence of the MLE of the Waring parameters. We use extensive simulation studies to compare the MLE and EFF methods, and the goodness-of-fit comparison with the Yule-Simon distribution. We also apply the Waring distribution to fit an insurance data.
1. Introduction
The power-law distributions are a class of heavy-tailed univariate distributions that describe a quantity whose probability decreases as a power of its magnitude, which is widely used in social science, network science and so on. Two commonly used discrete examples are Zipf distribution and Yule-Simon distribution (or Yule distribution). Zipf law is found by the linguist Zipf when studying the words in a linguistic corpus, in which the frequency of a certain word is proportional to , where r is the corresponding rank and d is some positive value. The Yule-Simon distribution is a highly skewed discrete probability distribution with very long upper tails, named after Udny Yule and Herbert Simon–winner of the 1978 Nobel Prize in economics, with distribution function
where
is the Gamma function, and α is the parameter. Yule (Citation1925) proposed the distribution first, applying it to model the number of species in the biological genera. Simon (Citation1955) rediscovered the ‘Yule’ distribution later, using it to examine city populations, income distributions, and word frequency in publications (Mills, Citation2017). In Price (Citation1965, Citation1976), Price, a famous American scientist, found that the number of citations of the literature follows the Yule distribution, when linking the published literature with his cited literature to form a directed network of scientific and technological literature. It is a cumulative advantage distribution based on the mechanism of ‘success breeds success’.
The two-parameter Waring distribution is a generalization of the Yule-Simon distribution, which provides more flexibility than the commonly used one-parameter Zipf distribution, Yule-Simon distribution, negative binomial distribution, etc. The Waring distribution can describe a wide variety of phenomena in actuarial science, network science, library and information science, such as number of shares purchased by each customer, number of traffic accidents, number of nodes in the internet connections, and frequency of authors who publish a certain number of paper (Huete-Morales & Marmolejo-Martín, Citation2020; Panaretos & Xekalaki, Citation1986; Seal, Citation1952; Xekalaki, Citation1983). The distribution function of is given by
(1)
(1) where
are the parameters of the Waring distribution. It is easy to prove that the Waring distribution is a heavy-tailed distribution, with a polynomial tail of order
. We can also derive that
if
, and
if
. The Yule-Simon distribution is a special case of the Waring distribution with
.
The parameter estimation is extremely important to make a statistical inference. Garcia (Citation2011) provided a fixed-point algorithm to estimate the Yule-Simon distribution parameter. For the Waring distribution, a commonly used method is the EFF (Expectation-First Frequency), which is essentially the method of moments. More specifically, the EFF method uses the sample mean to estimate
and the empirical first frequency
to estimate
, leading to
The EFF method has two drawbacks: first, it restricts that
, which can not be used when the first moment does not exist; second, it only uses the information of
and
, which loses information of the data. Xekalaki (Citation1985) proposed a factorial moment estimation for the bivariate generalized Waring distribution, which also suffers from these drawbacks.
In the current literature, researchers also considered the maximum likelihood estimator (MLE) of the Waring parameters. However, they usually directly applied the optimization algorithm to the log-likelihood function, without verifying the existence of the MLE (Rivas & Campos, Citation2021). As we all know, MLE does not exist in all cases. In fact, for some sample data, the MLE of Waring parameters exists, while for some sample data, it does not exist. For example, in the insurance share data analysed in Section 4, the MLE of the Waring parameters does not exist for the groups with central ages 17.5, 22.5 and 67.5; for each group, the age length equals 5. If we do not know whether MLE exists and we calculate it, then it is questionable to show the credibility of MLE. Based on this consideration, the existence of MLE will be investigated in this paper. More specifically, we apply the profile method to the log-likelihood function, deriving the necessary and sufficient conditions for the existence of the MLE of the Waring parameters. When the largest value in the observed sample is small, we also verify our theory by exactly solving the estimating equation system. Furthermore, we get two byproducts during the proof of the main result. The first one is our Lemma 2.3, which provides an alternative way to prove the existence of MLE for two parameters, while the conventional proof includes a complicated calculation of the Hessian matrix. The second one is our Lemma 2.4, which provides a comparison method for two increasing and concave functions. These results may play a role in other applications.
Through extensive simulation studies, we find that when the sample size is as small as n = 100, both MLE and EFF yield relatively poor estimates. When , MLE always results in much smaller biases than EFF; the relative bias of MLE decreases from 6%-7% when n = 200 to around 1% when n = 1000, while that of EFF is still around 10% even when n = 1000 for
. The relative standard errors from MLE are comparable with those from EFF for medium-sized samples (n = 200 and 400), but smaller for n = 1000. Overall, the MLE method results better performance than the EFF method when
is not large or the sample size is large enough. The performance of EFF is relatively better when
is large, say
. Our explanation is that, since
, if
is large, then
is close to 1, and thus EFF includes relatively more information than the case with small
. We also compare the Waring distribution and Yule-Simon distribution in terms of goodness-of-fit to the data, and we find that the Waring distribution fits the data similar to the Yule-Simon distribution when
, and much better when β departs from 1.
The rest of the paper is organized as follows. Section 2 presents the main result based on the profile method. Section 3 gives some numerical studies to show the advantage of MLE over the EFF method, and that of Waring distribution over the Yule-Simon distribution. The real insurance data analysis is presented in Section 4. All technical details are deferred to the Appendix.
2. Maximum likelihood estimator of the Waring parameters
For the two-parameter Waring distribution, we have
Suppose that
is a random sample from the Waring distribution
, and let
be the largest observe value,
be the number of observations equal to k,
, and
. Based on the data
, we can easily derive the likelihood function as
Then the log-likelihood is
(2)
(2) Taking partial derivatives with respect to α and β leads to the following maximum likelihood equations
(3)
(3)
(4)
(4) where
with
.
We first consider Equation (Equation3(3)
(3) ), which can be treated as the conditional maximum likelihood equation of α given a positive β. When m = 1, that is, all the observed values equal to 1, since
, thus there is no solution to the likelihood equation. We focus on the situation where
.
In the following, we first consider the conditional maximum likelihood Equation (Equation3(3)
(3) ) given any positive β, which can be regarded as a generalization of the Yule-Simon distribution, and we prove that those results for Yule-Simon distribution (
) also hold for any
. More specifically, given a positive β, we denote the conditional MLE of α as
. According to (Equation3
(3)
(3) ),
satisfies
(5)
(5) For notational ease, we define
(6)
(6) and present the properties of
in the following Proposition 2.1.
Proposition 2.1
Let be defined as in (Equation5
(5)
(5) ). We have the following properties.
Property 1. If
, we have
Property 2. If
Property 3.
Property 4. The first derivative
Property 5. When
Next we discuss the existence of MLE of . By (Equation3
(3)
(3) ), we have
(7)
(7) By (Equation4
(4)
(4) ), we have
Let
(8)
(8) If the curves
and
intersect at some
, we have solution to the equation system (Equation3
(3)
(3) )–(Equation4
(4)
(4) ). Later we prove that the intersection is unique and is the MLE of the Waring distribution.
To discuss whether and
intersect at some
, we first present the properties of
in the following proposition.
Proposition 2.2
Let be defined as in (Equation8
(8)
(8) ), we have the following properties.
Property 1*. If
Property 2*. If
Property 3*.
Property 4*. The first derivative
Property 5*. When
Based on Properties 1 and 4 of Proposition 2.1 and 1* and 4* of Proposition 2.2, it is easy to derive that when β is small. Therefore, if we can prove that
for some large β, due to the continuity of the two functions, there must exist solution to the equation systems (Equation3
(3)
(3) )–(Equation4
(4)
(4) ). This is the key idea to check the existence of the MLE.
Before presenting the main result, we first give two important lemmas.
Lemma 2.3
For the log-likelihood function , assume that for any β,
, and there exists
such that
,
for
and
for
. Then we have
.
Lemma 2.3 provides an alternative to the proof of MLE based on the profile method, which is simpler than the conventional proof that includes complicated calculation of the Hessian matrix.
Lemma 2.4
Assume that and
are increasing and concave functions for x>0, the curves
and
only intersect finite times, and the number of solutions to
is finite for both i = 1, 2, where
is any polynomial or fractional function of x. Further assume that
there exists some
there exists
Then, we have for all
.
Lemma 2.4 provides a general method to compare two increasing and concave functions, without requiring the explicit form of the functions, which not only simplifies the comparison of and
, but also has its own value in other applications.
Based on Propositions 2.1–2.2, Lemmas 2.3–2.4, we summarize the existence of MLE in the following Theorem 2.5.
Theorem 2.5
Suppose that is a random sample from the Waring distribution
, and
. Let
be the proportion of
with
. Let
If
If
If
To derive the necessary and sufficient conditions of MLE existence, we start form the conditional MLE of α for a given β, because it is easier to discuss the possible solutions by intersection of two curves determined by the estimating equations. Numerically, since we only have two parameters to estimate, thus it is quite efficient to solve that by the ‘optim’ function in R.
Remark 2.1
Unlike the existing literature which directly applied the optimization algorithm to the log-likelihood function, without verifying the existence of the MLE (Huete-Morales & Marmolejo-Martín, Citation2020; Rivas & Campos, Citation2021), we present the necessary and sufficient conditions for the existence of the MLE of the Waring parameters, which is the first attempt. It is easy to see that the sign of is equal to the sign of
For m = 2, we have
, and thus the MLE of
does not exist. For
, it depends, and we can check the sign of
for a general m. For m = 2, 3, we also carefully check the existence of real-valued solution to the equation system (Equation3
(3)
(3) )–(Equation4
(4)
(4) ), and find that the sign of
indeed determines the existence of MLE. The readers can refer to the authors for checking details.
One more comment on Theorem 2.5 is as follows. If , or
with
, the MLE of the Waring parameters is a finite vector. Then the Waring distribution fits the data better than the Yule-Simon distribution, if the estimated β departs from 1, and similarly if the estimated β is close to 1. If
, or
with
, the likelihood function will be maximized at the boundary region, i.e., infinity. Therefore, if we directly apply the optimization algorithm to the likelihood function, the MLE may be far from the true parameters; for example, in the real data application, we get that MLE
for the group with central age 67.5 (age from 65 to 70), where in fact that the MLE does not exist. In such cases, we can use the EFF method if the EFF estimates are in reasonable scales, and the Waring distribution will still fit the data better than the Yule-Simon distribution.
3. Simulation studies
3.1. Comparison of MLE and EFF
In this section, we give some numerical studies to compare the MLE and the EFF method in the Waring parameter estimation.
The Waring distributed observations are generated by the function rWARING in the R package gamlss.dist. We need mention that in the function rWARING, the parameters is , and the probability mass function is given by
Comparing the above probability mass function to (Equation1
(1)
(1) ), we can find that we need to add 1 to the generated values from rWARING, and the relationship between the parameters is
and
. Thus rWARING automatically restricts
and the EFF estimator exists. We consider 20 combinations of
, where
and
, with sample sizes n = 100, 200, 400 and 1000. We generate 500 replicates for each case.
Probably due to the parameter specification and restricted data-generating process of the function rWARING, we find that is satisfied in all cases, except two replicates in the case
with small sample size n = 100. By Remark 2.1,
is equivalent to
(9)
(9) It is easy to see that
where
means the empirical distribution. When
,
exists while
diverges. Thus (Equation9
(9)
(9) ) is very likely to hold, and the MLE exists. However, in real applications, it is possible that
(Section 4).
As mentioned immediately after Theorem 2.5, we use the ‘optim’ function to solve the MLE after verifying its existence. We tried four methods to initialize the parameters: (i) small values, ; (ii) large values,
; (iii) true values of the parameters plus a random perturbation
, but restrict that
and
; (iv) the EFF method. Extensive numerical studies show that these four initializing methods yield almost the same results, which indicates that the optimization is not sensitive to the initial values. Therefore, we use the EFF estimator for initialization if EFF produces positive estimates, otherwise, we set the initial values as
.
Among all the cases, the EFF method results in negative estimates only in one replicate in the case with small sample size n = 100; in another replicate, the denominator
is exactly 0, so the estimator does not exist; these two replicates are deleted for fair comparison. Since the parameters are in different scales, especially the parameter β, the maximal value is four times of the minimal one. Thus for fair comparison, we report the rBias (relative bias, defined as the bias divided by the true value of the parameter) and rStd (relative standard errors, defined as the standard error divided by the true value of the parameter) in Tables and . We find that, when the sample size is as small as n = 100, both MLE and EFF yield relatively poor estimates, with standard errors being larger than or close to 50% of the true value of the parameter, which indicates that it is challenging to accurately estimate the parameters with small sample sizes. Therefore, we focus on the comparison of MLE and EFF for
. First, MLE always results in much smaller biases than EFF. Though the rBias of EFF decreases when the sample size increases, it increases when the true α decreases, and it is still around 10% even when n = 1000 for
; the rBias of MLE decreases from 6%–7% to around 1% when n increases from 200 to 1000, regardless of the true α. Second, MLE results in comparable rStd with EFF for medium-sized sample (n = 200 and 400), but smaller rStd for n = 1000. Overall, the MLE method results better performance than the EFF method when
is not large or the sample size is large enough. The performance of EFF is relatively better when
is large, e.g.,
. Our explanation is that, since
, if
is large, then
is close to 1. Thus EFF includes relatively more information than the case with small
.
Table 1. Relative biases and relative standard errors of estimated parameters, for and 1.
Table 2. Relative biases and relative standard errors of estimated parameters, for and 2.
3.2. Goodness-of-fit comparison with Yule-Simon distribution
In this section, we compare the Waring distribution and the Yule-Simon distribution, in terms of goodness-of-fit to the data.
We fix , and generate data from the Waring distribution with
; data is generated from the function rWARING as in Section 3.1. When
, it is exactly the Yule-Simon distribution, and when β departs from 1, the Yule-Simon assumption is violated. We consider 500 replicates with sample sizes n = 100, 200, 400, 1000. To initialize the optimization for the MLE of the Yule-Simon parameter α, we use the first frequency
, that is,
. Figure presents the box-plots of the likelihood ratio statistics
where
is the log-likelihood function of the Waring fitting evaluated at the MLE
, and
is the log-likelihood function of the Yule-Simon fitting evaluated at the MLE
. If the true β equals 1, the Yule-Simon distribution is correct, so it is easy to prove that
; if the true β departs from 1, the Yule-Simon distribution is not correct, so
will be large. The box-plots in Figure confirm that the Waring distribution fits the data similar to the Yule-Simon distribution when
, and much better when β departs from 1. We further report the proportion of replicates that the Yule-Simon distribution is rejected at nominal level 0.05, in Table .
Figure 1. Box-plots of corresponding to
(first row), 1.5 (second row), and 2 (third row), respectively, where the dashed line indicates the critical value 3.84, and the number at the right side of the figure is the proportion that
. In the last piece, all
's are much larger than 3.84, and thus the dashed line and the rejection proportion are not shown in the figure.
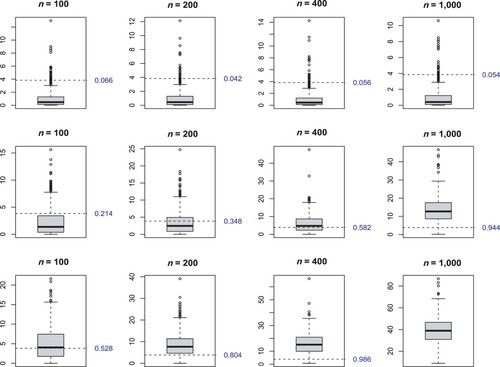
Table 3. Proportion of replicates that the Yule-Simon distribution is rejected at nominal level 0.05.
4. Real data application
Seal (Citation1947, Citation1952) provided data on insurance shares for 12 different age periods. The original data is about male lives assured in a British life office, maintained for administrative purposes. The analysed data is a random subset, and every tenth names in this list were included until the total of 2000 was reached. The lives sampled are scheduled according to the year of birth and the number of policies in force. The group is represented by the central age.
Seal (Citation1952) fitted the data using the discrete Pareto, with probability mass function
where
is a normalization constant, and the parameter d is estimated by the MLE. Here we apply the Waring distribution to fit the data. For the age periods centred at 17.5 and 22.5, the maximal number of shares is 2. The EFF method leads to negative parameter estimates, while the MLE is proved not to exist as in Remark 2.1. We focus on the rest 10 groups, with central ages from 27.5 to 72.5. Among these 10 groups, for the group with central age 67.5, we have n = 45 and
, and it is easy to verify that (Equation9
(9)
(9) ) does not hold. Thus the MLE does not exist. If we directly apply the optimization algorithm, we get
, which is meaningless. However, if we use the EFF method, we get
, and the resulted fitting is reasonably good. Thus, we need to be careful in using the MLE. Table summarizes the comparison of the actual distribution with discrete Pareto law fitting, Waring fitting with EFF and MLE, we find that the Waring distribution fits the data slightly better than the discrete Pareto law.
Table 4. Comparison of actual distribution (A) with discrete Pareto law fitting (P), Waring fitting with EFF (E) and MLE (M).
5. Discussion
To fit a given data set by the Waring distribution, we need to verify the existence condition of the MLE of the Waring parameters before we use the MLE. If the existence condition is not satisfied, it means that the likelihood is maximized at the boundary, i.e., infinity. Therefore, if we directly apply the optimization algorithm to the likelihood function, the MLE may be far from the true parameters; see for example, we get MLE for the group with central age 67.5, where in fact that the MLE does not exist. In such cases, we can use the EFF method if the EFF estimates are in reasonable scales. Based on the simulation studies and the real data analysis, we find that, when the sample size is small or the maximum observed value is small, the MLE is less likely to exist, and when the sample size is big and the maximum observed value is large, the MLE is more likely to exist. Nevertheless, we need verify the existence condition for the MLE.
Acknowledgements
The authors would like to thank two anonymous reviewers, an associate editor and the editor for constructive comments and helpful suggestions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Garcia, J. M. (2011). A fixed-point algorithm to estimate the Yule–Simon distribution parameter. Applied Mathematics and Computation, 217(21), 8560–8566. https://doi.org/10.1016/j.amc.2011.03.092
- Huete-Morales, M. D., & Marmolejo-Martín, J. A. (2020). The Waring distribution as a low-frequency prediction model: A study of organic livestock farms in Andalusia. Mathematics, 8(11), 2025. https://doi.org/10.3390/math8112025
- Mills, T. (2017). A statistical biography of george udny yule: A loafer of the world. Cambridge Scholars Press.
- Panaretos, J., & Xekalaki, E. (1986). The stuttering generalized waring distribution. Statistics and Probability Letters, 4(6), 313–318. https://doi.org/10.1016/0167-7152(86)90051-9
- Price, D. (1965). Network of scientific papers. Science, 149(3683), 510–515. https://doi.org/10.1126/science.149.3683.510
- Price, D. (1976). A general theory of bibliometric and other cumulative advantage processes. Journal of the American Society for Information Science, 27(5), 292–306. https://doi.org/10.1002/(ISSN)1097-4571
- Rivas, L., & Campos, F. (2021). Zero inflated Waring distribution. Communications in Statistics – Simulation and Computation, to appear. https://doi.org/10.1080/03610918.2021.1944638
- Seal, H. L. (1947). A probability distribution of deaths at age x when policies are counted instead of lives. Scandinavian Actuarial Journal, 1947, 118–43. https://doi.org/10.1080/03461238.1947.10419647
- Seal, H. L. (1952). The maximum likelihood fitting of the discrete Pareto law. Journal of the Institute of Actuaries, 78(1), 115–121. https://doi.org/10.1017/S0020268100052501
- Simon, H. A. (1955). On a class of skew distribution functions. Biometrika, 42(3–4), 425–440. https://doi.org/10.1093/biomet/42.3-4.425
- Xekalaki, E. (1983). The univariate generalized Waring distribution in relation to accident theory: Proneness, spells or contagion? Biometrics, 39(4), 887–895. https://doi.org/10.2307/2531324
- Xekalaki, E. (1985). Factorial moment estimation for the bivariate generalized Waring distribution. Statistical Papers, 26(1), 115–129. https://doi.org/10.1007/BF02932525
- Yule, G. U. (1925). A mathematical theory of evolution, based on the conclusions of Dr. J. C. Willis, F.R.S. Philosophical Transactions of the Royal Society B, 213, 21–87.
Appendices
The appendix contains some useful lemmas and technical proofs.
Appendix 1. Some useful lemmas
Lemma A.1
Define
where
are positive and
are nonnegative. Then
is an increasing and concave function.
Proof.
It is easy to derive that
Lemma A.2
When , we have
Proof.
Assume that
Then
which indicates that: (i)
, and then
; (ii)
, and then
. The proof is completed.
Appendix 2. Technical Proofs
Appendix 2.1. Proof of Lemmas 2.3–2.4
Proof
Proof of Lemma 2.3
Since for any β, . Thus, to prove
, we only need prove that
maximizes
. Therefore, we only need prove that
,
for
and
for
.
Consider the following decomposition,
where
, and thus
totally determines the sign of
. The proof is completed.
Proof
Proof of Lemma 2.4
We use the method of contradiction. If the conclusion is not correct, then there exists such that
,
for
and
for
for some
. By assumption (D), the curves
and
will intersect again after
, i.e., there exists
such that
,
for
and
for
(suppose that there exists only one such
, otherwise, we consider the largest intersection). According to assumption (D), take one point
(which is of course greater than
), use
as the starting point, and then take a ray interpolating
. Let
diverge to infinity so that the point
moves along the curve
. Since
is increasing and concave, the ray interpolating
tilts down around the start point
. By assumption (C), when
, the slope of the ray
Thus the limit of the ray is a ray with start point
and slope
, denoted as L, and the curve
is above L.
Note that the start point of the ray L, , is on the curve
. By assumption (D), there exists an
, which satisfies that, the curve
intersects L at
and
lies below L for
with some positive
. Without loss of generality, we assume that
is such point, that is,
lies below L for
.
Through the intersection , we make tangent line of the curve
. If the tangent line coincides with the ray, then take another point
, and make another tangent line of the curve
through the point
. Since
is increasing and concave, if the tangent line (of
) through
coincides with the ray L, the tangent line through
does not coincide with L. Note that the curve
is above L, while
is below the tangent line (a concave curve is always below its tangent line) which is below the ray L (the one which does not coincide with L must be below L according to the above discussion). Therefore,
, which contradicts with assumption (C).
To summary, no such exists that
,
for
and
for
for some
. We conclude that,
for
. The proof of Lemma 2.4 is completed.
Appendix 2.2. Proof of Propositions 2.1–2.2
Proof
Proof of Propositions 2.1
Proof of Property 1. If , we have
when
. Therefore, when
, the intersection of
and
converges to the origin of coordinates.
Proof of Property 2. If , then for any
, we have
. Thus, if
, then
because
is the intersection. We have
where
Based on Lemma A.2, tedious calculation yields
where
Simple algebra yields
where
.
Proof of Property 3. Since
(A1)
(A1) taking derivative with respect to β on both sides of (EquationA1
(A1)
(A1) ), we have
Simple algebra leads to
where
(A2)
(A2) Furthermore, since
which indicates that
. Therefore,
.
Taking derivative with respect to β twice on both sides of (EquationA1(A1)
(A1) ), we have
Proof of Property 4. If , then
, and thus (EquationA2
(A2)
(A2) ) indicates that
; therefore
. If
, then
, and thus (EquationA2
(A2)
(A2) ) indicates that
; therefore
.
Proof of Property 5. According to (Equation3(3)
(3) ), the conditional maximum likelihood equation of α can be rewritten as
Let
and then
is an increasing function of α. Since
, then x is less than, equal to or greater than
which is equivalent to that
is less than, equal to or greater than 1. Therefore,
is equivalent to
. Since
is a polynomial or fractional function of β, then
is a high-ordered polynomial equation, which has finite number of solutions.
Proof
Proof of Proposition 2.2
The proofs of Properties 1* and 5* are similar to the proofs of Properties 1 and 5 in Proposition 2.1, respectively, and Property 3* follows from Lemma A.1. In the following, we present the proofs of Properties 2* and 4*.
Proof of Property 2*. By Lemma A.2, it is easy to obtain
where
Therefore, we have
where
Proof of Property 4*. It is easy to derive that
and we have
Appendix 2.3. Proof of Theorem 2.5
By Properties 1, 4 of and 1*, 4* of
, when
,
and
; however,
while
. Thus, there exists
, such that
for
.
By Property 2 of and 2* of
, when
,
We first discuss the situation
. We have, there exists
, such that for
,
(A3)
(A3) In case of
, that is,
, we need compare
and
. If
,
and if
,
.
Therefore, if
(A4)
(A4) there must exist an intersection for the curves
and
. Part (II) of Theorem 2.5 follows directly from Lemma 2.4. Thus we only need prove part (I). In the following, we assume that (EquationA4
(A4)
(A4) ) holds so that
and
intersect at least once at some positive β.
Suppose that and
intersect firstly at
, where
, and then
for
. By Property 5 of
in Proposition 2.1 the curves
and
only intersect finite times. Therefore, there exists
such that
and
do not intersect for
. If for
, the curve
is above
. Then, due to (EquationA4
(A4)
(A4) ), the curve
will finally be below the curve
. Thus the two curves will intersect again. However, because the number of intersections is finite, it cannot be always the case that the curve
lies above
after the intersection, i.e., there exists an intersection that
lies below
after that intersection. Without loss of generality, we assume that
(A5)
(A5) Next, we prove that
is the maximizer of the log-likelihood function
. Since
is the conditional maximum likelihood estimator of α, i.e.,
We only need prove that
is a maximizer of
.
Since is a solution to the equation system (Equation3
(3)
(3) )–(Equation4
(4)
(4) ), then
To prove that
maximizes
, by Lemma 2.3, we only need prove that
is greater than zero for
and smaller than zero if
.
We first consider . When
, we have
. Therefore,
(A6)
(A6) We next consider
. By (EquationA5
(A5)
(A5) ),
if
. Then, by Lemma 2.4,
can't be above
at any
, i.e.,
for all
. Therefore,
(A7)
(A7) The proof is completed. We see that the overall proof depends on the fact that