
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider maximum likelihood estimation with two or more datasets sampled from different populations with shared parameters. Although more datasets with shared parameters can increase statistical accuracy, this paper shows how to handle heterogeneity among different populations for correctness of estimation and inference. Asymptotic distributions of maximum likelihood estimators are derived under either regular cases where regularity conditions are satisfied or some non-regular situations. A bootstrap variance estimator for assessing performance of estimators and/or making large sample inference is also introduced and evaluated in a simulation study.
1. Introduction
With advanced technologies in data collection and storage, in modern statistical analyses we often have multiple datasets as independent samples from different populations having shared parameters. Typically, one of these multiple datasets is primary with carefully collected data from a population of interest. The other datasets are from external sources, such as data from other studies, administrative records and publicly available information from internet.
On one hand, the fact that populations share common parameters provides a great opportunity for increasing statistical accuracy by utilizing multiple datasets instead of a single dataset. On the other hand, because of the difference in data collection, study purpose and/or time of investigation, heterogeneity often exists among populations so that we cannot simply combine all datasets into a single large dataset to run analysis, but must develop or modify statistical methodology to correctly utilize multiple datasets. The research on analysis with multiple datasets fits into a general framework of data integration (Kim et al., Citation2021; Lohr & Raghunathan, Citation2017; Merkouris, Citation2004; Rao, Citation2021; Yang & Kim, Citation2020; Zhang et al., Citation2017; Zieschang, Citation1990).
In this article, we study maximum likelihood estimation (MLE) for independent datasets with parametric populations sharing some (not necessarily all) parameters. For simplicity of presentation, we focus on the case of two independent datasets. The main idea and result can be extended to multiple datasets. Our research can also be extended to semi-parametric estimation, such as empirical likelihood or Cox regression for survival data.
Throughout, we consider two independent random samples. One random sample of size n, resulting a dataset , is sampled from a parametric population with probability density
(for either continuous or discrete x), where f is a known function and θ and ϕ are unknown parameter vectors. Another random sample of size m, resulting a dataset
, is sampled from a population with probability density
, where g is a known function and θ and φ are unknown parameter vectors. Note that
and
can be vectors. The shared parameter θ can be either the main parameter vector of interest or a nuisance parameter vector, and ϕ and φ are other parameter vectors in two populations.
Let ϑ denote the vector with θ, ϕ, and φ as sub-vectors. In Section 2, we derive the maximum likelihood estimator (MLE) of ϑ based on two datasets, which is expected to be asymptotically more efficient than each MLE based on a single dataset, since more data are used for estimating the shared parameter θ, a component of ϑ. The asymptotic normality of MLE of ϑ is established when densities f and g satisfy regularity conditions that are typically assumed for MLE. Applications to location-scale problems are discussed in Section 3, where we also present a situation in which f or g does not satisfy the regularity conditions. Section 4 contains an example in which regularity conditions do not hold and MLE is not asymptotically normal. The common mean of a discrete data problem is considered in Section 5. Section 6 is devoted to the scenario where an additional uncertainty exists in the second population density g. To handle the situation where asymptotic normality of the MLE of ϑ is not available, we introduce a bootstrap variance estimator in Section 7 and provide some simulation results to examine finite sample performances.
2. MLEs with two datasets
The following are regularity conditions for probability density (with a fixed ϑ) of a continuous or discrete random variable/vector X, typically assumed for MLEs in parametric populations (Shao, Citation2003).
| (R1) | For every x in the range of X, | ||||
| (R2) |
| ||||
| (R3) | The Fisher information matrix | ||||
| (R4) | For any given ϑ, there exists a positive number | ||||
In this section, we assume that both f and g satisfy regularity conditions (R1) –(R4). When some regularity conditions are not satisfied, we have to deal with the problem case by case. See, for example, the problem of normal and Laplace distributions in Section 3.2 and the problem of two truncation distributions in Section 4.
The log likelihood function of ϑ is
and the score function is
If
is a solution to the score equation
, then we call
an MLE of ϑ, although traditionally an MLE is defined as a maximizer of
over the range of ϑ and
satisfying
may not be a maximizer.
A solution to the score equation often does not have an explicit form, even when each MLE of a single population has an explicit solution.
Under regularity conditions (R1)-(R4), and
is the Fisher information matrix of information contained in two samples. Let
Then
is positive definite, where
and without loss of generality we assume that m = an for a fixed a>0. It can be seen that
is increasing in a in the sense that
for two non-negative definite matrices A and B if and only if A−B is non-negative definite.
Using the standard argument in asymptotic theory, e.g., Theorem 4.17 in Shao (Citation2003), we obtain the following result.
Theorem 2.1
Assume (R1) –(R4) and that m = an with a remaining fixed as n increases. Then, with probability tending to 1 as , there exists
(depending on n) such that
and
(1)
(1)
where
denotes convergence in distribution and
is the normal distribution with mean C and covariance matrix D.
The asymptotic result (Equation1(1)
(1) ) enables us to assess performance of
and to carry out large sample statistical inference on parameter ϑ or any of its components θ, ϕ, and φ. When some of regularity conditions (R1) –(R4) are not satisfied, however, we may apply the bootstrap method (see Section 3.2 and Section 7 for the normal and Laplace problem) or directly derive the asymptotic distribution of
(see Section 4 for the problem of two truncation distributions).
3. Application to location-Scale problems
An application of our general result in Section 2 is to the case where and
for two continuous probability density functions f and g on real line, i.e., both populations are in location-scale families. We have several scenarios.
Two location-scale families sharing the same location and scale parameters:
,
Two location-scale families sharing the same location parameter but having different scale parameters:
Two location-scale families sharing the same scale parameter but having different location parameters:
Under any location-scale problem, it is often true that and
and, hence, the inverse of
can be easily obtained. For example, if both f and g are continuously differentiable functions symmetric about 0, then it follows from Example 3.9 in Shao (Citation2003) that both
and
varnish.
In the following we consider a special case in details.
3.1. Normal and Laplace densities with a single scale parameter
Suppose that ,
, which is the normal distribution
, and that
,
, which is the Laplace distribution (also called double exponential distribution) with mean zero and standard deviation
. The two densities share the common scale parameter
.
The MLEs of θ based on data from f and g, respectively, are
In this particular case, we can obtain an explicit form of the MLE
of θ based on all data from two samples. The log likelihood based on two samples is
The score function is
Setting
and using the form of MLE from each sample, we obtain that
Since
and only one root is positive, we obtain that the MLE of θ is
(2)
(2)
Note that
is a nonlinear function of
and
. In general, the MLE of the shared parameter based on two datasets is not a simple function of separate MLEs based on each single dataset.
To derive the asymptotic distribution of , we can use the general result (Equation1
(1)
(1) ), because regularity conditions (R1) –(R4) are satisfied for f and g. Since
has an explicit form, we can also simply derive it. Because
's and
's are independent and
,
Define
Then,
Hence, by the delta method, e.g., Theorem 1.12 in Shao (2003),
where
is the derivative vector of g at
, i.e.,
This leads to the following result.
Corollary 3.1
Assume that m = an with a remaining fixed as n increases. Then, as ,
The asymptotic relative efficiency of with respect to
is
, which is decreasing in a and bounded between 0 and 1. The asymptotic relative efficiency of
with respect to
is
, which is increasing in a and bounded between 0 and 1.
3.2. Normal and Laplace densities with shared scale and location parameters
Consider a more general case where f and g share a scale parameter and a location parameter. That is, ,
, which is the normal distribution
, and
,
, which is the Laplace distribution with mean µ and standard deviation
. Note that regularity conditions (R1) –(R4) are not satisfied for g, since g is not always differentiable in µ.
For parameter vector , the log likelihood is
Although
is not always differentiable in µ, it is concave in µ and, hence, the MLE
of µ exists though it does not have an explicit form. The MLE of θ is given by (Equation2
(2)
(2) ) with
and
replaced by, respectively,
The asymptotic distribution of
cannot be obtained from (Equation1
(1)
(1) ), since g does not satisfy conditions (R1) –(R4). For assessing performance of
and/or making inference, we recommend a bootstrap method, which is discussed in Section 7 and studied by simulation.
4. Application to two truncation distributions
Let and
be positive density functions on the interval
and zero outside
, where
is an unknown scale parameter common for both populations, and f and g are known when θ is known. The likelihood is
where
is the indicator of event A,
and
. This likelihood is not always differentiable in θ, but it can be seen that the MLE of θ is
, a maximizer of the likelihood.
This is an example in which regularity conditions (R1) –(R4) in Section 2 are not satisfied so that result (Equation1(1)
(1) ) does not hold. The MLE
is not even asymptotically normal. In the following we directly derive the asymptotic distribution of
.
It follows from the result in Example 2.34 of Shao (Citation2003), the independence of 's and
's, and m = an that
where
and
are independent random variables with the same exponential distribution having density
, x>0. Because
we obtain that
From the independence of
and
, for any t>0,
This leads to the following result.
Theorem 4.1
Under the assumed conditions on f and g in this section,
where
is the exponential distribution with scale parameter
.
Inference on θ can be made using this asymptotic result.
The asymptotic relative efficiency of the MLE based on the first dataset with respect to the MLE
based on two datasets is
, which is increasing in a and bounded between 0 and 1. The asymptotic relative efficiency of the MLE
based on the second dataset with respect to the MLE
based on two datasets is
, which is decreasing in a and bounded between 0 and 1.
5. Application to Poisson and binomial samples
Here we consider a discrete data problem, where has the Poisson distribution with mean θ,
is binary with
, and
is the shared parameter. Let
be the sample mean of
's and
be the sample mean of
's. The score function based on two samples is
Setting
, we obtain the score equation
Since the score equation is a quadratic equation, it has two solutions if and only if
By the law of large numbers, as
, both
and
converge to θ almost surely and
almost surely. This shows that, with probability tending to 1 as
, the score equation has two real solutions,
The solution with + sign in front of the squared root is always larger than 1, out of the range
for θ in this problem. Hence, we conclude that the MLE of θ is
The minimum is taken because
. Again, the MLE
is a nonlinear function of the separate MLEs,
and
.
The asymptotic distribution of can be derived using the delta-method, but because regularity conditions (R1) –(R4) are satisfied, it is a corollary of Theorem 2.1 in Section 2.
Corollary 5.1
Under the Poisson and binary assumptions for two datasets and m = an, as ,
The asymptotic relative efficiency of the MLE based on the first dataset with respect to the MLE
based on two datasets is
, which is decreasing in a and bounded between 0 and 1. The asymptotic relative efficiency of the MLE
based on the second dataset with respect to the MLE
based on two datasets is
, which is increasing in a and bounded between 0 and 1.
6. MLEs with two samples and an additional uncertainty
In this section, we consider a scenario in which the first sample is obtained under a controlled study so that we know the form of probability density , but the form of
for the second sample has an additional uncertainty, because the second sample may be obtained through a past study and/or public records. We assume that the additional uncertainty comes from an unknown parameter ζ taking two possible values, 0 and 1, i.e., the probability density of the second sample is
, where
or 1 and g is still a known density when θ, φ, and ζ are known.
How do we derive the MLE of ? If ζ is known, then the MLE can be obtained using the method in Section 2. Since ζ takes only two values, if
is a consistent estimator of ζ, i.e.,
(3)
(3)
then we obtain the MLE of ϑ as
where
and
are MLEs under
and
, respectively.
A suggested consistent estimator of ζ is the MLE of ζ based on the second sample, 's. Let
and
be the MLEs of θ and φ, respectively, based on
's, when the value of ζ is fixed. Then the MLE of ζ is
The following result gives the asymptotic distribution of the MLE
.
Theorem 6.1
If (Equation3(3)
(3) ) holds and regularity conditions (R1) –(R4) are satisfied when
or 1, and if
with a remaining fixed as n increases, then
where
is the Fisher information as defined in Section 2 under the true value of ζ.
Condition (Equation3(3)
(3) ) has to be checked for each particular problem. The following is an example.
Suppose that is the density of
,
is the same normal density for
but
is the Laplace distribution with zero mean and standard deviation
given in Section 3.1. In other words, sample one is from the main study whereas sample two is from an external source in which the data may follow the same distribution as sample one but may deviate from sample one. The parameters ϕ and φ are constant (non-existing).
In this example, when , we can simply combine the two samples and the MLE of θ is
; on the other hand, when
, the MLE of θ is given by (Equation2
(2)
(2) ). To check (Equation3
(3)
(3) ), note that
Then,
and
When
,
and
, where
denotes convergence in probability as
. Hence
which implies that
. On the other hand, when
,
,
, and
which implies that
. This shows that (Equation3
(3)
(3) ) always holds in this example.
Still in this example, the results here and in Section 3.1 indicate that
The result can obviously be extended to the situation where the second sample is from a population that is one of k populations with
.
7. Bootstrap variance estimation
In situations where regularity conditions (R1) –(R4) are not satisfied for f or g, the asymptotic distribution of MLE may not be available, either it does not exist or it is not established. Here, we introduce a bootstrap variance estimator which can be used for assessing performance of
or making large sample inference. A description about the general bootstrap methodology can be found, for example, in Efron and Tibshirani (Citation1993) and Shao (Citation2003).
Let and
be two independent simple random samples with replacement from
and
, respectively, and let
be the MLE of ϑ based on dataset
. If we independently repeat this for
, where B is called the bootstrap replication size and is typically large, then the bootstrap variance estimator for
is the sample covariance matrix of
,
.
We carry out a simulation study to examine the performance of this bootstrap variance estimator in the normal-Laplace problem considered in Section 3.2. At the same time, we also check the performance of MLE based on two datasets,
's and
's, and compare it with
and
, which are the MLEs based on the single dataset of
's and single dataset of
's, respectively, where
sample mean of
's,
= sample median of
's,
, and
. The bootstrap is applied to obtain
for the standard deviation (SD) of any fixed point estimator.
The simulation results with 1000 replications are shown in Table . A summary is given as follows.
The MLE's,
The MLE
The bootstrap SD estimator
Table 1. Results from 1000 simulations for the normal-Laplace problem with location and scale
(n = m = 100, SD = standard deviation,
the MLE of
based on
's and
's,
the MLE of
based on
's,
the MLE of
based on
's, and
is by bootstrap with B = 500).
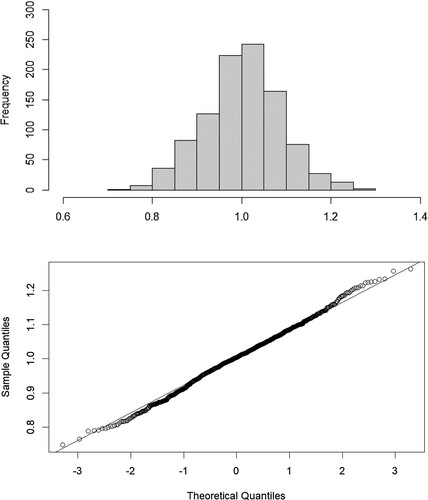
The histogram of 1000 values of from simulation is shown in Figure , together with a Q–Q plot. The result suggests
is asymptotically normal, although such a theoretical result has not been established.
Figure 1. Histogram and Q–Q plot of 1000 simulated values of .
Acknowledgments
The authors would like to thank two anonymous referees for helpful comments and suggestions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Efron, B., & Tibshirani, R. J. (1993). An introduction to the bootstrap. New York: Chapman and Halll/CRC.
- Kim, H. J., Wang, Z., & Kim, J. K (2021). Survey data integration for regression analysis using model calibration. arXiv 2107.06448.
- Lohr, S. L., & Raghunathan, T. E. (2017). Combining survey data with other data sources. Statistical Science, 32(2), 293–312. https://doi.org/10.1214/16-STS584
- Merkouris, T. (2004). Combining independent regression estimators from multiple surveys. Journal of the American Statistical Association, 99(468), 1131–1139. https://doi.org/10.1198/016214504000000601
- Rao, J. N. K. (2021). On making valid inferences by integrating data from surveys and other sources. Sankhya B, 83(1), 242–272. https://doi.org/10.1007/s13571-020-00227-w
- Shao, J. (2003). Mathematical statistics. 2nd ed. Springer.
- Yang, S., & Kim, J. K. (2020). Statistical data integration in survey sampling: A review. Japanese Journal of Statistics and Data Science, 3(2), 625–650. https://doi.org/10.1007/s42081-020-00093-w
- Zhang, Y., Ouyang, Z., & Zhao, H. (2017). A statistical framework for data integration through graphical models with application to cancer genomics. The Annals of Applied Statistics, 11(1), 161–184. https://doi.org/10.1214/16-AOAS998
- Zieschang, K. D. (1990). Sample weighting methods and estimation of totals in the consumer expenditure survey. Journal of the American Statistical Association, 85(412), 986–1001. https://doi.org/10.1080/01621459.1990.10474969