
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper deals with the Monte Carlo Simulation in a Bayesian framework. It shows the importance of the use of Monte Carlo experiments through refined descriptive sampling within the autoregressive model , where
and the errors
are independent random variables following an exponential distribution of parameter θ. To achieve this, a Bayesian Autoregressive Adaptive Refined Descriptive Sampling (B2ARDS) algorithm is proposed to estimate the parameters ρ and θ of such a model by a Bayesian method. We have used the same prior as the one already used by some authors, and computed their properties when the Normality error assumption is released to an exponential distribution. The results show that B2ARDS algorithm provides accurate and efficient point estimates.
1. Introduction
Time series are often used to model data in different areas of life. We can think of economic forecasts, the evolution of a biological system, time-stamped data from social media, E-commerce and sensor systems. The AutoRegressive (AR) model is the most widely used class of time series models, and particularly the first order AutoRegressive process denoted as AR(1).
On the other hand, the use of Bayesian inference has developed rapidly over the last decade in several fields including medicine (Ashby, Citation2006), genetics (Beaumont & Rannala, Citation2004), bioinformatics (Corander, Citation2006), econometrics (Geweke, Citation1999), etc.
Several works related to time series models have been treated by the Bayesian approach. Box et al. (Citation1976), Monahan (Citation1984) and Marriot and Smith (Citation1992) discussed the Bayesian approach to analyse the AR models. Diaz and Farah (Citation1981) devoted their work to a Bayesian technique for computing posterior analysis of an AR process in any arbitrary order. Amaral Turkmann (Citation1990) considered a Bayesian study of an AR(1) model with exponential white noise based on a noninformative prior. Ghosh and Heo (Citation2003) introduced a comparative study to some selected noninformative priors for the AR(1) model. Pereira and Amaral-Turkman (Citation2004) developed a Bayesian analysis of a threshold AR model with exponential white noise.
Several Bayesian methods for estimating autoregressive parameters have been proposed by different authors; for instance, Albert and Chib (Citation1993) and Barnett et al. (Citation1996) proposed a Bayesian method via Gibbs sampling to estimate the parameters in an AR model. Ibazizen and Fellag (Citation2003) proposed a Bayesian estimation of an AR(1) process with exponential white noise by using a noninformative prior, whereas Suparman and Rusiman (Citation2018) proposed a hierarchical Bayesian estimation for stationary AR models using a reversible jump MCMC algorithm. However, Kumar and Agiwal (Citation2019) proposed a Bayesian estimation for a full shifted Panel AR(1) time series model.
Bayesian inference is based on the posterior distribution, which can be interpreted as the result of the combination of two information sources: the information provided by the parameter which is contained in the prior distribution, and the information provided by the data which formalizes the likelihood function through the use of a given statistical model.
Posterior inference can be undertaken by applying classical Monte Carlo (MC) methods, which provide iterative algorithms that can generate approximate samples from the posterior distribution. These methods fall into two categories: the Markov Chain Monte Carlo (MCMC) methods such as Metropolis-Hastings and Gibbs algorithms (Smith & Robert, Citation1993), and the Monte Carlo (MC) method also known as Simple Random Sampling (SRS), for instance, Quasi Monte Carlo (Keller et al., Citation2008), Latin hypercube sampling (LHS) (Loh, Citation1996; Mckay et al., Citation1979; Stein, Citation1987), Descriptive Sampling (DS) (Saliby, Citation1990) as well as Refined Descriptive Sampling (RDS) (Tari & Dahmani, Citation2006). In the non-Bayesian estimation, the SRS is a widely used method in MC simulation. But unfortunately, the sampling method generates estimation errors, so it is not accurate enough. However, the RDS method (Aloui et al., Citation2015) has shown its effectiveness for several models and in various fields. For instance, in the field of medicine, Ourbih-Tari and Azzal (Citation2017) proposed an RDS algorithm for a nonparametric estimation of the survival function using Kaplan Meier and Fleming Harrington estimators in a case study. In the field of engineering, Baghdali-Ourbih et al. (Citation2017) have estimated the performance measures of the aggregate quarry of Bejaia city in Algeria, using a discrete-event simulation model. In the field of M/G/1 queuing models, M/M/1 retrial queues and M/G/1 retrial queues, simulation results using RDS outperform those obtained using the MC method (Idjis et al., Citation2017; Ourbih-Tari et al., Citation2017; Tamiti et al., Citation2018). Also, a comparison between RDS and LHS carried out on M/G/1 queues showed the efficiency of RDS over LHS (Boubalou et al., Citation2019). Since it is important to choose a sampling scheme that allows for a better parameter estimate while keeping the number of repetitions to a minimum, the RDS method is chosen for further work.
This paper will therefore explore the RDS method in a Bayesian sense by considering the AR(1) model, which has already been studied by Amaral Turkmann (Citation1990) and, later on, by Ibazizen and Fellag (Citation2003). For this purpose, we assume the noninformative prior given in Ibazizen and Fellag (Citation2003) for the AR(1) process with exponential white noise. Then, we develop an algorithm for the estimation of AR(1) model parameters in a Bayesian context by using the most accurate sampling method as the RDS method. The proposed algorithm is called Bayesian Autoregressive Adaptive Refined Descriptive Sampling (B2ARDS).
Some details of the RDS method are given in Section 2. Then, in Section 3, the methodology from Bayesian perspective is explained. Section 4 is concerned with the Bayesian estimates of the AR(1) model parameters and their variances using the RDS method through the B2ARDS algorithm. Section 5 presents simulation experiments performed by using the R Package and corresponding results are summarized in Tables and , and Figures and . Finally, Section 6 concludes this paper.
Figure 1. Sequences of estimates for different true values of ρ. (a)
. (b)
. (c)
.
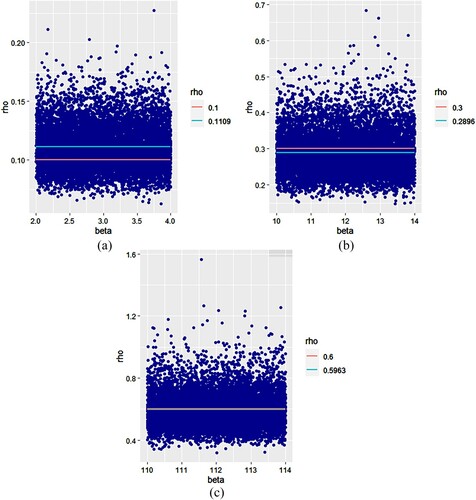
Figure 2. Sequences of estimates for
and different values of ρ. (a)
. (b)
. (c)
.
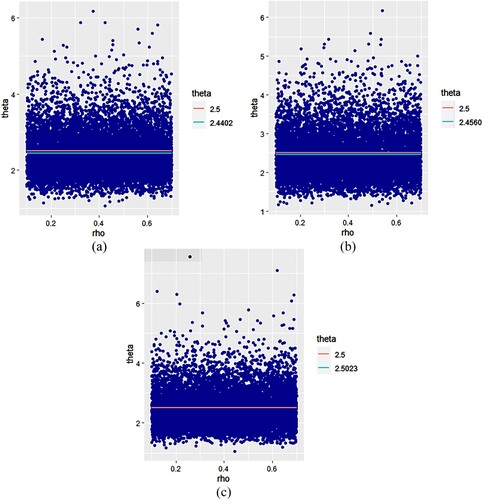
Table 1. Subsets of prime numbers size for a Gumbel distribution with mean ,
,
and
.
Table 2. The observed mean of a Gumbel distribution using three regular subsets of prime number size.
2. The use of RDS
DS is known to have two problems. From a theoretical perspective, DS can be biased. More practically, its strict operation requires a prior knowledge of the required sample size. Based on this, RDS has been proposed to make DS safe, efficient and convenient. RDS makes DS safe by reducing substantially the risk of sampling bias, efficient by producing estimates with lower variances and convenient by removing the need to determine in advance the sample size. Not only this, but RDS beats DS in several comparisons and such is the case, on a flow shop system (Tari & Dahmani, Citation2005a) and a production system (Tari & Dahmani, Citation2005b). So, RDS is the preferred method when it comes to performing MC simulation.
2.1. Description of the method
RDS is based on a block of sub-samples of randomly generated prime number sizes, so it distributes RDS sample values from sub-samples at the request of the simulation. We stop the process of the generation of sample values when the simulation terminates, say when m prime numbers
, have been used, which derives m sub-runs.
The choice of primes in the RDS method as sub-sample sizes is motivated by the definition of primes since we must avoid integers having multiples, whether they are even or odd numbers. Indeed, if the underlying frequency is different from the sampling frequency (the product of primes) or a multiple of it, then the bias of the estimates will be insignificant as demonstrated in Tari and Dahmani (Citation2006). This should ensure that the method reduces the sampling bias.
Remark: In the case of replicated simulation runs, the RDS method will distribute
blocks defined by
primes which are not the same for all replicated simulation runs.
2.2. RDS sample values
Formally, in an RDS run defined by a sample of size , the sample values drawn from the input real-valued random variable X having F as the cumulative distribution are given by the following formulas:
(1)
(1) where for any
the values of each sub-sample
are randomly selected without replacement from the regular numbers of the following sub-set
(2)
(2) and such
is the midpoint of the
subintervals in which the interval
is subdivided. The primes
, are randomly generated between 7 and a given value fixed by the user.
2.3. The estimator of RDS
The j-th sub-run generating values of the input random variable X leads to the following estimate of the parameter θ
(3)
(3) Therefore, in a given run, the use of refined descriptive sample of size
leads to the following sampling estimate of θ defined by the average of those estimates observed on different sub-runs:
(4)
(4) where h is the simulation function.
2.4. Example
We illustrate the method by taking the Gumbel distribution and the prime numbers ,
and
. The values of the variable are simulated by the formula
,
and
. When m = 3, the obtained sub-sets and sub-samples are given in Table using the formulas (Equation2
(2)
(2) ) and (Equation1
(1)
(1) ), respectively, together with the observed mean
in each sub-run using the formula (Equation3
(3)
(3) ), while the overall mean computed at the end of the run is given in Table using the formula (Equation4
(4)
(4) ).
3. Monte Carlo methods from a Bayesian perspective
We consider a random vector Y having a probability density function , where θ is a vector of unknown parameters. The Bayesian statistic considers θ as a random vector of density
called prior law of θ.
In a Bayesian sense, any inference is based on the computation of the posterior distribution which is the conditional distribution of the random vector θ knowing y and is denoted by its probability density . Bayesian estimator of the parameter θ is constructed from the posterior distribution
by minimizing an appropriate loss function. Most Bayesian estimators have the form of
, where
denotes the mathematical expectation of the posterior distribution
.
A major difficulty in an estimation by the Bayesian approach, is the explicit computation of the posterior distribution as soon as the number of parameters exceeds two. Also computing can be very difficult even if the law is known. Thus, several approximation methods such as the MC and MCMC methods are proposed in the literature. The latter allows for the estimation of moments of any order of random variables, too complex to be studied analytically, using iterative generation algorithms.
The Monte Carlo method is a numerical method of solving problems using random numbers. It is one of the most popular mathematical tools with a very wide scope, like differential equation integration, fluid mechanics equations, financial mathematics, particles transport and matrix inversion.
In a Bayesian sense, the Monte Carlo method consists in estimating
by
where
are independent and identically distributed i.i.d. random variables according to
. The strong law of large numbers ensures that
converges almost surely to
when
tends to infinity.
4. The use of RDS for the simulation of the proposed model
4.1. Presentation of the model
Consider the first order autoregressive process defined by
(5)
(5) where
and the
's are i.i.d. random variables with the exponential distribution exp
of parameter θ having a density
is assumed to be distributed according to exp
such that the process is mean stationary.
The likelihood function based on the observations is
where
and
(6)
(6) The Maximum Likelihood Estimators (MLE) of ρ and θ are introduced by Andel (Citation1988) , respectively as follows:
(7)
(7)
(8)
(8) The model given by (Equation5
(5)
(5) ) was processed using a Bayesian approach by Amaral Turkmann (Citation1990). The author's study is based on a noninformative prior defined as follows:
(9)
(9) The author derived the Bayes estimators of the independent parameters ρ and θ as follows:
and
where
such that 0<r<1.
Ibazizen and Fellag (Citation2003) proposed a Bayesian analysis of the model (Equation5(5)
(5) ) by using a more general noninformative prior defined by
(10)
(10) which includes the formula (Equation9
(9)
(9) ) as a special case (
). For θ, the prior (7) is proportional to the scale parameter
and for ρ, it is a special case of the beta distribution.
The authors have derived Bayesian estimators given below, but their formulas are complicated for computation. So, simulation experiments were carried out and the obtained results were compared to the MLE.
where
is the Gauss hypergeometric function of parameters
.
We note that to compute the latter, the Pochhammer coefficients for t = a, b and c are defined as follows
where Γ and
represent symbols of the usual functions Gamma and Beta, respectively.
This paper focuses on the Bayesian estimation of ρ and θ using the most accurate RDS method to generate numbers for the simulation, where the prior distribution of ρ and θ is the one given in (Equation10(10)
(10) ) because it is the most general noninformative prior.
4.2. Bayesian estimation of ρ and θ using the RDS method
Suppose that our data consists of the first observations
.
By using the prior in (Equation10(10)
(10) ) and the Bayes theorem, we get the following posterior:
(11)
(11) which is proportional to
(12)
(12) Knowing that the parameters ρ and θ are independent, the conditional posterior distributions of ρ and θ are respectively
(13)
(13) and
(14)
(14) The use of RDS method requires the computation of the inverse cumulative distribution functions
and
, so we put
The inversion method leads to the following ρ and θ values of the conditional posterior distributions which will be used for the generation of observations:
(15)
(15) and
(16)
(16) where the variables
and
following
are generated using the RDS algorithm given in subsection 4.3 (see Appendix 1 for the generation of the ρ values and Appendix 2 for the generation of the θ values).
4.3. Adaptive RDS algorithm to AR(1) model from the Bayesian perspective by using the R language
In this section, we present a new Bayesian Adaptive AR(1) RDS (B2ARDS) algorithm to estimate the parameters of the model given in (2).
Data structure
For each input random variable, we define a record with the following structure.
N: an integer defining the number of replications.
n: an integer defining the sample size.
p: a prime number defining the size of the sub-sample.
P: an array of generated primes.
r: an array of real numbers containing the sub-set of regular numbers.
R: an array of mixed values of .
: simulated observations from the AR(1) model.
ρ: an array containing the generated RDS sub-sample values, issued from the ρ distribution.
θ: an array containing the generated RDS sub-sample values, issued from the θ distribution.
Algorithm
Initialization for the experiment of N replicated runs.
Initialization of the run defined by the sample size n.
Simulate samples of n observations
from the model
Compute the values
Before each simulation run, generate a vector of prime numbers smaller than the sample size n and store them in a vector P.
Randomize the vector P.
Compute the sum of primes successively and stop when the sum is
Initialization of the sub-run defined by the prime p.
For each prime number
(f1) Compute the regular numbers
(f2) Randomize the
(f3) Generate the observations
(f4) Compute the simulation estimates
Compute the final RDS estimates of ρ and θ using the output sample of size
5. Results and discussion
5.1. Simulation study
In the following, we present a simulation study using the R language. We generate samples of n observations from the AR(1) model given in
which provides the values of
, S and
. Three simulation experiments were carried out with different sample sizes such as
for each selected ρ value such as 0.1, 0.3, 0.6, respectively. The proposed B2ARDS algorithm is used to compute the RDS estimates
and
together with their variances. Note that, in the estimation of ρ, different values of β are taken from one experiment to another in order to study the effect of varying β on the Bayesian estimates
and
. A summary of results is given in Tables and , together with
and
, computed using formulas (Equation7
(7)
(7) ) and (Equation8
(8)
(8) ), respectively (see Appendix 3 for details).
At the end of the simulation, we collect the sequences of and
estimates resulting from step
of the proposed algorithm. For N=10,000 replications, sequences of
estimates for initial values of
are represented in Figure while Figure represents sequences of
estimates for the same ρ values as in Figure .
5.2. Interpretation of tables
According to the simulation results given in Tables and , we have very small variances (given in parentheses). So, we can say that the sequences of RDS values and
, generated by the proposed B2ARDS algorithm are homogeneous. Also, in each case
is too close to the true value of ρ while, for some values of β,
is closer to the true value than
. It can be seen in Figure that when ρ is close to 0, the best values of
are obtained when
; while, when ρ is close to 1, the best values of
are obtained for high values of β (
). So, there are some values for ρ and β for which the resulting Bayesian estimate is ideal in accuracy.
Table 3. The simulated estimator and its variance for
and for various values of ρ, n and β. Variances in parentheses.
Table 4. The simulated estimator and its variance for
and for different values of ρ and n. Variances are given in parentheses.
For , the results in Table and Figure also prove that, for each case, the Bayesian estimate of θ is very close to the true value of θ and for some cases (n=20 and
), it is a better estimate than
. We notice here that the best values of
are obtained when ρ is close to 1.
5.3. Interpretation of figures
In each figure, the red line represents the true value of the parameter, while the green line represents the value of the resulting and
estimators for the j-th sub-run. We notice that the points which represent the estimates
and
are concentrated in a given band for all figures and nearly all points are concentrated around their mean, which represents in a Bayesian sense the resulting
and
estimators of the parameters ρ and θ, respectively. We can see from all figures that the resulting estimate is not only very close to the true value of the parameter in each case, but it coincides with it in some cases (Figure (c) and Figure (c)).
6. Conclusion
The proposed algorithm B2ARDS has allowed us to generate refined descriptive samples from input random variables for Bayesian estimation of AR(1) parameter in Monte Carlo simulation using the R software. As a consequence and apart from its already proved efficiency in the classical sense, we argue that the RDS method performs well even in a Bayesian context and allows the estimation of the AR(1) parameter using the Bayesian approach.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Albert, J. H., & Chib, S. (1993). Bayes inference via Gibbs sampling of autoregressive time series subject to Markov mean and variance shifts. Journal of Business
- Aloui, A., Zioui, A., Ourbih-Tari, M., & Alioui, A. (2015). A general purpose module using refined descriptive sampling for installation in simulation systems. Computational Statistics, 30(2), 477–490. https://doi.org/10.1007/s00180-014-0545-7
- Amaral Turkmann, M. A. (1990). Bayesian analysis of an autoregressive process with exponential white noise. Statistics, 21(4), 601–608. https://doi.org/10.1080/02331889008802270
- Andel, J. (1988). On AR(1) processes with exponential white noise. Communications in Statistics - Theory and Methods, 17(5), 1481–1495. http://doi.org/10.1080/03610928808829693
- Ashby, D. (2006). Bayesian statistics in medicine: A 25 year review. Statistics in Medicine, 25(21), 3589–3631. https://doi.org/10.1002/sim.v25:21
- Baghdali-Ourbih, L., Ourbih-Tari, M., & Dahmani, A. (2017). Implementing refined descriptive sampling into three phase discrete-event simulation models. Communications in Statistics : Simulation and Computation. Taylor and Francis, 46(5), 4035–4049. https://doi.org/10.1080/03610918.2015.1085557
- Barnett, G., Koln, R., & Sheather, S. (1996). Bayesian estimation of an autoregressive model using Markov chain Monte Carlo. Journal of Econometrics, 74(2), 237–254. https://doi.org/10.1016/0304-4076(95)01744-5
- Beaumont, M. A., & Rannala, B. (2004). The Bayesian revolution in genetics. Nature Reviews Genetics, 5(4), 251–261. https://doi.org/10.1038/nrg1318
- Boubalou, M., Ourbih-Tari, M., Aloui, A., & Zioui, A. (2019). Comparing M/G/1 queue estimators in Monte Carlo simulation through the tested generator getRDS and the proposed getLHS using variance reduction. Monte Carlo Methods and Applications, 25(2), 177–186. https://doi.org/10.1515/mcma-2019-2033
- Box, G., Jinkins, G., & Reinsel, G. (1976). Time series analysis: Forecasting and control. John Wiley and Sons.
- Corander, J. (2006). Is there a real Bayesian revolution in pattern recognition for bioinformatics. Current Bioinformatics, 1(2), 161–165. https://doi.org/10.2174/157489306777011932
- Diaz, J., & Farah, J. (1981). Bayesian identification of autoregressive processes. In Proceedings of the S.L, 22nd NBER-NSF. Seminar on Bayesian inference in econometrics.
- Geweke, J. (1999). Using simulation methods for Bayesian econometric models. Inference, Development, and Communication Econometric Reviews, 18(1), 1–126. https://doi.org/10.1080/07474939908800428
- Ghosh, M., & Heo, J. (2003). Default Bayesian priors for regression models with first-order autoregressive residuals. Journal of Time Series Analysis, 24(3), 269–282. https://doi.org/10.1111/jtsa.2003.24.issue-3
- Ibazizen, M., & Fellag, H. (2003). Bayesian estimation of an AR(1) process with exponential white noise. Journal of Theoretical and Applied Statistics, 37(5), 365–372. https://doi.org/10.1080/0233188031000078042
- Idjis, K., Ourbih-Tari, M., & Baghdali-Ourbih, L. (2017). Variance reduction in M/M/1 retrial queues using refined descriptive sampling. Communications in Statistics – Simulation and Computation, 46(6), 5002–5020. https://doi.org/10.1080/03610918.2016.1140778
- Keller, A., Heinrich, S., & Niederreiter, H. (2008). Monte Carlo and quasi Monte Carlo methods. Springer.
- Kumar, J., & Agiwal, V. (2019). Bayesian estimation for fully shifted panel AR(1) time series model. Thai Journal of Mathematics, 17, 167–183. https://thaijmath.in.cmu.ac.th
- Loh, W. L. (1996). On latin hypercube sampling. Annals of Statistics, 24(5), 2058–2080. https://doi.org/10.1214/aos/1069362310
- Marriot, J., & Smith, A. (1992). Reparametrization aspects of numerical Bayesian methods for autoregressive moving average models. Journal of Time Series Analysis, 13(4), 307–331. https://doi.org/10.1111/j.1467-9892.1992.tb00111.x
- Mckay, M. D., Conover, W. J., & Beckman, R. J. (1979). A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics, 21(2), 239–245. https://doi.org/10.2307/1268522
- Monahan, J. (1984). Fully Bayesian analysis of ARMA time series models. Journal of Econometrics, 21(3), 307–331. https://doi.org/10.1016/0304-4076(83)90048-9
- Ourbih-Tari, M., & Azzal, M. (2017). Survival function estimation with non parametric adaptative refined descriptive sampling algorithm : A case study. Communication in Statistics-Theory and Methods, 46(12), 5840–5850. https://doi.org/10.1080/03610926.2015.1065328
- Ourbih-Tari, M., Zioui, A., & Aloui, A. (2017). Variance reduction in the simulation of a stationary M/G/1 queuing system using refined descriptive sampling. Communication in Statistics-Simulation and Computation, 46(5), 3504–3515. https://doi.org/10.1080/03610918.2015.1096374
- Pereira, I., & Amaral-Turkman, M. A. (2004). Bayesian prediction in threshold autoregressive models with exponential white noise. sociedad De Estadistica E Investigacion Operativa, 13(1), 45–64. https://doi.org/10.1007/BF02603000
- Saliby, E. (1990). Descriptive sampling: A better approach to Monte Carlo simulation. Journal of the Operational Research Society, 41(12), 1133–1142. https://doi.org/10.1057/jors.1990.180
- Smith, A. F. M., & Robert, G. O. (1993). Bayesian computation via the Gibbs sampler and related Markov chain Monte Carlo methods. Journal of the Royal Statistical Society, 5(5), 3–23. https://doi.org/10.1111/j.2517-6161.1993.tbo1466.X
- Stein, M. (1987). Large sample properties of simulations using latin hypercube sampling. Technometrics, 29(2), 143–151. https://doi.org/10.1080/00401706.1987.10488205
- Suparman, S., & Rusiman, M. S. (2018). Hierarchical Bayesian estimation for stationary autoregressive models using reversible jump MCMC algorithm. International Journal of Engineering
- Tamiti, A., Ourbih-Tari, M., Aloui, A., & Idjis, K. (2018). The use of variance reduction, relative error and bias in testing the performance of M/G/1 retrial queues estimators in Monte Carlo simulation. Monte Carlo Methods and Applications, 24(3), 165–178. https://doi.org/10.1515/mcma-2018-0015
- Tari, M., & Dahmani, A. (2005a). Flowshop simulator using different sampling methods. Operational Research, 5(2), 261–272. https://doi.org/10.1007/BF02944312
- Tari, M., & Dahmani, A. (2005b). The three phase discrete event simulation using some sampling methods. International Journal of Applied Mathematics and Statistics, 3(5), 37–48.
- Tari, M., & Dahmani, A. (2006). Refined descriptive sampling: A better approach to Monte Carlo simulation. Simulation Modelling: Practice and Theory, 14(2), 143–160. https://doi.org/10.1016/j.simpat.2005.04.001
Appendices
Appendix 1 Computation of the ρ values
According to formula (Equation13(13)
(13) ), we have
By applying the inversion method, we get
where
.
We put , such that
.
Then
and
where
Appendix 2
Computation of the θ values
According to formula (Equation14(14)
(14) ), we have
We put
, such that
.
Then
and
where
so
Appendix 3
Computation of the MLE and by using the R language
We used the following programme to compute the MLE and
.
Program
;
;