
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this article, we introduce a flexible model-free approach to sufficient dimension reduction analysis using the expectation of conditional difference measure. Without any strict conditions, such as linearity condition or constant covariance condition, the method estimates the central subspace exhaustively and efficiently under linear or nonlinear relationships between response and predictors. The method is especially meaningful when the response is categorical. We also studied the -consistency and asymptotic normality of the estimate. The efficacy of our method is demonstrated through both simulations and a real data analysis.
1. Introduction
With the increase of dimensionality, the volume of the space increases so fast that the available data become sparse (Bellman, Citation1961). The sparsity is a problem to many statistical methods since not enough data is available to do model fitting or make inference. Because of the situations discussed above, many classical models derived from oversimplified assumptions and nonparametric methods are no longer reliable. Therefore, dimension reduction that reduces the data dimension but retains (sufficient) important information can play a critical role in high-dimensional data analysis. With dimension reduction as a pre-process, often the number of reduced dimensions is small. Hence, parametric and nonparametric modelling methods can then be readily applied to the reduced data.
Sufficient dimension reduction is one approach to do dimension reduction, which focuses on finding a linear transformation of the predictor matrix, so that given that transformation, the response and the predictor are independent (Cook, Citation1994, Citation1996; Li, Citation1991). For the past 25 years, sufficient dimension reduction is a hot topic and many methods have been developed to estimate the central subspace (Cook, Citation1996). These methods can be classified into three groups: inverse, forward and joint regression methods. Inverse regression methods use the regression of , and require certain conditions on
, such as linearity condition and/or constant covariance condition. Specific methods include sliced inverse regression (SIR; Li, Citation1991), sliced average variance estimation (SAVE; Cook & Weisberg, Citation1991) and directional regression (DR; Li & Wang, Citation2007). Also see (Cook & Ni, Citation2005; Cook & Zhang, Citation2014; Dong & Li, Citation2010; Fung et al., Citation2002; Zhu & Fang, Citation1996). The forward regression methods include the minimum average variance estimation (MAVE; Xia et al., Citation2002), its variants, (Xia, Citation2007; Wang & Xia, Citation2008), average derivative estimate (Härdle & Stoker, Citation1989; Powell et al., Citation1989), and structure adaptive method (Hristache et al., Citation2001; Ma & Zhu, Citation2013). The forward methods require nonparametric approaches such as kernel smoothing. Joint regression methods require the joint distribution of
, and methods include principal hessian direction (PHD; Cook, Citation1998; Li, Citation1992), and the Fourier method (Zeng & Zhu, Citation2010; Zhu & Zeng, Citation2006). They require either smoothing techniques or stronger conditions.
In this article, we develop a new sufficient dimension reduction method based on the measure proposed in Yin and Yuan (Citation2020) to estimate the central subspace. It involves the technique of slicing the range of into several intervals, which is similar to the classical inverse approaches, such as SIR and SAVE, but it does not require any linearity or constant covariance condition and can exhaustively recover the central subspace without smoothing requirement. On the other hand, comparing to other sufficient dimension reduction methods using distance measures, such as Sheng and Yin (Citation2016), our method makes more sense when the response
is categorical with no numerical meaning because the measure used in this article is properly defined for categorical variables.
This article is organized as follows: Section 2 introduces the new sufficient dimension reduction method, the algorithm, theoretical properties and the method of estimating the structural dimension d. In Section 3, we show the simulation studies, while Section 4 presents the real data analysis and a brief discussion is followed in Section 5.
2. Methodology
2.1. A measure of divergence
In Yin and Yuan (Citation2020), they proposed a new measure of divergence for testing independence between two random vectors. Let and
, where p and q are positive integers. Then the measure between
and
with finite first moments is a nonnegative number,
, defined by
(1)
(1)
where
and
stand for the characteristic functions of
and
, respectively. Let
for a complex-valued function f, with
being the conjugate of f. The weight function
is a specially chosen positive function. More details of
can be found in Yin and Yuan (Citation2020). They also give an equivalent formula as
(2)
(2)
where the expectation is over all random vectors. For instance, the last expectation is first taking the conditional expectation given
, then over
.
is an independent and identically distributed copy of
.
denotes a random variable distributed as
,
denotes a random variable distributed as
and
denotes a random variable distributed as
with
.
One property of is that it equals 0 if and only if the two random vectors are independent (Yin & Yuan, Citation2020). This property makes it possible that
can be used as a sufficient dimension reduction tool. What's more, the measure works well for both continuous and categorical
and because
is well defined for categorical
, our method is particularly meaningful when the class index of dataset does not have numerical meaning, where other measures do not attain similar advantage.
2.2. Review of sufficient dimension reduction
Let be a
matrix with
, and be the independence notation. The following conditional independence leads to the definition of sufficient dimension reduction:
(3)
(3)
where (Equation3
(3)
(3) ) indicates that the regression information of
given
is completely contained in the linear combinations of
,
. The column space of
in (Equation3
(3)
(3) ), denoted by
, is called a dimension reduction subspace.
If the intersection of all dimension reduction subspace is itself a dimension reduction subspace, then it is called the central subspace (CS), and it is denoted by (Cook, Citation1994, Citation1996; Li, Citation1991)). Under mild conditions, CS exists (Cook, Citation1998; Yin et al., Citation2008). Throughout the article, we assume CS exists, which is unique. Furthermore, let d denote the structural dimension of the CS, and let
be the covariance matrix of
, which is assumed to be nonsingular. Our primary goal is to identify the CS by estimating d and a
basis matrix of CS.
Here we introduce some notations needed in the following sections. Let be a matrix and
be the subspace spanned by the column vectors of
. dim
is the dimension of
.
denotes the projection operator, which projects onto
with respect to the inner product
, that is,
. Let
, where I is the identity matrix.
2.3. The new sufficient dimension reduction method
Let be a
arbitrary matrix, where
. Under mild conditions, it can be proved that solving (Equation4
(4)
(4) ) will yield a basis of the central subspace.
(4)
(4)
Here the squared divergence between
and
is defined as
The conditions
,
and
in Yin and Yuan (Citation2020) guarantee that the
is finite. Thus throughout the article, we assume they hold. The constraint
in (Equation4
(4)
(4) ) is needed due to the property
for any constant c (Yin & Yuan, Citation2020).
The following propositions justify our estimator. They ensure that if we maximize with respect to
under the constraint and some mild conditions, the solution indeed spans the CS.
Proposition 2.1
Let be a
basis matrix of the CS,
be a
matrix with
,
,
and
. If
, then
. The equality holds if and only if
.
Proposition 2.2
Let be a
basis matrix of the CS,
be a
matrix with
and
. Here
could be bigger, less or equal to d. Suppose
and
. Then
.
Proposition 2.1 indicates that if is a subspace of the CS, then
is less than or equal to
and the equality holds if and only if
is a basis matrix of the CS, i. e.,
. Proposition 2.2 implies that if
is not a subspace of the CS, then
is less than
under a mild condition. The above two propositions show that we can identify the CS by maximizing
with respect to
under the quadratic constraint. The condition in Proposition 2.2,
, was discussed in Sheng and Yin (Citation2013), where they showed the condition is not very strict and can be satisfied asymptotically when p is reasonably large. Proofs for Propositions 2.1 and 2.2 are in the Appendix A.
2.4. Estimating the CS when d is specified
In this section, we develop an algorithm for estimating the CS when the structural dimension d is known. Let be a random sample from
and let
be a
matrix. For the purpose of slicing, these n observations can be equivalently written as
, where
,
, where
is the number of observations for slice y. The empirical version of
denoted by
is defined as:
(5)
(5)
Here
is the Euclidean norm in the respective dimension. Let
be the estimate of
. Then an estimated basis matrix of the CS, say
, is
(6)
(6)
An outline of the algorithm is as follows.
Obtain the initials
: any existing sufficient dimension reduction method, such as SIR (Li, Citation1991) or SAVE (Cook & Weisberg, Citation1991) can be used to obtain the initial.
Iterations: let
Check convergence: if the difference between
In the above algorithm, we assume the structural dimension d is known, which is not true in practice. We will propose an approach to estimate d in Section 2.6.
2.5. Theoretical properties
Proposition 2.3
Let , and
be a basis matrix of the CS with
. Under the condition
,
is a consistent estimator of a basis of the CS, that is, there exists a rotation matrix
:
, such that
.
Furthermore, we can prove the -consistency and asymptotic normality of the estimator as stated below.
Proposition 2.4
Let , and
be a basis matrix of the CS with
. Under the regularity conditions in the supplementary file, there exists a rotation matrix
:
such that
, where
is the covariance matrix given in the supplementary file.
Proofs of Propositions 2.3 and 2.4 are in Appendices B and C, respectively.
2.6. Estimating structural dimension d
There is a rich literature of discussing determining d in sufficient dimension reduction, for example, some nonparametric methods such as Wang and Xia (Citation2008), Ye and Weiss (Citation2003) and Luo and Li (Citation2016) and some eigen-decomposition-based methods, for examples, Luo et al. (Citation2009), and Wang et al. (Citation2015). Here we apply the kNN method proposed in Wang et al. (Citation2015).
Given a sample , d can be estimated by the following kNN procedure.
Find the k-nearest neighbours for each data point
For each data point
Calculate the eigenvalues of the matrix
Calculate the ratios
In the last step, this maximal eigenvalue ratio criterion was suggested by Luo et al. (Citation2009) and was also used by Li and Yin (Citation2009) and Sheng and Yuan (Citation2020).
3. Simulation studies
Estimation accuracy is measured by the distance (Li et al., Citation2005), where
is the real d-dimensional CS of
,
is the estimate,
,
are the orthogonal projections onto
and
, respectively and
is the maximum singular value of a matrix. The smaller the
is, the better the estimate is. Also a method works better if it has a smaller standard error of
. In the following, the first three examples show the nice performance of the proposed method in terms of both continuous and categorical response, assuming we already know the dimension d. The last example illustrates the performance of estimating dimension d using the kNN procedure in Section 2.6.
Example 3.1
Consider the Model 1
where
,
and ϵ is independent of
.
, and
. We compare DCOV (Sheng & Yin, Citation2016), SIR (Li, Citation1991), SAVE (Cook & Weisberg, Citation1991) and LAD (Cook & Forzani, Citation2009) with our method ECD with 10 slices.
Table shows the average estimation accuracy () and its standard error (SE) under different
combinations and 500 replications. Note that ECD performs consistently better than other methods, under all the different
combinations.
Table 1. Estimation accuracy report for Model 1.
Example 3.2
This model was studied by Cui et al. (Citation2011). It has binary responses 1 and 0, which have no numerical meaning. Model 2 is
where
,
and
. The simulation results are reported in Table .
Table 2. Estimation accuracy report for Model 2.
Example 3.3
Consider another binary-response model, Model 3:
where
follows the multivariate uniform distribution
,
, and ϵ is independent of
,
, and
. The simulation results are reported in Table .
Table 3. Estimation accuracy report for Model 3.
From the simulation results, we find ECD method outperforms other methods when the response is continuous. When the response is categorical, it also performs better than SIR, SAVE and LAD and its performance is comparable to DCOV. To be more specific, the accuracy of ECD and DCOV is very close as sample size n gets large when the response is categorical. On the other hand, the computation speed of ECD is faster than that of DCOV due to its slicing technique in calculating
. For example, when
, ECD is about 2.7 times faster than DCOV under Model 1 and 2, and about 3.6 times faster under Model 3. Overall, ECD is superior to other methods.
Example 3.4
Estimating d. We test the performance of the kNN procedure in Section 2.6 based on Model 1 and Model 2. Table shows that the kNN procedure can estimate dimension d very precisely, no matter the response is continuous or categorical.
Table 4. Accuracy of estimating d with kNN procedure.
4. Real data analysis
To further investigate the performance of our method, we apply it to the Pen Digit database from the UCI machine-learning repository. The data contains 10,992 samples of hand-written digits . The digits were collected from 44 writers and every writer was asked to write 250 random digits. Every digit is represented as a 16-dimensional feature vector. The 44 writers are divided into two groups, in which 30 are used for training, while others are used for testing. The data set and more details are available at archive.ics.uci.edu/ml/machine-learning-databases/pendigits/.
We choose the 0's, 6's and 9's, three hardly classified digits, as an illustration. In this subset of the database, there are 2,219 cases in the training data and 1,035 cases in the test data. We apply the dimension reduction methods to the 16-dimensional predictor vector for the training set, which serves as a preparatory step for the three-group classification problem. Because the response has three slices, SIR estimates only two directions in the dimension reduction subspace. The other methods, SAVE, DCOV and ECD, all estimate three directions. Figure presents the two-dimensional plot of (SIR1, SIR2) and Figure shows the three dimensional plots of (SAVE1, SAVE2, SAVE3), (DCOV1, DCOV2, DCOV3) and (ECD1, ECD2, ECD3). SIR provides only location separation of the three groups. SAVE implies there are covariance differences among three groups, but no clear location separation is provided. Both DCOV and ECD get the location separation and covariance differences, but ECD presents a more clear separation among the three groups.The three-dimensional plot of (ECD1, ECD2, ECD3) gives a comprehensive demonstration of the different features of the three groups.
Figure 1. 2D-plot for the two predictors estimated by SIR.
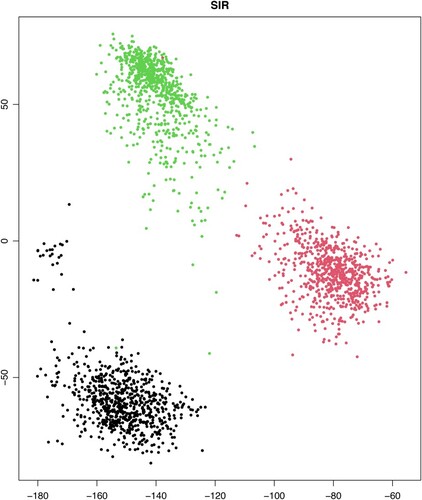
Figure 2. 3D-plots for the three predictors estimated by SAVE, DCOV and ECD.

5. Discussion
In this article, we proposed a new sufficient dimension reduction method. We studied its asymptotic properties and introduced the kNN procedure to estimate the structural dimension d. The numerical studies show that our method can estimate the CS accurately and efficiently. In the future, we consider to develop a variable selection method by combining our method with the penalized method such as LASSO (Tibshirani, Citation1996). Furthermore, it can be extended to large p small n problems by using the framework of Yin and Hilafu (Citation2015).
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Bellman, R. (1961). Adaptive control processes. Princeton University Press.
- Byrd, R. H., Gilbert, J. C., & Nocedal, J. (2000). A trust region method based on interior point techniques for nonlinear programming. Mathematical Programming, 89(1), 149–185. https://doi.org/10.1007/PL00011391
- Byrd, R. H., Mary, E. H., & Nocedal, J. (1999). An interior point algorithm for large-scale nonlinear programming. SIAM Journal on Optimization, 9(4), 877–900. https://doi.org/10.1137/S1052623497325107
- Cook, R. D. (1994). Using dimension-reduction subspaces to identify important inputs in models of physical systems. Proc. Phys. Eng. Sci. Sect. (pp. 18–25).
- Cook, R. D. (1996). Graphics for regressions with a binary response. Journal of the American Statistical Association, 91(435), 983–992. https://doi.org/10.1080/01621459.1996.10476968
- Cook, R. D. (1998). Regression graphics: ideas for studying regressions through graphics. Wiley.
- Cook, R. D., & Forzani, L. (2009). Likelihood-Based sufficient dimension reduction. Journal of the American Statistical Association, 104(485), 197–208. https://doi.org/10.1198/jasa.2009.0106
- Cook, R. D., & Ni, L. (2005). Sufficient dimension reduction via inverse regression: a minimum discrepancy approach. Journal of the American Statistical Association, 100(470), 410–428. https://doi.org/10.1198/016214504000001501
- Cook, R. D., & Weisberg, S. (1991). Sliced inverse regression for dimension reduction: comment. Journal of the American Statistical Association, 86(414), 328–332.
- Cook, R. D., & Zhang, X. (2014). Fused estimators of the central subspace in sufficient dimension reduction. Journal of the American Statistical Association, 109(506), 815–827. https://doi.org/10.1080/01621459.2013.866563
- Cui, X., Härdle, W., & Zhu, L. (2011). The EFM approach for single-index models. The Annals of Statistics, 12(3), 793–815.
- Dong, Y., & Li, B. (2010). Dimension reduction for non-elliptically distributed predictors: second-order methods. Biometrika, 97(2), 279–294. https://doi.org/10.1093/biomet/asq016
- Fung, W., He, X., Liu, L., & Shi, P. (2002). Dimension reduction based on canonical correlation. Statistica Sinica, 12(4), 1093–1113.
- Härdle, W., & Stoker, T. (1989). Investigating smooth multiple regression by the method of average derivatives. Journal of the American Statistical Association, 84(408), 986–995.
- Hristache, M., Juditsky, A., Polzehl, J., & Spokoiny, V. (2001). Structure adaptive approach for dimension reduction. The Annals of Statistics, 29(6), 1537–1811. https://doi.org/10.1214/aos/1015345954
- Lehmann, E. L. (1999). Elements of large-sample theory. Springer-Verlag.
- Li, K.-C. (1991). Sliced inverse regression for dimension reduction. Journal of the American Statistical Association, 86(414), 316–327. https://doi.org/10.1080/01621459.1991.10475035
- Li, K.-C. (1992). On principal Hessian directions for data visualization and dimension reduction: another application of stein's lemma. Journal of the American Statistical Association, 87(420), 1025–1039. https://doi.org/10.1080/01621459.1992.10476258
- Li, B., & Wang, S. (2007). On directional regression for dimension reduction. Journal of American Statistical Association, 102(479), 997–1008. https://doi.org/10.1198/016214507000000536
- Li, L., & Yin, X. (2009). Longitudinal data analysis using sufficient dimension reduction method. Computational Statistics and Data Analysis, 53(12), 4106–4115. https://doi.org/10.1016/j.csda.2009.04.018
- Li, B., Zha, H., & Chiaromonte, F. (2005). Contour regression: a general approach to dimension reduction. The Annals of Statistics, 33(4), 1580–1616. https://doi.org/10.1214/009053605000000192
- Luo, W., & Li, B. (2016). Combining eigenvalues and variation of eigenvectors for order determination. Biometrika, 103(4), 875–887. https://doi.org/10.1093/biomet/asw051
- Luo, R., Wang, H., & Tsai, C. L. (2009). Contour projected dimension reduction. The Annals of Statistics, 37(6B), 3743–3778. https://doi.org/10.1214/08-AOS679
- Ma, Y., & Zhu, L. (2013). Efficient estimation in sufficient dimension reduction. The Annals of Statistics, 41(1), 250–268. https://doi.org/10.1214/12-AOS1072
- Powell, J., Stock, J., & Stoker, T. (1989). Semiparametric estimation of index coefficients. Econometrica: Journal of the Econometric Society, 57(6), 1403–1430. https://doi.org/10.2307/1913713
- Serfling, R. J. (1980). Approximation theorems of mathematical statistics. Wiley.
- Sheng, W., & Yin, X. (2013). Direction estimation in single-index models via distance covariance. Journal of Multivariate Analysis, 122, 148–161. https://doi.org/10.1016/j.jmva.2013.07.003
- Sheng, W., & Yin, X. (2016). Sufficient dimension reduction via distance covariance. Journal of Computational and Graphical Statistics, 25(1), 91–104. https://doi.org/10.1080/10618600.2015.1026601
- Sheng, W., & Yuan, Q. (2020). Sufficient dimension folding in regression via distance covariance for matrix-valued predictors. Statistical Analysis and Data Mining, 13(1), 71–82. https://doi.org/10.1002/sam.v13.1
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), 58(1), 267–288. https://doi.org/10.1111/rssb.1996.58.issue-1
- Waltz, R. A., Morales, J. L., & Orban, D. (2006). An interior algorithm for nonlinear optimization that combines line search and trust region steps. Mathematical Programming, 107(3), 391–408. https://doi.org/10.1007/s10107-004-0560-5
- Wang, H., & Xia, Y. (2008). Sliced regression for dimension reduction. Journal of the American Statistical Association, 103(482), 811–821. https://doi.org/10.1198/016214508000000418
- Wang, Q., Yin, X., & Critchley, F. (2015). Dimension reduction based on the hellinger integral. Biometrika, 102(1), 95–106. https://doi.org/10.1093/biomet/asu062
- Xia, Y. (2007). A constructive approach to the estimation of dimension reduction directions. The Annals of Statistics, 35(6), 2654–2690. https://doi.org/10.1214/009053607000000352
- Xia, Y., Tong, H., Li, W. K., & Zhu, L.-X. (2002). An adaptive estimation of dimension reduction space. Journal of the Royal Statistical Society. Series B (Statistical Methodology), 64(3), 363–410. https://doi.org/10.1111/rssb.2002.64.issue-3
- Ye, Z., & Weiss, R. E. (2003). Using the bootstrap to select one of a new class of dimension reduction methods. Journal of the American Statistical Association, 98(464), 968–979. https://doi.org/10.1198/016214503000000927
- Yin, X., & Hilafu, H. (2015). Sequential sufficient dimension reduction for large p, small n problems. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 77(4), 879–892. https://doi.org/10.1111/rssb.2015.77.issue-4
- Yin, X., Li, B., & Cook, R. D. (2008). Successive direction extraction for estimating the central subspace in a multiple-index regression. Journal of Multivariate Analysis, 99(8), 1733–1757. https://doi.org/10.1016/j.jmva.2008.01.006
- Yin, X., & Yuan, Q. (2020). A new class of measures for testing independence. Statistica Sinica, 30(4), 2131–2154.
- Zeng, P., & Zhu, Y. (2010). An integral transform method for estimating the central mean and central subspace. Journal of Multivariate Analysis, 101(1), 271–290. https://doi.org/10.1016/j.jmva.2009.08.004
- Zhu, L., & Fang, K. (1996). Asymptotics for kernel estimate of sliced inverse regression. The Annals of Statistics, 24(3), 1053–1068. https://doi.org/10.1214/aos/1032526955
- Zhu, Y., & Zeng, P. (2006). Fourier methods for estimating the central subspace and the central mean subspace in regression. Journal of the American Statistical Association, 101(476), 1638–1651. https://doi.org/10.1198/016214506000000140
Appendix A
Proofs of Propositions 2.1 and 2.2
In order to prove Propositions 2.1 and 2.2 in Section 2.3 in the article, we first provide and prove the following Lemma A.1.
Lemma A.1
Suppose is a basis of the central subspace. Let
be any partition of
, where
. We have
, i = 1, 2.
Proof
Let ,
,
,
and
, and
,
. A simple calculation shows that
.
If , then F(0,1), F(1,0) > 0; otherwise, the conclusion automatically holds.
Claim, if , then
and
.
If not, then there exists a such that
or
. Without loss of generality, we assume there exists a
such that
.
But , and as
,
. Thus
, as
. That means, there exists a
such that
achieves a minimum in
. Hence,
. Note that function
is a ‘ray’ function, i. e.
. Thus using the fact that
, we can have
. And it is easy to calculate that
.
But .
means that
, which conflicts with our assumption.
Proof of Proposition 2.1
Since ,
, there exists a matrix
, which satisfies
. Therefore,
.
Assume the single value decomposition of A is , where U is a
orthogonal matrix, V is a
orthogonal matrix and Σ is a
diagonal matrix with nonnegative numbers on the diagonal, and it is easy to prove that all nonnegative numbers on the diagonal of Σ are 1. Based on Theorem 3, part (2) of Yin and Yuan (Citation2020),
.
Let . Since all nonnegative numbers on the diagonal of Σ are 1 and
, by Lemma A.1, we get
. The equality holds if and only if
. And again based on Theorem 3, part (2) of Yin and Yuan (Citation2020),
. Thus,
, and equality holds if and only if
.
Proof of Proposition 2.2
For the and
described in Proposition 2.2, there exists a rotation matrix
such that
, and
,
, where
is the orthogonal space of
.
Since and
,
, and according to Proposition 4.3 (Cook, Citation1998),
. Let
,
,
, and
. Then
. According to Yin and Yuan (Citation2020) Theorem 1, part (2),
, that is
.
Appendix B
Proof of Proposition 2.3
In order to prove Proposition 2.3 in Section 2.5 of this article, we provide and prove the following Lemma B.1 first.
Lemma B.1
If the support of X, say S, is compact and furthermore, , then
.
Proof
Based on Yin and Yuan (Citation2020) Corollary 1, we have that
Because
in probability, let
. Then for any
,
, when
, where
is the Frobenius norm. Hence, by the condition on X, we have that for a positive constant
, and large n,
. Hence the conclusion follows.
Proof of Proposition 2.3
To simplify the proof, we restrict the support of to be a compact set, and it can be shown that
(Yin et al., Citation2008, Proposition 10), where
is
restricted onto S. Without loss of generality, we assume
. Suppose
is not a consistent estimator of
. Then there exists a subsequence, still to be indexed by n, and an
satisfying
such that
but
.
By Lemma B.1, we have and by Lemma 3 in Yin and Yuan (Citation2020), we have
. Therefore,
.
On the other hand, because , we have
. If we take the limit on both sides of the above inequality, we get
. However, we have proved that under the assumption
,
, and we also assume that the central subspace is unique. Therefore,
conflicts with the above assumption, so
is a consistent estimator of a basis of the central subspace.
Appendix C
Proof of Proposition 2.4
Lagrange multiplier technique is used to prove the -consistency of vec
in the Proposition 2.4 in Section 2.5 of the article. First, we introduce the following notations and conditions and we also give a new definition.
For a random sample from the joint distribution of random vectors
in
and
in
, let
and
. Here
,
,
,
is the covariance matrix of X, and
is the sample estimate for
. Let
. Then there exists a
such that
is a stationary point for
. Let
. Then
. Let
be a basis of CS. Then under the assumption
, there exists a rotation matrix
, such that
. Without loss of generality, we assume
here. Therefore, there exists a
such that
is a stationary point for
. Let
.
In the proof, we need to take derivatives of and
with respect to vec
, so for the simplicity of notation, when we consider the derivatives of
and
, we use
and
to denote
and
, respectively.
Here are additional notations, which will be used later in the following proof. is the vec-permutation matrix.
is a identity matrix with rank m, and
denotes the ith column of
.
denotes the Kronecker product between matrix
and
. vec(·) is a vec operator.
Furthermore, we give the following definition and assumptions.
Definition A.1
Let , where α is a
matrix,
, c is a fixed small constant, and
is the Frobenius norm. We define an indicator function
where
is an i.i.d. copy of
and
is a small number. We define the second and third derivatives of
with respect to vec(
) as
and
. For the simplicity of notation, we will still use
and
to denote
and
, respectively.
The reason we use this definition is that under Definition C.1, the second and third derivatives of and
are bounded, near the neighbourhood of the central subspace.
Assumption C.1
Var, Var
, Var
, Var
, Var
, Var
, Var
are all
. Here
Here
are i.i.d copies and
are i.i.d copies in the yth slice.
Assumption C.2
is nonsingular.
Assumption C.1 is needed for Proposition 2.4 in the main article and Lemma C.1 in the next section, which is similar to the assumed conditions of Theorem 6.1.6 (Lehmann, Citation1999, Ch. 6). This assumption is required by the asymptotic properties of U-statistics.
Assumption C.2 is in the spirit of von Mises proposition (Serfling, Citation1980, Section 6.1). In this proposition, it claims that if the first nonvanishing term of Taylor expansion is the linear term, then the -consistency of the differentiable statistical function can be achieved. In our case, we assume the corresponding matrix is nonsingular, which guarantees the
-consistency. If the matrix is singular, then n or higher order consistency of some parts of our estimates can be proved.
In order to prove Proposition 2.4 in Section 2.5 of the paper, we provide and prove the following Lemma C.1 first.
Lemma C.1
Under Assumptions C.1, C.2 and the assumptions in Proposition 2.4, then . The explicit expression for
is in the proof.
Proof
The Taylor expansion of at
is
, where
, where
is the Frobenius norm and
. Next, we will give explicit expressions of
,
and
. With simple calculation,
,
where
and
It is obvious that
, where
and
Here
and
The remainder term involves the third derivative of
at
. Let
, where
is a
array and each
, is a
matrix. Therefore, the form of
can be written as
Based on the above explicit expression of
,
and
, the Taylor expansion of
at
can be written as
From the above Taylor expansion of
at
, we get
Next, we will prove two parts.
Part 1:
Part 2:
Proof of part 1
We will show that both and vec
are linear combinations of U-statistics and the asymptotic distribution can be achieved by the asymptotic property of U-statistics.
Based on Corollary 1 in Yin and Yuan (Citation2020),
With some calculation, we can get
where
Here
,
,
,
are U-statistics. In the notation
,
,
, where H denotes the number of slices and
is the number of samples in the yth slice.
Considering the term vec, which is also a linear combination of U-statistics, let
and then vec
.
Let
Here
are i.i.d copies and
are i.i.d copies in the yth slice.
According to Theorem 6.1.6 (Lehmann, Citation1999, Ch.6),
where
Let , where
is a
zero matrix. Then
Note that
and under Assumption C.1,
Therefore, according to Slutsky's theorem,
Let
Under Assumption C.2 and our definition of second derivative of , by SLLN of U-statistics,
. Therefore,
where
.
Proof of part 2
Under Assumption C.2 and Definition C.1,
Therefore, by Slutsky's theorem,
Therefore,
, or in other words,
is
-consistent estimation of
.
In the above proof, without loss of generality, we assume that . Note that with an orthogonal matrix
,
and
(Yin & Yuan, Citation2020). If define
, without assuming
, then Lemma C.1 holds by using
which is obtained by replacing every
in
with
. (Of course, then
in the proof).
Proof of Proposition 2.4
Let be a
matrix, where
is a
identity matrix. Then vec
and vec
. By Lemma C.1, we have
, or in other word,
, where
.