
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In randomized clinical trials with right-censored time-to-event outcomes, the popular log-rank test without adjusting for baseline covariates is asymptotically valid for treatment effect under simple randomization of treatments but is too conservative under covariate-adaptive randomization. The stratified log-rank test, which adjusts baseline covariates in the test procedure by stratification, is asymptotically valid regardless of what treatment randomization is applied. In the literature, however, under simple randomization there is no affirmative conclusion about whether the stratified log-rank test is asymptotically more powerful than the unstratified log-rank test. In this article we show when the stratified and unstratified log-rank tests aim for the same null hypothesis and that, under simple randomization, the stratified log-rank test is asymptotically more powerful than the unstratified log-rank test in the region of alternative hypothesis that is specified by a Cox proportional hazards model. We also provide some discussion about why we do not have an affirmative conclusion in general.
1. Introduction
The log-rank test (Mantel, Citation1966) and stratified log-rank test (Peto et al., Citation1976) are the two longstanding and most popular nonparametric tests for treatment effect in randomized clinical trials with two treatment arms and right-censored time-to-event outcomes. What motivates the stratified version of log-rank test is that baseline prognostic factors (covariates), measured prior to treatment assignments and thus not affected by treatments, are adjusted through stratification for efficiency gain.
Adjusting baseline covariates has been widely advocated to improve efficiency for tests and other analyzes, in the following two aspects. (i) In the design stage, covariate-adaptive randomization can be used to enforce the balance of treatment assignments across baseline prognostic factors, which results in more efficient tests (EMA, Citation2015). More details about covariate-adaptive randomization are given in Section 2. (ii) In the analysis stage, ‘incorporating prognostic baseline factors in the primary statistical analysis of clinical trial data can result in a more efficient use of data to demonstrate and quantify the effects of treatment’ (FDA, Citation2021), ‘under approximately the same minimal statistical assumptions that would be needed for unadjusted’ (EMA, Citation2015; FDA, Citation2021; ICH E9, Citation1998).
If the log-rank test is considered as ‘unadjusted test’, then the stratified log-rank test qualifies as an adjusted test under the same minimal assumption because it is still a nonparametric test without using any model. Tests using the Cox proportional hazards model as a working model are also qualified (DiRienzo & Lagakos, Citation2002; Kong & Slud, Citation1997; Lin & Wei, Citation1989), but the resulting tests can be less efficient than the unadjusted log-rank test when the working model is wrong (Kong & Slud, Citation1997). In this paper we focus on the stratified and unstratified log-rank tests.
Although stratified log-rank test uses information from baseline prognostic factors and thus is expected to be more efficient, an affirmative conclusion about whether it is asymptotically more efficient than the unstratified log-rank test is not available, under simple randomization in which patients are assigned to treatments completely at random. Another issue is that the stratified log-rank actually tests a null hypothesis stronger than that of the log-rank test and, hence, a prerequisite in their comparison is to investigate when the two null hypotheses are the same.
The purpose of this paper is to establish some affirmative conclusions about the stratified and unstratified log-rank tests, in terms of null hypothesis, asymptotic validity of tests and Pitman's asymptotic relative efficiency. The research is important as these two longstanding tests are used a lot in applications without a guidance on which one should be used.
Section 2 describes data, design, and log-rank test statistics. Section 3 introduces hypotheses, assumptions and the concept of validity for log-rank tests. Some theoretical results for stratified and unstratified log-rank tests are given in Section 4, where we show that, under simple randomization, the stratified log-rank test is asymptotically more powerful in the region of alternative hypothesis that is specified by a Cox proportional hazards model. Section 5 contains conclusions and Appendix provides technical proofs.
2. Data, design and test statistics
For a patient from the population under investigation, let and
be the potential life time and right-censoring time, respectively, under treatment
or 1, and W be the vector of all baseline covariates and other time-varying covariates, observed or unobserved. Suppose that a random sample of n patients is obtained from the population with independent
,
, identically distributed as
. For each patient, only one of the two treatments is assigned and received.
Let be a binary treatment indicator for patient i and
be the pre-specified treatment assignment proportion for treatment 1. Consider the design, i.e. the generation of
's for n sequentially arrived patients. Simple randomization assigns patients to treatments completely at random with
for all i, which may yield treatment proportions that substantially deviate from the target π across levels of some baseline prognostic factors. Because of this, covariate-adaptive randomization using Z, a sub-vector of W containing observed baseline prognostic factors with finitely many joint levels, is widely applied. When patient i with baseline
is arrived, a treatment is assigned using a mechanism dependent on all previously assigned treatments for patients with
. For example, the most popular covariate-adaptive randomization scheme, the stratified permuted block design (Zelen, Citation1974), randomly assigns sequentially arrived patients with
in blocks of size B, each having
patients in treatment 1, where B is appropriately chosen so that
is an integer and the last block is allowed to be incomplete. Another popular covariate-adaptive randomization is Pocock-Simon's minimization (Pocock & Simon, Citation1975; Taves, Citation1974). Other schemes can be found in two reviews, Schulz and Grimes (Citation2002) and Shao (Citation2021). To see how popular covariate-adaptive randomization is, it was used in more than 500 clinical trials between 1989 and 2008 (Taves, Citation2010) and 237 trials among nearly 300 trials published in two years, 2009 and 2014 (Ciolino et al., Citation2019). All commonly used covariate-adaptive randomization schemes satisfy the following mild condition (Antognini & Zagoraiou, Citation2015).
Given
,
Most commonly used covariate-adaptive randomization schemes except Pocock-Simon's minimization also satisfy the next condition.
Conditional on
Although simple randomization is not counted as covariate-adaptive randomization, it satisfies (D1) and (D2) with .
After is assigned, the observed outcome from patient i is
with
and
, together with an indicator of
.
The log-rank test statistic is (1)
(1) where
,
,
the indicator of the event
,
,
,
,
is the indicator of the event
, and the upper limit τ in the integral is a point satisfying
for j = 0, 1.
The stratified log-rank test statistic is a weighted average of the stratum-specific log-rank test statistics with strata constructed using Z, (2)
(2) where
,
, and
.
It is clear that in terms of test statistics, the stratified in (Equation2
(2)
(2) ) utilizes Z values whereas the unstratified
in (Equation1
(1)
(1) ) is unadjusted. Under covariate-adaptive randomization,
is not completely unadjusted since it uses Z-information through assignments
's, although it does not adjust for covariate-adaptive randomization in a correct way. On the other hand, the stratified
uses Z-information in both design and analysis stages.
We consider stratification with all levels of Z. In applications, it is allowed to use more covariates to form strata. The conclusions in what follows remain the same. However, it is not a good idea to use fewer levels of Z for stratification, because it may result in a test that is not asymptotically valid.
3. Null hypothesis, assumption and validity
Throughout, denotes a given significance level and
is the
th quantile of the standard normal distribution. When
, the log-rank test rejects the following null hypothesis
of no treatment effect,
(3)
(3) where
is the unconditional hazard function of
, j = 0, 1.
in (Equation3
(3)
(3) ) is a commonly adopted null hypothesis of no treatment effect unconditional on covariates.
The log-rank test is nonparametric. Its validity requires non-informative censoring (DiRienzo & Lagakos, Citation2002; Kong & Slud, Citation1997), i.e.,
(C) is independent of
given j.
Under simple randomization, it is well-known (Kalbfleisch & Prentice, Citation2011) that the log-rank test is asymptotically valid in the sense that
(4)
(4) with equality holding for at least one population P under
.
Unlike simple randomization, covariate-adaptive randomization generates a dependent sequence of treatment assignments, which may render conventional methods developed under simple randomization, such as the log-rank test, not valid under covariate-adaptive randomization (EMA, Citation2015; FDA, Citation2021). It is shown in Ye and Shao (Citation2020) that, under covariate-adaptive randomization with ν in (D2) strictly smaller than , the log-rank test is asymptotically conservative in the sense that,
(5)
(5) for all P under
.
The stratified log-rank in (Equation2
(2)
(2) ) actually tests the null hypothesis
(6)
(6) where
is the hazard function of
conditional on Z = z, j = 0, 1. Note that
in (Equation6
(6)
(6) ) holds if and only if the hazard functions are the same in every stratum z and, thus, is stronger than
in (Equation3
(3)
(3) ).
The validity of stratified log-rank test requires the following assumption on censoring:
(CZ) is independent of
given j and Z.
Conditions (C) and (CZ) are not comparable, although both are implied by that is independent of
given j, a reasonable condition for non-informative censoring.
Under simple randomization and covariate-adaptive randomization satisfying (D1) in Section 2, (Equation4(4)
(4) ) holds with
replaced by
and
replaced by
(Ye & Shao, Citation2020), provided that all levels of Z are used in stratification.
Since is stronger than
, the stratified and unstratified log-rank tests are not comparable. Thus, a prerequisite for the comparison of efficiency of two log-rank tests is
. Is there a scenario under which
? Consider the following transformation model assumption.
There is an increasing function h such that
Assumption (TR) is discussed in Cheng et al. (Citation1995), which includes many commonly used semiparametric models as special cases, for example, the Cox proportional hazards model (see formula (Equation7(7)
(7) ) in Section 4). It is a mild assumption since h is unknown and we only need to know it exists.
The proof of following result is in the Appendix.
Theorem 3.1
Under (TR), in (Equation6
(6)
(6) ) is the same as
in (Equation3
(3)
(3) ).
4. Comparison of two log-rank tests
When , is the stratified log-rank test
more efficient than the unstratified log-rank test
under simple randomization when both tests are asymptotic valid? Intuitively this sounds correct since
does not adjust for covariates.
Unfortunately, there is no result on this in the literature. In this section we try to fill this gap to some extent and explain why the two log-rank tests are not comparable in terms of efficiency. This is important because both stratified and unstratified log-rank tests are used a lot in applications.
To this goal, we first state the following asymptotic result (whose proof is given in Appendix) for the asymptotic distributions of stratified and unstratified log-rank tests under local alternatives. Define
where
,
,
, and
. Also, we use
to denote
for any i and
to denote
for any i and z. Note that, under the null hypothesis
,
for j = 0, 1, and under the null hypothesis
,
for all z and j = 0, 1.
Theorem 4.1
Assume (CZ) and (D1). Under the local alternative hypothesis that
Assume (C), (D1), and (D2). Under the local alternative hypothesis that
Because the local alternative hypotheses specified in (a) and (b) of Theorem 4.1 do not follow any model, and
can be arbitrarily very different and, thus,
and
may be not comparable in terms of asymptotic efficiency. In other words, the space of alternative hypothesis is too large to compare efficiency of
and
, as there is no model at all. A semiparametric model on alternative hypothesis narrowing down the space of alternative hypothesis may result in affirmative results of comparing efficiency. We derive a result under the Cox proportional hazards model to highlight this.
Suppose that the true hazard follows a Cox proportional hazards model,
(7)
(7) where
,
is the hazard conditional on covariate V, θ is an unknown parameter, η is an unknown parameter vector, and
is an unspecified function. Under model (Equation7
(7)
(7) ), (TR) holds with
and
.
Corollary 4.1
Assume that model (Equation7(7)
(7) ) holds,
is independent of
given j, and
for all t. Then, under simple randomization, the stratified log-rank test
is always more efficient than the unstratified log-rank test
in terms of Pitman's asymptotic relative efficiency.
The proof is given in the Appendix. A key to the proof is that the local alternative hypotheses in (a) and (b) of Theorem 4.1 can be unified into with the help of model (Equation7
(7)
(7) ).
As both log-rank tests are nonparametric and do not need model (Equation7(7)
(7) ), what does Corollary 4.1 tell us? It says that, under simple randomization, the stratified log-rank test
is more efficient in the region of alternative hypothesis specified by model (Equation7
(7)
(7) ), although we cannot claim that
is more efficient in the entire alternative hypothesis space.
We now turn to covariate-adaptive randomization, under which the unstratified log-rank test is not valid but conservative, as we discussed in Section 3. On the other hand, by Theorem 4.1(a), the stratified log-rank test
is valid for testing
regardless of which covariate-adaptive randomization is applied. Therefore, stratified log-rank test is a clear winner when covariate-adaptive randomization is applied.
Another way to adjust for covariates used in randomization is the modified (unstratified) log-rank test proposed by Ye and Shao (Citation2020), where
is a consistent estimator of
(see §3.2 of Ye and Shao Citation2020).
removes the conservativeness of
and is valid for testing
in (Equation3
(3)
(3) ) under covariate-adaptive randomization.
Even if model (Equation7(7)
(7) ) holds,
and
are not comparable in terms of asymptotic efficiency. We provide two simulation examples here to demonstrate that
is more efficient in one scenario but less efficient in another scenario, compared with
. The simulation setting is model (Equation7
(7)
(7) ) with
for all t and
, where
is binary with
,
, and
and
are independent.
and discretized
with 4 equal probability categories are used for stratified permuted block randomization with block size 4. In scenario 1, censoring is independent of treatment and
and distributed as uniform on (10,40). In scenario 2, censoring is independent of treatment and
, but conditioned on
, and censoring is distributed as 10 + the exponential distribution with mean
. The power curves over θ with
and n = 500 based on 2000 simulations are given in Figure . Note that
is more powerful than
under scenario 1 but less powerful under scenario 2. Both
and
are more powerful than the conservative
in any case.
Figure 1. Power curves based on n = 500 and 2000 simulations.
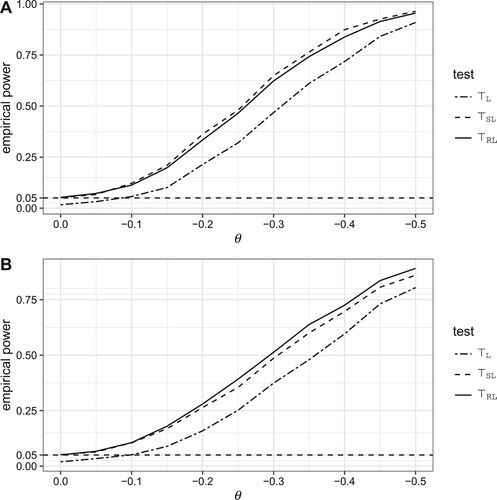
The reason why the stratified and the modified unstratified
are not comparable in asymptotic efficiency is that the two tests adopt different approaches in utilizing baseline covariates: the former adjusts baseline covariates by stratification, whereas the latter utilizes baseline covariates by modifying the unstratified
whose performance is affected by covariate-adaptive randomization.
5. Conclusion and discussion
Under some semiparametric models for survival time such as the transformation model (TR) described in Section 3, the null hypotheses of stratified and unstratified log-rank tests are the same.
Under simple randomization of treatment assignments, the stratified log-rank test is asymptotically more efficient than the unstratified log-rank test in terms of Pitman's relative efficiency in the region of alternative hypothesis specified by the Cox proportional hazards model given by (Equation7
Under covariate-adaptive randomization of treatment assignments, the unstratified log-rank test is not asymptotically valid but conservative, whereas the stratified log-rank test is asymptotically valid as long as the covariates used in randomization are all included in stratification. Thus, the stratified log-rank test is a clear winner. A modified unstratified log-rank test removes conservativeness and is valid, but its relative efficiency compared with the stratified log-rank test has no definite conclusion, because the two tests apply different approaches in utilizing covariates.
Because the region specified by the Cox model is quite large and the stratified log-rank test is a clear winner under covariate-adaptive randomization, we recommend the stratified log-rank test over the unstratified log-rank test.
Acknowledgements
We would like to thank two anonymous referees and an associate editor for helpful comments and suggestions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Antognini, A. B., & Zagoraiou, M. (2015). On the almost sure convergence of adaptive allocation procedures. Bernoulli Journal, 21(2), 881–908.
- Cheng, S., Wei, L., & Ying, Z. (1995). Analysis of transformation models with censored data. Biometrika, 82(4), 835–845. https://doi.org/10.1093/biomet/82.4.835
- Ciolino, J. D., Palac, H. L., Yang, A., Vaca, M., & Belli, H. M. (2019). Ideal vs. real: A systematic review on handling covariates in randomized controlled trials. BMC Medical Research Methodology, 19(1), 136. https://doi.org/10.1186/s12874-019-0787-8
- DiRienzo, A. G., & Lagakos, S. W. (2002). Effects of model misspecification on tests of no randomized treatment effect arising from cox's proportional hazards model. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63(4), 745–757. https://doi.org/10.1111/1467-9868.00310
- EMA (2015). Guideline on adjustment for baseline covariates in clinical trials. Committee for Medicinal Products for Human Use, European Medicines Agency (EMA).
- FDA (2021). Adjusting for covariates in randomized clinical trials for drugs and biological products. Draft Guidance for Industry. Center for Drug Evaluation and Research and Center for Biologics Evaluation and Research, Food and Drug Administration (FDA), U.S. Department of Health and Human Services. May 2021.
- ICH E9 (1998). Statistical principles for clinical trials E9. International Council for Harmonisation (ICH).
- Kalbfleisch, J. D., & Prentice, R. L. (2011). The statistical analysis of failure time data. Wiley.
- Kong, F. H., & Slud, E. (1997). Robust covariate-adjusted logrank tests. Biometrika, 84(4), 847–862. https://doi.org/10.1093/biomet/84.4.847
- Lin, D. Y., & Wei, L. J. (1989). The robust inference for the cox proportional hazards model. Journal of the American Statistical Association, 84(408), 1074–1078. https://doi.org/10.1080/01621459.1989.10478874
- Mantel, N. (1966). Evaluation of survival data and two new rank order statistics arising in its consideration. Cancer Chemotherapy Reports, 50(3), 163–170.
- Peto, R., Pike, M. C., Armitage, P., Breslow, N. E., Cox, D. R., Howard, S. V., Mantel, N., McPherson, K., Peto, J., & Smith, P. G. (1976). Design and analysis of randomized clinical trials requiring prolonged observation of each patient. i. introduction and design. British Journal of Cancer, 34(6), 585–612. https://doi.org/10.1038/bjc.1976.220
- Pocock, S. J., & Simon, R. (1975). Sequential treatment assignment with balancing for prognostic factors in the controlled clinical trial. Biometrics, 31(1), 103–115. https://doi.org/10.2307/2529712
- Schulz, K. F., & Grimes, D. A. (2002). Generation of allocation sequences in randomised trials: Chance, not choice. The Lancet, 359(9305), 515–519. https://doi.org/10.1016/S0140-6736(02)07683-3
- Shao, J. (2021). Inference for covariate-adaptive randomization: Aspects of methodology and theory (with discussions). Statistical Theory and Related Fields, 5(3), 172–186. https://doi.org/10.1080/24754269.2021.1871873
- Taves, D. R. (1974). Minimization: A new method of assigning patients to treatment and control groups. Clinical Pharmacology and Therapeutics, 15(5), 443–453. https://doi.org/10.1002/cpt.1974.15.issue-5
- Taves, D. R. (2010). The use of minimization in clinical trials. Contemporary Clinical Trials, 31(2), 180–184. https://doi.org/10.1016/j.cct.2009.12.005
- Ye, T., & Shao, J. (2020). Robust tests for treatment effect in survival analysis under covariate-adaptive randomization. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(5), 1301–1323. https://doi.org/10.1111/rssb.12392
- Ye, T., Shao, J., Yi, Y., & Zhao, Q. (2022). Toward better practice of covariate adjustment in analyzing randomized clinical trials. Journal of the American Statistical Association.
- Zelen, M. (1974). The randomization and stratification of patients to clinical trials. Journal of Chronic Diseases, 27(7-8), 365–375. https://doi.org/10.1016/0021-9681(74)90015-0
Appendix
A.1. Proof of Theorem 3.1
It is clear that in (Equation6
(6)
(6) ) implies
in (Equation3
(3)
(3) ). Thus, it suffices to show that, under (TR),
for all t implies
for all
. Define
and
. If
for all t, then
for all t. Condition (TR) implies that
Then
i.e.,
Since
or
depending on whether
or
,
This implies that
and, thus,
for all
, which together with
imply that
and hence
for all
.
A.2. Proof of Theorem 4.1
We prove (a) only, since the proof of (b) is similar. We first show that, under the null hypothesis or alternative hypothesis,
(A1)
(A1) where
the number of patients with treatment j in stratum z,
, j = 0, 1, and
Following the argument in the Appendix of Lin and Wei (Citation1989), we obtain that, under either the null or alternative hypothesis, the left hand side of (EquationA1
(A1)
(A1) ) is equal to
(A2)
(A2) where
denotes a quantity converging to 0 in probability as
. Define
and
. Similar to the proof of Theorem 2 in Ye et al. (Citation2022), the Lindeberg's Central Limit Theorem justifies that, conditioned on
and
, the random vector
converges in distribution to a 2-dimensional normal distribution with mean 0, conditional on
and
. Let M be the quantity in (EquationA2
(A2)
(A2) ) excluding
, which is the sum of two components of the previous random vector. Consequently,
Under (D1),
Then
unconditionally. Thus, by Slutsky's theorem, (EquationA1
(A1)
(A1) ) holds.
Next, under the local alternative specified in part (a), and
Hence, by (EquationA1
(A1)
(A1) ) and Slutsky's theorem,
It remains to show that
, under the specified local alternative. By Lemma 3 of Ye and Shao (Citation2020), within any stratum z,
. By the identity
from Kalbfleisch and Prentice (Citation2011) and the form of
, we obtain that, under the specified local alternative,
A.3. Proof of Corollary 4.1
A direct calculation shows that
where
and
are given in Theorem 4.1,
,
, and
denotes expectation under
.
Under the local alternative hypothesis with a fixed constant
, by Theorem 4.1,
, where
and
, where
Pitman's asymptotic relative efficiency of
with respect to
is
.
Applying Jensen's inequality with convex function
and
,
, we obtain that
. To reach the conclusion
, it remains to show that
.
The condition for all t implies that
and, hence,
Thus, it suffices to show
(A3)
(A3) Note that
where
is the expectation with respect to covariate
and is not depending on θ. Taking the derivative with respect to θ, we obtain that
Then,
which is the same as the left-hand side of (EquationA3
(A3)
(A3) ). As
is the probability of having an observed failure before time τ, it is a non-decreasing function of θ. This implies that (EquationA3
(A3)
(A3) ) holds.