
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Modern scientific research and applications very often encounter ‘fragmentary data’ which brings big challenges to imputation and prediction. By leveraging the structure of response patterns, we propose a unified and flexible framework based on Generative Adversarial Nets (GAN) to deal with fragmentary data imputation and label prediction at the same time. Unlike most of the other generative model based imputation methods that either have no theoretical guarantee or only consider Missing Completed At Random (MCAR), the proposed FragmGAN has theoretical guarantees for imputation with data Missing At Random (MAR) while no hint mechanism is needed. FragmGAN trains a predictor with the generator and discriminator simultaneously. This linkage mechanism shows significant advantages for predictive performances in extensive experiments.
1. Introduction
Modern scientific research and applications very often encounter data from multiple data sources, and for each data source, various variables can be collected for data analysis. Such increasing data sources bring big opportunities for predicting people's behaviours with huge potential social and commercial benefits. However, these different data sources usually can not be available for every sample, which leads to ‘fragmentary data’ and brings big challenges to data imputation and label prediction. To be more specific, we introduce two motivating examples that represent the most typically practical scenarios for fragmentary data.
Internet Loan: A leading company of wealth management is exploring its internet loan business and trying to predict the applicants' income for risk management purpose. There are five possibly available data sources (Table ). (i) Card: the credit card information; (ii) Shopping: the shopping history at internet; (iii) Mobile: the monthly bill of mobile phone; (iv) Bureau: the credit report from the Central Bank; (v) Fraud: the information from an anti-fraud platform. However, some applicants are not willing to provide their shopping or mobile information, not all the applicants have credit reports, and many of them are never included in the database of the anti-fraud platform. As a result, there are 10 ‘response patterns’ in the Internet Loan data as shown in Table , where ‘√’ means the data source is available for the applicants with the corresponding response pattern.
Table 1. The response patterns of the Internet Loan data.
ADNI: The Alzheimer's Disease Neuroimaging Initiative http://adni.loni.usc.edu is a widely used data by researchers for the Alzheimer's disease which has four data sources. (i) CSF: cerebrospinal fluid; (ii) PET: positron emission tomography; (iii) MRI: magnetic resonance imaging; (iv) Gene: the gene expression. As show in Table , it has 8 different response patterns corresponding to different data availability for each data source.
Table 2. The response patterns of the ADNI data.
Such kind of fragmentary data, also known as ‘block-wise missing data’ in the statistics literature, are very common in the area of risk management, marketing research, social sciences, medical studies and so on. Data imputation and label prediction are two main goals for the analysis of such data. But the extremely high missing rate and complicated missing patterns bring big challenges to the achievement of the goals.
Some work has been done to deal with fragmentary data in both areas of statistics and computer sciences in recent years. From the statistics perspective, methods based on model averaging (Fang et al., Citation2019), factor models (Zhang et al., Citation2020), generalized methods of moments (Xue & Qu, Citation2021), iterative least squares (Lin et al., Citation2021) and integrative factor regression (Li & Li, Citation2021) are proposed. These statistical methods provide useful theoretical properties but exhibit notable shortcomings. (i) They depend on certain statistical models, for example, linear regression models. (ii) They are not flexible in handling mixed data types that include continuous and categorical variables. (iii) Only a couple of methods consider imputation and prediction at the same time.
From the computer science perspective, GAIN (Yoon et al., Citation2018) first uses a Generative Adversarial Net (GAN) to impute data Missing Completed At Random (MCAR), which means the missingness occurs entirely at random without depending on any of the variables. MisGAN (Li et al., Citation2019) trains a mask generator along with the data generator for imputation. GAMIN (Yoon & Sull, Citation2020) proposes a generative adversarial multiple imputation network for highly missing data. HexaGAN (Hwang et al., Citation2019) deals with missing data imputation, conditional generation and semi-supervised learning together. GRAPE (You et al., Citation2020) proposes a graph-based framework for data imputation and label prediction. MIWAE (Mattei & Frellsen, Citation2019) and Not-MIWAE (Ipsen et al., Citation2021) propose imputation methods based on variational auto-encoding (VAE) framework instead of GAN. Ma and Chen (Citation2019) proposes a matrix completion algorithm when the data is missing not at random. However, these generative methods have various drawbacks. For instance, some of them (Ipsen et al., Citation2021; Mattei & Frellsen, Citation2019; Yoon & Sull, Citation2020; You et al., Citation2020) do not have the theoretical guarantee that the imputed data has the same distribution as the original data. Some of them (Hwang et al., Citation2019; Li et al., Citation2019; Yoon et al., Citation2018) only have theoretical results for data MCAR, which is highly unlikely in the practice. Most of them either consider data imputation and label prediction separately or only consider data imputation.
In this paper, by leveraging the structure of response patterns, we propose a ‘FragmGAN’ for fragmentary data imputation and prediction. The main contributions are as follows.
FragmGAN is a unified framework based on GAN to deal with fragmentary data imputation and label prediction at the same time. It's flexible in the sense that (i) it's applicable to both continuous and categorical data and label, and (ii) users can adjust the relative importance of the task of imputation to prediction by an ‘adjusting factor’.
FragmGAN has theoretical guarantees for imputation with data Missing At Random (MAR), which is much more general than MCAR and will be defined in Section 3.2. Also, the theoretical results do not need a hint mechanism that is required by GAIN.
Using similar technical skills, we extend the theoretical results of GAIN to MAR.
Other than the generator and discriminator, FragmGAN trains a predictor simultaneously. This linkage mechanism shows significant advantages for predictive performances in extensive experiments.
2. Related work
There are lots of discriminative and generative imputation methods that will be considered in our experiments, including Expectation Maximization (García-Laencina et al., Citation2010), matrix completion (Mazumder et al., Citation2010), MICE (van Buuren & Groothuis-Oudshoorn, Citation2011), MissForest (Stekhoven & Buhlmann, Citation2011) and Auto-Encoder (Gondara & Wang, Citation2017).
There are several other GAN based imputation methods. CollaGAN (Lee et al., Citation2019) proposes a collaborative GAN for missing data imputation but it focuses on image data. WGAIN (Friedjungová et al., Citation2020), CGAIN (Awan et al., Citation2021), PC-GAIN (Wang et al., Citation2021) and S-GAIN (Neves et al., Citation2021) extend GAIN in various ways. IFGAN (Qiu et al., Citation2020) conducts missing data imputation using a feature-specific GAN and MCFlow (Richardson et al., Citation2020) proposes a Monte Carlo flow method for data imputation but no theoretical result is provided. When all the variables are assumed to be categorical, theoretical results of GAN based methods are extended to an uncommon concept of Extended Always Missing At Random (Deng et al., Citation2020).
Although they are not our main interest, we also mention some other VAE based imputation methods including VAEAC (Ivanov et al., Citation2019), variational inference of deep subspaces (Dalca et al., Citation2019), iterative imputation using AE dynamics (Smieja et al., Citation2020), VAE using pattern-set mixtures (Ghalebikesabi et al., Citation2021) and VSAE (Gong et al., Citation2021). Some of them only focus on image data. A common disadvantage of VAE based methods is the lack of theoretical guarantee for imputation. Some results of empirical comparison of GAN and VAE based methods are presented in Camino et al. (Citation2019).
3. GAN-Based fragmentary data imputation
We first formulate the problem and discuss the method and theory of fragmentary data imputation in this section. The problem of label prediction will be addressed in Section 4.
Throughout the paper we usually use bold type letters to denote vectors and use the regular letters for scalars. The upper-case letters are used for random variables and the corresponding lower-case letters are their realizations. Abusing notation slightly, we use a generic notation or
to denote the distribution/probability or conditional distribution/probability for various continuous/categorical variables as long as there is no ambiguity.
3.1. Imputation method
Let be the d-dimensional data vector of interested variables that could take continuous or categorical values. Note that d is the number of variables but not the number of data sources since each data source may have multiple variables.
Define the mask vector such that
means
is observed and
means
is missing,
. So what we actually observe is
where ⊙ denotes element-wise multiplication.
Assume overall there are K (a fixed number) possible response patterns in the data and define as the pattern indicator, where
if the sample belongs to the kth response pattern and
otherwise,
. Note that
. In the fragmentary data setting,
can actually only take K (rather than
) different values and there is a one-to-one mapping between
and
. In the two motivating examples, K = 10 and 8 respectively.
Generator
Let be a d-dimensional noise vector that is independent of all other variables. It is typically taken as Gaussian white noise. We then feed
,
and
into the generator G and obtain
where G is a function from
to
, and
are the K possible values of
.
is the generated data vector but we are only interested in the missing variables. So the complete data vector after imputation is
Our target is to make sure the distribution of
is the same as the distribution of
, i.e.,
. The randomness of
makes our method a random imputation method rather than fixed imputation. Although we focus on single imputation in the paper, but by modelling the distribution of the data, we are able to make multiple imputation capture the uncertainty for the imputation value (Rubin, Citation2004; van Buuren & Groothuis-Oudshoorn, Citation2011).
Discriminator
The discriminator D tries to figure out which part of is from the generator. The vanilla GAIN (Yoon et al., Citation2018) aims to distinguish each component of
is real (observed) or fake (imputed). It's a hard task since d is usually a large number. Consequently, a hint mechanism, which reveals all but one of the components of
to D, is required for GAIN to solve the model identifiability problem and make sure the generated distribution is what we want.
In the fragmentary data setting, each sample should exactly belong to one of the K response patterns. By leveraging this informative structure, our discriminator D just needs to figure out which pattern belongs to. So D is a function from
to
(instead of
in GAIN) such that
is the predicted probability vector for
, where
is the predicted probability that
is from the kth response pattern and
. Note that the output layer of D has a softmax form.
We train the discriminator D to maximize the probability of correctly predicting . On the other hand, the generator G is trained to minimize the probability of D correctly predicting
. The objective function is defined to be the negative cross-entropy loss
(1)
(1) where
is just
. Note that the objective function depends on G through
. Then the minimax problem is given by
(2)
(2)
Remark 3.1
The key difference of our imputation method to GAIN is that we use a different objective function by taking the response patterns into consideration. This adjustment makes sure the model is identifiable even no hint mechanism is used as we show in the next subsection.
3.2. Theoretical results
Most previous theoretical results for GAN-based imputation methods including GAIN (Yoon et al., Citation2018), MisGAN (Li et al., Citation2019) and HexaGAN (Hwang et al., Citation2019) are established under the MCAR assumption, which means the missingness occurs entirely at random without depending on any of the variables. This is a very restrictive assumption and rarely satisfied in the real world. In contrast, our theoretical results will be established under the MAR assumption.
Assume can be decomposed into
, where
is an always observed subvector of
, and
could be missing. The missing mechanism is characterized (Little & Rubin, Citation2014) into three types.
Missing Completed At Random (MCAR):
is independent of
Missing At Random (MAR):
Missing Not At Random (MNAR):
Remark 3.2
For a random vector , it could be ambiguous for the definition of MAR. Another way to define MAR is
. However, since
appears in both sides of the condition, there is no way to generate a group of independently and identically distributed samples satisfying this equation, unless there exists an always observed subvector
such that
. This is the reason why we use the MAR definition as above.
The complete data vector can be decomposed into
correspondingly. Note that
. So
To verify that the solution to the minimax problem (Equation2
(2)
(2) ) satisfies
, we just need to show
. First we present a lemma.
Lemma 3.1
Let is a realization of
such that
. For a fixed generator G, the kth component of the optimal discriminator
to the minimax problem (Equation2
(2)
(2) ) is given by
for
, where
is a K-dimensional vector with only the kth element being 1, and
means that the sample belongs to the kth response pattern.
Proof.
All proofs are provided in A.1.
We now rewrite (Equation1(1)
(1) ) by substituting
to obtain the objective function for G to minimize
Theorem 3.2
A global minimum for is achieved if and only if
(3)
(3) for each
and
such that
and
.
It's worthy to mention that Lemma 3.1 and Theorem 3.2 do not depend on the MAR assumption and they are generally true even under MNAR.
Theorem 3.2 tells us that the optimal generator will generate data so that the conditional distributions of given
across different response patterns are the same. But it does not guarantee
yet.
To further explore, we assume the first response pattern is the case that all the variables are observed, i.e., for all
. Note the first response patterns in the two motivating examples are exactly the case. Then given
, there is no missing variable and we have
. So following (Equation3
(3)
(3) ), we have
(4)
(4)
Under the MAR assumption, is conditionally independent of
given
, and so is
since there is a one-to-one mapping between
and
. Therefore
(5)
(5) Combining (Equation4
(4)
(4) ) and (Equation5
(5)
(5) ) gives us the final theorem that provides theoretical guarantees for our proposed imputation method.
Theorem 3.3
Under the MAR assumption, the density solution to (Equation3(3)
(3) ) is unique and satisfies
So the distribution of
is the same as the distribution of
.
This theorem tells us that the optimal solution is uniquely identified and it is the one we need. Compared to GAIN (Yoon et al., Citation2018), our method does not need a hint mechanism for model identifiability. An intuitive explanation is that we just need to classify each sample into one of the K response patterns. It requires much fewer model parameters than GAIN, in which d binary classifiers need to be modelled if the hint mechanism is not applied. Note that we only require K to be a fixed number and it could be as large as . So theoretically FragmGAN can be applied to any kind of dataset with arbitrary missing patterns when the data vector is low-dimensional, for example, d = 4, and the associated computation is not too heavy. However, FragmGAN is not necessary better than GAIN in such cases. The most suitable scenario for FragmGAN is when K is relatively small compared to
.
Our theoretical results are established under MAR assumption while the vanilla GAIN (Yoon et al., Citation2018) assumes MCAR. However, we find that GAIN (with hint) also guarantees that under the MAR assumption, which is consistent to a recent theoretical result (Deng et al., Citation2020) considering a special case that all the variables are categorical. We provide a direct proof of this conclusion of GAIN in A.2.
4. A unified framework for imputation and prediction
Many previous methods including GAIN (Yoon et al., Citation2018) consider label prediction as a post-imputation problem, that is, they first impute the data and then develop a prediction model as if the data were fully observed. The disconnection between imputation and prediction mostly likely damages the accuracy of prediction. In this section we propose a unified framework that considers data imputation and label prediction together. The key idea is to train a predictor P with the generator and discriminator simultaneously.
Predictor
Let be the interested q-dimensional label that could be continuous or categorical. Unlike the semi-supervised learning, the label
is assumed to be available for all the training samples. A predictor P is a function from
to
such that
is a predicted value of
.
To evaluate the prediction performance of P, we define a loss function where L is from
to
. The explicit form of L depends on the data type of
and is very flexible. For example, if
is continuous, we may use
. If
is a binary scalar and the predicted value is the probability of being 1, then we may use
.
To train G, D and P together, define the linked objective function as
(6)
(6) where
is from (Equation1
(1)
(1) ) and
is an ‘adjusting factor’ that controls the relative importance of data imputation to label prediction.
The second part of (Equation6(6)
(6) ) does not involve D, so the target of D is still to maximize
. The first part of (Equation6
(6)
(6) ) does not involve P, so the target of P is to minimize the predictive loss
. Both parts of (Equation6
(6)
(6) ) involve G, but fortunately they both require G to minimize. So the minimax optimization problem is given by
(7)
(7)
The choice of γ is quite flexible. If the user is just interested in data imputation, he can take and
is reduced to
. If the user is mainly interested in label prediction, he may use a cross-validation procedure to choose an appropriate γ or simply take
which works quite well as shown in the experiments. Note that
is not a good choice since it will lead to overfitting. If the user cares about both imputation and prediction, he may decide γ by the relative importance of the two tasks in his mind.

The pseudo code to implement (Equation7(7)
(7) ) is given in Algorithm 1. Several issues are discussed as follows.
First, although the hint mechanism is not required for our theoretical results, it is still empirically helpful. So we also use the same hint mechanism as Yoon et al. (Citation2018) in implementation. The impact of including the hint mechanism or not will be checked in the experiments.
Second, the generator also generates data even for the observed variables, which can be used to check the generation performance. An extra loss function defined as
is added to
for training G, where
is a user-specified loss function depending on the variable type of
. The algorithm result is not sensitive to the choice of hyper-parameter α. Actually, as long as α is relatively large (
in the experiments), its main effect is to force
for the variable with
.
Third, when , Algorithm 1 actually implements (Equation2
(2)
(2) ) and the post-imputation prediction.
5. Experiments
In this section we check the imputation and prediction performance of FragmGAN in multiple datasets.
First we consider five UCI datasets (Lichman, Citation2013) used in GAIN (Yoon et al., Citation2018): Breast, Spam, Letter, Credit and News. Since the original datasets do not have any missing value, we randomly remove part of data by variable groups to make it fragmentary. Unless otherwise stated, the miss rate is 20%. By designing the removing strategy, we can make it MCAR or MAR. Specifically, we manually set several response patterns in advance. For MCAR, each sample is assigned to the patterns totally at random. For MAR, the probability of each sample being assigned to each pattern depends on the always observed covariate vector . For this group of datasets, we are able to check the performance of data imputation along with label prediction since the true data values are known.
Then we consider two datasets Internet Loan and ADNI for the motivating examples introduced in Section 1. The miss rates of them are 46.6% and 22.3%, respectively. More details of these two datasets are provided in A.3. Since the missing values are unknown, we can only check the label prediction performance for these two datasets.
For the purpose of comparison, we consider MICE, MissForest, matrix completion (Matrix), Auto-Encoder (AE), Expectation Maximization (EM) and MisGAN that have been mentioned in Section 1. For the prediction task for Internet Loan and ADNI, we also consider two statistical methods: Model Averaging (Fang et al., Citation2019) and FR-FI (Zhang et al., Citation2020).
The hyperparameters of FragmGAN and some implementation details are provided in A.3.
For each dataset, we randomly split it into a training set (80%) and a test set (20%) by response patterns. All the methods are fitted in the training set and then applied to the test set. The imputation and prediction performances are evaluated at the test set. We repeat this experiment 10 times and report the averages and standard deviations of the evaluation criteria (RMSE or AUC). In each table, the best result for each dataset is marked in bold type.
5.1. Results for the UCI datasets
Imputation Performance. Table reports the RMSEs of the imputation errors for the UCI datasets. We take for FragmGAN since imputation is the focus here. For both FragmGAN and GAIN, we consider two versions with or without the hint mechanism.
Table 3. Imputation performance for UCI datasets in terms of RMSE (Average Std) of imputation error.
As we can see from Table , FragmGAN outperforms all the other methods in most cases. For the two cases that FragmGAN is not the best (Breast and Letter with MAR, in which MissForest performs the best), it performs the second best. Both FragmGAN and GAIN perform better than their corresponding versions without hint, indicating that the hint mechanism really helps empirically. This is expected since the hint mechanism provides useful information to the discriminator. Note that the results here can not be directly compared to the results in the paper of GAIN (Yoon et al., Citation2018) since here we consider fragmentary data with certain response patterns while the missing data in GAIN is generated totally at random.
To check the imputation performance under different miss rates, we take the dataset Credit and generate missing data with miss rate from 10% to 80%. Figure presents the RMSEs of imputation errors under different miss rates. We can see that FragmGAN consistently performs the best. Again, both FragmGAN and GAIN perform better than their corresponding versions without hint. FragmGAN outperforms GAIN in both versions with or without hint.
Figure 1. RMSE of imputation error of the Credit data under different miss rates. Left: MCAR. Right: MAR.
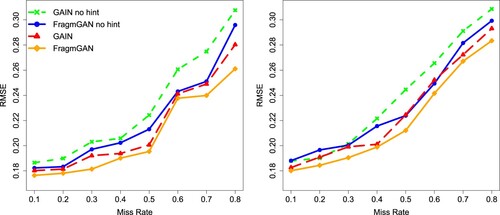
Overall speaking, FragmGAN performs quite well in data imputation in the sense that it has smaller RMSE of imputation error compared to the competitors. Specifically it is better than GAIN, indicating that considering the structure of response patterns in the algorithm is really useful.
Prediction Performance. Table reports the AUCs for the prediction performance in the datasets Breast, Spam, Credit and News. The dataset Letter is not considered here since it does not have a binary label. We include hint for both FragmGAN and GAIN. The adjusting factor γ is taken as 1 or 0.5 for FragmGAN. Note that when , FragmGAN first imputes data and then makes the prediction as if the data were fully observed. When
, the imputation and prediction are considered simultaneously.
Table 4. Prediction performance for UCI datasets in terms of AUC (Average ± Std).
As we can see, FragmGAN with outperforms the other methods in all the cases. This result shows that the linkage mechanism of training generator and predictor together can improve the prediction performance as we expected. Also note that although FragmGAN with
performs worse than FragmGAN with
, it still performs better than all the other methods.
5.2. Results for the motivating examples
For the dataset Internet Loan, the original label is the applicant's income, which is a continuous variable. In the analysis we use as the label Y. For the dataset ADNI, the original label Y is the score of Mini-Mental State Examination (MMSE) taking value from 0 to 30, in which higher score means better cognitive function. In the real analysis, we consider two labels. (i) The normalized MMSE which can be considered as a continuous variable. (ii) A binary label Y = 1 if MMSE≥28 and Y = 0 otherwise.
Prediction Performance. Table reports the RMSEs for the continuous label prediction and AUCs for the binary label prediction. The last two methods (Model Averaging and FR-FI) rely on linear regression models so they are not applicable to the binary label prediction. For the proposed FragmGAN, we take 1, 0.75, 0.5 and 0.25, indicating different relative importance of imputation to prediction. Also, we use a 5-fold cross-validation to select the best (for label prediction) γ. The CV criterion is defined as the averaged prediction performance in the leave-out samples.
Table 5. Prediction performance for the two motivation examples (Average ± Std).
Table shows that FragmGAN with the selected by cross-validation outperforms all the other methods in all the three cases, indicating that cross-validation is a good way to choose γ. FragmGAN with
always performs the second best. Note that γ controls the relative importance of data imputation to label prediction. As γ decreases from 1 to 0.25, the prediction performances first increase and then decrease. This result confirms two points that we have made: first, the linkage mechanism of training generator and predictor together can improve the prediction performance; second, a small γ close to 0 will lead to overfitting and damage the label prediction performance at the test data. Base on the results, we believe
is a reasonable choice if the users are not willing to apply cross validation to choose the best γ due to the computational burden.
6. Concluding remarks
Fragmentary data is becoming more and more popular in many areas and it is not easy to handle. By leveraging the structure in the response patterns, we propose a unified and flexible GAN based framework to deal with data imputation and label prediction simultaneously. An adjusting factor γ is used to adjust the relative importance of imputation to prediction. Theoretical guarantees for imputation are provided under the MAR assumption. Extensive experiments confirm the superiority of our proposed FragmGAN. It has wide application prospects especially in personal internet credit investigation, individual patient data (IPD) meta analysis in medical research and so on.
Based on the theoretical explorations and results of the experiments, we provide several practical suggestions for implementing FragmGAN in the practice.
Always use the hint mechanism although it is not required for the theoretical results.
Use
If you are interested in label prediction, use cross-validation to select the best γ or simply use
Possible future work includes the following. (i) We find that the best performances of data imputation (requires ) and label prediction (requires a γ between 0 and 1) are not achieved at the same time. This is an interesting phenomenon and further investigation may lead to some thought-provoking results. (ii) In this paper we assume that the label is always available in the training data. We may explore FragmGAN under a semi-supervised setting in which some labels are not available. A naive method is to consider the label as part of the data vector and apply GAIN or FragmGAN directly. But this method is trying to recover the distribution of
and the conditional distribution of
, which may not be desirable as we just mentioned in the first point. (iii) In this paper we assume that data are MAR. The extension of the results to the more general case of MNAR is a difficult but interesting task.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Awan, S. E., Bennamoun, M., Sohel, F., Sanfilippo, F., & Dwivedi, G. (2021). Imputation of missing data with class imbalance using conditional generative adversarial networks. Neurocomputing, 453(17), 164–171. https://doi.org/10.1016/j.neucom.2021.04.010
- Camino, R. D., Hammerschmidt, C. A., & State, R. (2019). Improving missing data imputation with deep generative models. arXiv:1902.10666v1.
- Dalca, A. V., Guttag, J., & Sabuncu, M. R. (2019). Unsupervised data imputation via variational inference of deep subspaces. arXiv:1903.03503v1.
- Deng, G., Han, C., & Matteson, D. S. (2020). Learning to rank with missing data via generative adversarial networks. arXiv:2011.02089v2.
- Fan, J., & Lv, J. (2008). Sure independence screening for ultrahigh dimensional feature space (with discussions). Journal of Royal Statistical Society Series B, 70(5), 849–911. https://doi.org/10.1111/j.1467-9868.2008.00674.x
- Fang, F., Lan, W., Tong, J., & Shao, J. (2019). Model averaging for prediction with fragmentary data. Journal of Business & Economic Statistics, 37(3), 517–527. https://doi.org/10.1080/07350015.2017.1383263
- Friedjungová, M., Vasata, D., Balatsko, M., & Jirina, M. (2020). Missing features reconstruction using a Wasserstein generative adversarial imputation network. In International Conference on Computational Science (ICCS 2020). pp. 225–239.
- García-Laencina, P. J., Sancho-Gómez, J. -L., & Figueiras-Vidal, A. R. (2010). Pattern classification with missing data: a review. Neural Computing and Applications, 19(2), 263–282. https://doi.org/10.1007/s00521-009-0295-6
- Ghalebikesabi, S., Cornish, R., Holmes, C., & Kelly, L. (2021). Deep generative missingness pattern-set mixture models. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics (AISTATS 2021). pp. 3727–3735.
- Gondara, L., & Wang, K. (2017). Multiple imputation using deep denoising autoencoders. arXiv:1705.02737.
- Gong, Y., Hajimirsadeghi, H., He, J., Durand, T., & Mori, G. (2021). Variational selective autoencoder: Learning from partially-observed heterogeneous data. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics (AISTATS 2021). pp. 2377–2385.
- Hwang, U., Jung, D., & Yoon, S. (2019). HexaGAN: Generative adversarial nets for real world classification. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019). pp. 2921–2930.
- Ipsen, N. B., Mattei, P. -A., & Frellsen, J. (2021). NOT-MIWAE: Deep generative modelling with missing not at random data. In International Conference on Learning Representations (ICLR 2021).
- Ivanov, O., Figurnov, M., & Vetrov, D. (2019). Variational autoencoder with arbitrary conditioning. In International Conference on Learning Representations (ICLR 2019).
- Lee, D., Kim, J., Moon, W.-J., & Ye, J. C. (2019). CollaGAN: Collaborative gan for missing image data imputation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019). pp. 2487–2496.
- Li, Q., & Li, L. (2021). Integrative factor regression and its inference for multimodal data analysis. Journal of the American Statistical Association, https://doi.org/10.1080/01621459.2021.1914635.
- Li, S. C. -X., Jiang, B., & Marlin, B. (2019). MisGAN: Learning from incomplete data with generative adversarial networks. In International Conference on Learning Representations (ICLR 2019).
- Lichman, M. (2013). UCI machine learning repository. http://archive.ics.uci.edu/ml.
- Lin, H., Liu, W., & Lan, W. (2021). Regression analysis with individual-specific patterns of missing covariates. Journal of Business & Economic Statistics, 39(1), 179–188. https://doi.org/10.1080/07350015.2019.1635486
- Little, R. J., & Rubin, D. B. (2014). Statistical analysis with missing data. (2nd ed.).John Wiley & Sons.
- Ma, W., & Chen, H. G. (2019). Missing not at random in matrix completion: The effectiveness of estimating missingness probabilities under a low nuclear norm assumption. In 33rd Conference on Neural Information Processing Systems (NeurIPS 2019).
- Mattei, P.-A., & Frellsen, J. (2019). MIWAE: Deep generative modelling and imputation of incomplete data sets. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019). pp. 4413–4423.
- Mazumder, R., Hastie, T., & Tibshirani, R. (2010). Spectral regularization algorithms for learning large incomplete matrices. Journal of Machine Learning Research, 11(Aug), 2287–2322.
- Neves, D. T., Naik, M. G., & Proenca, A. (2021). SGAIN, WSGAIN-CP and WSGAIN-GP: Novel GAN methods for missing data imputation. In International Conference on Computational Science (ICCS 2021). pp. 98–113.
- Qiu, W., Huang, Y., & Li, Q. (2020). IFGAN: Missing value imputation using feature-specific generative adversarial networks. In IEEE International Conference on Big Data (Big Data2020). pp. 4715–4723.
- Richardson, T. W., Wu, W., Lin, L., Xu, B., & Bernal, E. A. (2020). MCFlow: Monte carlo flow models for data imputation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020). pp. 14205–14214.
- Rubin, D. B. (2004). Multiple imputation for nonresponse in surveys. John Wiley & Sons.
- Smieja, M., Kolomycki, M., Struski, L., Juda, M., & Figueiredo, M. A. T. (2020). Iterative imputation of missing data using auto-encoder dynamics. In International Conference on Neural Information Processing (ICONIP 2020).
- Stekhoven, D. J., & Buhlmann, P. (2011). MissForest — non-parametric missing value imputation for mixed-type data. Bioinformatics, 28(1), 112–118. https://doi.org/10.1093/bioinformatics/btr597
- van Buuren, S., & Groothuis-Oudshoorn, K. (2011). MICE: multivariate imputation by chained equations in R. Journal of Statistical Software, 45(3), 1–67.
- Wang, Y., Li, D., Li, X., & Yang, M. (2021). PC-GAIN: pseudo-label conditional generative adversarial imputation networks for incomplete data. Neural Networks, 141(Sep), 395–403. https://doi.org/10.1016/j.neunet.2021.05.033
- Xue, F., & Qu, A. (2021). Integrating multi-source block-wise missing data in model selection. Journal of the American Statistical Association, 116(536), 1914–1927. https://doi.org/10.1080/01621459.2020.1751176
- Yoon, J., Jordon, J., & van der Schaar, M. (2018). GAIN: Missing data imputation using generative adversarial nets. In Proceedings of the 35th International Conference on Machine Learning (ICML 2018). pp. 5689–5698.
- Yoon, S., & Sull, S. (2020). GAMIN: Generative adversarial multiple imputation network for highly missing data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020). pp. 8456–8464.
- You, J., Ma, X., Ding, D., Kochenderfer, M., & Leskovec, J. (2020). Handling missing data with graph representation learning. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020).
- Zhang, Y., Tang, N., & Annie, Q. (2020). Imputed factor regression for high-dimensional blockwise missing data. Statistica Sinica, 30(2), 631–651.
Appendices
Appendix 1.
A.1. Proofs of the proposed FragmGAN
1.1. Proof of Lemma 3.1
Proof.
Let .
(A1)
(A1) Note that
. By the fact that
with
achieving its maximum when
, (EquationA1
(A1)
(A1) ) is maximized (for fixed G) when
for the
such that
.
1.2. Proof of Theorem 3.2
Proof.
(A2)
(A2)
(A3)
(A3) where ‘∝’ means equation holds by ignoring terms unrelated to G, and (EquationA2
(A2)
(A2) ) holds since
is a constant and
. Note that
is unrelated to
and
, so the second term of (EquationA3
(A3)
(A3) ) is unrelated to G. Following (EquationA3
(A3)
(A3) ), we have
where KL
denotes the KL divergence. Its minimum is achieved when
for each
and (almost) every
such that
and
.
1.3. Proof of Theorem 3.3
Proof.
Actually we have proved this theorem in the statements between Theorem 3.2 and Theorem 3.3 in Section 3.2.
A.2. Extend theoretical results of GAIN (Yoon et al., Citation2018) to missing at random
We first rewrite the formulation of GAIN under MAR with our notation (just a little bit different from the original GAIN paper).
The original data , dim
, dim
and
. Denote
as the response indicator for
. We assume
is missing at random, i.e.,
. Let
be a
-dimensional noise vector. Denote
and
is the complete data after imputation. Let
be the hint vector. The discriminator D is a function from
to
such that
is the predicted probability vector for
. The minimax problem is
(A4)
(A4) where log is element-wise logarithm and dependence on G is through
.
The proof of Lemma 1 in GAIN (Yoon et al., Citation2018) does not depend on the decomposition of . So the result still holds: the optimal D for given G is given by
for
.
Denote for
and
. Substituting
into
in (EquationA4
(A4)
(A4) ), we have the objective function for G (to minimize):
(A5)
(A5) Note that
and
are not related to
. So the second term of (EquationA5
(A5)
(A5) ) is not related to G and hence
which achieves its minimum when
(A6)
(A6) for
and
.
Let be a random vector taking value
with probability
, where
is a
-dimensional vector with only the ith element being 0,
. The hint vector
. Note that
means
for
and
implies nothing about
. With this
,
for
such that
and
.
For any and
, let
,
be any two vectors such that they are the same as
on the jth element for
, and the ith components of
and
are 0 and 1, respectively. So
if
and
if
. Define a realization of the hint vector
as
such that
if
and
if j = i. Since
, by (EquationA6
(A6)
(A6) ) we have
(A7)
(A7) Note
(A8)
(A8) where the first equation holds since
is equivalent to
, and the second equality holds due to the independence of
to the other variables. Combing (EquationA7
(A7)
(A7) ) and (EquationA8
(A8)
(A8) ), we have
.
Let and
be any vector in
. There exists a sequence of vectors
such that
and
only differ on one component and
and
. By the arguments above, we have
Note that
. And by the MAR assumption we have
. So
which implies
as we need.
A.3. Dataset details and hyper-parameters
The details of the five UCI datasets can be found in UCI machine learning repository (Lichman, Citation2013) and the paper of GAIN (Yoon et al., Citation2018).
For the datasets Internet Loan and ADNI, the number of variables at each data source and sample size of each response pattern are presented in below tables.
Table B1. The number of variables at each data source and sample size of each response pattern for the Internet Loan data.
Table B2. The number of variables at each data source and sample size of each response pattern for the ADNI data.
The original ADNI data is available at http://adni.loni.usc.edu. The number of variables from the last three sources in the original data is larger. We use feature screen methods (Fan & Lv, Citation2008) to screen out the 10 most important variables for each source for our experiment.
In all experiments, the depth of generator, discriminator and predictor in FragmGAN, GAIN and Auto-Encoder is set to be 3. The number of hidden nodes in each layer for generator and discriminator is , d and d, respectively. The number of hidden nodes in each layer for predictor is d, d/2 and 1, respectively. The activation function is ReLu except for the output layer that uses sigmoid. The training batch sizes
,
and
are all 64. The α in
is 10. For the cross-validation of FragmGAN, we search the value of γ on the grid of
.
We use PyTorch to implement FragmGAN, GAIN, Auto-Encoder and MisGAN. We use Python to implement
MICE (package ‘fancyimpute’, https://github.com/iskandr/fancyimpute),
MissForest (package ‘missingpy’, https://github.com/softmechanics/missingpy),
EM (package ‘impyute’, https://github.com/eltonlaw/impyute), and Matrix (https://www.cnblogs.com/wuliytTaotao/p/10814770.html).
We use R to implement Model Averaging and FR-FI.