
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In reliability theory, the reliability inference for s-out-of-k systems holds significant importance. In this paper, we explore the estimation of reliability for s-out-of-k systems based on partially constant stress accelerated life tests. Assume that the latent failure times of the components follow the Kumaraswamy distribution. Maximum likelihood estimates for the unknown parameters are established, and their uniqueness is demonstrated. In addition, confidence intervals for the unknown parameters are constructed using the covariance matrix. Confidence intervals for the reliability functions are determined by the Delta method, while Bootstrap intervals are provided for comparison purposes. Subsequently, Bayesian point and interval estimates based on MCMC techniques considering different loss functions are discussed. Lastly, we conduct an extensive simulation study and analyse one real data set, which reveals that the Bayesian approach yields the best results.
1. Introduction
As the product's reliability greatly influences its competitiveness, manufacturers are keen to ensure the reliability of their products and develop better production processes. However, in the face of modern products with extended lifespans and exceptional reliability, collecting product failure data under normal stress conditions is growing difficult and costly. To overcome the difficulty, accelerated life tests (ALT) have been proposed by scholars, i.e., life tests are performed under high stresses such as voltage, temperature, air pressure, and humidity to accelerate the failure. The failure data from the accelerated stages is then analysed using appropriate physical or statistical models to extrapolate life characteristics at normal stress levels. Recent literature includes (Asa et al., Citation2022; Hua & Gui, Citation2022; Samanta et al., Citation2019; Xu et al., Citation2015). However, the ALT cannot model data with unknown accelerating stresses and levels from Nelson (Citation2008). Partially accelerated life tests (PLAT) are employed in such situations and can be viewed as a reasonable alternative to estimate product reliability at normal stress. Unlike common ALT, some of the products under test in PALT will be tested under normal stress. Recent literature includes (Aljohani & Alfar, Citation2020; Ismail, Citation2014, Citation2016; C. Zhang et al., Citation2016).
As we all know, the exponential distribution and the Weibull distribution have been able to portray product lifetime characteristics satisfactorily, but they ignore the highly essential characteristic of lifetime, which is that lifetime is finite. Aban et al. (Citation2006) stated that the product's lifetime has to be inscribed as a distribution with a bounded model. Sufficiently large sample points that occur naturally in a lifetime test where the experimenter would have to drop or replace the data would undoubtedly result in wasted test costs. In this situation, Zhang and Xie (Citation2011) and Wang (Citation2017) pointed out that there are advantages to fitting the data by providing greater weights to the points through a bounded model. Furthermore, in terms of reliability estimation, Barlow and Proschan (Citation1975) and Genc (Citation2013) pointed out that models defined on unit intervals produce more credible results. Hence, this paper describes the product lifetime in terms of the Kumaraswamy distribution.
Kumaraswamy (Citation1980) developed the Kumaraswamy distribution, which is more suited for bounded data like atmospheric temperature, test fraction, daily rainfall, and daily stream flow, among other things. Let X be a random variable from the Kumaraswamy distribution, and then cumulative distribution function (CDF), probability density function (PDF) and hazard rate function (HRF) of X can be expressed as
and
respectively, where
are both shape parameters. In recent years, Gholizadeh et al. (Citation2011) obtained the maximum likelihood estimation and Bayesian estimation of the Kumaraswamy distribution. Kizilaslan and Nadar (Citation2016) estimated the parameters of the Kumaraswamy distribution and predicted the future values of the records using the maximum likelihood and Bayesian methods. Ghosh and Nadarajah (Citation2017) discussed Bayesian estimation of Kumaraswamy distributions based on three types of censored samples. Rastogi et al. (Citation2022) estimated the parameters of the Kumaraswamy distribution based on adaptive Type-II progressive censored in the constant stress PALT. The application of the Kumaraswamy distribution to the stress strength model can be found in Kohansal (Citation2019) and Wang et al. (Citation2020).
Previous studies in the ALT literature focussed on products with a single component. However, products generally contain numerous components to fulfil multiple functions and increase product reliability. Such products are referred to as a multicomponent system. The classical multicomponent system is the s-out-of-k:G system introduced by Bhattacharyya and Johnson (Citation1974). This system consists of k i.i.d. two-state (i.e., working or failed) components that function if and only if more than components are working, or the system fails if and only if the
th component fails. Assume that the component reliability function is
. Let X denote the number of surviving components in the system. Then, the probability that exactly s components in the system survive is
Then the s-out-of-k:G system reliability function is
Letting d = i−s, and expanding combinatorial numbers, then
We can find such examples in many real-life situations. For instance, a building structure consisting of four supporting pillars is a 3-out-of-4:G system if at least three pillars can support the weight. A V-8 engine operates properly when at least four of its eight cylinders are operating, so a V-8 engine can be considered a 4-out-of-8:G system. More examples can be found in Zuo (Citation2003). As a result, work on deriving multicomponent systems in ALT has become more exciting and vital. Recently, when the component lifetimes are Weibull distribution, Fan and Hsu (Citation2014) and Roy (Citation2018) considered the maximum likelihood estimation and optimal Bayesian plan for independent series systems based on constant stress ALT, respectively. Liu et al. (Citation2017) obtained nonparametric Bayesian reliability estimation for the masked data of parallel systems based on step stress ALT. Wang et al. (Citation2021) and Wang et al. (Citation2022) studied the reliability estimation for s-out-of-k:G systems when the component lifetime follows the Weibull distribution and the generalized inverted exponential distribution. In addition, some scholars have also made research on the multi-component system reliability from the perspective of stochastic order. Literature can be found in Guo et al. (Citation2020, Citation2022), Yan et al. (Citation2021, Citation2022), Yan and Niu (Citation2022), Zhang and Zhang (Citation2023) and Lu et al. (Citation2023) and references therein.
This paper aims to study the reliability inference of the s-out-of-k system based on constant stress PALT, and the Kumaraswamy distribution is adopted as the form of component lifetime distribution. The classical MLE method, Bayesian method, and Bootstrap method are used to construct the point and interval estimates of the relevant parameters. The results show that Bayesian estimation is the best estimation method to support the model. Our main contributions and innovations are as follows.
In response to the proposal of log-linearity by Wang et al. (Citation2021) and Wang et al. (Citation2022), which can only represent a limited number of stresses, we have developed an accelerated approach based on PALT for multicomponent systems with unlimited stresses. This approach can serve as an alternative method for reliability inference when log-linearity is restricted.
We develop a Bayesian reliability inference framework for s-out-of-k:G systems based on PALT and demonstrate the advantages of the Bayesian approach through numerical results.
We construct the reliability of the s-out-of-k:G system by taking the Kumaraswamy distribution as the underlying distribution with full consideration of the bounded nature of component lifetime.
2. Description and basic assumption of model
2.1. Model description
The total sample under constant stress PALT has K s-out-of-k:G systems, and suppose that systems are randomly assigned to normal stress level
, while the remaining
systems are set to accelerated stress level
. Stop the experiment when all the components fail.
Under this experimental procedure, the latent failure times of the system are given in Table .
Table 1. The latent failure times of the s-out-of-k:G system.
Denote the observed sample of the ordered failure time of the components for jth system under stress
. Clearly, given i and j, we have
.
2.2. Basic assumption
Under normal stress level
, the lifetime of the component follows the Kumaraswamy distribution, and then
Assume that the hazard rate function of the component under accelerated stress and normal stress follows the proportional hazard rate model, which can be shown as
Therefore, the reliability function of component lifetime can be calculated as
Then the CDF and PDF of the component lifetime can be given by
(3)
(3) and
(4)
(4) respectively.
Let us now focus on modelling the lifetime of s-out-of-k:G system. As discussed in the previous section, once the (k−s + 1)th component failure occurs, the system stops working. Therefore, the system reliability function of the corresponding s-out-of-k:G system with Kumaraswamy component lifetime under normal stress can be written as
(5)
(5)
3. Maximum likelihood estimation
The maximum likelihood estimation method is a frequently reliable and stable method for parameter estimation. It is pivotal in statistical inference. In this section, based on the previously developed model and the corresponding likelihood function, the maximum likelihood estimations (MLE) of all unknown parameters and reliability functions are derived.
Based on basic assumption and failure data , the likelihood function for model can be expressed as
(6)
(6) Substituting (Equation2
(2)
(2) ) and (Equation4
(4)
(4) ) into (Equation6
(6)
(6) ), the exact form of the likelihood function can be shown as
(7)
(7) and the associated log-likelihood function is
(8)
(8) For (Equation8
(8)
(8) ), we can give Theorems 3.1 and 3.2 to obtain the MLE for the relevant parameters.
Theorem 3.1
Suppose . For given α and λ, the MLE of β exists uniquely and can be expressed as
(9)
(9)
Proof.
See Appendix A.1.
Theorem 3.2
Suppose . For given λ, the MLE of α exists uniquely and can be expressed as
(10)
(10)
Proof.
See Appendix A.2.
Combining the above and (Equation8(8)
(8) ), the corresponding log-likelihood function including terms involving only λ is given by
(11)
(11) By taking the derivative of (Equation11
(11)
(11) ) regarding λ and setting it to zero, we have
(12)
(12) where
It is difficult to obtain the explicit MLE of λ from (Equation12
(12)
(12) ), but we can obtain an approximation solution by the fixed-point approach. The iterative scheme is
, where
is the dth iterate of λ. Stop iteration when
, where ε is estimation precision. Then, according to Theorems 3.1 and 3.2, we can obtain the MLE for α and β as follows:
Similarly, the MLE of
can be obtained from (Equation5
(5)
(5) ) by
4. Asymptotic confidence interval
4.1. Confidence intervals of parameters
In this subsection, we construct approximate confidence intervals (ACI) for unknown parameters α, λ, and β using the asymptotic normality of MLE. The variance-covariance matrix needs to be obtained to construct the ACI for parameters by calculating the Fisher information matrix. It is well known that obtaining an exact Fisher information matrix is difficult. We use the following observed Fisher information matrix instead,
(13)
(13) The detailed expressions of the second derivatives in (Equation13
(13)
(13) ) are given in Appendix 2.
Then, the asymptotic variance-covariance matrix of and
can be expressed as
Therefore, given the significance level
, the
asymptotic confidence interval for
and
can be expressed as
and
respectively, where
represents the upper
th quantile of
.
4.2. Confidence interval for reliability function
By the invariance property of the maximum likelihood estimation, we know that is MLE for
and asymptotically follows Normal distribution
. Now we calculate the variance of
using the Delta method established by Greene (Citation2000).
Denote the vector of partial derivatives of
with respect to the parameters α, λ and β, and then we have
According to the Delta method, the approximate asymptotic variance of
can be written as
where
is the transpose of P. Then the ACI of
can be obtained as
5. Bootstrap confidence interval
In general, the ACI does not necessarily perform well when the sample size is small. Thus, we use the percentile bootstrap confidence interval (PBCI) presented by Efron (Citation1982) to construct confidence intervals for the unknown parameters and the system reliability function. The detailed percentile bootstrap process is given as follows
| Step 1: | Collect the component failure data of the system and calculate the MLE of | ||||
| Step 2: | Generate the Bootstrap samples from distributions (Equation1 | ||||
| Step 3: | Obtain the MLE of Θ based on the Bootstrap sample, denoted as | ||||
| Step 4: | Repeat steps 2-3 B times, to obtain | ||||
| Step 5: | Arrange | ||||
| Step 6: | Given | ||||
6. Bayesian estimation
The Bayesian methods have been widely popular in statistical inference. Compared with the traditional MLE method, the Bayesian method's capability of integrating a prior information based on data makes it highly valuable in related fields. See (Cai et al., Citation2020; Dey et al., Citation2022; Xu & Tang, Citation2011).
This section explores the Bayesian estimation for unknown parameters and the system reliability function using two different loss functions. Assuming that all parameters are independent of each other, and the prior density functions for α, λ and β are given by
and
respectively, where
and
are hyper-parameters. Hence, the joint prior density function is
(14)
(14) Combining (Equation7
(7)
(7) ) and (Equation14
(14)
(14) ), the joint posterior density function for
and β can be written as
(15)
(15) The loss function is an essential element of the Bayesian framework. Here, we consider two distinct types of loss functions: the squared error loss (SEL) function, which is symmetric, and the LINEX loss (LL) function, which is asymmetric. Suppose U represents any function of parameters; and then the SEL function and LL function can be expressed as
and
respectively. Then the Bayesian estimations under SEL function and LL function can be expressed as
(16)
(16) and
(17)
(17) respectively.
It is challenging to calculate complex integrals from (Equation16(16)
(16) ) and (Equation17
(17)
(17) ) directly. We try to overcome this difficulty by two methods. The first one is numerical methods, such as the Lindley method and Tierney-Kadane method, but these methods do not construct interval estimates. The second one is the MCMC technique; compared to the first method, it is without the limitation of the inability to construct confidence intervals and is computationally inexpensive. As a result, we recommend employing the MCMC method to construct the Bayesian point and interval estimates.
Based on the joint posterior distribution (Equation15(15)
(15) ), the conditional posterior density functions of α, λ and β can be written as
(18)
(18)
(19)
(19) and
(20)
(20) respectively, where
Clearly, the conditional posterior density functions for parameters α and β are the Gamma
and truncated Gamma
, respectively. Hence, samples of α and β can be easily generated. Unfortunately, the conditional posterior distribution of λ cannot be considered some well-known distributions. Therefore, we employ the Metropolis-Hastings (M-H) algorithm within Gibbs sampling to generate the samples from the (Equation20
(20)
(20) ), (Equation18
(18)
(18) ), and (Equation19
(19)
(19) ) via the following process.
| Step 1: | Set the MLE of the parameters to the initial value of the iteration, denoted as | ||||
| Step 2: | In ith iteration, generate | ||||
| Step 3: | Generate | ||||
| Step 4: | Generate a random number ξ from | ||||
| Step 5: | Let
| ||||
| Step 6: | Compute the reliability function | ||||
| Step 7: | Repeat steps 2-6 N times. For the burn-in period, remove the initial M unstable points. Then, we can obtain N−M sets of random samples, which are | ||||
| Step 8: | To obtain the Bayesian credible intervals (BCI) for | ||||
7. Simulation study analysis
7.1. Monte Carlo simulation study
In this subsection, we evaluate the performance of the methods used in this manuscript for different combinations of sample sizes, depending on the following four criterion quantities to evaluate.
Mean square error (MSE) of parameter θ, calculated as
Average bias (AB) of parameter θ is defined by
Coverage probability (CP) of
Average length (AL) of
Table 2. MSE and AB (within bracket) for parameter α.
Table 3. MSE and AB (within bracket) for parameter λ.
Table 4. MSE and AB (within bracket) for parameter β.
Table 5. AL and CP (within bracket) for parameter α.
Table 6. AL and CP (within bracket) for parameter λ.
Table 7. AL and CP (within bracket) for parameter β.
Table 8. Estimation of .
From Tables , , and , one could conduct the following conclusions.
The MSEs and ABs of MLEs, BSELs, and BLLs decrease as the adequate sample size
Fixing sample size
For MLEs, BSELs, and BLLs for
Fix system structure
In general, the ALs values of BCIs are smaller than those of ACIs and PBCIs.
For parameters α, λ, and β and
7.2. Data analysis simulation
In this subsection, we choose the failure data set generated from s-out-of-k:G system with component lifetimes following Kumaraswamy distribution and accelerated under constant stress PALTs.
Consider that we have 10 5-out-of-6:G systems and allocate these samples equally to each stress level. Assume that the parameter vector is randomly chosen as , and
. The hyper-parameters are selected as
. Iterate the MCMC algorithm and the PBCI algorithm
times.
The generated random samples are shown in Table , and the point estimates and corresponding interval estimates are detailed in Table . From the numerical results in Table , the conclusions we drew in the previous subsection still hold.
Table 9. The generated data.
Table 10. Estimates of the parameters of the 5-out-of-6:G system under the generated data.
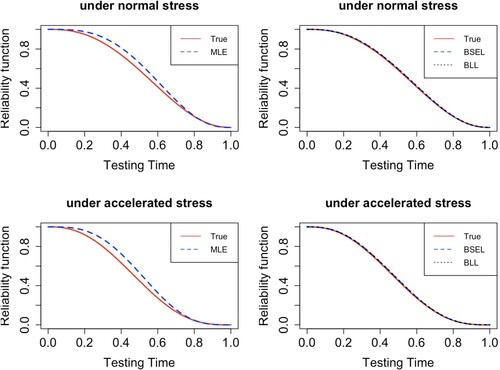
Figure gives the values of all iterations obtained by the MCMC method and depicts the convergence of the method, where the white dashed line indicates the true values of the parameters. The histogram of all iteration points of the MCMC method is given in Figure , where the red curve represents the kernel density estimation function of the posterior density. These two graphs show that the MCMC method works very well. Also shown in Figure are plots of the reliability functions obtained by different estimation methods under accelerated and normal stress.
8. A practical production example
This section uses the ALT real data set presented in Fu et al. (Citation2009) to illustrate the feasibility of the model and statistical inference approach proposed in this paper. The real data set has also been studied in Wang et al. (Citation2021) and Wang et al. (Citation2022). This data set shows the failure data in constant stress ALT performed with temperature and vibration frequency as accelerated stresses for a specific type cylinder of series product. It is mentioned in the Fu et al. (Citation2009) that the cylinder consists of a series of grease, piston rubber ring, and piston rod, and then the cylinder system is 1-out-of-3:G system. In addition, the cylinder system has an operating temperature stress of
.
Figure 1. Sampling trace plot of parameters by MCMC method.
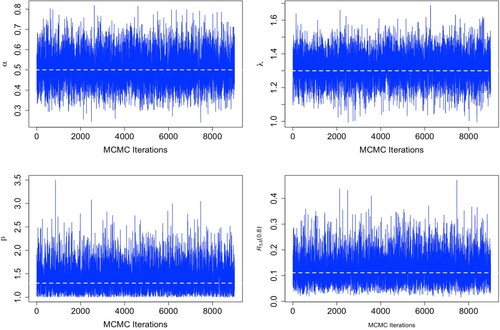
Figure 2. Histogram and kernel density estimates of parameters generated by the MCMC method.
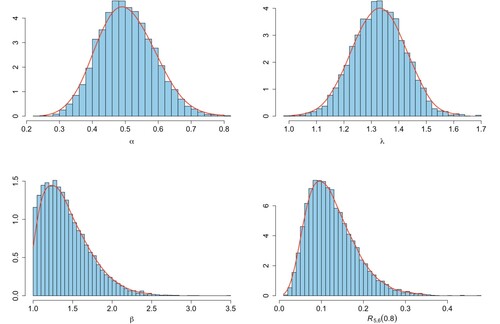
Figure 3. Comparison of the estimated reliability function with the true reliability function.
We analyse the constant stress PALT of the cylinder system and estimate the system reliability using temperature as the stress. Therefore, we fix the cylinder vibration frequency always at 50HZ, while we select the accelerated failure data at ,
and
and divide it into two groups, i.e., Group I (
and
) and Group II (
and
).
Considering the bounded property of the Kumaraswamy distribution, we divided all the data by . and the results are shown in the Table . We used the KS test to do a goodness-of-fit test on the distribution and the data. The values of the KS test statistic and the corresponding p-values are presented in Table , which shows that the Kumaraswamy distribution can be used as the underlying fitted distribution for the cylinder system reliability function.
Table 11. Failure times of the cylinder series system of product.
Table 12. The KS tests under the different groups.
The estimates of the correlation parameter for Kumaraswamy are presented in Tables and . Its Bayesian estimates are obtained under non-informative prior conditions, i.e., . Furthermore, we set
,
,
. Tables and show that the point estimates and interval estimates for α and λ are close. However, there is a minor discrepancy between the various estimates of the acceleration factor β.
In addition, although the non-informative prior leading to Bayesian estimation does not showing its full advantage, the numerical results show that the Bayesian method is still superior to the maximum likelihood estimation method in this example. The fitted CDFs and empirical distributions are compared in Figures and .
Figure 4. Comparisons of empirical CDFs and the fitted Kumaraswamy CDFs under data group I.
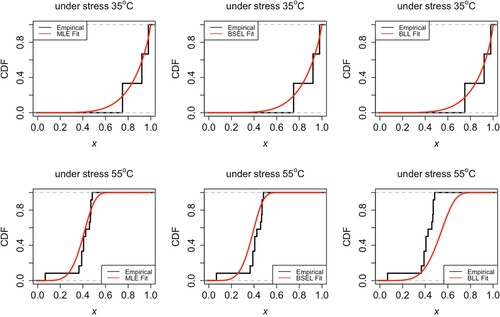
Figure 5. Comparisons of empirical CDFs and the fitted Kumaraswamy CDFs under data group II.
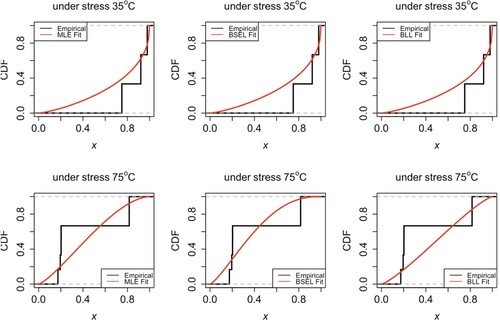
Table 13. Estimates for Kumaraswamy coefficient parameters under cylinder data group I.
Table 14. Estimates for Kumaraswamy coefficient parameters under cylinder data group II.
9. Concluding remarks
In this paper, we study parameter estimation and reliability inference for s-out-of-k: G systems with Kumaraswamy component lifetime distributions based on a constant stress PALT. We obtained different point and interval estimates by classical maximum likelihood estimation, Bayesian, and Bootstrap methods. Extensive Monte Carlo simulations compare the performance of these methods, and the results are satisfactory. The Bayesian estimation method generally performs better in the presence of additional prior information. Moreover, we study a real data set illustrating the methods used in this paper.
Based on this paper's research methodology and results, multicomponent systems' reliability estimation and properties can continue to be investigated under step stress and progressive stress ALT in future work. Meanwhile, studying optimal Bayesian design plans for systems with components following the Kumaraswamy lifetime distribution under the control of experimental costs is an interesting issue. In addition, current studies on ALT for multicomponent systems are based on the independent case between components, while the dependent case of the components is also a very interesting topic, e.g., (Guo et al., Citation2024; Zhang, Yan, Wang, et al., Citation2022; Zhang, Yan, Zhang, et al., Citation2022; Zhang & Zhang, Citation2022) used copula theory to deal with the dependency between components, and (J. Zhang et al., Citation2024; Zhang et al., Citation2023) modelled statistical dependence with the help of stochastic arrangement increasing. Therefore, we are eager to derive the ALT framework for multicomponent systems with dependent components in the future.
Acknowledgments
The authors are very grateful for the insightful and constructive comments and suggestions from the Editor-in-Chief, an Associate Editor, and two anonymous reviewers, which have greatly improved the presentation of this manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aban, I., Meerschaert, M., & Panorska, A. (2006). Parameter estimation for the truncated Pareto distribution. Journal of the American Statistical Association, 101(473), 270–277. https://doi.org/10.1198/016214505000000411
- Aljohani, H. M., & Alfar, N. M. (2020). Estimations with step-stress partially accelerated life tests for competing risks Burr XII lifetime model under type-II censored data. Alexandria Engineering Journal, 59(3), 1171–1180. https://doi.org/10.1016/j.aej.2020.01.022
- Asa, A., Mhe, A., Hma, B., & Ae, C. (2022). Estimations of accelerated Lomax lifetime distribution with a dependent competing risks model under type-I generalized hybrid censoring scheme. Alexandria Engineering Journal, 61(8), 6489–6499. https://doi.org/10.1016/j.aej.2021.12.006
- Barlow, R., & Proschan, F. (1975). Statistical theory of reliability and life testing: Probability models. Holt, Rinehart and Winston.
- Bhattacharyya, G. K., & Johnson, R. A. (1974). Estimation of reliability in multicomponent stress-strength model. Journal of the American Statistical Association, 69(348), 966–970. https://doi.org/10.1080/01621459.1974.10480238
- Cai, J., Shi, Y., & Liu, B. (2020). Bayesian analysis for dependent competing risks model with masked causes of failure in step-stress accelerated life test under progressive hybrid censoring. Communications in Statistics – Simulation and Computation, 49(9), 2302–2320. https://doi.org/10.1080/03610918.2018.1517212
- Dey, S., Wang, L., & Nassar, M. (2022). Inference on Nadarajah-Haghighi distribution with constant stress partially accelerated life tests under progressive type-II censoring. Journal of Applied Statistics, 49(11), 2891–2912. https://doi.org/10.1080/02664763.2021.1928014
- Efron, B. (1982). The Jackknife, the Bootstrap and other resampling plans. Society for industrial and applied mathematics.
- Fan, T. H., & Hsu, T. M. (2014). Constant stress accelerated life test on a multiple-component series system under Weibull lifetime distributions. Communications in Statistics-Theory and Methods, 43(11), 2370–2383. https://doi.org/10.1080/03610926.2013.809115
- Fu, Y., Han, G., Chen, J., & Ma, J. (2009). Research of accelerated life test of complex system based on pneumatic system (in Chinese version). Journal of Mechanical Strength, 31(4), 578–583.
- Genc, A. (2013). Estimation of P(X>Y) with Topp-Leone distribution. Journal of Statistical Computation and Simulation, 83(2), 326–339. https://doi.org/10.1080/00949655.2011.607821
- Gholizadeh, R. A., Shirazi, M. A., & Mosalmanza, S. (2011). Classical and Bayesian estimations on the Kumaraswamy distribution using grouped and un-grouped data under difference loss functions. Journal of Applied Sciences, 11(12), 2154–2162. https://doi.org/10.3923/jas.2011.2154.2162
- Ghosh, I., & Nadarajah, S. (2017). On the Bayesian inference of Kumaraswamy distributions based on censored samples. Communication in Statistics-Theory and Methods, 46(17), 8760–8777. https://doi.org/10.1080/03610926.2016.1193197
- Greene, W. H. (2000). Econometric analysis (4th ed.). Wiley.
- Guo, Z., Zhang, J., & Yan, R. (2020). The residual lifetime of surviving components of coherent system under periodical inspections. Mathematics, 8(12), 2227–7390. https://doi.org/10.3390/math8122181
- Guo, Z., Zhang, J., & Yan, R. (2022). On inactivity times of failed components of coherent system under double monitoring. Probability in the Engineering and Informational Sciences, 36(3), 923–940. https://doi.org/10.1017/S0269964821000152
- Guo, M., Zhang, J., Zhang, Y., & Zhao, P. (2024). Optimal redundancy allocations for series systems under hierarchical dependence structures. Quality and Reliability Engineering International, 40(4), 1540–1565. https://doi.org/10.1002/qre.3508
- Hua, R., & Gui, W. (2022). Inference for copula-based dependent competing risks model with step-stress accelerated life test under generalized progressive hybrid censoring. Computational Statistics, 37(5), 2399–2436. https://doi.org/10.1007/s00180-022-01203-w
- Ismail, A. A. (2014). Inference for a step-stress partially accelerated life test model with an adaptive type-II progressively hybrid censored data from Weibull distribution. Journal of Computational and Applied Mathematics, 260, 533–542. https://doi.org/10.1016/j.cam.2013.10.014
- Ismail, A. A. (2016). Statistical inference for a step-stress partially-accelerated life test model with an adaptive type-I progressively hybrid censored data from Weibull distribution. Statistical Papers, 57(2), 271–301. https://doi.org/10.1007/s00362-014-0639-x
- Kizilaslan, F., & Nadar, M. (2016). Estimation and prediction of the Kumaraswamy distribution based on record values and inter-record times. Journal of Statistical Computation & Simulation, 86(12), 2471–2493. https://doi.org/10.1080/00949655.2015.1119832
- Kohansal, A. (2019). On estimation of reliability in a multicomponent stress-strength model for a Kumaraswamy distribution based on progressively censored sample. Statistical Papers, 60(6), 2185–2224. https://doi.org/10.1007/s00362-017-0916-6
- Kumaraswamy, P. (1980). A generalized probability density function for double-bounded random processes. Journal of Hydrology, 46(1-2), 79–88. https://doi.org/10.1016/0022-1694(80)90036-0
- Liu, B., Shi, Y., Zhang, F., & Bai, X. (2017). Reliability nonparametric Bayesian estimation for the masked data of parallel systems in step-stress accelerated life tests. Journal of Computational & Applied Mathematics, 311, 375–386. https://doi.org/10.1016/j.cam.2016.07.029
- Lu, B., Zhang, J., & Yan, R. (2023). Optimal allocation of a coherent system with statistical dependent subsystems. Probability in the Engineering and Informational Sciences, 37(1), 29–48. https://doi.org/10.1017/S0269964821000437
- Nelson, W. (2008). Accelerated testing: Statistical models, test plans, and data analysis. Wiley.
- Rastogi, M. K., Saad, J., Farghal, A. A., & G. A. Elmougod (2022). Partially constant-stress accelerated life tests model for parameters estimation of Kumaraswamy distribution under adaptive type-II progressive censoring. Alexandria Engineering Journal, 61(7), 5133–5143. https://doi.org/10.1016/j.aej.2021.10.035
- Roy, S. (2018). Bayesian accelerated life test plans for series systems with Weibull component lifetimes. Applied Mathematical Modelling, 62, 383–403. https://doi.org/10.1016/j.apm.2018.06.007
- Samanta, D., Gupta, A., & Kundu, D. (2019). Analysis of Weibull step-stress model in presence of competing risk. IEEE Transactions on Reliability, 68(2), 420–438. https://doi.org/10.1109/TR.24
- Wang, L. (2017). Inference of constant-stress accelerated life test for a truncated distribution under progressive censoring. Applied Mathematical Modelling, 44, 743–757. https://doi.org/10.1016/j.apm.2017.02.011
- Wang, L., Dey, S., Tripathi, Y. M., & Wu, S. J. (2020). Reliability inference for a multicomponent stress-strength model based on Kumaraswamy distribution. Journal of Computational and Applied Mathematics, 376, Article 112823. https://doi.org/10.1016/j.cam.2020.112823
- Wang, L., Wu, S. J., Zhang, C., Dey, S., & Tripathi, Y. M. (2022). Analysis for constant-stress model on multicomponent system from generalized inverted exponential distribution with stress dependent parameters. Mathematics and Computers in Simulation, 193(C), 301–316. https://doi.org/10.1016/j.matcom.2021.10.017
- Wang, L., Zhang, C., Tripathi, Y. M., Dey, S., & Wu, S. (2021). Reliability analysis of Weibull multicomponent system with stress-dependent parameters from accelerated life data. Quality and Reliability Engineering International, 37(6), 2603–2621. https://doi.org/10.1002/qre.v37.6
- Xu, A., Fu, J., Tang, Y., & Guan, Q. (2015). Bayesian analysis of constant-stress accelerated life test for the Weibull distribution using noninformative priors. Applied Mathematical Modelling, 39(20), 6183–6195. https://doi.org/10.1016/j.apm.2015.01.066
- Xu, A., & Tang, Y. (2011). Objective Bayesian analysis of accelerated competing failure models under type-I censoring. Computational Statistics & Data Analysis, 55(10), 2830–2839. https://doi.org/10.1016/j.csda.2011.04.009
- Yan, R., & Niu, J. (2022). Stochastic comparisons of second-order statistics from dependent and heterogenous modified proportional hazard rate observations. Statistics, 57(2), 328–353. https://doi.org/10.1080/02331888.2023.2177999
- Yan, R., Wang, J., & Lu, B. (2021). Orderings of component level versus system level at active redundancies for coherent systems with dependent components. Probability in the Engineering and Informational Sciences, 36(4), 1275–1297. https://doi.org/10.1017/S0269964821000401
- Yan, R., Zhang, J., & Wang, J. (2022). Optimal allocation of relevations in coherent systems. Journal of Applied Probability, 58(4), 293–298.
- Zhang, J., Guo, Z., Niu, J., & Yan, R. (2024). Increasing convex order of capital allocation with dependent assets under threshold model. Statistical Theory and Related Fields, 1–12. https://doi.org/10.1080/24754269.2023.2301630
- Zhang, C., Shi, Y., & Wu, M. (2016). Statistical inference for competing risks model in step-stress partially accelerated life tests with progressively type-I hybrid censored Weibull life data. Journal of Computational & Applied Mathematics, 297, 65–74. https://doi.org/10.1016/j.cam.2015.11.002
- Zhang, T., & Xie, M. (2011). On the upper truncated Weibull distribution and its reliability implications. Reliability Engineering & System Safety, 96(1), 194–200. https://doi.org/10.1016/j.ress.2010.09.004
- Zhang, J., Yan, R., & Wang, J. (2022). Reliability optimization of parallel-series and series-parallel systems with statistically dependent components. Applied Mathematical Modelling, 102, 618–639. https://doi.org/10.1016/j.apm.2021.10.003
- Zhang, J., Yan, R., & Zhang, Y. (2022). Reliability analysis of fail-safe systems with heterogeneous and dependent components subject to random shocks. Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk and Reliability, 237(6), 1073–1087.
- Zhang, J., Yan, R., & Zhang, Y. (2023). Stochastic comparisons of largest claim amount from heterogeneous and dependent insurance portfolios. Journal of Computational and Applied Mathematics, 431, Article 115265. https://doi.org/10.1016/j.cam.2023.115265
- Zhang, J., & Zhang, Y. (2022). A copula-based approach on optimal allocation of hot standbys in series systems. Naval Research Logistics (NRL), 69(6), 902–913. https://doi.org/10.1002/nav.v69.6
- Zhang, J., & Zhang, Y. (2023). Stochastic comparisons of relevation allocation policies in coherent systems. Test, 32(3), 865–907. https://doi.org/10.1007/s11749-023-00855-0
- Zuo, M. J. (2003). Optimal reliability modeling, principles and applications. Wiley.
Appendices
Appendix 1. Proof of Theorem
A.1. Proof of Theorem 3.1
By taking the derivative of Equation (Equation8(8)
(8) ) to β and setting it to zero, then (Equation9
(9)
(9) ) can be obtained simply. Then, we will demonstrate that the log-likelihood function (Equation8
(8)
(8) ) will reach its maximal value at
.
Let , using
, and then we can obtain
Hence, the log-likelihood function (Equation8
(8)
(8) ) can be written as
From (Equation9
(9)
(9) ), we get
inserted into the above inequality. Then we have
The equation holds when
, so the proof is complete.
A.2. Proof of Theorem 3.2
Replace β in (Equation8(8)
(8) ) with (Equation9
(9)
(9) ) and re-express it as
By taking the first-order partial derivative of
to α and letting it be
, we can obtain
For
, because
, use
to easily get
These two limits implied that
exists.
And then consider
which suggests that the (Equation8
(8)
(8) ) given λ is concave. Therefore, combining the above two results, it is proved that equation
has a unique maximal value at
given λ.