
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this study, we explore the problem of hypothesis testing for white noise in high-dimensional settings, where the dimension of the random vector may exceed the sample sizes. We introduce a test procedure based on spatial-sign for high-dimensional white noise testing. This new spatial-sign-based test statistic is designed to emulate the test statistic proposed by Paindaveine and Verdebout [(2016). On high-dimensional sign tests. Bernoulli, 22(3), 1745–1769.], but under a more generalized scatter matrix assumption. We establish the asymptotic null distribution and provide the asymptotic relative efficiency of our test in comparison with the test proposed by Feng et al. [(2022). Testing for high-dimensional white noise. arXiv:2211.02964.] under certain specific alternative hypotheses. Simulation studies further validate the efficiency and robustness of our test, particularly for heavy-tailed distributions.
1. Introduction
In this paper, we consider testing for white noise or serial correlation, which is a fundamental problem in statistical inference. For univariate time series, the famous Box-Pierce portmanteau test and its variations are very popular due to their convenience in practical application (Li, Citation2003; Lütkepohl, Citation2005). Many efforts have been devoted to extending those methods for testing multivariate time series, such as Hosking (Citation1980) and Li and McLeod (Citation1981). Recently, high-dimensional time series data frequently appear in many applications, including finance and econometrics, biological and environmental research, etc., where the dimensions of the time series is comparable or even larger than the observed length of the time series. In this case, the above traditional white noise tests can not directly apply for high-dimensional data.
Recently, there are two types of omnibus tests proposed to deal with high-dimensional white noise test. One is the max-type test. Chang et al. (Citation2017) proposed a test statistic using the maximum absolute autocorrelation and cross-correlations of the component series. Tsay (Citation2020) proposed a rank-based max-type test using the Spearman rank correlation. Chen et al. (Citation2022) extended Tsay (Citation2020)'s work to other types rank-based correlations, such as Kendall's tau correlation and Hoeffding's D statistic, etc. As known to all, the max-type tests perform well for the sparse alternatives where only a few auto-correlations are nonzero and large, but perform less powerful for the dense alternatives where there are many small nonzero auto-correlations. So researchers proposed sum-type tests for the high-dimensional white noise test. Li et al. (Citation2019) proposed a test statistic by using the sum of the squared singular values of several lagged sample autocovariance matrices. Feng et al. (Citation2022) proposed a new sum-type test statistic by excluding some terms from the test statistic proposed by Li et al. (Citation2019) and showed that it has better size performance. However, the above two sum-type tests are both based on the independent component model, which only allows the underlying distribution of the time series to be light tailed. Unfortunately, the assumption of light-tailed distribution may be no appropriate for many applications, such as stock security returns. Thus, we need to construct a robust high-dimensional white noise test procedure for the heavy tailed distributions.
The classic spatial-sign-based procedures are very robust and efficient in traditional multivariate analysis. See Oja (Citation2010) for an overview. Recently, many literatures show that the spatial-sign-based procedures also perform very well in high-dimensional settings. Wang et al. (Citation2015), Feng and Sun (Citation2016) and Feng et al. (Citation2021) proposed some spatial-sign-based test procedures for the high-dimensional one sample locationproblem. Feng et al. (Citation2016) and Huang et al. (Citation2023) considered high-dimensional two sample location problem. Zou et al. (Citation2014) and Feng and Liu (Citation2017) also extended the spatial-sign-based method to the high-dimensional sphericity test. Some spatial-sign-based test procedures for high-dimensional alpha test in factor pricing model were proposed by Liu et al. (Citation2023), Zhao et al. (Citation2022) and Zhao (Citation2023). In an important work, Paindaveine and Verdebout (Citation2016) proposed a spatial-sign-based test for i id.ness against serial dependence. However, they assume that the random vectors have independent spherical directions, which is too limited in applications. In practice, there is always some correlations between the random vectors. So we propose a new spatial-sign-based test procedure for the high-dimensional white noise test in this article. Under the elliptical symmetric distribution assumption, we establish the asymptotical normality of the proposed test statistic under the null hypothesis and a special alternative hypothesis. We also show that the asymptotical relative efficiency of our method with respect to the test proposed by Feng et al. (Citation2022) is equivalent to the corresponding asymptotical relative efficiency of spatial-sign-based method with respect to the least-square based procedures in high-dimensional settings (Feng & Sun, Citation2016; Liu et al., Citation2023; Wang et al., Citation2015; Zhao, Citation2023). Simulation studies also demonstrate the superiority of our method for heavy-tailed distributions.
This paper is organized as follows. In Section 2, we introduce our proposed spatial-sign-based test procedure for high-dimensional white noise test and establish the theoretical results. Simulation studies are showed in Section 3. An application involving real data are presented in Section 4. The conclusion and additional discussion are provided in Section 5. All technical details are collected in Section 6.
2. Test procedure
Let be a p-dimensional weakly stationary time series with a mean of zero. We consider the following testing problem:
(1)
(1) where the dimension of time series p is comparable to or even greater than the sample size n. In this context, we define a time series
as white noise if the elements
are all independent and identically distributed. This definition differs from those provided in Shekhar et al. (Citation2003) and Cai and Kwan (Citation2022). Under the null hypothesis,
. So, Li et al. (Citation2019) proposed the following test statistic:
They established the asymptotical normality of
by random matrix theory. Feng et al. (Citation2022) removed the diagonal elements
from the summation and proposed the following test statistic:
They also established the asymptotical normality of
by the martingale central limit theorem. Both the above two tests need the assumption of an independent component model, that is,
and
is a sequence of independent random vectors of dimensions p with independent components. However, a common drawback of the independent component model is their inability to handle many well-known heavy-tailed distributions, such as the multivariate student t and the mixture of multivariate normal distributions. Thus, we need to propose a robust and efficient test procedure for heavy-tailed distributions.
Under the assumption that have independent spherical directions, Paindaveine and Verdebout (Citation2016) proposed a standardization test statistic
(2)
(2) where
and
. They showed that
as
under the null hypothesis. However, the assumption of independent spherical directions always does not hold in practice. In addition, they did not give the power function of
under the alternative hypothesis. So we need to establish the theoretical results of the spatial-sign-based test statistic under more general scatter matrix assumption.
We consider the following test statistic:
(3)
(3) which is mimic to the test statistic (Equation2
(2)
(2) ). Next, we will show that the asymptotic variance of
under the null hypothesis is
and
, which is equal to
if
have independent spherical directions.
We need the following conditions.
| (C1) | (Error Distribution) The error vectors | ||||
| (C2) | (Covariance Matrix) | ||||
Under the Condition (C1), can be decomposed as
where
is a random vector uniformly distributed on the unit sphere in
and
is a nonnegative random variable independent of
. The covariance matrix can be written as
. Condition (C2) is the same as the Conditions (C1) and (C2) in Wang et al. (Citation2015). If the eigenvalues of
are all bounded, Condition (C2) will hold.
Theorem 2.1
Under Conditions (C1)-(C2), we have where
.
Then, we estimate as follows:
By Proposition 1 of Zhao (Citation2023), we have
under the null hypothesis as
. So by Theorem 2.1, we reject the null hypothesis if
where
and
is the upper α quantile of standard normal distribution.
Next, we consider the power function of our test procedure. Specially, we consider the following alternative hypothesis:
(4)
(4) where
is a random vector uniformly distributed on the unit sphere in
and
is a nonnegative random variable independent of
. Let
,
and
. We also assume the following condition for
and
.
| (C3) | The eigenvalues of | ||||
Theorem 2.2
Under in (Equation4
(4)
(4) ) with Condition (C3) holding, if
, we have, for H = 1,
where
and
.
Note that under Condition (C3), we have under the null hypothesis. So, by Theorem 2.2, the power function of
is
In addition, according to Theorem 5 in Feng et al. (Citation2022), the power function of the sum-type test proposed by Feng et al. (Citation2022) is
under Condition (C3). Thus, the asymptotic relative efficiency of our SS test with respect to FLM test is
by Cauchy inequality. Next, we consider three special distributions for
.
. So,
3. Simulations
We compare our method with the max-type test proposed by Chang et al. (Citation2017) (abbreviated as MAX), the sum-type test (abbreviated as FLM) and the Fisher's combined probability test (abbreviated as FC) proposed by Feng et al. (Citation2022). First, we consider the null hypothesis. To verify the robustness of the proposed testing method, we consider the following three scenarios for :
Multivariate normal distribution.
Multivariate t-distribution.
Multivariate mixture normal distribution.
Thereinto, ,
,
,
with
. Table reports the empirical sizes of SS, MAX, FLM, FC tests with n = 100, 200 and p = 40, 80, 100. From Table , we observe that both FLM and SS tests can control the empirical sizes in most cases. However, the empirical sizes of MAX test are a little conservative under the multivariate normal distribution, while a litter larger than the nominal level under the multivariate t-distribution. And the empirical sizes of FC tests also have the same performance as MAX test.
Table 1. Size performance of different tests.
Next, we compare the empirical power performance of the above four tests. We consider three models for :
VAR(1) model:
VMA(1) model:
VARMA(1) model:
Here, ‘VAR(1)’, ‘VMA(1)’ and ‘VARMA(1)’ are the abbreviations of 1-order vector autoregressive process, vector moving average process and vector autoregressive moving average process, respectively. Here, are generated from Scenarios (I)–(III) with
. Let
. We consider the alternative hypothesis with
for
and
otherwise. Here, m controls the signal strength and sparsity of
. We consider two cases for m : (1) dense case:
and
for
; (2) sparse case:
and
for
. Table reports the empirical power of the above four tests with n = 200, p = 80. Under the multivariate normal distribution, the performance of SS test is similar to FLM test, which is consistent to the theoretical result. Under the dense case, the powers of sum-type tests–SS and FLM are more powerful than MAX and FC tests. However, MAX and FC tests outperform SS and FLM tests under the sparse case. For the heavy-tailed distributions, our SS test has better performance than FLM test, which shows the advantage of the spatial-sign-based method. In addition, we found that the powers of the SS and FLM tests with H = 1 are larger than those tests with H = 2, 3. It is not strange because we consider the alternative hypothesis with 1-order. How to choose the best H for the general case deserves some further studies.
Table 2. Power performance of different tests with n = 200, p = 80.
4. Application
In this section, we are interested in testing whether the error series under Sharpe-Lintner Capital Asset Pricing Model (CAPM) (Lintner, Citation1975; Sharpe, Citation1964) is white noise, i.e.
(5)
(5) where
and p is the number of securities. The CAPM model is one of the most popular factor pricing models in finance, which has the explicit form
for
and
, where
is the return of the ith security at time t,
is the risk free rate at time t,
is the excess return of the ith security at time t and
is the market return at time t. We gathered return data for the securities listed in the S&P 500 index. Initially, we compiled the monthly returns of all the securities in the S&P 500 index from January 2005 to November 2018. As the composition of the index changes over time, we focused on p = 374 securities that remained in the S&P 500 index throughout the entire period. This resulted in a total of T = 165 consecutive observations. The time series data for the safe rate of return and the market factors were sourced from Ken French's data library web page. We selected the one-month US treasury bill rate as the risk-free rate (
). The value-weighted return on all NYSE, AMEX, and NASDAQ stocks from CRSP served as a proxy for the market return (
).
Specifically, we let
where
and
are the ordinary least-squares (OLS) estimators of
and
, respectively. To demonstrate the usefulness of the proposed test, we treat
as the observation of
, instead of considering the testing problem within the CAPM model. First, we applied SS, FLM, MAX and CC tests for the total samples. All the tests reject the null hypothesis at significant level 0.05. We apply the Box-Pierce test, a conventional autocorrelation test, to the residuals of each security under the CAPM model with the total sample sizes. The histogram of p-values from the Box-Pierce test for the U.S. datasets is shown in Figure . We also observe some autocorrelations for some securities. So for the following application, we employ the sliding window method. With a predetermined length n, we carry out each of the necessary tests on the data gathered from the period spanning τ to
for every τ in the range of
. Here,
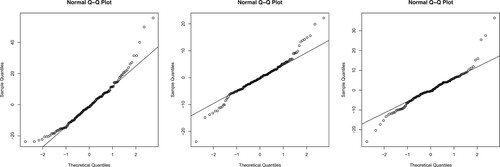
represents the sliding window of length n. Figure displays the p-values for each test with a length of n = 36 (equivalent to three years). Our findings indicate that the MAX test is unable to reject the null hypothesis when the sample size is not sufficiently large. In most instances, the p-values of our proposed SS test are lower than those of the FLM test. Furthermore, we documented the frequency of null hypothesis rejection for the FLM and SS tests in these T−n test results, corresponding to the T−n sliding windows, which resulted in rates of 0.74 and 0.84, respectively. This indicates that our proposed SS test outperforms the other three tests in this application, primarily due to the heavy-tailed nature of the residuals. Figure provides some Q-Q plots of these residuals.
Figure 1. Histogram of p-values of the Box-Pierce of residuals of CAPM model for U.S.'s datasets.
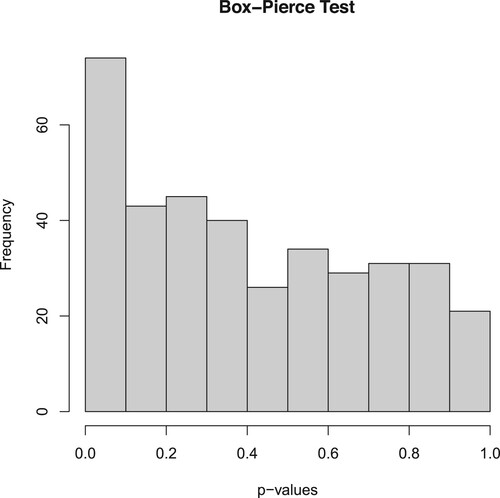
Figure 2. p-values of white noise tests for the U.S.'s datasets with CAPM model.
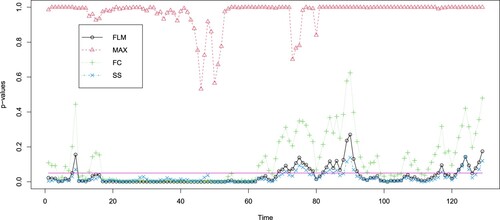
Figure 3. Q–Q plots of the residuals of three securities with CAPM model.
5. Conclusion
In this study, we develop a new test procedure for high-dimensional white noise testing based on spatial-sign. Unlike the method proposed by Feng et al. (Citation2022), which constructs their test statistic using sample auto-covariance, our test statistic is constructed using auto-spatial-sign-covariance.We provide theoretical results for our proposed methods under the assumption of an elliptical distribution. Furthermore, we establish the asymptotic relative efficiency of our test in comparison to the sum-type test proposed by Feng et al. (Citation2022). Our simulation studies and application to real data demonstrate the superiority of our method over the sum-type test proposed by Feng et al. (Citation2022), particularly for heavy-tailed distributions.
As revealed in our simulation studies, our proposed test does not perform well against sparse alternatives. However, the max-type test proposed by Feng et al. (Citation2022) can not control the empirical sizes under heavy tailed distributions. This makes it intriguing to develop a max-type test procedure based on spatial-sign for high-dimensional white noise testing. Moreover, Feng et al. (Citation2022) demonstrated the asymptotic independence between their sum-type test statistic and the max-type test statistic. It would be interesting to investigate if the spatial-sign-based max-type test statistic also exhibits asymptotic independence with our proposed spatial-sign based sum-type test statistic. If this is the case, then we could construct a new combined test procedure based on this finding.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Cai, J., & Kwan, M. P. (2022). Detecting spatial flow outliers in the presence of spatial autocorrelation. Computers, Environment and Urban Systems, 96, 101833. https://doi.org/10.1016/j.compenvurbsys.2022.101833
- Chang, J., Yao, Q., & Zhou, W. (2017). Testing for high-dimensional white noise using maximum cross-correlations. Biometrika, 104(1), 111–127. https://doi.org/10.1093/biomet/asw066
- Chen, D., Song, F., & Feng, L. (2022). Rank based tests for high dimensional white noise. arXiv:2204.08402.
- Feng, L., & Liu, B. (2017). High-dimensional rank tests for sphericity. Journal of Multivariate Analysis, 155, 217–233. https://doi.org/10.1016/j.jmva.2017.01.003
- Feng, L., Liu, B., & Ma, Y. (2021). An inverse norm sign test of location parameter for high-dimensional data. Journal of Business & Economic Statistics, 39(3), 807–815. https://doi.org/10.1080/07350015.2020.1736084
- Feng, L., Liu, B., & Ma, Y. (2022). Testing for high-dimensional white noise. arXiv:2211.02964.
- Feng, L., & Sun, F. (2016). Spatial-sign based high-dimensional location test. Electronic Journal of Statistics, 10(2), 2420–2434. https://doi.org/10.1214/16-EJS1176
- Feng, L., Zou, C., & Wang, Z. (2016). Multivariate-sign-based high-dimensional tests for the two-sample location problem. Journal of the American Statistical Association, 111(514), 721–735. https://doi.org/10.1080/01621459.2015.1035380
- Hall, P., & Heyde, C. C. (1980). Martingale limit theory and its application. Academic Press.
- Hosking, J. R. (1980). The multivariate portmanteau statistic. Journal of the American Statistical Association, 75(371), 602–608. https://doi.org/10.1080/01621459.1980.10477520
- Huang, X., Liu, B., Zhou, Q., & Feng, L. (2023). A high-dimensional inverse norm sign test for two-sample location problems. Canadian Journal of Statistics, 51(4), 1004–1033. https://doi.org/10.1002/cjs.v51.4
- Li, W. K. (2003). Diagnostic checks in time series. Chapman and Hall/CRC.
- Li, Z., Lam, C., Yao, J., & Yao, Q. (2019). On testing for high-dimensional white noise. The Annals of Statistics, 47(6), 3382–3412. https://doi.org/10.1214/18-AOS1782
- Li, W. K., & McLeod, A. I. (1981). Distribution of the residual autocorrelations in multivariate ARMA time series models. Journal of the Royal Statistical Society Series B: Statistical Methodology, 43(2), 231–239. https://doi.org/10.1111/j.2517-6161.1981.tb01175.x
- Lintner, J. (1975). The valuation of risk assets and the selection of risky investments in stock portfolios and capital budgets. In Stochastic optimization models in finance (pp. 131–155). Elsevier.
- Liu, B., Feng, L., & Ma, Y. (2023). High-dimensional alpha test of linear factor pricing models with heavy-tailed distributions. Statistica Sinica, 33, 1389–1410.
- Lütkepohl, H. (2005). New introduction to multiple time series analysis. Springer.
- Oja, H. (2010). Multivariate nonparametric methods with R: An approach based on spatial signs and ranks. Springer Science & Business Media.
- Paindaveine, D., & Verdebout, T. (2016). On high-dimensional sign tests. Bernoulli, 22(3), 1745–1769. https://doi.org/10.3150/15-BEJ710
- Sharpe, W. F. (1964). Capital asset prices: A theory of market equilibrium under conditions of risk. The Journal of Finance, 19(3), 425–442.
- Shekhar, S., C. T. Lu, & Zhang, P. (2003). A unified approach to detecting spatial outliers. GeoInformatica, 7(2), 139–166. https://doi.org/10.1023/A:1023455925009
- Tsay, R. S. (2020). Testing serial correlations in high-dimensional time series via extreme value theory. Journal of Econometrics, 216(1), 106–117. https://doi.org/10.1016/j.jeconom.2020.01.008
- Wang, L., Peng, B., & Li, R. (2015). A high-dimensional nonparametric multivariate test for mean vector. Journal of the American Statistical Association, 110(512), 1658–1669. https://doi.org/10.1080/01621459.2014.988215
- Zhao, P. (2023). Robust high-dimensional alpha test for conditional time-varying factor models. Statistics, 57(2), 444–457. https://doi.org/10.1080/02331888.2023.2180003
- Zhao, P., Chen, D., & Zi, X. (2022). High-dimensional non-parametric tests for linear asset pricing models. Stat, 11(1), e490. https://doi.org/10.1002/sta4.v11.1
- Zou, C., Peng, L., Feng, L., & Wang, Z. (2014). Multivariate sign-based high-dimensional tests for sphericity. Biometrika, 101(1), 229–236. https://doi.org/10.1093/biomet/ast040
Appendix
Proof of theorems
A.1. Proof of Theorem 2.1
Define
for
and
,
. Let
be the σ-field generated by
. It is easy to show that
and it follows that
is a zero mean martingale. Let
,
and
. The central limit theorem (Hall & Heyde, Citation1980) will hold if we can show
(A1)
(A1) and for any
,
(A2)
(A2) It can be shown that
So
Simple algebras lead to
as
. And
by Lemma 1 in Wang et al. (Citation2015). Thus, we have
. Similarly,
and
So
. Consequently, (EquationA1
(A1)
(A1) ) holds.
To show (EquationA2(A2)
(A2) ), we only need to prove that
By Lemma 1 in Wang et al. (Citation2015), we can show that
Here we complete the proof.
A.2. Proof of Theorem 2
where
By lemma 4 in Zou et al. (Citation2014) and condition (C3), we have
and
. So
. Thus, by taking the same procedure as the proof of Theorem 1 in Zhao et al. (Citation2022), we have
Let
. We can decompose
as
where
After some tedious algebra, we have
by Condition (C3). Taking the same procedure as the proof of Theorem 2.1, we can show that
And
Thus, we have