
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
For a panel data model (PDM), it is common that the error terms of panel regression model are heteroscedastic. In the available literature, the heteroscedastic consistent covariance matrix estimators (HCCMEs) have been used for adequate testing of the coefficients of PDM. Usually, these HCCMEs are based on the residuals derived from ordinary least square (OLS) estimator which is considerably inefficient in the presence of heteroscedasticity. To get efficient estimation, the existing literature proposes some adaptive estimators for the PDM. This paper presents the HCCMEs, derived from some adaptive estimator, while considering the panel data-set with unit-specific heteroscedasticity. Through the Monte Carlo simulations, we present the numerical evaluation and attractive findings.
Public Interest Statement
Panel data are multi-dimensional data consisting of measurements over time. The observations of multiple phenomena, obtained over multiple time periods for the same companies, firms, countries or individuals etc., constitute the panel data. Panel data have several advantages over purely crosssectional or purely time series data. To model such data, a panel data model (PDM) is used that provides information on individual behaviour, both across individuals and over time. In spite of its many advantages, a PDM may pose several estimation and inference problems due to several reasons and heteroscedasticity in cross-sectional units at the same point in time (i.e. unit-specific heteroscedasticity) is one of them. The present article addresses the same issue and suggests how one can improve in the inferential issue in the presence of unit-specific heteroscedasticity.
1. Introduction
In econometrics, one important type of data is known as the panel data. Panel data are based on various observations, collected from same individuals over several time periods. A regression model that fits panel data is known as the panel data model (PDM). In econometrics, analysis of PDM is the most dynamic assortment somewhat in light of the fact that panel data-sets give a rich domain to advancement of estimation methods and hypothetical results. In more useful terms, researchers have possessed the capacity to utilize time-series and cross-sectional data to inspect issues which could not be handled in either setting alone.
An important assumption of classical linear regression model (CLRM) is homoscedasticity that the variance of error term remains constant and thus, the error term is identically distributed. If this assumption is not met, there exists the issue of heteroscedasticity and the OLS results are inadequate in this case. Heteroscedasticity is a common problem in the PDM and it is desirable to concentrate on it for making robust inference. The ordinary technique used for estimation of PDM like the OLS does not lead to efficient estimation and correct inference in the presence of heteroscedasticity. The OLS estimator is not biased and inconsistent but does not remain best linear unbiased estimator (BLUE) when the assumption of homoscedasticity is violated. Furthermore, usual t and F statistic are unable to construct precise confidence interval and to perform correct testing of hypothesis. Moreover, presence of the high leverage points in given data-set may also lead to incorrect inference. Therefore, focus of this study is to bring improvement in inference of linear PDM suffering from heteroscedasticity, namely the unit-specific heteroscedasticity (USH).
Mazodier and Trognon (Citation1978) were the first who studied the problem of heteroscedasticity in the PDM, and later, Baltagi and Griffin (Citation1988) and Randolph (Citation1988) considered it. For the efficient estimation of the PDM under heteroscedasticity, some adaptive estimators are available in the literature. Li and Stengos (Citation1994) developed an adaptive estimator for the unit time-varying heteroscedasticity (UTVH) and Roy (Citation2002) proposed an adaptive estimator for the USH. Baltagi, Bresson, and Pirotte (Citation2004) studied performance of both of these estimators and found that Roy’s estimator performed well in terms of relative MSE and was not dependent on selection of bandwidth. However, the estimator proposed by Li and Stengos for UTVH showed loss in efficiency for smaller bandwidth but performed well under higher bandwidth.
To tackle the problem of heteroscedasticity, Eicker (Citation1963) and White (Citation1980) proposed HCCME for non-panel data which made it conceivable to draw asymptotically robust inference. In the existing literature, it can be seen that Arellano (Citation1987) built White’s estimator for the PDM. For common regression models, Ahmed, Aslam, and Pasha (Citation2011) and Aslam, Riaz, and Altaf (Citation2013) used the adaptive HCCME (AHCCME). Cribari-Neto (Citation2004) proposed a variant of the HCCME for common regression models to take into account the effect of leverage points. This estimator is known as HC4. Cribari-Neto, Souza, and Vasconcellos (Citation2007) proposed another version of the HCCME for linear regression models to study the effect of maximal leverage on associated inference. It is termed as the HC5. Adaptive versions of the HC4 and HC5 have been used for common regression models by Aslam et al. (Citation2013). It has been noticed in the available literature that the AHCCMEs are not used for the PDM. Therefore, this is the main concern of the current study.
This article unfolds as follows. Section 2 describes the PDM with USH and adaptive estimator. Section 3 describes the AHCCME. In Section 4, the quasi-t test statistic and computation of confidence interval and power of test are discussed. Empirical results are presented in Section 5. An illustrative example has been given in Section 6 and, finally, Section 7 concludes the said work.
2. Adaptive estimator for USH
Following Li and Stengos (Citation1994) and Roy (Citation2002), consider the standard one-way error component model(1)
(1)
where xit is 1 × q, is a unit-time varying error component (UTVEC) and
is the unit-specific error (USE) component assumed to be i.i.d. with that
,
where
. In other words, the conditional variance of USE is suffering from heteroscedasticity of unknown form. Throughout the paper, we assume T is small and N is large.
Matrix form of Model (1) is presented by Li and Stengos (Citation1994) as(2)
(2)
where , eT is a T-dimensional column vector of ones, ⊗ denotes the Kronecker product,
, and v are the NT × 1 column vectors of dependent variable and UTVEC, respectively, while x is an NT × q matrix of regressors.
Following the work of Baltagi and Griffin (Citation1988), Roy (Citation2002) presented inverse of the conditional variance–covariance matrix of error term (Zμ + v) in (2), which is denoted by W−1,(3)
(3)
where matrix of ones. For Model (2), the true generalized least square (TGLS) estimator of β is
(4)
(4)
The estimation of (4) involves covariance matrix of order NT × NT. So for large data-set, Roy proposed following version of (4)(5)
(5)
where xi is a T × q matrix of regressors for the ith individual, yi is T × 1 and is T × T covariance matrix
(6)
(6)
where and
To find estimates of
and γi need to be estimated which are unknown parameters in (6). Roy (Citation2002) estimated
as
where is similarly defined as
and
is the within group estimator (WGE) (for more details; see (Greene, Citation1997)).
Roy (Citation2002) defined and proposed the following kernel estimator for
(7)
(7)
where is the OLS residual from the regression of yjt on xjt,
is the kernel function with d as the smoothing parameter. Using (7), the estimates of ωi can be found as
and hence an estimator of
can be obtained as
The AGLS estimator of β is then obtained as
3. The AHCCME
For common regression models (i.e. models for cross-sectional data), Ahmed et al. (Citation2011) used the AHCCME (AHC0-AHC3). For common regression models, Cribari-Neto (Citation2004) proposed HC4 and Cribari-Neto et al. (Citation2007) proposed HC5. The AHC4 and AHC5 have been used for common regression models by Aslam et al. (Citation2013). However, such covariance estimators have not been studied yet by any author for the PDM. According to the above cited studies, the HC3, HC4, and HC5 give attractive performance to improve testing. Therefore, in the present study, we skip HC1 and HC2 but HC0 is included as a standard estimator.
The usual covariance matrix of is
Following White (Citation1980), Ahmed et al. (Citation2011), and Aslam et al. (Citation2013), we define a consistent estimator of the PDM as follows:(8)
(8)
where and
is the AGLS residual given as
.
The estimator in (8) is termed as AHC0.
Consider and hit as the itth diagonal element of hat matrix
then the AHC3 can be defined as
where (see similar construction of the HCCME in Uchôa, Cribari-Neto, and Menezes (Citation2014)). An observation with
is declared as a high leverage point by Hoaglin and Welsch (Citation1978). A general rule-of-thumb, cited in Cribari-Neto (Citation2004), is that the values of hit in excess of two or three times the average (i.e.
and
) are regarded as influential. The adaptive versions of Cribari-Neto (Citation2004) and Cribari-Neto et al. (Citation2007) estimator have not been studied in context of the PDM yet by any author. Therefore, we propose to use AHC4 and AHC5 for the PDM. The AHC4 and AHC5 are
where ,
,
being the average
leverage (i.e. the average value of all leverages). Since 0 < hi < 1 and hence
where
0 < c < 1, hmax is the maximum value of leverages. Since 0 < hi < 1 and δi > 0, hence .
Generally, the estimators presented above can be written in unified fashion as(9)
(9)
4. Adaptive heteroscedasticity consistent interval estimators (AHCIE), test statistic, and power of test
Cribari-Neto and Lima (Citation2009) considered heteroscedasticity consistent interval estimators (HCIE) based on and HCCMEs for common regression models. Aslam et al. (Citation2013) used the AHCIE in their work for non-panel regression models. But, we are going to consider the AHCIE for the PDM.
Let be a function of parameter of interest,
is its estimate and
is the asymptotic standard error. Consider the studentized statistic,
It is quite easy to show that
Consider the hypothesis, against
, where
is a hypothesized value of βr under H0.
Under homoscedasticity, the test statistic for above given hypothesis is(10)
(10)
where is the rth diagonal element of Ψ and r = 0, 1, 2,…, q−1. Then
is likely to follow a Student’s t distribution with degree of freedom (NT − tr(H)), such that
. For large sample size, the quantity above converges in distribution to the standard normal distribution (for more details; see (Cribari-Neto & Lima, Citation2009)). Thus, a test of asymptotic significance α rejects H0 if
where
is the
quantile of standard normal distribution. Thus, the true size of test can be computed as
(11)
(11)
Similar, the power of test can be measured as(12)
(12)
when the errors are heteroscedastic, the statistic in (10) can be re-defined as follows:
, s = 0, 3, 4 and 5.
In a similar manner, the confidence interval can be constructed. A (1−α)×100% (two tailed) confidence interval based on the AHCCME is(13)
(13)
5. Empirical results
For the empirical results, we use the same Monte Carlo scheme as used in some previous studies like Li and Stengos (Citation1994), Roy (Citation2002), and Rilstone (Citation1991)
The considered model is
where xit = 0.5wi,t-1 + wit and , i.e. wit is generated from lognormal distribution. The values assigned to β0 and
are 5 and 0.5, respectively. The vit and
can be generated as
,
, with
. It is supposed that heteroscedasticity is of additive form. Let the total variance
and the expected variance of μi is
and
, respectively. For comparison across different data generating process, the expected total variance is set to be
. The values of
are 0, 1, 2, and 3, where 0 indicates the homoscedastic USE and other shows different levels of heteroscedasticity for the fixed value of
and the values assigned to
are 2, 4, and 6. Increase in
cause increase in degree of heteroscedasticity. Moreover, the value of
can be obtained using different values of
for each value of
and α is obtained using the additive heteroscedastic design specified above for given
. Thus, the values of ωifor each
under the four different values of
are obtained. The Gaussian kernel cited in Roy (Roy, Citation2002) is used and defined as
.
Roy (Citation2002) used 0.5, 1, and 1.5 as bandwidth. In the present work, we used 0.5 as bandwidth.
The simulations are 5000 with two schemes for fixed small T but large N:
| (1) | Scheme I: N = 50; T = 3; NT = 150 | ||||
| (2) | Scheme II: N = 100; T = 3; NT = 300 | ||||
| (1) | The pooled OLSE | ||||
| (2) | The WGE | ||||
| (3) | The AGLS estimator (AGLSE) | ||||
| (4) | The AHCCME | ||||
Tables and show mean and MSE for Schemes I and II, respectively. Intercept is excluded in the WG estimation, therefore it does not appear in these tables and discussion is concentrated only on the slope estimates. Table shows that all the estimators remain almost unbiased and there is no issue of bias under heteroscedasticity. But the OLSE is inefficient for smaller UTVH () as it yields higher MSEs than the AGLSE. For
, the MSE of OLSE is more than twice of AGLSE and WGE. The WGE performs better than OLSE in terms of MSE but outperformed by AGLSE for
. Due to gain in efficiency, the AGLSE remains an attractive choice. Such results are actually due to Roy (Citation2002). Performance of the OLSE improves for larger UTVH (
). For
and
, the MSE of OLSE is identical to AGLSE. The similar behavior of all the estimators is observed in Table as noticed in Table . The MSE of OLSE decreases with the increase of sample size but it is still less efficient than the AGLSE and WGE for smaller UTVH (
).
Table 1. Mean and MSE (N = 50, T = 3)
Table 2. Mean and MSE (N = 100, T = 3)
Empirical sizes are displayed in Figure at 5% LOS and . The OLSE curve shows high over-rejection. While the curves produced by the AGLSE and WGE are closer to nominal LOS (5%). The curve of AHC0 shows deviation from nominal level (5%) under mild and moderate heteroscedasticity but becomes closer to 5% under severe heteroscedasticity for small sample. However, the AHC0 gets improvement in performance for large sample. Similar results have been reported by Long and Ervin (Citation2000) for cross-sectional data. The AHC4 and AHC5 curves are closer to the nominal LOS (5%).
Figure 1. Empirical size (%) for β.
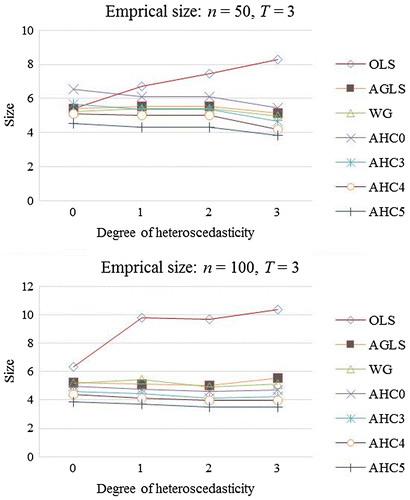
Tables and display empirical sizes for Schemes I and II, respectively. In Table , the test based on the OLS variance estimator is largely liberal under smaller UTVH (). It expresses high size distortion for the cases of heteroscedasticity. Under severe heteroscedasticity (
= 3), the NRR produced by the OLS variance estimator based quasi-t test is 8.30% at 5% LOS for smaller UTVH (
). However, the quasi-t test, based on the OLS variance estimator, gives better NRR for the larger UTVH (
). The quasi-t test, based on the AGLS variance estimator, performs better than the test based on the OLS variance estimator. For instance, for
, the NRR yields by AGLS variance estimator based quasi-t test is 5.14% at 5% LOS for smaller UTVH (
). It verifies the reported results of Roy. The quasi-t tests that employ AHCCMEs yield good NRR from smaller UTVH (
) to the larger UTVH (
). The best NRR among the AHCCMEs, is observed by the tests based on AHC4 and AHC5. In case of severe heteroscedasticity (
), the AHC4 yields exact NRR for
at 5% LOS. The results given by the AHC4 and AHC5 confirm the findings made by Cribari-Neto (Cribari-Neto, Citation2004) and Cribari-Neto et al. (Cribari-Neto et al., Citation2007) for the non-panel data and also justify their formulation for the PDM.
Table 3. NRR of quasi-t test for N = 50, T = 3
Table 4. NRR of quasi-t test for N = 100, T = 3
In Table , behavior of all the estimators is similar as presented in Table . The tests, based on the AGLSE variance estimator, perform well in terms of NRR as reported by Roy (Roy, Citation2002). Performance of the AHC4 and AHC5 remains attractive and justifies our proposal for the PDM.
Estimation of confidence interval is done as illustrated in Equation (13). For , empirical coverage is presented in Figure . The OLSE curve exhibits under-coverage, while the curve of AGLSE is closer to the nominal coverage (95%). The curve of AHC0 shows under-coverage for small sample but coverage rate is closer to the nominal coverage (95%) for the large samples. On the other side, the curves of AHC4 and AHC5 are closer to the nominal coverage (95%).
Figure 2. Empirical coverage (%) for β.
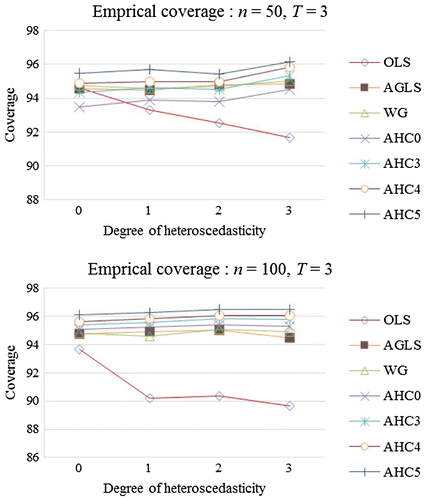
For the above-mentioned estimators, Tables and carry empirical coverage and average length for Schemes I and II, respectively. Performance of the OLSE is not satisfactory in for smaller UTVH as it shows under-coverage. However, the OLSE gets improvement in performance from smaller () to larger UTVH (
). While the AGLSE shows remarkable performance for homoscedastic as well as for all types of heteroscedastic cases. The empirical coverage of the WGE is closer to nominal coverage (95%) for all degrees of heteroscedasticity and it outperforms the OLSE. It is noticed that the best empirical coverage among AHCCMEs are produced by our AHC4 and AHC5. The AHC4 exhibits exact coverage for
in case of mild heteroscedasticity (
) and also for larger UTVH (
) when
. The AHC5-based confidence intervals display coverage that is close to the nominal coverage (95%).
Table 5. 95% Confidence interval: coverage (%) and length (N = 50, T = 3)
Table 6. 95% Confidence interval: coverage (%) and length (N = 100, T = 3)
Performance of the estimators in Table is similar to that observed in Table . For the large samples, Roy’s estimator outperforms the OLSE. Among the AHCCME, AHC4 and AHC5 express very good coverage and average interval length and they remain attractive choice.
Figures – show empirical power curves, built upon all the above mentioned estimators for Scheme I. For , Figure gives indication that for homoscedastic (
) and heteroscedastic situations (
, 2 and 3), all the estimators show identical power of test to that of the AGLSE except OLSE. However, as
increases, the OLSE gets improvement in such a way that for
, all the estimators become near to identical in power of test. Table gives numerical values of the empirical power for a specific case i.e.
Aslam (Citation2006) presented power curve analysis of the above mentioned estimators in context of the PDM and our results verify his findings.
Figure 3. Empirical power at 5% LOS (N = 50, T = 3; ).
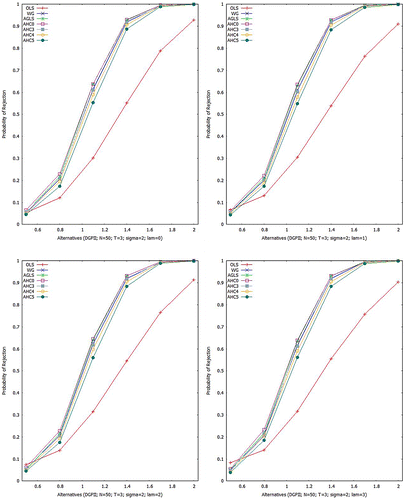
Figure 4. Empirical power at 5% LOS (N = 50, T = 3; ).
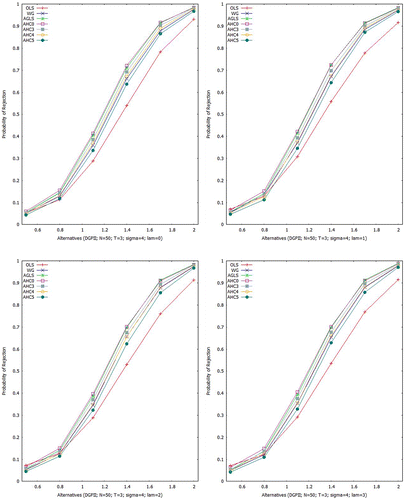
Figure 5. Empirical power at 5% LOS (N = 50, T = 3; ).
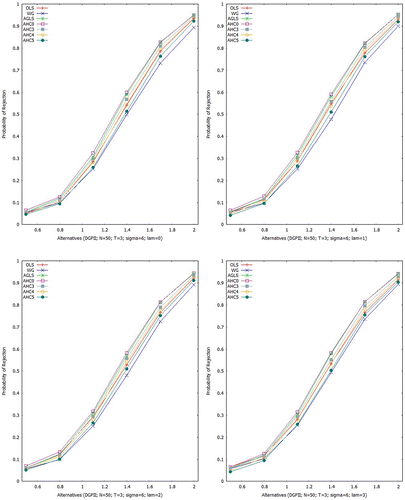
Table 7. Power results (%) for 
For all the estimators under consideration, empirical power curves for Scheme II are displayed in Figures –. In case of larger sample, it is noticed that power curves of all the estimators get slumber. Performance of the OLSE is not good for smaller UTVH () but it becomes closer to the AGLSE for larger UTVH (
).
Figure 6. Empirical power at 5% LOS (N = 100, T = 3; ).
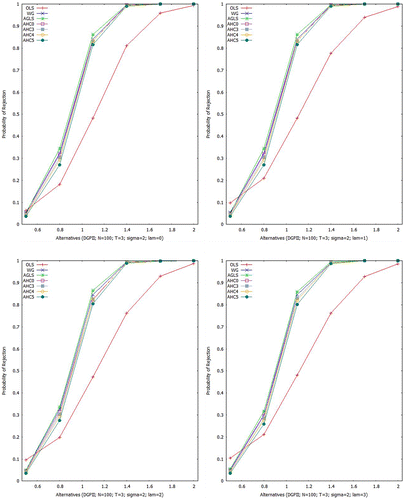
Figure 7. Empirical power at 5% LOS (N = 100, T = 3; ).
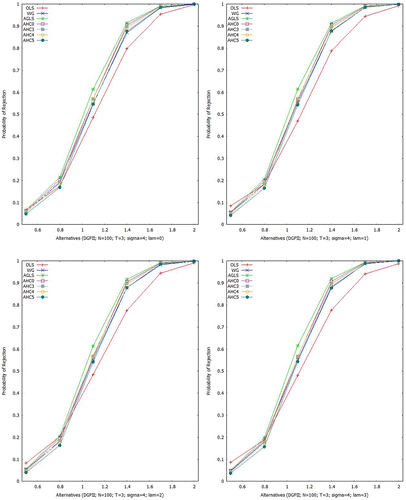
Figure 8. Empirical power at 5% LOS (N = 100, T = 3; ).
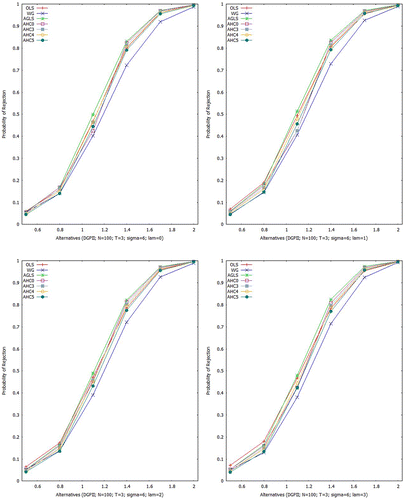
6. Illustrative example
We take an example of panel data of productivity of USA (Munnell, Citation1990) with T = 17 and N = 48. The model of interest is(14)
(14)
where y denotes gross production, x1 is high way capital, x2 is water utility capital, x3 is utility capital, x4 is private capital, x5 is employed capital, and x6 is unemployed capital.
In order to evaluate the testing performance of all the stated estimators, following Cribari-Neto (Citation2004), an extra variable (e.g. ) is being added as an explanatory variable. Thus, Model (14) is reformulated as
(15)
(15)
The USH is found after the Wald test (with p-value < 0.01). Table displays the comparative statistics obtained from Model (14). The results obtained from fitting of Model (15) are presented in Table . All the regression coefficients are found to be statistically significant while referring to Table . In Model (15), we include square of employed capital as an extra explanatory variable with the expectedly no impact on determining the gross production. Thus, it should be statistically non-significant. We perform the inference again. In this situation, the attractive estimator would be one that does not reject the null hypothesis of β7 = 0. Table shows that the tests based on only AHC4 and AHC5 do not reject the hypothesis of β7 = 0 at 1% LOS.
Table 8. Comparative statistic of model (14)
Table 9. Comparative statistic of model (15)
7. Conclusion
To improve the testing of coefficients of the PDM with the problem of USH, we have used the HCCMEs, based on Roy’s (Citation2002) adaptive estimator. It is found that the AHC4 and AHC5 perform better than all the competing estimators in terms of NRR, power of tests and empirical coverage of interval estimators. On the basis of our findings, the adaptive versions of HCCME are found to be as attractive choice for the testing of PDM as they are for the linear regression models with heteroscedastic errors.
Funding
The authors received no direct funding for this research.
Additional information
Notes on contributors
Afshan Saeed
Muhammad Aslam is a tenured associate professor at the Department of Statistics, Bahauddin Zakariya University, Multan, Pakistan. He acquires a teaching experience of more than 20 years at postgraduate level. His main area of interest runs around the inference of linear regression models with issues of heteroscedasticity and multicollinearity. He has conducted a number of researches in the stated area while leading a research team, comprising of his research students and few colleagues. Recently, this team has developed three R packages, namely “mctest”, “lmridge”, and “liureg” which are available on the R CRAN. These are comprehensive packages for detection of multicollinearity, estimation of the ridge and Liu regression models with different choices of penalties. The present article is a part of PhD research project of Afshan Saeed (the Principal author) under the supervision of Aslam. This article, primarily addresses the inference of panel data model with the issue of unit-specific heteroscedasticity.
References
- Ahmed, M., Aslam, M., & Pasha, G. R. (2011). Inference under heteroscedasticity of unknown form using an adaptive estimator. Communications in Statistics – Theory and Methods, 40, 4431–4457.10.1080/03610926.2010.513793
- Arellano, M. (1987). Computing robust standard errors for within-group estimators. Oxford Bulletin of Economics and Statistics, 49, 431–434.
- Aslam, M. (2006). Adaptive procedures for estimation of linear regression models with known and unknown heteroscedastic errors ( dissertation). Pakistan: Bahauddin Zakariya University.
- Aslam, M., Riaz, T., & Altaf, S. (2013). Efficient estimation and robust inference of linear regression models in the presence of heteroscedastic errors and high leverage points. Communications in Statistics – Simulation and Computation, 42, 2223–2238.10.1080/03610918.2012.695847
- Baltagi, B. H., & Griffin, M. (1988). A generalized error component model with heteroscedastic disturbances. International Economic Review, 29, 745–753.10.2307/2526831
- Baltagi, B. H., Bresson, G., & Pirotte, A. (2004). Adaptive estimation of heteroskedastic error component models. USA: Texas A & M University, Working Paper.
- Cribari-Neto, F. (2004). Asymptotic inference under heteroskedasticity of unknown form. Computational Statistics & Data Analysis, 45, 215–233.10.1016/S0167-9473(02)00366-3
- Cribari-Neto, F., & Lima, M. G. A. (2009). Heteroskedasticity-consistent interval estimators. Journal of Statistical Computation and Simulation, 79, 787–803.10.1080/00949650801935327
- Cribari-Neto, F., Souza, T. C., & Vasconcellos, K. L. P. (2007). Inference under heteroskedasticity and leveraged data. Communications in Statistics – Theory and Methods, 36, 1877–1888.10.1080/03610920601126589
- Eicker, F. (1963). Asymptotic normality and consistency of the least squares estimators for families of linear regressions. The Annals of Mathematical Statistics, 34, 447–456.10.1214/aoms/1177704156
- Greene, W. H. (1997). Econometric analysis (3rd ed.). Upper Saddle River, NJ: Prentice Hall.
- Hoaglin, D. C., & Welsch, R. E. (1978). The hat matrix in regression and ANOVA. American Statistical, 32, 17–22.
- Li, Q., & Stengos, T. (1994). Adaptive estimation in the panel data error component model with heteroscedasticity of unknown form. International Economic Review, 35, 981–1000.10.2307/2527006
- Long, J. S., & Ervin, L. H. (2000). Using heteroscedasticity consistent standard errors in the linear regression model. American Statistical, 54, 217–224.
- Mazodier, P., & Trognon, A. (1978). Heteroscedasticity and stratification in error components models. Anna. de l’Insee, 30–31, 451–482.
- Munnell, A. H. (1990). Why has productivity growth declined? Productivity and public investment. New England: Economic Review.
- Randolph, W. C. (1988). A transformation for heteroksedastic error components regression models. Economics Letters, 27, 349–354.10.1016/0165-1765(88)90161-9
- Rilstone, P. (1991). Some Monte Carlo evidence on the relative efficiency of parametric and semi parametric EGLS estimators. Journal of Business & Economic Statistics, 9, 179–187.
- Roy, N. (2002). Is adaptive estimation useful for panel models with heteroscedasticity in the individual specific error component? Some monte carlo evidence Economic Review, 21, 189–203.
- Uchôa, C. F. A., Cribari-Neto, F., & Menezes, T. A. (2014). Testing inference in heteroscedastic fixed effects models. European Journal of Operational Research, 235, 660–670.10.1016/j.ejor.2014.01.032
- White, H. (1980). A heteroscedasticity-consistent covariance matrix estimator and a direct test for heteroscedasticity. Econometrica, 48, 817–838.10.2307/1912934