
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Clustering is a powerful technique in data-mining, which involves identifing homogeneous groups of objects based on the values of attributes. Meta-heuristic algorithms such as particle swarm optimization, artificial bee colony, genetic algorithm and differential evolution are now becoming powerful methods for clustering. In this paper, we propose a new meta-heuristic clustering method, the Whale Clustering Optimization Algorithm, based on the swarm foraging behavior of humpback whales. After a detailed formulation and explanation of its implementation, we will then compare the proposed algorithm with other existing well-known algorithms in clustering, including PSO, ABC, GA, DE and k-means. Proposed algorithm was tested using one artificial and seven real benchmark data sets from the UCI machine learning repository. Simulations show that the proposed algorithm can successfully be used for data clustering.
Public Interest Statement
Clustering is an important and useful operation in data-mining, which involves classifying a particular set of unlabeled data into two or more groups, so that there is maximum similarity among the data of each claster based on the selection criteria. Clustering algorithms cover a broad spectrum of utilization, having applications in such diverse fields as medical science, decision making, manufacturing, image processing, etc. Nawdays, considering the existence of such a massive amount of non-labeled data, the deployment of intelligent methods for data clustering has become a necessity. Therefore, this study deploys whale optimization algorithm (WOA) to solve clustering problems. The obtained solutions of the proposed algorithm are more accurate than those achieved using existing methods; moreover, due to its search methodology, the possibility of local optima entrapment is very low.
1. Introduction
Data mining is the procedure of identifying correlation and patterns among attributes in databases by using appropriate techniques.
Data mining levels are preprocessing of data, selection of efficient and appropriate algorithm and to analyze the data. Some of the methods in data mining are the summation, association, and clustering. Data clustering is the most popular and practical method of them, that have been used for a variety of applications in data mining as pattern recognition (Andrews, Citation1972; Chen, Kim, & Mahnassani, Citation2014; Chen, Qi, Fan, Limeng, & Yong, Citation2015), image analysis (Aziz, Ewees, & Hassanien, Citation2018; Chien-Chang, Hung-Hun, Meng-Yuan, & Horng-Shing, Citation2018; Lillesand & Keifer, Citation1994), security, vector quantization and other fields (Chiranjeevi & Jena, Citation2016; Gribkova, Citation2015; He, Pan, & Lin, Citation2006).
Clustering is gathering unlabelled objects into groups with respect to similarities between these objects. Such that the objects in the same cluster are more similar to each other than objects in different clusters according to some predefined criteria (Elhag & Ozcan, Citation2018; Zhang, Ouyang, & Ning, Citation2010). A number of algorithms have been proposed that take into account the nature of the data, the quantity of the data and other input parameters in order to cluster the data. The similarity criteria in clustering are various in different researches. Most of the clustering problems have exponential complexity in terms of the number of clusters. Because most of the similarity criterion functions are non-complex and nonlinear, clustering problems have several local solutions (Welch, Citation1982).
Clustering algorithms can be simply classified as hierarchical clustering and partitional clustering (Frigui & Krishnapuram, Citation1999; Han & Kamber, Citation2001; Leung, Zhang, & Xu, Citation2000; Sander, Citation2003). Hierarchical clustering groups data with a sequence of partitions either from singleton clusters to a cluster, including all objects or vice versa. This study is centralized on partitional clustering, that divide the data set into a set of disjoint clusters. The most popular partitional clustering algorithms are the prototype-based clustering algorithms where each cluster is represented by the center of the cluster, and the used objective function is the sum of the distance from the object to the center.
k-means is a popular, center-based clustering approach due to its simplicity and efficiency with linear complexity. However, the solution of the k-means algorithm depends on the initial random state and always converges to the local optimum (Jain & Dubes, Citation1998; MacQueen, Citation1967). Recently, researchers to overcoming this problem have presented heuristic clustering algorithms. Due to the large amount of information and the complexity of the problems, classical optimization methods are incapable of solving most of the optimization problems; therefore, researchers have started to use meta-framework algorithms. Today, nature-inspired algorithms are widely used to solve these problems in various fields (Faieghi & Baeanu, Citation2012; Farnad & Baleana, Citation2018; Sharma & Buddhirju, Citation2018). Meanwhile, clustering techniques, as well as other data mining and data analysis steps, have made significant progress using the collective intelligence algorithms.
Clustering with heuristic algorithms is emerging as an alternative to more conventional clustering techniques (Cui, Citation2017; Zhang et al., Citation2010).
Selim and Al-Sultan (Selim & Al-Sultan, Citation1991) used a simulated annealing approach for the clustering problem. Predetermined parameters of the algorithm are discussed and its convergence to a global solution of the clustering problem is demonstrated.
Mualik and Mukhopadhyay (Maulik & Mukhopadhyay, Citation2010) presented a combined clustering algorithm. They combined SA with artificial neural networks to improve solution quality. The proposed hybrid algorithm was used to cluster three real-life microarray data sets and the results of the proposed approach were compared with some commonly used clustering algorithms. The results indicated the superiority of the new algorithm. Mualik and Bundyopadyay (Mualik & Bandyopadhyay, Citation2000) presented an approach based on genetic algorithm to solve the clustering problem. They examined the algorithm on synthetic and real-life data sets to evaluate its performance.
Shelokar et al. (Shelokar, Jayaraman, & Kulkarni, Citation2004) proposed a clustering algorithm based on ant colony optimization (ACO). The proposed algorithm was tested on some artificial and real-life data sets. The performance of this technique in comparison with popular algorithms such as GA, SA, and TS appeared to be very promising. Merve et al. (Van Der Merve & Engelhrecht, Citation2003) presented an approach to solving clustering problem used the particle swarm optimization (PSO) algorithm. A PSO clustering and a hybrid method were used, where the particles of the swarm are selected by the answers of the k-means algorithm. Both methods were compared with the k-means algorithm and the results indicated that the proposed algorithms and better answers.
Tunchan (Tunchan, Citation2012) presented a new PSO approach to the clustering problem that is efficient, easy-to-tune and applicable when the number of clusters is known or unknown. Karaboga et al. (Karaboga & Ozturk, Citation2011) used the artificial bee colony algorithm to solve the clustering problem. The results of simulations on 13 test problems from UCI indicated the superior performance of the proposed algorithm in comparison to PSO algorithm and some other approaches. Furthermore, the authors were found that the ABC algorithm can be appropriate to solve multivariate clustering problems.
Zhang et al. (Zhang et al., Citation2010) proposed an artificial bee colony (ABC) clustering algorithm to clustering that Deb’s rule is used to selection process instead of greedy selection. They test the algorithm on several well-known real data sets and compared with other popular heuristics algorithms in clustering. Results were very encouraging in terms of the quality of clusters. Armando and Farmani (Armando & Farmani, Citation2014) proposed a method that is the combined of k-means and ABC algorithms to improve the efficiency of k-means in finding a global optimum solution.
Karthikeyan and Christopher (Karthikeyan & Christopher, Citation2014) propose an algorithm by a combination of PSO algorithm and ABC algorithm used for data. This algorithm is compared with other existing clustering algorithms to evaluate the performance of the proposed approach. Sandeep and Pankaj (Sandeep & Pankaj, Citation2014) proposed a new hybrid sequential clustering approach, that uses PSO algorithm in sequence with the Fuzzy k-means algorithm in data clustering. Experimental results show that the new approach improves quality of formed clusters and avoids being trapped in local optima.
Recently, Mirjalili and Lewis (Mirjalili & Lewi, Citation2016) described a new swarm based meta-heuristic optimization algorithm that mimicking the social behavior of humpback whales in hunting that called whale optimization algorithm (WOA)(Mirjalili, Mirjalili, & Lewis, Citation2014¸Mirjalili & Lewi, Citation2016, Horng, Dao, Shieh, & Nguyen, Citation2017). The algorithm is inspired by the bubble_net hunting strategy. They have tested the WOA algorithm with 29 mathematical benchmark optimization problems and compared the performance of WOA algorithm with other conventional modern heuristic algorithms such as PSO (Kenedy & Eberhart, Citation1995), Differential Evolutional (Storn & Price, Citation1997), Gravitational Search Algorithm (Rashedi, Nezamabadi- Pour, & Saryazdi, Citation2009) and Fast Evolutionary Programming (Yao & Liu, Citation1999). WOA was recognized to be enough competitive with other well-known and popular meta-heuristic methods.
In this paper, the WOA algorithm is extended for solving the clustering problem as an optimization problem. We intend to use the advantages of the whale optimization algorithm, such as the low number of parameters and lack of local optima entrapment, in solving clustering problems. Our main goal is to cluster unlabeled data using the whale optimization algorithm so that we can get better results with simple solutions and do a complete search compared to the existing methods. The performance of the proposed algorithm has been tested on various data sets and compared with several clustering algorithms. The remaining of this paper is organized as follows: Section 2 discussed the clustering problem. Section 3 describes the WOA algorithm. The new WOA clustering algorithm was proposed in section 4. Section 5 provided the experimental results. Finally, conclusions and some future research direction are in section 6.
2. The clustering problem
Clustering is applied to grouping data objects of a given data set based on some similarity measures. Similar objects are ideally put in the same cluster while dissimilar objects are placed in different clusters. Most of the researchers used instance measurement for evaluating similarities between objects, which is obtained from the Minkouski metric.
In general, the problem can be expressed as follows: Suppose that be a set of n objects of a data set with m dimensions. Each
is described by a real-valued m dimensional vector as
where each
denotes the value of jth attribute of the ith object. The goal of clustering is assigned each object
to one of the k cluster in the set of partition
, such that distance between
and
center of kth cluster center be the minimum and
1.
2.
3. .
So, clustering problem is minimizing the following Euclidean distance:
where denotes ith data object and
represents the kth cluster center.
is the association weight of pattern
with cluster k and defined as
According to Equation (2.2), we assign each object to the nearest cluster center out of the all cluster centers.
3. Whale optimization algorithm
Whale optimization algorithm was proposed by Jalili and Lewis for optimizing numerical problems (Mirjalili & Lewi, Citation2016). The algorithm simulates the intelligence hunting behavior of humpback whales. This foraging behavior is called bubble-net feeding method that is only be observed in humpback whales. The whales create the typical bubbles along a circle path while encircling prey during hunting. Simply, bubble-net hunting behavior could describe such that humpback whales dive down approximation 12 m and then create the bubble in a spiral shape around the prey and then swim upward the surface following the bubbles. In order to perform optimization, the mathematical model for spiral bubble-net feeding behavior is given as follows:
3.1. Encircling prey
Humpback whales can find the place of prey and encircle them. The WOA algorithm considers; current best search agent position be the target prey or close to the optimum point, and other search agents will try to update their position towards the best search agent. This behavior is formulated as the following equations:
where t indicates the current iteration, is the position vector of the best solution have been obtained so far iteration t,
is the position vector of each agent, | | is the absolute value, and . is an element-by-element multiplication. The coefficient vectors
and
are calculated as follows:
where is linearly decreased from 2 to 0 over the course of the iteration and r is a random number [0,1].
3.2. Bubble-net attacking method
The Bubble-net strategy is hybrid of combined two approaches that can be mathematically model as follows::
a. Shrinking Encircling Mechanism
This behavior of Whales simulated by decreasing the value of in the equation (3.3). Note that the fluctuation range of
is also decreased by
. In other words,
is a random value in the interval
where a is decreased from 2 to 0 over the course of iterations. Setting random values for
in [−1,1], the new position of a search agent can be defined anywhere in between the original position of the agent and the position of the current best agent.
b. Spiral Updating Position
In this approach, a spiral equation is created between the position of whale and prey to simulate the helix-shaped movement of humpback whales as follows:
where is the distance between the whale and prey, b is constant defines the logarithmic shape, l is random in [−1,1] and is an element-by-element multiplication.
Indeed, humpback whales swim along a spiral-shaped path and at the same time within shrinking circle. Assuming a probability of 50%, choosing either the shrinking encircling movement or the spiral model movement is simulated during iterations of the algorithm. It means that:
where p is a random number in [0,1].
3.3. Search for prey
Almost all meta-heuristic algorithms explore the optimum using random selection. In the bubble-net method, the position of the optimal design is not known, so humpback whales search for prey randomly. In contrast to the exploitation phase with in interval [−1,1] in this phase consider,
be a vector of the random values greater than 1 or less than −1. With this assumption, search agent able to move far away from a reference whale. In return, the position of search agent will be updated according to randomly chosen from search agent, instead of the best search agent found so far. These two actions formulated as follows:
where is a random position vector.
The WOA algorithm starts from a set of random solutions. At each iteration, search agents update their position according to the above explanations. WOA is a global optimizer. Adaptive variation of the search vector allows the WOA algorithm easily transit between exploration and exploitation. Furthermore, WOA includes only two main internal parameters to be adjusted. High exploration ability of WOA is due to the position updating mechanism of Whales using (3.9). High exploitation and convergence are emphasized, which originate from (3.6) and (3.2). These equations show that the WOA algorithm is able to provide high local optima avoidance and convergence speed during the course of the iteration.
4. Whale optimization-based clustering algorithm
Whale optimization algorithm is a new meta-heuristic optimization algorithm that simulates the intelligence bubble-net hunting behavior of humpback whales. WOA is a simple, robust and swarm based stochastic optimization algorithm. Population-based WOA has an ability to avoid local optima and get a global optimal solution. These advantages cause WOA to be an appropriate algorithm for solving different constrained or unconstrained optimization problems for practical applications without structural reformation in the algorithm.
In the context of WOA, a swarm refers to a number of potential solutions to the optimization problem, where each potential solution is referred to as a search agent. The aim of the WOA is to find the search agent position that results in the best evaluation of a given objective function.
In this section, we are going to solve the clustering problem using WOA. Inspired by the context of clustering, assume that search agent represents k cluster centers (k is predefined and shows the number of clusters). Each search agent is constructed as follows:
where refers to the jth cluster center vector of the ith search agent in cluster
. Therefore, a swarm represents a number of candidates clustering for the vectors of the data set. We prefer intra-distance of clusters be the fitness function that measures the distance between cluster center and data vectors of the same cluster according to Equations (2.1) and (2.2).
According to above assumptions the pseudo code of whale optimization clustering algorithm proposes as follows: pseudocode
Algorithm 1 The Whale Optimization-based Clustering Algorithm
1: procedure2: Load data samples3: Initialize each search agent to contain k randomly cluster centers4: while do5: for each search agent i do6: for each data vector
do7: Calculate the Euclidean distance of
to all cluster centers.8: Assign
to the cluster
such that
9: Calculate the fitness using (4.2)
10: end for11: end for12: is the best search agent13: for each search agent do14: update a, A, C, I and p15: if
then16: if
then17: update search agent by (3.2)18: else if
then19: select random search agent20: update current search agent by (3.9)21: end if22: else if
then23: update the position of current search agent by (3.6)24: end if25: end for26: t = t + 127: end while28: return
29: end procedure
From theoretical standpoint, WOA clustering algorithm can be considered as a global optimizer because it includes exploration and exploitation ability simultaneously. Furthermore, the proposed hyper-cube mechanism defines a search space in the neighborhood of the best solution and allows other search agents to exploit the current best record inside that domain. Adaptive variation of the search vector A allows the WOA clustering algorithm to smoothly transit between exploration and exploitation. It means that by decreasing A, some iterations are concentrated to exploration, and the rest is dedicated to exploitation.
5. Experimental study
In this work, the performance of WOA clustering approach was compared to well-known algorithms namely the ABC clustering proposed by Karaboga and Ozturk (Karaboga & Ozturk, Citation2011), the PSO clustering proposed by Merve and Engelbrecht (Van Der Merve & Engelhrecht, Citation2003), the differential evolution-based (DE) clustering algorithm proposed by Sakar et al. (Sarkar, Yegnanafayana, & Khemani, Citation1997), the genetic algorithm-based clustering technique, called GA-clustering (GA), proposed by Mualik and Bandyopadyay (Mualik & Bandyopadhyay, Citation2000) and k-means a vector quantization algorithm proposed by MacQueen (MacQueen, Citation1967). All algorithms were programmed in Matlab 2013b and executed on an Intel core, i7 CPU, 4 Gb and 1.73 GHz computer running Microsoft Windows XP. The parameter settings are the same in the original corresponding papers. Here, 8 data sets are used to evaluate the performance of proposed algorithm compared with above heuristics. One artificial data set that is generated in Matlab environment using mean vector and variance matrix sigma. Other data sets are from classification problems from the UCI databases (Blake & Merz, Citation1998) that are Iris, wine, contraceptive method choice (CMC), Balance, Breast Cancer, Glass and Thyroid data sets. The data sets are used in this study can be described as follows:
Artificial data set ART: This data sets contain 300 objects and three clusters. Samples are drawn from three independent bivariate normal distribution, where classes were distributed according to ,
,
and sigma
is the covariance matrix.
The artificial produced data set are described in Figure .
Figure 1. The ART datset and clustering of ART data set.
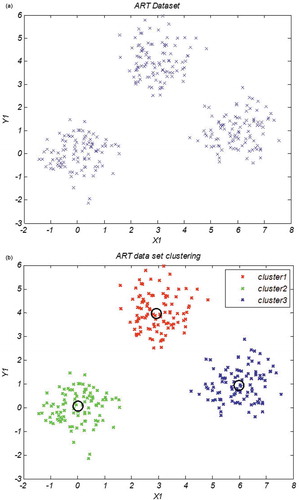
Figure visualizes the clusters performed by WOA clustering approach on art data set. Attention at position of the cluster centers specified by WOA shows that proposed algorithm has a high ability to find the global optimal answers.
Iris data set: This data set contains 150 random samples of flowers from the Iris species setosa, versicolor and virginica used by Fisher (Fisher, Citation1936). From each species, there are 50 observations with four attributes, which are sepal length, sepal width, petal length and petal width in cm.
Wine data set: This data set are the results of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars (Forina, Leardi, Armanino, & Lanteri, Citation1998). The analysis determined the quantities of 13 constituents found in each of the three types of wines. So, there are 178 instances with 13 numeric attributes in Wine data set.
CMC data set are a subset of the 1987 Indonesia Contraceptive Prevalence survey. The samples are married women who were either not pregnant or do not know if they were at the time of the interview. The problem involves predicting the choice of the current contraceptive method of a woman based on her demographic and socio-economic characteristics. This data set contains 1473 objects with 9 attributes and 3 clusters.
Balance data set: This data set was generated to model psychological experimental results. Each example is classified as having the balance scale tip to the right, tip to the left or be balanced. The data set include 4 inputs, 3 classes and there are 625 examples.
Cancer data set: This data set is based on Breast Cancer Wisconsin-Original set. It contains 569 patterns with 11 attributes and 2 clusters.
Glass data set: This data set contains one of the biggest numbers of classes. It is used to classify glass types as float processed building windows, vehicle windows, containers, tablewares or headlamps. Nine inputs are based on 9 chemical measurements with one of six types of glass, which are continuous with 70, 76, 17, 13, 9 and 29 instances of each class respectively. The total number of instances is 214.
Thyroid data set: This data set is the diagnosis of thyroid, whether it is hyper or hypofunction. Five inputs are used to classify three classes of Thyroid function as being over function, normal function or under function. The data set is based on new-thyroid data and contains 215 patterns. There are two control parameters in WOA algorithm. The swarm size of whales set in 50 and the maximum number of iteration supposed to 300. The parameter settings of ABC, PSO, GA, DE and ACO are set the same as their original papers. The effectiveness of stochastic algorithms is greatly dependent on 20 times individually for their own effectiveness test, each time with randomly generated initial solutions.
Table summarizes results, obtained from the clustering algorithms for the data sets described above. The values reported are averages of intra-cluster distances over 20 simulations, standard deviations, and ranking of the techniques based on mean values. At a glance, it is obvious that the WOA algorithm gets the best performance in six of the problems and the second rank in two problems. In artificial problem and Iris, Balance, Cancer and Thyroid data sets proposed algorithm is in rank 1 in comparison with other algorithms. In Glass problem, that contains one of the biggest numbers of clusters, also the WOA clustering algorithm is in rank 1 and mean value of intra-cluster distance function is 231.29. This value is very smaller in comparison with other algorithms. IN Glass problem PSO algorithm is in rank 2 and mean value, in this case, is 240.89. This result shows the excellence of WOA clustering algorithm between the other swarm intelligence algorithms. The high performance of WOA clustering in average values will be highlighted when reviewing the values of standard deviations in different clustering algorithms. For example, in Iris and Cancer problems, proposed algorithm has the smallest SD values. In Wine, CMC and Thyroid SD values are in second place.
Table 1. Comparison of the performance of WOA clustering algorithm with other well-known clustering algorithms
It is worthy to note that, biggest value of SD is in WOA clustering algorithm is 4.51 that be seen in Glass problem. According to mean value of WOA in CMC problem, the high value of SD is negligible. As a result of above discussion, solutions of using WOA to solve clustering problem is very significant and successful. By foreseeing the benefits of WOA algorithm namely, the lowest number of predetermined parameters, simplicity in implementation, ability to avoid local optima and get a globally optimal solution, It can be said that WOA clustering is an excellent offer to solve clustering problems.
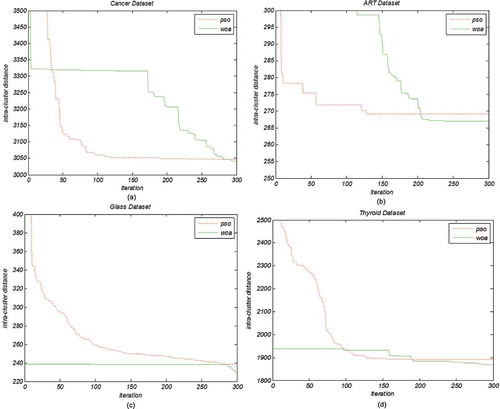
The convergence of curves of the WOA and PSO clustering for ART, Cancer, Glass and Thyroid data sets are provided in Figure . As it is obvious in this figure, usually the WOA clustering (with intra-cluster distance fitness function) behavior in the convergence towards the optimum only in final iterations. This is probably due to avoiding local optimum. This means that, the algorithm fails in local search and as a result does exploration in the initial steps of iteration avoiding local search, but in the last iterations, algorithm cleverly tends towards the global optimum response. In 100 last iterations, the performance of algorithm in local search improves significantly and finally PSO fails compared with WOA.
Figure 2. Convergence of curves of the WOA and PSO for some data sets.
6. Conclusion
Nowadays, simulation the intelligence behavior of animals and insects for solving the search and optimization problems is very common. Whale optimization algorithm which is inspired by bubble-net the haunting strategy of humpback whales is most closely studied a meta-heuristic algorithm in the area of swarm intelligence, which is a new, simple and robust optimization approach. In this paper, the whale optimization algorithm developed to solve popular clustering problem. Clustering is gathering data into clusters such that the data in the same cluster have a high degree of similarity and data from different clusters being as possible as dissimilar. The results of this algorithm is compared with well-known k-means clustering approach and other popular stochastic algorithms such as PSO, artificial bee colony, differential evolution, and genetic algorithm clustering. The Preliminary computational experience in terms of the intra-cluster distance function and standard deviation shows that the whale optimization algorithm can successfully be applied to solve clustering problems. Moreover, these results proposed algorithm was effective, easy to implementation and robust as compared with other approaches. There are some directions that can improve the performance of the proposed algorithm in the future. The combination of WOA clustering algorithm with other clustering approaches and using other fitness functions in clustering approach can be further researches.
Additional information
Funding
Notes on contributors
Jhila Nasiri
J. Nasiri Roveshti is currently Ph.D. student in IAU, Tabriz Branch, Iran. Her current interests include data mining and optimization.
Farzin Modarres Khiyabani
Farzin Modarres Khiyabani is an assistant professor of mathematics at Tabriz Islamic Azad University. His research interests include operation research, meta-heuristic algorithms, numerical optimization and image processing. His articles have been published in various international journals indexed in WOS.
References
- Andrews, H. C. (1972). Introduction to mathematical techniques in pattern recognition. New York, NY: Wiley-Interscience .
- Armando, G., & Farmani, M. R. (2014). Clustering analysis with combination of artificial bee colony algorithm and k-means technique. International Journal of Computer Theory and Engineering, 6(2), 141–145. doi:10.7763/IJCTE.2014.V6.852
- Aziz, M. A. E., Ewees, A. A., & Hassanien, A. E. (2018). Multi-objective whale optimization algorithm for content- based image retrieval. Multimedia Tools and Applications, 1–38.
- Blake, C. L., & Merz, C. J. (1998). University of California at Irvine repository of machine learning databases. Retrieved from http://www.ics.uci.edu/mlearn/MLRepository.html.
- Chen, Y., Kim, J., & Mahnassani, H. (2014). Pattern recognition using clustering algorithm for scenario definition in traffic simulation- based decision support systems. IEEE 17th International Conference on Intelligent Systems., 798–803.
- Chen, Z., Qi, Z., Fan, M., Limeng, C., & Yong, S. (2015). Image segmention via improving clustering algorithms with density and distance. Information Technology and Quantitative Management, 55, 1015–1022.
- Chien-Chang, C., Hung-Hun, J., Meng-Yuan, T., & Horng-Shing, L. H. (2018). Unsupervised learning and pattern recognition of biological data structures with density functional theory and manchine learning. Scientific Reports, 8, 557. doi:10.1038/s41598-017-18931-5
- Chiranjeevi, K., & Jena, U. R. (2016). Image compression based on vector quantization using cuckoo search optimization technique. Ain Shams Engineering Journal. doi:10.1016/j.asej.2016.09.009
- Cui, D. (2017). Application of whale optimization algorithm in reservoir optimal operation. Advances in Science and Technology of Water Resources, 37(3), 72–79, 94.
- Elhag, A., & Ozcan, E. (2018). Data clustering using grouping hyper-heuristics. Evolutionary Computation in Combinatorial Optimization, LNCS, 10782, 101–115.
- Faieghi, M. R., & Baeanu, D. (2012). Anovel adaptive controller for two-degree of freedom polar robot with unkown perturbations. Communications in Nonlinear Science, 17(2), 1021–1030. doi:10.1016/j.cnsns.2011.03.043
- Farnad, B., & Baleana, D. (2018). A new hybrid algorithm for continuous optimization problem. Applied Mathematical Modeling, 55, 652–673. doi:10.1016/j.apm.2017.10.001
- Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annual Eugenics, .7, 179–188. doi:10.1111/j.1469-1809.1936.tb02137.x
- Forina, M.,Leardi, R., Armanino, C. & Lanteri, S. (1998). PARVUS, An extendible package for data exploration, classification and correlation. Via Brigata Salerno, 16147 Genoa, Italy: Institute of pharmaceutical and food analysis and technologies.
- Frigui, H., & Krishnapuram, R. (1999). A robust competitive clustering algorithm with applications in computer vision. IEEE Transactions Pattern Analysis Mach Intelligent, 21, 450–465. doi:10.1109/34.765656
- Gribkova, S. (2015). Vector quantization d clustering in the presence of censoring. Multivariate Analysis, 140, 220–233. doi:10.1016/j.jmva.2015.05.015
- Han, J., & Kamber, M. (2001). Data mining: Concepts and techniques. Murgan Kufmann.
- He, Y., Pan, W., & Lin, J. (2006). Cluster analysis using multivariate normal mixture models to detect differential gene expression with microarray data. Computer Statistical Data Analysis, 51, 641–658. doi:10.1016/j.csda.2006.02.012
- Horng, M. F., Dao, T. K., Shieh, C. S., & Nguyen, T. T. (2017). A multi-objective optimal vehicle fuel consumption based on whale optimization algorithm. Smart Innovation Systems and Technologies, 64, 371–380.
- Jain, A., & Dubes, R. (1998). Algorithms for clustering data. Englewood Cliffs, NJ: Prentice-Hall.
- Karaboga, D., & Ozturk, C. (2011). A novel clustering approach: Artificial bee colony (ABC) algorithm. Applications Soft Computation, 11(1), 652–657. doi:10.1016/j.asoc.2009.12.025
- Karthikeyan, S., & Christopher, T. (2014). A hybrid clustering approach using artificial bee colony (ABC) and particle swarm optimization. International Computation Applications, 100, 15.
- Kenedy, J., & Eberhart, R. (1995). Particle swarm optimization. In: Proceeding of the 1995 IEEE international conference on neural network, 194–208.
- Leung, Y., Zhang, J., & Xu, Z. (2000). Clustering by scale-space filtering. IEEE Transactions Pattern Analysis Mach Intelligent, 22, 1396–1410. doi:10.1109/34.895974
- Lillesand, T., & Keifer, R. (1994). Remote sensing and image interpretation. New York, NY: John Wiley & Sons.
- MacQueen, J. (1967). Some method for classification and analysis of multivariate observations. In: Proceeding of the fifth Berkeley symposium on mathematical statistics and probability, 1, 281–297.
- Maulik, U., & Mukhopadhyay, A. (2010). Simulated annealing based automatic fuzzy clustering combined with ANN classification for analyzing micro-array data. Computation Operational Researcher, 37, 1369–1380. doi:10.1016/j.cor.2009.02.025
- Mirjalili, S., & Lewi, A. (2016). The whale optimization algorithm. Advancement Engineering Softwares, 95, 51–67. doi:10.1016/j.advengsoft.2016.01.008
- Mirjalili, S., Mirjalili, S. M., & Lewis, A. (2014). Grey wolf optimizer. Advancement Engineering Software, 69, 46–61. doi:10.1016/j.advengsoft.2013.12.007
- Mualik, U., & Bandyopadhyay, S. (2000). Genetic algorithm-based clustering technique. Pattern Recognition, 33, 1455–1465. doi:10.1016/S0031-3203(99)00137-5
- Rashedi, E., Nezamabadi- Pour, H., & Saryazdi, S. (2009). GSA: A gravitational search algoritm. Information Sciences, 179, 2232–2248. doi:10.1016/j.ins.2009.03.004
- Sandeep, U. M., & Pankaj, G. G. (2014). Hybrid particle swarm optimization (HPSO) for data clustering. International Computation Applications, 97(19), 1–5.
- Sander, J. (2003). Coursteme homepage for principles of knowledge discovery in data. Retrieved from: http://www.cs.ualberta.ca/-joerg.
- Sarkar, M., Yegnanafayana, B., & Khemani, D. (1997). A clustering algorithm using an evolutionary programming-based approach. Pattern Recognition, 975–986. doi:10.1016/S0167-8655(97)00122-0
- Selim, S. Z., & Al-Sultan, K. (1991). A simulated annealing algorithm for the clustering problem. Pattern Recognition, 24(10), 1003–1008. doi:10.1016/0031-3203(91)90097-O
- Sharma, S., & Buddhirju, K. M. (2018). Spatial-spectral ant colony optimization for hyperspectralimage classification. International Journal of Remote Sensing, 39(9), 2702–2717. doi:10.1080/01431161.2018.1430403
- Shelokar, P. S., Jayaraman, V. K., & Kulkarni, B. D. (2004). An ant colony approach for clustering. Analytica Chimica Acta, 509, 187–195. doi:10.1016/j.aca.2003.12.032
- Storn, R., & Price, K. (1997). Differential evolution- a simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization, 11, 341–359. doi:10.1023/A:1008202821328
- Tunchan, C. (2012). A particle swarm optimization approach to clustering. Experiments System Applications, 39, 1582–1588.
- Van Der Merve, D. W., & Engelhrecht, A. P. (2003). Data clustering using particle swarm optimization. Conference of evolutionary computation CEC03, 215–220.
- Welch, J. W. (1982). Algorithmic complexity - 3 NP-Hard problems in computational statistics. Journal Statistical Computation Sim, 15, 17–25. doi:10.1080/00949658208810560
- Yao, X., & Liu, Y. (1999). Evolutionary programing made faster. IEEE Transactions Evolution Computer, 3, 82–102. doi:10.1109/4235.771163
- Zhang, C., Ouyang, D., & Ning, J. (2010). An artificial bee colony approach for clustering. Experiments System Applications, 37, 4761–4767. doi:10.1016/j.eswa.2009.11.003