
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the presence of heteroscedasticity, the ordinary least-squares (OLS) estimator remains no more efficient while the popular Almon technique is being considered for a finite distributed lag model (DLM). The available literature proposes few adaptive estimators which are more efficient than the OLS estimator when there is heteroscedasticity of unknown form. This study suggests the similar adaptation combined with the Almon technique in order to get more efficient estimator of vector of lag coefficients in the DLM. Performance of the proposed estimator has been evaluated through the Monte Carlo simulations. The simulation results show an attractive performance of the proposed estimator in terms of efficiency.
PUBLIC INTEREST STATEMENT
A distributed lag model (DLM) is a model for a sort of time series data in which a regression equation is used to predict current values of a dependent variable based on both the current values of an explanatory variable and the past period (lagged) values of this explanatory variable. Precisely, a DLM is a dynamic model in which the effect of a regressor on regressand occurs over time rather than all at once. The non-constant variances of the error term (i.e., issue of heteroscedasticity), associated with such model, may result in inefficient estimation of the unknown coefficients of the stated DLM. This paper addresses the same issue and suggests some more efficient estimation method.
1. Introduction
The distributed lag model (DLM) includes lagged values of independent variables as explanatory variables. The use of such model is motivated by the fact that the effect of change in an independent variable is not always completely exhausted within one time period but is “distributed” over several, and perhaps many, future periods. The DLM has gained paramount importance because of its frequent use in econometrics and statistics. However, estimation of the DLM has remained core issue for many researchers because of two problems that are almost certain to arise when the ordinary least-squares (OLS) method is applied directly to this model. Firstly, if the number of lags is large enough but the sample size is small, it may not be possible to infer about the parameters because of inadequate degrees of freedom to carry out the traditional tests of significance. Secondly, in most of the economic time series, the successive (lag) values tend to be highly correlated causing the problem of multicollinearity which leads to imprecise estimation of parameters because the variances of estimates tend to be large due to multicollinearity among explanatory variables (Baltagi, Citation2011; Gujarati, Citation2003; Maddala, Citation1977). To overcome these problems, various methods have been proposed by different researchers (Almon, Citation1965; Koyck, Citation1954; Shiller, Citation1973) for estimation of the DLM. All these methods are based on some prior knowledge about the behaviour of parameters and this source of prior knowledge includes non-stochastic and stochastic smoothness priors (Gujarati, Citation2003; Vinod & Ullah, Citation1981). Among the available methods proposed for estimation of the DLM, a technique of polynomial distributed lag (PDL) proposed by Almon (Citation1965) has gained much popularity. In Almon’s technique, the DLM is transformed into a model which has fewer explanatory variables and thus, severity of collinearity reduces considerably. This technique not only reduces the effect of multicollinearity but it also reduces the number of parameters to be estimated in the DLM (Maddala, Citation1977). The Almon procedure is based on the assumption that parameters in the DLM lie on some polynomial of suitable degree.
Application of the OLS, combined with the Almon technique, requires that the DLM meets all the assumptions about the error term which are considered for a classical linear regression model. The assumption of homoscedasticity is considered as one of the important assumptions which states that the error variances are constant across all the observations. But in practice, this assumption is frequently violated and the random errors in such case are said to be heteroscedastic. In the presence of heteroscedasticity, the usual OLS estimator (OLSE) remains unbiased, consistent and asymptotically normal but becomes inefficient and its usual covariance matrix estimator becomes biased and inconsistent.
If the form of heteroscedasticity is known, the method of weighted least-squares (WLS) is the best choice to get efficient estimates of parameters but the form of heteroscedasticity is seldom known. In such situation, the estimated weighted least-squares (EWLS) estimator can be used which can provide more efficient estimates than the OLSE (Fuller & Rao, Citation1978; Pasha, Citation1982). Besides this, some adaptive estimators have been proposed which are more efficient than the OLSE (Carroll, Citation1982; Carroll & Ruppert, Citation1982; Robinson, Citation1987). A vast literature (Ahmed, Aslam, & Pasha, Citation2011; Aslam, Citation2006, Citation2014; Aslam, Riaz, & Altaf, Citation2013) is available to justify the use of such adaptive estimators as a substitute of the OLSE in the presence of heteroscedasticity of unknown form. However, estimation of DLM by the Almon technique in presence of heteroscedastic errors has not grabbed the attention of researchers. This paper addresses this issue and proposes the use of adaptive estimator combined with the Almon technique as a replacement of the OLSE for efficient estimation of the DLM in the presence of heteroscedasticity of unknown form.
This paper is organized as follows. Section 2 describes the DLM with heteroscedastic errors and the adaptive estimation. Section 3 briefly describes the Monte Carlo scheme and data generating process along with the results. Section 4 concludes the paper.
2. The distributed lag model and adaptive estimation
The general form of a finite DLM is
In matrix notation, the model in Equation (1) can be written as follows:
where
Clearly, is a
vector of observations on response variable,
is a
vector of unknown lag coefficients or lag weights,
is a vector of random error with mean zero and variance
with tth diagonal elements
i.e.,
. When the error term is homoscedastic,
and
, where I(T-s) is an identity matrix of order
.
Direct application of the OLS to estimate DLM given in Equation (1) may have some serious problems as discussed earlier. For estimation of the DLM, Almon (Citation1965) proposed a technique which is widely used by the practitioners. Almon assumed that the coefficients could be well approximated by a polynomial of degree r in i which was less than s (the lag length) i.e.,
Substituting Equation (3) in Equation (1), one can estimate by the usual OLS procedure and then using Equation (3), one can get the estimates of
. In matrix notations, Equation (3) can be written as
where is as mentioned before and
are matrix and
vector, respectively. By substituting Equation (4) in Equation (2), one can obtain
Here, The OLS estimator of
is as follows:
The parameter vector β can be estimated as follows:
which is the Almon estimator of . If the error term is homoscedastic, it is the best linear unbiased estimator (BLUE) of
(Judge, Griffiths, Hill, Lütkepohl, & Lee, Citation1980). A major advantage of the Almon technique is that if a distributed lag is assumed to lie on a polynomial of a specified degree then the distributed lag can be estimated by standard linear regression methods (Fair & Jaffee, Citation1971). Moreover, the Almon technique reduces the effect of multicollinearity (Fair & Jaffee, Citation1971; Judge et al., Citation1980; Maddala, Citation1977) because there are fewer explanatory variables in the transformed model as compared to the actual DLM.
In the presence of heteroscedasticity, does not remain efficient and consequently
also becomes inefficient. Thus, some efficient estimator of
is desired which will further give an efficient estimator of
. The WLS estimator is one possible solution to estimate model (5) efficiently if
are known. Let
be the diagonal matrix of weights whose tth diagonal element
then the WLS estimator is
However, in practical situations, are usually not known and their estimates are used. The resulting EWLS estimator of the parametric vector
is
where is a nonsingular diagonal matrix containing estimated weights used for variance-stabilizing transformation.
Now the concern is to construct and for this purpose, an adaptive estimator proposed by Carroll (Citation1982) can be used. Carroll (Citation1982) assumed the error variance to be a smooth function of the mean values as:
where is unknown and
The estimate of
, in context of model (5), is given as follows:
Carroll (Citation1982) presented the kernel estimator of in the form of Nadaraya-Watson (Nadaraya, Citation1964; Watson, Citation1964) estimator as
where is the kernel function with smoothing parameter
and
are the OLS residuals of model (5).
Thus we have , where
and the adaptive weighted least-squares (AWLS) estimator of
can be defined as follows:
Carroll (Citation1982) proved that has the same asymptotic properties as that of the WLS estimator (i.e.,
), based on the true weights. It has a normal limiting distribution with mean
and covariance
. Furthermore, such adaptive estimator is more efficient than the OLSE in the presence of heteroscedasticity of unknown form (for more details, see Carroll [10, p. 1226–1227]).
The use of such efficient estimator combined with the Almon technique may increase the efficiency of the Almon estimator when a DLM is plagued with the heteroscedasticity of unknown form. Therefore, an efficient estimator of parameter vector based on adaptive estimator
can be given as follows:
3. Numerical evaluation
Following Frost (Citation1975) and Güler, Gültay, and Kaçiranlar (Citation2017), we used the following model to generate observations:
where and
are independent normal variates with mean 0 and standard deviation 1. Stated differently
is normally distributed with mean 0 and standard deviation
. Following the work of Alkhamisi, Khalaf, and Shukur (Citation2006), Månsson, Shukur, and Kibria (Citation2010) and Aslam (Citation2014), two other probability distributions for the error term are used which are Student’s t(6) and F(4,16). Following Frost (Citation1975), the lag length s = 10 and the degree of polynomial r = 3 are used and the values of
to
are set to be 0.630, 1.224, 1.560, 1.680, 1.626, 1.440, 1.164, 0.840, 0.510, 0.216 and 0.000, respectively.
The variate is independent normal with mean 0 and standard deviation 1. For each replication, the data are generated by drawing values of
for
and
for
. The values of
are generated using Equation (7a) and (7b) and the values of
are generated by Equation (6). Each replication allows for regression with T = 30 observations (t = 11 to 40) to be run with lags up to 10 periods. The observations of
(T = 30) thus generated are kept fixed in the simulation study. However, these observations are replicated twice, thrice and so on to get large samples with T = 60, 120 and 240 observations, respectively. This replication was done so that the degree of heteroscedasticity be retained the same for all sample sizes (see Aslam Citation2014; Cribari-Neto Citation2004 for such replications to get large samples).
The expected correlation between successive values of is indicated by λ. Following Güler et al. (Citation2017), we used five different values for λ as 0.5, 0.8, 0.9, 0.95, and 0.99. It is expected that the degree of multicollinearity increases as λ increases and this setup leads us to investigate behavior of the estimators with the increasing degree of multicollinearity.
The values of are generated at the beginning of the simulations and kept fixed while the values of
are repeated through the replications. After constructing the matrix X, Z is obtained by Z = XA.
Following Cribari-Neto and da Silva (Citation2011) and Aslam (Citation2014), the variance of error term is generated as follows:
Here, The degree of heteroscedasticity is measured by
The degree of heteroscedasticity is a useful measure to represent strength of heteroscedasticity from mild to severe. For each, the value of
is chosen in such a way that
4, 36 and 100 in order to represent mild, moderate and severe heteroscedasticity, respectively. Obviously, for
,
indicates the homoscedasticity in error terms.
Following Ahmad et al. (Citation2011) and Aslam et al. (Citation2013), we used the normal kernel in our study for the estimation of error variances and it has been cited in Roy (Citation2002) that in the nonparametric literature, the choice of the kernel function is not crucial as long as it satisfies certain regulatory conditions and the sample size is not small (see also (Delgado, Citation1992)). The normal kernel is
According to Silverman (Citation1998), the optimal choice for the smoothing parameter h in case of normal kernel is for c = 1.06 with
as the sample standard deviation of the regressor x. The number of Monte Carlo Simulations is set to be 5000. All the computations are performed through programming routines, developed in the R language (R 3.2.4).
To evaluate the performance of the conventional OLSE and our proposed AWLSE when the DLM is plagued with the problem of heteroscedasticity of unknown form, we use mean squared error (MSE) criterion and focus on the estimator which yields lower MSE. A colossal literature (Alheety and Kibria, Citation2009; Ahmed et al., Citation2011; Aslam, Citation2014; Aslam et al., Citation2013; Gibbons, Citation1981; Kibria, Citation2003; Lawless & Wang, Citation1976; Özbay & Kaçıranlar, Citation2017; Özbay, Kaçıranlar, & Dawoud, Citation2017) is available to justify the use of MSE to evaluate the performance of estimators.
For any particular estimator of
, the MSE is given by
However, for evaluation purpose, the estimated MSE for any estimator of
can be given by
where M is the number of repetitions in a simulation and is the estimated value of β in ith repetition. The relative efficiency of the AWLSE with respect to OLSE is given as follows:
The simulated EMSE results for the OLSE and AWLSE are presented in Figures and when the probability distribution of the error term is N(0,1). Figure shows the EMSE along with sample size for the case when λ = 0.50. In Figure , (a), (b), (c) and (d) are used for the case of homoscedasticity, mild, moderate and severe heteroscedasticity, respectively. Figure indicates that the EMSE of OLSE and AWLSE remains almost identical for all sample sizes when the error term is homoscedastic (δ = 1). For the case of mild heteroscedasticity (δ = 4), the EMSE of AWLS remains slightly lower than that of the OLSE. However, the EMSE of both estimators tends to increase with the increase in degree of heteroscedasticity. For the case of moderate and severe heteroscedasticity (i.e., δ = 36 and 100), we note that EMSE of the AWLSE remains smaller than that of the OLSE for all sample sizes which indicates the superiority of the AWLSE on OLSE in terms of efficiency. Furthermore, the EMSE of both estimators decreases considerably with the increase in sample size. Almost the similar behaviour of estimators is observed for other collinearity levels.
Figure 1. EMSE comparison of OLS and AWLS estimators when λ = 0.50.
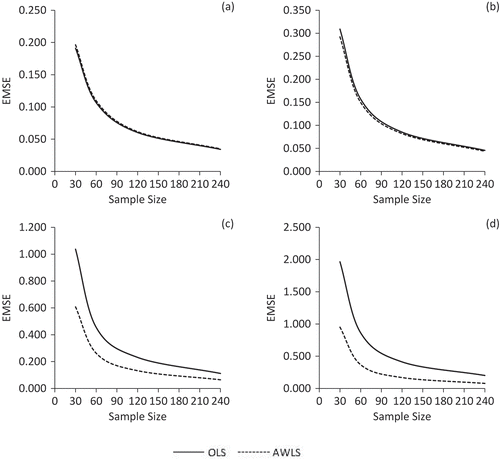
Figure 2. EMSE comparison of OLS and AWLS estimators for the case of severe heteroscedasticity (δ = 100).
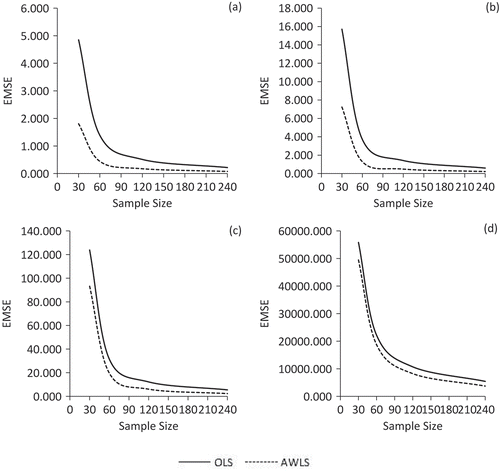
The results for the case of severe heteroscedasticity are presented in Figure for discussion purpose. In Figure , (a), (b), (c) and (d) are used for λ = 0.80, 0.90, 0.95 and 0.99, respectively. A dramatic increase in the EMSE of both estimators is observed with the increase in collinearity level. However, the AWLSE yields lower EMSE for all collinearity levels. Moreover, the difference in the EMSE of both estimators reduces with the increase in collinearity levels.
Tables and present the EMSE of OLSE and AWLSE when the probability distribution of error term is t(6) and F(4, 16). Almost similar performance of the AWLSE can be observed as it exhibits in case of normal errors, when the probability distribution of error term is t(6) and F(4, 16). Efficiency of the AWLSE improves further when the error term is not only heteroscedastic but it is also non-normal, especially when the probability distribution of error term is standardized F(4, 16). For example, when T = 30 and λ = 0.50, the gain in efficiency when using the AWLSE is 70.78%, 74.29% and 103.18 for the errors distributed as N(0, 1), t(6) and F(4, 16), respectively, if the heteroscedasticity is mild (δ = 36) while the corresponding figures about gain in efficiency are 106.75%, 110.60% and 161.12% for severe heteroscedasticity (δ = 100). This shows that the AWLSE gives better performance not only in case of normal error distribution but also in case of non-normal error distribution.
Table 1. Estimated MSE when the distribution of error term is t (6)
Table 2. Estimated MSE when the distribution of error term is F (4, 16)
Moreover, it is observed that the level of collinearity and the degree of heteroscedasticity has a negative effect on the EMSE of both estimators (the OLSE and AWLSE). The EMSE of both estimators tends to increase with the increase in level of collinearity and degree of heteroscedasticity. On the other hand, the stated EMSE decreases as the sample size grows. The probability distribution of errors has almost similar effect on the EMSE of both estimators but the gain in efficiency of the AWLSE is the largest when the errors are F(4, 16).
4. Conclusion
This study is focused to estimate the DLM plagued with the heteroscedasticity of unknown form. One of the most popular technique, which is used for estimating the parameters of the DLM, is proposed by Almon (Citation1965). In Almon technique, the DLM is transformed under the assumption that lag coefficients lie on a polynomial of some suitable degree and then the OLS is applied on the transformed model. If the error term is homoscedastic, there is no hindrance in applying the OLS to the transformed model but in presence of heteroscedastic errors, the OLSE for the transformed model may become seriously inefficient. Based on the work of Carroll (Citation1982) we have proposed an adaptive estimator combined with the Almon technique, which is more efficient as compared to the conventional Almon estimator, which is based on the OLS. A Monte Carlo experiment is conducted and the AWLSE is compared with the conventional OLSE for the Almon technique, using the MSE criterion. The estimators are evaluated by varying degree of heteroscedasticity, degree of collinearity, sample size and probability distribution for the error term. The simulation results reveal that the proposed estimator (AWLSE) is an attractive choice for being more efficient over the conventional Almon OLSE in the presence of heteroscedasticity of unknown form.
Additional information
Funding
Notes on contributors
Muhammad Aslam
Muhammad Aslam is a tenured associate professor at the Department of Statistics, Bahauddin Zakariya University, Multan, Pakistan. He acquires a teaching experience of more than 20 years at postgraduate level. His main area of interest revolves around the inference of linear regression models, including the distributed lag model (DLM) and panel data model (PDM), with issues of heteroscedasticity and multicollinearity. He has conducted a number of researches in the stated area while leading a research team, comprising of his research students and few colleagues. Recently, this team has developed three R packages, namely “mctest,” “lmridge,” and “liureg” which are available on the R CRAN. These are comprehensive packages for detection of multicollinearity, estimation of the ridge and Liu regression models with different choices of penalties. This paper is a part of PhD research project of Mr. Abdul Majid (the Principal author) under the supervision of Dr. Aslam. This paper also suggests some efficient estimation the DLM in the presence of heteroscedasticity.
References
- Ahmed, M., Aslam, M., & Pasha, G. R. (2011). Inference under heteroscedasticity of unknown form using an adaptive estimator. Communication in Statistics-Theory and Methods, 40(24), 4431–4457. doi:10.1080/03610926.2010.513793
- Alheety, M. I., & Kibria, B. M. G. (2009). On the Liu and almost unbiased Liu estimators in the presence of multicollinearity with heteroscedastic or correlated errors. Surveys in Mathematics and Its Applications, 4, 155–167.
- Alkhamisi, M., Khalaf, G., & Shukur, G. (2006). Some modifications for choosing ridge parameters. Communication in Statistics-Theory and Methods, 35(11), 2005–2020. doi:10.1080/03610920600762905
- Almon, S. (1965). The distributed lag between capital appropriations and expenditures. Econometrica : Journal of the Econometric Society, 33(1), 178–196. doi:10.2307/1911894
- Aslam, M. Adaptive procedures for estimation of linear regression models with known and unknown heteroscedastic errors (Ph.D. thesis), Bahauddin Zakariya University, Multan, Pakistan, 2006.
- Aslam, M. (2014). Performance of Kibria’s method for the heteroscedastic ridge regression model: Some monte carlo evidence. Communication in Statistics-Simulation and Computation, 43(4), 673–686. doi:10.1080/03610918.2012.712185
- Aslam, M., Riaz, T., & Altaf, S. (2013). Efficient estimation and robust inference of linear regression models in the presence of heteroscedastic errors and high leverage points. Communications in Statistics - Simulation and Computation, 42(10), 2223–2238. doi:10.1080/03610918.2012.695847
- Baltagi, B. H. (2011). Econometrics (5th ed.). Berlin: Springer.
- Carroll, R. J. (1982). Adapting for heteroscedasticity in linear models. Annals of Statistics, 10(4), 1224–1233. doi:10.1214/aos/1176345987
- Carroll, R. J., & Ruppert, D. (1982). Robust estimations in heteroscedastic of linear models. Annals of Statistics, 10(2), 429–441. doi:10.1214/aos/1176345784
- Cribari-Neto, F. (2004). Asymptotic inference under heteroscedasticity of unknown form. Computational Statistics & Data Analysis, 45(2), 215–233. doi:10.1016/S0167-9473(02)00366-3
- Cribari-Neto, F., & Da Silva, W. B. (2011). A new heteroskedasticity-consistent covariance matrix estimator for the linear regression model. AStA Advances in Statistical Analysis, 95(2), 129–146. doi:10.1007/s10182-010-0141-2
- Delgado, M. A. (1992). Semiparametric generalized least squares estimation in the multivariate nonlinear regression model. Econometric Theory, 8, 203–222. doi:10.1017/S0266466600012767
- Fair, C. R., & Jaffee, M. D. (1971). A note on the estimation of polynomial distributed lags. Econometric research program research memorandum. (No:120). University of California, Berkeley School of Law.
- Frost, P. A. (1975). Some properties of the Almon lag technique when one searches for degree of polynomial and lag. Journal of the American Statistical Association, 70(351), 606–612.
- Fuller, W. A., & Rao, J. N. K. (1978). Estimation for a linear regression model with unknown diagonal covariance matrix. Annals of Statistics, 6(5), 1149–1158. doi:10.1214/aos/1176344317
- Gibbons, D. G. (1981). A simulation study of some ridge estimators. Journal of American Statistical Association, 76(373), 131–139. doi:10.1080/01621459.1981.10477619
- Gujarati, D. N. (2003). Basic Econometrics (4th ed.). New York: McGraw-Hill.
- Güler, H., Gültay, B., & Kaçiranlar, S. (2017). Comparisons of the alternative biased estimators for the distributed lag models. Communication in Statistics-Simulation and Computation, 46(4), 3306–3318. doi:10.1080/03610918.2015.1053919
- Judge, G. G., Griffiths, W. E., Hill, R. C., Lütkepohl, H., & Lee, T. C. (1980). The theory and practice of econometrics. New York, NY: Wiley Publication.
- Kibria, B. M. G. (2003). Performance of some new ridge regression estimators. Communications in Statistics - Simulation and Computation, 32(2), 419–435. doi:10.1081/SAC-120017499
- Koyck, L. M. (1954). Distributed lags and investment analysis. Amsterdam: North Holland Publishing Company.
- Lawless, J. F., & Wang, P. (1976). A simulation study of ridge and other regression estimators. Communications in Statistics A, 5(4), 307–323. doi:10.1080/03610927608827353
- Maddala, G. S. (1977). Econometrics. New York: McGraw-Hill.
- Månsson, K., Shukur, G., & Kibria, B. M. G. (2010). A simulation study of some ridge regression estimators under different distributional assumptions. Communication in Statistics-Simulation and Computation, 39(8), 1639–1670. doi:10.1080/03610918.2010.508862
- Nadaraya, E. A. (1964). On estimating regression. Theory Probability and Its Applications, 9(1), 141–142. doi:10.1137/1109020
- Özbay, N., & Kaçıranlar, S. (2017). The Almon two parameter estimator for the distributed lag models. Journal of Statistical Computation and Simulation, 87(4), 834–843. doi:10.1080/00949655.2016.1229317
- Özbay, N., Kaçıranlar, S., & Dawoud, I. (2017). The feasible generalized restricted ridge regression estimator. Journal of Statistical Computation and Simulation, 87(4), 753–765. doi:10.1080/00949655.2016.1224880
- Pasha, G. R. Estimation methods for regression models with unequal error variances (Ph.D. thesis), University of Warwick, Coventry, Warwick, U.K, 1982.
- Robinson, P. M. (1987). Asymptotically efficient estimation in the presence of heteroscedasticity of unknown form. Econometrica : Journal of the Econometric Society, 55(4), 875–891. doi:10.2307/1911033
- Roy, N. (2002). Is adaptive estimation useful for panel models with heteroskedasticity in the individual specific error component? Some Monte Carlo evidence. Econometric Reviews, 21, 189–203. doi:10.1081/ETC-120014348
- Shiller, R. J. (1973). A distributed lag estimator derived from smoothness priors. Econometrica : Journal of the Econometric Society, 41(4), 775–788. doi:10.2307/1914096
- Silverman, B. W. (1998). Density estimation for statistics and data analysis. London: Chapman & Hall/CRC.
- Vinod, H. D., & Ullah, A. (1981). Recent advances in regression methods. New York: Marcel Dekker.
- Watson, G. S. (1964). Smooth regression analysis. Sankhya A, 26(4), 359–372.