
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Multiple imputation (MI) has become the most popular approach in handling missing data. Closely associated with MI, the fraction of missing information (FMI) is an important parameter for diagnosing the impact of missing data. Currently γm, the sample value of FMI estimated from MI of a limited m, is used as the estimate of γ0, the population value of FMI, where m is the number of imputations of the MI. This FMI estimation method, however, has never been adequately justified and evaluated. In this paper, we quantitatively demonstrated that E(γm) decreases with the increase of m so that E(γm) > γ0 for any finite m. As a result γm would inevitably overestimate γ0. Three improved FMI estimation methods were proposed. The major conclusions were substantiated by the results of the MI trials using the data of the 2012 Physician Workflow Mail Survey of the National Ambulatory Medical Care Survey, USA.
PUBLIC INTEREST STATEMENT
In any big surveys such as the National Ambulatory Medical Care Survey, USA, you select people into your sample and ask them to answer your questions. Some will answer, and others will not answer. When you finally get your survey data, it is inevitable that you will have missing data due to those non-respondents. How to minimize the effects of the missing data on your survey has been a big topic in statistics. Multiple imputation (MI) has become the most popular approach in handling missing data. Closely associated with MI, the fraction of missing information (FMI) is an important parameter for diagnosing the impact of missing data. This paper shows that the current method for estimating FMI bears intolerable biases. We proposed three improved methods that would give more accurate estimate of FMI.
1. Introduction
Multiple imputation (MI) becomes the most popular approach to accounting for missing data (Carpenter & Kenward, Citation2013, Dohoo, Citation2015, Rezvan, Lee, & Simpson, Citation2015, Rubin, Citation1987, Van Buuren, Citation2012). Closely associated with MI, fraction of missing information (FMI) is an important parameter for diagnosing the effects of data missingness (Rubin, Citation1987). FMI can be interpreted as the fraction of information about Q due to non-response, where Q is the quantity of interest (Rubin, Citation1987). As MI become increasingly important, the importance of FMI is also increasing. The best known use of FMI is to define the relative efficiency (RE) of MI as RE = (1 + γ0/m)−1/2, where γ0 is the population value of FMI and m is the number of imputations (Rubin, Citation1987). Based on this RE, Rubin concluded that m ≤ 5 would be sufficient for MI (Rubin, Citation1987). Little et al. as well as Wagner suggested that FMI be used as an alternative tool for measuring data missing data or the response rate (Little et al., Citation2016, Wagner, Citation2010). Siddique, Harel, Crespic, and Hedekerd (Citation2014) used FMI to verify the missing data mechanisms. The most common practice of FMI estimation is to use γ̂0 = γm, where γ̂0 is the estimated value of γ0 and γm is the FMI obtained from MI of a given m, e.g. (Khare, Little, Rubin, & Schafer, Citation1993, Lewis et al., Citation2014, Schafer, Citation2001, Schenker et al., Citation2006). However, the accuracy of the γ̂0 = γm method has not been adequately evaluated. This paper is to quantify possible biases of γ̂0 = γm and to improve FMI estimation methodology if necessary and possible.
Established by Rubin in Citation1987, the current FMI paradigm is defined by Equations (1)–(11) below:
where subscript m and ∞ stands for a finite and infinite m, the subscript 0 for the population value, the subscript i for the ith imputation, and the bar hat for the parameter’s mean.
where B, U, and T are the between-imputation, within-imputation, and the total variances.
where is the fractional variance increase due to data missingness.
where is the degrees of freedom.
Equation (11) cannot be used to calculate γ0 in practice because B0, U0, and T0 are usually unknown. No researchers have provided an equation that explicitly links γm and γ0. The justification for using γ̂0 = γm is not available from Equations (1)–(11).
Assume γ∞ = γ0. For γ̂0 = γm to be valid, E(γm) = γ0 must be true. For E(γm) = γ0 to be true, E(γm) must be independent of m. To understand E(γm), let the same MI of a given m be repeated for j times. Denote the γm from each MI repeat as γm1, γm2, γm3, …, γmj. By definition, the expected value is the sum of all possible values each multiplied by the probability of its occurrence (Hogg, McKean, & Craig, Citation2013). Therefore, E(γm) can be defined as:
Equation (12) shows that E(γm) can be understood as the ultimate mean of γm when j becomes infinity. If E(γm) is independent of m, we should have E(γ2) = E(γ3) = … = E(γm) = γ0, and the use of = γm would be justified. If E(γm) depends on m, we should have E(γ2) ≠ E(γ3) ≠ … ≠ E(γm) ≠ γ0. The use of γ̂0 = γm may not be justified if the difference between E(γm) and γ0 is intolerably big.
Rubin indicated that the mean of γm can be regarded as γ0 [1 page 143], underlining an assumption that E(γm) is independent of m. Harel briefly mentioned that γm “tends to decrease as m increases” without providing any details (Harel, Citation2007). Although Harel’s statement favours E(γm) ≠ γ0, it cannot be a base for disproving γ̂0 = γm because it might be acceptable to use γ̂0 = γm if the decrease of γm with the increase of m is statistically negligible. To date the justifications for using γ̂0 = γm is still missing.
For FMI estimation, Harel’s 2007 paper (Harel, Citation2007) is important in that it pointed out that, unlike γm that “tends to decrease as m increases,” the quantity Bm/(Um + Bm) “does not tend to decrease as m increases” (Harel, Citation2007). Harel used γ̂0 = Bm/(Um + Bm) to estimate FMI in his research (Harel, Citation2007). The goal of Harel’s paper was not to find a better FMI estimation method per se and his discussion on γ̂0 = Bm/(Um + Bm) was brief. Most researchers have not used Harel’s method for FMI estimation probably because most people may have treated Harel’s method as being research-specific rather than a method that may potentially be universally used for FMI estimation.
In this study, we examined the relationships between m, γm, γ∞, and γ0, quantified the decrease of γm with the increase of m, quantified the biases of γ̂0 = γm, and proposed improved methods for FMI estimation. Only univariate FMI definition will be examined in this paper even though multivariate FMI definition may exist. The major conclusions were substantiated by the MI trials using the data of the 2012 Physician Workflow Mail Survey (PWS) of the National Ambulatory Medical Care Survey (NAMCS). This paper focuses on MI approach only even though it may be possible to estimate FMI via a non-MI approach (Savalei & Rhemtulla, Citation2012, Zheng & Lo, Citation2008).
2. The relationships between m, γm, γ∞, and γ0
2.1. The condition for γ∞ = γ0
To use γm for estimating γ0, one must assume γ∞ = γ0. Most researchers simply treat γ∞ and γ0 as synonyms (e.g. He et al., Citation2016). But they are not. Imagine a population of imputations (POI) is generated by repeating the imputation of the same model on the same data for an infinite number of times. An MI is simply a sample of the POI with sample size m. The sample value and the population value of FMI for the POI are γm and γ∞, respectively. The population for γ0, however, is not POI but the population of the sampling units of the survey. A γ∞ is inseparably linked to an MI, but a γ0 can be independent of MI. The γ0 may be estimated by MI as well as other methods such as maximum likelihood (Savalei & Rhemtulla, Citation2012, Zheng & Lo, Citation2008). Using Equations (5)–(7), one can prove that the condition for γ∞ = γ0 is Bm/Um = B0/U0. When we use MI to estimate γ0, we have to assume γ∞ = γ0, which is probably why γ∞ and γ0 are often treated as synonyms in MI analyses. In this paper, we will assume γ∞ = γ0 because we use MI to estimate γ0.
2.2. Bm/Um is independent of m
Equation (7) that defines γm does not have m as a factor. Combining Equations (5), (6), and (7) gives an expanded definition of γm with m as one of the independent factors affecting γm:
Equation (13) shows that γm is a function of three factors, i.e. γm = F(m, Bm, Um). In Equation (13), Bm and Um always appear together as Bm/Um. Letting cm = Bm/Um, then γm becomes a function of two factors, i.e. γm = F(m, cm).
Whether cm is independent of m is important in understanding the m–γm relationship. If cm depends on m, the direct effects of m on γm would be confounded by the indirect effects of m on γm via m’s effects on cm, which in turn could be due to m’s effect on Bm, Um or both. If cm is independent of m, then the m–γm relationship would be greatly simplified.
In order to establish that cm is independent of m, we need to prove E(Bm/Um) = B0/U0. Equation (2) indicates that the relationship between m and Bm is that between the sample size n and the variance (s2) so that E(Bm) is independent of m, i.e. E(Bm) = B0 (Serfling, Citation1980). Equation (3) indicates that the relationship between m and Um is that between the sample size n and the sample mean x̅ so that E(Um) is independent of m, i.e. E(Um) = U0 (Hogg et al., Citation2013). Jensen’s Inequality (Hogg et al., Citation2013) determines that E(1/Um) ≥ 1/E(Um). Therefore E(Bm/Um) = E(Bm)E(1/Um) ≥ E(Bm)/E(Um) = B0/U0, or E(Bm/Um) ≥ B0/U0. Our simulation studies show that the maximum difference between E(Bm)/E(Um) and E(Bm/Um) is less than 0.1%, which is negligible in virtually any statistics work. We can safely regard E(Bm/Um) = B0/U0 as a fact for the purpose of studying the m–γm relationship. The cm’s independence of m is thus proved. The subscript m can be removed from cm. As a result, we can indeed letting cm = Bm/Um be a constant c in Equation (13) and make γm become a function of the single factor m, i.e. γm = F(m).
2.3. The γm = F(m,γ0) equation
When m goes infinite, γm becomes γ0. Our goal is to establish the mathematic relationship between γm and γ0 at a finite m, which is currently missing in published literatures. In the discussions above, we have showed that it is mathematically legitimate to letting cm be a constant c in studying the m–γm relationship because cm is independent of m. What is the best value to choose for c to obtain the most truthful m–γm relationship? The answer is: c = E(Bm/Um) = B0/U0. If and only if c = E(Bm/Um) = B0/U0, the m–γm relationship as determined by Equation (13) would reflect the true m–γm relationship. From Equations (10) and (11) we can obtain B0/U0 = γ0/(1 − γ0). Replacing Bm/Um in Equation (13) with γ0/(1 − γ0), we obtain an equation that directly links γm to γ0 as follows:
Establishment of equation is a significant step forward in understanding the relationship between m, γm, and γ0 because it links the three factors in the same equation for any m, finite or infinite.
For a given analysis of a given dataset, γ0 is a constant. When we repeat the same MI of a given m for j times, the γm value from each repeat of the MI will not change when the γm is determined by Equation (14). In other words, we will have γm1 = γm2 = γm3 = … γmj = E(γm) (see Equation (12)). In other words, the γm value obtained from Equation (14) will be E(γm). For different data and analyses, γ0 is a variable. Equation (14) shows that E(γm) is a function of the two factors, m and γ0, i.e. E(γm) = F(m, γ0).
3. The decrease of E(γm) with the increase of m
3.1. E(γm) > γ0 for any finite m
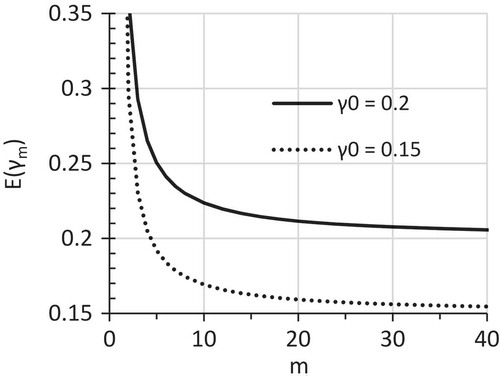
We all know that E(x̅) is independent of n and equals to μ, which provides the theoretical base for μ̂ = x̅ (Hogg et al., Citation2013). The use of γ̂0 = γm implies the assumption that E(γm) = γ0. Using Equation (14), the m–E(γm) relationship curve can be constructed for any given γ0. Figure presents the m–E(γm) relationship curves for γ0 = 0.15 and 0.2. Based on Figure , for the first time in MI research, we can explicitly state this important fact: E(γm) decreases with the increase of m. The decrease of E(γm) with the increase of m can be interpreted as follows: For a given dataset with a given MI model, the ultimate mean of γm, which is the mean of an infinite number of individual γm values obtained from repeating the MI of the given m for an infinite number of times, would always be greater than the γ0. Of course what is called “the ultimate mean” here is the E(γm) (Hogg et al., Citation2013). Therefore, by showing E(γm) decreases with the increase of m, we have proved that E(γm) > γ0 for any finite m (Figure ). The fact that E(γm) > γ0 is further illustrated by more data in Table for a wider range of m values and more γ0 values.
Table 1. Changes of E(γm), Dγ, and RDγ with the increase of m at different γ0 levels, where Dγ = 100(E(γm)−γ0)/γ0 and RDγ = 100(γm−γm+1)/γm+1
Figure 1. The m–E(γm) relationship curve at γ0 = 0.2 and 0.15 as determined by Equation (14).
3.2. The bias of the current FMI estimation method
The fact that E(γm) > γ0 dictates that the current FMI estimation method γ̑0 = γm must be biased. One achievement of this paper is that we successfully quantified the bias of the current FMI estimation method. We use Dγ, the percentage difference between E(γm) and γ0 as the parameter to measure this bias, i.e.:
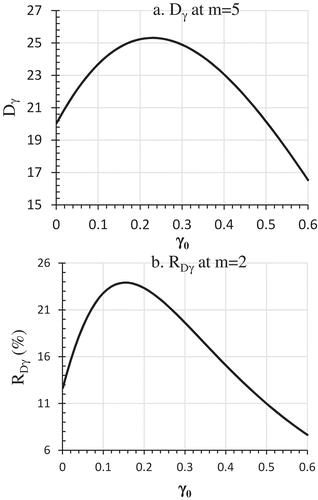
Table presents the Dγ values at different γ0 and m values as determined by Equation (14). At a given m, Dγ differs at different γ0 values (Table ). For m = 2, Dγ is 80.59% and 53.64% for γ0 = 0.2 and 0.01, respectively (Table ). When γ0 increased from 0.001 to 0.6, Dγ first increases with the increase of γ0, reaches a peak, and then decreases (Table and Figure ). The value of the γ0 at which Dγ reaches the peak differs with m (data not shown). For m = 5, the maximum Dγ value of 25.31% occurs at γ0 = 0.23, and the minimum Dγ value of 16.53% occurs at γ0 = 0.6 (Figure )). In other words, one could overestimate FMI by 25% at m = 5 if the current method is used. A bias of this magnitude cannot and should not be ignored. Development of a better FMI estimation method is indeed necessary.
Figure 2. Effects of γ0 levels on Dγ as defined by Equation (15) and RDγ as defined by Equation (16): a. Dγ at m = 5; b. Dγ at m = 2.
3.3. The γm decrease rate: smaller at larger m
We use Rγd, the percentage rate of the γm decrease per unit m, to measure the rate of the γm decrease:
RDγ is affected by both m and γ0 (Table and Figure , b1 and b2). At m = 5, RDγ is 3.87% and 2.96% for γ0 = 0.2 and 0.01, respectively (Table ). Figure ) show that RDγ increases initially, reaches a peak, and then decreases as γ0 increases from 0.001 to 0.6. For m = 2, the maximum RDγ = 23.91% occurs at γ0 = 0.15 (Figure )). For m = 5, the maximum RDγ = 3.88% occurs at γ0 = 0.21 (data not shown). The gradual reduction of RDγ makes it possible for choosing a sufficient m when the m-driven γm reduction becomes negligibly small.
4. Improved methods for γ0 estimation
Regarding γ̂0 = γm as the control, any method that gives more accurate FMI estimation than this control will be considered as an improved method. Three improved methods are proposed below.
4.1. Improved method 1: γ̂0 = γm≥100
The control method is to use γ̂0 = γm regardless the size of m. The first improved method is to choose a sufficiently large m when use γ̂0 = γm. Data in Figure show that E(γm) approaches γ0 as m gets larger. Therefore, γm would estimate γ0 with an adequate accuracy when m is sufficiently large. Various criteria have been used to determine the sufficient m (Bodner, Citation2008, Graham, Olchowski, & Gilreath, Citation2007, Hershberger & Fisher, Citation2003, Pan, Wei, Shimizu, & Jamoom, Citation2014, Royston, Citation2004, Rubin, Citation1987). An adequately accurate estimation of γ0 using γ̂0 = γm offers another criterion for determining a sufficient m. As measured by RDγ, the gain in reducing the bias from increasing a unit m becomes smaller at a greater m. Using Equation (14), we can prove the bias of the default method as measured by Dγ would be about 1% or less for any reasonable γ0 values when m is greater than 100. We arbitrarily choose a bias of ≤1% as an acceptable level and recommend m ≥100 as being sufficient for an adequately accurate estimation of γ0 using γ̂0 = γm. This method can be expressed as γ̂0 = γm≥100.
4.2. Improved method 2: γ̂0 = γm(m/(m + 1))
Calculating γm for different m and γ0 combinations using Equation (14), one will find the following approximation stands well for m ≥10:
From Equation (17), we obtain the following method of estimating γ0 from γm:
For those who may be interested, this method may be proven by resolving γ0 from Equation (14) using Taylor series expansion approximation. An advantage of this method is that one could use it to have a more accurate FMI estimation from the m and the γm information available in an earlier publication that uses a small m and γm to estimate FMI.
4.3. Improved method 3: γ̂0 = cm/(cm + 1), where cm = Bm/Um
In Section 2.2, we proved that E(Bm/Um) = B0/U0. In other words, Bm/Um is an unbiased estimation of B0/U0. As a result, Equation (19) below is a better γ0 estimation than γ̂0 = γm:
where cm = Bm/Um. Harel used this method to estimate γ0 for his study on two-stage MI (Harel, Citation2007). However, the justification for this method discussed here was not available in Harel’s paper or any other published literature (Harel, Citation2007).
5. Results from MI trials of PWS12
5.1. Methods
PWS was a supplemental survey of NAMCS, which collects data about the provision and use of ambulatory medical care services in the United States (Lau, McCaig, & Hing, Citation2016). The 2012 PWS data (PWS12) were used for the MI trial, which had 2,567 responded physicians in the sample. PWS data can be accessed via NCHS Research Data Center (RDS) program (https://www.cdc.gov/rdc/index.htm).
MI was conducted on three variables representing the physician’s practice size at different scales, namely SIZE100, SIZE20, and SIZE5. The three variables had the same missing data percentage of 29% due to item non-responses. The hot-deck imputation method (Andridge & Little, Citation2010) was used. The RDS-released PWS12 data, which had 3.6% of missing values for SIZE after some of the missing values in PWS12 were replaced by the corresponding non-missing values for the same physician from the 2011 PWS data, were used as the hot-deck donor. Two MI models denoted as MI-1 and MI-2 were used. MI-1 did not use any covariate in the imputation and the non-missing replacement values for the missing value were randomly chosen from entire donor dataset. MI-2 used PRIMEMM as the covariate in the imputation and the non-missing replacement values for the missing value were randomly chosen from the cell of the same PRIMEMM value in donor dataset. PRIMEMM was the physician’s primary employment type that was coded into nine categories for this research. The MIs had m = 3, 5, 10, 20, 30, 40, 60, 80, and 100, with each MI being repeated for 30 times. Excluding m, there were 12 treatment combinations (3 imputed variables × 2 imputation models × 2 analytic models). The hot-deck imputation method used in this study was similar to that used by the survey for creating the RDC-released PWS12 data. According to Rubin (Citation1987, equation 4.3.8), the hot-deck bias can be expressed as E(B) = B(n1/n), where n is the number of the units of the full sample and n1 is the number of the units with observed values. Since the n1/n ratio is independent of m, the percentage fraction of the hot-deck bias would be a fixed value as long as the n1/n ratio is fixed. Therefore the m–γm relationship obtained from the hot-deck-based MI trials should still be valid. One should be aware of the potential hot-deck bias when interpreting the results of this study.
The quantity of interest (Q) was the means of the SIZE100, SIZE20, and SIZE5. Two analytical models denoted as Anal-1 and Anal-2 were used. In Anal-1, Ui, the within-imputation variance of the ith complete dataset generated by the MI, was the total variance of SIZE100, SIZE20, or SIZE5 in the ith dataset. In Anal-2, Ui was the variance of the ith dataset after the variance due to the effect of PRIMEMM was removed. Analyses were based on un-weighted data. Results obtained in this study were for research purpose only.
Barnard and Rubin (Citation1999) suggested that, for making the statistical inferences in MI-involved analyses, instead of using the degrees of freedom () as defined by Equation (6), the adjusted degrees of freedom (DFa) as proposed by their paper should be used where the complete-data degrees of freedom is not sufficiently large. However in the γm definition, i.e. Equation (7),
does not function as the degrees of freedom per se but mealy as a mathematical value in the estimation of γm. We have found that replacing
in Equation (7) with DFa will result in an erroneous estimation of γm. Therefore we used
, instead of DFa, when used Equation (7) for the γm estimation in this study.
5.2. The γm decrease with the increase of m in the MI trials
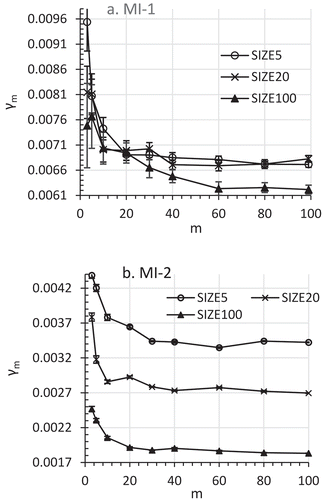
Would the γm decrease due to the increase of m (see Section 2.1 and 3.1) be big enough to stand out from sampling errors and other noises in real-world MI analyses? The answer is yes, as demonstrated by the data in Figure . Figure shows the effects of m on γm in SIZE100, SIZE20, and SIZE5 for the two MI models for Anal-2. In spite of the γm variations due to sampling errors as shown by the error bars in the graphs, the dominant trend was clear: γm decreased significantly as m increased from 3 to 100. The γm values at m = 3–40 were significantly greater than γ100 in most cases (Figure ). These results suggest that the γm decrease with the increase of m is not ignorable in FMI estimation in real world data analyses.
Figure 3. Effects of m on γm at δ = 29% for analytic model = Anal-2: a. MI model = MI-1; b. MI model = MI-2.
5.3. Variation of γm, Bm, and Um
In establishing the MI framework, Rubin (Citation1987) assumed that Um ≈ U0, which would be more likely to be true if the variance of Um is negligible. The authors did not find any information on the magnitude of Um variance in published literature. A detailed study on Bm variance was reported by Pan et al. (Pan et al., Citation2014). The variance of Bm was substantial when m < 30 (Pan et al., Citation2014). The variations in Bm and Um would inevitably lead to γm variation. As a result, when using γ̑0 = γm at an insufficient m, the inaccuracy of γ̑0 would not only come from E(γm) > γ0 but also from the variation of γm. The possible bias from sampling-error-driven γm variation has not been given an adequate attention.
The coefficient of variations (CV) of Bm, Um, and γm are presented in Table . Both the imputations models and the analytic models affected the variations of γm, Bm, and Um (Table ). CV of Um was much smaller—usually 1–10% that of Bm. The CV of Bm and γm were very similar, with the CV of γm being always slightly smaller than that of Bm. The greater the m, the smaller the variations of γm, Bm, and Um (Table ). These results were in agreement with Harel’s conclusion (Hogg et al., Citation2013) that it is necessary to choose a sufficient m for MI to control the variations of γm. Due to the significant effects of the MI model and the analytic model on the variations of γm, Bm, and Um (Table ), it may not be possible to propose a single m that fits all situations for controlling the variance of γm, Bm, and Um.
Table 2. Coefficient of variations (%) of Bm, Um, and γm for SIZE100
An advantage of using γ̂0 = γm≥100 is that not only can this method reduce the E(γm) > γ0 bias but also reduce γm variation because of a large m. The other two improved methods can effectively reduce or even eliminate the E(γm) > γ0 bias even if when m is small. However the γ̑0 inaccuracy may be a concern for any FMI estimation methods unless a sufficient m is chosen. Data in Figure suggest that a ≥20 m may be necessary to reduce the γm variation to an acceptable level for using γ̂0 = γm(m/(m + 1)) and γ̂0 = cm/(cm + 1).
5.4. Comparison of different FMI estimation methods
Table presents data for visualizing the performance of these three improved γ0 estimation methods described in Section 4 in comparison with the default method γ̂0 = γm in an example of real-world data analyses. The treatment combination of the MI trials was {SIZE20, MI-2, Anal-2}. The control values was the γm values at m = 3, 5, etc., which would be the FMI estimation when the default method was used. The γ100 value was used as the γ̑0 for the improved method γ̂0 = γm≥100. The best γ̂0 was calculated by Equation (19) using (B̅100)/(U̅100) as the estimate of B0/U0, where B̅100 and U̅100 were the mean of the 30 replicates of B100 and U100.
Table 3. Comparison of different γ0 estimation methods for SIZE20 with imputation model = MI-2 and analytic model = Anal-2 in the PWS12 MI trials. The best γ̂0 was calculated by Equation (19) using (B̅100)/(U̅100) as the estimate of B0/U0, where B̅100 and U̅100 were the mean of the 30 replicates of B100 and U100, respectively
For m ≤ 80, all three improved methods performed better than the control method (Table ). These results suggest that the three improved methods proposed in this paper can be used to replace the control method in real world data analyses. In general we recommend to use γ̂0 = cm/(1 + cm), for it essentially eliminates the E(γm) > γ0 bias at all levels of m. But the two other methods may come in handy under certain circumstances. For example, if an earlier publication which had used m = 5 without providing Bm and Um values, one can simply use γ̂0 = γmm/(1 + m) to convert the biased γ0 estimate of the paper into a more correct γ0 estimate.
6. Conclusions
In most published researches, γ∞ and γ0 are treated as synonyms. However, the two are different. The γ0 is independent of MI, whereas γ∞ is a parameter of MI. γ∞ equals to γ0 only if Bm/Um = B0/U0. To use MI for FMI estimation, one has to assume γ∞ = γ0, which will also be the assumption here.
The γm decreases with the increase of m. We quantified the m–γm relationship. The magnitude and the rate of the γm decrease varies with m and γ0. At m = 2, γ2 is greater than γ0 by 50–81% depending on the γ0 level. At m = 5, the recommended m value as being sufficient by some (e.g. Rubin, Citation1987), γm is greater than γ0 by 20–25% when γ0 value ranges from 0.001 to 0.6. The decrease of γm with the increase of m determines that E(γm) > γ0 for any finite m. The results from the MI trials suggest that the volume of the γm decrease with increased m is not ignorable in real world data analyses in spite of the noises from sampling errors and other sources.
E(Bm) and E(Um) are independent of m. Therefore, the decrease of γm with the increase of m is not due to an indirect effect of m on E(Bm) and E(Um). As a result, it is not necessary to use the Bm and Um from the same MI for best γm estimation. Instead, one should use the best estimates of B0 and U0 available, which leads to the development of Equation (14) that links γm to γ0 directly.
The variation in γm can be substantial. The CV of γm was essentially identical with that of Bm, and CV of Um was 1–10% that of γm or Bm. The variation of γm is smaller as m gets bigger. The inaccuracy of FMI estimation due to γm variation should be concerned in FMI estimation when m is small regardless what method is used.
The current method γ̂0 = γm may result in a substantial FMI overestimation when m is not sufficiently large. Three improved methods are proposed for estimating γ0 from MI of a finite m. These three methods are (1) γ̂0 = γm≥100, (2) γ̂0 = γm(m/(m + 1)), and (3) γ̂0 = cm/(cm + 1), where cm = Bm/Um. In our MI trials, all three improved methods gave more accurate γ0 estimates than γ̂0 = γm where m is less than 80.
When m is sufficiently large, say, m ≥ 100, all three methods should give a statistically sound estimation of γ0. When m is not sufficiently large, say, m < 100, the third method γ̂0 = cm/(cm + 1) should be one’s best option for γ0 estimation. The second method γ̂0 = γm(m/(m + 1)) has its value where Bm and Um are not available and the only values available to use for γ0 estimation are m and γm.
Competing interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Acknowledgements
Dr. Yulei He of NCHS is sincerely thanked for his invaluable insights and suggestions.
Additional information
Funding
Notes on contributors
Qiyuan Pan
Qiyuan Pan is a mathematical statistician in Division of Health Care Statistics, National Center for Health Statistics (NCHS), Centers for Disease Control and Prevention (CDC), U.S. Department of Health and Human Services (HHS), USA. He obtained his PhD from University of Maryland, USA.
Rong Wei
Rong Wei is a mathematical statistician in Mathematical Statistics Branch, Division of Research and Methodology, NCHS, CDC, HHS. She obtained her PhD from University of Wisconsin, USA.
Notes
1. The findings and conclusions in this report are those of the authors and do not necessarily represent the official position of the National Center for Health Statistics (NCHS) or Centers for Disease Control (CDC), USA.
References
- Andridge, R. R., & Little, R. J. (2010). A review of hot deck imputation for survey non-response. International Statistical Review, 78(1), 40–64. doi:10.1111/j.1751-5823.2010.00103.x
- Barnard, J., & Rubin, D. B. (1999). Small-sample degrees of freedom with multiple imputation. Biometrika, 86(4), 948–955. doi:10.1093/biomet/86.4.948
- Bodner, T. E. (2008). What improves with increased missing data imputations? Structural Equation Modeling: A Multidisciplinary Journal, 15, 651–675. doi:10.1080/10705510802339072
- Carpenter, J., & Kenward, M. (2013). Multiple imputation and its application. John Wiley & Sons.
- Dohoo, I. R. (2015). Dealing with deficient and missing data. Preventive Veterinary Medicine, 122(1–2), 221–228. doi:10.1016/j.prevetmed.2015.04.006
- Graham, J. W., Olchowski, A. E., & Gilreath, T. D. (2007). How many imputations are really needed? Some practical clarifications of multiple imputation theory. Prevention Science, 8(3), 206–213. doi:10.1007/s11121-007-0070-9
- Harel, O. (2007). Inferences on missing information under multiple imputation and two-stage multiple imputation. Statistical Methodology, 4, 75–89. doi:10.1016/j.stamet.2006.03.002
- He, Y., Shimizu, I., Schappert, S., Xu, J., Beresovsky, V., Khan, D., … Schenker, N. (2016). A note on the effect of data clustering on the multiple-imputation variance estimator: A theoretical addendum to the Lewis et al. article in JOS 2014. Journal of Official Statistics, 32(1), 147–164. doi:10.1515/jos-2016-0007
- Hershberger, S. L., & Fisher, D. G. (2003). A note on determining the number of imputations for missing data. Structural Equation Modeling, 10(4), 648–650. doi:10.1207/S15328007SEM1004_9
- Hogg, R. V., McKean, J. W., & Craig, T. A. (2013). Introduction to mathematical statistics (7th ed.). Boston: Pearson Education, Inc.
- Khare, M., Little, R. J. A., Rubin, D. B., & Schafer, J. L. 1993. Multiple imputation of NHANES III. Proceedings of the Survey Research Methods Section, American Statistical Association, pp. 297–302.
- Lau, D. T., McCaig, L. F., & Hing, E. (2016). Toward a more complete picture of outpatient, office-based health care in the U.S: Expansion of NAMCS. American Journal of Preventive Medicine, 51(3), 403–409. doi:10.1016/j.amepre.2016.02.028
- Lewis, T., Goldberg, E., Schenker, N., Beresovsky, V., Schappert, S., Decker, S., … Shimizu, I. (2014). The relative impacts of design effects and multiple imputation on variance estimates: A case study with the 2008 National Ambulatory Medical Care Survey. Journal of Official Statistics, 30(1), 147–161. doi:10.2478/jos-2014-0008
- Little, R. J., Wang, J., Sun, X., Tian, H., Suh, E.-Y., Lee, M., … Mohanty, S. (2016). The treatment of missing data in a large cardiovascular clinical outcomes study. Clinical Trials, 13(3), 344–351. doi:10.1177/1740774515626411
- Pan, Q., Wei, R., Shimizu, I., & Jamoom, E. (2014). Determining sufficient number of imputations using variance of imputation variances: Data from 2012 NAMCS Physician Workflow Mail Survey. Applied Mathematics, 5, 3421–3430. doi:10.4236/am.2014.521319
- Rezvan, P. H., Lee, K. J., & Simpson, J. A. (2015). The rise of multiple imputation: A review of the reporting and implementation of the method in medical research. BMC Medical Research Methodology, 15, 30. doi:10.1186/s12874-015-0022-1
- Royston, P. (2004). Multiple imputation of missing values. The Stata Journal, 4(3), 227–241.
- Rubin, D. B. (1987). Multiple imputation for nonresponse in surveys. New York, NY: John Wiley & Sons.
- Savalei, V., & Rhemtulla, M. (2012). Missing information from full information maximum likelihood. Structural Equation Modeling: A Multidisciplinary Journal, 19(3), 477–494. doi:10.1080/10705511.2012.687669
- Schafer, J. L. (2001). Analyzing the NHANES III multiply imputed data set: Methods and examples. Retrieved from ftp://ftp.cdc.gov/pub/Health_Statistics/NCHS/Datasets/NHANES/NHANESIII/7a/doc/analyzing.pdf.
- Schenker, N., Raghunathan, T. E., Chiu, P.-L., Makuc, D. M., Zhang, G., & Cohen, A. J. (2006). Multiple imputation of missing income data in the national health interview survey. Journal of the American Statistical Association, 101, 924–933. doi:10.1198/016214505000001375
- Serfling, R. (1980). Approximation theorems of mathematical statistics. John Wiley & Sons, Inc.
- Siddique, J., Harel, O., Crespic, C. M., & Hedekerd, D. (2014). Binary variable multiple-model multiple imputation to address missing data mechanism uncertainty: Application to a smoking cessation trial. Statistics in Medicine, 33, 3013–3028. doi:10.1002/sim.6137
- Van Buuren, S. (2012). Flexible imputation of missing data. Boca Raton, FL: Chapman and Hall/CRC Press.
- Wagner, J. (2010). The fraction of missing information as a tool for monitoring the quality of survey data. Public Opinion Quarterly, 74(2), 223–243. doi:10.1093/poq/nfq007
- Zheng, T., & Lo, S.-H. (2008). Comment: Quantifying the fraction of missing information for hypothesis testing in statistical and genetic studies. Statistical Science, 23, 321–324. doi:10.1214/08-STS244A