
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We develop a simulation method for Markov Jump processes with finite time steps based in a quasilinear approximation of the process and in multinomial random deviates. The second-order approximation to the generating function, Error = O(dt2), is developed in detail and an algorithm is presented. The algorithm is implemented for a Susceptible-Infected-Recovered-Susceptible (SIRS) epidemic model and compared to both the deterministic approximation and the exact simulation. Special attention is given to the problem of extinction of the infected population which is the most critical condition for the approximation.
PUBLIC INTEREST STATEMENT
The overall goal of population dynamics is to understand the collective time-evolution of populations in terms of their reciprocal and environmental influences. The description is made in terms of the number of individuals that share the same relevant characteristics and results in a intrinsic (unavoidable) stochasticity. This manuscript describes a new implementation of the core stochastic methods. The new method takes advantage of particularities that more often than not appear in biological populations such as in the description of biological cycles and/or the progress in time of epidemic outbreaks. The present method is more efficient than a general approach, while keeping accuracy within desirable levels. Understanding, modelling and predicting population processes is an important ingredient in the development of public policies such as health or farming, to mention just a few.
1. Introduction
In a broad sense, stochastic population processes correspond to the time-evolution of countable sets (and subsets) of individuals in interaction. The description is performed by tracking the number of members of each relevant subpopulation over time. The classification scheme used for the populations is dictated by the problem. For example, in an epidemic problem, it is often sensible to group the population in at least two sets: susceptible, S and infectious, I. In the description of the lifecycle of an insect, we will often refer to subsets (compartments) corresponding to different developmental stages such as eggs, larvae, pupae and adults. Such models can be used in a large range of problems in chemistry and biology. The quality of such models largely depends on the quality of the transcription between natural science and mathematics. For example, stochastic compartmental models applied to vector-borne diseases such as yellow fever perform very satisfactorily when compared to real (historic) data (Fernández, Otero, Schweigmann, & Solari, Citation2013). The vector component of the model can be used to forecast the expected range of the vector (in this case, the mosquito Aedes aegypti) (Otero, Solari, & Schweigmann, Citation2006), yielding results that agree well with field studies (Zanotti et al., Citation2015). However, if the modelling strategy is going to be useful, it is a practical requirement that it shall use a reasonable amount of computational resources. The general family of population processes described in this work is associated with the probabilities ruled by the Kolmogorov Forward Equation (KFE) for jump processes (Kolmogoroff, Citation1931), since populations update by jumps (events) such as the hatching of an egg that decreases the egg-population by one and increases the larvae population by one.
The description of population problems by means of stochastic methods has a modern history of over 100 years (McKendrick, Citation1914) (though its origins can be traced further back to Malthus, Citation1798). This approach has several advantages over other existent approaches. In the first place, it recognises the individual level and the intrinsic impossibility of describing this level in a deterministic way. Further, it deals with integer variables, which is the only consistent way of dealing with individuals at all levels of presence (from extinction to groups of billions). Further, for systems where the actual evolution time is relevant, the use of Markov Jump processes (Ethier & Kurtz, Citation1986) (continuous-time Markov chains) provides a rationale for organising the dynamics. The relation between the stochastic description of population problems and the – possibly more popular – differential equations approach has been studied and established by Kurtz (see Ethier & Kurtz, Citation1986), where the validity and limitation of the so-called deterministic limit is discussed (see also Aparicio, Natiello, & Solari, Citation2012).
The “jumps” in the Markov Jump process are the symbolic description of the dynamical evolution, identifying situations where the population suffers drastic changes at a point in time (e.g., an individual is born). This change is called an event. The list of events will control the outcome possibilities of a model. Events come in different flavours, characteristic times, and so on and the more accurate the description in biological terms, the larger the number of events that need to be considered.
The origin of this approach goes back to Kolmogorov (Kolmogoroff, Citation1931) and, more specifically, to Feller’s work on stochastic processes (Feller, Citation1949) developing from the equations that he named Kolmogorov equations. Subsequently, Kendall (Citation1949, Citation1950) devised an algorithm to implement Feller’s approach.
Event-based models, though powerful and successful (see above), are computationally time-consuming. The approach requires to track all individual events in their given time order. On the contrary, experimental data are usually collected and grouped within reasonable time intervals (in an epidemic outbreak, we speak of number of cases per week, while e.g., municipal housing policies consider only the balance between birth, death, emigration and immigration over a year). Eventually, we arrive to a situation where approximations to Kendall’s algorithm are required. Rather than computing a large number of individual events, it would be desirable to estimate the overall event-count within a fixed time step, drastically shortening computation resources without loosing accuracy.
Approximating a stochastic process with another stochastic process is an interesting issue by itself. Consider families of processes such as e.g., , a Kendall problem for a population of size
and
its approximation. If the approximation should have a chance to be satisfactory, we should have, in some abstract sense, that
, where
is the error of the approximation. A minimum, necessary, requirement is of course that
, but this is not enough. In all situations, simulations and modelling involve a finite value (or range) of
. A way to estimate and control
for any
is needed. Things do not get easier when one realises that since
for any finite
, the statistics of
and
will differ, eventually, when the number of repetitions is very large. Approximations involve hence different tolerances: (a) small
so that it makes sense to attempt to approximate
with
, and (b) medium large statistics so that while
satisfactorily uncovers the dynamical effects of the system in study, its stochastic difference with
can still be considered negligible.
In previous works, we have developed a Poisson approximation (Solari & Natiello, Citation2003) to Kendall’s algorithm as well as a general view of approximation methods (Solari & Natiello, Citation2014). These approximation methods are organised building upon the concept of linear events (those where the probability rate depends linearly on the involved populations) along with a consistent multinomial approximation for the linear situation with constant (in time) coefficients.
The goal of this work is to develop a new consistent multinomial approximation to Kendall processes based on a linear approximation to event rates (called quasilinear approximation), allowing for general time-dependencies in the event rates. The manuscript is organised closely following Solari and Natiello (Citation2014), of which it is an extension and in some form a natural development. After a section refreshing the idea of KFE, we state the quasilinear approximation in Section 3. This section starts by presenting and defining the approximation, subsequently formulating the computation of averages within it. Then, the error estimates of the approximation, which are necessary to control the accuracy of the implementation are computed in Section 3.2 and finally the generating function is computed. The section ends with the statement of the stochastic dynamical equations, in Lemmas 3 and 4, for the second-order approximation. These lemmas are the central tools in the following sections dealing with examples. Section 4 deals with a well-known example, rendered technically difficult by the time-dependency. Section 5 dwells in a more elaborated example, which is the source for numerical tests. Some concluding remarks are found in Section 6.
2. Kolmogorov Forward Equation
Let denote a state of the system with the count of how many events of each type has occurred up to a given time. Denote the product
by
and the generating function by
, where
is the probability of having
events at time
given the initial population state
. Finally,
is the population array
, where the subpopulations satisfy
. The transition matrix
denotes the modification acted by event
on population
(Solari & Natiello, Citation2003) and it has integer entries.
For a general Markov Jump process, the KFE for the generating function reads (Solari & Natiello, Citation2003),
where is the transition rate associated with event
, in other words, the probability per unit time for the occurrence of event
given the state
.
The population array denotes the count of individuals
in each subpopulation
(at a given time
or after the occurrence of
events) which is necessarily non-negative. The following definition is therefore proper:
Definition 1. A set of states , with the property that if
at
then
for all
is called positively invariant.
Positively invariant sets are often called trapping sets. For example, the extinction state where all subpopulations are zero is a trapping set. The set of states with non-negative populations is a positively invariant set as well.
3. Quasilinear approximation
A common feature in all population problems involving higher organisms is that the events modifying the system can be regarded as belonging to only three classes:
Individual death events where the relevant consequence is to reduce some subpopulation in one unit, while no other subpopulation is modified.
Development events where one subpopulation increases by one and another decreases by the same amount (e.g., a transition from pupa to adult in insect development).
Creation events where some populations decrease by a total of
members and some other populations increase by a larger number
An interesting fact in biological processes is that rarely, if ever, an event can exist that does not decrease any population. Biological “creation” processes always involve the modification of some previous entity (usually one individual of another subpopulation which in the act of creation ceases to exist). In this poetical sense, becoming adult decreases the young population in one, being born decreases the pregnant female population in one, becoming ill decreases the healthy (often called susceptible) population in one, etc., and no other subpopulation is decreased in each case. Hence, we will hereafter consider processes where the events may be sorted according to the subpopulation
that they decrease. Clearly, not all population problems are linear as in (Solari & Natiello, Citation2014). However, similar arguments to those used to prove Lemma 7 in (Solari & Natiello, Citation2014) apply here, this is,
Lemma 1. Let the polynomial transition rate be such that it only decreases the subpopulation
in one unit, i.e.,
and
. Population space is positively invariant only if
Proof. Positive invariance demands that for any sufficiently short time the probability
of occurrence of an event
such that
is zero (we are just saying that no event can push a subpopulation into negative counts). Under the Markov Jump Process assumptions (Durrett, Citation2001; Feller, Citation1940), this probability may be written as
. Hence,
and we can extract a factor of
thus proving the relation. Polynomial smoothness gives the desired result.◽
Therefore, we introduce the quasilinear approximation, namely we let the transition rates be approximated by
where is the subpopulation decreased by
. We shall denote by
the quasilinear approximant of
and
the quasilinear approximant of the probabilities. The quasilinear approximation consists in replacing
by a self-consistent average
(to be specified later in detail), i.e., an average based on the generating function
. In other words, we extract a linear part associated with the decreasing subpopulation on each
(in the situation where
is actually linear,
is just a constant). The quasilinear approximation allows for further computation. Indeed,
cf. (Solari & Natiello, Citation2014; Equation 10).
An important feature of this work is that the quasilinear approach is an approximation. Hence, error bounds relative to the full-problem must be considered. We discuss this issue in subsection 3.2.
Since the approximated problem is linear, most of the results in Solari and Natiello (Citation2014) can be transported or generalised to the present work, once the appropriate changes for possible time-dependencies in the quasilinear coefficients are introduced. For the present problem, the main specification reads
(the -symbol with two population indices is the Kronecker delta) and it will introduce a time-dependency through the expectation values.
We have that (a constant) for linearly decaying events.
3.1. Dynamical equation for the average populations
Starting from the population values , we obtain
and further
where it is sufficient to sum over all events such that
. Recalling Equations (3) and (4) (
is the population decreased by event
),
we obtain expressions within the quasilinear approximation:
This result has an equivalent in (Solari & Natiello, Citation2003; Equation 48), the large limit:
Lemma 2. If exists and
is polynomial in
, then under the generalised mass action law (Ethier & Kurtz, Citation1986; Solari & Natiello, Citation2003) (i.e.,
, being
a typical size for the system) the deterministic limit of the population dynamics reads
Proof. From Equation (6), we obtain
By the generalised mass action law, is a polynomial in the random variable
, where
. For the moments of a multinomial, it holds that
. Hence, if
exists,
Furthermore, . Since the right-hand side is finite, we can also interchange the limits in the left-hand side.
3.2. Error estimates
We want to reconsider the error estimates of (Solari & Natiello, Citation2003) in order to assess the accuracy of the approximation. The procedure in (Solari & Natiello, Citation2003; Sections 3 and 4) is general enough and it can be reproduced here, taking care of the proper expression for the ’s and the generating function.
Bounds to the error of the approximation can be computed by integrating the difference between the exact and approximate time-evolutions from the same initial condition. We start by defining the auxiliary operator
formally solving the exact time-evolution as
This is achieved by expanding the right-hand side of Equation (1) using Equation (2) and reordering the sum over events. denotes the set of events that decrease the subpopulation
. Note that for
,
and
for
(from Equation 5), being then
.
The approximate time-evolution in the quasilinear approximation is recovered putting together Equations (1) and (3), finally leading to
We can now compute the error estimate as:
given that (
being the exact generating function). Note that all operators in the square bracket depend on
. Hence, for suitable bounded positive constants
and
, using Grönwall’s inequality it also holds that
Finally, for a suitable bounded positive constant, it follows that
The present approach has smaller upper bounds than the method developed in (Solari & Natiello, Citation2003), since the constant is proportional to
:
Thus, only the nonlinear processes contribute to the error.
The conditions that optimise the estimation of average values and dispersions require that (Solari & Natiello, Citation2003; Equations 26 and 51)
where is the approximated generating function, to be considered in the next section. The later expression can be read
where the averages are taken with the approximated generating function with initial condition . Hence, we arrive to the condition
(we recall that is the population decreased in one by the event
). This expression justifies our early (intuitive) choice for
in Equation (3).
3.3. Generating function
The quasilinear generating function can be computed taking advantage of the linearity properties of the approximation (Solari & Natiello, Citation2014; Equation 35). For the present work, rendering time-dependency explicit, we have
where satisfies the equation
to be integrated over , and the coefficients
express the initial condition in terms of the event matrix
:
. Recasting the result in population space (Solari & Natiello, Citation2014; Equation 36), we may write
, (where
is the generating function for one individual of the population
, see Lemma 5 in Appendix A) thus arriving to a differential equation for the generating function for each subpopulation to be integrated over
(cf. Solari & Natiello, Citation2014; Equation 43):
We recall that for ,
and
for
. Hence, for
we have
,
and
We rewrite Equation (10) as an integral equation. We set first
Hence,
The first term is the probability of no events, while the second term is built with two objects,
The first contribution gives the probability of the first event taking place precisely in the interval while the second factor is the generating function for an individual after the occurrence of an event
at time
. The factor
counts the event
.
3.4. Ordinary differential equation form of the approximation
The approximation lemma in Appendix A establishes the relevant properties of the generating functions within the approximation. Picard’s iteration scheme starts with
. The next-order approximation obeys (always with the initial condition
at any order)
with the solution
In general, we have
When computing specific problems, the coefficients may actually depend on the solutions
and a further approximation scheme will be required to approximate the time integrals. A more manageable expression is obtained by changing variables in Equation (12) via
. First we let
Then, Equation (12) reads,
and further :
3.4.1. Second-order approximation
From the approximation lemma in Appendix A, we know that is a
-th degree polynomial in the variables
, with time-dependent coefficients. We propose the following approximated expression for
:
since we will only need event strings of length at most two to implement the second-order approximation.
Lemma 3. The following relations hold, for and
:
and
Proof. Straightforward substitution of Equation (14) into Equation (13) gives the result by separating terms after powers of .◽
Note also that can be decomposed as the sum of
identical probabilities per generated individual,
.
Each member of subpopulation undergoes an event
with probability
. In terms of the population,
events are produced, with
a random variable distributed with
.
The occurrence of this event produces an increment in the subpopulations
. The newly arrived members of the population
may in turn undergo a new transition triggered by event
(or no transition at all). The probability of this sequence
is
, i.e., the probability of event
following event
for each of the new individuals
, conditioned to the actual occurrence of
. Thus, there will be
additional events subtracting individuals from the
subpopulation as a consequence of event
. This will modify in turn the subpopulations in the set
by an amount
. The value of
is drawn from
.
Lemma 4. The approximated generating function
Equation (14) corresponds to a concatenation of multinomial processes.
Proof. Consider a process described by strings of length two such that
. Then,
where is given by the conditional probability and corresponds to a multinomial
where . The generating function is
The generating function of the marginal probability
is itself a multinomial distribution resulting from the competing exponential events. Finally, 14 corresponds to the first order in of the development of
.◽
The proof actually applies to any order of the truncation of 12 which results always in the concatenation of multinomial distributions arising from the generating function for the marginal probabilities (which are themselves multinomial since they are the consequence of competing exponential events).
4. Example: SIR
Equipped with the lemmas of the previous section, we are in a position to compute an approximate generating function and approximate dynamics keeping the steps of the time-evolution sufficiently low to guarantee error control.
Let us consider a SIR epidemic system. There are three subpopulations: Susceptible, Infected and Recovered. At a given time we have the initial values
,
and
. We are interested in the dynamical outcome at a later time
and hence
. The transitions are as follows:
Contagion
Recovery
There are no events decreasing the recovered population, hence . Further, at time
we have:
The expected average values at time for a process initiated at time
read,
The last line can be computed in two equivalent ways. Either as stated, using that the individual expectation values correspond to adequate -derivatives of the quasilinear generating function evaluated at
, or noting that for this problem
can be splitted as a contribution independent of event
, plus a contribution following the occurrence of event
, i.e.,
. While
is independent of
,
is distributed with
. Hence,
since from the joint distribution we have that the expectation value of
conditioned to
is
and
.
The results are completed by
Hence,
while . In the above equations,
. We write them in this form since in order to solve the differential equations we will evaluate
at time
, where
is the integration variable. As for the probabilities, we are also interested in the
’s evaluated at
and they obey the following differential equations:
with initial conditions , respectively
and
. Being
a constant, the last equation can be solved straightforwardly, while the others require to adopt some form of approximation. For example, approximating
, i.e., by a constant value, we obtain a first approximation
Subsequently, a first-order approximation for the rate is produced using the calculated values and :
Finally, this first-order approximation is used to solve the second-order equations. Recall that what enters in the differential equations is , while the equations have to be integrated over
.
The stochastic number of events occurring in a short time-interval starting at
can be obtained as follows:
Solve 15 and obtain the coefficients
Compute the stochastic number of events
For the case of contagion events, we note that
5. Example: SIRS
In this example, we extend the previous results including loss of immunity of recovered individuals and provide numerical computations within the quasilinear approximation. While in the SIR model of the previous section an individual will suffer no other events after following the sequence , the loss of immunity in the present example allows for the occurrence of arbitrarily long sequences of
events, being the computational situation more involved.
5.1. Formulae
We consider now a Susceptible-Infected-Recovered-Susceptible (SIRS) epidemic system. We have three subpopulations: Susceptible, Infected and Recovered. The transitions are as follows
Contagion
Recovery
Immunity loss
We have that
which must be calculated with the first-order approximation (which is a multinomial distribution). The generating function reads,
Hence,
With these elements we can compute
and
Hence,
The remaining rates are linear, hence and
As for the differential equations,
The stochastic number of events occurring in a short time-interval can be obtained as follows:
Solve 16 and obtain the coefficients
Compute the stochastic number of events
Compute the stochastic number of following events. For example, from
5.2. Comments
Let us assume that we have the SIRS system
and our population values are . In case, the race between recovery of infected and new infection (i.e., the next event influencing
) is won by the recovery, the epidemic stops at that point, and the infected population becomes extinct. We know then that, with this initial condition, extinction is bounded by
. We know as well that the probability of extinction increases with time. We further know that the probability of extinction in a time-interval
is bounded as
to a very good approximation (the parenthesis expresses the probability of the occurrence of an event in
).
We now consider the case in our approximation up to first order. Since, and
we need
and
.
The probability must be multiplied by the probability
since both events are assumed to be independent in the approximation. Thus,
. This function is convex and it is zero at
while also
. Hence, unlike the exact case, the probability is not non-decreasing.
The observation imposes a qualitative limit for the possible time steps, namely . For example,
,
,
we have
Another interesting feature that generalises to all systems is that the expression that appears in the denominator of
can be written as
and has the form
. The factors
are
and according to the approximation lemma (in Appendix A), they admit a power-series expansion. If only the lowest orders are to be kept, it is needed that
. In the case of our example, considering
this requires
, but the requirement to neglect
in front of
in all cases require to consider the worst scenario
. This translates into
. Thus, further approximations should be considered with caution and it is advisable not to perform them. In the same form,
will have 12 terms when parsed by the first and second powers of
.
5.3. Simulations
We use the SIRS model to illustrate the differences between different simulations. The model corresponds exactly to a Feller–Kendall process; hence, we visually compare the exact process, the deterministic model and the present approach.
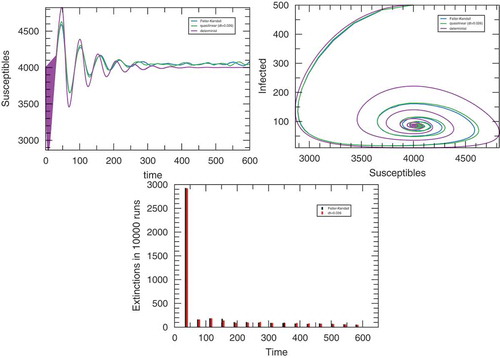
In Figure , it is shown that the approximated method closely follows the exact simulation in contrast with the deterministic method that presents large departures after reaching the minimum number of infected individuals (upper right panel in the figure). Both the total number of runs (out of ) where the infected population goes into extinction and the distribution in time of these events is well represented by the approximation method (no extinction is possible in the deterministic simulation).
Figure 1. Simulation outputs of the SIRS model for and
for the approximated stochastic simulation. The upper left panel displays the average time-trace of the number of infected individuals. Upper right: average trace of the trajectory in the
plane. The bottom panel displays the number of process in which the infected population became extinct. In all cases,
simulations where performed.
6. Concluding remarks
The goal of this manuscript has been to discuss, develop and implement a quasilinear approximation to the Feller–Kendall algorithm for Markov Jump processes. The work follows closely the ideas in Solari and Natiello (Citation2014), where linear and constant transition rates are discussed. In the present work, we extend those ideas to the more useful situation where rates are not necessarily linear and – quite important – they are also time-dependent. The relevance of the use of approximations ultimately lies in the judgement of the user. However, for population problems with realistic aspirations, the Feller–Kendall algorithm soon becomes too slow and reliable approximations are a reasonable way out. The alternatives available for choosing a proper approximation level are therefore also discussed.
Acknowledgements
M.A.N. acknowledges support from the Kungliga Fysiografiska Sällskapet (Lund, Sweden). R.B., M.O. and H.G.S. acknowledge support from Buenos Aires University under grant 20020130100361BA.
Additional information
Funding
Notes on contributors
Mario A. Natiello
The authors participate in several long-term collaborations concerning the propagation of epidemic diseases in different populations (ranging from human groups to crops) with emphasis in those propagated by vectors, thus involving ecological aspects. The aim of this cross-disciplinary group is to develop the understanding of general population dynamics problems combining mathematical and biological expertise in a way that goes beyond the individual disciplines.
References
- Aparicio, J. P., Natiello, M., & Solari, H. G. (2012). The quasi-deterministic limit of population dynamics. International Journal of Applied Mathematics and Statistics, 26(2), 30–45.
- Durrett, R. (2001). Essentials of stochastic processes. New York: Springer Verlag.
- Ethier, S. N., & Kurtz, T. G. (1986). Markov processes. New York: John Wiley and Sons.
- Feller, W. (1949). On the theory of stochastic processes, with particular reference to applications (pp. 403–432). University of California Press.
- Feller, W. (1940). On the integro-differential equations of purely discontinuous Markoff processes. Transactions of the American Mathematical Society, 480(3), 488–515. ISSN 00029947. Retrieved from http://www.jstor.org/stable/1990095
- Fernández, M. L., Otero, M., Schweigmann, N., & Solari, H. G. (2013). A mathematically assisted reconstruction of the initial focus of the yellow fever outbreak in buenos aires (1871). Papers in Physics, 5, 50002. doi:10.4279/PIP.050002
- Kendall, D. G. (1949). Stochastic processes and population growth. Journal of the Royal Statistical Society. Series B (Methodological), 11, 230–282. doi:10.1111/j.2517-6161.1949.tb00032.x
- Kendall, D. G. (1950). An artificial realization of a simple “birth-and-death” process. Journal of the Royal Statistical Society. Series B (Methodological), 12, 116–119. doi:10.1111/j.2517-6161.1950.tb00048.x
- Kolmogoroff, A. (1931). Über die analytischen methoden in der wahrscheinlichkeitsrechnung. Mathematische Annalen, 104, 415–458. ISSN 0025–5831. doi:10.1007/BF01457949
- Malthus, T. 1798. An essay on the principle of population. www.esp.org. London: Electronic Scholarly Publishing Project. Retrieved from http://www.esp.org/books/malthus/population/malthus.pdf
- McKendrick, A. G. (1914). Studies on the theory of continuous probabilities, with special reference to its bearing on natural phenomena of a progressive nature. Proceedings of the London Mathematical Society, s2–13, 401–416. doi:10.1112/plms/s2-13.1.401
- Otero, M., Solari, H. G., & Schweigmann, N. (2006). A stochastic population dynamic model for Aedes aegypti: Formulation and application to a city with temperate climate. Bulletin of Mathematical Biology, 68, 1945–1974. doi:10.1007/s11538-006-9067-y
- Solari, H. G., & Natiello, M. A. (2003). Stochastic population dynamics: The Poisson approximation. Physical Review E, 67, 31918. doi:10.1103/PhysRevE.67.031918
- Solari, H. G., & Natiello, M. A. (2014). Linear processes in stochastic population dynamics: Theory and application to insect development. The Scientific World Journal - Journal of Probability and Statistics, 2014, ID 873624, 1–15. Retrieved from http://downloads.hindawi.com/journals/tswj/aip/873624.pdf
- Zanotti, G., De Majo, M., Sol, I. A., Nicolás, S., Campos, R. E., & Fischer, S. (2015). New records of Aedes aegypti at the southern limit of its distribution in Buenos Aires Province, Argentina. Journal of Vector Ecology, 400(2), 408–411. doi:10.1111/jvec.12181
Appendix A.
Properties of exact solutions
We may think of as the conditional probability of the standard formulation of the Kolmogorov Forward Equation.
resumes all the information of the path at time
that is relevant for the future (the condition), while
represents the number of events that have occurred after the initial time
. Thus,
. The transition probabilities may then show a dependence with time as well. To lighten the notation, we have suppressed the initial time in the arguments since we will seldom use it.
The description by events offers more information than the description by states of the population. The projection of the increments in the number of events, , onto population states is made by the matrix
with elements
which in general is an integer-valued rectangular matrix of dimensions
with
. Since the matrix is rectangular, we are certain to have zero eigenvalues whenever
. We call the associated eigenvectors,
, structural zeros. We take the following results from (Solari & Natiello, Citation2014):
Definition. A nonzero vector such that
, for
is called a structural zero of
.
There are structural zeros. The basis of the space of events can be taken as the union of the
vectors
with components
and the
vectors
. We have that
.
Equation (1) can be formally written as:
Thus the operator is defined as acting over the monomials
as
. If we write
it is clear that
and then
We call the operator that solves the Kolmogorov Backward Equation
with , where
is the generating function corresponding to no events. Following (Solari & Natiello, Citation2003), we have
where and then we can write
Thus, we obtain
where is the identity operator. Then,
Recalling Equation (8)
where are the approximated probabilities,
Using the later and Equation (A1), we obtain the result
A.1. The approximation lemma
The form of the approximations to the generating function can also be obtained by the following iterative scheme starting from Equation (12), recalling also the auxiliary definition in Equation (11):
with . The following Lemma was originally proved in (Solari & Natiello, Citation2014; Lemma 22). We add to the present version one more item (item e) and a slightly improved iteration scheme.
Lemma 5. For ,
sufficiently small and for each order of approximation
,
in 12 is a polynomial generating function for one individual of the population, i.e., it has the following properties:
The coefficients of
Proof. We proceed inductively. For , we set
and replacing in the iterated form we obtain
Noting that
we realise that properties (a)–(e) hold for . In particular,
Under the iterative scheme A4, assuming that the properties hold for arbitrary (with
), it is immediate that property (a) holds also for
, since the iterative scheme adds one power of
to the previous polynomial. Moreover, the correction
reads (with the auxiliary
defined in Equation 11):
Note that throughout, we will consider the individual ’s inside each square bracket to be truncated to the same order of the bracket, since this implies no loss of generality. Thus, property (b) follows since by the inductive hypothesis
and hence
. Using that
and that for
, we can drop the higher order terms. Thus, we have (for arbitrary
),
but since we can also drop higher order terms in
since they do not contribute to the leading order. Finally,
thus giving both (c) and (e). For (d) we observe that,
Inserting the expression for above, we may write:
Recalling the expression for we finally obtain:
Hence, if is a polynomial with positive coefficients, the same property holds for
since it results from multiplication by positive numbers and integration term by term.
It remains to be shown that A4 converges towards a solution of 12, or what is the same, that . However, for
,
with
Then, for bounded transition rates and sufficiently small , the iterative scheme is a contraction map and by Banach’s theorem has a fixed point which is the solution we are looking for.