
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We derive the Local Asymptotic Normality (LAN) property for a multivariate generalized integer-valued autoregressive (MGINAR) process with order p. The generalized thinning operator in the MGINAR(p) process includes not only the usual Binomial thinning but also Poisson thinning, geometric thinning, Negative Binomial thinning and so on. By using the LAN property, we propose an efficient estimation method for the parameter of the MGINAR(p) process. Our procedure is based on the one-step method, which update initial -consistent estimators to efficient ones. The one-step method has advantages in both computational simplicity and efficiency. Some numerical results for the asymptotic relative efficiency (ARE) of our estimators and the CLS estimators are presented. In addition, a real data analysis is provided to illustrate the application of the proposed estimation method.
PUBLIC INTEREST STATEMENT
We derive the Local Asymptotic Normality (LAN) property for a multivariate generalized integer-valued autoregressive (MGINAR) process with order p. recently, there has been a growing interest in modelling discrete-valued time series that arise in various fields of statistics.
The MGINAR process is one of the class of discrete-valued time series models and contains various classes. By using the LAN property, we propose an efficient estimation method for the parameter. Our procedure is based on the one-step method, which update initial root-n consistent estimators to efficient ones. The one-step method has advantages in both computational simplicity and efficiency. Some numerical results for the asymptotic relative efficiency (ARE) of our estimators and the CLS estimators are presented. In addition, a real data analysis is provided to illustrate the application of the proposed estimation method.
1. Introduction
Recently, there has been a growing interest in modelling discrete-valued time series that arise in various fields of statistics (e.g., Weiß, Citation2018). This paper is concerned with a special class of observation-driven models termed “integer-valued autoregressive processes” (INAR processes), which were introduced independently by Al-Osh and Alzaid (Citation1987) and McKenzie (Citation1985, Citation1988). They introduced the integer-valued autoregressive process with order 1 (INAR(1) process) to model non-negative integer-valued phenomena with time dependence. The more general INAR(p) processes were considered by Alzaid and Al-Osh (Citation1990), Du and Li (Citation1991) and so on. The INAR process consists of a mixture both of the distribution of thinning operator and the distribution of the innovation process. Alzaid and Al-Osh (Citation1990) discussed the INAR(p) process in case that the thinning operator follows Binomial distribution (i.e., specified), while the distribution of the innovation process is left unspecified. Latour (Citation1998) introduced a generalized version of the INAR(p) process, namely, the causal and stationary generalized integer-valued autoregressive (GINAR(p)) process. The generalized thinning operator in the GINAR(p) process includes not only the usual Binomial thinning but also Poisson thinning, Geometric thinning, and Negative Binomial thinning (by Ristić, Bakouch, & Nastić, Citation2009). The above history is appropriate for the univariate case. Nowadays, extensions for the multivariate case are being actively researched and applied. One of the first approaches to multivariate thinning mechanism was by McKenzie (Citation1988). After that, Franke and Subba Rao (Citation1993) introduced a multivariate INAR(1) (MINAR(1)) model based on independent Binomial thinning operators. The extensions for the MINAR(1) model were discussed by Latour (Citation1997), Karlis and Pedeli (Citation2013), and so on. This paper discusses a parameter estimation problem for a multivariate version of the GINAR(p) (MGINAR()) process. The MGINAR model is quite a large class, including all the models described above.
Estimation of the parameter for the INAR() process can be carried out in a variety of ways. Common ways for estimating parameters include the method of moments (MM), based on the Yule-Walker equations, and conditional least squares (CLS). The main advantage of both approaches is their simplicity due to the closed-form formulae and robustness due to require no assumption for the distribution. It is known that MM and CLS estimators are asymptotically equivalent. However, Al-Osh and Alzaid (Citation1987) and so on have recommended using maximum likelihood (ML) estimators instead of MM and CLS estimators because they are less biased for small sample sizes. However, it is well known that the ML method is computationally unattractive due to complicated transition probabilities, including many convolutions. To overcome this problem, Drost, Van Den Akker, and Werker (Citation2008) considered one-step, asymptotically efficient estimation of the INAR(
) model. Their method can reduce high computational cost due to the convolutions involved in the ML method. Following Drost et al. (Citation2008), this paper provides a one-step method, which update initial
consistent estimators to efficient ones for the MGINAR (
) processes. In the class of multivariate integer-valued models, the number of convolutions involved in the likelihood function is very large. For some distributions with reproductive property, the likelihood can be simplified, but it is impossible to apply such a simplification for all models in the MGINAR (
) processes. Therefore, it would be quite important to reduce the computational cost by using a one-step estimation. We first establish the local asymptotic normality (LAN) structure for experiments of the MGINAR (
) process. Considering the CLS estimator as the initial estimator, a one-step update estimator is proposed. We can also show that this estimator is asymptotically efficient.
The organization of this paper is as follows. In Section 2, the MGINAR () process is introduced and the LAN property is established. Section 3 discusses the efficient estimation. The CLS estimator is introduced and its asymptotic property is shown. Then, by using the LAN property, a one-step estimator is proposed to update the CLS estimator. In Section 4, the asymptotic relative efficiency (ARE) of the one-step estimator and the CLS estimator is examined through some simulation experiments. In addition, a real data analysis is provided to illustrate the application of the proposed estimation method. The proofs and other details are included in the Appendix.
2. The LAN property
Let be a
- dimensional non-negative integer-valued random process (i.e.,
). The multivariate generalized integer-valued autoregressive process of order
(MGINAR(
)) is defined by
where is a
-matrix for
and the matrix thinning
gives a
-dimensional random vector with
th component
Note that for any ,
;
is a collection of independent and identically distributed (i.i.d.), non-negative, integer-valued random variables with the distribution function
and the mean
;
is a collection of i.i.d. non-negative, integer-valued random vectors, where the
th component
has an independent distribution function
and the mean
. Suppose that the starting values
have a distribution
on
, and
.
are independent of each other.
Throughout the paper, the number of lags () and the dimensions (
) are fixed and known. Let
and
denote the classes of distributions of
and
that belong to parametric classes, respectively, say
and
. For instance, when we consider the Binomial thinning operator and the Binomial innovation,
and
should be defined by
and
for
, and
. Our goal is to estimate the parameter
with
, efficiently, where
For (probability) measures , we introduce the following notations for the convolutions:
⊛
⊛
Based on the above notations, we consider the corresponding probability space for denoted by
, where
is a sample space,
is the
-algebra, and
is the probability measure given by
(distribution of
),
(parameter),
(class of distribution of
) and
(class of distribution of
). Furthermore, we introduce
as the natural filtration generated by
(i.e.
).
From (1) and (2), we can write
where . Hence, it follows, for any
,
For some , the transition probability
is given by
We consider parametric MGINAR models in which the parameter space is restricted to the stationary parameter space, for instance, in case of the Binomial thinning operator and , the thinning part of the parameter space should be defined by
. Suppose that
is a combination of a family of parametric distributions for the thinning operator and innovation (immigrant) with the formula below:
Suppose that for any ,
with
is a strictly stationary process. Let
denote the law of
on the measurable space
under
. Here
is the sample space and the power set
is the
-algebra on this sample space. Observing
yields the following sequence of experiments:
where the initial distribution is fixed and the distributions for the thinning operator and innovation (immigrant) are parametrized (i.e., once
is fixed, the distributions are given by
and
).
To prove the LAN property for the sequence of experiments , we impose the following assumptions.
Assumption 1 . (A1) is an open, convex subset of
with
.
(A2) The supports of and
do not depend on
and
and we have, for all
.
(A3) For all and all
,
are defined, continuous in , and satisfied with
for
, respectively.
(A4) Let denotes
For every , there exist a
and a random variable
such that for all
,
,
,
,
, and
.
(A5) Let and
be the first and second derivatives of log-likelihood for
. The information equality
is satisfied, and
is nonsingular and continuous in
.
(A6) For all ,
and
.
(A7) implies
.
To prove that has the LAN property, we need to determine the behavior of a localized log-likelihood ratio. To this end, we first write down the following likelihood:
In addition, we introduce the following log-likelihood:
Following Drost et al. (Citation2008), we establish the LAN property by using a Taylor expansion. To do so, the transition score for is needed. The transition score
can be derived by calculating the partial derivatives of
as follows. For the partial derivatives with respect to
(
),
where if
and
if
. For the partial derivatives with respect to
(
),
where if
and
⊛
if
.
Then, by using the Equations (3) and (4), we can derive a Taylor expansion of the localized log-likelihood ratio, and the appropriate limit theorems suggest that has the LAN property as follows:
Theorem 1. Suppose that any given any
satisfies Assumptions (A1)-(A7), and let
be a probability measure on
with finite support. Then, the sequence of experiments
has the LAN property in
, i.e., for every
the following expansion holds,
where the score (also called the central sequence)
satisfies
The Fisher information defined by
with is nonsingular, and
under
.
3. Efficient estimation
This section provides efficient estimators based on the one-step update method. First, we use the multivariate conditional least squares estimator as an initial estimator of (e.g., Bu, McCabe, & Hadri, Citation2008).
Definition 1 Suppose that is observed from the MGINAR(
) process defined by (1). Then, the conditional least squares (CLS) estimator
for
is defined by
where
Note that by calculating the derivative of with respect to all entries of
, we have
where and
are
with .
Then, Du and Li (Citation1991) showed the following.
Proposition 1 .
where
Moreover, we have the following.
Proposition 2. The CLS estimator is not asymptotically efficient, because it is evident that for some
except for some special cases.
Since we have a -consistent but inefficient estimator of
, we update the CLS estimator to an efficient estimator by using the LAN result.
Theorem 2. Let be a probability measure on
with finite support. Let
be a CLS estimator. Define
where
with . Then, under Assumptions (A1)-(A7),
is an asymptotically efficient estimator of
in the sequence of experiments
. Moreover,
yields a consistent estimator of
, i.e.,
under
4. Numerical study
In this section, we first examine asymptotic relative efficiency (ARE) of our proposed estimator and the CLS estimator through some simulation experiments. Then, we present a real data analysis to illustrate the application of the proposed estimation method.
4.1. Simulation study
Our proposed estimator () and the conditional least squares estimator (
) under the MGINAR model are compared through a series of simulation experiments. Specifically, we assess the small sample properties of the two estimators in the following cases: a Binomial thinning operator and a Binomial innovation (Case 1); and a Poisson thinning operator and a Poisson innovation (Case 2) with
and
. The count series
are defined by
where
and ,
. We suppose the initial distribution as
(i.e., the initial value is fixed by
). The
and
are defined by
Case 1: Binomial thinning operator and Binomial innovation
Case 2: Poisson thinning operator and Poisson innovation
Then, the true parameter vector is written by
Note that the parameter vector is chosen to obtain stationary count series.
We ran Monte Carlo replicas with sample sizes
. For each replica, we estimate the model parameters based on two procedures (CLS:
, Efficient Est:
) and calculate the (approximated) bias (Table ) and diagonal part of the (approximated) MSE (Table ) of the parameter estimators. Finally, we calculate the (approximated) ARE (Table ) defined by
MSE of
MSE of
. Simulations are carried out in R. For the calculation of
, we need an explicit form of the score
under the given distributions
and
. Please see the derivation of the score
for each case in the Appendix.
Table 1. Bias results for the MGINAR(1) model
Table 2. Diagonal part of MSE Results for the MGINAR(1) model
Table 3. ARE (asymptotic relative efficiency) Results for the MGINAR(1) model
The bias results are reported in Table . It can be seen that the biases for both estimators tend to be when the sample size is sufficiently large. This implies that the both estimators are asymptotically unbiased. However, for the CLS estimator of
and
, the biases are relatively large, which implies that the convergence rate is relatively slow. In contrast, our proposed estimator improves the CLS estimator in terms of bias.
The corresponding MSE results are displayed in Table . Similar to the bias results, the MSEs for both estimators tend to be when the sample size is sufficiently large, which implies that both estimators converge to the true values in probability. However, for the CLS estimator of
and
, the MSEs are relatively large, which implies that the convergence rate of the variance is relatively slow. In contrast, our proposed estimator improves the CLS estimator, because it appears that the MSEs of all components converge to
.
Finally, the ARE (asymptotic relative efficiency) results are given in Table . The ARE of two estimators is defined as the ratio of their asymptotic variances (e.g., Cox & Hinkley, Citation1974; Serfling, Citation2011). Let and
be two estimators of
. Let
and
be the asymptotic covariance matrices, i.e.,
for i = 1,2, respectively. Then, the ARE of and
is given by
In our study, we consider the ARE of our proposed estimator () and the conditional least squares estimator (
) as follows:
Clearly, in this setup, if an ARE is larger than , it suggests that our proposed estimator improves the CLS estimator in terms of efficiency. Table reports the ARE results, but
and
are replaced as the sample MSEs. It can be seen that the ARE tends to be larger than
as the sample size increases, which implies that our estimator improves the CLS estimator in terms of efficiency. We tried the same simulation studies under some different settings with respect to the parameter values. We omit them, but the results are similar.
4.2. Real data analysis
The data set consists of the number of cases of infectious diseases per week by prefecture for the period 2015–2018 (208 weeks) as reported by the National Institute of Infectious Diseases (NIID) in Japan (URL: https://www.niid.go.jp/niid/en/). Here we use the number of cases of “Epidemic keratoconjunctivitis (EK)” and “Aseptic meningitis (AM)” in Shimane prefecture. The sample path plot for the data in Figure reveals some seasonality or periodicity, but it looks that there exist no trend and stationarity.
Figure 1. The number of cases of epidemic keratoconjunctivitis (left hand side) and aseptic meningitis (right hand side) per week in Shimane prefecture.
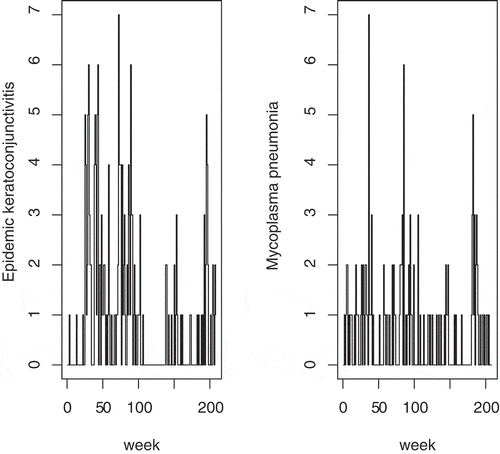
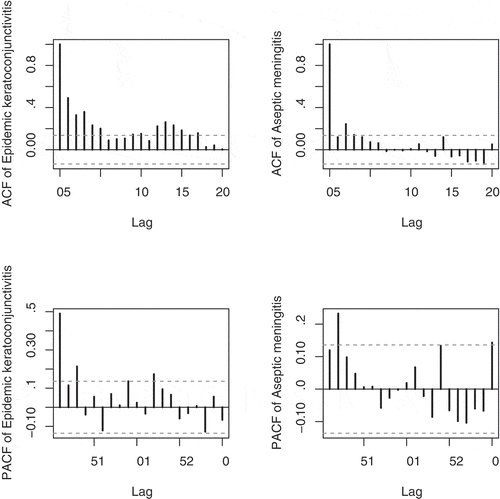
Figure shows the sample ACF and PACF plots for each disease. The figure shows the time dependency but any long-range dependence is not observed, so it is acceptable to fit the MGINAR(1) model.
Figure 2. The sample ACF and PACF for the epidemic keratoconjunctivitis data (left hand side) and aseptic meningitis data (right hand side).
We suppose that the time series count data follows
where both of the thinning operator and the innovation follows the Binomial or Poisson distribution. The CLS estimator () for the parameter (
) is obtained as follows:
Next, our proposed estimators for the Binomial thinning and the Binomial innovation () and for the Poisson thinning and the Poisson innovation (
) are obtained as follows:
For both cases of the Binomial distribution and the Poisson distribution, is greatly changed by our proposed estimation. In contrast, there is not much change with respect to
.
Finally, we evaluate the goodness of fit for each estimator based on AIC. Denote AIC for an estimator under the Binomial distribution by
, and under the Poisson distribution by
. Then, we obtained
From the above results, we can see that our proposed estimators take good performance in terms of goodness of fit.
Acknowledgements
We thank the anonymous referees for constructive comments. This work was supported by JSPS KAKENHI, Grant Number JP16K00036.
Additional information
Funding
Notes on contributors
Hiroshi Shiraishi
Hiroshi Shiraishi received the BS degree in mathematics in 1998 and the MS and Dr degrees in mathematical science from Waseda University, Japan in 2004 and 2007, respectively. He joined the GE Edison Life Insurance Company, the Prudential Life Insurance Company of Japan and the Hannover-Re Reinsurance Company, in 1998, 2000 and 2005, respectively. His research interests are actuarial science, time series analysis, econometric theory and financial engineering. In particular, he investigates the statistical analysis of discrete-valued time series/the statistical estimation of optimal dividend problems in the field of the actuarial science/the statistical estimation of Hawkes graphs and so on. He is currently an associate professor in the Department of Mathematics, Keio University, Japan. He is a fellowof the Institute of Actuary of Japan (FIAJ).
References
- Al-Osh, M. A., & Alzaid, A. A. (1987). First-order integer-valued autoregressive (INAR(1)) process. Journal of Time Series Analysis, 8(3), 261–18. doi:10.1111/j.1467-9892.1987.tb00438.x
- Alzaid, A. A., & Al-Osh, M. A. (1990). An integer-valued pth-order autoregressive structure (INAR(p)) process. Journal of Applied Probability, 27(2), 314–324. doi:10.2307/3214650
- Bu, R., McCabe, B., & Hadri, K. (2008). Maximum likelihood estimation of higher-order integer-valued autoregressive processes. Journal of Time Series Analysis, 29(6), 973–994. doi:10.1111/j.1467-9892.2008.00590.x
- Cox, D. R., & Hinkley, D. (1974). Theoretical statistics. London: Chapman and Hall.
- Drost, F. C., Van Den Akker, R., & Werker, B. J. M. (2008). Local asymptotic normality and efficient estimation for INAR (p) models. Journal of Time Series Analysis, 29(5), 783–801. doi:10.1111/j.1467-9892.2008.00581.x
- Du, J. G., & Li, Y. (1991). The integer-valued autoregressive (INAR(p)) model. Journal of Time Series Analysis, 12(2), 129–142. doi:10.1111/j.1467-9892.1991.tb00073.x
- Franke, J., & Subba Rao, T. 1993. Multivariate first-order integer-valued autoregression. Technical report No.95, Universität Kaiserslautern.
- Karlis, D., & Pedeli, X. (2013). Flexible bivariate INAR(1) processes using copulas. Communications in Statistics-Theory and Methods, 42(4), 723–740. doi:10.1080/03610926.2012.754466
- Latour, A. (1997). The multivariate GINAR(p) process. Advances in Applied Probability, 29(1), 228–248. doi:10.2307/1427868
- Latour, A. (1998). Existence and stochastic structure of a non-negative integer-valued autoregressive process. Journal of Time Series Analysis, 19(4), 439–455. doi:10.1111/jtsa.1998.19.issue-4
- McKenzie, E. (1985). Some simple models for discrete variate time series. Water Resources Bulletin, 21(4), 645–650. doi:10.1111/j.1752-1688.1985.tb05379.x
- McKenzie, E. (1988). Some ARMA models for dependent sequences of Poisson counts. Advances in Applied Probability, 20(4), 822–835. doi:10.2307/1427362
- Ristić, M. M., Bakouch, H. S., & Nastić, A. S. (2009). A new geometric first-order integer-valued autoregressive (NGINAR(1)) process. Journal of Statistical Planning and Inference, 139(7), 2218–2226. doi:10.1016/j.jspi.2008.10.007
- Serfling, R. (2011). Asymptotic relative efficiency in estimation. In M. Lovric (Ed.), International encyclopedia of statistical science, (pp. 68–82). Berlin, Heidelberg: Springer.
- Weiß, C. H. (2018). An introduction to discrete-valued time series. Chichester: John Wiley & Sons.
Appendix
Proof of Theorem 1 The proof is similar to that for Theorem 1 in Drost et al. (Citation2008).
Expansion of the log-likelihood ratio: Let with
. Under Assumption (A1), we obtain by Taylor’s theorem,
where is a random point on the line-segment between
and
and
Then, we show
Part 0: auxiliary calculations
Part 1:
Part 2:
Part 3: non-singularity of
In what follows, for simplicity, we write and
for
with
.
Part 0: We first show that the existence of . To do so, we need to show for each
It can be shown by Assumptions (A4) and (A6).□
Part 1: From Equations (3) and (4), it follows that
since and
are independent of
. Let
and
. From the above equations, it follows that
and by Part 0, it follows that
Hence, we have, by Lemma B.1 of Drost et al. (Citation2008),
An application of the Cramér-Wold device concludes the proof of Part 1.□
Part 2: Assumption (A3) implies that, for fixed and for each
, the mapping
is continuous, respectively. Since we have already proved (9) in Part 0, by Lemma B.3 of Drost et al. (Citation2008), the proof is completed if we have where
For and
, it follows that from Equation (3)
where
and
which implies that
where the third equation follows the independence between and
. This result and Lemma B.3 of Drost et al. (Citation2008) yield
By the same argument, we obtain
This completes the proof of Part 2.
Part 3: The proof of the non-singularity for is provided by Assumption (A5) in the same way as Drost et al. (Citation2008).
Proof of Theorem 2 The proof is the same as Theorem 3.2 of Drost et al. (Citation2008).
To calculate the one-step estimator , we need to know the score functions
and
for each distribution. In what follows, we show the derivation of these functions for Cases 1 and 2 in Section 4.
Derivation of the score for the Case 1 For Case 1, the probability functions
and
are given by
for , which implies that the derivatives
and
are written as
Let
for and
. Let
and
for
. Then, we obtain for
where and
.
The derivation of the score for Case 2 For Case 2, the probability functions
and
are given by
for , which implies that the derivatives
and
are written by
Let
and
for . Then, we obtain for
where and
□