
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The Almon technique is widely used to estimate the parameters of the distributed lag model (DLM). The technique suffers a setback from the challenge of multicollinearity because the explanatory variables and their lagged values are often correlated. The Almon-Ridge estimator (A-RE) and Almon-Liu estimator (A-LE) were introduced as alternative estimators for efficient modelling. We developed a new method of estimating the coefficients of the DLM using the Almon-KL estimator (A-KLE). A-KLE dominates the other estimators considered in this study via theoretical findings, simulation design and two numerical examples. The estimators’ performance was compared using the mean squared error.
1. Introduction
Distributed lag model (DLM) is a model that is commonly adopted to predict the current values of a response variable based on both the current values of a regressor (explanatory variable) and its lagged values (Cromwell, Hannan, Labys, & Terraza, Citation1994; Judge, Griffiths, Hill, & Lee, Citation1980). For instance, the effect of public investment such as road and highways construction on growth in the gross national product (GNP) will show up with a lag, and this effect will likely linger on for some years (Maddala, Citation1974). Under certain assumptions, the ordinary least squares estimator (OLSE) is the easiest method of estimating the distributed lags’ parameters. The assumptions include assuming a fixed maximum lag; the error should be normally distributed and unrestricted relationship among the lagged explanators. However, multicollinearity arises from the relationship between the explanatory variables and their lagged explanators, resulting in a large variance of the coefficient estimates. The OLSE becomes inefficient when there is multicollinearity. Also, the method suffers a breakdown when the number of observations does not sufficiently exceed the number of lags (Almon, Citation1965; Fisher, Citation1937; Frost, Citation1975; Maddala, Citation1974). Almon technique proposed by Almon (Fisher, Citation1937) is widely used to estimate the parameters of DLM because the methods reduced the effect of multicollinearity (Fair & Jaffee, Citation1971; Majid, Aslam, Altaf, & Amanullah, Citation2019). The assumption under the Almon lag model is that there must be a finite lag length and the lag weight approximated by a polynomial of suitable degree.
The Almon estimator (AE) is the best linear unbiased estimator (BLUE) for the DLMs (Vinod & Ullah, Citation1981). Therefore, this estimator has widespread usage in applied econometrics due to its ease of estimation. However, the estimator still suffers a breakdown when there is a high correlation among the explanatory variables. Biased estimators were developed as alternatives to the OLS estimator in the linear regression model (LRM) (Baye & Parker, Citation1984; Hoerl & Kennard, Citation1970; Kaçıranlar & Sakallıoğlu, Citation2001; Kibria & Lukman, Citation2020; Li & Yang, Citation2012; Liu, Citation1993; Lukman, Ayinde, Kibria, & Adewuyi, Citation2020; Massy, Citation1965; Swindel, Citation1976). Some of these estimators have been adapted to AE to mitigate the effect of multicollinearity.
The ridge estimator was suggested as an alternative to the AE (Chanda & Maddala, Citation1984; Lindley & Smith, Citation1972; Lukman, Ayinde, Binuomote, & Onate, Citation2019; Maddala, Citation1974; Vinod & Ullah, Citation1981; Yeo & Trivedi, Citation2009). The limitation of the ridge regression estimator for the DLMs was pointed out in the following study (Lindley & Smith, Citation1972; Maddala, Citation1974; Yeo & Trivedi, Citation2009). According to Maddala (Citation1974) and Yeo and Trivedi (Citation2009), the empirical findings do not fulfil expectations despite adopting different ridge parameters, k. Alternative estimators include the Almon modified ridge and Liu estimators (Gültay & Kaçıranlar, Citation2015). Özbay & Kaçıranlar (Citation2017) introduced the Almon two-parameter estimator to deal with the problem of multicollinearity for the DLM. The estimator extends the two-parameter estimation procedure by Özkale and Kaçıranlar (Citation2007) to the DLM. The Almon two-parameter ridge was also developed to handle multicollinearity in DLM (Lipovetsky, Citation2006; Lipovetsky & Conklin, Citation2005; Ozbay, Citation2019). Kibria and Lukman (Citation2020) developed the Kibria–Lukman estimator (KLE) to cushion the effect of multicollinearity in the LRM. The estimator gain advantage over the ridge and the Liu estimator. Thus, the focus of this study is to develop the Almon-KL estimator (A-KLE) based on KLE.
The other part of the article is structured as follows: we introduced the DLM, its estimation methods, and the proposed estimator in Section 2. Section 3 deals with the theoretical comparisons and the choice of biasing parameters. We examined the estimators’ performance using a simulation study and two examples in Sections 4 and 5, respectively. Finally, we provide a concluding remark.
2. Distributed lag model (DLM) and method of estimation
The finite DLM is defined as
(2.1)
(2.1)
where
are the current and lagged coefficients of
denotes the t-th observation on the response variable
denotes the (t-p)th observation on the explanatory variable
is the disturbance term corresponding to the t-th observation and is assumed to be IN(0,
) and p denotes the lag length. Model Equation(2.1)
(2.1)
(2.1) can be written in matrix form as
(2.2)
(2.2)
where
The OLSE of is
(2.3)
(2.3)
The OLS estimator of is BLUE when there is no violation of the model assumptions (Lukman et al., Citation2019). As earlier mentioned, there is high tendency of multicollinearity among the regressors since lags of the same explanatory variable appear in the model (Güler, Gültay, & Kaçiranlar, Citation2015; Gültay & Kaçıranlar, Citation2015). It becomes difficult to estimate with the conventional OLS when the lag length (p) is known and large (Güler et al., Citation2015; Gültay & Kaçıranlar, Citation2015; Ozbay, Citation2019; Özbay & Kaçıranlar, Citation2017). The Almon polynomial lag distribution was recommended as a replacement to the OLS estimator (Almon, Citation1965). The Almon polynomial lag is defined as
(2.4)
(2.4)
The above equation can simply be written as
(2.5)
(2.5)
where
and
are
vector and
matrix, respectively. The ranks of matrices
and
are assumed to be
and
respectively. If
then the rank of A is s + 1. We substitute Equation(2.5)
(2.5)
(2.5) into Equation(2.2)
(2.2)
(2.2) and obtained the new equation as,
(2.6)
(2.6)
where
The OLS estimator of Equation(2.6)
(2.6)
(2.6) becomes the AE in Equation(2.7)
(2.7)
(2.7) :
(2.7)
(2.7)
such that
(2.8)
(2.8)
EquationEquation (2.8)(2.8)
(2.8) is referred to as AE of
which is still BLUE. A notable problem with this technique centered on the choice of lag length and the degree of the polynomial, respectively because the two are unknown in practice. One of the suggested means of selecting the lag length is to select a reasonable lag and check if it fit the model Equation(2.1)
(2.1)
(2.1) using any of the following criteria: Akaike information criterion (AIC), Bayesian information criterion (BIC) and adjusted coefficient of determination
(Davidson & MacKinnon, Citation1993). The ridge estimator was suggested as an alternative approach due to the limitation of the AE. The Almon-Ridge estimator (A-RE) of
is defined as
(2.9)
(2.9)
where
Özbay and Toker (Citation2021) examined the predictive performance of A-RE. According to Gültay & Kaçıranlar (Citation2015), the Almon-Liu estimator (A-LE) is defined as:
(2.10)
(2.10)
where
The Liu estimator overcomes the limitation in the ridge estimator for the LRM. Recently, Kibria and Lukman (Citation2020) developed the KL estimator (KLE) to mitigate multicollinearity in the LRM. The estimator is a modification of the Liu estimator; it gained an advantage over the Liu estimator using the mean squared error. The bias of KLE is two times lower than the bias of the ridge estimator. Thus, the KL estimator performs better than the ridge and the Liu estimators. Following this merit, the estimator is adapted to the AE to handle multicollinearity in this study. The A-KLE is defined as
(2.11)
(2.11)
where
Suppose and
such that
are the ordered eigenvalues of
and
is the matrix whose columns are the eigenvectors of
and the canonical form of the estimators are as follows:
(2.12)
(2.12)
(2.13)
(2.13)
(2.14)
(2.14)
(2.15)
(2.15)
The statistical properties of A-KLE are as follows:
The bias of the A-KLE is defined as:
(2.16)
(2.16)
where
The variance of the A-KLE is defined as:
(2.17)
(2.17)
Therefore, the mean square error matrix (MSEM) and the scalar mean square error (SMSE) of A-KLE, respectively, are
(2.18)
(2.18)
and
(2.19)
(2.19)
3. Theoretical comparisons among the estimators
In this section, we adopted Lemma 3.1 to evaluate the estimators’ performance.
Lemma 3.1.
Let and
be two linear estimators of
The difference in the covariance of the two estimators
is positive definite if and only if
Consequently,
(R Core Team, Citation2020; Trenkler & Toutenburg, Citation1990).
3.1. Comparison between  and
and
Theorem 3.1.
The estimator is preferred to
in the MSEM sense, if and only if,
where
Proof.
(3.1)
(3.1)
It is noted that is non-negative (nn) because
for
3.2. Comparison between and
Theorem 3.2.
The estimator is preferred to
in the MSEM sense, if and only if,
where
and
Proof.
(3.2)
(3.2)
It is noted that is non-negative because
for
3.3. Comparison between and
Theorem 3.3.
The estimator is preferred to
in MSEM sense if and only if,
where
and
Proof.
(3.3)
(3.3)
It is noted that is non-negative since
for
and
4. Monte Carlo simulation study
We conducted a simulation study for DLM to explore the estimators’ performance. The dependent variable and explanatory variables are generated according to the following study (Güler et al., Citation2015; Özbay & Kaçıranlar, Citation2017; Özbay & Toker, Citation2021). (4.1)
(4.1)
(4.2)
(4.2)
(4.3)
(4.3)
where
denotes the correlation between the regressors and its values are chosen as follows: 0.8, 0.9, 0.99, and 0.999. The MSE is minimized subject to the constraint
(Güler et al., Citation2015; Özbay & Kaçıranlar, Citation2017; Özbay & Toker, Citation2021).
and
are generated such that
and
respectively. The choices of
are 1, 5 and 10. The data for each replication are determined in accordance with the following studies (Güler et al., Citation2015; Özbay & Kaçıranlar, Citation2017; Özbay & Toker, Citation2021). An observation of T-p = 60 and 100 with the lag length of 8 and 16 was evaluated. The experiment is repeated 2000 times using the RStudio programming language (R Core Team, Citation2020). The model (4.1) is transformed back to the Almon model Equation(2.6)
(2.6)
(2.6) after generating the observations. The mean squared error is obtained as follows:
(4.4)
(4.4)
where
denotes the estimate of the ith parameter in jth replication and
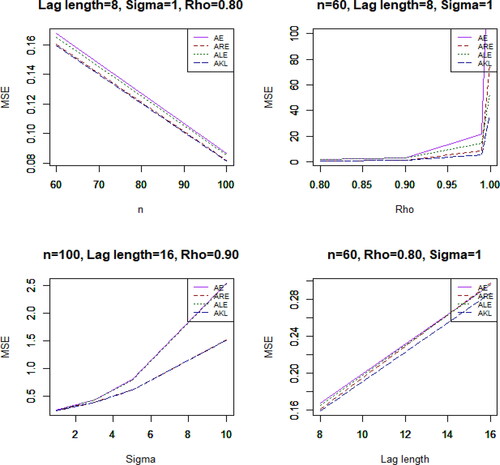
is the true parameter values. The simulated MSE values are presented in and for lag length are 8 and 16, respectively.
Table 1. Estimated MSE’s when lag length is 8.
Table 2. Estimated MSE’s when lag length is 16.
From and , we observed the following trend about the mean squared error. The mean squared error increases as the following increases: level of multicollinearity, lag length, and the error variance. The mean squared error decreases as the sample size increase. This trend is more feasible considering . The results show that AE suffers setback when the regressors are correlated. The biased estimators provide a more consistent estimate when there is multicollinearity. However, the A-KLE produces the best result by producing smaller mean squared error among all the estimators under study.
Figure 1. Graphical illustration of the simulation result.
5. Applications
To illustrate the theoretical findings of the paper, we consider the two real datasets.
5.1. Application example I
The Almon dataset is employed to illustrate the performances of each of the estimators (Almon, Citation1965). These data are quarterly data that spanned from 1953 to 1967 with expenditures as the response variable and appropriations as the independent variable. Following Güler et al. (Citation2015), the lag length is taken to be 8 and the lag weight approximated by a polynomial of order 2. The eigenvalues of are computed to be 2.388929e + 13, 1.628323e + 09, 4.312742e + 07, and 4.782067e + 00, respectively. The condition index of
is determined to be 2235083, which revealed the presence of severe multicollinearity among the explanatory variable and its lagged variables. The library dLagM in RStudio is used to analyse the data. The biasing parameter for A-RE and A-KLE is computed using:
(5.1)
(5.1)
The biasing parameter for the A-LE is obtained using the following:
(5.2)
(5.2)
The regression parameter before transformation is presented in as follows:
By canonical transformation, the matrix
is the matrix of the eigenvectors,
is a
diagonal matrix of eigenvalues of
such that
The Almon-estimators of
are presented in . The result in supports the fact that the Almon-estimator suffers set back when there is multicollinearity. The regression coefficient of the biased estimators appears very similar. The A-KLEr has the lowest mean squared error followed by the A-RE.
Table 3. Estimates and t-tests for beta coefficients.
Table 4. Estimates for the Almon coefficients.
Table 5. Estimates and t-tests for beta coefficients.
5.2. Application example II
This dataset is composed of monthly global mean sea level (GMSL) (compared to 1993–2008 average) series by CSIRO, land ocean temperature anomalies (1951–1980 as a baseline period) by GISS, NASA, and monthly Southern Oscillation Index (SOI) by Australian Government Bureau of Meteorology (BOM) between July 1885 and June 2013 (Church & White, Citation2011; Demirhan, Citation2020). In this study, the response and the explanatory variables were chosen to be GMSL and land ocean temperature anomalies, respectively. The dataset is available in the R package data (seaLevelTempSOI). More detail on the data description is available in the study of Demirhan (Citation2020). The lag length is taken to be 4 and the lag weight approximated by a polynomial of order 2 (Demirhan, Citation2020). The eigenvalues of are computed to be 6607.86, 1590.99, 67.12 and 6.96, respectively. The condition number is 948.82 which shows that the explanatory variable and its lagged variables are correlated. The regression parameter before canonical transformation is presented in Table 5.
By canonical transformation, the Almon-estimators of are in . From , the Almon-estimator for the second lag has a positive sign as opposed a negative sign by other estimators. As mentioned earlier, one of the effects of multicollinearity on the AE is that the coefficients can occasionally exhibit a wrong sign. The results show that the new estimator has the lowest mean squared error. This result agrees with the theoretical and simulation result.
Table 6. Estimates for the Almon coefficients.
6. Some concluding remarks
The DLM is often adopted to predict the current values of a response variable based on both the current values of a regressor and its lagged values. Multicollinearity arises from the relationship between the regressors and their lagged explanators. The AE is popularly used to estimate the parameters of the models. However, the estimator suffers a setback when there is multicollinearity. The A-RE and A-LE estimators were suggested as alternative techniques. In this study, we developed the A-KLE to mitigate the threat of multicollinearity for the DLM. We theoretically proved that A-KLE dominates AE, A-RE and A-LE. The theoretical findings were supported by the results of the simulation study and two numerical examples.
Acknowledgements
This paper was written and completed while the first author visited Professor B. M. Golam Kibria at Florida International University from April 1 to 30, 2021. The International Mathematical Union sponsored this trip.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Almon, S. (1965). The distributed lag between capital appropriations and expenditures. Econometrica, 30, 96–178.
- Baye, M. R., & Parker, F. D. (1984). Combining ridge and principal component regression: A money demand illustration. Communications in Statistics - Theory and Methods, 13(2), 197–205. doi:https://doi.org/10.1080/03610928408828675
- Chanda, A. K., & Maddala, G. S. (1984). Ridge estimators for distributed lag models. Communications in Statistics-Theory and Methods, 13(2), 217–225.
- Church, J. A., & White, N. J. (2011). Sea-level rise from the late 19th to the early 21st century. Surveys in Geophysics, 32(4–5), 585–602. doi:https://doi.org/10.1007/s10712-011-9119-1
- Cromwell, J. B., Hannan, M. J., Labys, W. C., & Terraza, M. (1994). Multivariate tests for time series models. Thousand Oaks, CA: Sage.
- Davidson, R., & MacKinnon, J. G. (1993). Estimation and inference in econometrics. Oxford: Oxford University Press.
- Demirhan, H. (2020). dLagM: An R package for distributed lag models and ARDL bounds testing. PLoS One, 15(2), e0228812. doi:https://doi.org/10.1371/journal.pone.0228812
- Fair, C. R., & Jaffee, M. D. (1971). A note on the estimation of polynomial distributed lags (Econometric Research Program Research Memorandum No. 120). Berkeley: University of California, Berkeley School of Law.
- Fisher, I. (1937). Income in theory and income taxation practice. Econometrica, 5(1), 1–55. doi:https://doi.org/10.2307/1905400
- Frost, P. A. (1975). Some properties of the Almon lag technique when one searches for degree of polynomial and lag. Journal of the American Statistical Association, 70(351), 606–612. doi:https://doi.org/10.2307/2285941
- Güler, H., Gültay, B., & Kaçiranlar, S. (2015). Comparisons of the alternative biased estimators for the distributed lag models. Communications in Statistics - Simulation and Computation. doi:https://doi.org/10.1080/03610918.2015.1053919
- Gültay, B., & Kaçıranlar, S. (2015). Mean square error comparisons of the alternative estimators for the distributed lag models. Hacettepe Journal of Mathematics and Statistics, 44(5), 1215–1233.
- Hoerl, A. E., & Kennard, R. W. (1970). Ridge regression: Biased estimation for non orthogonal problems. Technometrics, 12(1), 69–82. doi:https://doi.org/10.1080/00401706.1970.10488635
- Judge, G. G., Griffiths, W. E., Hill, R. C., & Lee, T. (1980). The theory and practice of econometrics. New York, NY: Wiley (pp. 637–660).
- Kaçıranlar, S., & Sakallıoğlu, S. (2001). Combining the Liu estimator and the principal component regression estimator. Communications in Statistics - Theory and Methods, 30(12), 2699–2705. doi:https://doi.org/10.1081/STA-100108454
- Kibria, G. B. M., & Lukman, A. F. (2020). A new ridge-type estimator for the linear regression model: Simulations and applications. Scientifica, 2020, 1–16. doi:https://doi.org/10.1155/2020/9758378
- Li, Y., & Yang, H. (2012). A new Liu-type estimator in linear regression model. Statistical Papers, 53(2), 427–437. doi:https://doi.org/10.1007/s00362-010-0349-y
- Lindley, D. V., & Smith, A. F. M. (1972). Bayes estimates for the linear model. Journal of the Royal Statistical Society: Series B (Methodological), 34(1), 1–41. doi:https://doi.org/10.1111/j.2517-6161.1972.tb00885.x
- Lipovetsky, S. (2006). Two parameter ridge regression and its convergence to the eventual pairwise model. Mathematical and Computer Modeling, 44(3–4), 304–318. doi:https://doi.org/10.1016/j.mcm.2006.01.017
- Lipovetsky, S., & Conklin, W. M. (2005). Ridge regression in two parameter solution. Applied Stochastic Models in Business and Industry, 21(6), 525–540. doi:https://doi.org/10.1002/asmb.603
- Liu, K. (1993). A new class of biased estimate in linear regression. Communication in Statistics-Theory and Methods, 22(2), 393–402.
- Lukman, A. F., Ayinde, K., Binuomote, S., & Onate, A. C. (2019). Modified ridge‐type estimator to combat multicollinearity: Application to chemical data. Journal of Chemometrics, 33(5), e3125. doi:https://doi.org/10.1002/cem.3125
- Lukman, A. F., Ayinde, K., Kibria, G. B. M., & Adewuyi, E. (2020). Modified ridge-type estimator for the gamma regression model. Communications in Statistics - Simulation and Computation, 1–15. doi:https://doi.org/10.1080/03610918.2020.1752720
- Maddala, G. S. (1974). Ridge estimator for distributed lag models (NBER Working Paper Series No. 69). Cambridge, MA: National Bureau of Economic Research.
- Majid, A., Aslam, M., Altaf, S., & Amanullah, M. (2019). Addressing the distributed lag models with heteroscedastic errors. Communications in Statistics - Simulation and Computation, 1–19. doi:https://doi.org/10.1080/03610918.2019.1643884
- Massy, W. F. (1965). Principal component regression in explanatory statistical research. Journal of the American Statistical Association, 60(309), 234–256. doi:https://doi.org/10.1080/01621459.1965.10480787
- Ozbay, N. (2019). Two-parameter ridge estimation for the coefficients of Almon distributed lag model. Iranian Journal of Science and Technology, Transactions A: Science, 43 (4), 1819–1828.
- Özbay, N., & Kaçıranlar, S. (2017). The Almon two parameter estimator for the distributed lag models. Journal of Statistical Computation and Simulation, 87(4), 834–843. doi:https://doi.org/10.1080/00949655.2016.1229317
- Özbay, N., & Toker, S. (2021). Prediction framework in a distributed lag model with a target function: An application to global warming data. Environmental and Ecological Statistics, 28(1), 87–134. doi:https://doi.org/10.1007/s10651-020-00477-x
- Özkale, M. R., & Kaçıranlar, S. (2007). The restricted and unrestricted two parameter estimators. Communications in Statistics - Theory and Methods, 36(15), 2707–2725. doi:https://doi.org/10.1080/03610920701386877
- R Core Team. (2020). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.R-project.org.
- Swindel, B. (1976). Good ridge estimators based on prior information. Communication in Statistics-Theory and Methods, A5, 1065–1075.
- Trenkler, G., & Toutenburg, H. (1990). Mean squared error matrix comparisons between biased estimators—An overview of recent results. Statistical Papers, 31(1), 165–179. doi:https://doi.org/10.1007/BF02924687
- Vinod, H. D., & Ullah, A. (1981). Recent advances in regression methods. New York, NY: Marcel Dekker (pp. 226–238).
- Yeo, S. J., & Trivedi, P. K. (2009). On using ridge-type estimators for a distributed lag model. Oxford Bulletin of Economics and Statistics, 51(1), 85–90. doi:https://doi.org/10.1111/j.1468-0084.1989.mp51001006.x