 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
For ease of instruction in the classroom, the one-way analysis of variance F statistic is rewritten in terms of pairwise differences in individual sample means instead of differences of individual sample means from the overall sample mean. Likewise, the Kruskal–Wallis statistic may be rewritten in terms of pairwise differences in individual average ranks rather than differences of individual average ranks from the overall average rank. In unbalanced designs, it is seen that the contribution to either test statistic from a pair of samples is related to the product of the sample sizes multiplied by the square of the relevant pairwise difference. Supplementary materials for this article are available online.
1 F Statistic Alternate Form
In the one-way analysis of variance (ANOVA) test of the equality of means, assuming independent samples from normal populations with a common variance, the F statisticis used to determine the p-value
. Here, for sample i, ni
observations are observed with a sample mean
and a sample standard deviation si
. Also, g is the number of populations we are sampling from, with an overall sample average of
where
is the total sample size, and
is a weighted average (“pooled”) estimate of the common variance.
Intuitively, we fail to reject the null hypothesis when the F statistic is “small,” and we reject the null hypothesis when the F statistic is “large.” When discussing this with students I indicate that if all the sample means are close, then they must also be close to the overall sample average
, and this makes each of the summands
in the numerator of the F statistic small. Likewise, each sample average
substantially different than the overall sample average gives rise to a large value of
and, consequentially, contributes to a large F statistic.
I contend that the intuitive discussion of “small” versus “large” F is more easily held if the various sample means are compared with each other rather than with the overall sample average. In particular, some algebra (proof available from the author) reveals(1)
(1) where the summation in the right-hand expression is over all
pairs of
. For instance, with g = 3 populations, this summation has
terms, and is given by
The good news with this alternate form for F is that we can readily see that:
Large contributions to the F statistic occur when pairs of sample means are substantially different.
In the unbalanced situation (i.e., different sample sizes), the contribution of
to the size of the F statistic depends not only on the difference in sample means, but also on the product of the sample sizes.
An outline of a classroom worksheet which helps students see these advantages is given as a supplement to this article. This worksheet also points out the disadvantage of potentially needing to sum quite a few more terms, , than the g terms needed with the standard F statistic.
Two other quick notes about the alternate form are in order. First, the alternate form of the one-way ANOVA F statistic readily reduces to a familiar form when testing the equality of g = 2 means (again, in the equal variance case). In particular, we find
This is just the square of the t statistic in the two independent sample test of the equality of means (technically, . Note that t is large in magnitude, causing us to reject
, if and only if F is large.
Second, in the balanced sample case—say that each sample size so that n = gs, note that the F statistic reduces to
This special case of the alternate F statistic, but not that for the general unbalanced case, appears as an exercise in Casella and Berger (Citation2002) (exercise 11.12, p. 565). The authors state in this exercise that this result was “communicated by George McCabe, who learned it from John Tukey.”
To illustrate computing with the alternate form, we consider the blood lead levels of children of battery plant workers who are exposed to lead dust and vapor. As is well-established, lead exposure has a number of negative health consequences, especially for growing children (Centers for Disease Control Citation2021). From Morton (Citation1982), p. 554, we have the blood lead levels of children by parental lead exposure level: Workers with Low exposure, Medium exposure, and High exposure to lead, as determined by the plant manager. The data are shown in , and boxplots of lead level by exposure level appear in .
Fig. 1 Child blood lead levels by parent lead exposure level.
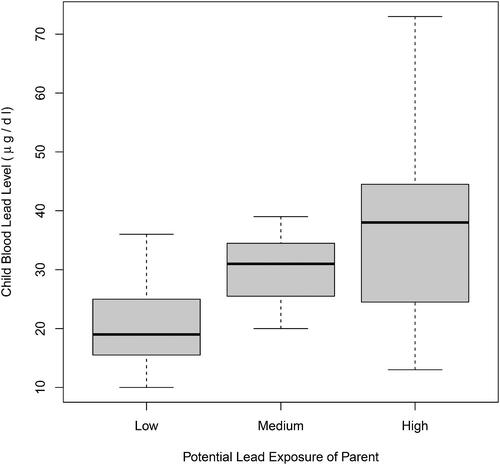
Table 1 Child blood lead levels by parent exposure level.
In this case, using the alternate form, we find
If the necessary assumptions are true, then under the null hypothesis this F statistic follows an F distribution with 2 numerator degrees of freedom and 31 denominator degrees of freedom. This gives a p-value of about 0.016 so, for example, with a significance level of 0.05 we reject the hypothesis of equal mean blood lead levels across the three exposure levels.
Furthermore, using the alternate form we may state what fraction of the F statistic is attached to each of the pairs of samples as shown in .
Table 2 Contributions to the F statistic by pairs of samples.
2 Kruskal–Wallis Statistic Alternate Form
A similar alternate form may be given for the Kruskal–Wallis test of equal distributions. Here the standard test statistic iswhere
is the average rank of the observations from sample i. The rest of the notation is as above. If the null hypothesis is true, then K will follow an approximate
distribution, with degrees of freedom
. (This approximation is generally considered good with g = 3 groups if the samples sizes are all at least 5, and with g larger than 3 if the sample sizes are all at least 4. See, e.g., Rice Citation1995).
The average of the assigned ranks , n is
. Consequently, K is large when there are some average ranks
that are far from the overall average rank of
. As with the F statistic above, however, one may compare pairs of average ranks directly in determining the size of the Kruskal–Wallis statistic. Some algebra gives
(2)
(2)
So, as before, the good news with this alternate form for K is that we can readily see:
Large contributions to the K statistic occur when pairs of average ranks are substantially different.
In the unbalanced situation (i.e., different sample sizes), the contribution of
In the balanced sample case—say that each sample size so that n = gs, note that the K statistic reduces to
For the lead example above K can be shown to be 8.51 with an associated p-value of 0.014. (Average ranks were assigned to ties—rank 11.5 for the two values of 23, rank 18.5 for the two values of 34, rank 20.5 for the two values of 35, and rank 25.5 for the two values of 39. For simplicity, no correction term was included for ties.) Consequently, we reject the hypothesis of equal blood lead level distributions across the three exposure levels at the 0.05 level.
For the K statistic it can be shown, using 3. above, that 10.4% is due to the difference in the Low and Medium exposure groups, 11.0% is due to the difference in the Medium and High exposure groups, and 78.6% is due to the difference in the Low and High exposure groups.
3 Closing Comment
The various alternate forms of the one-way ANOVA F statistic and the Kruskal–Wallis statistic are scarce in the balanced sample case and possibly non-existent in the unbalanced sample case within the statistical literature. However, these alternate forms are similar in spirit to a result concerning the computation of the sample variance which does have some visibility in the statistical literature. In particular, given data values , the sample variance may be written without reference to the sample mean:
This result may be found, for example, in Heffernan (Citation1988), and even appeared on the cover of the journal Teaching Statistics in 2009 (vol. 31, no. 2).
Supplemental Material
Download MS Word (73.3 KB)Supplementary Materials
In the supplement, we provide exercises for students to investigate the alternate forms of the one-way ANOVA F and Kruskal-Wallis test statistics. Notes for instructors on these exercises are also provided.
References
- Casella, G., and Berger, R. L. (2002), Statistical Inference, 2nd ed., Pacific Grove, CA: Duxbury.
- Centers for Disease Control (2021), “Health Effects of Lead Exposure,” https://www.cdc.gov/nceh/lead/prevention/health-effects.htm, Accessed 4 September 2021.
- Heffernan, P. (1988), “New Measures of Spread and a Simpler Formula for the Normal Distribution,” The American Statistician, 42, 100–102.
- Morton, D. E., Saah, A. J., Silberg, S. L., Owens, W. L., Roberts, M. A., and Saah, M. D. (1982), “Lead Absorption in Children of Employees in a Lead-Related Industry,” American Journal of Epidemiology, 115, 549–555.
- Rice, J. (1995), Mathematical Statistics and Data Analysis, 2nd ed., Belmont, CA: Duxbury Press, p. 454.