ABSTRACT
This article synthesizes ideas that emerged over the course of a 10-week symposium titled “Teaching Reproducible Research: Educational Outcomes” https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium that took place in the spring of 2021. The speakers included one linguist, three political scientists, seven psychologists, and three statisticians; about half of them were based in the United States and about half in the United Kingdom. The symposium focused on a particular form of reproducibility—namely computational reproducibility—and the paper begins with an exposition of what computational reproducibility is and how it can be achieved. Drawing on talks by the speakers and comments from participants, the paper then enumerates several reasons for which learning reproducible research methods enhance the education of college and university students; the benefits have partly to do with developing computational skills that prepare students for future education and employment, but they also have to do with their intellectual development more broadly. The article also distills insights from the symposium about practical strategies instructors can adopt to integrate reproducibility into their teaching, as well as to promote the practice among colleagues and throughout departmental curricula. The conceptual framework about the meaning and purposes of teaching reproducibility, and the practical guidance about how to get started, add up to an invitation to instructors to explore the potential for introducing reproducibility in their classes and research supervision.
1 Introduction
Project TIER https://www.projecttier.org (Teaching Integrity in Empirical Research) is one of the many initiatives that have emerged within the last decade or so dedicated to promoting transparency and reproducibility in quantitative research. In the spring of 2021, to create a forum for sharing experiences and ideas among these many actors, Project TIER collaborated with the UK Reproducibility Network https://www.ukrn.org (UKRN) and the Sheffield Methods Institute https://www.sheffield.ac.uk/smi (SMI), University of Sheffield, to organize a virtual symposium titled “Instruction in Reproducible Research: Educational Outcomes” https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium.
The symposium included ten presentations, each of which consisted of two parts. First, each speaker prerecorded a video of their talk for symposium participants to watch at their convenience. Then, roughly ten days after the video became available, a live discussion among the speaker, a moderator, and the general audience took place via video-conference.
The talks and discussions considered strategies for introducing reproducibility at many points in the curriculum, including both introductory and advanced courses in statistics, quantitative methods, and data science; topics courses in which students conduct data analysis; and supervision of theses and dissertations. The presenters included one linguist, three political scientists, seven psychologists, and three statistician/data scientists; about half of them were based at U.S. institutions and about half at U.K. institutions. A list of the speakers and the titles of their talks is provided in , and the videos of their talks can be accessed from the symposium website https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium.
Table 1 Symposium presentations: names of speakers and titles of talks.
This article synthesizes the main themes that emerged from the symposium. The purpose is to highlight practical lessons that could be of use to instructors contemplating introducing reproducibility into their classes and research supervision for the first time, as well as those who are already teaching reproducible methods and would like to expand their repertoire of strategies. Most of the symposium presentations focused on undergraduate education, but the lessons that emerged apply to the training of graduate students as well.
Although the symposium focused on education and pedagogy, the last few decades have witnessed a parallel increase in attention to the reproducibility of professional research. Evidence of widespread nonreproducibility of published research across the social and natural sciences has been accumulating for more than 35 years (see, e.g., Dewald, Thursby, and Anderson Citation1986; Bollen et al. Citation2015; Maniadis and Tufano Citation2017; Christensen and Miguel Citation2018). Recent efforts to ameliorate the problem have been undertaken by government research institutions (Holdren Citation2013; Bollen et al. 2015; National Academies of Sciences, Engineering, and Medicine (NASEM) Citation2019; National Institutes of Health (NIH) Citation2020), private foundations (notably the Alfred P. Sloan Foundation https://sloan.org, Arnold Ventures https://www.arnoldventures.org/about, and the Gordon and Betty Moore Foundation https://www.moore.org), and grass-roots academic organizations (notably BITSS https://www.bitss.org, COS https://www.cos.io, and UKRN https://www.ukrn.org). Numerous discipline-based professional societies have adopted policies requiring authors of statistical papers published in their journals to submit data and code that can be used to reproduce their results (Hoeffler Citation2017a).
This article begins with the what and why of teaching reproducible research.
Section 2 explains precisely what we mean by reproducibility, emphasizing the central role of documentation, and distinguishing between specifications (which define the documentation that should be provided for a completed project) and workflow (the process of incrementally constructing that documentation throughout the research process).
Section 3 explains why teaching reproducibility is important. The value lies partly in the credibility and usefulness of reproducible research, partly in enhanced student engagement and understanding of their work, and partly with broader aspects of intellectual development. Moreover, the principles of openness and transparency embodied in reproducible research methods inherently promote equity and inclusion.
The article then addresses the how of teaching reproducible research.
Section 4 suggests practical strategies that can be adopted by individual instructors wishing to integrate reproducibility into their teaching. A recurring theme in this section is the flexibility and adaptability of reproducible methods. Introducing reproducible methods does not require instructors to dramatically overhaul their courses and abandon the methods they are accustomed to; making incremental changes to the ways they teach quantitative research skills is often more effective.
Section 5 goes beyond questions of what instructors can do individually to introduce their students to reproducible methods and considers the potential benefits of coordination at the level of a department or program.
Section 6 concludes by proposing a vision of a world in which reproducible methods have been thoroughly and ubiquitously integrated into the quantitative methods training of students in the natural and social sciences.
2 What Do We Mean by Reproducibility? And what are the Keys to Teaching Reproducibility?
The notion of reproducibility addressed in the symposium was that of computational reproducibility, as used in the National Academies of Science, Engineering and Medicine (NASEM Citation2019) report on Replicability and Reproducibility in Science.Footnote1 That report defines reproducibility as “obtaining consistent results using the same input data; computational steps, methods, and code; and conditions of analysis” (p. 46). Like the NASEM report, we will use the terms reproducibility and computational reproducibility interchangeably. In the context of applied quantitative research, a study satisfies this definition of reproducibility if it would be possible for an independent third party to obtain the data used for the project, perform all the computational steps involved in processing and analyzing the data, and obtain results identical to those reported by the authors of the study.Footnote2
In practice, the key to computational reproducibility is documentation.
Researchers can ensure their results are reproducible by assembling and making publicly available a collection of electronic materials that we refer to as reproduction documentation, or simply documentation. To serve its purpose, reproduction documentation should contain everything necessary to enable an interested reader to independently reproduce all the computational steps involved in the data processing and analysis conducted for a project and generate results identical to those reported by the authors of the study.
The key to teaching reproducibility is, therefore, teaching students to construct documentation for their own work. It is useful to break down the task of documentation into two dimensions, which we refer to as specifications and workflow. Specifications define the contents and organization of the documentation that will be circulated and archived with the study after the research is complete; workflow refers to the process of constructing the documentation while conducting the research.
2.1 Specifications
Project TIER has formulated specifications for reproduction documentation in a set of standards known as the TIER Protocol https://www.projecttier.org/tier-protocol/protocol-4-0. The TIER Protocol was designed for students at early stages in their quantitative methods training, but meets the highest professional standards of reproducibility,Footnote3 and is applicable to the work of undergraduate and graduate students at all levels.
For a complete research paper, the main components of the documentation specified by the TIER Protocol include (a) copies of the data files used for the study, (b) scripts that execute the data processing and analysis that generate the results of the study, (c) output files that preserve the results as they are generated, and (d) various forms of supplementary information (such as codebooks, information on data provenance, and a read-me file).
The complete hierarchy of folders, subfolders, and files specified by the TIER Protocol is illustrated in . A complete exposition of the TIER Protocol, with detailed explanations of each component of the documentation https://www.projecttier.org/tier-protocol/protocol-4-0, can be found on the Project TIER website. To see examples of how the specifications of the TIER Protocol are manifested in a stylized research paper, see the Midlife Crisis Demo Project, https://www.projecttier.org/tier-protocol/demo-project also available on the TIER website.
Fig. 1 The TIER Protocol (version 4.0) default hierarchy of folders and files.
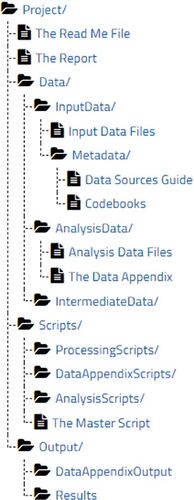
An initial perusal of the TIER Protocol may give the impression that it is highly didactic and rigid, but in fact it is meant to be flexible and adaptable. Note, for instance, that it does not prescribe a particular choice of software; it is written in language that applies to any scriptable statistical package. Many of the conventions it prescribes (the folder structure, the contents of the Read Me File and the Data Appendix, and the use of headers in scripts, to name just a few) are indeed highly detailed and specific. But the purpose of writing explicit and concrete specifications was to help novice students understand clearly what is expected of the documentation they produce for their projects. As explained in comments on the Project TIER website about Flexibility and Adaptability of the TIER Protocol, https://www.projecttier.org/tier-protocol/protocol-4-0//#/%3A/%7E/%3Atext/%3DFlexibility/%20and/%20Adaptability/%20of/%20the/%20TIER/%20Protocol more experienced students and researchers should feel free to modify the Protocol to suit their purposes. For example, the documentation required for a homework problem or a lab exercise in an introductory class may be much simpler than the documentation for a complete research paper. On the other hand, ensuring reproducibility of projects with exceptional computational demands may require additional measures such as preserving the entire computational environment with a tool such as Docker (Nüst, Sochat et al. Citation2020; Nüst, Eddelbuettel et al. Citation2020).
2.2 Workflow
The idea behind a reproducible workflow is that the documentation of a project should be integrated into the entire research process. The various components of the documentation should be constructed and assembled in tandem with every step of data collection, processing and analysis. Creating reproduction documentation is not a discrete task to be attended to after the substantial work for a project has been completed.
Before students even begin collecting data or other research materials, they should build a hierarchy of folders, following the structure of the TIER Protocol or any other organizational conventions they have chosen, where they can store their materials as their work progresses. As soon as a student obtains a file containing data for the project, they should save a copy in the appropriate folder in this hierarchy and assemble the associated metadata (such as codebooks and citations of the data sources). All the computations necessary to prepare the data for analysis and generate the results of the project should be executed with scripts, rather than by typing individual commands interactively or using point-and-click menus; these scripts are both the focal point of students’ work as they conduct their research and an essential component of the reproduction documentation for the completed project. When commands in the scripts generate output that will be included in the documentation—such as processed data files used in the analysis, or figures and tables presented in the final report—additional commands or options should save each piece of output in the appropriate folder.
When students have finished the data processing and analysis that generate their results, the reproduction documentation should be nearly complete. Some final cleaning up of scripts may be necessary (e.g., removing extraneous code, and being sure that they include sufficient comments), and it is important to do a final test to ensure that all the scripts run, but by the end of the project all the documentation should have been constructed and saved in the appropriate folders in the hierarchy created at the outset.
This workflow requires students to work deliberately. Establishing a folder hierarchy and writing relative directory paths that guide the software through the hierarchy ensure students think holistically about the structure of a project, and documenting each step of work before going on to the next requires them to keep track of the details. Initially, students may perceive the need to repeatedly pause, document, and plan as impediments to getting on with the substantive job of seeing what they can learn from their data. However, as noted by several symposium speakers and participants, students quickly begin to appreciate the benefits.
When students pay attention to where their data files, scripts, and other research documents are stored, they do not have to waste time searching for them each time they sit down to work on a project. And the value of executing and saving computations in scripts is brought home dramatically when, after getting deep into the processing and analysis of their data, students realize they need to change something they did earlier. When they understand they can make that change simply by editing a script—rather than going back to the beginning and reconstructing a long sequence of procedures that were executed interactively—their resistance to working in scripts breaks down. With a little experience (often less than a full semester in an introductory class), students learn that the efficiency gains achieved with a reproducible workflow outweigh the startup costs associated with the deliberate planning and documentation that is required.
3 Why is Teaching Reproducibility Important?
As noted by Ingram (Citation2021), teaching reproducible methods is valuable for a wide variety of reasons, ranging from concrete outcomes related to skills development and career readiness to intangible dimensions of intellectual development and citizenship.
3.1 Enhancing the Scientific Value of Research
Using reproducible methods increases the scientific value of students’ research and its usefulness to other scholars in several ways.
Assembling and sharing reproduction documentation makes it possible for an interested reader to check whether the results of a study are computationally reproducible, simply by running the scripts and seeing whether the results generated match those reported in the study. The widespread failures of reproducibility of published research that have persisted for several decades suggest it is important to be able to verify that a study is reproducible. Although showing that a study is computationally reproducible does not imply the methods or conclusions are correct, results that cannot be reproduced should be treated with skepticism (Peng Citation2011; Bollen et al. 2015).
Reproduction documentation can be used not only to reproduce the results reported in the paper, but also to explore questions not addressed in the paper and extend the research in new directions. Consider a typical paper that reports some descriptive statistics, presents the results of certain analyses, and conducts some robustness checks. Without documentation, readers know only what the authors chose to include in the paper. But when documentation is available, interested readers can explore the data without constraint, simply by editing the scripts included in the documentation. They can explore additional descriptive statistics, experiment with alternative analyses, and check other aspects of robustness. The ability to explore the data deepens the reader’s understanding of the original paper and may generate questions and hypotheses that stimulate new lines of research. Reproducibility thus facilitates a process of cumulative research, in which existing studies serve as foundations upon which new research is built.
Even for readers who do not choose to run the scripts for a study, reproduction documentation provides transparency. Details provided in research papers about decisions made during data processing and technical aspects of the analysis are often scattered throughout the text, footnotes, appendixes, and captions on figures and tables. Without documentation, putting these pieces of information together to get a coherent account of precisely what the authors did with their data is often difficult or impossible.
Scripts that execute all the computations performed on the data, assuming they are well-written and contain sufficient comments, remove any ambiguity about how the data were wrangled and analyzed.
For all of these reasons, reproducible methods are essential to good research practice, and therefore should be an integral part of research training.
3.2 Job and Career Readiness
For graduate students who plan to pursue careers in quantitative research, proficiency in reproducible research methods is essential. In light of the widespread reproducibility failures observed in the past, many academic journals and funders of research have adopted strong reproducibility policies, and such policies are becoming the norm. To succeed in this environment, scholars embarking on research careers now or in the future will need to be proficient in reproducible methods.
Training in reproducible methods is also beneficial to undergraduates seeking jobs. The skills in computation, data management, and documentation that are central to reproducible research are highly advantageous to candidates for internships or analyst/research assistant positions in government agencies, think tanks, and consulting firms. For students who do not go on to jobs that involve working with statistical data, the habits they develop by conducting reproducible research—establishing a systematic scheme for organizing the materials used for a project, working deliberately at every step, and documenting the entire process in a way that will be useful to others—will be of value in almost every field of employment.
3.3 Collaboration
Whether they enter careers in academia, government, nonprofits, or the private sector, the ability to collaborate with a team will be an essential skill for students entering the workforce. For tasks that involve data management and analysis, a reproducible workflow provides structure that facilitates collaboration.
A critical dimension of adopting a reproducible workflow is deciding on a number of conventions to be followed throughout a project—for example, conventions for naming and organizing files and folders, designating a working directory and using relative directory paths, writing headers at the beginning of scripts, and constructing codebooks and other types of metadata. Establishing these conventions at the outset of a project avoids misunderstandings and duplication of efforts among collaborators. Transparent documentation of every step of work also creates a record to which team members can refer if at any point questions arise about how they got to where they are at the moment. If there are personnel changes over the course of a project, having a well-defined set of conventions and transparent documentation of work completed to date facilitates the smooth hand-off of responsibilities from outgoing to incoming team members.
3.4 Mastery of Methods
Three symposium presenters (Bussberg Citation2021; Hayes-Harb Citation2021; Sullivan Citation2021) discussed how teaching reproducibility helps students develop a sense of mastery in the wrangling and analysis of statistical data.
Because they must work attentively and deliberately, students end up with a firm grasp on what they have done with their data and are able to discuss and write about their projects coherently. Executing all the computations by writing well-organized commands with thorough comments helps them understand exactly how the statistical procedures they implement work, interpret their results sensibly, and draw well-founded conclusions. Even in introductory courses, when the set of skills that students master is quite modest, a successful experience helps them develop confidence that will contribute to further success in future research experiences.
3.5 Intellectual Development
Conveying subject matter knowledge and teaching analytical methods are among the purposes of higher education, but as Horton (Citation2021) discussed in his symposium presentation, they are not the only ones. To put their knowledge and analytical skills to good use, students must learn to think independently, use evidence and logically sound reasoning to evaluate and formulate hypotheses and arguments, and they must gain trust in their own judgment. Learning to conduct applied statistical research, particularly using reproducible methods, promotes these higher-order dimensions of intellectual development.
Students need to learn that the work they do for their classes is not just a contrived game in which their goal is to meet the expectations of their professors and be duly rewarded. On the contrary, they should understand that the issues they study have real meaning that they can discover if they engage with their work in a genuine spirit of inquiry. Conducting projects using reliable statistical data from reputable sources is a tangible way of helping students believe in their ability to discover something with real meaning. But it is essential that they adopt reproducible methods for processing and analyzing their data. As discussed above, the enhanced understanding and mastery that students gain using reproducible methods help them develop confidence in their analytical abilities and in their judgment. As a result, their belief that their work is truly meaningful, and more generally that they are capable of generating real insights that they can support with convincing evidence, are strengthened. Conversely, allowing students to submit projects that they understand poorly and that they know they would not be able to reproduce perpetuates the idea that the project was indeed part of a contrived game, and undermines their belief in their ability to engage in a genuine process of inquiry.
Ultimately, gaining confidence in their analytical and interpretive skills, their judgment, and their ability to formulate original ideas and arguments about meaningful questions helps students discover their own voices and develop a sense of agency. And they are then empowered to participate constructively in public discourse—in academia, politics, social service, or any other arena. If their participation in public discourse reflects the habit of basing arguments on transparent analysis based on verifiable evidence, their contributions will be for the good.
Perhaps it is too much to expect that teaching students how to document statistical research will materially influence the nature of public discourse. But that expectation would be akin to the frequently expressed notion that one purpose of education is to prepare the next generation for civic life (Converse Citation1972; Torney-Purta et al. Citation2001; Campbell Citation2006; Delbanco Citation2012), and it may therefore be reasonable to consider. Scattered efforts of individual instructors may inspire a few students, but a pervasive shift in norms among educators—toward greater emphasis on transparency and reproducibility—will be necessary to have a systemic effect on the quality of public discourse.
3.6 Diversity and Inclusion
The presentation by Parsons and Azevedo (Citation2021) emphasized the connections between transparent and reproducible research practices and diversity, equity, and inclusion. Parsons and Azevedo lead the Framework for Open and Reproducible Research Training (FORTT), https://forrt.org/dei an initiative that promotes training in reproducible research, with the particular goal of “creat[ing] conditions for knowledge to become a public good—accessible to all members of society” (Framework for Open and Reproducible Research Training [FORRT] Citation2022, citing Steltenpohl, Daniels, and Anderson Citation2020). Parsons and Azevedo cited cases in which open research practices have promoted social justice by helping to reveal systematic barriers in access to research and educational resources (Steltenpohl, Daniels, and Anderson Citation2020; Bukach et al. Citation2021).
The transparency provided by reproduction documentation is especially valuable to people who are not closely connected with the research community. Individuals who are trained in leading graduate programs and hold positions at well-endowed institutions are able to absorb critical knowledge about data sources, computational tools, methodological norms, and implicit assumptions that prevail in their areas of research simply by being immersed in an active research environment and establishing relationships with other well-positioned scholars. For individuals with this background, reproduction documentation might not be of great value because much of the information it contains would to them be matters of common knowledge. But for individuals who have not had the opportunity to immerse themselves in an active research community, reproduction documentation can make explicit the knowledge that is implicit in the research culture, and thereby make it possible to engage creatively with research that others have conducted.
4 Practical Tips
This section distills some practical lessons from advice offered by several symposium presenters about effective methods for teaching reproducibility. A recurring theme in this advice is that teaching reproducibility need not be disruptive or burdensome. The general principles and purposes of reproducibility can be achieved through a variety of practices that can be flexibly adapted to suit a wide variety of contexts—different disciplines, levels of the curriculum, software preferences, institution type and class size, and diverse student backgrounds.
4.1 Integrating Reproducibility in Existing Courses
Three of the symposium presenters, Bussberg (Citation2021), Hayes-Harb (Citation2021), and Sullivan (2021), described their experiences integrating reproducibility into existing courses and supervised student research that were a regular part of their departments’ curricula, as opposed to offering stand-alone workshops or special topics courses on reproducibility or open science. Just as reproducibility should be recognized as a routine and integral dimension of quantitative research, it should be a standard component of the quantitative methods curriculum. The value of workshops and short courses to early career researchers and other working professionals are clear, but a consensus emerged from the symposium that in degree programs at colleges and universities, integrating reproducibility training into the regular curriculum is usually the preferred approach.
4.2 File-Sharing Platforms
File-sharing platforms—like Dropbox, Google Drive, the Open Science Framework, GitHub, RStudio Cloud, and many others—are a key tool for conducting, and especially for teaching, reproducible research. Ideally, students should store all their work on an online platform, with permissions set so that both the students and the instructor have read–write access to the documentation. For a simple homework problem or lab exercise, the materials on the platform could be as minimal as one data file and one script. For more involved projects or complete research papers, the students should build the folder hierarchy (as described above in “specifications”) on the platform and populate it with the documentation they assemble as they conduct the research (as described above in “workflow”).
When instructors can access the entire project, they are able to provide much more insightful guidance and feedback than is possible when they must rely on students’ verbal descriptions of what they have done with their data and the questions they have encountered. By exploring the files students have stored on the platform—in particular by running the scripts and seeing where errors occur—instructors can diagnose exactly any problems the students encounter and guide them toward an effective solution. Symposium participants who have adopted this interactive, platform-based approach to advising reported that it transformed the nature of their communication with their students.
4.3 Software Neutrality
To illustrate their general comments about reproducible research, a number of symposium speakers presented examples of curricular materials they had created or projects completed by their students. Several types of software were used in these applications, including R, Stata, and SPSS, and many other programs, such as Matlab, SAS, and Python could have served as well. Presenters repeatedly emphasized, however, that the fundamental purposes and principles of reproducibility are software-neutral: they can be achieved using any type of software that suits the needs and preferences of the instructor and students.
Despite this unity of concept and principle across statistical packages, there are important differences in how reproducibility is implemented with different types of software. The symposium presentation by McNamara (Citation2021), for example, compared several distinct syntactical styles for writing R code. Another software-dependent issue is the choice between writing scripts that generate results and then copy/pasting the output into the manuscript of the report, versus using a Markup language with embedded code (such as R Markdown) to write a single source file that renders both text and results of computations in a formatted report (as described by Baumer et al. Citation2014; Xie, Allaire, and Groleman Citation2019). Despite these software-dependent differences in implementation, the basic principles of reproducibility remain constant, and instructors should feel free to choose whatever software and workflow is best suited to their purposes.
This principle of software neutrality is not sufficiently appreciated. At the beginning of faculty development workshops hosted by Project TIER, participants frequently express the belief that if they want to start practicing and teaching reproducible research methods, they will need to abandon the software they have been using for years and learn some particular new package. They learn over the course of the workshop that this belief is incorrect, but it is worrisome that it is not uncommon. It would be unfortunate if instructors exploring how they might incorporate reproducibility in their teaching were discouraged by the misperception that doing so would necessarily entail switching to a new type of software.
4.4 What If Getting Your Students to Write Scripts Is Not Feasible?
As described above, documentation is the key to reproducibility, and scripts are an essential component of documentation. Indeed, the use of scriptable software is generally considered a sine qua non of reproducible research (Stodden, Leisch, and Peng Citation2014). But not every instructor is able to teach quantitative methods with scriptable software. In many cases, departmental policies or demands of the job market dictate that students learn to work with data using interactive spreadsheets, most commonly Excel and Google Sheets.
Nonetheless, even when working interactively in spreadsheets is the only option, there are many reproducibility concepts that can be incorporated into a curriculum.
Broman and Woo (Citation2018) provide a guide to best practices with spreadsheets. For example, completing a full or partial preregistration for a project guides students through some of the deliberate thought processes that take place in scripted research. And forms of documentation other than scripts are still valuable, such as information on data provenance and codebooks for both source data and processed data used in analyses. Particularly in introductory courses, having students engage in even a small subset of reproducibility-related tasks helps establish a foundation upon which they can hone their skills later in their training and careers.
4.5 Ex Ante Documentation Versus Ex Post Reproduction
An approach to teaching reproducibility that is distinct from, but complementary to, the approach highlighted in this paper was the focus of the symposium talks by Janz (Citation2021) and Hoces de la Guardia (Citation2021). In the approach described by Janz and Hoces de la Guardia, students attempt to reproduce results reported in previously published papers; we refer to this exercise as “ex post reproduction.” In contrast, we refer to the workflow discussed so far in this paper, in which students construct documentation for projects that they carry out themselves, as “ex ante documentation”.
Janz (Citation2016) provides detailed guidance to instructors wishing to introduce ex post reproduction in their classes. To carry out an ex post reproduction, students first try to identify and obtain copies of the data that were used in the study; once they have the data, they write scripts that process and organize the data as necessary and then implement the procedures that the authors of the paper used to generate the results they reported. Conducting an ex post reproduction gives students insight into the experience of reproducing the work of others, which informs their work as they assemble the ex ante documentation that will assist others in reproducing their work.
In her symposium talk, Janz (Citation2021) addressed a particular issue that can be problematic in an ex post reproduction. When the data used in a paper are not available from a publicly accessible source, students must contact the author to request it. But the willingness and ability of authors to provide data upon request varies a great deal (even when sharing the data is not restricted by issues related to confidentiality or intellectual property rights). The authors change institutions and may be hard to locate, they may be slow to respond when students contact them, they may never have constructed a clean and documented dataset that is easy to share with others, or they may not remember where they stored it. Moreover, the authors may be worried that the goal of the reproduction exercise is to expose errors in their work. Janz offered practical advice to students and instructors about approaching authors with empathy and respect, so that the reproduction exercise becomes a constructive process rather than a source of conflict (see also Janz and Freese Citation2021).
Hoces de la Guardia’s (Citation2021) presentation focused on the Social Science Reproduction Platform (SSRP), https://www.socialsciencereproduction.org an online tool for ex post reproduction that he has developed with colleagues at the Berkeley Initiative for Transparency in the Social Sciences (BITSS) https://www.bitss.org. The SSRP is a platform on which students can post descriptions of their attempts to reproduce results reported in existing papers. Instructors and students can find comprehensive guidelines for conducting and reporting on a reproduction on the platform and in accompanying documentation. More broadly, the platform is intended to serve the research community by crowdsourcing a collection of projects that can be used to assess the state of reproducibility in social science research.
Instructors interested in ex post reproduction may also be interested in the ReplicationWiki https://replication.uni-goettingen.de/wiki/index.php/Main_Page (Hoeffler Citation2017b), a crowd-sourced collection of replications, mostly of studies published in economics journals. The website welcomes submissions of new replications by students and provides links to many other useful resources.
4.6 Start Where You Are, Advance Incrementally
To instructors who have not yet incorporated reproducibility into their teaching, introducing their students to a reproducible workflow and a comprehensive protocol for script-based documentation of data processing and analysis may appear to be a high hurdle. But the good news is that there is no need to leap over that hurdle in a single bound. Several experienced instructors noted during the symposium that the methods they use for teaching reproducibility were developed over years of trial and error. Instructors in the early stages of this process may similarly find that discovering the computational tools and pedagogical methods that are most effective in their particular environments requires experimentation over many iterations of a course.
Remember that reproducible research is not an end in itself; teaching reproducible research is valuable to the extent that it trains future scientists in credible research methods, enhances student learning of analytical methods and substantive knowledge, promotes their intellectual development, and prepares them to participate constructively in civil discourse. Small steps that serve these purposes, even if they fall short of a comprehensive reproducibility protocol, will be valuable if they serve these purposes. And over time, small steps provide a foundation for further innovations that lead to a robust set of practices for reproducible research.
5 Departmental Coordination
The strategies outlined above offer guidance to individual instructors wishing to introduce reproducibility into their teaching and research advising. The presentation by McAleer (Citation2021) focused on a coordinated effort that he and colleagues in the University of Glasgow School of Psychology and Neuroscience undertook to integrate reproducibility throughout all levels of instruction in their program.
Over several years in the late 2010s, McAleer and colleagues engaged in a review and reform of their undergraduate and graduate programs, with the goal of “creat[ing] a curriculum centered on reproducible research” (McAleer Citation2021).
Harmonization and sequencing of methods throughout the entire course of study mean that principles and practices introduced in first-year courses are reinforced and developed as students move through the program. And as several authors (e.g., Button, et al. Citation2020; O’Hara Citation2016; Ingram Citation2021) have pointed out, when students learn to adopt good reproducibility habits beginning at the earliest points in their training, they are likely to maintain those habits throughout the course of their studies and professional careers.
Central to the reforms at Glasgow was a decision to move away from teaching quantitative methods using point-and-click menus and instead focus on scriptable software. The revised curriculum also includes more opportunities for students to gain hands-on experience with data, emphasizing data wrangling and visualization, and introduces other open science practices, such as pre-analysis plans and registered reports. Equally important is building communities of support and encouraging students to collaborate by sharing ideas, drafts of papers, data, and code. A rich collection of resources generated by this Glasgow initiative is available at https://psyteachr.github.io.
Another example of a successful department-level initiative was presented by Towse and Davies (faculty members) and James and Ball (final-year undergraduates), all of the Lancaster University Department of Psychology (Towse et al. Citation2021; see also Towse et al. Citation2020). That team has developed an online platform, known as LUSTRE http://www.johnntowse.com/LUSTRE/ (Lancaster University STatistics REsources), on which undergraduate and graduate students can post study descriptions, data, and supporting documentation for projects involving quantitative data. LUSTRE was designed to facilitate transparency and data sharing, and those principles are reinforced as students assemble and upload their materials to the platform. In addition to providing these pedagogical benefits, LUSTRE showcases reproducible student projects and demonstrates the feasibility of incorporating reproducibility in quantitative methods training.
A number of symposium participants commented that the Glasgow and Lancaster experiences, though exemplary, are atypical. Department members’ views about why and how (even whether) reproducibility should be integrated into the curriculum are divided, and building a departmental consensus can be difficult or impossible. In the ensuing discussion, however, several ideas emerged about the most effective strategies for building department- or program-level support for reproducibility training.
Broadly speaking, the suggestions advocated leading by example rather than compulsion, helping people understand that reproducibility is a well-defined and feasible goal, and framing the discussion in terms of the scientific and pedagogical benefits of teaching reproducibility rather than the deficiencies of practices that are not reproducible. If some department members resist, listen to them carefully and try to understand their concerns. Many of those concerns may be assuaged if you explain that, as described in the Section 4, introducing reproducibility does not require you to dramatically overhaul your courses, assign complex research projects, or change the software you use. Concerns that teaching reproducibility would be burdensome on the instructor or crowd-out other elements of the curriculum should also be taken seriously. But if you are candid about the fact that some startup costs are unavoidable, a skeptical colleague might be more willing to entertain the possibility that those costs will be offset by big efficiency gains.
The LUSTRE platform at Lancaster University provides an example of a noncoercive strategy for demonstrating to colleagues the feasibility of teaching reproducibility. For similar purposes of raising awareness, Project TIER has created two publicly accessible repositories of student research with reproduction documentation. One is a collection of projects on the Project TIER website, https://www.projecttier.org/tier-classroom/student-work/{\#}student-papers and the other is an archive on the Dataverse platform https://dataverse.harvard.edu/dataverse/TIER. Alternatively, any instructor seeking an easy way to share student work with colleagues could simply set up a folder on one of the common platforms like Dropbox, Box, or Google Drive.
6 Vision and Reality
The vision that emerged from the symposium is of a world in which the value and feasibility of teaching reproducibility are fully appreciated, and instruction in reproducible methods is ubiquitous in quantitative methods training across the natural and social sciences. It would be a norm in this world that whenever students complete assignments involving computational data processing or analysis, they also submit documentation that facilitates independent reproduction of their results. This would be true for the first problem set in an introductory statistics class in which students find means and generate bar graphs, computationally intense doctoral dissertations, and everything in between. The extent and composition of the documentation would of course depend on the nature of the project, and the diversity in the preferences, resources, and experiences of instructors and students would be reflected in the wide variety of tools and conventions that are adopted to ensure reproducibility. But practices would be unified by the purposes of promoting credible scientific research, enhancing student learning, and fostering the broad intellectual development that is at the heart of higher education.
We are still a long way from this vision of ubiquitous reproducibility training, but appreciation of the central place of reproducibility in both research and education has grown substantially in the first fifth of the twenty-first century, and it now appears we have reached a critical mass that ensures the current spike in interest will not go down in history as a passing fad. Support from government agencies, private foundations, and initiatives based in academic institutions and NGOs will help maintain momentum. One of the strongest drivers will simply be the compelling benefits that flow from reproducible pedagogy and the scope for adapting practices to suit a wide range of contexts.
Ultimately progress will be measured by the extent to which scholars and educators view reproducibility as a routine and essential dimension of training in quantitative research methods.
Additional information
Funding
Notes
1 Before the NASEM (2019) report, the term reproducibility was used to mean several different things, and was sometimes conflated with the term replicability. For the history of the use of reproducibility, replicability, and related terms, see Stodden et al. (Citation2013), Liberman (Citation2015), Freese and Peterson (Citation2017), Plesser (Citation2018), Patil, Peng, and Leek (Citation2019), and Vilhuber (Citation2020).
2 This notion of reproducibility was proposed in an early paper by King (Citation1995). Note, however, that King used the term replicability rather than reproducibility—an example of the lack of standardization in terminology cited in footnote 1.
3 A number of professional associations have formulated standards for reproduction documentation similar to the TIER Protocol. Notable examples of comprehensive, practical guides to reproduction documentation include the Data and Code Availability Policy https://www.aeaweb.org/journals/data/data-code-policy of the American Economic Association, and the DIME Analytics Data Handbook of the World Bank’s Development Impact Evaluation group (Bjarkefur et al. Citation2021).
References
- Baumer, B., Çetinkaya-Rundel, M., Bray, A., Loi, L., and Horton, N. J. (2014), “R Markdown: Integrating a Reproducible Analysis Tool into Introductory Statistics,” Technology Innovations in Statistics Education, 8. DOI: 10.5070/T581020118..
- Bjarkefur, K., Cardoso de Andrade, L., Daniels, B., and Jones, M. R. (2021), Development Research in Practice: The DIME Analytics Data Handbook. Washington, DC: World Bank.
- Bollen, K., Cacioppo, J. T., Kaplan, R. M., Krosnick, J. A., and Olds, J. L. (2015), “Social, Behavioral, and Economic Sciences Perspectives on Robust and Reliable Science: Report of the Subcommittee on Replicability in Science”, Advisory Committee to the National Science Foundation Directorate for Social, Behavioral, and Economic Sciences. Available at http://ora.emory.edu/research-compliance/oric/documents1/8%20%20Social,%20Behavioral,%20and%20Economic%20Sciences%20Perspectives%20on%20Robust%20and%20Reliable%20Science.pdf.
- Broman, K. W., and Woo, K. H. (2018), “Data Organization in Spreadsheets,” The American Statistician, 72, 2–10.
- Bukach, C. M., Bukach, N., Reed, C. L., and Couperus, J. W. (2021), “Open Science as a Path to Education of New Psychophysiologists,” International Journal of Psychophysiology, 165, 76–83.
- Bussberg, N. (2021), “Incorporating an Accessible Reproducibility Workflow into Entry-Level Courses [videorecording],” TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/incorporating-accessible-reproducibility-workflow-entry-level-courses/.
- Button, K. S., Chambers, C. D., Lawrence, N., and Munafo, M. R. (2020), “Grassroots Training for Reproducible Science: A Consortium-Based Approach to the Empirical Dissertation,” Psychology Learning & Teaching, 19, 77–90.
- Campbell, D. E. (2006), “What is Education’s Impact on Civic and Social Engagement?” in Measuring the Effects of Education on Health and Civic Engagement: Proceedings of the Copenhagen Symposium, eds. R. Desjardins and T. Schuller, Paris: OECD.
- Christensen, G., and Miguel, E. (2018), “Transparency, Reproducibility, and the Credibility of Economics Research,” Journal of Economic Literature, 56, 920–980.
- Converse, P. E. (1972), “Change in the American Electorate,” in The Human Meaning of Social Change, eds. A. Campbell and P. E. Converse, New York: Russell Sage Foundation.
- Delbanco, A. (2012), College: What It Was, Is, and Should Be, Princeton, NJ: Princeton University Press.
- Dewald, W. G., Thursby, J. G., and Anderson, R. G. (1986), “Replication in Empirical Economics: The Journal of Money, Credit and Banking Project,” American Economic Review, 76, 587–603.
- Framework for Open and Reproducible Research Training (FORRT). (2022, March 8), “Toward Social Justice in Academia: Diversity, Equity and Inclusion,” [website]. Available at https://forrt.org/dei/.
- Freese, J., and Peterson, D. (2017), “Replication in Social Science,” Annual Review of Sociology, 43, 147–165.
- Hayes-Harb, R. (2021), “Reproducibility Education in an Undergraduate Capstone Course [videorecording],” TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/reproducibility-education-undergraduate-capstone-course/.
- Hoces de la Guardia, F. (2021), “How to Teach Reproducibility in the Classroom (BITSS) [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/how-teach-reproducibility-classroom-bitts/.
- Holdren, J. F. (2013), “Memorandum for the Heads of Executive Departments and Agencies: Increasing Access to the Results of Federally Funded Scientific Research,” White House Office of Science and Technology Policy.
- Hoeffler, J. (2017a), “Replication and Economics Journals Policies,” American Economic Review Papers and Proceedings, 107, 52–55.
- Hoeffler, J. (2017b). “ReplicationWiki—Improving Transparency in the Social Sciences,” D-Lib Magazine, 23, 3/4 (March/April). DOI: 10.1045/march2017-hoeffler..
- Horton, N. J. (2021), “Transparent and Reproducible Analysis as a Key Component of Data Acumen [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/transparent-and-reproducible-analysis-key-component-data-acumen/.
- Ingram, M. C. (2021), “Teaching Transparency: Principles and Practical Considerations with Illustrations in Stata and R,” in Teaching Research Methods in Political Science, ed. J. L. Bernstein, pp. 114–130, Northampton: Edward Elgar Publishing.
- Janz, N. (2016), “Bringing the Gold Standard into the Classroom: Replication in University Teaching,” International Studies Perspectives, 17, 392–407.
- Janz, N. (2021), “Teaching Replication [videorecording],” TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/keynote-tba/.
- Janz, N., and Freese, J. (2021), “Replicate Others as You Would Like to Be Replicated Yourself,” PS: Political Science & Politics, 54, 305–308.
- King, G. (1995), “Replication, Replication,” PS: Political Science & Politics, 28, 444–452.
- Liberman, M. (2015, October 31). “Replicability vs. Reproducibility – Or Is it the Other Way Around?” Language Log [blog]. Available at https://languagelog.ldc.upenn.edu/nll/?p=21956#:˜:text=But%20just%20because%20a%20study,arrive%20at%20the%20same%20conclusions.
- Maniadis, Z., and Tufano, F. (2017), “The Research Reproducibility Crisis and Economics of Science,” The Economic Journal, 127, F200–F208.
- McAleer, P. (2021), “Creating a Curriculum Centered on Reproducible Research for the Psychologists of the Future [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/creating-curriculum-centered-reproducible-research-psychologists-future/.
- McNamara, A. (2021), “Consistency Is Key: A Case Study in R Syntaxes [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/tba/.
- National Academies of Sciences, Engineering, and Medicine (NASEM). (2019), Reproducibility and Replicability in Science [online]. Washington, DC: The National Academies Press. DOI: 10.17226/25303.
- National Institutes of Health (NIH). (2020, October 29). “Final NIH Policy for Data Management and Sharing,” Notice Number: NOT-OD-21-013.
- Nüst, D., Eddelbuettel, D., Bennett, D., Cannoodt, R., Clark, D., Daróczi, G., Edmondson, M., Fay, C., Hughes, E., Kjeldgaard, L., Lopp, S., Marwick, B., Nolis, H., Nolis, J., Ooi, H., Ram, K., Ross, N., Shepherd, L., Sólymos, P., Swetnam, T. L., Turaga, N., Petegem, C. V., Williams, J., Willis, C., and Xiao, N. (2020), “The Rockerverse: Packages and Applications for Containerisation with R,” The R Journal, 12, 437–461.
- Nüst, D., Sochat, V., Marwick, B., Eglen, S. J., Head, T., Hirst, T., and Evans, B. D. (2020), “Ten Simple Rules for Writing Dockerfiles for Reproducible Data Science,” PloS Computational Biology, 16, e1008316.
- O’Hara, M. (2016), “Reproducibility as a Pedagogical Strategy [paper presentation],” AEA Conference on Teaching and Research in Economic Education (CTREE), Atlanta, GA.
- Patil, R., Peng, R., and Leek, J. (2019), “A Visual Tool for Defining Reproducibility and Replicability,” Nature Human Behaviour, 3, 650–652.
- Parsons, S., and Azevedo, F. (2021), “Building a Community from Open Scholarship Pedagogy with a Framework for Open and Reproducible Research Training [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/building-community-open-scholarship-pedagogy-framework-open-and-reproducible-research-training-forrt/.
- Peng, R. D. (2011), “Reproducible Research in Computational Science,” Science (New York, NY), 334, 1226–1227.
- Plesser, H. (2018), “Reproducibility vs. Replicability: A Brief History of a Confused Terminology,” Frontiers in Neuroinformatics, 11, 1–4.
- Steltenpohl, C. N., Daniels, K. M., and Anderson, A. J. (2020), “Giving Community Psychology Away: A Case for Open Access Publishing,” Global Journal of Community Psychology Practice, 10, 1–14.
- Stodden, V., Bailey, D. H., Borwein, J., LeVeque, R. J., Rider, W., and Stein, W. (2013, February 16). “Setting the Default to Reproducible: Reproducibility in Computational and Experimental Mathematics.” Available at http://stodden.net/icerm_report.pdf.
- Stodden, V., Leisch, F., and Peng, R. D., eds. (2014), Implementing Reproducible Research, Boca Raton, FL: CRC Press/Taylor & Francis Group.
- Sullivan, J. (2021), “A Practical Approach to Teaching Reproducibility, and Improving Your Own Research at the Same Time [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/practical-approaches-ensuring-undergraduates-master-reproducibility/.
- Torney-Purta, J., Lehmann, R., Oswald, H., and Schulz, W. (2001), Citizenship and Education in Twenty-Eight Countries: Civic Knowledge and Engagement at Age Fourteen, Amsterdam: International Association for the Evaluation of Educational Achievement.
- Towse, J. N., Davies, R., James, R., and Ball, E. (2021), “LUSTRE: An Online Tool for Training Students in Data Management and Data Sharing [videorecording],” in TIER Spring Symposium: Instruction in Reproducible Research [online]. Available at https://www.projecttier.org/fellowships-and-workshops/2021-spring-symposium/lustre-online-tool-training-students-data-management-and-data-sharing/.
- Towse, J. N., Ellis, D. A., and Towse, A. S. (2020), “Opening Pandora’s Box: Peeking inside Psychology’s Data Sharing Practices, and Seven Recommendations for Change,” Behavior Research Methods, 53, 1455–1468.
- Vilhuber, L. (2020), “Reproducibility and Replicability in Economics,” Harvard Data Science Review, 2. DOI: 10.1162/99608f92.4f6b9e67..
- Xie, Y., Allaire, J. J., and Groleman, G. (2019), R Markdown: The Definitive Guide, Boca Raton, FL: CRC Press/Taylor & Francis Group.