Abstract
We advocate for greater emphasis in training students about data management, within the context of supporting experience in reproducible workflows. We introduce the Lancaster University STatistics REsources (LUSTRE) package, used to manage student research project data in psychology and build capacity with respect to data acumen. LUSTRE provides a safe space to engage students with open research practices—by making tangible different phases of the reproducible research pipeline, while emphasizing its value as a transferable skill. It is an open-source online data catalogue that captures key data management information about a student research project of potential relevance to data scientists. Embedded within a taught programme, it also highlights concepts and examples of data management processes. We document a portfolio of open teaching resources for LUSTRE, and consider how others can implement or adapt them to facilitate data management and open research. We discuss the role of LUSTRE as a; (a) resource and set of activities for promoting good data management practices; (b) framework to enable the delivery of key concepts in open research; (c) an online system to organize and showcase project work.
1 Introduction: Why Data Management Matters in a Data-Centric World
There are numerous benefits to data sharing. It enables new knowledge though data reuse. It increases the credibility of research as rated by citizens (Funk et al. Citation2019) and research peers (Munafò et al. Citation2017). Research papers with shared data potentially benefit from a citation advantage (Colavizza et al. Citation2020). Even outside of a research context, it promotes trust toward the institutions that share data (Gonzálvez-Gallego and Nieto-Torrejón Citation2021). For these and other reasons, there have been numerous calls for greater data sharing from both within and outside of science communities.
Yet data sharing currently remains a fringe practice overall (Hardwicke et al. Citation2020). More concerning still, even when datasets are publicly archived, they may not always be functional. Roche et al. (Citation2015) demonstrated that there were problems with the majority of open datasets for Ecology and Evolution, with issues that limited or prevented their exploitation or reuse. Problems included instances where only partial data were provided, or quantitative data were shared but without a data dictionary/essential meta-data, or stored only in proprietary formats. Subsequent work has shown that broadly comparable conclusions can be drawn across a range of science disciplines (e.g., Hardwicke et al., Citation2018; Towse, Ellis, and Towse Citation2021b). In other words, even in the small minority of cases with open datasets, on closer inspection many are not FAIR (Findable, Accessible, Interoperable and Reusable; Wilkinson et al., 2016) and as such have been labeled “re-useless” (Mons et al. Citation2017).
Our ambition is to help address these twin concerns of prevalence and functionality of data sharing. We demonstrate by example how one might highlight for students the importance and benefits of data management. On the one hand, this makes principles salient—fostering attention to responsible data stewardship, and normalizing reproducible workflows. On the other hand, this also showcases key practices—fostering attention to choices that affect data functionality (see also Meyer Citation2018). To realize this ambition we describe our approach to promote data sharing for a student audience, who are the researchers, data scientists, and business professionals of the future.
By formally introducing and embedding data management into their experience, students will increasingly expect and respect data transparency. To the extent that it becomes normalized in research, alongside a consideration of say ethics and other dimensions of good research practice culture (Ostblom and Timbers Citation2022), we predict that scaffolding data management experiences will ultimately have downstream benefits for research and nonacademic data science contexts. In other words, data stewardship has the potential to contribute to students’ engagement with research through transparent practices (see Grahe et al. Citation2020), whether stimulating critical thinking through consideration of risks of data breaches or evaluation of data handling. In so doing we emphasize that data management is not just a scholarly concern but rather a key transferable skill (Janssen and Zuiderwijk Citation2014; Weerakkody et al. Citation2017).
Thus, we encourage good practice by setting relevant norms and incentives that promote students’ data stewardship. Providing structured teaching about data management should be a key component in student training in general and support for research projects in particular, under the broader and important agenda of data acumen (Horton et al. Citation2021). It is important to create opportunities for good habits to be developed, and to encourage the behaviors and practices we hope to become more widespread. To build capacity for positive behavior. In this context, we respond to clarion calls from across the research community for more guidance and clearer training in data sharing (Roche et al. Citation2021; Soeharjono and Roche Citation2021).
The rest of this article is structured as follows. In the following section, we introduce the LUSTRE package designed to facilitate teaching of how to share high quality, functionally effective, datasets. We then use the subsequent section to explain in more detail how the resources can be integrated into the workflow of empirical work. LUSTRE emphasizes the potential to shape data handling choices, to promote efficient strategies, and to raise awareness of the resources and tools that can help channel student enthusiasm for open research into good research habits.
Next, we motivate research data evaluating student attitudes to data management, addressing issues for students both as consumers of science and as producers. We then consider broader applications and uses of the LUSTRE concept, note some of the inevitable limitations at this point in time, and finish with our conclusions.
2 LUSTRE: A Student Resource for Engaging with Long-Term Data Management
LUSTRE stands for “Lancaster University STatistics REsources”. The public interface is a searchable online catalogue of psychology student projects and the gateway to the empirical research data generated for these projects (see and https://johnntowse.com/LUSTRE/). It is built from the Omeka system that is designed to facilitate and organize digital collections but refines and develops that system to fit the profile of student research data project.
Fig. 1 Front page of the LUSTRE student project system.
However, the pedagogic utility of the resource lies not just in the presentation of a searchable, public, catalogue of research that students—and others—can explore. Students can benefit from this shop-window—examining what peers have achieved, with opportunity to model their own archives accordingly. But more than that, the value stems from the experiences that accompany the underlying database.
To contribute to LUSTRE, students complete a data acquisition form and create associated digital objects (e.g., project datasets, codebook, analysis code and participant consent forms). Assembling and developing these data assets brings data management into their active research experience. LUSTRE provides a research sandbox (i.e., a safe isolated environment) within which data management can be explored and learned. It thereby encourages students to explore different facets of data management.
LUSTRE comprises multiple components, that both work interactively but also can used on their own. There are the web pages themselves as well as the code resource used to build the online system (https://doi.org/10.5281/zenodo.6908561). But also, for example, lecture materials, website records, a supporting mini website, accompanying activities and resources—all these being available at the accompanying project page https://osf.io/zctgy/. Together these can all support a more reproducible stance for empirical projects (for a similar framework see Vilhuber et al. Citation2022). Of course, some of these may be less relevant than others but they can be used modularly. Some may have more immediate or short-term value for students, while others, from repeated, cumulative, experiences, may contribute to longer-term value.
Our starting point is to motivate key LUSTRE elements and explain how they fit together to support and enhance each other. The technical details are then explained/provided on the accompanying OSF project page
Teaching materials for data management, with both shareable presentation slides and video recordings. These cover both academic and nonacademic contexts, and foreground the student as both the producer and the consumer of research content.
Direct student experiences with data records. This experience emerges from a specific class activity—students (individually or in small groups) are assigned a project record from a former student. They upload their assigned project record to LUSTRE. This engages students with the heterogenous range of peer-datasets, and the importance of mapping project content (principally, research data) to the various meta-data elements that can be used to distinguish and locate psychological research across a set of student projects.
So while (1) draws attention to the principles, requirements and benefits of data sharing, (2) makes tangible the detailed practice involved in data archiving. Research data are varied and sometimes complex—making explicit the landscape of data archiving can potentially help students understand in concrete terms what is involved.
Opportunity for indirect experience with a data repository. LUSTRE website represents an informational resource that students can interrogate and use to learn about past project details. This is introduced and explained explicitly in the teaching materials. Yet this allows students to explore the system at their own pace (guided by the web materials we have developed). For example, they can look at previous projects with specific supervisors, thereby understanding what might be appropriate for their own project interests. Users can filter and explore projects by analytic frameworks (addressing which projects employed particular statistical models) and by topic and methodological approach. Such options may be particularly relevant to statistics and data science educators looking for ways to narrow their search for particular projects. The various filters enable users to understand the scale and form of project work in areas that they might be considering. Do their potential project ambitions and aspirations match the submissions of former students? Whether in terms of content, scale, methodology, analysis or theme? Are they overestimating what might be achieved, or underestimating what is expected? The project catalog can help navigate all these and other questions.
A long-term record of student research activity. LUSTRE represents a public catalogue of records in relation to student empirical work. Not only does this represent a body of knowledge in and of its own right, it presents an opportunity to obtain and reuse project data to teach statistics, or for secondary data analysis. Our hope is that peer-created datasets can potentially be used to engage learners with analytic ideas and issues, given their relevance and realism, but also to support student work in reproducibility exercises (see Frank and Saxe Citation2012).
Summary. To the extent that students can see these peer-created datasets as “This is the type of research that I’m going to be handling”, they may be find them more approachable and meaningful. To the extent that peer-created datasets have a Goldilocks-profile (i.e., the appropriate level of complexity—not too big or complex, not too little or oversimplified) their granularity may be advantageous in teaching data science and data analysis skills, in comparison with either complex (and potentially overwhelming) real-world research data or abstract toy datasets that may be simple enough to expose data analysis principles but will lack the relevance to stimulate student motivation.
LUSTRE has been designed to support a specific psychology curriculum. Working with empirical data is a central part of the United Kingdom psychology student experience. With structured research methods experiences across undergraduate and taught masters training, data handling and data processing will be familiar already. It is not too early at all to incorporate data management into masters level research projects. Indeed, one risk in leaving data management training too late is that sub-optimal habits may become entrenched. The core data management principles likely extend well beyond psychology and given the arguments above for data acumen as a transferable skill, we expect the issues discussed here to be relevant to multiple disciplines.
3 How Data Management Fits in to the Student Research Project
With the existence of a LUSTRE database that captures and presents information about student projects, an exemplar of the life cycle of a research project can be represented in . Of course, this is how we choose to use and fit data management into empirical work at one institution and at one point in time. Irrespective of data management, project research design and development is a complex and multi-faceted process, and sets out the sequence of events that lead a student to think about a research topic, to identify a supervisor and to choose the key research questions that will be addressed in a study (likely incorporating an ethics application and potentially some form of preregistration). The key is that if, by using LUSTRE, students at the earliest stages of their project design can inspect records of previous projects, then they can potentially make more informed choices about the scope and the shape of a suitable project.
Fig. 2 The life cycle of research projects incorporating data management.
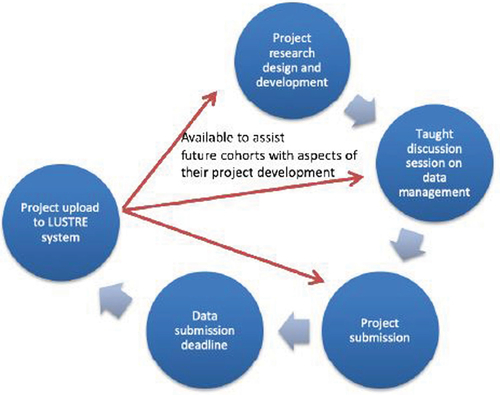
As part of a module that prepares students to conduct research, psychology students are introduced to the data management requirements of their project. This is delivered before project design or ethics applications stages. Minimally, it would be possible for students to learn about the system entirely through self-directed learning, supervisory discussions and rubrics in handbooks etc. However, our approach has been to provide contextually guided support (scaffolding) to motivate and explain LUSTRE. That is, a central teaching session occurs within a methods-focused module on data management. This session explains LUSTRE within a wider discussion of the (research) opportunities and potential (legal) complications of open (and for that matter, closed) data. Session content also covers data management issues beyond academia per se, offering transferable skills and knowledge about data stewardship.
sets out a life cycle or work-flow in which data submission follows the project submission. This is driven by practical concerns, to ensure that students focus on project content first, and that they can separately prepare and submit their data afterwards. This also makes explicit the need to deploy an efficient submission process to harvest datasets and related materials. In our experience a dedicated shared E-mail box works well. LUSTRE requires a simple data acquisition form which identifies the various elements of the project that are required, and which directs students to provide the key components of a data archive (see below).
Inherent to project records are a set of meta-data elements, that is, variable fields providing project information. We have interpreted the standard Dublin-Core items (DCMI Citation2008) embedded within Omeka with reference to components of psychology research projects, and we have added more specific items that we expect to be useful (e.g., requiring students to be explicit about study sample size, and analytic methods). As a result, LUSTRE foregrounds the importance of meta-data in the organization of research product archives, and the importance of enabling effective searches for products among the responsibilities of data stewardship. Optimal preparation of a data record and retrieval of information draw on such meta-data, and therefore this makes the value of meta-data more tangible.
A student submits their research project for data archiving by providing the following elements:
A completed data acquisition form—This collects, in a simple and straightforward manner, the key elements about the submitted project required for the LUSTRE database. In other words, it provides an interface between the project that is submitted for assessment and the digital record fields for the database. To simplify the process students are encouraged merely to copy-and-paste relevant sections from the submitted project onto the form. The data acquisition form is designed, as far as possible, to lower the barriers to obtaining the requisite information. We have a how-to guide for this form on the accompanying website.
A consent form—A consent form provides an important element in understanding participant agreement to, or restrictions on, data use. It is recommended that open datasets include a consent form (Towse, Ellis, and Towse Citation2021a). Moreover, consent forms provide an important digital asset in their own right, for future students to use in their independent work.
Analysis code—Analysis code is important for several reasons. Presentation of data analysis in a project report (as for a journal article) is almost always a summary description of the underlying process. Thus, there may be assumptions and analytic choices built into the analysis that are not captured by the descriptive text or reported outcomes, and these can affect the ability to carry out analytic reproducibility (Hardwicke et al., Citation2018; see also Meteyard and Davies Citation2020). Since the data analysis curriculum has moved to emphasize more reproducible analytic workflows (Tucker et al. Citation2022), inclusion of analysis code is sensible, meaningful and, for most cases, little extra work insofar as code is created as part of analysis process. This requirement to include analysis code was introduced in the 2020/2021 teaching cycle, so will likely not accompany earlier records.
The dataset file/files—A copy of the raw data file or files used in the project.
4 Student Attitudes toward Data Sharing; an Ongoing Data Project
A key LUSTRE component is the provision of teaching materials to explain the role of data sharing in the research process. This should highlight the importance of data sharing to enhance research—and commercial—transparency, as well as shape students’ project work. Yet, students can encounter issues of open research and data use in various contexts, and at multiple points in the curriculum, both directly and indirectly. Teaching the LUSTRE system is not their only entry point to open research ideas.
Indeed, students are encouraged to carry out secondary data analysis using open datasets within a separate, class activity—an exercise that often reveals significant obstacles in analytic reproducibility (see Hardwicke et al. Citation2018).
Nonetheless, we sought to identify specifically how exposure to data management materials affected student perceptions of open research. Accordingly, we developed and preregistered an ongoing study to measure the impact of learning about data management on student opinions about data sharing and reproducibility (accessible from the OSF project page). Here, we describe the logic and motivation for the study design in which we measure student views before, and after formal teaching took place. Details of the study, and the conclusions warranted from it, are described on an external repository, since they will involve ongoing and repeated testing epochs.
A key design element was to probe students about, on the one hand, data sharing in scientific research—reflecting whether they felt they should have access to the data from research publications—as well as, on the other hand, their own data sharing obligations—how did students feel about making their data available to others? Sharing empirical project information opens up researchers to additional scrutiny, which may be viewed as aversive and data sharing may be perceived as imposing additional efforts and psychological work (Houtkoop et al. Citation2018). It is therefore possible that a divergence of views would emerge, with respect to data management by others and data management by themselves.
Several insightful surveys and investigations of open research and data sharing practices have been published (e.g., Abele-Brehm et al. Citation2019; Melero and Navarro-Molina Citation2020; Tenopir et al. Citation2020; Baždarić et al. Citation2021). However, these normatively focus on the active scientific community: researchers who publish. Our focus here is on student attitudes, and as such, the focus is somewhat different. We therefore chose to base assessment materials from the STORM project led by Gilligan-Lee and colleagues (Gilligan-Lee et al. Citation2022), which addresses undergraduate knowledge and views of open science. At the same time, the STORM project examined a diverse range of open research practices, and since we were asking students to complete survey materials alongside their learning activities, we decided to be selective in the materials presented.
4.1 Method
All masters-level students taking a taught module to prepare for their project (initial cohort, 2020/2021, N = 43; second wave of data acquisition, 2021/2022, N = 44) were invited to complete an online survey prior to the scheduled teaching of a session on “Data archiving” (the survey administration was approved by the FSTREC ethics committee, FST20086). The invitation was sent using the online student communication platform and also verbally delivered in the preceding week’s session by a staff member. A reminder of the invitation was also posted. A verbal and written reminder of the invitation was issued to recomplete the survey after the session.
Respondents were presented with 16 Likert-scale items from the STORM project (e.g., item 1, It is important to repeat studies with a different sample of participants to see if you get the same results; item 9, After a study, it is important that data from the study are freely available and easy to understand, for anyone who wants to view it). They were then presented with the following 4 Likert-scale items specifically on attitudes to data sharing adapted from the ATOPP survey (Baždarić et al. Citation2021);
Data from scientific research should be publicly available.
Making data publicly available data is simple & straightforward nowadays.
Data from my scientific research as a student should be publicly available.
I do not want my data to be downloadable and reusable in other research.
Finally, there were two free-text fields to provide further information, asking:
Briefly describe key reasons for your answer to the previous question
and
What makes publicly available data useful? Briefly identify as many attributes/dimensions that you can think of
4.2 Results and Discussion
Two substantive, linked, issues emerged from the initial wave of data collection. First, only a modest proportion of students completed the initial survey materials (18/43 undertook the survey, with 17 completed). Some were submitted prior to the synchronous teaching but after release of materials (there is a teaching requirement to make slides and resources available at least 48 hr before any taught session). So we cannot always be certain students completed the survey before accessing teaching resources. Second, only one student resubmitted responses after the taught session—despite all students being invited to follow the online link a second time.
These present obvious sampling constraints. Accordingly, we restrict ourselves here to some brief, broad conclusions, and instead we develop an ongoing, more data-centric analysis at the OSF project, that will be updated with additional waves of student cohorts.
Students clearly voiced a belief at the outset in the value of open data as a community endeavor. For example, “I believe research data should be made publicly available, in order for the study to be replicated…” expresses a common attitude. Indeed, some respondents take a more active position; “I plan to share data from my dissertation project via the OSF and have already looked at the process to do so. Just because we are students, doesn’t mean our research data is any less important.” Meanwhile, at least one student recognized the intellectual investment required; “Transparency is important but we have to admit that it requires a lot from researchers’ self-awareness.”
The final survey question asked students about the attributes of useful public data. This sought to understand whether they recognized components of high-quality data such as data completeness and reusability (which we anticipated might be more salient after the taught session). Answers—which as a reminder came from prior to the session—generally focused instead on the purposes of public data (for replications and secondary data analysis). This semantic reframing is revealing, underlining the gap between positive aspirations—that is, that data sharing is a good thing—and implementation decision choices—that is, trying the make data useful to others. This is the gap which the current project attempts to narrow.
5 Additional Information for Students and Educators
In the current implementation, students submit their data along with accompanying digital objects to a central venue (a shared E-mail mailbox). To be clear, we do not automatically upload the data directly to the online repository. In principle, all data could be attached to project records and be fully open. However, as authors we do not currently have the resources to scrutinize all datasets sufficiently to ensure public-facing data are fully anonymized and that sharing is compliant with consent, etc. As such, we avoid the risk legal and moral hazards in compromising participant rights. Instead, we have, first, used the “exhibit” feature within Omeka to collate a sample of student projects where open data has been provided. In such cases, we have made available a consent form, a codebook or data dictionary, and the raw data (the latter is typically in a plain text, .csv format). Second, other project datasets are held offline, and can be requested and accessed as required by use of a central E-mail, so they are available in a safeguarded fashion. In addition,
The “exhibit” feature provides a convenient way to describe and manage these open data records, and the exhibit can be edited to enlarge the collection as new project records are acquired. Moreover, this offers an exemplar of how exhibits can be deployed. In principle, multiple exhibits can be developed and presented that address a range of pedagogic issues. For example, exhibits could be used to draw attention to projects that address specific methodological or ethical issues, or which have certain notable features about them (e.g., maybe highlighting specific good practices). Once a database of projects has been created, exhibits allow for them (and the accompanying digital assets) to be arranged and grouped in flexible ways.
Although raw data are not always shared, consent forms associated with research projects should generally be available. Consent forms provide an evidential trail on what participants have (or have not) agreed to with respect to data usage. Moreover, we argue that collating a library of consent forms has meaningful value in and of itself. They can be used by students for preparing their projects, especially where they access contemporary, discipline relevant examples. Consent forms will vary across projects (e.g., for infancy work, where parents provide consent, versus experimental work involving adults who provide their own consent). Consequently, students should not need to create consent forms from scratch nor rely on (potentially out of date or overly generic) textbook examples. Indeed, by developing and iterating examples of consent forms, that explain data curation and reuse, students can be encouraged to develop good practice.
In addition to the online database, and the source code for this, we have provided teaching materials with both slides and a recorded video for a data management session. We also offer materials used for an online presentation of the LUSTRE system from 2020.
Educators can use these to develop or complement their own teaching resources.
These teaching materials cover some issues around data anonymization, why this is important, and how this can be more complex than some imagine (for example, with respect to indirect identifiers). As public data sharing becomes more widespread, then deploying appropriate and sensitive anonymization procedures for human research becomes increasingly important. Thus, providing students with practical experience and exercises will become key to enabling them to navigate the ethical and practical concerns appropriately. The teaching materials also discuss nonacademic examples of data breaches, by way of pointing to issues beyond the research context.
An accompanying student assignment may be of interest to data scientists and data science educators. Having delivered the taught material and interactive session with LUSTRE, we set a simple and broad task. We ask students to identify a research paper of their choosing, where underlying research data has been shared. Students then audit and evaluate the shared data. They are free to choose scales of data functionality discussed in the session (Roche et al. Citation2015), or qualitative assessment of the data, and they can focus on specific functionality dimensions (e.g., data completeness) or overview a wider portfolio of attributes. The assignment provides an indication of how well data management issues have been assimilated by each student, but also has flexibility—potentially a follow-up session for example, might collate student assessments—presumably from different data sources—to identify patterns, trends, and conclusions.
In summary, we encourage others to take advantage of LUSTRE, noting that there are many ways to do so. One option would be to replicate the system described performing an independent and full system installation. This would create a comparable training experience to that described here. Another option would be for student projects from another programme to be added to the current system database. One meta-element specifies “publisher”—so in principle it would be straightforward to distinguish institutions. Moreover, the “exhibit” function already described could be used to describe and annotate different sources.
An alternative approach is a “hybrid” implementation, either involving only some subset of the elements we describe here—for example just the teaching materials without the data deposit requirement—or using some or all of the elements but also extending or adapting them to optimize its functionality in a particular context. We recognize that open data systems come in different shapes and sizes (e.g., Poldrack et al. Citation2013 for a specialist example) and we do not wish to be prescriptive in exactly how LUSTRE or other systems can be used. Yet another possibility, is that data science training can specifically use the system for its potential with respect to data reuse, for the exhibited datasets or by requests connected to displayed records.
6 LUSTRE limitations and Constraints
Here, we consider some reflections on the limits of LUSTRE, to provide a more balanced perspective. It is reasonable to ask “How well does it work?” or “What are the drawbacks?” in the implementation of some form of the system we have described. Bear in mind in this section that we have outlined one specific version of the LUSTRE deployment that we have used, whilst there are many ways that it could be “exported” or generalized in the context of different course programmes.
First, the LUSTRE package cannot offer an exhaustive account of data management (there are many other excellent online resources that would complement what we deliver, see for example; https://www.go-fair.org/fair-principles/ and https://forrt.org). Second, it takes a psychology-based perspective; for other subjects, data management issues and priorities may naturally differ. Third, the teaching materials have been developed for a single, 2-hr taught session at masters level. Of course, there is (much) more that one could say about data management. For example, although we draw attention to the importance of high-quality data sharing, we lack the teaching space to train students individually on all aspects of data quality, as it might apply to their specific project.
One practical, and potentially idiosyncratic limitation is that the process of uploading project records from one cohort to another in not comprehensive/exhaustive. Over several years, the “data archiving” session has been timetabled when there has been disrupted delivery. As a result, previously not all students have uploaded assigned project records. A subsequent system to check and monitor class assignment completion should increase project availability.
Within many programmes, student research projects are a distributed enterprise. In contrast to say a taught module delivered by a single academic, research projects may be supervised by academics across an entire Department or School. Consequently, processes and requirements have to be deployed consistently and equitably across the large team involved. Data archiving requirements therefore involve group decisions about project workflow—supervisors (who will be working alongside students in their data archiving) and administrators (who oversee the many moving parts) need to be reminded of the system requirements. Likewise, as a distributed exercise, elements such as consent forms require evaluation and reflection to be refined and avoid propagation of out of date content. There is no inherent quality filtering system.
At the time of writing, we lack the data richness to report systematically on student attitudes toward open research and reproducibility. Such data are aggregated and described on the accompanying OSF project page. Therefore, we cannot conclude yet that teaching LUSTRE changes students’ views substantially about data management. Indeed, one might realistically anticipate only a gradual shift of viewpoints across multiple teaching points and student experiences over time, at least when students know that data sharing is neither universal nor fully optimized.
7 Conclusion
It is important to expose students to issues within open research, as these issues gain traction within psychological, scientific and research communities (for an overview, see Ball et al. Citation2022). As far as is feasible, it is vital to do so as both a procedural as well as intellectual exercise. Open and reproducible science is not just the responsibility of others. Students are consumers and evaluators of open research and they are potential contributors as well.
It is all too easy to be critics of questionable or non-open research practices that can be found in the research literature. Instead, by placing students in the role of contributors to and evaluators of open research, they can better understand the decision, constraints and consequences involved. This enables them to develop grounded, critical thinking with respect to public data processes. This applies not only to research data management, but also data management as a transferable skill in many professions and activities, where responsible data stewardship is critical. As such, learning about data management is one important part of acquiring and refining data acumen (Horton et al. Citation2021), a key contemporary skill. We hope LUSTRE builds data management capacity and data use, both through its specific features and the larger learning ecosystem within which it sits.
Acknowledgments
We are grateful to Lancaster University Faculty of Science & Technology for a Teaching Development Grant that facilitated the implementation of this LUSTRE project. We also acknowledge CETL (Centre for Excellence in Teaching and Learning) for an award relating to a previous version of the project involving also Dennis Hay and Andrea Towse, and to Rob Thompson for software programming on that initial (LUPSY) project.
References
- Abele-Brehm, A. E., Gollwitzer, M., Steinberg, U., and Schönbrodt, F. D. (2019), “Attitudes toward Open Science and Public Data Sharing: A Survey Among Members of the German Psychological Society,” Social Psychology, 50, 252–260. DOI: 10.1027/1864-9335/a000384..
- Ball, R., Medeiros, N., Bussberg, N. W., and Piekut, A. (2022), “An Invitation to Teaching Reproducible Research: Lessons from a Symposium,” Journal of Statistics and Data Science Education. DOI: 10.1080/26939169.2022.2099489..
- Baždarić, K., Vrkić, I., Arh, E., Mavrinac, M., Gligora Marković, M., Bilić-Zulle, L., Stojanovski, J., and Malički, M. (2021), “Attitudes and Practices of Open Data, Preprinting, and Peer-Review—A Cross Sectional Study on Croatian Scientists,” PloS One, 16, e0244529. DOI: 10.1371/journal.pone.0244529..
- Colavizza, G., Hrynaszkiewicz, I., Staden, I., Whitaker, K., and McGillivray, B. (2020), “The Citation Advantage of Linking Publications to Research Data,” PloS One, 15, e0230416. DOI: 10.1371/journal.pone.0230416.
- DCMI (2008), Dublin Core Metadata Element Set, Version 1.1. DCMI Recommendation. Available at https://www.dublincore.org/specifications/dublin-core/dces/. Accessed July 15, 2022.
- Frank, M. C., and Saxe, R. (2012), “Teaching Replication,” Perspectives on Psychological Science, 7, 600–604. DOI: 10.1177/1745691612460686.
- Funk, C., Hefferon, M., Kennedy, B., and Johnson, C. (2019), Trust and Mistrust in Americans’ Views of Scientific Experts. Pew Research Center Science & Society. Accessed September 5, 2022. https://www.pewresearch.org/science/2019/08/02/trust-and-mistrust-in-americans-views-of-scientific-experts/.
- Gilligan-Lee, K., Farran, E. K., Topor, M., Williams, A. Y., and Silversteain, P. (2022), STORM Project. Available at https://osf.io/av4ky/. Accessed 2 August 2022.
- Gonzálvez-Gallego, N., and Nieto-Torrejón, L. (2021), “Can Open Data Increase Younger Generations’ Trust in Democratic Institutions? A Study in the European Union,” PloS One, 16, e0244994. DOI: 10.1371/journal.pone.0244994.
- Grahe, J. E., Cuccolo, K., Leighton, D. C., and Cramblet Alvarez, L. D. (2020), “Open Science Promotes Diverse, Just, and Sustainable Research and Educational Outcomes,” Psychology Learning & Teaching, 19, 5–20. DOI: 10.1177/1475725719869164..
- Hardwicke, T. E., Mathur, M. B., MacDonald, K., Nilsonne, G., Banks, G. C., Kidwell, M. C., Hofelich Mohr, A., Clayton, E., Yoon, E. J., Henry Tessler, M., Lenne, R. L., Altman, S., Long, B., and Frank, M. C. (2018), “Data Availability, Reusability, and Analytic Reproducibility: Evaluating the Impact of a Mandatory Open Data Policy at the Journal Cognition,” Royal Society Open Science, 5, 180448. DOI: 10.1098/rsos.180448.
- Hardwicke, T. E., Wallach, J. D., Kidwell, M. C., Bendixen, T., Crüwell, S., and Ioannidis, J. P. A. (2020), “An Empirical Assessment of Transparency and Reproducibility-Related Research Practices in the Social Sciences (2014–2017),” Royal Society Open Science, 7, 190806. DOI: 10.1098/rsos.190806.
- Horton, N. J., Baumer, B. S., Zieffler, A., and Barr, V. (2021), “The Data Science Corps Wrangle-Analyze-Visualize Program: Building Data Acumen for Undergraduate Students,” Harvard Data Science Review, 3. DOI: 10.1162/99608f92.8233428d..
- Houtkoop, B. L., Chambers, C., Macleod, M., Bishop, D. V. M., Nichols, T. E., and Wagenmakers, E.-J. (2018), “Data Sharing in Psychology: A Survey on Barriers and Preconditions,” Advances in Methods and Practices in Psychological Science, 1, 70–85. DOI: 10.1177/2515245917751886..
- Janssen, M., and Zuiderwijk, A. (2014), “Infomediary Business Models for Connecting Open Data Providers and Users,” Social Science Computer Review, 32, 694–711. DOI: 10.1177/0894439314525902..
- Melero, R., and Navarro-Molina, C. (2020), “Researchers’ Attitudes and Perceptions towards Data Sharing and Data Reuse in the Field of Food Science and Technology,” Learned Publishing, 33, 163–179. DOI: 10.1002/leap.1287..
- Meteyard, L., and Davies, R. (2020), “Best Practice Guidance for Linear Mixed-Effects Models in Psychological Science,” Journal of Memory and Language, 112, 104092. DOI: 10.1016/j.jml.2020.104092..
- Meyer, M. N. (2018), “Practical Tips for Ethical Data Sharing,” Advances in Methods and Practices in Psychological Science, 1, 131–144. DOI: 10.1177/2515245917747656..
- Mons, B., Neylon, C., Velterop, J., Dumontier, M., da Silva Santos, L., and Wilkinson, M. (2017), “Cloudy, Increasingly FAIR; Revisiting the FAIR Data Guiding Principles for the European Open Science Cloud,” Information Services & Use, 37, 49–56.
- Munafò, M. R., Nosek, B. A., Bishop, D. V. M., Button, K. S., Chambers, C. D., Du Sert, N. P., Simonsohn, U., Wagenmakers, E.-J., Ware, J. J., and Ioannidis, J. P. A. (2017), “A Manifesto for Reproducible Science,” Nature Human Behaviour, 1, 0021. DOI: 10.1038/s41562-016-0021.
- Ostblom, J., and Timbers, T. (2022), “Opinionated Practices for Teaching Reproducibility: Motivation, Guided Instruction and Practice,” Journal of Statistics and Data Science Education. DOI: 10.1080/26939169.2022.2074922..
- Poldrack, R. A., Barch, D. M., Mitchell, J. P., Wager, T. D., Wagner, A. D., Devlin, J. T., Cumba, C., Koyejo, O., and Milham, M. P. (2013), “Toward Open Sharing of Task-based fMRI Data: The OpenfMRI Project,” Frontiers in Neuroinformatics, 7, 12. DOI: 10.3389/fninf.2013.00012.
- Roche, D., Berberi, I., Dhane, F., Lauzon, F., Soeharjono, S., Dakin, R., and Binning, S. (2021), “Slow Improvement to the Archiving Quality of Open Datasets Shared by Researchers in Ecology and Evolution,” DOI: 10.32942/osf.io/d63js..
- Roche, D. G., Kruuk, L. E. B., Lanfear, R., and Binning, S. A. (2015), “Public Data Archiving in Ecology and Evolution: How Well Are We Doing?” PloS Biology, 13, e1002295. DOI: 10.1371/journal.pbio.1002295.
- Soeharjono, S., and Roche, D. G. (2021), “Reported Individual Costs and Benefits of Sharing Open Data among Canadian Academic Faculty in Ecology and Evolution,” BioScience, 71, 750–756. DOI: 10.1093/biosci/biab024..
- Tenopir, C., Rice, N. M., Allard, S., Baird, L., Borycz, J., Christian, L., Grant, B., Olendorf, R., and Sandusky, R. J. (2020), “Data Sharing, Management, Use, and Reuse: Practices and Perceptions of Scientists Worldwide,” PloS One, 15, e0229003. DOI: 10.1371/journal.pone.0229003.
- Towse, A. S., Ellis, D. A., and Towse, J. N. (2021a), “Making Data Meaningful: Guidelines for Good Quality Open Data,” The Journal of Social Psychology, 161, 395–402. DOI: 10.1080/00224545.2021.1938811.
- Towse, J. N., Ellis, D. A., and Towse, A. S. (2021b), “Opening Pandora’s Box: Peeking inside Psychology’s Data Sharing Practices, and Seven Recommendations for Change,” Behavior Research Methods, 53, 1455–1468. DOI: 10.3758/s13428-020-01486-1.
- Tucker, M. C., Shaw, S. T., Son, J. Y., and Stigler, J. W. (2022), “Teaching Statistics and Data Analysis with R,” Journal of Statistics and Data Science Education, 1–32. DOI: 10.1080/26939169.2022.2089410..
- Vilhuber, L., Son, H. H., Welch, M., Wasser, D. N., and Darisse, M. (2022), “Teaching for Large-Scale Reproducibility Verification,” Journal of Statistics and Data Science Education. DOI: 10.1080/26939169.2022.2074582..
- Weerakkody, V., Irani, Z., Kapoor, K., Sivarajah, U., and Dwivedi, Y. K. (2017), “Open Data and its Usability: An Empirical View from the Citizen’s Perspective,” Information Systems Frontiers, 19, 285–300. DOI: 10.1007/s10796-016-9679-1..
- Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., Gonzalez-Beltran, A., Gray, A. J. G., Groth, P., Goble, C., Grethe, J. S., Heringa, J., ’t Hoen, P. A. C., Hooft, R., Kuhn, T., Kok, R., Kok, J., Lusher, S. J., Martone, M. E., Mons, A., Packer, A. L., Persson, B., Rocca-Serra, P., Roos, M., van Schaik, R., Sansone, S.-A., Schultes, E., Sengstag, T., Slater, T., Strawn, G., Swertz, M. A., Thompson, M., van der Lei, J., van Mulligen, E., Velterop, J., Waagmeester, A., Wittenburg, P., Wolstencroft, K., Zhao, J., and Mons, B. (2016), “The FAIR Guiding Principles for Scientific Data Management and Stewardship,” Scientific Data, 3, 160018. DOI: 10.1038/sdata.2016.18.