
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Stochastic volatility, or variability that is well approximated as a random process, is widespread in modern finance. While understanding that volatility is essential for sound decision making, the structural and data constraints associated with complex financial instruments limit the applicability of classical volatility modeling. This article investigates stochastic volatility in functional time series with the goal of accurately modeling option surfaces. We begin by introducing a functional analogue of the familiar stochastic volatility models employed in univariate and multivariate time series analysis. We then describe how that functional specification can be reduced to a finite dimensional vector time series model and discuss a strategy for Bayesian inference. Finally, we present a detailed application of the functional stochastic volatility model to daily SPX option surfaces. We find that the functional stochastic volatility model, by accounting for the heteroscedasticity endemic to option surface data, leads to improved quantile estimates. More specifically, we demonstrate through backtesting that Value-at-Risk estimates from the proposed functional stochastic volatility model exhibit correct coverage more consistently than those of a constant volatility model.
1. Introduction
A functional time series is a time-ordered sequence
of random functions often used to model the time dynamics of random phenomena that live on a continuum
Functional time series models enable statistical analysis and prediction of curves and surfaces evolving over time. The study of functional time series has become increasingly relevant as the collection of data in high resolution or frequency has become commonplace.
Functional time series can offer key practical advantages over multivariate or vector time series. By modeling random phenomena on a continuum, functional time series meet the needs of real world applications in which measurement locations are often sparse, changing over time, or irregularly spaced. Applying multivariate time series methods in similar settings would require that measurements lie on a regular unchanging grid and demand special handling of missing data. Furthermore, the number of parameters associated with a vector time series model would grow with the number of measurement locations and quickly become unreasonable, whereas the parametrization of a functional time series model is independent of the measurement locations.
More fundamentally, functional time series methods extend the domain of functional data analysis to time dependent functional data. While the celebrated results of Karhunen (Citation1947) and Loève (Citation1945) imply that functional principal component analysis (FPCA) provides an optimal finite dimensional representation for i.i.d. functional data, that optimality no longer holds when observations exhibit time dependence. However, FPCA provides a foundation for the development of methods intended specifically for time dependent functional data. Further background on the foundations of functional data analysis and FPCA can be found in Ramsay et al. (Citation2005), Horváth and Kokoszka (Citation2012), and Hsing and Eubank (Citation2015).
Functional time series methods have found application in a wide variety of domains such as demographic forecasting (Hyndman and Booth Citation2008; Shang et al. Citation2011; Hyndman et al. Citation2013; Li et al. Citation2020), spatiotemporal modeling (Besse et al. Citation2000; Ruiz-Medina et al. Citation2014; Cressie and Wikle Citation2015; Jang and Matteson Citation2018; King et al. Citation2018), yield curve forecasting (Kowal et al. Citation2017; Citation2019; Sen and Klüppelberg Citation2019), high frequency finance (Hörmann et al. Citation2013; Aue et al. Citation2017; Huang SF et al. Citation2020; Li et al. Citation2020), traffic flow modeling (Klepsch et al. Citation2017), and electricity demand forecasting (Shang Citation2013; Yasmeen and Sharif Citation2015; Chen and Li Citation2017).
Many important multivariate time series models have been generalized to a functional setting. The functional analogue of the autoregressive integrated moving average (ARIMA) model has been developed by several authors. Bosq (Citation2000) developed the theoretical foundations of the functional autoregression model on Hilbert and Banach spaces, while Aue and Klepsch (Citation2017) studied the functional moving average model. Klepsch et al. (Citation2017) derived sufficient conditions for the wide-sense stationarity of a functional ARMA model on separable Hilbert spaces. Sen and Klüppelberg (Citation2019) explored how a functional ARMA model leads to a vector ARMA structure on the principal component scores. Li et al. (Citation2020) addressed long memory in functional time series by developing fractionally differenced functional ARIMA models. Developments related to forecasting functional time series appear in Hyndman and Shahid Ullah (Citation2007), Bosq (Citation2014), and Aue et al. (Citation2015). Kowal et al. (Citation2017) and Kowal et al. (Citation2019) introduced a Bayesian framework for functional time series through a dynamic linear model formulation.
Compared to the extensive literature on functional generalizations of ARIMA and dynamic linear models, relatively little has been written on the important problem of modeling heteroscedasticity in functional time series. In time series analysis, accounting for heteroscedasticity or time-varying volatility is critical to accurate and reliable uncertainty quantification in forecasting problems. Heteroscedasticity is commonly addressed through autoregressive conditional heteroscedasticity (ARCH) models, generalized autoregressive conditional heteroscedasticity (GARCH) models, or stochastic volatility (SV) models. In univariate time series, the ARCH model was proposed by Engle (Citation1982) and the GARCH model by Bollerslev (Citation1986), while the univariate SV model was proposed by Taylor (Citation1982) and Taylor (Citation1986), with further investigations and comparisons by Taylor (Citation1994), Shephard (Citation1996), and Ghysels et al. (Citation1996) among others. Multivariate GARCH models were examined in Bollerslev et al. (Citation1988) and Bollerslev (Citation1990), while multivariate SV models were considered in Harvey et al. (Citation1994), Daniélsson (Citation1998), and Asai et al. (Citation2006). Bayesian methods for multivariate GARCH and SV models were proposed in Vrontos et al. (Citation2003) and Yu and Meyer (Citation2006), respectively. To date, there have been several important contributions on the topic of heteroscedastic functional time series models. Hörmann and Kokoszka (Citation2010) formalized the notion of weakly dependent functional time series, while Hörmann et al. (Citation2015) addressed serial correlation through a dynamic Karhunen-Loève expansion, a functional analogue of the dynamic principal component analysis introduced for multivariate time series in Brillinger (Citation1981). Hörmann et al. (Citation2013) and Aue et al. (Citation2017) proposed functional ARCH and GARCH models, respectively.
This article investigates stochastic volatility in the functional time series setting. In ARCH/GARCH models, the conditional volatility process is a deterministic function of past data, while in SV models the conditional volatility is driven by its own stochastic process and is not measurable with respect to past observable information. Although seemingly less popular in applications, stochastic volatility models have been observed to provide a better fit with fewer parameters when compared to GARCH models (Daniélsson Citation1998; Kim et al. Citation1998). SV models also provide a natural discrete analogue to the stochastic differential equations used in option pricing, such as the stochastic volatility diffusion of Hull and White (Citation1987).
Stochastic volatility is ubiquitous in financial time series modeling, as it is often observed empirically in the dynamics of asset prices and returns (Hull and White Citation1987; Heston Citation1993; Heston and Nandi Citation2000; Gatheral Citation2006; Shephard and Andersen Citation2009). Accordingly, we illustrate the benefits of our functional stochastic volatility (FSV) model in a financial application and model the daily price movements of SPX options contracts. SPX options have the Standard and Poor’s 500 Index as the underlying asset. For each day from January 1, 2010 to December 31, 2017, we have quotes of hundreds to thousands of option contracts which differ by their strike price and time to maturity. These contracts can be understood as a discrete collection of points observed from an underlying continuous option surface. Exploratory analyses indicate that these SPX option surfaces exhibit stochastic volatility. We demonstrate through a backtest that the FSV model leads to more accurate estimates of the portfolio Value-at-Risk (VaR) compared to a constant volatility model as its quantile estimates consistently exhibit the correct coverage. Hence the FSV model can benefit portfolio managers, risk managers, and other practitioners who need to monitor risk metrics of portfolios containing futures, options, swaptions, and other derivatives whose price dynamics are determined by an underlying continuum. More broadly, the FSV model can benefit any forecaster who is concerned not only with prediction but also quantile estimation and uncertainty quantification for functional time series data.
We now outline the remainder of the article. Section 2 describes the FSV and justifies the consideration of a finite-dimensional form. Section 3 addresses Bayesian inference for the FSV model. Section 4 presents the application of the FSV model to SPX option portfolio risk management.
2. Method
In time series analysis, data often exhibit both time-varying volatility and autocorrelation. Therefore, SV models are commonly used in conjunction with ARMA models by allowing the innovations of the ARMA process to have time-varying volatility. In this section, we formulate the FSV model in the context and notation of a functional ARMA model. Then we show how the FSV model can be reduced to a tractable finite dimensional representation that facilitates inference with familiar techniques from vector time series. Lastly, we describe the basis functions used for dimension reduction.
2.1. Functional Stochastic Volatility
We define an FSV model as a sequence of random functions that can be decomposed as the product of a volatility process with a serially uncorrelated noise process. More precisely, let be compact and let
be the set of square-integrable functions defined on
Suppose
is a sequence of random functions in
that can be decomposed as the product
where
is a sequence of i.i.d. mean zero random functions in
2.2. Functional ARMA with Stochastic Volatility
We assume that the data of interest arise from an underlying functional ARMA process driven by an FSV process as defined in the previous section. More precisely, suppose for each time t that Yt is observed at
locations with measurement error as
where
are the observation locations,
is the mean function, and
is the measurement error.
The functional ARMA(p,q) model for satisfies
(1)
(1)
where
is a sequence of mean zero random functions with
and
when
for all
In other words, the functions
are uncorrelated across time but not necessarily independent. These conditions are satisfied by the FSV model in Section 2.1, and hereafter we will suppose that
is an FSV process. The parameter kernel functions
and
are analogous to the parameter matrices in a multivariate ARMA model and determine the time-varying conditional mean.
Previous work has established sufficient conditions for the existence of a unique wide-sense stationary and causal solution to EquationEquation 1(1)
(1) . Suppose the volatility process
is wide-sense stationary so that there exists a common function
for all t, implying that
It is shown in Theorem 3.8 of Klepsch et al. (Citation2017) and in Li et al. (Citation2020) that a unique wide-sense stationary and causal solution exists provided that
and
are Hilbert-Schmidt kernels so that
and
for each j, and
satisfies the summability condition
The functional ARMA model can be defined more generally with bounded linear operators acting on separable Hilbert spaces as in Klepsch et al. (Citation2017).
For the sake of simplicity and computational tractability, we will work with the functional AR(1) process and drop the index on the kernel function ψ1 so that
2.3. Reducing a Functional Time Series to a Vector Time Series
The functional ARMA model becomes more tractable upon making a few assumptions. In particular, we suppose there exist orthonormal deterministic functions such that the following conditions hold:
The functional ARMA process
The kernel
3. The coefficient vectors
and the conditional covariance function of is defined and satisfies
where is the sigma field generated by
and
with
Under assumptions 1–3 above, the coefficients form a K-dimensional first order vector autoregressive, or VAR(1), process satisfying
where
is assumed diagonal and equal to
The coefficient series
is a VAR(1) process with stochastic volatility as the conditional covariance matrix of
depends on the random vector
and thus is not
-measurable.
In this article, we use VAR(1) dynamics for a choice well-suited for modeling volatility clustering. More precisely, we suppose
For the sake of parsimony, we assume the matrices and
are diagonal and that the series
is independent of the series
for all distinct pairs of indices j and k. Thus, for K-dimensional parameter vectors
and
we have
Letting and
we can succinctly summarize our hierarchical model as follows:
(2)
(2)
(3)
(3)
(4)
(4)
(5)
(5)
where
A functional ARMA(p,q) process can similarly be reduced to a VARMA(p,q) process with stochastic volatility. The assumptions that are orthonormal and
is diagonal could be relaxed through the use of a structural VAR with stochastic volatility as in Chan (Citation2021).
2.4. Basis Function Selection
A functional time series represents an infinite-dimensional random process, but in practical implementations we seek a finite-dimensional representation which, under suitable regularity conditions, best approximates the underlying process with minimal information loss. In our application, we use the first K functional principal components, estimated from spline-smoothed functional data, as our basis functions Refer to Section 1 of the supplementary material for justification, and to Kneip (Citation1994), Hall and Vial (Citation2006), Chakraborty and Panaretos (Citation2019), and Mohammadi and Panaretos (Citation2021) for further foundations on assessing the finite dimensionality of functional data.
3. Inference
This section describes Bayesian inference for the FSV model. Subsection 3.1 briefly reviews Gibbs sampling, while Subsection 3.2 presents the prior specification and resulting full conditional distributions.
3.1. Markov Chain Monte Carlo and Gibbs Sampling
Suppose our observed data are sampled from a joint density
where
represents the parameters of the model. Let
be the prior density on
The posterior density after observing
is given by
See Gelman et al. (Citation2013) for an overview of Bayesian data analysis.
For many complex models, the posterior density cannot be evaluated analytically because the integral in the denominator is intractable. To address this problem, Markov Chain Monte Carlo (MCMC) methods (Robert and Casella Citation2004) construct a Markov chain on the parameter space that has the posterior as its stationary distribution. The sample path of the Markov chain can then be used to approximate posterior summaries, functionals, or other quantities of interest.
The Gibbs sampling algorithm proceeds by partitioning the parameter space into disjoint blocks such that and then iteratively sampling from the full conditional distributions
The full conditional distributions are often analytically tractable even when the joint posterior distribution is not. One advantage of the Gibbs sampling approach is that it does not require any tuning parameters. The Gibbs sampling algorithm is also modular, allowing one to plug in existing techniques to sample from the full conditional distributions when they are available. See Robert and Casella (Citation2004) for a more detailed description of the Gibbs sampling algorithm, its theoretical properties, and its origins.
3.2. Prior Specification and Full Conditional Distributions
This section presents the prior specification for the FSV model and the resulting full conditional distributions. In order to write these succinctly, we introduce matrix variate notation to simplify EquationEquations 2–5 in Section 2.3.
From the terms in EquationEquations 3–5, we define the following KT-dimension random vectors and
Then the random vectors satisfy
(6)
(6)
where
and
and
denote the K × K identity and zero matrices respectively.
From the terms in EquationEquation 2(2)
(2) , we set
and define the ny-dimensional random vectors
and
along with the block diagonal matrix
Then we have
Writing the SV parameters as
it follows from EquationEquation 2
(2)
(2) that
and
For the log-variance process h and its associated SV parameters the priors are assigned as in Kim et al. (Citation1998) and Kastner and Frühwirth-Schnatter (Citation2014). More specifically, the conditional prior of h given
factors as
where
and the priors of the SV parameters
are independent so that
with
for all k.
To the remaining parameters, we assign the following priors, which yield closed form full conditional distributions:
where
indicates a K × K matrix normal distribution with mean matrix M and scale matrices U and
The density function is given in Section 3 of the supplementary material. The notation
indicates an inverse gamma distribution with shape parameter
and scale parameter
In summary, all full conditional densities will be proportional to the joint density of which factors as
The full set of prior hyperparameters is
The full conditional distributions of h and along with an associated sampler are presented in Kim et al. (Citation1998) and Kastner and Frühwirth-Schnatter (Citation2014). After Gibbs updates to
and
is recalculated through EquationEquation 6
(6)
(6) . As each
is assumed to be independent of the others with different k, each
is a univariate time series with an associated stochastic volatility process
as in Kim et al. (Citation1998). That article carries out Bayesian inference for
and its three associated parameters
through a mixture sampler applied to
The R package stochvol developed by Kastner (Citation2016) employs this mixture sampler as well as the Ancillarity-Sufficiency Interweaving Strategy in Kastner and Frühwirth-Schnatter (Citation2014) to achieve highly efficient Bayesian inference.
The remaining full conditional distributions are as follows:
where
The full conditional distributions for and
follow from the well-known Bayesian linear regression with the normal-inverse-gamma conjugate prior. A derivation can be found, for example, in Gelman et al. (Citation2013). Though the dimension of
is potentially very large, we can exploit the block structure of its precision matrix. Section 2 of the supplementary material describes how to sample efficiently from the full conditional for
Refer to Section 3 of the supplementary material for a derivation of the full conditional for
We note that the above Bayesian inference can readily be extended to the associated VAR(p) of a functional AR(p) process using Minnesota-type priors as in (Doan et al. Citation1984; Litterman Citation1986; Giannone et al. Citation2015; Chan Citation2021). For the VARMA(p,q) case with q > 0, this extension is less straightforward.
4. Value-at-Risk Estimation for Option Portfolios
In this section, we apply the FSV model to SPX option surface data in order to estimate Value-at-Risk for option portfolios. The results indicate that modeling stochastic volatility can improve quantile estimates in this setting. Subsection 4.1 provides an overview of the application. Subsection 4.2 describes in detail the SPX option surface data set and its representation as a functional time series Subsection 4.3 motivates the application of an FSV model through an exploratory analysis and visualizes the basis functions chosen for the application. Subsection 4.4 discusses the construction of a forecast distribution for
from posterior samples and describes how the forecast distribution is used to estimate quantiles. Subsection 4.5 evaluates the quality of the forecast against a benchmark constant volatility model.
4.1. Overview of Application
The field of financial risk management is concerned with estimating worst case outcomes (rather than mean outcomes) in order to quantify the magnitude of potential losses due to adverse movements in market prices or other risk factors. Consequently, the problem of quantile estimation is of key importance. Stochastic volatility models are often employed in the field because they better represent the empirical movements of financial time series and, as a result, improve upon quantile estimates for univariate and multivariate time series (Sadorsky Citation2005; Han et al. Citation2014; Huang AY Citation2015; Bui Quang et al. Citation2018). This application tests whether the same pattern holds for a functional time series.
In the present application, the functional time series represents a surface of option price quotes and is modeled with the proposed FSV model. An option gives the owner the choice to buy (if a call option) or sell (if a put option) an underlying asset St at some fixed strike price κ at some future maturity date u > t. For any single underlying asset (such as the S&P 500 Index) there exists an entire surface of options for that asset, because options can differ by their strike price κ and maturity date u. These two variables define the dimensions of the domain variable
The range variable
can be thought of as a proxy for the price of the option with contract terms τ, as there is a one-to-one relationship between
and the option price. These variables are described in full detail in Subsection 4.2.
Consider a loss random variable for some functional
The loss random variable
represents the decrease in value of a portfolio of options from time t to time t + 1. The functional Πt is determined by the composition of the option portfolio held at time t. Both
and Πt are constructed explicitly in Subsection 4.4.
The next-day Value-at-Risk for
is defined as
(7)
(7)
(8)
(8)
In other words, Value-at-Risk is the quantile function for the loss random variable
Estimating Value-at-Risk is a key problem in financial risk management as it identifies the potential magnitude of loss Lt due to the random market price movements of Yt.
A natural approach for evaluating the quality of an estimator is to compare the proportion of observed exceedences of the quantile estimate to the true level of the quantile. Define the exceedence indicator variables
for
and set
If we assume the Xt variables are independent and identically distributed, then
Kupiec (Citation1995) proposes a binomial hypothesis test of
against
in order to evaluate the whether the estimator
has the correct exceedence rate. This is done on a year-by-year basis in Subsection 4.5.
4.2. SPX Option Surface Data Set as a Functional Time Series
This section describes the SPX option data set and its representation as a functional time series. It will provide full descriptions of the domain and range variables, and motivate the use of a functional time series model.
A European option is a financial contract that, at some fixed maturity date in the future, gives the owner the option to purchase (if a call option) or sell (if a put option) a unit of an underlying asset at a fixed strike price, regardless of the actual market price of said asset. In the case of an SPX option, the underlying asset is the Standard & Poors (S&P) 500 Index.
Our method is applied to daily SPX option surfaces sourced from OptionMetrics’s IvyDB database (2017) from January 1, 2010 to December 31, 2017. There are T = 2013 days in total. Each daily option surface includes between 1400 and 10,000 option contracts, which are differentiated by their strike price, date of maturity, and whether they are call options or put options. Option prices are quoted based on their Black-Scholes implied volatility, the log of which is the variable of interest There is a one-to-one relationship between the option price and
(see EquationEquation 11
(11)
(11) ). The unfamiliar reader can regard
as a proxy for option price.
The domain variable is two-dimensional with
being the square root of number of days to maturity, and
being the Black-Scholes call option delta, which is the change in call option premium for a $1.00 change in the underlying asset price holding all other parameters including implied volatility fixed. The formula for
is given in EquationEquation 13
(13)
(13) . The variable
is set as such because the implied volatility of an option is a function of its remaining time to maturity instead of the preset date of maturity. The variable
is set as the call option delta so that implied volatility is static with respect to the ratio of the underlying asset price to the strike price instead of the absolute strike price. The functional domain
is the rectangle determined by the two univariate domains:
We include both call and put options in our analysis. They share the same implied volatility if their strike price and maturity match, but their option deltas differ by a deterministic relationship. In order to keep domain variables equivalent for the two types of options, we convert a put option’s delta to its equivalent call option delta by adding to its value. Refer to Hull (Citation2018) for an introduction to option pricing. Since illiquid option prices have high measurement error, options whose bid-ask spread is larger than 10% of the premium are excluded from the analysis.
On any given day t, the observation points are determined by the options traded on the market that day. The set of observation points changes every day, motivating the use of a functional time series model for the SPX option data set. The observation set changes each day because the option contracts in the market are issued with a fixed date of maturity. Hence, the remaining time to maturity
decreases with each passing day and all observation points shift towards the short maturity end of the domain with observations dropping out the domain when contracts mature (that is, when
). Furthermore, new observations enter the domain whenever new sets of option contracts are issued. Lastly, movements in the underlying S&P500 Index change the delta
of all options simultaneously, resulting in daily lateral shifts in observation points.
4.3. Basis Function Estimation and Exploratory Analysis
This section motivates the use of an FSV model. We estimate the functional basis that will be passed into subsequent Bayesian analysis using FPCA and present an initial exploratory analysis. The sample time courses and principal component scores suggest that the functional time series exhibits stochastic volatility.
We used penalized spline smoothing, as implemented in the R package mgcv by Wood (Citation2011), to estimate the mean function and functional principal components
These are shown in . The following knot sequences, chosen based on empirical quantiles of the observation points, were used in each dimension of the domain to define the cubic tensor splines:
Figure 1. Mean Function and Functional Principal Components
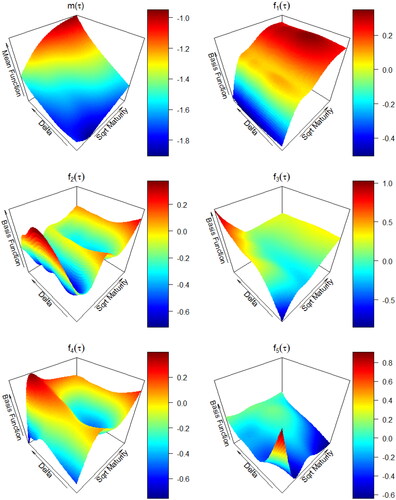
The mean function demonstrates the characteristic “volatility skew” endemic to equity option markets. The Black-Scholes model assumes a Gaussian distribution for market returns. If such an assumption were true, the observed volatility surface would be flat. However, we see that the S&P500 returns exhibit both heavy tails and a negative skewness, leading to convexity and skewness in the mean function, respectively.
We have found that setting K = 5 leads to interpretable basis functions corresponding to local effects acting on specific regions of the domain. The first principal component is negative when time to maturity is small while positive when time to maturity is large, resulting in a tilt of the surface with respect to maturity. The second principal component
results in a bending effect with respect to maturity. The third principal component
tilts the short maturity end of the surface with respect to delta. The fourth principal component
has a similar bending effect as the second but pushes the edges upward in general. The fifth principal component
pushes up one of the corners.
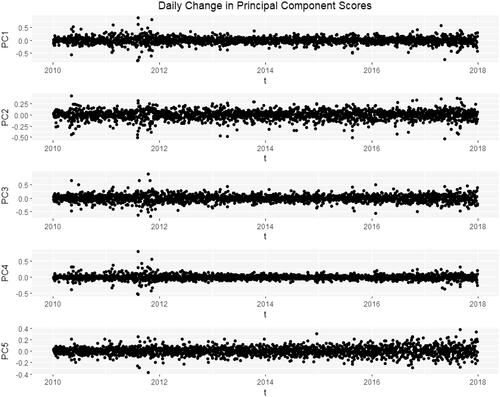
In an exploratory analysis, we see evidence for stochastic volatility. For five fixed sample domain points the differenced time courses
are shown in . The time-differenced principal component scores are shown in . Both sets of series exhibit stochastic volatility and motivate the application of the FSV model. Because the amount of stochastic volatility observed in the previous section varies year-by-year, the model is fit separately to each of the 8 years of data.
Figure 2. Differenced time courses for five sample locations
which exhibit stochastic volatility.
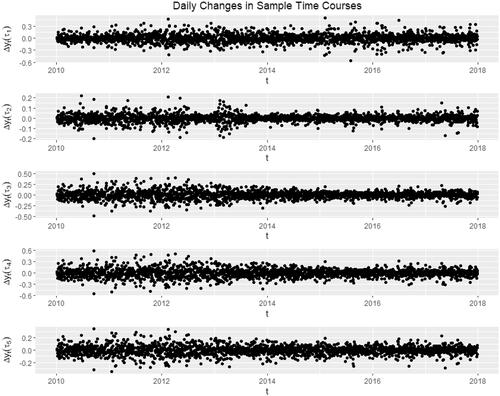
Figure 3. Differenced Principal Component Scores which exhibit stochastic volatility.
4.4. Value-at-Risk Estimation for Option Portfolios
A forecast distribution for portfolio loss is required to estimate quantiles and thus Value-at-Risk. This section describes how to use the posterior samples produced by our MCMC algorithm to build a conditional forecast distribution
for a next-day option portfolio loss random variable
where
The option portfolio pricing functional Πt is explicitly described by EquationEquations 11–15. The forecast distribution
is constructed from EquationEquations 4.4
(4)
(4) –14. The key quantity of interest in financial risk management is the Value-at-Risk (VaR) which is defined by the quantile of a loss distribution for a given time horizon and is defined in EquationEquation 7
(7)
(7) .
For this application, we complete the prior specification as follows. For each k,
while
The prior for follows the example of Kim et al. (Citation1998) and implies a prior mean of 0.86 to reflect the volatility clustering endemic to financial time series. We have found that the results are not sensitive to the choice of priors for μk and σk provided the series has a reasonable length. The hyperparameters of the matrix normal prior for
and the inverse gamma prior for
were chosen so that these prior distributions do not strongly influence the results.
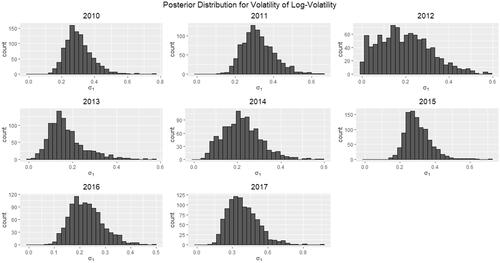
As we saw in our exploratory analysis (see and ), the amount of stochastic volatility varies for each year. Thus, we fit the FSV model separately to each year of data. presents the 95% pointwise credible intervals for each of the log-volatility processes htk against t. Years 2010–2011 and 2015–2017 exhibit a higher degree of roughness in the random variation, indicating a higher presence of stochastic volatility for these years. This is further illustrated by the posterior histograms of the stochastic volatility parameter σ1 appearing in . The histograms are bounded away from zero, especially in the years 2010–2011 and 2015–2017. The results are similar for
Figure 4. 95% pointwise credible bands for the latent log-volatility process with posterior median in bold. Dates range from start of 2010 to end of 2017. The roughness of random variation in htk indicates a notable presence of stochastic volatility in years 2010–2011 and 2015–2017.
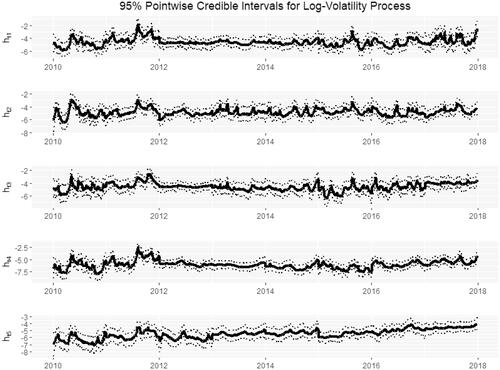
Figure 5. Posterior distributions for σ1, the volatility of The histograms exhibit most of their probability mass away from 0 particularly in the years 2010–2011 and 2015–2017, indicating the presence of stochastic volatility.
To simplify the presentation of what follows, it should be understood that a posterior draw corresponds to the fit from the year containing t. For each posterior sample from the associated year’s model parameters we forecast the option surface at time t + 1 from time t as follows:
where
Given this forecast of the implied volatility surface and observation points
we can compute the Black-Scholes log-implied volatilities
as
(9)
(9)
With their implied volatilities known, the options in the portfolio can be priced with the Black-Scholes formula (Black and Scholes Citation1973). If an option’s log-implied volatility at time t is yt, then its price is given by
(10)
(10)
(11)
(11)
where
(12)
(12)
and
St is the spot price of S&P500 at time t,
κ is the option strike price,
qt is the dividend yield of S&P500 at time t,
yt is the log of implied volatility at time t,
Suppose on day t the set of traded options are at locations Then the updated observation points
on day t + 1 are calculated as follows:
Days to maturity
Option delta
The other option parameters
These forecasted option prices can be compared to the actual option prices and
on days t and t + 1, respectively, to assess the performance of the forecast. Given a portfolio with cti units of option i for
we can compute the forecasted loss distribution
and actual loss
of the portfolio as
(14)
(14)
(15)
(15)
We can take sample quantile of the forecasted loss distribution as our estimate of the
one-day Value-at-Risk, setting
(16)
(16)
The next step is to assess whether the quantiles of the forecast distribution match the quantiles of the true loss distribution.
4.5. Backtesting Value-at-Risk
In order to evaluate the accuracy of our Value-at-Risk estimates, we can test if the historically observed exceedence rates of our quantile estimates are consistent with the true quantile levels. This process of evaluation based on historical data is known as backtesting. A 95% Value-at-Risk estimate should be breached by approximately 5% of observed losses if the observed trials are independent and the estimate is accurate. We can test whether the estimator proposed in Subsection 4.4 is accurate in this sense using the binomial hypothesis test discussed in Subsection 4.1.
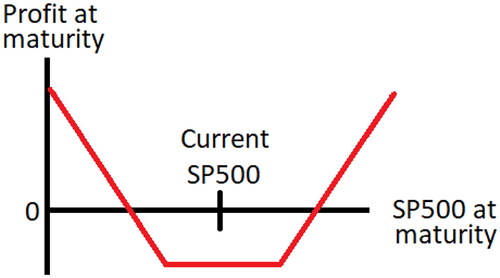
We focus on option portfolios whose values are most sensitive to movements in volatility. An option strangle is a portfolio consisting of an out-of-money call option (whose strike is below the current S&P 500 level) and an out-of-money put option (whose strike is above the current S&P 500 level) where the call and put strikes are roughly the same distance apart from the current S&P 500 level. Such portfolios are particularly sensitive to movements in implied volatility since a strangle profits from large moves in the S&P but loses money on small moves. The profit diagram of a strangle portfolio is illustrated in .
Figure 6. Profit diagram for an option strangle portfolio.
The binomial test of Kupiec (Citation1995) described in Subsection 4.1 requires independent trials, so we use a different randomized option portfolio on each trading day in order to decorrelate the trials. To construct these randomized portfolios, on each day a set of random out-of-money options are chosen from the subset of options common to both days t and t + 1 so that the actual price movement can be computed. These out-of-money options are chosen in 25 unique pairs of calls and puts so that we can form strangle positions. Hence, if a call option with strike price
is selected, then the put option whose strike is closest to
is also chosen so that the put and call options are roughly the same distance apart from the current spot price with both options out-of-money.
For each consider a simple randomized portfolio
on these 50 options where each cti is either 1 or −1 with equal probability. These coefficients determine the portfolio pricing functionals
through EquationEquations 14
(14)
(14) and Equation15
(15)
(15) . Since the actual price movements of these portfolios are known, we can apply the binomial hypothesis test described in Subsection 4.1 to the one-day Value-at-Risk estimator in EquationEquation 16
(16)
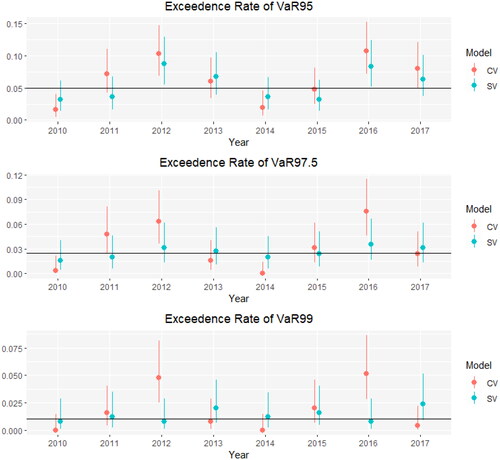
(16) . A separate binomial test is done for each year. The 95% confidence intervals of the exceedence rates of VaR95, VaR97.5, and VaR99 are shown in blue in .
Figure 7. 95% confidence intervals for the exceedence rates of value-at-risk. CV indicates constant volatility while SV indicates stochastic volatility.
For comparison, we also made forecasts based on a benchmark model with constant volatility. The benchmark model assumes each coefficient series has constant volatility
Setting
the benchmark model satisfies
for all t. Each vk is assigned an independent
prior. The full conditional distribution for v is standard, and all other full conditional distributions remain the same with the substitution
for each t.
The results in indicate that the exceedence rates of the stochastic volatility-based VaR estimates are generally closer to the true quantile levels than those of the constant volatility-based VaR estimates. The binomial confidence intervals associated with the stochastic volatility model’s VaR estimates include the true level in almost all years, while the intervals associated with the constant volatility model’s VaR estimates miss far more frequently. These findings indicate that incorporating stochastic volatility leads to better quantile estimates.
5. Conclusion
To review, we introduced an analogue of the familiar stochastic volatility model for functional time series, with the goal of accurately modeling option surfaces. We reduced that functional specification to a finite dimensional vector time series model and discussed a strategy for Bayesian inference that enables forecasting, quantile estimation, and other uncertainty quantification. Motivated by an exploratory analysis that revealed evidence of stochastic volatility, we applied the FSV model to SPX option surfaces and demonstrated through backtesting that the FSV model leads to improved quantile estimates and thus improved Value-at-Risk estimates for option portfolios.
Supplemental Material
Download PDF (215.5 KB)Additional information
Funding
References
- Asai M, McAleer M, Yu J. 2006. Multivariate stochastic volatility: review. Econom Rev. 25(2–3):145–175.
- Aue A, Horváth LF, Pellatt D. 2017. Functional generalized autoregressive conditional heteroskedasticity. J Time Ser Anal. 38(1):3–21.
- Aue A, Klepsch J. 2017. Estimating functional time series by moving average model fitting. arXiv:170100770.
- Aue A, Norinho DD, Hörmann S. 2015. On the prediction of stationary functional time series. J Am Stat Assoc. 110(509):378–392.
- Besse PC, Cardot H, Stephenson DB. 2000. Autoregressive forecasting of some functional climatic variations. Scand J Stat. 27(4):673–687.
- Black F, Scholes M. 1973. The pricing of options and corporate liabilities. J Polit Econ. 81(3):637–654.
- Bollerslev T. 1986. Generalized autoregressive conditional heteroskedasticity. J Econom. 31(3):307–327.
- Bollerslev T. 1990. Modelling the coherence in short-run nominal exchange rates: a multivariate generalized ARCH model. Rev Econom Stat. 72(3):498–505.
- Bollerslev T, Engle R, Wooldridge J. 1988. A capital asset pricing model with time-varying covariances. J Polit Econ. 96(1):116–131.
- Bosq D. 2000. Linear processes in function spaces: theory and applications. Lecture notes in statistics. New York: Springer.
- Bosq D. 2014. Computing the best linear predictor in a Hilbert space. applications to general ARMAH processes. J Multivariate Anal. 124:436–450.
- Brillinger DR. 1981. Time series: data analysis and theory. Vol. 36. Philadelphia (PA): SIAM.
- Chakraborty A, Panaretos VM. 2019. Testing for the rank of a covariance operator. The annals of statistics (forthcoming). https://arxiv.org/pdf/1901.02333.pdf.
- Chan JC. 2021. Minnesota-type adaptive hierarchical priors for large Bayesian VARs. Int J Forecasting. 37(3):1212–1226.
- Chen Y, Li B. 2017. An adaptive functional autoregressive forecast model to predict electricity price curves. J Business Econ Stat. 35(3):371–388.
- Cressie N, Wikle C. 2015. Statistics for spatio-temporal data. New York: Wiley.
- Daniélsson J. 1998. Multivariate stochastic volatility models: estimation and a comparison with VGARCH models. J Empirical Finance. 5(2):155–173.
- Doan T, Litterman R, Sims C. 1984. Forecasting and conditional projection using realistic prior distributions. Econom Rev. 3(1):1–100.
- Engle RF. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica. 50(4):987–1007.
- Gatheral J. 2006. The volatility surface: a practitioner’s guide. Wiley finance series. New York: John Wiley & Sons.
- Gelman A, Carlin J, Stern H, Dunson D, Vehtari A, Rubin D. 2013. Bayesian data analysis. 3rd ed. Chapman & Hall/CRC Texts in statistical science. Boca Raton (FL): Taylor & Francis.
- Ghysels E, Harvey A, Renault E. 1996. Stochastic volatility. Montreal: Centre Interuniversitaire de Recherche en Économie Quantitative, CIREQ. Cahiers de recherche.
- Giannone D, Lenza M, Primiceri GE. 2015. Prior selection for vector autoregressions. Rev Econ Stat. 97(2):436–451.
- Hall P, Vial C. 2006. Assessing the finite dimensionality of functional data. J R Stat Soc B. 68(4):689–705.
- Han CH, Liu WH, Chen TY. 2014. VaR/CVaR estimation under stochastic volatility models. Int J Theor Appl Finan. 17(02):1450009.
- Harvey A, Ruiz E, Shephard N. 1994. Multivariate stochastic variance models. Rev Econ Stud. 61(2):247–264.
- Heston SL. 1993. A closed-form solution for options with stochastic volatility with applications to bond and currency options. Rev Finance Stud. 6(2):327–343.
- Heston SL, Nandi S. 2000. A closed-form GARCH option valuation model. Rev Finance Stud. 13(3):585–625.
- Hörmann S, Horváth L, Reeder R. 2013. A functional version of the ARCH model. Econom Theory. 29(2):267–288.
- Hörmann S, Kidziński L, Hallin M. 2015. Dynamic functional principal components. J R Stat Soc B. 77(2):319–348.
- Hörmann S, Kokoszka P. 2010. Weakly dependent functional data. Ann Stat. 38(3):1845–1884.
- Horváth L, Kokoszka P. 2012. Inference for functional data with applications. Springer series in statistics. New York: Springer.
- Hsing T, Eubank R. 2015. Theoretical foundations of functional data analysis, with an introduction to linear operators. Wiley series in probability and statistics. Chichester: Wiley.
- Huang AY. 2015. Value at risk estimation by threshold stochastic volatility model. Appl Econ. 47(45):4884–4900.
- Huang SF, Guo M, Chen MR. 2020. Stock market trend prediction using a functional time series approach. Quant Finance. 20(1):69–79.
- Hull J. 2018. Options, futures, and other derivatives. London: Pearson.
- Hull J, White A. 1987. The pricing of options on assets with stochastic volatilities. J Finance. 42(2):281–300.
- Hyndman R, Booth H. 2008. Stochastic population forecasts using functional data models for mortality, fertility and migration. Int J Forecasting. 24(3):323–342.
- Hyndman RJ, Shahid Ullah M. 2007. Robust Forecasting of mortality and fertility rates: a functional data approach. Comput Stat Data Anal. 51(10):4942–4956.
- Hyndman RJ, Booth H, Yasmeen F. 2013. Coherent mortality forecasting: the product-ratio method with functional time series models. Demography. 50(1):261–283.
- Jang PA, Matteson DS. 2018. Spatial correlation in weather forecast accuracy: a functional time series approach. JSM 2018 Proceedings, Statistical Computing Section, 2776–2784.
- Karhunen K. 1947. Über lineare Methoden in der Wahrscheinlichkeitsrechnung. Annales Academiae Scientiarum Fennicae. 37:1–79.
- Kastner G. 2016. Dealing with stochastic volatility in time series using the R package stochvol. J Stat Software Art. 69(5):1–30.
- Kastner G, Frühwirth-Schnatter S. 2014. Ancillarity-sufficiency interweaving strategy (ASIS) for boosting MCMC estimation of stochastic volatility models. Comput Stat Data Anal. 76:408–423. CFEnetwork: the annals of computational and financial econometrics.
- Kim S, Shepherd N, Chib S. 1998. Stochastic volatility: likelihood inference and comparison with ARCH models. Rev Econ Stud. 65(3):361–393.
- King MC, Staicu AM, Davis JM, Reich BJ, Eder B. 2018. A functional data analysis of spatiotemporal trends and variation in fine particulate matter. Atmos Environ. 184:233–243.
- Klepsch J, Klüppelberg C, Wei T. 2017. Prediction of functional ARMA processes with an application to traffic data. Econom Stat. 1(C):128–149.
- Kneip A. 1994. Nonparametric estimation of common regressors for similar curve data. Ann Statist. 22(3):1386– 1427.
- Kowal DR, Matteson DS, Ruppert D. 2017. A Bayesian multivariate functional dynamic linear model. J Am Stat Assoc. 112(518):733–744.
- Kowal DR, Matteson DS, Ruppert D. 2019. Functional autoregression for sparsely sampled data. J Business Econ Stat. 37(1):97–109.
- Kupiec PH. 1995. Techniques for verifying the accuracy of risk measurement models. JOD. 3(2):73–84.
- Li D, Robinson PM, Shang HL. 2020. Long-range dependent curve time series. J Am Stat Assoc. 115(530):957–971.
- Litterman RB. 1986. Forecasting with Bayesian vector autoregressions – five years of experience. J Business Econ Stat. 4(1):25–38.
- Loève M. 1945. Fonctions Aléatoires de Second Ordre. Comptes Rendus de l’Académie des Sciences. Série I: Mathématique. 220:469.
- Mohammadi N, Panaretos VM. 2021. Detecting whether a stochastic process is finitely expressed in a basis. https://arxiv.org/abs/2111.01542
- OptionMetrics. 2017. IvyDB US file and data reference manual, version 3.1, Rev. 1/17/2017. New York (NY): OptionMetrics; p. 10019.
- Quang P, Klein T, Nguyen N, Walther T. 2018. Value-at-risk for south-east Asian stock markets: stochastic volatility vs. GARCH. JRFM. 11(2):18.
- Ramsay J, Ramsay J, Silverman B, Media SS, Silverman H. 2005. Functional data analysis. Springer series in statistics. Cham: Springer.
- Robert CP, Casella G. 2004. Monte Carlo statistical methods. Springer texts in statistics. Cham: Springer.
- Ruiz-Medina M, Espejo R, Ugarte M, Militino A. 2014. Functional time series analysis of spatio–temporal epidemiological data. Stoch Environ Res Risk Assess. 28(4):943–954.
- Sadorsky P. 2005. Stochastic volatility forecasting and risk management. Appl Financ Econ. 15(2):121–135.
- Sen R, Klüppelberg C. 2019. Time series of functional data with application to yield curves. Appl Stochastic Models Bus Ind. 35(4):1028–1043.
- Shang HL. 2013. Functional time series approach for forecasting very short-term electricity demand. Appl Stat. 40(1):152–168.
- Shang HL, Booth H, Hyndman R. 2011. Point and interval forecasts of mortality rates and life expectancy: a comparison of ten principal component methods. DemRes. 25:173–214.
- Shephard N. 1996. Statistical aspects of ARCH and stochastic volatility. London: Chapman & Hall; p. 1–67. Reprinted in the Survey of Applied and Industrial Mathematics, Issue on Financial and Insurance Mathematics, 3, 764–826, Scientific Publisher TVP, Moscow, 1996 (in Russian).
- Shephard N, Andersen TG. 2009. Stochastic volatility: origins and overview. Berlin, Heidelberg: Springer Berlin Heidelberg. p. 233–254.
- Taylor S. 1982. Financial returns modelled by the product of two stochastic processes-a study of the daily sugar prices 1961-75. Time Ser Anal Theory Pract. 1:203–226.
- Taylor S. 1986. Modelling financial time series. New York: Wiley.
- Taylor S. 1994. Modelling stochastic volatility: a review and comparative study. Math Finance. 4(2):183–204.
- Vrontos ID, Dellaportas P, Politis DN. 2003. A full-factor multivariate GARCH model. Econom J. 6(2):312–334.
- Wood SN. 2011. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J R Stat Soc B. 73(1):3–36.
- Yasmeen F, Sharif M. 2015. Functional time series (FTS) forecasting of electricity consumption in Pakistan. IJCA. 124(7):15–19.
- Yu J, Meyer R. 2006. Multivariate stochastic volatility models: Bayesian estimation and model comparison. Econom Rev. 25(2–3):361–384.