
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In financial markets, systemic risk is a type of risk in which the failure of one stock in the market triggers a sequence of failures. Our study proposes a Bayesian decision scheme to dynamically monitor systemic risk under any preferences and restrictions in financial risk management. We begin by capturing the moving correlations of stock returns because such correlations represent the strengths of the relationships among stocks. Then, we construct a dynamic financial network to link the stocks with strong relationships. Using the financial space, which is related to the position of stocks in the network plot, we locate two stocks in the financial space that are a short distance apart, because the relationship between these two stocks is strong. Using the distances between stocks in the financial space, together with the salient preferences and restrictions in financial risk management, we propose a systemic risk score. We then use 20 years of data to demonstrate the effectiveness of our proposed systemic risk score to give an early signal of global financial instabilities.
1. Introduction
Systemic risk describes a chain of failures among institutions or markets that is triggered by contagion from a failure in one of them (Chan et al. Citation2005). Compared with the failure of an individual institution, we might think it unlikely that many institutions could fail simultaneously. However, institutions can never isolate themselves from external influences (Bhar and Nikolova Citation2013; Raddant and Kenett Citation2021), and the relationships among the institutions, as one source of systemic risk, can transfer a failure from one to another. Even if the initial shock is created by the failure of one institution, it can create a chain of breakdowns when the relationships among institutions are strong (Contreras et al. Citation2022). The subprime mortgage crisis in 2008 (Dwyer and Tkac Citation2009; Tomczak Citation2023) is a well-known global incident demonstrating the importance of studying systemic risk in the markets. A market crash will also induce a high level of systemic risk—such as the crash of 2020, which was brought about by the COVID-19 pandemic (So et al. Citation2021b). Regional incidents, too, including the European sovereign debt crisis (Ureche-Rangau and Burietz Citation2013) and the war in Ukraine (Lockett Citation2022), affect not only the local markets but also the global market, and research on the immediate impact and aftershocks of these crises is still ongoing. In this paper, we develop a new approach for measuring systemic risk over time that incorporates a variety of financial risk-management scenarios.
Extensive research has suggested several possible directions (De Bandt and Hartmann Citation2000; Benoit et al. Citation2017) for the study of systemic risk. One direction focuses on balance sheets and macroeconomic data (Jackson and Pernoud Citation2021), with the balance sheet approach reflecting major businesses’ relationships with other institutions (Hanson et al. Citation2011; Haldane and May Citation2011; Cai et al. Citation2018), while the macroeconomic data approach reflects the market situation (Brunnermeier Citation2009; Rodríguez-Moreno and Peña Citation2013; He and Krishnamurthy Citation2019). Another direction focuses on textual information (Maiya and Rolfe Citation2014; Kawata and Fujiwara Citation2016; So et al. Citation2022), extracting real-time financial news and building a network based on keywords to track the market situation.
Our proposal for the study of systemic risk focuses on the relationships revealed by daily stock returns. We assume that, if a business relationship exists between two institutions, any news concerning one of them will affect the stock returns of both. Therefore, by capturing the correlations of stock returns (De Nicolo and Kwast Citation2002; Blei and Ergashev Citation2014), we can measure the strength of the business relationship between those two institutions. When the relationships among institutions in the market are strong, any bad news about one member of the market can trigger a chain reaction of failures (Mantegna and Stanley Citation1999). Therefore, it is important to detect the pairs of institutions that possess a strong relationship (Battiston et al. Citation2012; Thurner and Poledna Citation2013; Huang et al. Citation2013; So et al. Citation2021a).
In the literature, several useful statistics are aimed at using stock returns to detect the relationships between institutions and market crashes, including but not limited to systemic expected shortfalls (SES) (Acharya et al. Citation2017), SRISK (the expected capital shortfall of a financial entity, conditional on a prolonged market decline) (Brownlees and Engle Citation2017), CoVaR (the value at risk (VaR) of the financial system, conditional on institutions being under distress) (Adrian and Brunnermeier Citation2016), and Absorption Ratio (AR), which measures supply and demand (Kritzman et al. Citation2011). Using statistical models to capture the instability contributed by the relationships among institutions is also possible (Girardi and Ergün Citation2013; So et al. Citation2020a, Citation2021c). Some studies have analyzed the market situation by using network statistics (Tabak et al. Citation2014; Wang et al. Citation2017; Neveu Citation2018; So et al. Citation2021a; Lai and Hu Citation2021; So et al. Citation2021b). As a further development on these approaches, Billio et al. (Citation2012) constructed a systemic risk measure using principal component analysis and a network of Granger-causality. Hautsch et al. (Citation2015) studied the realized systemic risk (volatility) beta value, using the significant relationship in the tail event, along with information from the market and balance sheets. Diebold and Yılmaz (Citation2014) considered the variance decomposition technique to construct a network to measure systemic risk. Wang et al. (Citation2021) considered a multilayered network to handle various types of stock information in detecting systemic risk. Härdle et al. (Citation2016) considered the network-analysis-based tail event on stock returns.
As with the work of some others, our proposal involves Bayesian methods in the computation of systemic risk—such use is not new. Gandy and Veraart (Citation2017) considered a weighted directed network that measured individual liabilities among institutions. Ballester et al. (Citation2023) studied the transmission of systemic credit risk by using a Bayesian network. Lupu et al. (Citation2020) estimated some common systemic risk measures with a Bayesian entropy estimation method. Deng and Matteson (Citation2022) proposed the Bayesian Spillover Graphs to study the dynamic network and identify some special features of the network.
Specifically, the proposed systemic risk measurement is based on the work of Das (Citation2016), and two components constitute our score. First, we assign a weight to each institution with the Bayesian framework. In application, investors may for example have a greater concern about systemic risk among the institutions that belong to a particular industry, and the relationships among institutions in that industry should be the focus, even though the business relationships of others also deserve attention. Another example would be an investor who faces restrictions on investments or has preferences for systemic risk management; the proposed systemic risk score has set up a weight with the Bayesian framework to adjust to those restrictions and preferences.
In addition to the weight assigned to each stock, we aggregate information from the pairwise relationships of institutions, to measure their contribution to systemic risk. We consider a network model that represents the institutions as nodes and the significance of business relationships by edges. When an institution fails, the impact first transfers to those who have a business relationship with the failed institution. Depending on the strength of their relationship to the failed institution and the loss in that impact, other institutions might then generate the next impact and transfer it to a further institution, which may not be directly linked to the source of the first impact (Martínez-Jaramillo et al. Citation2010; Aiyar Citation2012; Acemoglu et al. Citation2015). Therefore, a network model that highlights those strongly related institutions accounts for the contagion of failure resulting from connectedness in the market (Chen et al. Citation2020).
Although a network model explores and visualizes significant business relationships, our study builds further upon the financial network with a latent space, extending the concept of the latent space from Chu et al. (Citation2021). The latent space converts the binary indicator in the network—whether or not a pair of institutions is significantly related—to a continuous measure of the likelihood that a pair of institutions is related. The latent space includes all of the institutions as points and assigns each one’s position such that the distance between two points reflects the significance of their relationship to all other institutions in the latent space. An advantage of using the latent space model over simply a network model is that the distances in latent space can provide hints that indicate the indirect relationships between two institutions, formed by a chain of institutions, by assigning a short distance between the institutions, while the distance in a network—that is, the length of the shortest path between institutions—may miss it. Some studies visualize the network and make use of the arrangement of positions in the visualization to measure systemic risk (Heimo et al. Citation2007; Linardi et al. Citation2020). We have chosen a Bayesian approach to look for the best position in the latent space. Combining these two components, then, we take the weights of each institution and the network with an embedded latent space, or what we call the financial space, since the space is related to financial information, as input into the systemic risk score.
To the best of our knowledge, we are the first to combine a Bayesian framework for weight assignments and the concept of a financial network with an embedded latent space. As an application of the systemic risk score, we attempt to construct an early signal that warns of impending market crashes. We consider the stock return data in the Hong Kong market for the past 20 years and use the systemic risk score to detect any prior signal of the financial turnulence during that period. We also compare the model’s performance in raising an early signal with that of other well-known systemic risk measures. In the literature, Billio et al. (Citation2016) proposed an early signal based on entropy measures with the financial market in Europe. Allaj and Sanfelici (Citation2022) used realized variance and the feedback rate of price volatility to construct an early signal. We examine our proposed model by considering dynamic time wrapping, which matches the pattern of two time series, to determine the lead and lag relationships. When the systemic risk score leads the market returns before and during the crashes at a reasonable distance, we say that the systemic risk score has raised an early signal predicting the market crashes. We also use the systemic risk score to demonstrate various applications for establishing the weight of each institution in the Bayesian framework. We demonstrate that our approach overcomes the difficulties in determining a representative weight under complex risk-management restrictions and preferences.
In the remainder of this paper, Section 2 describes the study’s methods and materials and the details and setup of the two components of the proposed systemic risk score, and lists other systemic risk measures for comparison. Section 3 describes the approach to estimate the model parameters and the relevant settings. Section 4 describes the experimental approach, the results of the comparison, and some properties of the systemic risk score. Section 5 discusses the results, summarizes the limitations of our model, and proposes possible directions for future research.
2. Materials and Methods
2.1. Systemic Risk Score
Suppose there are n stocks in the financial market of interest. Our proposed systemic risk score takes two inputs, the first of which is the weight of stock i in measuring the systemic risk, for
Because the weights determine the amount of attention we pay to each stock, the purpose of calculating systemic risk determines how we should assign the weights. Let
be the vector of weight. In our study, we made two assumptions on the weights:
All entries in
are non-negative, and
The sum of all entries of
The first assumption is required to ensure that the systemic risk score is well-defined. Following this assumption, a zero weight for stock i means that the stock i receives minimum attention or is not being considered when measuring systemic risk. The second assumption is not compulsory. This assumption says that we measure the attention to each stock in a relative sense, instead of in an absolute sense. This is also helpful when we compare the systemic risk score across scenarios. For example, suppose that we treat the weights as the amount of assets allocated to each stock. The systemic risk score will be proportional to the total capital, even if the proportion of assets allocated to each stock is identical. Only when we put the weights on the same scale will the comparison across portfolios become meaningful.
The next input to the proposed systemic risk is the contribution of systemic risk given by the relationship between stock i and j. As explained in the Introduction, strong relationships between stocks build the path toward a failure contagion. We assign the value of
according to the strength of the relationship, accounting not only for the direct connection but also for the indirect connection, which is linked through a chain of intermediates.
We make use of the significance of the business relationships between stocks, together with the importance of the stocks, to construct the systemic risk scores. Let is a matrix of systemic risk contributions given by the pairwise relationships of stocks. Our systemic risk score is defined by
a function of both the weights and the systemic risk contributions. There are many possible formulations for systemic risk, but motivated by Das (Citation2016), we select those with the following properties:
S has to be non-negative. In particular, when
When
S is continuously differentiable on the weight
The first property ensures a natural representation of risk: If we do not put weight on any asset, the systemic risk in our consideration must be 0. The second property follows directly from the meaning of the matrix C: The higher the contribution given by the relationship of a pair of stocks, the higher the systemic risk. The third property is helpful for understanding the proposed systemic risk score. This property ensures that scaling all of the weights by a positive factor will scale the by the same factor.
Hence, according to Euler’s homogeneous function theorem, we decompose the systemic risk into the sum product of the partial derivatives and the weights.
(1)
(1)
Based on EquationEquation (1)(1)
(1) , the partial derivative with respect to
represents the change in systemic risk per unit weight contributed by a small change in weight. If the partial derivative is large, stock i will have a large influence on the systemic risk. This happens when the relationships between stock i and some other stocks contribute significantly to the systemic risk, and consequently, those stocks should be the focus of our attention. Therefore, we adopt the systemic risk score S in this study, so that
(2)
(2)
The fraction in EquationEquation (2)
(2)
(2) is necessary for the third property. Putting the partial derivatives and the weights together, we have
(3)
(3)
Because there is a square root outside the quadratic form we need to guarantee that the sum inside the square root of EquationEquation (3)
(3)
(3) is positive. A sufficient condition is to require C to be positive semi-definite. In our case, because the weights are non-negative, we only require all entries of C to be non-negative.
2.2. Bayesian Decision Theory Applied to Various Financial Scenarios
The assignment of weights – that is, of the attention we pay to each stock—depends on the situation. For example, if we care about the systemic risk encountered in a particular portfolio, we can set the weights as the proportion of assets allocated to each stock. We can always find the optimal allocation by minimizing the systemic risk score. However, in a case in which there are some restrictions or limitations on the weight selection, instead of looking for an optimal allocation, we are interested in studying how these restrictions affect the systemic risk.
Therefore, instead of looking for a single weight to represent the financial scenario, we produce multiple values for systemic risk, one on each possible combination of weights. This approach coincides with the framework of Bayesian decision theory (Rachev et al. Citation2008; Ando Citation2009). We assign a distribution to the weights and then study the distribution of systemic risk score defined in EquationEquation (3)
(3)
(3) . This approach bypasses the difficulties of looking for a weight that represents the scenario. Adopting the Bayesian decision process also gives us flexibility in setting the level of importance of each of the possible weights. Although multiple weights are available under the constraints, some of them are in favor of the market participants. The level of importance distinguishes the amount of emphasis put upon each of the weights, which in the framework of Bayesian decision theory is equivalent to setting an informative prior for the weights. Correspondingly, the prior density takes on the role of the level of importance.
Throughout our paper, we assign two kinds of distribution to the prior for the weights. We emphasize that other distributions are also possible, as long as they fit the financial scenario and the preference toward each combination of weights. The level of importance, or equivalently the prior density, assigned to each combination of weights, is determined by the hyperparameter, regardless of the choice of distribution. Therefore, the specification of hyperparameters is also important in setting up the financial scenario of interest.
The first distribution is the Dirichlet distribution. This distribution matches the two assumptions on the weights in Section 2.1 when there is no further restriction on the collection of possible combinations of weights. The hyperparameter of the Dirichlet distribution is a vector of length n, is positive in all entries, and determines the mean and variance of the weights
We have three specifications of hyperparameters to be considered in our study.
Random Allocation.
In a random allocation, every possible combination of weights has the same level of importance—such as taking every entry of
Allocation proportional to market capitalization.
In an allocation that is proportional to market capitalization, the mean of weights
Allocation including a risk-free asset.
In an allocation that includes a risk-free asset, one extra stock, representing the risk-free asset, is inserted into the consideration. Therefore, now we have
The second distribution to the prior for the weights is a joint of multiple independent scaled Dirichlet distributions. This is the distribution of weights when each stock is pre-assigned into exactly one of the G groups, and the sum of the weights of stocks in each group is predetermined. We let
Allocation with an equally shared industry sum of weights.
In an allocation with an equally shared industry sum of weights, we first classify the stocks according to their industry. Within each group, we use a random allocation—that is, we take every entry of
Allocation with the industry of focus.
In the allocation with an equally shared industry sum of weights, we have set the sum of weights in each group to be
Allocation with a weights competition within groups.
In the allocation with an equally shared industry sum of weights, we make use of the random allocation and state no preference for any combination of weights within each group. In this specification of an allocation with a weights competition within groups, stocks compete for weights within their group. We achieve this by taking every entry of
2.3. Setting up the Contribution of Systemic Risk with a Latent Space Model
The next input to the systemic risk score is the contribution of systemic risk given by the business relationship between two institutions. Information on the relationships between institutions is often inaccessible however, and even if we can gain access to the data, it is still not easy to determine the contribution to systemic risk given specifically by the two institutions’ relationship. Therefore, we need a proxy for the relationship between the two institutions. In our study, we choose the correlation of stock returns as our proxy. We believe that if two institutions have a significant relationship, whenever one of them suffers and its stock returns fall, the other one will also be impacted. We therefore first use the stock returns to construct a network of significant business relationships. Then, we embed a financial space into the network to further study the indirect business relationships, which are relationships created through a sequence of intermediate institutions (Ng et al. Citation2021).
2.3.1. Network Setup
We study the strength of the relationships by considering the correlations between the stock returns (Chen et al. Citation2020; Patro et al. Citation2013). Suppose our dataset of stock contains information of T trading days in total. Let is the closing price of stock
on day t. The log return
(4)
(4)
is the difference in the log price on two consecutive trading days. Let
be the 21-days historical average log return of stock i on day t – that is,
(5)
(5)
If the sample correlation of the 21-day historical log return between two distinct stocks i and j on day t
(6)
(6)
exceeds a threshold, we say the relationship between stocks i and j on trading day t is strong and we assign
otherwise, we set
Correlations of the 21-day historical average log return are significantly positive at
and
when
is at least 0.2914, 0.3687, 0.5034, respectively. We consider these three critical values as the thresholds in our study.
For each trading day t, we gather all over i and j to form an adjacency matrix
so that we put an edge between the nodes representing stocks i and j in the network of the day t if
Because the correlation is symmetric—that is,
—the dynamic network is a sequence of undirected networks. Also, we do not assign any value to
as we do not include the self-loop in the analysis.
2.3.2. Financial Space
The financial network assigns edges to indicate significant business relationships between institutions. To quantify the contribution of systemic risk, we introduce the concept of financial space, which is latent, unobserved, and D-dimensional. We first let be the coordinates of stock i in the financial space on trading day t. The financial space is a low-dimensional representation of the relationship among those stocks. In particular, the distance between two institutions in the financial space serves as a measurement of the strength of the relationship. Moreover, to have a better understanding of the distance between nodes, we follow a typical choice of
i.e. restricting our attention to a two-dimensional financial space, in the sequel (Sewell and Chen Citation2015). As a remark, in literature, some studies pick other choices of D when they are considering a more complex network (Zhang et al. Citation2022).
To give meaning to the distances, we consider a typical network plot that assigns the node positions to give a uniform length of edges and distribution of nodes, to avoid any crossing or blending of edges (Battista et al. Citation1994). This is often achieved by adopting a network configuration that assigns a shorter distance between those nodes that are more strongly related, and vice versa. To assess the systemic risk on each trading day t, we borrow the concept of “the shorter the distance, the stronger the relationship,” to give meaning to the distance between nodes i and j on the plot of the network corresponding to trading day t.
The financial space is a latent space, meaning that we measure the distance between institutions by considering their relative positions. By embedding the financial space into the network, we assign the nodes in the plot that match their position in the financial space. Therefore, instead of assigning the distances from observed information, we first locate each node in the financial space and then measure the distance between the two nodes. Unlike the nodes and edges in the networks, the financial space is latent and we do not observe the positions directly from the correlations or the network; therefore, we apply the technique of latent space modeling (Hoff et al. Citation2002; Sewell and Chen Citation2015; Chu et al. Citation2021) to find the positions that best represent the systemic risk in the market. The latent space modeling technique for a network aims to use a metric space, usually a two-dimensional Euclidean space, to explain the existence of edges between nodes in a network, and hence to explore the relationships between nodes.
Previous studies have used the nodes-distance measure to calculate connectedness among banks (Cai et al. Citation2018; Abbassi et al. Citation2017). By employing the distance measure, we can account for the relationship between nodes. Therefore, from the perspective of an individual stock, the closer it is to other nodes, the higher its chance of suffering contagion from the failure of those neighboring nodes. From the perspective of the market, the shorter the distance between stocks, the easier it is for financial incidents to initiate a contagion of failure, thereby triggering a systemic breakdown.
We then measure the distance between stocks i and j on day t by
(7)
(7)
where
is the Euclidean norm. Recall that the financial space is latent and unobserved. We need some rules to guide ourselves when looking for a position for each stock.
First, for each trading day, we aim to maintain an identical spread of positions. In other words, before considering any data, the positions of stocks on any trading day should have an identical distribution.
After the first day, we determine the positions for trading day t based on the positions from the previous trading day. To maintain an identical spread, we assume that stocks move from their previous positions with a suitable shrinkage towards the center. The center represents the average position that a stock holds throughout the entire study period. Additionally, we introduce the persistence parameter matrix to quantify the extent to which information from trading day
influences the positions on the current day. A larger value of the persistence parameter indicates a stronger influence of the positions from the last trading day on the current positions.
Let diagmat be a function that creates a diagonal matrix with its diagonal entries arranged in the same sequence as the input, represents the average position of stock i throughout the entire study period,
is a diagonal matrix that measures the transition sizes of the positions of stock i in the financial space between consecutive trading days, and
is also a diagonal matrix that measures the persistence of stock i. On day
we assume that the position for stock i follows a D-variate normal distribution:
(8)
(8)
where I is the identity matrix. After the first day, the position of stock i on trading day t is determined as follows:
(9)
(9)
For each stock i and dimension d, we consider the sequence as a univariate autoregressive time series of order 1. To ensure an identical variance over all the marginal distribution of the position in all t, we set the initial spread as
as shown in EquationEquation (8)
(8)
(8) , and restrict
for all i and d.
The setup in EquationEquations (8)(8)
(8) and Equation(9)
(9)
(9) indicates that the position of stocks across dimension are independent. Therefore, equivalent to EquationEquations (8)
(8)
(8) and Equation(9)
(9)
(9) , the position of stock i on dimension d on day 1 is
(10)
(10)
and the position of stock i on dimension d on day
is
(11)
(11)
2.3.3. Potential factors for Strong Relationships between Stocks
Multiple potential factors affect the chance for two stocks to be strongly related. In our study, we classify the stocks into groups by industry: Finance
Utilities
Properties
and Commerce & Industry
Stocks from the same industry share some common characteristics, thus inflating the correlations of their returns. However, any common characteristic is only limited to those within the same industry, so the inflation applies only to those pairs of stocks belonging to the same industry. The extra risk due to the common characteristic results in different probabilities when comparing a pair of stocks coming from the same industry to another pair coming from two different industries. In other words, if both stocks i and j come from industry m on trading day t, we assign Otherwise, if stocks i and j come from two different industries, we set
2.3.4. Forming a Network of Significant Business Relationships
We use the financial space and other potential factors to explain the significance of the relationship between two stocks. In our study, the significance of a business relationship depends on whether the correlation of returns exceeds the threshold described in Section 2.3.1, which is binary. Therefore, we assign a Bernoulli distribution for the significance of the relationship between stocks i and j on trading day t with a log odds
(12)
(12)
where
are the respective effects of the M covariates
We assume there is conditional independence on the status of relationships, given the corresponding log odds.
Under the formulation given by EquationEquation (12)(12)
(12) , when the factors increase by 1 unit, the log odds increase by
the corresponding value of the effect. The negative sign in front of
indicates that a smaller
leads to a larger
When the distance increases by 1 unit, the log odds decrease by 1 unit.
2.4. Contribution to Systemic Risk with Financial Space
Summarizing all of the above formulations about the financial network and financial space, we have constructed a relationship between the probability of observing a significant business relationship between two institutions and the latent financial space covering those potential factors, which are not included in the covariates. The distance in the financial space has taken into account the indirect relationship between institutions—a feature that comes from the triangular inequality of the Euclidean space. The distance between any two institutions is bounded above by the chain of intermediate institutions. Therefore, even though we are considering the pairwise correlation between the returns of two institutions, the financial space can also capture the indirect relationship.
With this advantage, we use the estimated log odds obtained by plugging the estimate of the latent position and the effect parameters into EquationEquation (12)
(12)
(12) , as a measure of the contribution to systemic risk. To satisfy the requirement that all entries of C are non-negative, we need to transform the log odds. With abuse of notation, we take a transformation C on the matrix
so that we can substitute C by
in EquationEquation (3)
(3)
(3) to calculate the systemic risk on day t. A natural choice is to set the
entry of the transformed output to be
(13)
(13)
because this transformation, which is the inverse function of the logit function, guarantees that the range of
is non-negative and also outputs the probability of stocks i and j having a significant positive correlation at time t. The diagonal entries
are fixed to be 1 to include the allocation of weights into the calculation of the systemic risk score. Therefore, the systemic risk score on trading day t becomes
(14)
(14)
To represent the sequence of the systemic risk score along time, we make an abuse of notation to set to be the systemic risk score on trading day t.
3. Parameter Estimation
In our study, we estimate the position in the financial space of stock
at time
the average position
of stock
the transition sizes of positions in the financial space
of stock
the parameter of persistence matrix
of stock
and the effect parameter
of the covariate
with a Bayesian approach.
3.1. Posterior Distribution
Let be the collection of all edges in the financial network,
be the collection of the positions in the financial space,
be the collection of all effect parameters for each covariate,
be the collection of all the average positions in the financial space,
be the collection of all transition sizes in the financial space in consecutive trading days, and
be the collection of all parameters of persistence.
We assign an independent normal prior with mean and variance
to the effect parameter
an independent normal prior with mean
and variance
to
an independent inverse gamma prior with shape
and scale
to
and an independent uniform prior to
In other words, we assume that
and
are independent of each other. Additionally, we assume that
and
are independent and local independence within
meaning that given all the parameters, the elements in
are independent of each other.
Based on the above assumptions, the log posterior of our model, with the constant term excluded, has the following generic form:
(15)
(15)
(16)
(16)
(17)
(17)
where we have made use of the Bayes theorem in EquationEquation (15)
(15)
(15) , the independence between
and
in EquationEquation (16)
(16)
(16) , and the independence among
and
in EquationEquation (17)
(17)
(17) .
Based on the local independent assumption, the likelihood has the following generic form:
(18)
(18)
where, following the EquationEquation (12)
(12)
(12) , the likelihood of single observation
is
(19)
(19)
We have dropped those parameters that are unrelated to the stock i and j on the trading day t in EquationEquation (18)(18)
(18) .
Let be the set of effect parameters
but
is excluded. The
of the full conditional of the effect parameters, with the constant term excluded, is
(20)
(20)
Let be the set of average positions
but
is excluded. The
of full conditional of the average position on dimension d of stock i, with the constant term excluded, is
(21)
(21)
Let be the set of transition sizes
but
is excluded. The
of full conditional of the persistence on dimension d of stock i, with the constant term excluded, is
(22)
(22)
Let be the set of persistence matrices
but
is excluded. The
of full conditional of the transition sizes on dimension d of stock i, with the constant term excluded, is
(23)
(23)
when all
3.2. Identification Issue
In our model, any two sets of the latent position in the financial space give the same likelihood when they are equivalent under rigid transformation, i.e. translation, reflection, rotation, and any sequence of the above three. This creates an identification issue because many sets of the position of stocks in the financial space give the same likelihood and thus we cannot distinguish them by the likelihood. Following the proof in Appendix F, in Bayesian analysis, the normal prior on the average position of each stock in the financial space, i.e. has eliminated the identification issue due to translation. The assumption of using a diagonal matrix for the covariance of the position in the financial space at each time point, i.e. EquationEquations (8)
(8)
(8) and Equation(9)
(9)
(9) , has eliminated the identification issue due to rotation, except for rotation about the origin by a multiple of
with
in our case.
Therefore, in our case, the identification issue on the parameters exists only due to reflection and rotation about the origin by a multiple of Rotation about the origin by a multiple of
is the same as first permuting the entries and then reflecting along the vertical axis. Therefore, in the following discussion, to further elaborate, we let
be a
permutation matrix which is obtained by swapping some of the rows in the identity matrix, and let
for
so that the reflection matrix
is a diagonal matrix with
or 1 in the diagonal. The model parameters
(24)
(24)
give the same posterior as that using the following model parameters
(25)
(25)
for any
and
Therefore, after each iteration of the MCMC, we transform the MCMC iterate according to the definition in EquationEquation (25)(25)
(25) to maintain the unique representation of the model parameters. The transformation follows these steps:
For each dimension
We select the permutation matrix
The first constraint addresses the identification issue caused by reflection. For each dimension d, there are two scenarios: either the absolute value of the minimum average coordinate is not greater than the absolute value of the maximum average coordinate, or vice versa. These two scenarios are equivalent and lead to the same posterior with appropriate choices of In our study, we choose the former scenario.
The second constraint deals with the identification issue arising from the permutation of coordinates. Although there are D! Scenarios in total, which are equivalent with appropriate choices of only one scenario exists where the maximum absolute value of the average coordinate forms a non-increasing sequence of length D.
In our case with the above constraints reduce to the followings:
For each dimension
If
Through this transformation, we can select the unique representation of the model parameters from a total of 4 sets of model parameters, which share the same posterior density, for each MCMC iterate.
3.3. Initial values
Because the posterior is intractable, we estimate the parameters via the Markov chain Monte Carlo (MCMC) method. As input to the MCMC, we first must assign the position for each stock in the financial space. In a full estimation, we assign a shorter distance between a pair of individuals if they are linked. In accord with Sewell and Chen (Citation2015), we estimate the distance matrix between institutions i and j at time t, denoted by the entry of
by
(26)
(26)
We then apply classical multidimensional scaling on each estimated distance matrices to obtain the first guess of the initial values of the positions in the financial space at each t. To avoid the nodes on the latent space clustering at the same position, we add a normal random noise with a standard deviation of 0.001 to each coordinate.
After that, to draw the best connection of stocks in the financial space over time, we sequentially, starting from perform a Procrustes transformation (Hurley and Cattell Citation1962) to get the second guess of the initial values of the positions in the financial space. The Procrustes transformation takes two inputs, one is the first guess of the initial values of the positions in the financial space at time
which we transform to the second guess. Another one is the second guess of the initial values of the positions in the financial space at time t, obtained from the previous transformation.
Let be the second guess of the initial value of
i.e. after the Procrustes transformation. The transformation rotates the first input about the origin to get
so that the sum of the squared Euclidean distances of all stocks traveled to
from
is minimized. The second guess of the initial values of the positions in the financial space at the first trading day directly takes the first guess, i.e. we do not transform with Procrustes the first guess of the initial values of the positions in the financial space.
We determine the initial value of effect parameters for
by fitting a logistic regression to
(27)
(27)
(28)
(28)
using the function glm in R, so that the distance between institutions in the financial space, and the known factors
for
are included as covariates. Suppose
is the estimate of
in the logistic regression for
We set the initial value of
denoted by
in the MCMC to be the same value as
for
Recall that, in our model, we have restricted to be
for identification. Therefore, after performing the logistic regression, we scale the coordinate of the stock in the financial space by a factor of
In other words, let
be the initial value of the position of stock i at trading day t in the financial space for MCMC. We have the initial value
(29)
(29)
for all i and t.
Finally, for each dimension d, we fit an autoregressive model of order 1 to the time series of using the function ar in R and then use the estimate of the mean, the standard deviation, and the autoregressive coefficient as the initial values of
and
denoted by
and
respectively.
3.4. Hyperparameters for the Priors
To utilize the result from the logistic regression fitted for the initial values of we set the mean of the normal prior of
to be the estimates of
obtained from the logistic regression, i.e.
The variance of the normal prior
i.e.
are set to be 10. The mean and variance of the normal prior of
are set to be
and
respectively. The shape and scale parameters of the inverse gamma prior of
are set to be 2.04 and 1.04, respectively, so that the prior mean and prior variance are 1 and 25. These setting aims at keeping the prior non-informative.
3.5. MCMC Algorithm
Suppose we take L iterates in total for the MCMC estimation. Given the state-space structure of our model, we adopt the particle Gibbs with the ancestor sampling method to improve the convergence (Lindsten et al. Citation2014). We use particles to balance the computational time and the convergence speed.
In the sequel, we introduce a superscript to the variables to indicate the MCMC sample at the
iteration. We also introduce the superscript
to represent the
particle in the
iterate. Furthermore, those parameters with tilde
on top represent the proposed sample. Denote
to be the collection of
from time
to
and
to be the realization of a random variable from the standard uniform distribution.
The variables a and indicate the acceptance ratio and controls the acceptance rate respectively. The subscript, attached to the acceptance ratio a and the variable controls the acceptance rate
indicates the parameters that these two variables refer to. The variables w, W, and A respectively refer to the unnormalized weight, normalized weight, and normalized ancestor weight that are used in the particle Gibbs. Let
be the index of the selected particle in the particle Gibbs that will be used as the MCMC sample.
Then, with the initial values set, for iteration
For all variables that we estimate via the MCMC, we first set the
Conduct a single step MCMC for each of
Sample
Calculate the acceptance ratio
If
Conduct a particle Gibbs with ancestor sampling for the position in the financial space
For
Sample for Q particles, denoted by
Set
Evaluate for each
where is a collection of stock indices excluding the index i.
For
(Resampling) Resample the Q particles, denoted by
where are the normalized weights.
(Ancestor Sampling) Sample 1 ancestor, denoted by
Sample for Q particles, denoted by
and set
Set
Evaluate for each
where is a collection of stock indices excluding the index i.
Select
and set the output (or equivalently
) to be
Conduct a single step MCMC for each of
Sample
Calculate the acceptance ratio
If
Conduct a single step MCMC for each of
Sample
Calculate the acceptance ratio
If
Conduct a single step MCMC for each of
Sample
Calculate the acceptance ratio
If
3.6. Settings of MCMC
During the estimation, we conduct iterations to obtain a sufficient number of samples for estimation. Furthermore, we treat the first
of iterates as burn-in. Therefore, we consider only the last 5000 iterates in the estimation.
Starting from the iterates, we adjust
and
which are the variables that control the acceptance rate of the proposal of
and
respectively, based on the acceptance rate for every 50 iterates until reaching the end of adaptation process. As we estimate the parameters one by one, we would like the acceptance rate to stay between
to
having a maximum difference of
from the optimal acceptance rate
(Gelman et al. Citation1997). We use the new step size for the next 50 iterates. This adapting process is repeated until we have made 3000 iterations. After that, we keep the step size until the end of the estimation. In Appendix D, we provide the diagnostic of the MCMC estimation.
4. Results
In this section, we first demonstrate four settings of the systemic risk score with the financial space model. By establishing a suitable distribution of the weights, the systemic risk score possesses intuitive properties that are useful in real-life applications. Then, we compare the performance of the systemic risk score with other approaches that are listed in Appendix A.
The aim of making the comparison is to evaluate the performance of each measure in detecting an early signal of future financial instability. By applying the dynamic time warping (DTW) algorithm (Giorgino (Citation2009); see Appendix B for details), we identify whether there are lead and lag relationships between the systemic risk measure and the market return
Here
indicates not only the systemic risk score proposed in Section 2.3 but also other formulations of the same systemic risk score and other competitive systemic risk measure. We will introduce them in the later section.
We first treat the systemic risk measure and the market return as functions of time. We can raise the early warning signal only if the systemic risk scores lead the market returns, meaning that the pattern appearing in a systemic risk score also appears in the market returns at a later date, at least during the periods of pre-turbulence and post-turbulence. In addition, given a leading relationship, the systemic risk measure should be increasing and taking a large value in the proximity of the market crashes, if it is going to indicate an early warning signal.
4.1. Experiment Setting
Our study focuses on the Hong Kong stock market during the 20 years from May 2003 to April 2023. We have chosen the constituent stocks of the Hang Seng Indexes as the stocks of interest. Therefore, in the DTW algorithm, we have chosen the returns of the Hang Seng Index (HSI) as a proxy of the market returns in Hong Kong.
We adopt a rolling window approach to monitor systemic risk using the most up-to-date information (Chan et al. Citation2023). The rolling window covers two years, the first of which comprises the trading days from May 2003 to April 2005. We make use of the financial network to estimate the parameters, including the effect of known factors and the position of the institution in the financial space. We then slice the window by one trading day and again estimate the parameters. In principle, we repeat the process of estimating the parameters and slicing the rolling window until the window reaches the last trading day in our study period.
The computational burden of the rolling window approach increases with the number of trading days in our study. To alleviate the burden, the parameters do not change significantly when we add a few days at the end of the rolling window or drop a few days at the beginning. This assumption is important because, instead of repeating the full estimation, we conduct a partial estimation by reusing the estimation result from an earlier rolling window.
Therefore, as is shown in , in the first rolling sample, we conduct a full estimation using the financial networks from May 2003 through April 2005. A full estimation involves all of the parameters, including the effect of known factors the position of stocks in the financial space
the average position of stock in the financial space
the transition sizes of positions in the financial space
and the parameter of persistence matrix
of the financial space. Then, in the period of partial estimation, in the
slice of the rolling window following the latest full estimation, we reuse the parameter estimates but with the position in the financial space from trading day T to
In the partial estimation, we conduct 50 iterates only to update the latest information, with no burn-in period. As an example, in the first slice, we estimate the position on the last trading day in April 2005 and the first trading day in May 2005 only. In the last slice, we estimate the position from the last trading day in April 2005 to the last trading day in May 2005.
Table 1. The rolling window scheme keeps the size of the data at two years in the full estimation.
After slicing to include the last trading day in the month of partial estimation, the first rolling sample is completed. In the next rolling sample, we start over with a full estimation, using the network from June 2003 through May 2005, and then we continue the slicing with partial estimation. This process is repeated until all 216 rolling samples are completed.
To calculate systemic risk, we must ensure that only the latest up-to-date information is involved and none of the future information is included. Therefore, we calculate only the value of systemic risk from May 2005 to April 2023, which are the trading days involved in the partial estimation. As an example, to assess the systemic risk on the first trading day in May 2005, we first conduct a full estimation of the financial networks from May 2003 to April 2005, and then we conduct a partial estimation to obtain the configuration of the financial space on the first trading day in May 2005. Finally, we use EquationEquation (14)(14)
(14) to calculate the value of systemic risk. The computational details related to the proposed systemic risk score are available in Appendix C.
In Appendix D.1, D.2, and E, the posterior density plot and trace plot provide evidence that the Markov chain has converged before the burn-in period. However, despite using the transformation described in Section 3.2 to establish the unique representation, we observe in Appendix E that the posterior density exhibits multiple modes. Furthermore, Appendix E demonstrates that the posterior mean yields a lower value in the posterior density compared to the posterior mode. Therefore, when computing the systemic risk score and determining the values utilized in the partial estimation, we employ the posterior mode instead of the posterior mean. Although our financial space model produces a multi-modal posterior density, the systemic risk score, as defined in EquationEquation (14)(14)
(14) , remains invariant to translation, reflection, and rotation in the financial space. This invariance arises because the score solely considers the distance between pairs of stocks in the financial space, disregarding their specific positions in the space.
4.2. Data
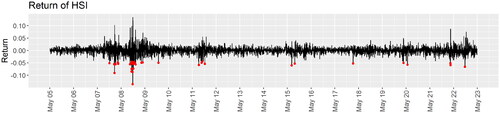
We first set up the period that is regarded as turbulence. In , we mark with red dots the trading days that the return of HSI has dropped below three standard deviations from the mean over the whole study period. We find that it has covered most financial turbulence in the study period, including but not limited to the subprime mortgage crisis and the global financial crisis from mid-2007 to early 2009, the fluctuation from mid to late 2011, China’s stock market turbulence (Han and Khoojine Citation2019) from mid-2015 to early 2016, the trade war between the US and China (Liu Citation2018) in 2018, the COVID-19 pandemic in early 2020, and the rapid transmission of COVID-19 in Hong Kong and the continuation of warfare in Ukraine (Lockett Citation2022; Jiaxing Li Citation2022) in 2022. Therefore, we select the periods mentioned above as the turbulence.
Figure 1. Return of HSI. The red dots are the trading days that the return dropped below the three standard deviations from the mean over the whole study period.
In , we present the densities of
and
the time series of networks constructed using the critical values for a 21-day historical correlation to be significantly positive at the
and
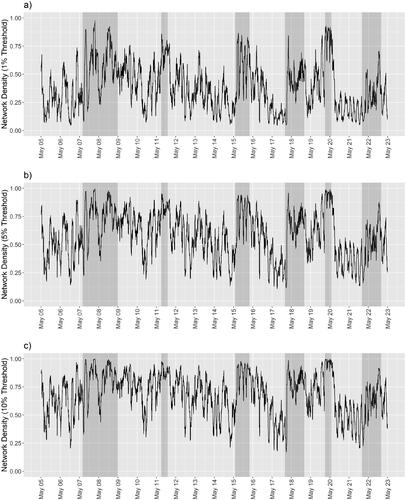
level, respectively. The regions shaded in gray are the periods when the financial turbulence occurs. We find that, except during 2022, when there is financial turbulence, the network densities often reach higher values than those during normal periods. The differences are more apparent in
than in
and
The differences in network densities between the normal and turbulent periods allow us to recognize an early signal when we observe an unusual increase in network densities. This builds the foundation for our further analysis of the network and the embedded financial space.
Figure 2. The network densities over time of the three networks constructed using the critical value for a 21-day historical correlation to be significantly positive at the (a) (b)
and (c)
levels.
4.3. Properties of Our Proposed Measure in Financial Risk Management
We plot the results of the comparisons in , in which each plot refers to a financial scenario comparing the specifications of the priors listed in Section 2.2. We summarize the four financial scenarios of interest in .
Figure 3. The systemic risk scores in four financial scenarios (Scenario 1: (a–c); Scenario 2: (d–f); Scenario 3: (g–i); Scenario 4: (j-l)) under three different threshold values of correlation in the construction of networks (1% Threshold: (a, d, g, j); 5% Threshold: (b, e, h, k); 10% Threshold: (c, f, i, l)). The red lines refer to the baseline systemic risk scores. The lines in other colors refer to the measurements of systemic risk under specific considerations.
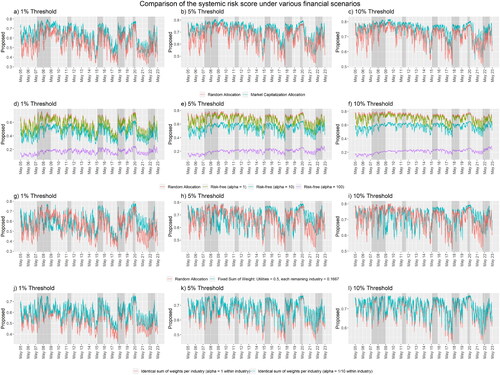
Table 2. The four financial scenarios that make use of the specifications of hyperparameters and distributions of choice are listed in Section 2.2.
The first specification represents a scenario that considers market capitalization, which equates to the total dollar value of a stock. A larger company often has a higher market capitalization and hence makes a greater contribution to systemic risk. Therefore, to calculate systemic risk, we use Dirichlet priors for the weights with the hyperparameters
proportional to the market capitalization shared among all stocks in the study; in other words, the prior mean is proportional to the market capitalization. To encourage the selection of weights that are close to the prior mean, we set the sum of all
to be the reciprocal of the smallest
so that all entries of
are at least 1. This arrangement assigns a higher level of importance to those combinations of weights that follow the market capitalization closely. The sum of the hyperparameters controls the penalty on the level of importance for those weights deviating from the proportion of market capitalization. In , the systemic risk score under the market capitalization allocation often has a higher systemic risk than the baseline. This is because approximately
of the total market capitalization is shared by one-fourth of the stocks. Therefore, a change in log odds in any of the dominating stocks in the financial space produces a greater effect on the systemic risk score than on the baseline.
The second specification includes in the analysis a risk-free asset, which does not contribute to systemic risk. Therefore, to reduce the impact brought about by financial instability, we allocate a certain proportion of money to the risk-free asset. To measure the systemic risk encountered in the portfolio with different preferences for the proportions allocated to the risk-free asset, we assign hyperparameters corresponding to each preference. First, we set the hyperparameters for all risky assets
This provides a fair ground for comparison with the baseline, which always has zero weight assigned to the risk-free asset. We then consider three cases, with each taking a different hyperparameter for the risk-free asset
The higher the hyperparameter for the risk-free asset, the higher the average proportion allocated to it. In our study, because the number of stocks varies over time, the corresponding average proportion allocated to the risk-free asset is also dynamic. Using the number of stocks that constitute the HSI on May 2023 – that is,
– when
and 100, the mean weights for the risk-free asset are
and
respectively. In , the higher the hyperparameter that is assigned to the risk-free asset, the smaller the systemic risk is, and the gap between cases is wider during financial turbulence than during normal periods. Moreover, none of the four lines cross each other. Therefore, we can claim that increasing the allocation to a risk-free asset always decreases the effect of financial turbulence on the portfolio, especially during financial turbulence. Thus, practitioners could design their portfolios by changing the proportion allocated to risk-free assets, to monitor the systemic risk encountered in their investments.
The third specification assigns a fixed-weight sum of stocks in each industry. We demonstrate this with a focus on the Utilities industry to study the impact of the COVID-19 pandemic and the global energy crisis (Rankin et al. Citation2021). In our study, stocks are classified in industries. Therefore, the sum of weights for the Utilities industry is 0.5, while for all other industries the fixed sum of weights is equally shared, i.e.
for each of the remaining three industries. Using the stock classification by HSI on May 2023, there are five stocks from the energy industry, so their average weights are
This specification shows the systemic risk of the Utilities industry; maintaining half of the weights from other industries accounts for the impact outside the Utilities industry. We observe that before March 2020, the systemic risk of the energy industry is more or less close to the baseline, but after March 2020, the systemic risk is usually above the baseline. This observation matches the actual situation, in which the COVID-19 pandemic and the global energy crisis increased systemic risk in the Utilities industry.
The last specification also presets a sum of the weights of stocks in each industry. We allocate assets to the stocks equally in each industry, but we prefer only a few within each industry. In traditional portfolio theory, investing in a wider variety of stocks diversifies risk. In this specification, each industry shares the same preset sum of weights. However, amateur investors often do not allocate their money equally to all stocks and instead select only a few from each industry. Although the average weight is identical to both the specification of interest and the baseline, we find that the systemic risk score for the specification of interest generally is higher than the baseline. This coincides with conventional wisdom, as each relationship between companies becomes more important.
4.4. Comparisons of Our Proposed Measures with Alternative Formulations
We also compare the performance on raising an early signal by the systemic risk scores and other systemic risk measures in the literature. We again use the market capitalization allocation for the weights. We show the point-to-point comparison plot produced by dynamic time wrapping for each of the formulations of the same systemic risk scores and some common systemic risk measures that are listed in Appendix A.
To facilitate the discussion, we let
and
be the time series of the systemic risk score constructed using the methods in EquationEquation (14)
(14)
(14) , where the corresponding adjacency matrices of the input time series of the networks to estimate
are
and
respectively. Let
and
be the time series of systemic risk score constructed using the methods in EquationEquation (A2)
(A2)
(A2) , where the adjacency matrices to compute the systemic risk score on trading day t are
and
respectively. Let
and
be the time series of the systemic risk score constructed using the methods in EquationEquation (A5)
(A5)
(A5) , where the input time series of networks to obtain estimated log odds are
and
respectively.
In , the systemic risk measures and the returns in the HSI are in red and blue, respectively. Each dotted line links two points so that there is one from each time series. The color of the dotted line indicates the leading time series. The gray dotted line indicates a tie. We evaluate the performance of each systemic risk measure by observing the period preceding the turbulence, where the periods of turbulence are shaded in gray. The red dotted line between the two curves indicates that the systemic risk measure has shown a pattern that later appears in the HSI returns.
Figure 4. We compare by dynamic time wrapping the performance of the Das (Citation2016) and our proposed systemic risk scores (red): using the financial space model (a–c), using the adjacency matrix directly (d–f), and using a random effects model (g–i), with the returns of the HSI (blue) as the reference. We construct the network using the critical value for 21-day of historical correlation to be significantly positive at the (a, d, g) (b, e, h)
and (c, f, i)
levels. We only present those dotted lines that are relevant to financial turbulence, to indicate the lead and lag relationships during the turbulence.
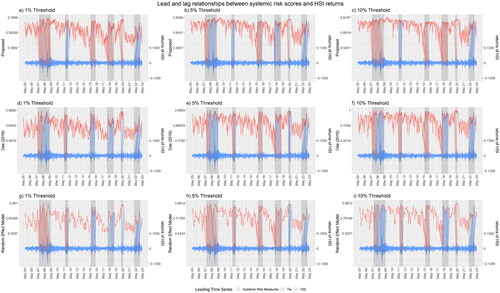
shows that regardless of the choice of systemic risk contribution and the threshold level in the construction of the network, we observe that there is an unusual climb in the values of the systemic risk score on or before the market crashes. Then, the systemic risk score falls gradually and keeps fluctuating until the next market crash.
also shows the performance of the systemic risk score in detecting an early signal of financial instability. To better illustrate, we have selected parts of the wrapping curve (dotted lines in the figures) that are relevant to the market crashes. We first observe the results from the network with the financial space. Before the global financial crisis in mid-2007, both the and
lead the market return for 6 months during the crisis and continued to increase for 3 to 6 months throughout the crisis period. We believe with the 1% and 10% threshold, the systemic risk score successfully represents an early signal about the market. In the market crash brought on by the COVID-19 pandemic, the
and
value leads the market return for 3 months, while only the
values lead for 6 months. In
the number of days ahead of the crashes brought on by the COVID-19 pandemic is also too long to claim as an early signal. The
and
values continued leading for three months during the crisis, and the systemic risk score is also climbing during the crisis period. Therefore, we believe that an early signal is demonstrated successfully.
On the other hand, in the market turbulence from mid to late 2011, the systemic risk score failed to raise an early signal. All three systemic risk scores were lagging behind the market return. In the crashes from mid-2015 through early 2016, the systemic risk score also failed to raise an early signal. Although all of them lead the market before the crashes, the number of days ahead of the crashes in all the three
and
are also too long to claim it as an early signal. Moreover, the climbing trend comes too late to raise an early signal. In the market turbulence in 2018, not to mention the lagging
although all of the
and
lead the market return, the number of days ahead are too long. Therefore, no early signal appears. Finally, in the market crash in 2022, none of the
and
leads the market returns throughout the period. Although we observed a climb near the end of March, the systemic risk score has already missed the greatest drop in that period. Therefore, early signals also do not appear.
Different results are delivered when we use the adjacency matrix instead of the financial space to measure the contributions to systemic risk, i.e. the formulation proposed by Das (Citation2016). As is shown in the middle row of , during the global financial crisis from mid-2007 to early 2009, the systemic risk score does not lead the market return throughout the crisis for all the
and
During the crashes brought by the COVID-19 pandemic, only the
leads for three months, giving a warning signal for the crisis, and in the remaining crashes, the systemic risk score lags the market returns. The leading by the
does not hold throughout the whole period of the COVID-19 pandemic crash. The
lags the market returns. In the market turbulence in mid to late 2011, the
has raised an early signal as it has led the market for 2 to 3 months. However, the leadership does not hold in
and
During the crashes in mid-2015 through early 2016, both
and
lead the market return, but the number of days ahead of the crashes is either too short or too long to claim it as an early signal. Moreover, the climbing trend in
comes too late to raise an early signal. None of
and
lead the market throughout the whole crashes in 2018 and 2022.
Similar observations were found when we used the random effects model to measure the contribution to systemic risk. The systemic risk score led the market returns during the global financial crisis from mid-2007 to early 2009 only in and
and the leadership with the
does not persist throughout the whole period. For the market crash brought by the COVID-19 pandemic, only the
leads for three months, giving a warning signal for the crisis. In the market turbulence from mid to late 2011, all the
and
failed to lead the market throughout the whole period. In the market crash from mid-2015 through early 2016, the
and
thresholds lead for 6 months. However, it is hard to claim that as a warning signal because the value of systemic risk is moving downward. In other combinations of thresholds and crashes, the systemic risk scores lag the market returns. In the turbulence throughout 2018,
lags the market return. Even though
leads the market return in the market, the systemic risk score is declining in the pre-crisis period and not lead throughout the whole period. The
also suffers from a similar issue but lags the market return in most of the turbulence period.
We also compare the number of times that the systemic risk score leads the market returns with reference to and . The proposed systemic risk score has a similar number of time points that leading the returns of the HSI when comparing them with the scores using the adjacency matrix and the random effects models. Comparing the systemic risk score based on the the proportion of time that the
leads the market returns is larger than
followed by
Comparing the systemic risk score based on the
the proportion of time that the
leads the market returns is smaller than both
and
Finally, comparing the systemic risk score based on the
the proportion of time that
leads the market returns is the least, followed by the
and finally the
We believe that it is more important to lead the market returns, as an early signal, in the proximity of the crashes. Therefore, in terms of the early signal that we have successfully demonstrated, the systemic risk score based in the financial space performs better than the other two setups do.
Figure 5. The complete wrapping curves between the Das (Citation2016) and our proposed systemic risk scores (red): using the financial space model (a-c), using the adjacency matrix directly (d-f), and using a random effects model (g-i), with the returns of the HSI (blue) as the reference. We construct the network using the critical value for 21-day of historical correlation to be significantly positive at the (a, d, g),
(b, e, h), and
levels (c, f, i).
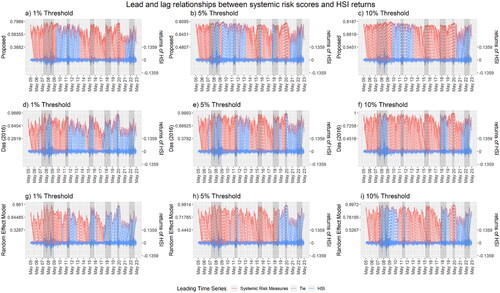
Table 3. Number of time points in the wrapping curve that each systemic risk score leads, ties with, or lags the returns of the HSI, as summarized from .
Next, we consider the performance of other systemic risk measures. shows the performance of three other systemic risk measures in providing an early signal of financial instability. Again, those regions shaded in gray are the periods of market turbulence or worldwide financial incident. We have selected the parts of the wrapping curve that are relevant to the market crashes for better illustration.
Figure 6. We compare here by dynamic time wrapping the performances of three other systemic risk measures: (a) CoVaR, (b) the systemic expected shortfall, and (c) the absorption ratio, using the returns of the HSI as the reference time series. We include only the dotted lines for the time points that are relevant to financial turbulence.
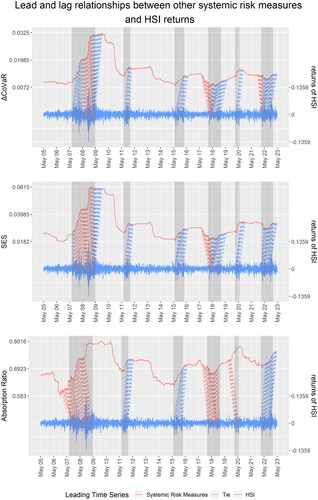
Although all three measures climb during most market crashes, the systemic risk measure seldom leads the market returns throughout the periods of the crashes. Among all of the other systemic risk measures considered in this study, only the absorption ratio (AR), defined in Appendix A.5, leads the market returns during the global financial crisis from mid-2007 to early 2009, the turbulence throughout 2018, and also during the crash of the COVID-19 pandemic, for 6 to 9 months. However, as an early signal, the AR may not be dependable given the low position of the value of the AR before the global financial crisis from mid-2007 to early 2009. It is even dropping before the turbulence throughout 2018. The only time that we can claim the AR as an early signal is before the COVID-19 pandemic, when the AR keeps climbing, especially with a jump after late 2019, until mid-2020.
In the global financial crisis from mid-2007 through early 2009, CoVaR leads only from mid-2008 to early 2009, which covers the strongest period of the crash throughout the study period. However, the measure lags during the remaining period of the crisis. The Systemic Expected Shortfall (SES), defined in Appendix A.4, leads from mid-2007 to early 2009 but still does not lead throughout the whole financial crisis, and it also lags the market returns in the most remaining market crashes.
5. Discussion
In this paper, we have proposed a new approach for predicting systemic financial risk by using stock return correlations, financial networks, and a latent unobserved financial space. We first observe the relationships between institutions through the correlations among their stock returns, demonstrating that the stock returns often reveal the impact of news about an institution. If two institutions have a significant relationship, any impact on one could transfer to the other institution, so by capturing the correlations among their stock returns, we can evaluate the strength of the relationship between the two institutions.
In the business world, institutions can be related either directly or indirectly. Where there is a direct relationship, institutions may rely on each other to earn revenue, and the failure of one can severely harm others’ ability to earn. In the case of an indirect relationship, the contagion of failure from one institution to others can occur between other institutions that do not have a direct relationship with the source of failure. The key issue, therefore, is how strongly two institutions are related, rather than whether or not any relationship between them exists. A failure in one institution that has a strong relationship with others can lead to subsequent failures in the other institutions, and we therefore construct a financial network to use for capturing those strong inter-institutional relationships. That financial network shows that relationships are stronger during financial turbulence than in normal periods.
To better explain the contagion of systemic risk, we have introduced the concept of financial space, which is closely related to the visualization of network and latent space modeling. We allow each institution to take its optimal position in the financial space so that the distances between institutions accurately reflect their relationships. At the same time, the financial space allows us to visualize the relationship by embedding the financial space into the network. The position of stocks in the financial space represents the market situation in the sense the denser the financial space, the greater the systemic risk.
We thus make use of the distances between institutions in the financial space as one of the inputs to our proposed systemic risk score. A previous study took the network itself into account (Das Citation2016) that we base on their work. First, we dynamically relate the systemic risks together. Often the relationships between companies are time-dependent, and the financial space model has the potential to keep track of changes in those relationships and to give an early warning signal of upcoming financial instabilities via the model’s systemic risk scores. The second advancement is that we smooth the systemic risk score by replacing the binary value in the adjacency matrix with the distance between the stocks in the network plot. This gives more information about the closeness of the relationship between each pair of companies. The third advancement is the use of Bayesian decision setting, which allows for consideration of various financial situations. Our systemic risk scores take the weights assigned to each stock as the second input. Often, a particular setting of a stock’s weight is insufficient to describe a financial situation, but in using the Bayesian decision theory we collect all possible cases and give each a level of importance according to how well each case fits the financial situation. We believe this provides a better picture with which investors and portfolio managers can monitor systemic risk in their situations.
In our study, we have also compared the performance of the systemic risk score with various other systemic risk measures from previous studies. We have used the dynamic time wrapping technique to match the pattern of the systemic risk measures and the returns of the Hong Kong market. Our proposed systemic risk score using the financial space fairly consistently leads the returns of the HSI beginning roughly three months before the historical worldwide financial incident, including the global financial crisis and the COVID-19 pandemic. Although our measure is not perfect in producing an early signal all of the time, the performance is better than that of other measures, including that using an adjacency matrix (Das Citation2016) and an institution-specified random effects model.
On the other hand, the indication of turbulence in a smaller scale incident, like those from mid to late 2011, from mid-2015 to early 2016, and throughout 2018 and 2022, is weaker than the indication in a worldwide financial incident. We believe that the worldwide financial incident is caused by the superposition of multiple factors. Before the crashes, the systemic risk score captures some of the factors and has sufficient time to raise a signal. Therefore, even though the performance of the systemic risk score on a smaller scale of the incident is not as satisfactory as in a worldwide financial incident, the climbing systemic risk score over the turbulence period can also be a sign of accumulating the factors to trigger a larger scale of the incident.
We have also demonstrated several applications of the systemic risk scores in the Bayesian framework. By assigning a suitable before the weights, we inject our beliefs into the measurement of systemic risk. Our score for systemic risk also has an intuitive explanation in accord with traditional knowledge in investment, so investors can apply their knowledge to determine the systemic risk in their investment. Once the contribution of systemic risk is determined, we can change our prior belief for various applications and recompute the systemic risk score without spending much computational power.
Our proposed approach for predicting systemic risk inherits the advantage from Das (Citation2016) that the score is a general approach to studying systemic risk. We have chosen the correlation of stock returns as our source of data to construct the network. As we explain in Section 4.2, during financial turbulence, the networks of institutions are usually more connected than they are during normal periods. This is one of the criteria for being a good source of data for measuring the relationships’ contribution to the systemic risk score. However, because the correlations measure the institutional associations and do not consider the interactions, they might not be the perfect measure of connectedness. Nevertheless, as we discussed in Section 2.4, the latent space model can capture the relationships through a chain of intermediates, which is often neglected in network studies, and because the distances in the latent space are symmetric, they are natural for embedding an undirected network. Therefore, we decide to use an undirected network, and hence we have to set symmetric criteria, for the correlation, to determine whether a pair of stocks is linked.
Since we build both the financial space model and the random effect model based on whether there are edges between two nodes in the network, and summarize the estimated chance of observing a link via averaging, as shown in our study, the performance of the systemic risk score can be linked to network densities. On one hand, from , we observe that before the turbulence from mid-2015 to early 2016, and throughout 2018, the network densities are dropping. On the other hand, we found a similar pattern in all sub-figures in .
We also find that the systemic risk score in the turbulence period of 2022 is lower than other normal periods. The major reason is the absence of edges in the network. This means that there are fewer pairs of stocks having a significant correlation, which coincides with the result in . However, the correlation of stock returns is not the only factor that triggers market turbulence. This is one example showing that the correlation measure is not a perfect criterion to determine the edge in the network.
Therefore, we suggest readers, who are interested in applying the model to other datasets, first examine the network densities, which require much less computation cost, for a glance at the limitation of the resulting systemic risk score with their data input. Nevertheless, it does not mean that the network densities have a similar performance as the financial space model or the random effect model. As the formulation of Das (Citation2016) is solely based on the adjacency matrix, which gives a systemic risk score even more closely related to the network densities than those via models, we can see from that the systemic risk score using the network densities alone cannot make the same performance as those using the financial space model and the random effect model.
Moreover, our proposed systemic risk score is not confined to a single type of data—it is flexible enough to measure the systemic risk even if the contribution to systemic risk C is not symmetric. Therefore, a possible direction for future research is to determine and compare systemic risk scores using the contributions of systemic risk based on various sources of data. For example, in the study of the social network, we can use the proposed financial space concept to create a latent social space to detect social communities (Gerlach et al. Citation2018). The systemic risk score proposed in this study can be a measure of the strength of relationships within a community or a measure of social capital (Shin Citation2021). In epidemiological studies, a contagion space provides a latent plane to study the evolution of pandemic (So et al. Citation2020b; Chu et al. Citation2020, Citation2021). The proposed financial space can be interpreted as a pandemic space where the proposed systemic risk score can give a measure of pandemic risk. From the information retrieval perspective, our approach can help to analyze a dynamic news topic network (So et al. Citation2022) and a Google Trends dynamic network (Chu et al. Citation2023).
In addition, the network construction process converts a continuous measure into a binary one, and information about the strength of the relationship is lost. We can partially see the effect on loss when we compare the proposed systemic risk score with the systemic risk score using the adjacency matrix directly. A remedy would be to incorporate multiple levels together, such as the three levels of thresholds we used in our study. The levels would be sequential, so the correlations would be required to pass the lower level before they could reach a higher level. By doing that, we could reduce the loss of information in the conversion and could distinguish those institutions with stronger relationships.
Last, we find that the systemic risk scores fluctuate more vigorously than other systemic risk measures do, such as the SES, CoVaR, and absorption ratio. We can also observe this feature in , the network density plot. An advantage of this feature is that the systemic risk scores are more sensitive to the latest market situations. However, such fluctuations can also produce a false positive that initiates a false warning signal. We believe that by tuning the number of days of correlation to be considered in the formation of the network, we could strike a balance between the model’s sensitivity to market updates and the false positive issue.
Acknowledgements
We thank the Editor-in-Chief, Professor David Matteson, and four anonymous reviewers for their helpful comments. We also thank the Turing AI Computing Cloud (TACC) platform for providing us with the computational resources to conduct the analyses in this paper. This work was partially supported by the Hong Kong RGC Theme-based Research Scheme, grant number T31-604/18-N, and The Hong Kong University of Science and Technology research grant “Risk Analytics and Applications” (grant number SBMDF21BM07). The funding recipient was MKPS.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abbassi P, Brownlees C, Hans C, Podlich N. 2017. Credit risk interconnectedness: What does the market really know? J Financ Stab. 29:1–12. https://www.sciencedirect.com/science/article/pii/S1572308917300311.
- Acemoglu D, Ozdaglar A, Tahbaz-Salehi A. 2015. Systemic risk and stability in financial networks. Am Econ Rev. 105(2):564–608.
- Acharya VV, Pedersen LH, Philippon T, Richardson M. 2017. Measuring systemic risk. Rev Financ Stud. 30(1):2–47.
- Adrian T, Brunnermeier MK. 2016. Covar. Am Econo Rev. 106(7):1705–1741.
- Aiyar S. 2012. From financial crisis to great recession: the role of globalized banks. Am Econom Rev. 102(3):225–230.
- Allaj E, Sanfelici S. 2022. Early warning systems for identifying financial instability. International Journal of Forecasting; [accessed] https://www.sciencedirect.com/science/article/pii/S0169207022001133.
- Ando T. 2009. Bayesian portfolio selection using a multifactor model. Int J Forecast. 25(3):550–566. https://www.sciencedirect.com/science/article/pii/S016920700900003X.
- Ballester L, López J, Pavía JM. 2023. European systemic credit risk transmission using Bayesian networks. Res Int Busin Finance. 65:101914. https://www.sciencedirect.com/science/article/pii/S0275531923000405.
- Battista GD, Eades P, Tamassia R, Tollis IG. 1994. Algorithms for drawing graphs: an annotated bibliography. Comput Geom. 4(5):235–282. https://www.sciencedirect.com/science/article/pii/092577219400014X.
- Battiston S, Puliga M, Kaushik R, Tasca P, Caldarelli G. 2012. DebtRank: Too central to fail? Financial networks, the FED and systemic risk. Scient Rep. 2(1):1–6.
- Benoit S, Colliard JE, Hurlin C, Pérignon C. 2017. Where the risks lie: a survey on systemic risk. Rev Finance. 21(1):109–152.
- Bhar R, Nikolova B. 2013. Measuring the interconnectedness of financial institutions. Economic Syst. 37(1):17–29. https://www.sciencedirect.com/science/article/pii/S0939362512000775.
- Billio M, Casarin R, Costola M, Pasqualini A. 2016. An entropy-based early warning indicator for systemic risk. J Int Financ Markets Instit Money. 45:42–59.
- Billio M, Getmansky M, Lo AW, Pelizzon L. 2012. Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J Financ Econom. 104(3):535–559.
- Blei SK, Ergashev B. 2014. Asset commonality and systemic risk among large banks in the United States. Available at SSRN 2503046.
- Brownlees C, Engle RF. 2017. SRISK: a conditional capital shortfall measure of systemic risk. Rev Financ Stud. 30(1):48–79.
- Brunnermeier MK. 2009. Deciphering the liquidity and credit crunch 2007–2008. J Econom Persp. 23(1):77–100.
- Cai J, Eidam F, Saunders A, Steffen S. 2018. Syndication, interconnectedness, and systemic risk. J Financ Stabil. 34:105–120. https://www.sciencedirect.com/science/article/pii/S1572308917303698.
- Chan LSH, Chu AMY, So MKP. 2023. A moving-window Bayesian network model for assessing systemic risk in financial markets. PLoS One. 18(1):e0279888.
- Chan N, Getmansky M, Haas SM, Lo AW. 2005. Systemic risk and hedge funds. National Bureau of Economic Research. Working Paper 11200; [accessed]. http://www.nber.org/papers/w11200.
- Chen L, Han Q, Qiao Z, Stanley HE. 2020. Correlation analysis and systemic risk measurement of regional, financial and global stock indices. Physica A. 542:122653.
- Chopin N, Singh SS. 2015. On particle Gibbs sampling. Bernoulli. 21(3):1855–1883.
- Chu AMY, Chan TWC, So MKP, Wong WK. 2021. Dynamic network analysis of COVID-19 with a latent pandemic space model. Int J Environ Res Public Health. 18(6):3195.
- Chu AMY, Chong ACY, Lai NHT, Tiwari A, So MKP. 2023. Enhancing the predictive power of google trends data through network analysis: infodemiology study of Covid-19. JMIR Public Health Surveill. 9(1):e42446.
- Chu AMY, Tiwari A, So MKP. 2020. Detecting early signals of covid-19 global pandemic from network density. J Travel Med. 27(5):taaa084.
- Contreras S, Delis MD, Ghosh A, Hasan I. 2022. Bank failures, local business dynamics, and government policy. Small Bus Econ. 58(4):1823–1851.
- Das SR. 2016. Matrix metrics: network-based systemic risk scoring. J Alterna Invest. 18(4):33–51.
- De Bandt O, Hartmann P. 2000. Systemic risk: a survey. Available at SSRN 258430.
- De Nicolo G, Kwast ML. 2002. Systemic risk and financial consolidation: Are they related? J Bank Finance. 26(5):861–880.
- Deng G, Matteson DS. 2022. Bayesian spillover graphs for dynamic networks. In: Uncertainty in Artificial Intelligence. PMLR. p. 529–538.
- Diebold FX, Yılmaz K. 2014. On the network topology of variance decompositions: measuring the connectedness of financial firms. J Economet. 182(1):119–134.
- Dwyer GP, Tkac P. 2009. The financial crisis of 2008 in fixed-income markets. J Int Money Finance. 28(8):1293–1316.
- Florens JP, Simoni A. 2021. Revisiting identification concepts in bayesian analysis. Ann Econom Statist. 2021(144):1–38.
- Gandy A, Veraart LA. 2017. A Bayesian methodology for systemic risk assessment in financial networks. Manage Sci. 63(12):4428–4446.
- Gelman A, Gilks WR, Roberts GO. 1997. Weak convergence and optimal scaling of random walk metropolis algorithms. Ann Appl Probab. 7(1):110–120.
- Gerlach M, Peixoto TP, Altmann EG. 2018. A network approach to topic models. Sci Adv. 4(7):eaaq1360.
- Giao BC, Anh DT. 2016. Similarity search for numerous patterns over multiple time series streams under dynamic time warping which supports data normalization. Vietnam J Comput Sci. 3(3):181–196.
- Giorgino T. 2009. Computing and visualizing dynamic time warping alignments in R: the dtw package. J Stat Soft. 31(7):1–24.
- Girardi G, Ergün AT. 2013. Systemic risk measurement: multivariate GARCH estimation of CoVaR. J Bank Finance. 37(8):3169–3180.
- Haldane AG, May RM. 2011. Systemic risk in banking ecosystems. Nature. 469(7330):351–355.
- Han D. Khoojine AS. 2019. Network analysis of the Chinese stock market during the turbulence of 2015–2016 using log-returns, volumes and mutual information. Physica A. 523:1091–1109.
- Hanson SG, Kashyap AK, Stein JC. 2011. A macroprudential approach to financial regulation. J Economic Perspect. 25(1):3–28.
- Härdle WK, Wang W, Yu L. 2016. Tenet: tail-event driven network risk. J Economet. 192(2):499–513.
- Hautsch N, Schaumburg J, Schienle M. 2015. Financial network systemic risk contributions. Rev Finance. 19(2):685–738.
- He Z, Krishnamurthy A. 2019. A macroeconomic framework for quantifying systemic risk. Am Economic J. 11(4):1–37.
- Heimo T, Saramäki J, Onnela JP, Kaski K. 2007. Spectral and network methods in the analysis of correlation matrices of stock returns. Physica A. 383(1):147–151.
- Hoff PD, Raftery AE, Handcock MS. 2002. Latent space approaches to social network analysis. J Am Stat Assoc. 97(460):1090–1098.
- Huang X, Vodenska I, Havlin S, Stanley HE. 2013. Cascading failures in bi-partite graphs: model for systemic risk propagation. Sci Rep. 3(1):1–9.
- Hurley JR, Cattell RB. 1962. The procrustes program: producing direct rotation to test a hypothesized factor structure. Behav. Sci. 7(2):258–262.
- Jackson MO, Pernoud A. 2021. Systemic risk in financial networks: a survey. Annu Rev Econ. 13(1):171–202.
- Jiaxing Li ZS. 2022. Stock markets crash in Hong Kong, Shanghai and Shenzhen on a raft of bad news after China’s leadership reshuffle. South China Morning Post; [accessed 2023 Oct 25]. https://www.scmp.com/business/china-business/article/3197041/chinas-leadership-reshuffle-stuns-investors-markets-see-risks-policy-mistakes-shocks-economy.
- Kawata S, Fujiwara Y. 2016. Constructing of network from topics and their temporal change in the Nikkei newspaper articles. Evolut Inst Econ Rev. 13(2):423–436.
- Kritzman M, Li Y, Page S, Rigobon R. 2011. Principal components as a measure of systemic risk. JPM. 37(4):112–126.
- Lai Y, Hu Y. 2021. A study of systemic risk of global stock markets under COVID-19 based on complex financial networks. Physica A. 566:125613.
- Linardi F, Diks C, van der Leij M, Lazier I. 2020. Dynamic interbank network analysis using latent space models. J Economic Dynam Control. 112:103792.
- Lindsten F, Jordan MI, Schon TB. 2014. Particle Gibbs with ancestor sampling. J Mach Learn Res. 15:2145–2184.
- Liu Y. 2018. Hong Kong stocks down a wretched 14 per cent in 2018 – the worst performance in 7 years. South China Morning Post; [accessed 2023 Oct 25]. https://www.scmp.com/business/markets/article/2180077/hong-kong-stocks-get-boost-trump-xi-weekend-phone-call-signalling.
- Lockett H. 2022. China shares fall sharply on concerns over Covid outbreak and Ukraine war. Financial Times; [accessed 2022 Jul 10]. https://www.ft.com/content/528f580a-6770-4940-b8f8-670cf409580a.
- Lupu R, Călin AC, Zeldea CG, Lupu I. 2020. A Bayesian entropy approach to sectoral systemic risk modeling. Entropy. 22(12):1371.
- Maiya AS, Rolfe RM. 2014. Topic similarity networks: visual analytics for large document sets. In: 2014 IEEE International Conference on Big Data (Big Data). p. 364–372.
- Mantegna RN, Stanley HE. 1999. Introduction to econophysics: correlations and complexity in finance. Cambridge: Cambridge University Press.
- Martínez-Jaramillo S, Pérez OP, Embriz FA, Dey FLG. 2010. Systemic risk, financial contagion and financial fragility. J Econom Dynam Control. 34(11):2358–2374.
- Neveu AR. 2018. A survey of network-based analysis and systemic risk measurement. J Econ Interact Coord. 13(2):241–281.
- Ng KC, So MKP, Tam KY. 2021. A latent space modeling approach to interfirm relationship analysis. ACM Trans Manage Inf Syst. 12(2):1–44.
- Patro DK, Qi M, Sun X. 2013. A simple indicator of systemic risk. J Financ Stabil. 9(1):105–116.
- Plummer M, Best N, Cowles K, Vines K. 2006. Coda: convergence diagnosis and output analysis for mcmc. R News. 6(1):7–11.
- Rachev ST, Hsu JS, Bagasheva BS, Fabozzi FJ. 2008. Bayesian methods in finance. Hoboken: John Wiley & Sons.
- Raddant M, Kenett DY. 2021. Interconnectedness in the global financial market. J Int Money Finance. 110:102280.
- Rankin J, Milman O, Ni V. 2021. Global energy crisis: how key countries are responding. The Guardian; [accessed 2022 July 28]. https://www.theguardian.com/business/2021/oct/12/global-energy-crisis-how-key-countries-are-responding.
- Rodríguez-Moreno M, Peña JI. 2013. Systemic risk measures: The simpler the better? J Bank Finance. 37(6):1817–1831.
- Sakoe H, Chiba S. 1978. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans Acoust, Speech, Signal Process. 26(1):43–49.
- Sewell DK, Chen Y. 2015. Latent space models for dynamic networks. J Am Stat Assoc. 110(512):1646–1657.
- Shin B. 2021. Exploring network measures of social capital: toward more relational measurement. J Plann Literature. 36(3):328–344.
- So MKP, Chan LSH, Chu AMY. 2021a. Financial network connectedness and systemic risk during the COVID-19 pandemic. Asia-Pac Financ Markets. 28(4):649–665.
- So MKP, Chan TWC, Chu AMY. 2020a. Efficient estimation of high-dimensional dynamic covariance by risk factor mapping: applications for financial risk management. J Economet. 227:151–167.
- So MKP, Chu AMY, Chan TWC. 2021b. Impacts of the COVID-19 pandemic on financial market connectedness. Finance Res Lett. 38:101864.
- So MKP, Chu AMY, Lo CCY, Ip CY. 2021c. Volatility and dynamic dependence modeling: review, applications, and financial risk management. Wiley Interdiscip Rev Comput Stat. 2021:e1567.
- So MKP, Mak ASW, Chu AMY. 2022. Assessing systemic risk in financial markets using dynamic topic networks. Sci Rep. 12(1):2668.
- So MKP, Tiwari A, Chu AMY, Tsang JTY, Chan JNL. 2020b. Visualizing Covid-19 pandemic risk through network connectedness. Int J Infect Dis. 96:558–561.
- Tabak BM, Takami M, Rocha JM, Cajueiro DO, Souza SR. 2014. Directed clustering coefficient as a measure of systemic risk in complex banking networks. Physica A. 394:211–216.
- Thurner S, Poledna S. 2013. Debtrank-transparency: controlling systemic risk in financial networks. Sci Rep. 3(1):1888.
- Tomczak K. 2023. Transmission of the 2007–2008 financial crisis in advanced countries of the european union. Bulletin of Econ Res. 75(1):40–64.
- Tormene P, Giorgino T, Quaglini S, Stefanelli M. 2009. Matching incomplete time series with dynamic time warping: an algorithm and an application to post-stroke rehabilitation. Artif Intell Med. 45(1):11–34.
- Ureche-Rangau L, Burietz A. 2013. One crisis, two crises… the subprime crisis and the European sovereign debt problems. Econom Modell. 35:35–44.
- Wang GJ, Xie C, He K, Stanley HE. 2017. Extreme risk spillover network: application to financial institutions. Quant Finance. 17(9):1417–1433.
- Wang GJ, Yi S, Xie C, Stanley HE. 2021. Multilayer information spillover networks: measuring interconnectedness of financial institutions. Quant Finance. 21(7):1163–1185.
- Zhang X, Xu G, Zhu J. 2022. Joint latent space models for network data with high-dimensional node variables. Biometrika. 109(3):707–720.
Appendix A.
Other Measures of Systemic Risk in the Literature
Several approaches have been used to create systemic risk measures in previous studies. In this study, we have compared the performance of our score with that of other measures. The first two are related to our score, one of which is the systemic risk score proposed by Das (Citation2016), which uses the adjacency matrix of the network as the contribution of systemic risk, without accessing the financial space. The other one uses a random effects model instead of the financial space model. The remaining three are common systemic risk measures in the literature: CoVaR, SES, and AR.
A.1 Using Adjacency Matrix of Network
The first approach, motivated by Das (Citation2016), considers the adjacency matrix of the network as the contribution of systemic risk. Because the existence of an edge between nodes represents a significant relationship, we calculate the systemic risk by replacing the contribution of systemic risk C with the adjacency matrix of the network linking the stocks with significant business relationships:
(A1)
(A1)
(A2)
(A2)
where
is the weight. The adjacency matrix contains only a binary value, which equals the sum of the products of weights of those institutions that have significant relationships. We have used this formulation in Section 4.4 to compare the systemic risk score under this setting to other formulations, showing the differences and advantages in using the financial space over solely considering the direct relationship between institutions in .
A.2 Using Institution-Specified Random Effect Model
The second approach considers an institution-specified random effects model instead of the latent space model. In Section 2.3.4, the financial space affects the log odds via the distance between institutions in the space. We consider an alternative to replace the distance with a sum of two random effects, one on each institution of the pair under consideration.
(A3)
(A3)
where
and
are univariate random intercepts. This comparison assesses the performance of our proposed model versus that of a simpler standard base model. The apostrophe on
and
distinguish the random intercept from the latent position. Similarly, the apostrophe on
distinguishes the two formulations of log odds.
Let be the estimated log odds using the random effects model specified by EquationEquation (A3)
(A3)
(A3) on a trading day t, and let
be the matrix of the estimated log odds. We need to transform the estimated log odds to ensure that the contribution to systemic risk is positive. Again, the natural choice is EquationEquation (13)
(13)
(13) . We substitute
into C to calculate the systemic risk:
(A4)
(A4)
(A5)
(A5)
where
is the weight. The random effects model is a simplified model of our latent space model. We have used this formulation in Section 4.4 to compare the systemic risk score under this setting to the one using financial space, showing the ability to capture the indirect business relationship with the financial space in .
A.3 Using CoVaR
The third approach measures the change of conditional value-at-risk (CoVaR) in the market returns when there is distress on stock j from the CoVaR of market returns when stock j is of normal status. In other words, it is the difference between the market returns when the return of stock j equals its VaR and when the return of stock j equals its median.
In our study, we define the distress as VaR, which is defined by the
percentile of the returns of stock within the most recent two years. Some stocks have incomplete information within the last two years, which may be due to non-listing or other reasons. We first let
be the set of stocks with no missing returns within the last two years preceding the trading day t. We denote the number of stocks in
by
On trading day t, we let
be the
VaR of stock j. In particular, when
we have
as the median of the returns of stock j. We replace the subscript j with market when we are referring to the market returns. Furthermore, we denote
to be the
VaR of the market, given that the return of stock j is
Therefore, the value of
and
satisfy the following equations, with respect to the returns in the last two years preceding trading day t:
(A6)
(A6)
(A7)
(A7)
where
is the market returns at trading day t, and we use
and 50 for our study.
We measure the systemic risk of the market on trading day t by taking an average of
(A8)
(A8)
over all j.
A.4 Using the Systemic Expected Shortfall
The fourth approach considers the distress over the whole market rather than that of a particular stock. We let to be the
VaR of the market on trading day t, and
be the expected return of stock j conditional on the market return on the trading day t less than
Then,
satisfies the following equation, with respect to the returns in the most recent two years.
(A9)
(A9)
where
is the collection of trading days of size
in the last two years before the trading day t, so that the market return is less than
In other words, trading day
is inside
if
and the trading day
is in the last two years preceding trading day t. We measure the systemic risk of the market on trading day t by taking the average of
over all j with
(A10)
(A10)
where
is the (unconditional) expected returns of stock j.
A.5 Using Absorption Ratio
The last approach we analyzed from previous studies considers the proportion of information absorbed by the first few principal components in the two-year historical covariance matrix of stock returns. That covariance matrix provides information on the variation in stock returns that cannot be explained by the average returns. The principal components analysis sequentially extracts the most important information from the covariance matrix while ensuring that there are no correlations in the information. If the first few principal components can explain most of the information in the covariance matrix, the variation most likely depends on these pieces of information. In other words, these few pieces of information control the variation of the stocks. If this important information is adverse news, it drives the stock returns to fall together, and that creates an impact on the market.
We study the proportion of information absorbed by the first principal components of the historical covariance matrix
of stock returns in the last two years preceding trading day t. If the returns are available for all 76 stocks constituting the Hang Seng Indexes in May 2023, we consider the first 15 principal components (rounded down to the nearest integer). Let
be the eigenvalues and let
be the corresponding eigenvectors of
We then have the following equation satisfied,
(A11)
(A11)
Therefore, we calculate the absorption ratio by
(A12)
(A12)
Appendix B.
Dynamic Time Wrapping
Suppose that two time series have T trading days. A wrapping curve is a function taking value value from
as input and returning value from
as output, pairing K points from each of the time series and satisfying the following requirements:
These requirements align the starting and ending points of both time series, and ensure that the wrapping curve matches points along the time. Moreover, the wrapping curve has to follow the local slope constraints, so that the and
are restricted according to the step pattern (Tormene et al. Citation2009). We will introduce the step pattern of interest in a later paragraph.
The dynamic time wrapping algorithm aims at an optimal wrapping curve so that the average accumulated distortion between
and
is minimized. The distortion refers to the extent of mismatch in the two time series. The first factor is the absolute difference between the two time series S and R at trading days
and
as the distortion.
(B1)
(B1)
The second factor depends on the step pattern together with a normalizing constant. Therefore, given among all possible choices of
the step pattern also takes part in determining the optimal wrapping curve. The normalization constant makes sure the wrapping curve
of different lengths is comparable. Joining all of the information together, the average accumulated distortion is defined.
(B2)
(B2)
where
is a per-step weighting coefficient and
is the corresponding normalization constant to make sure the wrapping curves
with different lengths are comparable.
Because the first factor of distortion is measured in an absolute sense, both the location and scale of the time series have an impact on the resulting wrapping curve (Giao and Anh Citation2016). Therefore, a suitable transformation is necessary for a meaningful result. In our study, we have chosen the z standardization, translating and scaling the whole time series so that the mean and the standard deviation of the resulting time series are 0 and 1, respectively. The market return has been further multiplied by negative 1 so that a spike in the systemic risk score matches a crash in the market return.
In the above constraints on the wrapping curve, the alignment of the starting and ending points may produce a bias in studying the lead and lag relationships. Therefore, we follow Tormene et al. (Citation2009) to allow open start and end points, and we make further assumptions as a replacement to achieve a meaningful wrapping curve:
The first constraint fixes the function and the value of K to be T. The third constraint bounds the points in the two time series to match a moderate integer (Sakoe and Chiba Citation1978), which here we have chosen to be 150. The first two constraints constitute the so-called asymmetric step pattern, so that
and
Appendix C.
Computational Details Related to the Proposed Systemic Risk Score
First, to facilitate the computation of the systemic risk score, no matter which distribution is assigned to the weights, we use a simulation-based approach to calculate the systemic risk score. In our study, we simulate a sample of size and estimate the systemic risk score by
(C1)
(C1)
where
is simulated from the distribution of weights, and C is the contribution to systemic risk.
Referring to Section 2.2, we have considered two choices of priors in our study. The first one is a Dirichlet distribution. The sampling procedure is standard. The second choice requires sampling from a Dirichlet distribution multiple times. Suppose we have fixed G, which is the number of groups in total, and have determined the sum of weights in each group. For each group g, we sample
from the Dirichlet distribution of the dimension being the number of stocks in group g. Then, we concatenate all
together to form
a vector of length n, so that the sum of all entries in
equals 1.
Appendix D.
Diagnostic of the MCMC Estimation
In our experiment, we employ particles in the particle Gibbs with ancestor sampling approach. Additionally, we conduct a separate experiment using
particles to examine the impact on the MCMC diagnostics. Thus, in this section, we present the MCMC diagnostic results for both settings.
D.1 Posterior Plot
shows the log of the posterior density of every iteration in each rolling sample. shows that the Markov chains in each rolling sample have converged after the burn-in. Comparing both sides of the figures, the log of posterior density does not show much difference when using and
particles.
D.2 Trace plot of Selected Parameters
and display the trace plots of selected parameters in each rolling sample for particles and
particles, respectively. Both figures demonstrate that the parameters in each rolling sample have converged after the burn-in period. We have also selected some parameters related to the financial space, but we defer the demonstration and the discussion of these parameters to Appendix E.
D.3 Step size Adaptation and Acceptance Rate
As described in Section 3.6, we adjust the step size during the burn-in period to achieve an optimal acceptance rate. provides a summary of the average finalized step size for each parameter and systemic risk score using and
particles, respectively. The step size for
is automatically tuned by the particle Gibbs with ancestor sampling scheme, as explained in Section 3.5. The average step sizes for
and
across all stocks and dimensions are reported.
shows the minimum, mean, and maximum of the average acceptance rates over all parameters, excluding during each MCMC stage and of each systemic risk score when using
and
particles respectively. After the burn-in period, in both
and
particles, the mean of the average acceptance rate stays at or slightly above the upper bound of the desired intervals, i.e. 0.268.
illustrates the update rate of the particle Gibbs approach applied to the financial space for three selected rolling samples (i.e. rolling samples 4, 118, and 216). The update rate of
represents the proportion of iterations in which the value of
changes. We observe that, in general, using a higher threshold percentage on the networks and a larger number of particles results in a higher update rate.
While the update rates typically range from 0.8 to 0.85 for particles and around 0.95 for
particles on most trading days, occasional drops below these levels are inevitable due to particle degeneracy (Chopin and Singh Citation2015). However, it does not show a pattern of increasing update rates from a low value at the beginning. Instead, the rates fluctuate around a level slightly lower than the ideal rate Lindsten et al. (Citation2014). We believe that the use of ancestor sampling has mitigated the issue of particle degeneracy.
D.4 Effective sample size
We calculate the effective sample size using the coda package in R (Plummer et al. Citation2006). present the minimum, mean, and maximum average effective sample sizes across parameters during the burn-in period, after the burn-in period, and the entire MCMC period using and
particles, respectively. Occasionally, the dependence among model parameters results in a lower effective sample size, but in general, the effective sample size reaches around 1500. Additionally, we observed that the effective sample size does not differ much between
and
particles.
D.5 Area under ROC
To assess the accuracy of our model in estimating the edges in the network, we compute and illustrate in the area under the receiver operating characteristic (AUROC) curve for each rolling sample and each network threshold
and
using
and
particles. We observe that a smaller threshold percentage yields a higher accuracy. Furthermore, there is an improvement in AUROC when using
particles compared to
particles.
D.6 Computation Time
In the rolling sample analysis, the number of stocks n and the number of trading days T vary. The number of stocks n ranges from 28 to 65, corresponding to the number of constituents in HSI. The number of trading days T ranges from 487 to 501. To indicate how well the algorithm scales, we selected three sets of n and T (i.e. rolling samples 4, 118, and 216) and reported the computation time in . We believe that the computation time grows linearly with n. However, since the variation in T in the rolling sample analysis is small, it is difficult to determine precisely how the computation time grows with T. When comparing the computation time between and
particles, we believe that the computation time grows linearly with Q.
Figure D1. The posterior plot of each rolling sample (arranged in colors) for all three thresholds (1% Threshold: (a-b); 5% Threshold: (c-d); 10% Threshold: (e-f)) along the iterations using (a, c, e) and
(b, d, f) particles.
Figure D2. The trace plot of effect parameters in each rolling sample (arranged in colors) for all three thresholds (1% Threshold: (a, d, g, j); 5% Threshold: (b, e, h, k); 10% Threshold: (c, f, i, l)) along the iterations when using particles.
Figure D3. The trace plot of effect parameters in each rolling sample (arranged in colors) for all three thresholds (1% Threshold: (a, d, g, j); 5% Threshold: (b, e, h, k); 10% Threshold: (c, f, i, l)) along the iterations when using particles.
Figure D4. The update rate of the particles Gibbs approach with (solid) and
particles (dashed) to the parameter
on some selected rolling sample (4: (a); 118: (b);216: (c)). The black lines indicate the ideal rates of
(
solid;
dashed) Lindsten et al. (Citation2014).
Figure D5. The area under ROC over each rolling sample (date referred to the last trading day in each rolling sample) and each of the network (red),
(green), and
(blue) respectively using
(solid) and
(dashed) particles.
Table D1. The average finalized step size of each parameter and of each systemic risk score when using and
particles.
Table D2. The minimum, mean, and maximum of the average acceptance rates over all parameters during each MCMC stage and of each systemic risk score when using particles.
Table D3. The minimum, mean, and maximum of the average acceptance rates over all parameters during each MCMC stage and of each systemic risk score when using particles.
Table D4. The minimum, mean, and maximum of the average effective sample size over parameters during each MCMC stage and of each systemic risk score when using particles.
Table D5. The minimum, mean, and maximum of the average effective sample size over parameters during each MCMC stage and of each systemic risk score when using particles.
Table D6. The number of stocks, the number of trading days, and the computation time taken for the MCMC of three selected rolling samples.
Appendix E.
The Multi-Modal Nature of the Posterior Density
To handle the identifiability issue, we have transformed the MCMC iterate as described in Section 3.2. To have the unique representation of the latent positions, after transforming the MCMC iterate, we observe that the posterior density of some latent positions has multiple modes.
displays both the trace plot and density plot of the estimated posterior density for the positions of CNOOC Limited (0883.HK), BOC Hong Kong (2388.HK), and Esprit Holdings (0330.HK) on April 8, 2005 in the first rolling sample. The network used was constructed using a 1% threshold. Despite the transformation being applied to every MCMC iterate, the density plots of most stock on any trading day in each rolling sample exhibit a multi-modal nature. We specifically selected this combination of stocks and trading day to demonstrate the multi-modal nature. The estimated posterior density for the positions of CNOOC Limited (0883.HK) and Esprit Holdings (0330.HK) exhibits multiple modes, while the estimated posterior density for the position of BOC Hong Kong (2388.HK) has a single mode.
Upon examining the trace plot for the selected stock, we observed that the Markov chain traverses across modes throughout the iterations, indicating good mixing of the MCMC iterates for positions of stocks in the financial space.
Supported by , even after applying the transformation in Section 3.2 to achieve the unique representation of the latent positions based on the MCMC iterates, the posterior density remains multi-modal and exhibits reflection symmetry across the two axes and the two diagonals. Therefore, as shown in sub-figures (c) and (i) of , the posterior mean of a stock in the financial space may lie in a low probability region. It is worth mentioning that even though sub-figure (f) of suggests the possibility of the posterior mean lying in a high probability region, we assert that the posterior density evaluated at the posterior mean is smaller than the posterior density evaluated at the posterior mode. presents the log posterior density of the first rolling sample based on the network constructed using three threshold levels, along with the log posterior density of the posterior mean. We found that the posterior mean has a substantially lower posterior density than any iterate, including the initial values, supporting our choice to prefer the posterior mode to the posterior mean when computing the systemic risk score and determining reused values used in partial estimation.
Figure E1. The MCMC trace plot (a, b, d, e, g, h) and the density plot (c, f, i) of CNOOC Limited (0883.HK) (a-c), BOC Hong Kong (2388.HK) (d-f), and Esprit Holdings (0330.HK) (g-i) on 8 April 2005 in the first rolling sample. The red cross indicates the estimated posterior mean.
Figure E2. The log posterior density of the first rolling sample based on the network constructed by the three threshold levels (1% Threshold: (a); 5% Threshold: (b); 10% Threshold: (c)). The red horizontal line indicates the log posterior density evaluated at the posterior mean.
Appendix F.
Details on the Identifiability Issue
F.1 Definition of Unidentified Model
Let be the parameters space and
be the model parameter, such that we have
(F1)
(F1)
in our study.
Let be a subset of the parameter space so that the probability of
in the prior is zero. Referring to the result in Florens and Simoni (Citation2021), the model is unidentified when for any
there exist two distinct
such that for any
we have
(F2)
(F2)
Recall that according to EquationEquation (15)(15)
(15) , the log posterior is the sum of the log likelihood, log prior densities, and a constant term, i.e. the marginal likelihood of the observed data. The constant term is excluded because it has no effect when we change the parameters. Therefore, we have, after excluding the constant term
(F3)
(F3)
Therefore, the EquationEquation (F2)(F2)
(F2) becomes
(F4)
(F4)
In other words, the model is unidentified when multiple possible values give the same posterior density. In the following section, we demonstrate that this happens in our model and how we solve this issue.
F.2 Identification Issue Due to the Log Likelihood
Since the log likelihood depends on the distance between the latent positions, instead of the latent positions themselves, as discussed in Section 3.2, any rigid transformation of the financial space is invariant to the log likelihood.
Suppose we first rotate the financial space around the origin, reflect along the axes, and then translate the financial space. We summarize rotation and reflection by an orthogonal matrix and the translation by a vector
so that for every
we have
(F5)
(F5)
satisfying
and
(F6)
(F6)
Therefore, the log likelihood in EquationEquation (F4)(F4)
(F4) cancels out. The identification issue occurs when the
prior density is equal, i.e.
(F7)
(F7)
To avoid identification issues due to the rigid transformation of the financial space, we have to assign a suitable prior and set up constraints to the model parameters to guarantee that among all possible and
the only
satisfying EquationEquation (F7)
(F7)
(F7) is
F.3 Addressing the Identification Issue Due to Translation
Denote
and
as the position of stock i on trading day t in the financial space, the average position of stock i in the financial space, the diagonal matrix of the persistence of stock i in the financial space, and the diagonal matrix of transition size of stock i in the financial space respectively indicated by
We also denote
and
as the collection of all
and
respectively.
According to EquationEquations (8)(8)
(8) and Equation(9)
(9)
(9) , the normal prior of the latent positions
given
and
evaluated at both
and
are identical. Therefore, to address the identification issue due to translation, we have set up a suitable prior for
In our study, the log prior density of after excluding the constant term and substituting the hyperparameters, is
(F8)
(F8)
Further substituting EquationEquation (F5)(F5)
(F5) into EquationEquation (F8)
(F8)
(F8) , we have
(F9)
(F9)
EquationEquation (F8)(F8)
(F8) equals the EquationEquation (F9)
(F9)
(F9) for every
if and only if the translation vector
is zero. In other words, the prior of
addresses the identification issue due to translation.
F.4 Addressing the Identification Issue Due to Arbitrary Rotation
EquationEquation (F5)(F5)
(F5) lists all outcomes of rigid transformation in the financial space, based on
and
On one hand, the transformation given by
has been eliminated by the normal prior of
On the other hand, we also notice that not all
give a legitimate
as a parameter to the model since we have assumed both
and
are diagonal matrices. Therefore, we require
when serving as a legitimate parameter to the model, to be also a diagonal matrix.
Therefore, in the case of dimensional, the orthogonal matrix
has to satisfy either
The diagonal entries are zero, and the off-diagonal entries are either
The diagonal entries are either
This requirement is satisfied when we either rotate the financial space about the origin by multiples of reflect along the axes, or perform any sequence of these two operations.
To emphasize that the orthogonal matrix is no longer arbitrary, we introduce the permutation matrix and the reflection matrix
as in Section 3.2. The permutation matrix indicates which entry in each column of
is non-zero. The reflection matrix governs the sign of the non-zero entry in each column of
The EquationEquation (F5)
(F5)
(F5) becomes
(F10)
(F10)
and now always fit as a parameter to the model.
The two constraints applied to each MCMC iterate, as introduced in Section 3.2, have fixed the permutation matrix and the reflection matrix
in EquationEquation (F10)
(F10)
(F10) . Therefore, there is only one
satisfying EquationEquation (F7)
(F7)
(F7) , and hence the identification issue due to rigid transformation in the financial space is solved.